基于Hadoop的維吾爾文文本分類
2018-08-17 03:00:34艾比布拉阿不拉哈力旦阿布都熱依木吳冰冰
計算機工程與設計 2018年8期
艾比布拉·阿不拉,馬 振,哈力旦·阿布都熱依木,吳冰冰
(新疆大學 電氣工程學院,新疆 烏魯木齊 830047)
0 引 言
對于文本分類,已有不少這方面的研究,但是利用大數據的處理方式來進行維吾爾文文本分類的研究還處于起步階段。文獻[1]提供了一種使用字符級卷積網絡進行文本分類;文獻[2]設計了一種適用于文本聚類任務的特征選擇算法,提出詞條屬性的概念;文獻[3]提出一種基于TextRank算法和互信息相似度的維吾爾文關鍵詞提取及文本分類方法;文獻[4]提出一種基于深度置信網絡的維吾爾文短信文本分類模型;文獻[5]使用了一種自動的維吾爾文組詞算法dme-TS,該算法用一種組合統計量(dme)來度量文本中相鄰單詞之間的關聯程度。
本文結合Hadoop分布式計算的特點與改進維吾爾文組詞算法(DM算法)的優點,運用MapReduce并行計算模型,然后再利用Hadoop生態環境下的子項目Mahout來對組詞后的文本進行維吾爾文文本分類計算,其中包括文本的序列化、向量化、訓練貝葉斯分類器和分類器的測試,設計了基于Hadoop和改進維吾爾文組詞算法的文本分類模型,并用實驗進行驗證。該模型在維吾爾文檢索系統、輿情分析等方面具有重要的意義。
1 改進的維吾爾文組詞算法
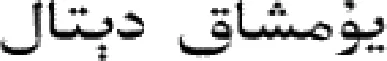
1.1 互信息(mutual information)
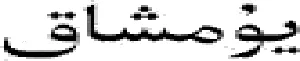
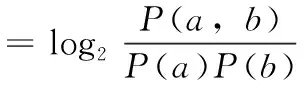
(1)

(2)
其中,T是閾值,當互信息值大于T時,即單詞a,b之間是強關聯,則表示單詞a,b應該連在一起,作為一個特征單元。反之,則應該斷開。
1.2 t-測試(difference of t-test)
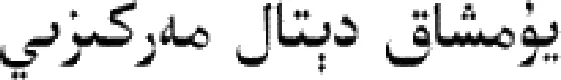
(3)
其中,P(c|b)、P(b|a)分別是b關于c和a關于b的條件概率。σ2(P(c|b))、σ2(P(b|a))是各自的方差。單詞b與單詞a和c的關系如式(4)
(4)
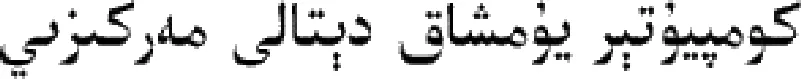
dts(x,y)=ta,y(x)-tx,b(y)
(5)
當dts(x,y)>α(α為閾值),則單詞x,y之間是強關聯,應該連在一起。
1.3 組合互信息和t-測試差的統計量
由于互信息反應的是兩個單詞之間的靜態結合力,t-測試差考慮了上下文關系。這兩種算法在一定程度形成優劣互補,因此可以將其線性組合成一種新的DM算法,首先考慮到MI和dts之間的變化范圍不一樣,因此現將其標準化,即分別算出其各自對應的標準差MI*(x,y)、dts*(x,y),然后按照一定的權重比值將其疊加在一起,如式(6)
dm(x,y)=α×MI*(x,y)+β×dts*(x,y)
(6)
α,β分別為互信息和t-測試差的權值系數。
1.4 DM分段式組詞算法
在對維吾爾文文本進行預處理的時候,由于標點符號兩邊的單詞不可能組成在一起,因此在組詞前必須先保留標點符號,在組詞結束后在對其去除。本文首先對文本按標點進行分段處理,然后在每一段分別進行組詞。
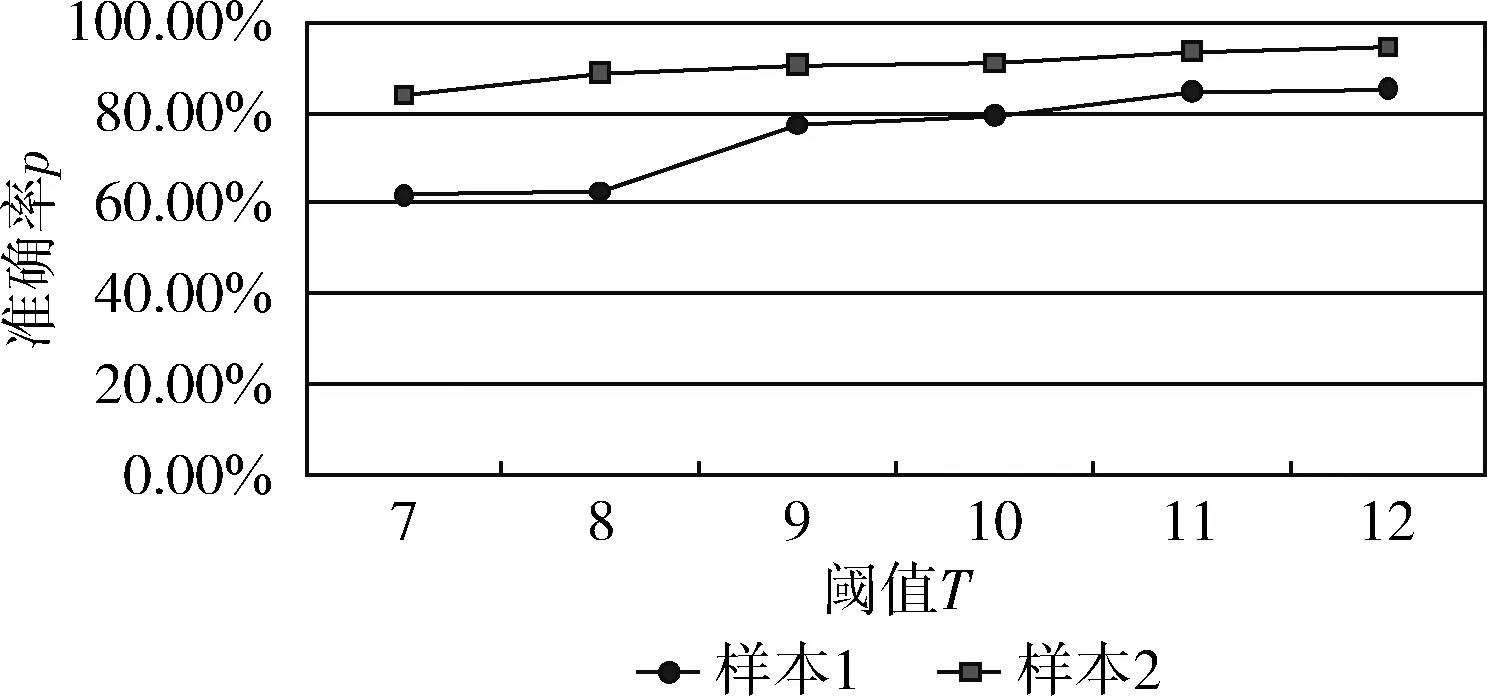
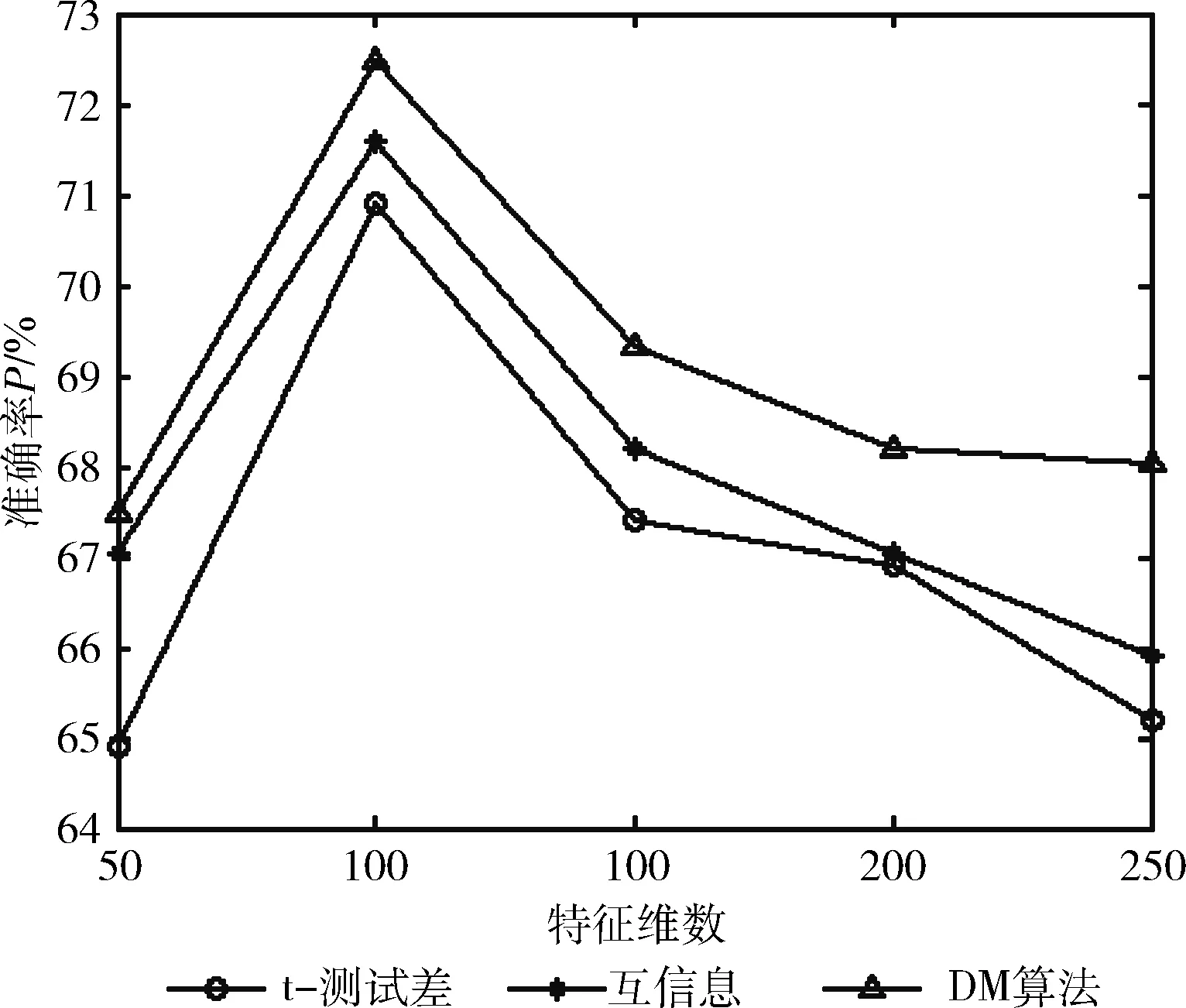
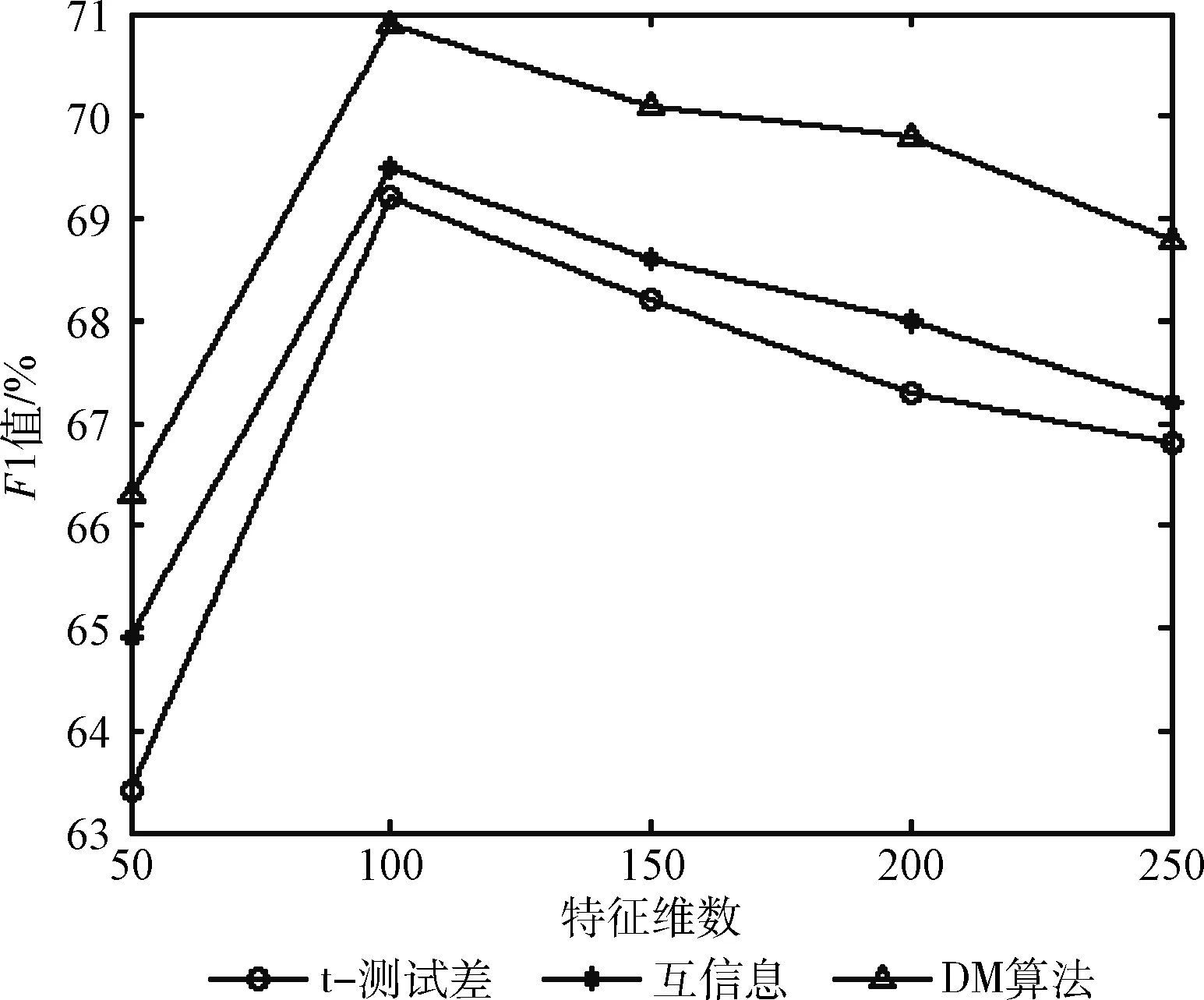
從文本集中讀取一個文本,按標點符號將其才分成長度不同的m個字符串;然后依次計算出每個詞串中的每個單詞之間的dm值,并與給定的閾值進行比較。假定dm給定的閾值為T,如果dm(x,y)>T,則單詞x和y之間應該組合在一起。反之,如果dm(x,y) 圖1 語義劃分實例 由于實驗平臺是以Hadoop為基礎的,采用的是分布式文件處理系統HDFS,它處理的任務是用MapReduce進行編寫程序的。因此特征抽取的并行化處理是必不可少的過程[6]。 并行DM算法在Hadoop平臺上的實現步驟如下: 步驟1 初始化Hadoop任務。用戶向ResourceMana-ger提交Job。 步驟2 讀取并復制源數據。將源數據復制到Hadoop的分布式文件系統HDFS中,并合理分配到各個子節點。 步驟3 MapReduce過程。實現各個子節點映射數據集并處理。 特征抽取一共分為4個MapReduce任務,執行流程如圖2所示。 圖2 MapReduce任務執行流程 第一個MapReduce的任務是統計每類包含的文檔數,文檔總數,每個單詞出現的頻數; 第二個MapReduce的任務是計算相鄰兩個單詞的互信息,輸出鍵值對<(x,y),MI(x,y)>; 第三個MapReduce的任務是計算相鄰兩個單詞的t-測試差,輸出鍵值對<(x,y),dts(x,y)>; 第四個MapReduce的任務是計算dm(x,y),并根據其值組詞輸出。 組合式MapReduce計算作業每個子任務都需要提供獨立的作業配置代碼。MapReduce1的輸出路徑outpath1將作為MapReduce2和MapReduce3的輸入路徑。MapReduce4任務必須要等MapReduce2和MapReduce3執行完成后才能執行,其組合式MapReduce作業的配置和執行代碼如下: //子任務mapreduce1配置執行代碼 Configuration jobconf 1=new Configuration(); job1=new Job(jobconf1,“Job1”); job1.setJarByClass(jobclass1); … … //job1的其它設置 FileInputFormat.addInputPath(job1,input1); FileOutputFormat.setOutputPath(job1,outpath1); job1.waitForCompletion(true); //子任務mapreduce2配置執行代碼 Configuration jobconf2=new Configuration(); job2=new Job(jobconf2,“Job2”); FileInputFormat.addInputPath(job2,outpath1); … … //job2的其它設置 //子任務mapreduce3配置執行代碼 Configuration jobconf3=new Configuration(); job3=new Job(jobconf3,“Job3”); FileInputFormat.addInputPath(job3,outpath1); … … //job3的其它設置 //子任務mapreduce4配置執行代碼 Configuration jobconf4=new Configuration(); job3=new Job(jobconf4,“Job4”); FileInputFormat.addInputPath(job4,outpath1); … … //job4的其它設置 //設置job4與job2的依賴關系,job4將等待job2執行完畢 Job4.addDependingJob(job2); //設置job4與job3的依賴關系,job4將等待job3執行完畢 Job4.addDependingJob(job3); //設置JobControl, 把job任務加入到jobControl JobControl JC=new JobControl(“sumJob”); … JC.run(); 基于Hadoop和DM算法的文本分類模型的方法包括文本序列化、改進維吾爾文組詞算法、文件向量化、樸素貝葉斯分類算法,最終實現維吾爾文文本的準確分類。具體步驟如下: 步驟1 采用MapReduce計算模型將文本數據轉化為Hadoop能夠處理的SequenceFile文件。每一行的key值為每個文件夾的名字加上文件夾下面的文件名,value值為文件夾下面的文件內容[7]。 步驟2 利用MapReduce計算模型對序列化文件進行DM算法組詞計算。 步驟3 把經過DM算法處理過的序列文件轉化為向量文件。具體實現如下: (1)對序列化文件進行單詞計數、單詞編碼。 (2)創建并合并局部變量。 (3)對局部變量采用TF-IDF算法計算得到新的局部變量。TF-IDF算法如下: 在一份給定的文件里,詞頻(term frequency,TF)指的是某一個給定的詞語在該文件中出現的頻率,如式(7)所示 (7) 其中,ni,j是該詞ti在文件dj中出現的次數,而分母是在文件dj中所有字詞的出現次數之和。 逆向文件頻率(inverse document frequency,IDF)是一個詞語普遍重要性的度量。如式(8)所示 (8) 其中,|D|是語料庫的總數,|{j:ti∈dj}|包含詞語ti的文件數目。 某一特定文件內的高詞語頻率,以及該詞語在整個文件集合中的低文件頻率,可以產生出高權重的TF-IDF,如式(9)所示 tfidfi,j=tfi,j×idfi (9) (4)創建局部變量并合并。 序列化文件到向量文件這步可分為8個小步驟,在Mahout中是由7個Job和1個reduce操作并分別執行的[8]。文本轉化為向量流程如圖3所示。 步驟4 利用Hadoop的子項目Mahout[9]訓練樸素貝葉斯,生成分類器模型。 分類器生成之后,接著就是對分類器進行測試。基于Hadoop和DM算法的文本分類模型的整體處理流程如圖4所示。 數據源來源于新疆維吾爾自治區人民政府網(http://www.xinjiang.gov.cn/)和Ulinix(http://www.ulinix.com/)等主要維吾爾文門戶網站。實驗數據描述見表1。 圖3 文本轉化為向量流程 圖4 維吾爾文文本分類流程 樣本1訓練集樣本1測試集樣本2訓練集樣本2測試集社會事實12826318100生活與健康1403724090體育922429997文學1272835092 本次實驗的實驗環境為,采用的3臺計算機,一個namenode,兩個做datanode,操作系統為CentOS 7.0,Hadoop版本為2.7.0,Java安裝的版本為jdk1.8.0-20,Mahout版本為0.9。Maven版本為3.2.3。 文本分類中對性能評估[10]的指標有很多,其中常用的有查全率(recall,R)、查準率(precision,P)和F1值等。P=分類正確的文本數目/所有的分類文本數目,R=分類正確的文本數目/應有的文本數目 實驗1:DM算法閾值T的確定:將DM算法的閾值T設置為不同的數,得到相應的分類結果,實驗結果如圖5所示。在此,設置11為閾值T進行后續的實驗。 圖5 不同閾值下的維吾爾文文本分類的準確度 實驗2:本文改進算法與互信息算法、t-測試差算法的比較。實驗采用樣本1和樣本2數據,特征維數從1000到6000之間取值,對查準率(P)和平均值F1的值的變化進行了統計和對比,如圖6、圖7所示。 圖6 改進算法與互信息、t-測試差的分類準確率 圖7 改進算法與互信息、t-測試差的F1值 實驗結果表明: (1)由圖5可知,當樣本數目確定的時候,維吾爾文文本分類的準確率跟組詞時所取的閾值T有關,當T≥11時,分類的準確率趨于穩定。 (2)由圖6可知,當特征維數小于100時,3種算法的準確性都是呈逐漸上升趨勢。當特征維數大于100小于250時,3種算法都是緩慢下趨勢。總體來看,本文改進算法優于互信息算法和t-測試差算法。 (3)由圖7可知,從F1值方面來看,本文改進算法也在分類性能方面也都明顯高于互信息算法和t-測試差算法。
2 DM算法的并行化
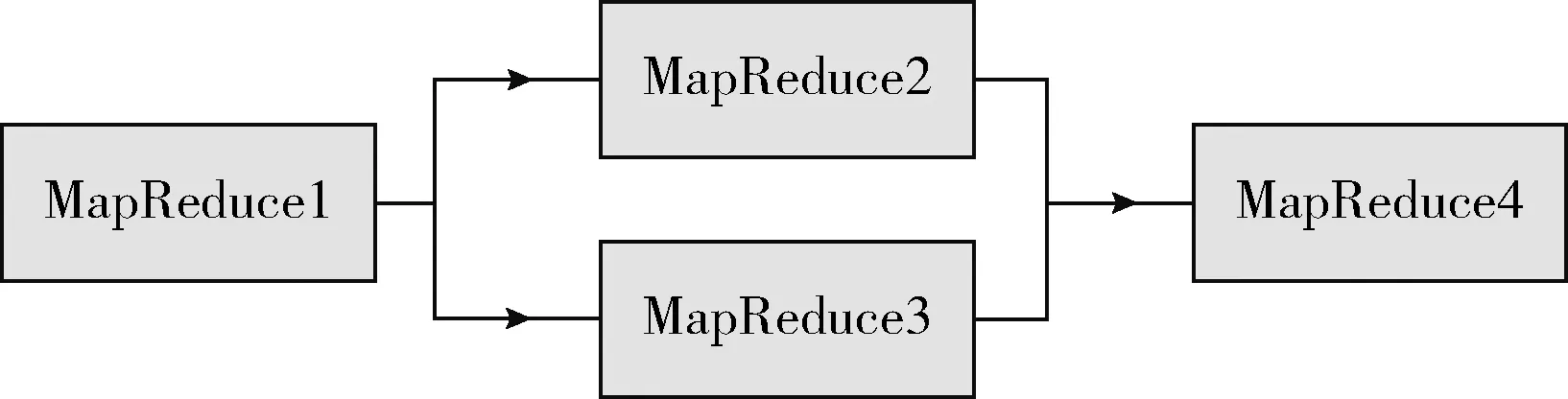
3 基于Hadoop和DM算法的文本分類模型
4 實驗及結果分析
4.1 數據集
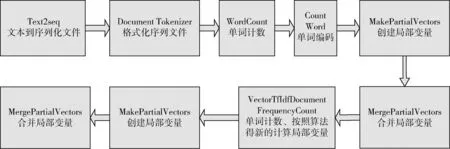
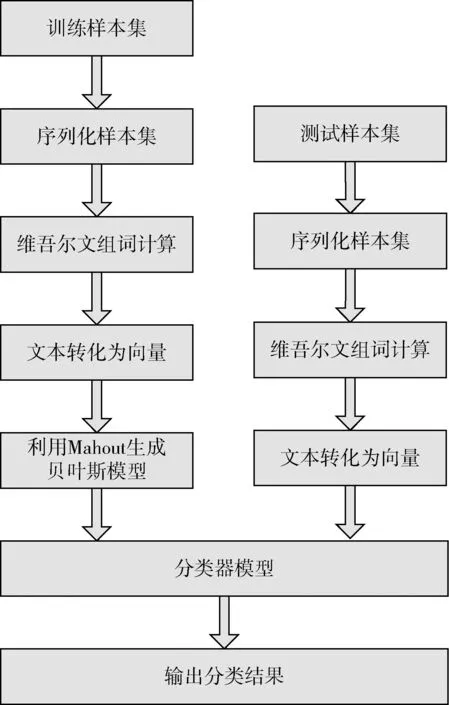
4.2 分類及性能評估
5 結束語

猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
