基于卷積降噪自編碼器的藏文歷史文獻版面分析方法
2018-08-17 07:10:42張西群馬龍龍段立娟劉澤宇
中文信息學報 2018年7期
張西群,馬龍龍,段立娟,劉澤宇,吳 健
0 引言
近年來,人們對傳統歷史文化的保護和傳承越來越重視,研究人員對歷史文獻數字化的興趣也越來越高漲。
藏族是一個擁有豐富傳統文化的民族,是中華燦爛文明不可或缺的重要組成部分。藏文歷史文獻是藏族傳統文化寶庫中一顆璀璨的明珠,其作為承載藏族古老文明的載體,受到了歷史學家、語言學家、佛學家、文獻學家的廣泛關注。一直以來,中央政府非常重視藏文歷史文獻及文物的保護及發掘,先后多次進行了藏族文物歷史文獻的收集和保護工作[1];但是,藏文歷史文獻的研究和發展現狀仍然不容樂觀。當前對藏文歷史文獻的保護主要停留在存放保護階段。大部分的藏文歷史文獻被保存在博物館、廟宇或研究院的庫房中,只有部分根據需要以人工輸入、掃描、拍照等電子化手段進行保存,以供研究。這種方式存在耗費大量人力物力、傳輸流通不便、不能對藏文歷史文獻內容充分挖掘和利用等問題。同時,歷史文獻的研究與保護也存在著矛盾。在研究藏文歷史文獻的過程中,無法避免對歷史文獻的觸摸以及翻動,這一環節對有著幾百年甚至上千年歷史的文獻來說,可能是致命的。而采用數字化的方法對藏文歷史文獻圖像進行自動的版面分析和識別,將文獻內容轉化為數字化的文本存儲,可以大大提高對藏文歷史文獻的利用效率;可以大批量遠距離在線瀏覽和傳輸,實現資源的共享;能夠在妥善保存原件的基礎上,實現對藏文歷史文獻的充分研究和傳承。因此,采用數字化技術對現有的藏文歷史文獻中的文本部分進行自動識別并轉化為數字形式存儲,對藏族歷史文化的研究、保護和傳承具有非常重要的意義。
版面分析是歷史文獻數字化過程中重要的基礎步驟。在過去的幾十年中,國內外的研究者針對印刷或手寫的歷史文獻提出了許多不同的版面分析方法。版面分析方法多依賴于所處理文獻的版面特點,通常針對不同的文獻版面布局使用特定的版面分析方法。此外,現有的版面分析方法主要用來處理一些主流語言(如: 中文、英文、法語等)的歷史文獻,很少有針對少數民族語言歷史文獻特點的版面分析方法提出。由于藏文歷史文獻的固有特點,文本和邊框、文本和圖形之間通常會有粘連的情況發生;版面也較為復雜,文獻圖像顏色不一致,噪點多,文獻中的邊框、線段經常會出現彎曲、傾斜、斷裂等情況。以上這些特點給實現高性能的藏文歷史文獻的版面分析帶來了較大挑戰。圖1展示了一個藏文歷史文獻圖像的樣例。現有的文獻版面分析方法大部分是對近現代比較規則的印刷書籍的版面進行分析,不適用于版面比較復雜的歷史文獻;已有的歷史文獻的版面分析方法,大多是針對某一種語言文字的歷史文獻特點提出的方法,并不完全適用于藏文歷史文獻。

圖1 藏文歷史文獻圖像
受文獻[2]的啟發,本文提出了一種基于卷積降噪自編碼器的藏文歷史文獻版面分析方法,該方法克服了藏文歷史文獻的退化、顏色不一致、噪點多等特點對版面分析效果的影響。具體分為四步。第一步,首先使用超像素聚類算法將藏文歷史文獻的圖像聚類成不同的超像素塊;第二步,利用卷積降噪自編碼器提取超像素塊的特征;第三步,使用SVM分類器將藏文歷史文獻圖像的超像素塊進行分類;最后,將藏文歷史文獻的版面分析結果存儲在XML文件中。實驗結果表明,此方法能夠有效地對藏文歷史文獻的版面進行分析,將不同的版面元素分離。
本文其他部分組織如下: 第一節介紹文檔版面分析的相關工作;第二節引入本文提出的版面分析方法;第三節給出實驗結果及分析;第四節簡述結論。
1 相關工作
近年來,研究人員針對不同特點的文獻提出了多種多樣的方法對文獻版面進行分析。Sébastien[3]將它們分為了三類。
第一種類型的方法通常用于典型的、版面布局較簡單的文獻,例如,曼哈頓布局類型的文獻。Dai-Ton[4]提出了一種自適應的過分割和融合算法來對印刷出版物進行版面分割;利用圖像背景中的白色矩形信息先將圖像盡可能地過分割,然后將通過形態學方法檢測出的直線和圖畫區域從圖像中去除,通過連通區域分析得到候選文本;通過預定義的規則將字體大小相同、距離相近的候選文本組合成一個連通區域;然后使用段落分布模型將不同段落分割開;此方法在現代印刷報紙、雜志等出版物上獲得了較好的分割效果。郭[5]提出了一種改進的連通區域分析方法,對報紙和雜志圖像進行版面分析;該方法先對單個字域進行擴充以填補字內的空隙,然后再通過投影進行文本塊連通,最后通過分析連通塊的投影,對連通塊進行標記;其實驗結果表明此方法對報紙和雜志的版面分析是比較有效的。
第二種方法的不同之處在于它們嘗試適應文獻圖像中的局部變化,以便能夠使用相同的方法來分割更多布局類型的文獻圖像。Chen等[2]在他們以前研究[6]的基礎上,提出了一種基于超像素分類的無監督學習方法來分析歷史文獻版面,對待分析文本圖像先進行超像素聚類,然后對超像素進行分類,并將分類結果融合成連通區域;此方法與其原來的方法相比,不僅降低了計算復雜度,也提升了分析效果。Yadav[7]提出了一種基于角點檢測的文本提取方法,其受到在視頻中利用角點檢測進行文本區域檢測的啟發和文本圖像中文本區域的角點密度比其他區域的角點密度大的先驗知識;先將文本圖像均分成較小的塊,然后利用角點密度對圖像塊進行分類;此方法在一些手寫文本圖像和歷史印刷圖像數據集上都得到了較好的結果。
第三種類型的方法通過結合先前提出的一些方法或者使用先進的神經網絡來克服以上兩類算法的缺點。Ramel[8]提出了一種混合的文本區域提取方法,通過在二值化的圖像中進行連通區域檢測,然后根據連通塊的大小為每個連通塊標記預分類標簽;再融合前景和背景信息,根據預定義的規則將有重疊的連通區域進行合并及重新標記分類;最后將重心距離較近的文本塊合并;此方法在其印刷歷史書籍上得到了較好的效果。姜[9]在大型中文古籍《四庫全書》自動版面分析系統中,使用了基于傳統的混合方法和先驗規則的自動處理與人工修正相結合的設計思想;能夠自動采用相應算法處理多種規范和準規范的版面。肖[10]在復雜背景下彝文古籍文本提取方法的研究中,利用邊緣檢測和小波變換對原始圖像進行了分解,然后通過GBDT(Gradient Boost Descent Tree)分類器進行文本和非文本的分類,并結合形態學變化和先驗規則準確定位文本區域。Bukhari[11]提出一種手寫阿拉伯歷史文獻的正文和側邊注釋分割的方法;通過將圖像連通區域歸一化,提取連通區域的形狀特征和上下文特征組成特征向量,然后利用AutoMLP(Auto Multi-Layer Perception)分類器對圖像中的連通區域進行分類,結合最近鄰分析得到最終的分割結果。
2 基于卷積降噪自編碼器的藏文歷史文獻版面分析方法
本文所提出方法的流程圖如圖2所示。首先,將藏文歷史文獻進行超像素聚類,獲得超像素塊;然后,利用卷積降噪自編碼器對超像素塊進行特征提取;最后,利用SVM分類器對藏文歷史文獻的超像素塊進行分類,從而提取出藏文歷史文獻版面的各個部分,并將結果保存在XML中。
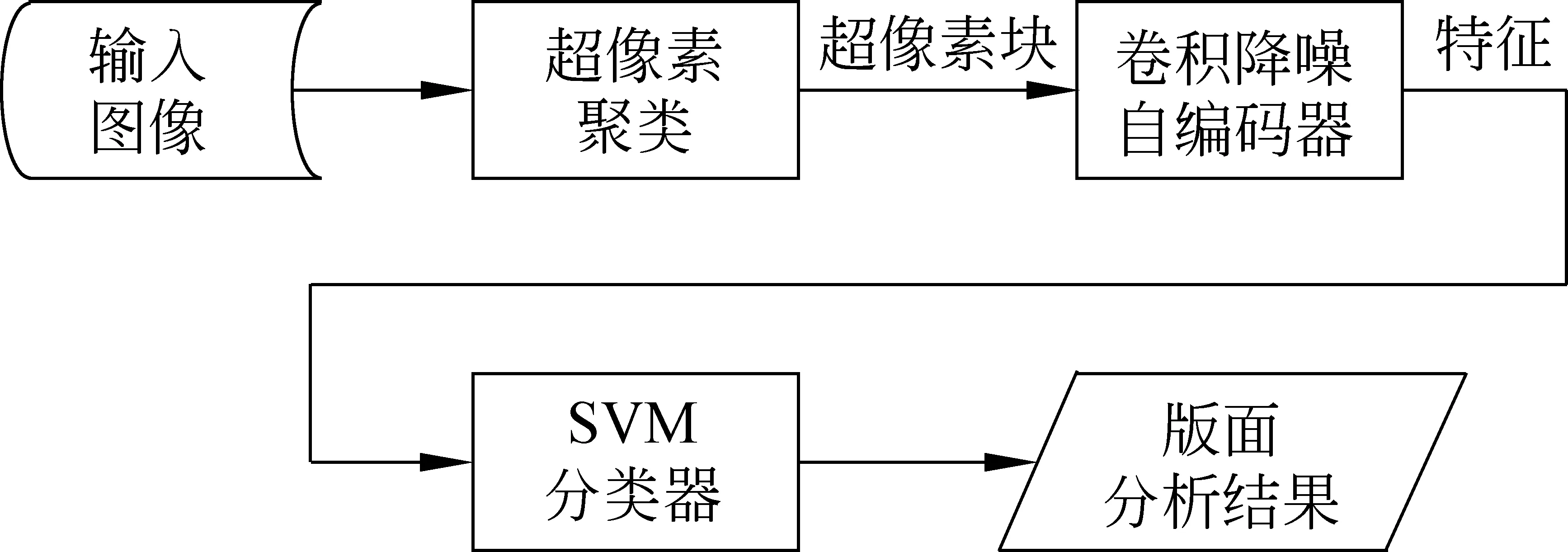
圖2 版面分析流程圖
2.1 超像素聚類
超像素(Superpixel)是一種圖像預處理技術,它利用相鄰像素點在紋理、顏色、亮度等特征上的相似程度將相鄰像素點聚成一個圖像塊,從而獲取圖像的冗余信息,相比傳統的圖像處理基本單元——像素,超像素有利于提取圖像的局部結構特征,能夠大幅度減小后續處理的計算復雜度。
本文采用了SLIC[12](Simple Linear Iterative Clustering)算法進行超像素聚類。此算法不僅方法簡單而且能夠得到高質量整齊的超像素;還有比其他超像素分割方法更高的效率[13],并且可以用于彩色圖像和灰度圖像。SLIC唯一需要的參數就是設定預期超像素的個數。SLIC算法首先將圖像換到CIELAB顏色空間,通過CIELAB顏色空間中的L(亮度通道),A(顏色通道,從紅色到深綠),B(顏色通道,從藍色到黃色)的值以及像素的坐標x、y定義的五維空間進行局部的像素聚類。在這個空間距離不規范的五維空間中,簡單地使用歐氏距離進行聚類是不合適的,所以SLIC使用了一種全新距離計算方法,計算方法如式(1)所示。
(1)

超像素聚類算法在五維空間進行聚類時考慮了顏色相似性和像素接近度,使得預期的超像素塊的大小和它們的空間范圍大致相等,加強了超像素形狀的整齊性。圖3為藏文歷史文獻的超像素聚類結果,不同的灰度邊緣代表不同的超像素塊。從圖3中可以看出,大部分不同的版面元素能夠被超像素塊分割開。

圖3 藏文歷史文獻的超像素聚類結果
2.2 卷積降噪自編碼器
2.2.1 自編碼器介紹
自編碼器(AutoEncoder,AE)是深度神經網絡的一種。經過訓練后它能嘗試將輸入通過編碼器編碼,然后利用解碼器解碼出與原輸入盡可能一致的輸出。一般意義上的自編碼器內部有一個隱藏層h,可以產生表示輸入的編碼。通常會給自編碼器加上一些強制的約束,使它只能近似地復制與訓練數據相似的輸入。強制約束使模型優先學習輸入數據中具有顯著性的特性,因此AE能夠學習到數據的有用特征。除了這種單層的自編碼器,還有堆疊自編碼器(Stacked AE,SAE)、卷積自編碼器(Convolutional AE,CAE)、降噪自編碼器(Denoising AE,DAE)等多種類型的自編碼器[14]。
堆疊自編碼器,由一系列的自編碼器堆疊而成。每個自編碼器的編碼作為下一層的輸入,這樣一層一層堆疊起來,構成一個深層網絡,其能夠逐層地學習原始數據的多種表達。卷積自編碼器,利用卷積從數據中自動學習并提取特征。它的權值共享結構大大減少了網絡的參數。結合局部連接,使得網絡在圖像分析中優勢明顯,能夠自動提取圖像的紋理、顏色等特征,其提取的特征有更好的魯棒性和泛化能力。降噪自編碼器,是在自編碼器的基礎上,將原始輸入加入噪聲,輸出目標為沒有被噪聲污染過的原始輸入;這就迫使編碼器去學習輸入信號的更加魯棒的表達,使得其泛化能力比一般編碼器更強。
大部分的藏文歷史文獻是寫在藏紙上面的。藏紙是一種用傳統手工技術制造的紙張,其表面粗糙,顏色不均勻。在獲取藏文歷史文獻的圖像時,也會產生光照不均勻、圖像模糊等情況。為了克服藏文歷史文獻的以上缺點,取得比較好的版面分析效果,本文選用卷積降噪自編碼器(Convolutional Denoising AE,CDAE)來提取超像素塊的特征。
2.2.2 CDAE的結構
CDAE的結構如圖4所示。為了能夠展示清楚卷積降噪自編碼器的結構,將其編碼器部分和解碼器分開展示,并標示了每層的Feature Map(FM)個數。它主要由三個卷積層(Conv1,Conv2,Conv3)和相應的三個反卷積層(DConv1,DConv2,DConv3)和兩個全連接層(FC1,FC2)組成。各層的具體參數如表1所示。表中“-”的意思是沒有此項參數。

圖4 自編碼器結構圖

表1 CDAE的各層的參數
2.2.3 CDAE的輸入和目標輸出
一般的降噪自編碼器的輸入為原始圖像加上噪聲,輸出目標為原始圖像。通過這樣的訓練使自編碼器能夠學習到樣本的魯棒性的表達,降低噪聲污染的影響。藏文歷史文獻圖像本身有許多噪聲存在,為了使CDAE能夠學習到藏文歷史文獻的魯棒性表達,消除噪聲的影響,本文結合gamma矯正方法和Otsu算法消除了藏文歷史文獻中的噪點,光照不均衡等的影響,得到了較為清晰的藏文歷史文獻的二值化圖像。并以超像素塊在此二值化圖像上的對應位置的像素塊作為CDAE的目標輸出,以原始藏文歷史文獻的灰度圖像中對應位置的像素塊為輸入訓練CDAE自編碼器。
圖5對CDAE編碼器部分的輸入和三個卷積層在這個輸入上提取的Feature Map進行了可視化。圖中每一個塊代表該層不同的濾波器所提取的特征;從圖中可以看出,同一個卷積層的不同濾波器所產生的特征具有相似性,而不同的卷積層之間所提取的特征差異比較大,這也證實了不同卷積層可以學習到原始輸入不同層次的表達。圖6展示了CDAE的輸入,目標輸出和真實輸出之間的對比。輸入數據為藏文歷史文獻的灰度圖,從圖中可以看出,輸入圖像有比較多的噪點;目標輸出為輸入圖像相應的二值化圖像;從CDAE經過訓練以后產生的真實輸出可以看出,與原始輸入圖像相比大部分的噪點被消除,而且與目標輸出非常相似。

圖5 CDAE編碼器輸入和三層卷積提取的Feature Map

圖6 CDAE的訓練數據和真實輸出
2.3 SVM分類器
支持向量機(Support Vector Machine)是一種分類算法。通過尋求結構風險最小化來提高其泛化能力,實現經驗風險和置信范圍的最小化。通俗來講,它是一種二分類模型,其基本模型定義為特征空間上的間隔最大的線性分類器,即支持向量機的學習策略便是間隔最大化,最終可轉化為一個凸二次規劃問題的求解。解線性分類問題,線性分類支持向量機是一種非常有效的方法,但有些分類問題是非線性的,這時支持向量機可以使用核技巧引入一個核函數K,將數據映射到高維空間,來解決在原始空間中線性不可分的問題。常用的核函數有多項式核函數、線性核函數和徑向基核函數等[15]。以上介紹的SVM主要是用來解決二分類問題,如果使用SVM解決多分類問題,大致有兩種思路。一種是將多分類問題轉化為多組二分類問題直接求解;第二種思路是適當改變原始支持向量機的優化問題,直接得到多分類支持向量機;但由于第二種思想計算太過復雜、計算量太大沒有被廣泛應用。
本文將從藏文歷史文獻圖像中提取的超像素分為三類,即邊框、文本和背景,其類別標簽分別標記為0、1、2。選用多分類帶徑向基核函數的支持向量機來訓練超像素的分類模型。
3 實驗結果及分析
3.1 實驗程序框架
實驗的操作系統為Ubuntu14.04,GPU為NVIDIA K40M。目前構建卷積神經網絡的開源框架有很多,如Theano、Keras、Pytorch、TensorFlow、Caffe等。本文實驗選用Keras進行模型搭建,Tensorflow作為Keras后端并利用TFRecords保存訓練數據[16]。
3.2 實驗數據準備
實驗數據來源于青海民族大學提供的藏文歷史文獻《班禪大師作品全集》的圖像,共440張。版面主要有兩種類型,一種為邊框內只嵌入文本;另一種為如圖1所示的邊框內嵌入文本和非文本。通過SLIC算法將每個圖片聚成1 000個左右的超像素塊,以超像素塊中心點的像素點所屬的類別代表超像素的類別;為了避免重復計算,圖片的超像素塊信息存儲在相應的XML文件中。
由于超像素塊的形狀是不規則的,為了訓練自編碼器,選擇超像素塊的固定邊長為45像素的外接四邊形區域代替超像素塊。自編碼器的輸入為超像素塊的灰度圖,輸出為其對應的二值化圖像塊。在所有圖像中,屬于文本、邊框、背景的超像素塊分別為33萬多塊,4萬多塊和8萬多塊。為了均衡訓練數據,從三類超像素塊中分別隨機取三類超像素塊各4.65萬塊,共13.95萬塊構成實驗數據集。其中,前12萬塊(每類包括4萬塊)作為訓練集,其余1.95萬塊做測試集,訓練集中的后10%做驗證集。為了方便實驗,將數據集以輸入圖像塊,目標圖像塊,類標簽的TFRecords格式存儲在二進制文件中。
3.3 實驗
3.3.1 自編碼器的輸入對結果的影響
文獻[2]中以三通道彩色圖像作為其CAE的輸入和目標輸出,其數據集的各個部分有明顯的顏色區別,顏色信息能對其分類準確性產生比較積極的影響;然而藏文歷史文獻圖像的不同頁面之間在顏色和亮度上有比較大的差異;雖然卷積自編碼器有比較強的特征提取和泛化能力,但是面對藏文歷史文獻圖像的復雜性,本文認為顏色信息不會對藏文歷史文獻超像素塊的分類產生積極的影響。以下實驗驗證了這一想法。
用同樣結構的自編碼器,輸入分別設為彩色圖像和灰度圖像,目標輸出均為其對位輸入;訓練好自編碼器之后分別用它們提取的特征訓練SVM分類器,對超像素塊做分類。CAE為卷積自編碼器,其結構與CDAE相同。實驗結果如表2所示。

表2 顏色信息對分類結果影響的對比
從實驗結果可以看出,輸入為彩色圖像的自編碼器提取的特征分類結果低于灰度圖像。此實驗表明了對于藏文歷史文獻來說顏色信息沒有對分類產生比較積極的作用,導致分類準確率低于單通道的灰度圖像;所以在訓練CDAE時,本文選擇了藏文歷史文獻的灰度圖像作為輸入,消除顏色信息對特征提取過程的干擾,降低計算的復雜度。
3.3.2 降噪對超像素塊分類的影響
降噪自編碼器能夠學習輸入信號的更加魯棒的表達,使得它的泛化能力比一般編碼器更強。表3中分別用二值化圖和灰度圖做目標輸出,訓練同樣結構的自編碼器來提取特征對超像素塊進行分類。

表3 降噪對分類結果影響的對比
由結果可以看出,用降噪方式訓練的自編碼器具有更高的分類準確率,這證實了降噪自編碼器能夠消除噪聲的干擾,更專注于藏文歷史文獻中內容相關的信息。
3.3.3 實驗結果對比分析
本文用相同的超像素數據分別對文獻[2]中的方法和本文的方法進行了實驗。文獻[2]中的方法采用了三個不同的全連接層結構自編碼器組成,選用不同尺度的訓練數據逐層進行訓練。對一個超像素塊分別用這三個自編碼器從不同的尺度提取特征,然后將三個自編碼器提取的特征組成一個特征向量。為了更加全面地對比實驗結果,除了按照文獻[2]中的原始方法(輸入圖像和目標輸出均為彩色圖像)進行了實驗,在不改變其自編碼結構的情況下,還使用了跟本方法類似的降噪方式訓練其自編碼器。實驗結果如表4所示。
從表4中可以看出,在藏文歷史文獻的版面分析方面,本文的方法要明顯優于文獻[2]中的方法。從實驗結果可以看出,用不同的方式訓練的文獻[2]的自編碼器,分類正確率差異比較小。這表明在藏文歷史文獻上,文獻[2]中的方法獲取的特征雖然也學習到了能夠區分不同超像素類別的特征,但其特征的泛化能力和魯棒性較弱。本文的方法可以彌補其不足,得到泛化能力和魯棒性都較強的特征,取得了較高的分類正確率。

表4 實驗結果對比
圖7展示了進行超像素分類后的藏文歷史文獻的版面分析結果,文本區域、邊框、邊緣背景區域分別用不同的灰度邊緣來區分。從圖中可以看出大部分的版面元素都能夠得到正確的分類結果,但是由于版面的不規則和算法的局限性,有部分超像素塊被誤分為其他類別。

圖7 版面分析結果
4 總結
本文提出了基于卷積降噪自編碼器的藏文歷史文獻的版面分析方法,首先對藏文歷史文獻圖像進行超像素聚類,然后訓練卷積降噪自編碼器來提取特征,再利用SVM分類器對超像素塊進行分類。實驗表明,在藏文歷史文獻的版面分析上,本文的方法獲得了較高的分類準確率。但本文設計的方法仍存在一些不足,如藏文歷史文獻圖像數據種類和數量還需完善,網絡結構還有改善空間,識別率有待提高,最終結果比較依賴超像素聚類結果等,后續將繼續研究改進。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
