一種改進的延時調度算法
2018-08-10 06:07:00王鐘斐王鐘磊
電子設計工程 2018年15期
關鍵詞:作業
王鐘斐,王鐘磊
(1.寶雞文理學院數學與信息科學學院,陜西寶雞721013;2.成都銀行四川成都610000)
近年來,隨著互聯網應用的飛速增長,海量數據的存儲以及處理問題得到廣泛的關注。基于這一背景,云計算[1-3]應運而生,該新興的商業計算模型以網絡技術、虛擬化技術、分布式計算技術為基礎,以按需分配為業務模式,具備動態擴展、資源共享、寬帶接入等特點[1]。
當前大多數云計算系統都采用Hadoop平臺[4-6]來開發和調試程序,Hadoop項目是由Doug Cutting領隊開發的開源框架。Hadoop平臺中的作業調度器是以可插拔的方式加載的,目前Hadoop發布版本中的主流調度器有3種:先進先出調度器(First In First Out Scheduler)[7-9]、公平調度器(Fair Scheduler)[10-11]以及計算能力調度器(Capacity Scheduler)[12-14]。其中,FIFO為Hadoop的默認作業調度器,這種調度算法簡單明了,但在某些特殊情況下,本地化任務[15-16]不能充分實現。
文中從Hadoop主旨出發,設計了旨在增加本地化任務比率并減少作業響應時間的改進算法。通過分析各個作業的作業時間敏感度指標并進行排序,本文算法優先選擇時間敏感度高的作業及任務進行資源分配,同時,引入延時的調度思想,以能夠獲得更大比率的本地化任務,并且顯著縮短作業的響應時間。實驗結果表明,使用本文改進算法可以顯著降低作業的響應時間。
1 問題的提出
先進先出調度算法(FIFO)為Hadoop的默認作業調度器,適用于在集群中運行單一作業。該算法簡單明了,而且JobTracker的工作負擔比較輕,但是它也存在以下不足之處。
首先,它遵循嚴格的FIFO作業順序來分配任務,這意味著,假如隊列中第一個作業還有未被分配的map任務,那么隊列中的其他任何作業任何任務都得不到分配。這種缺陷在數據本地性方面也會有很大影響,即便隊列中其他作業的任務在某個節點上有多個輸入數據塊,這些任務在第一個作業所有map任務被調度前,都得不到調度。其次,由于數據本地化是由工作節點的心跳信息序列隨機決定的。即工作節點根據自己完成任務的進度以及自身的空閑任務槽情況,發送相關信息給主機節點并請求任務分配,由于集群中節點眾多,而且運行情況各異,因此數據本地化的具體信息不能事先估計。
文中考慮到小規模集群系統中短作業比較多、數據規模處理不大的特點,提出了一種改進的延時調度算法。該算法有兩個特點,一是優先選擇時間敏感度高的作業及任務進行資源分配,這可以優先分配資源給交互型的短作業;二是根據優先級的不同決定每個作業的等待時間,這樣可以獲得更大比率的本地化任務,并且顯著縮短作業的響應時間。
2 改進的延時調度算法
針對原有調度算法在特殊情況下,本地化任務不能充分實現的問題,本文從Hadoop主旨出發,設計了旨在增加本地化任務比率從而減少作業響應時間的改進算法。算法的主要思想是:在執行某個作業的非本地化任務之前,都有公平的機會獲得該作業本地化任務。即該算法的中心思想是為每個作業在合理的等待時間內找到一個本地化map任務。
對于短作業的優先調度目標,引入作業進度時間敏感度,即單位時間內作業的進度增加情況。顯然,作業進度時間敏感度越高,說明進度對時間的敏感程度越高,這時若該作業等待調度時間越久,則會嚴重影響到該作業的執行性能,這種延時在交互型作業中更加不可忍受。舉個例子:假設我們有兩個作業A和B,A是科學計算的作業,在10 s時間中,進度增加了1%,那么說明此刻,該作業的作業進度時間敏感度為0.001,該作業的預期完成時間為1 000 s;而作業B是一個交互型作業,在2 s的時間內,已經運行了50%,那么該作業的PTU值為0.25,預期完成時間為4 s,在這樣的情況下,如果A作業延時10 s調度,則不會給作業所屬的用戶帶來非常明顯的作業響應滯后的感覺,而如果B作業延時10 s調度,這時云計算的用戶體會非常糟糕。我們更關注在短時間內,進展速度快的作業應該優先得到執行,需要盡快分配集群資源響應該作業。因此,我們設計該指標計算公式如下:
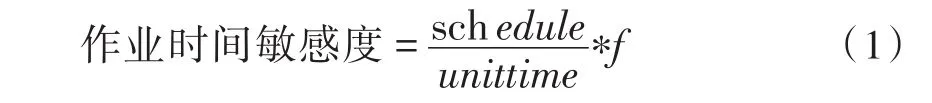
公式中的f即調節因子,根據實際情況,調節作業優先級在該作業進度時間敏感度指標中的比重。
首先,該算法在進行任務分配時不必遵循嚴格的作業順序。假如作業隊列中第一個作業中沒有本地化map任務,那么調度器會繼續在后續作業中查找。其次,為了給每個作業公平的機會去獲得自己的本地化任務,當某個作業等待一段時間T1后,還不能從具有空閑任務槽的節點中找到本地化任務,那么為了避免浪費集群的計算資源,本文提出的算法會分配該作業的一個非本地化任務。這樣,該算法不僅能達到高本地化任務的比率,也能增加集群的高利用率。第三,按照作業時間進度的指標對作業進行排序,這樣對于某些交互型的需要很快響應的作業,調度器能夠優先調度并分配集群資源。第四,當某個新作業加入隊列時,把該作業放在隊首,優先給該作業分配定額的計算資源,隨后該作業在隊列中的位置則由該作業的作業時間敏感度值所決定。
優化調度算法的執行示意圖如下所示:
1)在0:00時,集群現狀如圖1所示。
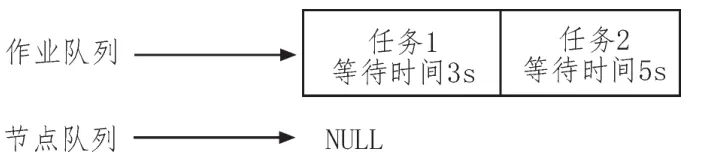
圖1 某時刻集群現狀
2)0:04 s時,由于此時任務1的等待時間為3 s,故分配該任務給節點A,該任務為非本地化任務,如圖2所示。
3)0:08 s時,如圖3所示任務3進入隊列,則放入隊首,同時,由于節點B具有任務2的本地化數據,將任務2分配至節點B,任務2為本地化任務。
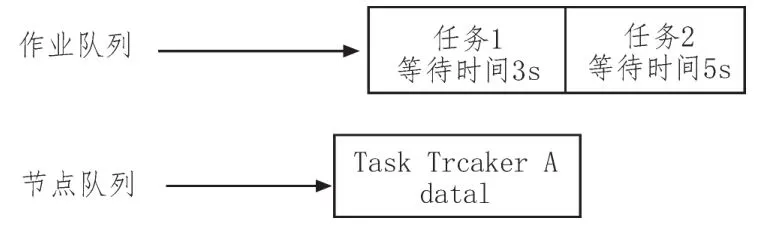
圖2 某時刻集群現狀
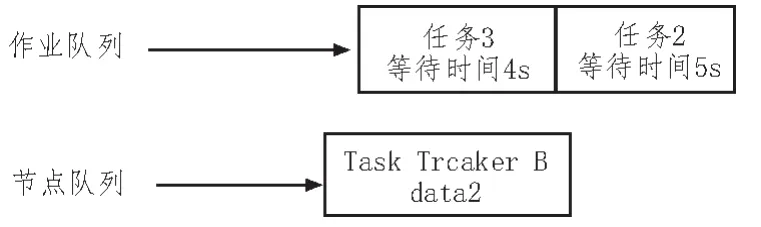
圖3 某時刻集群現狀
因此在優先響應短作業的前提下,通過對非本地化任務的延時調度,寄希望于具有本地化數據的節點在一定時間內向主控節點報告狀態,從而使該非本地化任務編程本地化任務。
優化后算法的偽代碼如下所示:

3 實驗結果分析
測試數據:設定兩組相同的任務,但輸入數據規模不同,其中作業A處理數據為1 GB,作業B處理數據為64 MB,這樣相對B而言,作業A為長作業,而B為短作業,因此作業B需要及時分配集群計算資源,盡快得到響應。
如圖4所示,采用作業時間敏感度排序:當1 GB作業正在運行時,64 MB作業加入到作業隊列,剛開始64 MB作業進展緩慢,這是前期集群在準備作業B的執行資源,隨后由于B作業處理數據規模非常小,這時其作業時間敏感度相對較高,優先得到調度及計算資源分配,而1 GB作業則由于分配少量計算資源而相對執行速度較慢。
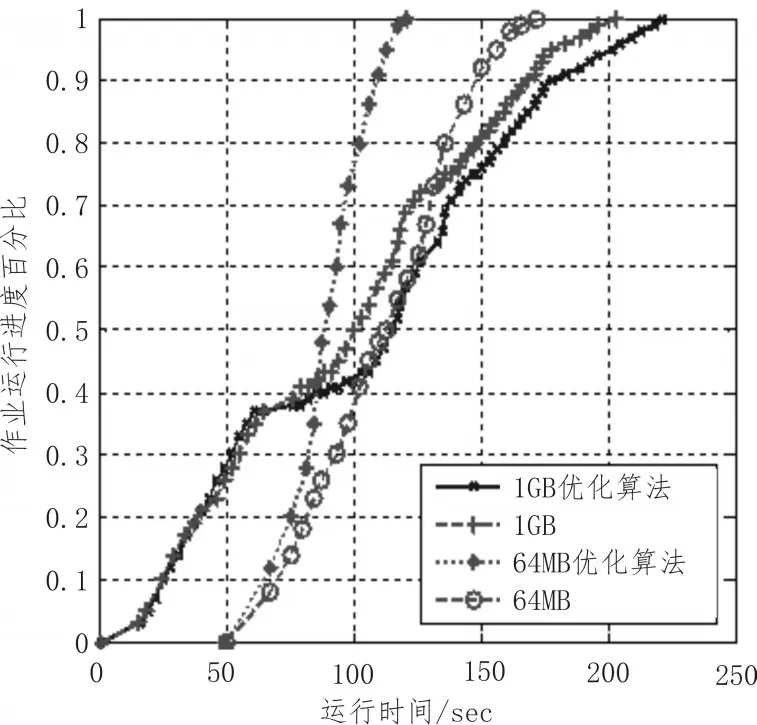
圖4 作業時間敏感度因子對作業執行影響
未采用作業時間敏感度排序:1 GB作業和64 MB作業呈現競爭計算資源的情況,作業進度增加速率差別不大。
縱向比較同一個作業在不同情況下的執行結果:
采用作業時間敏感度排序:
64 MB作業:67 s
1 GB作業:252 s
未采用作業時間敏感度排序:
64 MB作業:102 s
1 GB作業:237 s
由上面數據可以看出:對于64 MB的短作業來講,采用作業時間敏感度的作業運行時間比未采用作業時間敏感度的作業運行時間減少了35 s,減少百分比為34.31%,雖然這時的1 GB長作業運行時間增加了15 s,其增加百分比為6.33%。
因此,加入作業時間敏感度排序指標可以有效減少短作業執行時間,提高用戶體驗,而長作業雖然響應時間增加,但是增加不大,基本不會影響該作業的預期執行效果。
4 結 論
首先簡要介紹了現有Hadoop平臺的3種調度算法;然后提出現有算法的本地化任務不能充分實現的問題;為解決此問題,本文考慮到小規模集群系統中短作業比較多、數據規模處理不大的特點,提出了一種改進的延時調度算法;實驗結果表明,本文的改進算法不但可以獲得更大比率的本地化任務,并且能夠顯著縮短作業的響應時間。
猜你喜歡
小主人報(2022年1期)2022-08-10 08:28:44
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
學生天地(2020年17期)2020-08-25 09:28:54
作文成功之路·小學版(2020年7期)2020-08-24 08:19:30
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
作文成功之路·小學版(2020年7期)2020-01-02 10:10:44
趣味(數學)(2018年12期)2018-12-29 11:24:10
小學生作文(中高年級適用)(2017年10期)2017-11-13 06:01:00
能源(2016年2期)2016-12-01 05:10:46
故事大王(2016年7期)2016-09-22 17:30:08
