MapReduce框架下一種負載均衡的Top-k連接查詢算法
2018-08-24 07:51:24,,
計算機測量與控制 2018年8期
關鍵詞:排序
,,
(1.首都師范大學 信息工程學院,北京 100048; 2.北京交通大學 交通運輸學院,北京 100044)
0 引言
排序查詢處理對于大規模數據分析至關重要,通常使用的排序查詢方法稱為Top-k連接查詢算法[1]。Top-k查詢中,根據每個對象的屬性計算一個權重,再通過給定的評分函數為對象進行評分,返回k個最重要的結果[2]。在-+大數據時代,用戶檢查大量未排序的查詢結果集是不現實的。并行化執行不僅可以實現高效地運行,并且可以返回精準的結果。目前MapReduce是一種廣泛應用的并行編程環境[3]。
目前,學者也提出了一些并行的Top-k連接查詢算法。例如,文獻[4]在MapReduce的背景下,提出了兩種關于Top-k連接的方法。一種稱為RanKloud的算法,其在掃描記錄期間計算統計數據,并使用這些統計數據計算提前終止的閾值(Top-k結果的最低分數)。此外,還提出了一種新的分區方法,稱為uSplit,旨在以使用敏感方式對數據進行重新分區。然而,RanKloud不能保證正確的返回k個檢索結果。另外,常用的一種基于 MapReduce 框架的用來計算Top-k連接結果的通用二路連接算法為Reduce-side join,簡稱為RSJ[5],其連接是在Reduce函數中實現。
本文在MapReduce編程模型中實現并行Top-k連接查詢算法(Parallel Top-k Join,P-TKJ),同時融入提前終止機制和負載均衡機制來增強Top-k連接處理的性能。主要創新點為:在MapReduce中提出了一個新的Top-k連接處理框架,盡可能地利用并行性,并避免鏈接MapReduce作業的初始化開銷;使用直方圖形式的數據表示,并融入了提前終止策略、數據過濾和負載平衡策略,以便設計出高效的并行Top-k連接算法。
1 MapReduce 編程模型
MapReduce是Hadoop中的一個編程框架,為并行算法提供了一個容錯和可靠的編程環境。為了處理大量的數據,該框架支持一個可擴展的文件系統,稱為Hadoop分布式文件系統(HDFS),用于在硬件群集中的機器上存儲大量文件。
MapReduce計算過程分成Map和Reduce兩個階段[6],其中數據的格式以鍵值對
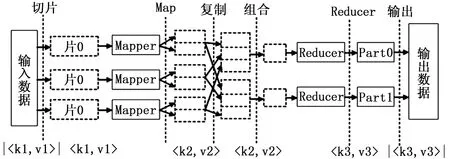
圖1 MapReduce編程模型的處理過程
2 問題描述
2.1 Top-k連接查詢
給定具有n個得分屬性的輸入表或關系T,使用τ代表T的記錄(或元組),τ[i]是指第i個得分屬性(i∈[1,n])。Top-k查詢q(k,f)基于單調評分函數f返回k個最佳查詢結果。當應用于關系T時,Top-k查詢q(k,f)的結果是T中一組k個記錄τi,…,τk中得分最小的Δk,即f(θ)的值。在不失一般性的情況下,分數最低的記錄被認為是最好的[7]。
通常在排名感知處理中,需要兩個(或更多)輸入關系連接的Top-k結果,視為一個運算符,稱之為Top-k連接查詢[8]。可以通過先執行連接,然后通過評分函數對連接記錄進行排名,并輸出前k個排名結果。然而,這會導致處理過程的資源浪費,所以需要提出高效的算法來解決交織排序和連接的問題[9]。
在本文中,認為輸入關系Ti包含了一個連接屬性ai,一個得分屬性si,以及其他一些屬性。因此,Ti由唯一標識符(τ,id)、連接屬性值或連接值(τ,ai)和得分屬性值(τ,si)所描述的記錄組成。本文關注二元多對多的Top-k等值連接,其中輸入表T0和T1連接在連接屬性a0=a1上,得分屬性(s0和s1)的組合是為了生成Top-k連接記錄,作為得分函數f的輸入。
2.2 問題描述
考慮兩個輸入表T0和T1,它們分別在一組機器上被水平分割,并具有連接屬性a0,a1和得分屬性s0,s1。給定由整數k定義的Top-k連接查詢q(k,f,T0,T1),和用于組合得分屬性s0和s1產生連接記錄的單調得分函數f。并行Top-k連接問題要求產生具有最低分數的Top-k連接記錄。
在MapReduce環境中,輸入表T0和T1被拆分為HDFS塊,并按照水平分區的概念存儲在HDFS中。一個記錄τ在每個文件中都是(τ.id,τ.ai,τ.si)形式,其中τ.id是唯一標識符,τ.ai是連接屬性,τ.si是得分屬性。除了這個三元組之外,每一行可能都包含其他任意長度的記錄元素的屬性τ。因此,在一般情況下,每個節點只存儲每個關系記錄的一個子集。問題在于設計一個由Map和Reduce階段組成的算法,通過并行方式有效計算Top-k連接方式。
最后,本文注意到Top-k連接并行處理中最昂貴的部分是計算每個連接值的Top-k連接記錄。因此,在本文中,我們著重于提供一個完全并行的解決方案來解決這個問題。獲得Top-k連接結果的最后一步需要處理k·m個連接記錄(其中m表示不同連接值的個數),這通常比初始表Ti的值小幾個數量級,即k·m<<|Ti|。因此,可利用一個集中程序來處理這些單獨的Top-k結果,而沒有顯著的開銷。
3 提出的并行Top-k連接查詢算法
3.1 方法概述
上傳兩個輸入表T0和T1,并作為單獨的文件存儲在HDFS中,根據得分屬性以升序排序。此外,對于每個輸入表,計算并存儲在HDFS直方圖H(T0)和H(T1)中,它們維護一系列連接屬性值的記錄數。需要注意的是,這些信息可以在輸入表上傳到HDFS的過程中構建,而開銷可以忽略不計。
給定一個Top-k連接查詢,計算每個輸入表(基于直方圖)的分數范圍,這些范圍決定了作業執行前足以產生正確結果的記錄子集。因此,可以選擇性地在Map階段加載和處理存儲數據的一小部分,一旦遇到分數值大于邊界的記錄,就終止Mappers的處理。此外,通過引入數據過濾和負載均衡機制來優化Reduce端連接的性能,該機制均衡地將連接值分配給Reduce任務。
3.2 直方圖構建
在Hadoop中處理數據需要上傳數據,整個數據集從外部源按順序讀取并存儲在HDFS中[10]。這個階段主要是I/O密集型任務,CPU沒有充分利用,可以利用這個階段在后臺建立直方圖。通常情況下,直方圖的大小比初始數據集要小幾個數量級,但是在準確性和磁盤大小之間權衡,即在構建過程中更大直方圖可以實現更高的準確性,同時會消耗更多磁盤空間的。
為達到預期的目的,本文選擇了構建等寬直方圖,其構造簡單且符合一次通過的要求。更詳細地說,當一個記錄τ(τ.ai,τ.si)在上傳階段被讀取,可以通過增加對應分數值τ.si的bin的內容來更新連接值為τ.ai的直方圖。
圖2描繪了相同連接屬性值下,T0和T1的等寬直方圖。對于每個輸入表Ti,創建與連接屬性中單獨值數量一樣多的直方圖。每個直方圖被表示為H(Ti)。例如,所描述的T1的直方圖H(T1)表示它總共包含11個具有連接值a1=x的記錄。此外,第一個直方圖框表示存在2條記錄,得分在0-10之間(表示為[0-10]:2),剩下的bin是:[10-20]:3,[20-30]:2以及[30-40]:4。

圖2 相同的連接屬性值(a0=a1=x)下,T0和T1的等寬直方圖的例子
3.3 提前終止機制
為了減少連接的處理成本,本文只處理兩個表的輸入記錄子集,來保證提供正確的Top-k連接結果。直觀地說,只有表Ti中分數低于bi的記錄才會參與連接,用來產生Top-k連接結果。 因此,為了實現提前終止操作,需要有一種方法來確定分數范圍b0和b1,以便盡可能早地放棄高于bi分數的記錄。
1)分數界限估計:將兩個表的直方圖作為輸入,問題在于要計算每個表Ti中輸入記錄得分的正確分數界限bi。為此,本文使用文獻[11]中提出的算法來進行分數界限估計。在實踐中,這個算法對兩個表格的直方圖執行連接,并估計連接結果的數量和分數范圍。這個算法的用處為:第一,識別直方圖bin和相應分數范圍用來產生k個連接記錄;第二,確保沒有其他直方圖bin組合可以產生具有比這第k個連接記錄更小分數值的連接記錄。為此直方圖bin不斷被訪問和加入,直到加入記錄的數量超過k,或者任何直方圖bin產生的連接記錄得分都不小于當前第k個記錄的得分。用一個例子來解釋算法的操作,描述如下。
示例1:考慮圖2中描述的直方圖,并假設Top-k連接結果(k=1)被要求使用作為評分函數的總和。通過檢查每個直方圖的第一個bin,可以知道在[0-15]范圍內存在2(= 1×2)個連接記錄,即[0-15]:2。通過每個直方圖,還可以知道存在[10-25]:3,[5-20]:4和[15-30]:6。只有在T0的第三個bin被檢查后(產生的連接記錄沒有顯示在這里),才可以安全地停止處理,并且報告得分范圍b0=15和b1=20。這是因為得分[0-15]內已經有至少2條記錄(即多于k=1),并且T0或T1bin組合產生的任何連接記錄的分數都將大于15。
2)在Hadoop中實現提前終止操作:假設輸入表以HDFS格式存儲,并且直方圖也可用,創建一個提前終止機制,在Map階段有選擇地只處理分數比各自界限低的輸入記錄。需要注意的是,提前終止機制是通過擴展Hadoop來實現的,也就是說,不會更改Hadoop核心。
3.4 數據過濾
Map任務會處理一組輸入記錄(以鍵值對的形式)并生成一組輸出記錄。限制輸出記錄的數量非常重要,這會影響整體性能,因為這些記錄需要通過Reduce任務進行混洗(消耗通信成本)和處理(消耗處理成本)。數據過濾技術通常是通過消除不影響結果的輸入記錄來限制Map輸出記錄的數量。應該注意的是,數據過濾是依賴于作業的,這意味著每個作業都需要基于查詢類型的不同過濾機制。
Top-k查詢的過濾過程中,考慮在n維空間Rn中定義的多維數據集S(例如,p∈S且p=[p1,…pn]),以及一個Map任務,即訪問完整數據集S的子集S′。另外,讓一個偏好函數f(p)=ω1·p1+…+ωn·pn為數據對象賦值。目標是檢索出得分最高的top-k對象。對于由Map任務讀取的每個對象p∈S′,分配一個分數f(p)。通過在優先隊列中保存k個最高得分對象來執行Map任務中的過濾。只有這些k個對象需要發送到Reduce階段,而不是由Map任務訪問的|S′|個對象。
圖3所示為一個2維數據集中的Top-k查詢過濾例子。白點和黑點對應于由兩個不同Map任務訪問的對象。 黑點對象的局部Skyline集合用虛線連接。這些是一個Map任務中唯一需要發送到Reduce階段的象,而剩余的黑點則被過濾。
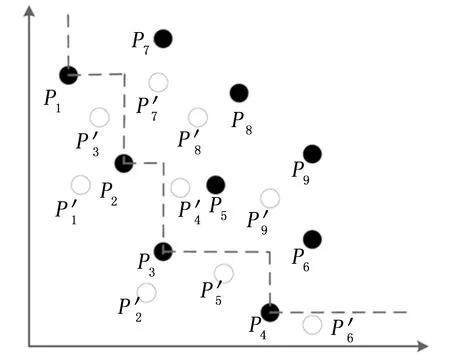
圖3 具有兩個Map任務的Top-k示例,空心點對應第1個Mapper,實心點對應第2個Mapper
3.5 負載均衡機制
Reduce任務的工作量由其需要處理和連接的記錄數決定[12]。為了執行負載均衡,本文目標是將一些連接值分配給Reduce任務,以最小化每個Reduce任務的最大記錄數,這個問題相當于多處理器調度問題。然而,多處理器調度問題是一種NP-hard問題,因此本文使用了一種名為LPT(最長處理時間)的啟發式算法來進行調度。該算法根據連接記錄的數量對連接值進行排序,然后將它們分配給迄今為止連接總數最低的處理器(Reducer)。
3.6 基于 MapReduce的并行實現
算法1展示了如何在Map階段實現提前終止、數據過濾和負載均衡機制。該算法將每個輸入表的分數界限作為輸入,并訪問排序的輸入表。另外,如上所述,HashMapH用來捕獲一些連接值分配給Reduce任務。只要表T1中的輸入記錄τ的得分低于得分邊界b1,即∑si≤bi,則將該記錄傳遞給Reduce任務。以此確保沒有得分高于邊界的記錄可以產生屬于Top-k連接的連接結果,從而可以棄用高得分記錄的連接結果,顯著減少需要傳遞和處理的記錄數量。
算法1:P-TKJ Map階段輸入:T0,T1,b0,b1,H
輸出:T0,T1中分數低于b0,b1的記錄
Function Map(τ(τ.ai,τ.si))//表Ti中的記錄
1:r←H.get(τ.ai)
2:if (τ∈T0) then
3: if(τ.s0≤b0) then
4:τ.tag←0
5: output[(τ.ai,τ.si,τ.tag,r),τ]
6; else
7: if(τ.s0≤b1) then
8:τ.tag←1
9: output[(τ.ai,τ.si,τ.tag,r),τ]
10: 執行數據過濾
11:end
算法2展示了Reduce階段的流程。將Map階段的輸出鍵值對根據連接值(τ.ai)分組,并使用自定義分區程序分配給Reduce任務。在每個Reducer中,需要按照得分(τ.si)的升序對每個組中的記錄進行排序,這是通過使用組合鍵排序來實現的。Reduce階段的輸出形式為a,τ.id,τ'.id,f(τ.τ')。
每個Reduce任務將與特定連接屬性值相關的所有記錄作為輸入,并獨立于其他Reduce任務,對每個這樣的連接值執行Top-k連接。而且,由于按升序對記錄進行排序訪問,因此只要在存儲器(M0和M1)中,從每個輸入表(第6行)中只讀取與k相同數量的記錄即可,因為任何其他記錄都不能產生Top-k連接結果。
算法2 :P-TKJ Reduce 階段
輸出:連接值key的Top-k記錄。
Function Reduce(key,V)
1:for (τ∈V) do
2:if(τ.tag=0) then
3:載入τinM0
4:else
5:載入τinM1
6:if(M0.size()≥k)and(M1.size()≥k)則
隨著互聯網和云計算技術的急速發展和普及,云計算在提高使用效率的同時,為數字內容安全和用戶個人敏感信息保護帶來了很大的挑戰。
7:執行提前終止機制
8:output[RankJoin(k,f,M0,M1)]
9:end
4 實驗評估
4.1 實驗設置
將算法部署在由8個服務器節點組成的內部Hadoop集群[13]中。對于Map和Reduce任務,JVM堆大小設置為2GB。HDFS大小配置為128MB,默認復制因子為3。
使用了兩種Hadoop平臺上計算Top-k連接的算法進行比較,分別為傳統RSJ算法和本文提出的P-TKJ算法。這兩種算法的區別在于,本文P-TKJ算法具有提前終止、數據過濾和負載均衡機制。
對于記錄數據集,使用了一個合成數據生成器來生成大量的輸入數據集。輸入表Ti的大小從1 GB到50 GB。根據偏態分布(ZIPF分布)來生成評分屬性,其中偏度為0.5,表示為ZI0.5。改變每個表中不同連接值的數量(從100到2000),從而影響連接選擇性,以研究它對本文算法的影響。為了驗證算法的可擴展性,本文創建了4個不同大小的數據集,記為DS1-DS4。這些數據集的各個參數顯示在表1中。另外,各種算法中都設置Top-k中的k=10。
對于性能指標,本文使用的主要度量是每個作業的總執行時間。另外,還測量了在Map和Reduce階段消耗的CPU時間。

表1 用于可擴展性研究的數據集
4.2 實驗結果
圖4給出不同數據集大小下,兩種算法的總執行時間。圖5給出了分別在Map和Reduce階段所消耗的CPU處理時間。

圖4 算法的總執行時間

圖5 Map和Reduce階段所消耗的CPU處理時間
可以看出,P-TKJ算法的執行時間優于RSJ 算法將近1倍。而且,當數據集的大小增加時,優勢更加明顯。以上實驗這有力證明了本文算法支持大量輸入的可擴展性。
這是因為RSJ雖然為并行Top-k連接問題提供了一個正確的解決方案,但是它在性能方面有嚴重的局限性。首先,盡管直觀上一小部分列表記錄就足以產生正確的結果,但是它需要完整地訪問兩個輸入表。換句話說,就磁盤訪問、處理成本以及通信而言,這明顯導致資源的浪費。理想情況下,如果確定已經訪問過的記錄能夠產生正確的結果,只需要有選擇地只訪問幾個HDFS塊,并終止Map階段的處理。其次,由于RSJ不使用與每個連接值關聯的記錄數量知識,為此其將Map輸出鍵(連接值)分配給Reduce任務是隨機執行的,這可能會導致不均衡的工作分配,從而延遲了工作的完成。
相比而言,本文使用了提前終止策略,使Map階段輸入記錄的數量減少,所以算法比RSJ執行更快。另外,由于本文方法很好地對Reducer任務進行了負載平衡。在沒有負載均衡機制時,使用Hadoop默認的基于散列的分區,將Map輸出鍵分配給Reducers,這本質上是一種隨機分區。而由于本文的負載均衡機制,以更統一的方式將連接結果分配給Reducers,從而以更公平的方式分配工作。另外,本文融入了數據過濾操作,減少了Reducer任務數量,這也一定程度上提高了算法執行速度。
為了驗證不同k對算法性能的影響,這里設定k=5、10、15、20和25。在DS1上分別進行實驗,并統計相應的執行時間,結果如圖6所示。可以看出,不同k值下兩種算法的執行時間幾乎不受影響。這是因為連接查詢是消耗時間最高的操作。但Top-k通過在連接階段實行部分合并,不同k值下所維護的元組數量基本相同,所以執行時間也基本不變。
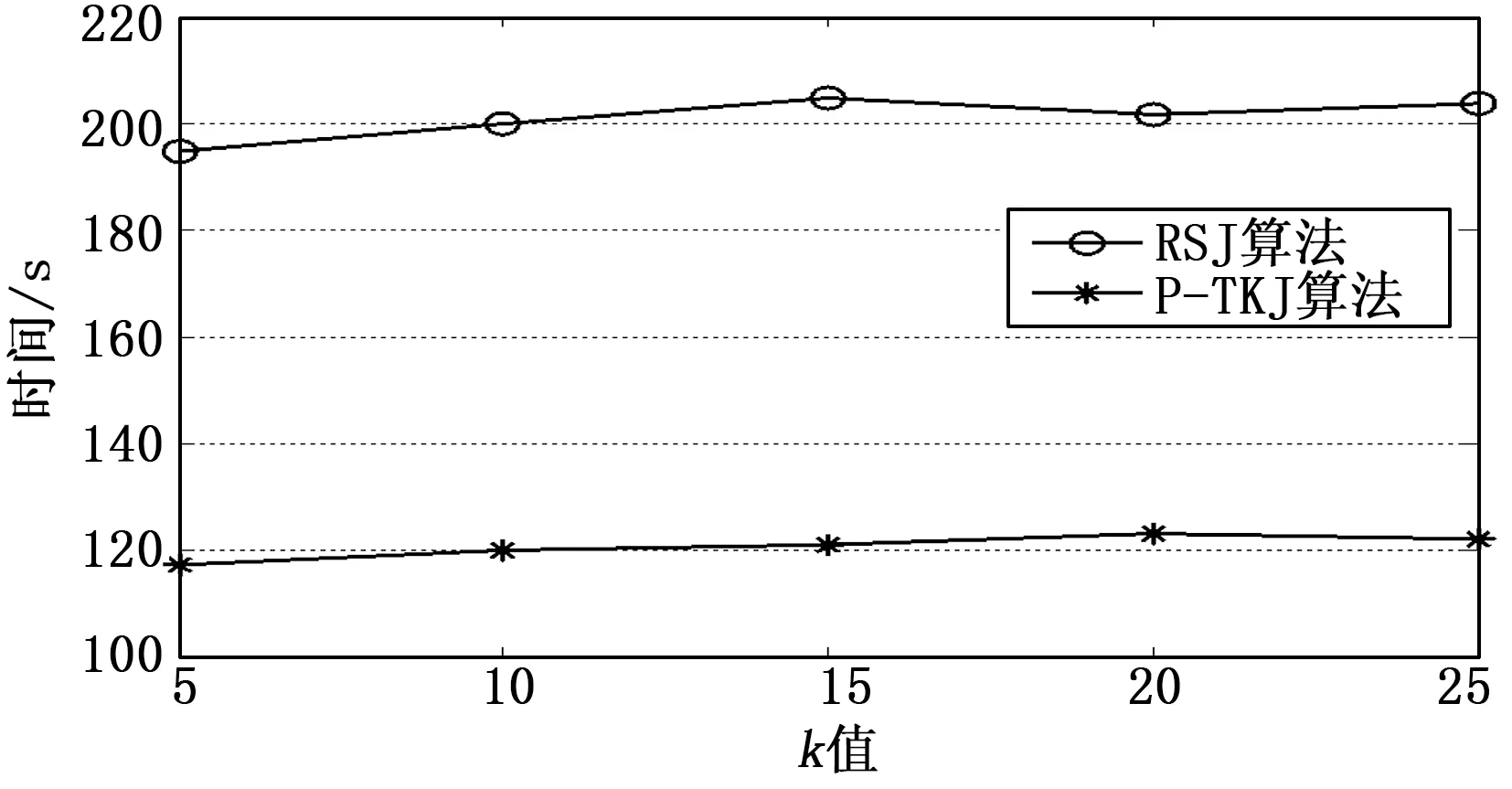
圖6 不同k值下的執行時間
5 結論
本文介紹了一種在MapReduce框架上處理Top-k連接的并行化計算框架。使用數據匯總,以直方圖的形式表示,并將這些操作在數據上傳過程中通過后臺CPU處理,以此提高CPU利用率。同時利用提前終止策略、數據過濾和負載均衡策略提高了算法對數據分析訪問和處理的效率。實驗結果證明了提出算法的可擴展性和有效性。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
名家名作(2021年9期)2021-10-08 01:31:36
名家名作(2021年4期)2021-05-12 09:40:02
名家名作(2021年3期)2021-04-07 06:42:16
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
新世紀智能(語文備考)(2019年12期)2020-01-13 06:04:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
名家名作(2017年2期)2017-08-30 01:34:24
