基于足球比賽事件檢測的視頻分析方法*
2018-07-18 06:47:54羅安平
沈陽工業大學學報 2018年4期
劉 陽, 羅安平
(沈陽工業大學 信息科學與工程學院, 沈陽 110870)
視頻分析方法的研究作為視頻語義領域的一個重要分支在學術和商用兩個方面得到了廣泛關注.不僅因為其擁有巨大的商業價值,也因為其涉及到信號處理、人工智能、計算機視覺、模式識別、人機交互及數據庫等諸多學科領域,具有重要的理論意義.視頻分析實際上就是通過提取特定的特征來檢測目標事件,并以檢測出的目標事件為基礎進行分析得到用戶需要的信息[1].
事件檢測就是將用戶感興趣的視頻段從一個完整的、擁有大量信息的視頻中提取出來[2].最開始的事件檢測方法是通過人工來進行目標事件的檢測和提取,也就是專業人士根據自己的工作經驗利用純手工的方式,將目標事件從完整的視頻中檢測和提取出來.但是當今社會是一個信息爆炸的社會,視頻數據每天都在高速地增長著,這種方式非常耗費人力資源,同時可靠性很差,容易出錯,所以如何對視頻中的目標事件進行快速且準確的自動檢測成為了本文研究的重點.
1 事件檢測過程
本文以足球比賽視頻中的進球事件為例,介紹了一種機器學習和人工規則相結合的事件檢測方法,其流程圖如圖1所示,具體步驟如下:
1) 將訓練樣本視頻段和完整的足球比賽視頻進行鏡頭分割,得到訓練樣本鏡頭序列和比賽視頻鏡頭序列;
2) 結合人工規則和傳統經典算法對分割好的鏡頭進行語義標注;
3) 通過特殊鏡頭定位將疑似目標事件的語義鏡頭序列提取出來,本文以進球事件為例,通過檢測球門鏡頭初步提取疑似進球事件的語義鏡頭序列;
4) 利用訓練樣本鏡頭序列計算隱馬爾科夫模型的初始參數,建立進球事件的隱馬爾科夫模型;
5) 通過前向算法計算訓練樣本鏡頭序列的概率,用來確定判斷的閾值;
6) 計算該模型下產生這些語義鏡頭序列的概率,并根據判斷閾值檢測出測試數據中的進球事件.
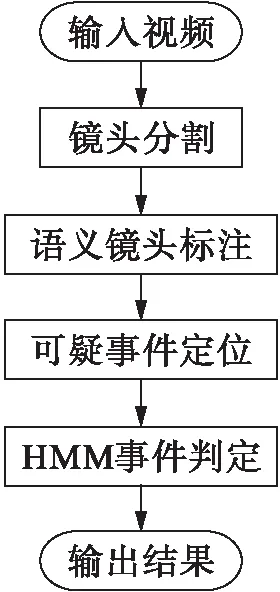
圖1 事件檢測流程圖Fig.1 Flow chart of event detection
2 鏡頭分割與語義標注
視頻是由連續圖像幀構成的,而當一系列保持較高相似性和連續性的幀組合在一起就形成了鏡頭,因此,足球視頻可以看作是由一系列語義鏡頭組成的.而事件則是一系列按照一定規律排列的語義鏡頭序列.
若要得到語義鏡頭,首先需要將視頻進行鏡頭分割并提取關鍵幀,再通過對關鍵幀的處理得到特征值[3],從而對鏡頭進行語義標注.本文選取了Twin Comparison算法進行鏡頭分割,該算法是一個能夠識別突變和漸變的雙閾值算法.算法考慮了漸變過程中幀與幀之間的累積差異,并進行了兩次視頻掃描,一次使用較高的閾值來檢測突變,另一次使用較低的閾值來檢測潛在的漸變.鏡頭分割完成后就可以按一定規律進行關鍵幀提取,需要注意的是:關鍵幀必須是能夠反映鏡頭內容的[4],文中將鏡頭的中間幀作為關鍵幀.
本文通過提取特征值并結合決策樹來對鏡頭進行分類和語義標注.在決策樹的第一層首先區分的是重放鏡頭和非重放鏡頭,提取重放鏡頭的步驟如下:
1) 利用Logo鏡頭幀間差的特征提取可能的Logo.
2) 利用這些提取的Logo生成一個相對標準的模板.
3) 利用Logo模板將所有的Logo檢測出來.
4) 按順序兩個Logo鏡頭之間的鏡頭就是重放鏡頭.決策樹的第2層則是通過顏色直方圖來判斷場地面積,以此將非重放鏡頭分為場內鏡頭和場外鏡頭;第3層通過計算人臉比例提取場內鏡頭中的特寫鏡頭;第4層通過計算場地和球員面積比例將剩下的場內鏡頭分為遠鏡頭和中鏡頭.決策樹流程圖如圖2所示.
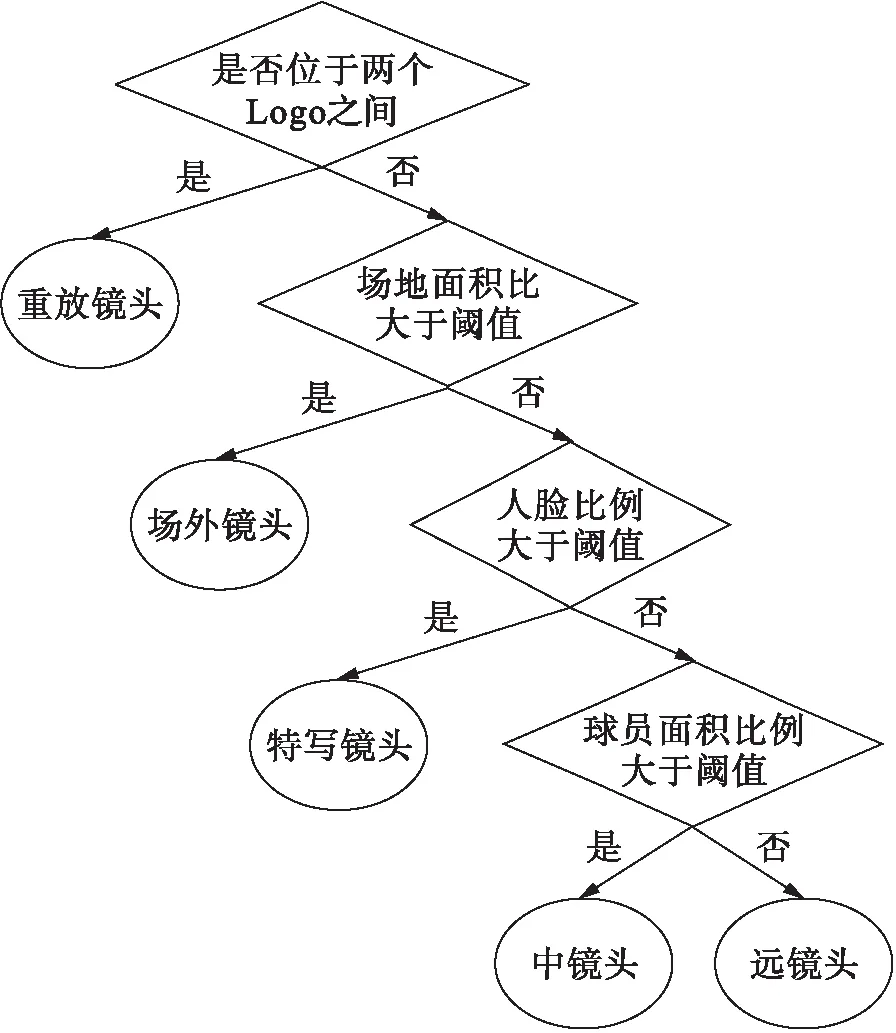
圖2 決策樹流程圖Fig.2 Flow chart of decision tree
3 基于球門檢測的進球事件定位
從一個完整的足球比賽視頻中檢測出進球事件,首先需要從比賽視頻中提取可能的語義鏡頭序列.當發生進球事件時,最先出現的一定是禁區附近的區域,這通常包含了清晰的球門遠鏡頭或中鏡頭,進球完成后,通常會出現運動員、教練員或者裁判員的一些特寫鏡頭,最后會出現進球的重放鏡頭,因此,提取可能為進球事件的語義鏡頭序列步驟如下:
1) 從分割好的鏡頭中提取關鍵幀.
2) 對關鍵幀圖像進行robert算子提取邊緣檢測(檢測結果如圖3所示).

圖3 邊緣檢測Fig.3 Edge detection
3) 利用霍夫變換平行線檢測將兩條相鄰的平行線合并為一條直線(霍夫變換檢測結果如圖4所示).
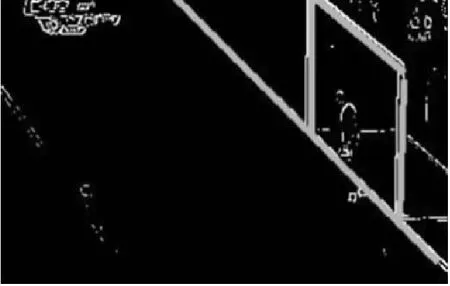
圖4 霍夫變換檢測結果Fig.4 Detection result of Hough transform
4) 在步驟3)得到的線段中選取兩根豎直最長的線段作為候選球門柱.
5) 利用啟發規則判斷步驟4)中的候選門柱是否為球門,啟發規則如下:
① 判斷兩根球門柱的長度,如果都不在一個范圍內則不是球門,這個范圍由圖片的分辨率決定,如本文的范圍是15~200個像素;
② 判斷兩根球門柱之間的距離,如果不在一定范圍內則不是球門,本文的范圍是20~260個像素;
③ 判斷兩根球門柱之間的長度差,如果不在一定范圍內則不是球門,本文的范圍是0~20個像素;
④ 判斷兩根球門柱之間的距離和最長球門柱之間的比值,若不在0.5~3.5的范圍內則不是球門;
⑤ 兩個球門柱構成的最小矩形的中心位置應處在一定的區域內,其中心點的縱坐標應在一定范圍內,如果不符合則認為不是球門,本文的范圍是20~340個像素.
6) 找到包含球門的鏡頭后,以該語義鏡頭為開始,在語義鏡頭序列中尋找重放鏡頭.根據實際情況確定尋找的最大長度,如本文尋找長度為10,即如果開始鏡頭與重放鏡頭之間超過10個鏡頭,則繼續尋找下一個包含球門的鏡頭;反之,該鏡頭序列為候選進球事件序列.
圖5則是通過上述方法提取的可能為進球事件的語義鏡頭序列關鍵幀.在取得可能的進球事件語義鏡頭序列后,則需要采用隱馬爾科夫模型(hidden Markov models,HMM)來做進一步的判斷.

圖5 疑似進球事件序列Fig.5 Suspected scoring event sequence
4 基于HMM進球事件檢測
HMM可以被看作是一個關于進球事件的語義鏡頭序列模型,這個序列可以通過“隨機行走”產生[5],即從初始位置W0出發,通過狀態轉移矩陣A選擇一個可能的狀態θ1,并到達W1.如果W1的狀態為θ1,則根據觀察值狀態矩陣選擇一個該狀態下可能的語義鏡頭O1,然后再根據狀態矩陣轉移到下一個狀態.通過模型中的狀態(θ1,θ2,…,θN)產生一系列的語義鏡頭(O1,O2,…,ON),則狀態序列產生的語義鏡頭序列的概率便是評判該序列是否為進球事件語義鏡頭序列的標準.而語義鏡頭序列概率需要使用向前算法來計算[6],其定義為
γm(i)=P(O1,O2,…,Om,qm=θi|λ)
(1)
式中:m為鏡頭序列的鏡頭數;qm為第m個鏡頭的狀態;λ為模型狀態.因此一個語義鏡頭序列的概率為
(2)
對于與模型相符合的序列,HMM能以較大的概率產生序列;與模型不符合的序列,則產生序列的概率會較小[7].實踐中一般采用Baum-Welch算法使模型產生更合適的事件語義鏡頭序列,但該算法易收斂于局部最優,本文設計了一種遺傳算法來訓練HMM,從訓練樣本中自動獲得模型參數.
5 基于Baum-Welch算法的HMM
Baum-Welch算法[8]描述為:給定訓練序列語義鏡頭O和模型狀態λ,定義ξt(i,j)為馬爾可夫鏈在t時刻處于狀態θi,t+1時刻處于狀態θj的概率[9-10],即
(3)
式中:αt(i)和βt+1(j)分別為t、t+1時刻處于狀態θi條件下產生序列O的概率;aij為狀態轉移矩陣中的對應元素;bj(Ot+1)為觀測符號矩陣中的對應元素.則t時刻馬爾可夫鏈處于狀態θi的概率為
(4)
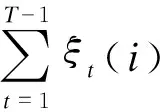
(5)
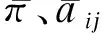
6 結合遺傳算法的HMM
遺傳算法是模擬自然界優勝劣汰的進化現象,把搜索空間映射為遺傳空間,將可能的解編碼成一個染色體,并不斷用適應度函數去計算每條染色體的適應值,從中選取最優解.
在HMM的參數π、a和b中,b的選取最為重要,因為π為初始狀態量,對模型影響并不是很大,而a為狀態轉移量,由于本文應用的HMM中狀態僅有三個,且應用了從左向右的諾爾馬夫鏈,所以a的選取對模型影響也不是十分明顯.只要通過遺傳算法訓練出最優的初值b就可以明顯提高HMM的模型性能,使其能夠在盡量少的訓練樣本下得到性能最優的模型.
6.1 編碼方案
初值b中每個元素的取值范圍為[0,1],為了保證精度,本文選取長度為64的二進制數來表示該參數,它能產生264種不同的編碼.
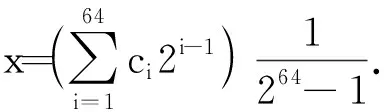
6.2 適應度函數
適應度函數為判斷每條染色體優劣的函數,訓練模型為了能更好地描述代表進球事件的語義鏡頭序列,定義染色體優劣的評判標準為:在該模型下一個代表進球事件的語義鏡頭序列概率越大越好.適應度用各組訓練樣本的對數似然函數來表示,即
f(λ)=ln(P(Ok|λ))
(6)
6.3 遺傳算子選擇
本文采用了基于適應值比例的賭輪盤選擇方法,這種方法可以想象成向劃分好扇區的輪盤里扔色子,事先生成一組滿足均勻分布的隨機數,代表n次擲色子或者n個色子一起扔,輪盤不動,色子所在區域為選擇結果,也就是要選擇的染色體.
6.4 終止準則
常用的終止準則是預先設置最大進化的代數或預先設置一個適應度改善的閾值.對于前一種準則,在進化代數到達預置值時進化終止;而后一種準則是在適應度改善低于該閾值時進化停止.本文采用了兩種準則相結合的方法,同時設置閾值和最大進化代數,在達到最大迭代數之前如果達到閾值,則進化結束.
6.5 訓練算法
首先通過對訓練樣本的觀察和統計得到幾組初始參數,然后將這幾組參數中的b進行編碼,形成種群,通過適應度函數計算種群中所有染色體的適應度,并利用賭輪盤方法選擇染色體,對選擇出的染色體進行交叉和變異操作,將形成的子代代替父代放入種群中,重復以上操作直到達到終止準則為止.
7 實驗與結論
實驗視頻選自2016年英超聯賽多個場次的比賽.實驗視頻分為兩部分,一部分作為訓練視頻片段,分為4組,分別包含10、20、30、50個進球視頻片段;另一部分作為測試視頻片段,含有30個進球視頻片段和20個非進球視頻片段.實驗通過對測試樣本的識別準確率來判斷模型的性能.
識別率的比較結果如表1所示,由表1中可以看出,在訓練樣本增加的時候,本文所提算法的識別率增加速度要遠高于Baum-Welch算法,因此可以得出,改進算法能夠有效避免局部最優解.

表1 識別率比較Tab.1 Comparison in recognition rate
本文還做了適應性測試以證明本方法的有效性.選取了歐冠和西甲等各個聯賽的完整視頻作為測試數據進行進球事件的檢測,適應性測試結果如表2所示.由表2可見,本文提出的事件檢測方法能夠比較準確地實現足球視頻中進球事件的檢測.

表2 適應性測試Tab.2 Adaptability test
綜上所述,本文所提出的基于人工規則和機器學習相結合的事件檢測算法可以有效地在不影響準確率的情況下節約時間成本,提高了HMM訓練算法在訓練樣本相對較少情況下的查全率和查準率.本算法流程還存在不足之處,如機器學習算法有待改進.尋求更加詳細和全面的鏡頭語義標注方法,進一步提高機器學習算法對目標事件的識別能力是今后的研究重點.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
