離群點檢測技術在教育教學中的應用*
2018-07-06 07:11:42陳世超楊現民潘青青邢蓓蓓
現代教育技術 2018年6期
陳世超 楊現民 潘青青 邢蓓蓓
(江蘇師范大學 智慧教育研究中心,江蘇徐州 221116)
引言
隨著互聯網的普及與發展,在線教育在整個教育生態體系中的地位越來越凸顯,以MOOC為代表的在線課程學習也越來越受到學習者的推崇。然而,在實際的學習過程中,相關研究發現不同學習者的學習水平和效果存在較大差異[1][2]:一方面,部分學習者進行在線學習時表現出極高的積極性和參與度,能夠獲得優質的學習效果;另一方面,部分學習者動機不足,不能深度參與,甚至是游離在學習活動之外。這種兩極化的離群現象表現得十分突出,在一定程度上影響了在線教學的整體質量和效果。
近年來,在線教育數據呈現“爆炸式”增長,數據挖掘技術在教育中的應用研究受到了廣大研究者的普遍關注,國外的相關研究主要集中于學習行為特點及其關系[3][4][5],國內研究則傾向于將數據挖掘視為一種技術工具,實現對在線學習的監測和評估。數據挖掘技術在教育領域的應用日益廣泛,如為學生提供建議、為教師提供反饋、預測學生表現、發現不良學生行為、對學生進行分組、構建課程、規劃和調度、數據分析和可視化等[6]。數據挖掘技術能夠分析教學中的離群數據,解決在線學習效果的極端現象,挖掘教育中被忽視的隱藏價值,為教育教學的質量提升和科學決策提供借鑒。
一 離群點檢測技術的內涵及應用價值
離群點檢測(Outlier Detection,OD)又被稱為異常檢測、孤立點檢測、偏差檢測,是識別不符合預期模式或數據集的項目、事件或觀察結果[7]。目前,研究者對于離群點的研究尚未有統一的定義。獲得廣大研究者認同的是由Hawkins[8]給出的離群點的本質性定義:離群點是數據集中偏離大部分數據的數據,由于偏離其它數據太多,使人懷疑這些數據的偏離并非由隨機因素產生,而是產生于完全不同的機制。
離群點在不同情境中的側重點不同,通過對這種顯著偏離預期行為和狀態的數據、項目或事件進行異常捕捉和分析,一方面降低了錯誤決策的風險,幫助識別和預防不良影響;另一方面可以發現潛在的、有意義的信息,幫助領域工作從業者快速定位特殊信息,為行業的決策者制定高質量決策。離群點檢測算法可以大致分為五類:基于分布的離群點、基于深度的離群點、基于聚類的離群點、基于距離的離群點和基于密度的離群點[9],如圖1所示。
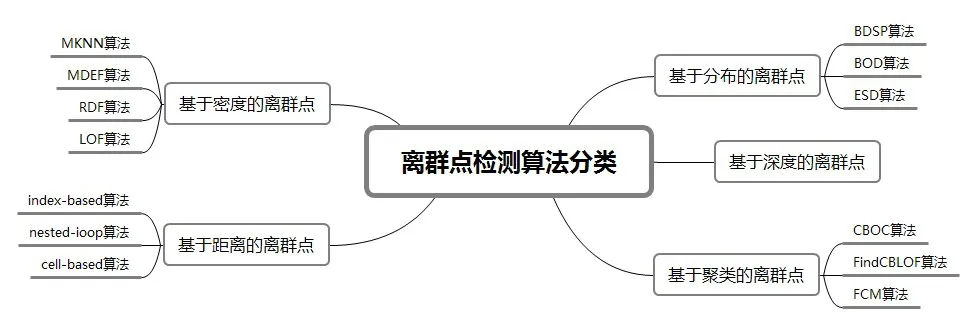
圖1 離群點檢測算法的分類
二 離群點檢測技術在教育教學中的應用框架
當前教育數據挖掘已經受到國內外教育工作者的重視,其技術的應用價值也逐漸凸顯。相對而言,離群點檢測技術在教育中的應用研究卻相對較少。根據研究對象的不同,可將離群檢測分為對學習者、教師、教育資源、學校、地區等的離群,其分析結果則應用于學生狀態檢測、優質師資鑒別、資源質量篩選、學校水平衡量以及教育發展評估等多個方面。通過離群點檢測發現教育教學中的特殊現象,并進行深入分析,及時采取措施干預,從中發現新的規律和方法,對教育的應用指導具有重要意義。
1 學習者離群
學習者離群主要通過收集學習者的基本信息、學習狀態(測驗評分、考試成績、課后作業、互動頻次、發言次數)、性格特征、課堂問題行為、家庭狀況等數據,對其學習和生活軌跡進行追蹤檢測,定位異常學習者,分析其行為規律,進而為學習者糾正學習誤區、合理分配資源、增加個性化指導、加強心理輔導,降低學習者的失敗風險。Cheng等[10]采用基于聚類的離群點檢測算法在學習社區中定位異常學習行為,即首先使用聚類方法將類似行為模式的學習者聚集到群集中,再對沒有聚類的數據進行離群檢測,構建基于行為因素分析的行為過濾模型,實現對學習者的定位與分析,進而為其提供個性化的監督與指導。
2 教師離群
教師質量評估是檢驗教學質量的重要手段,借助離群點檢測技術可以從教師本身及其相關信息視角出發,對教師的教學質量進行評估。教師離群主要通過收集教師的個人信息、職稱、教學風格、提問傾向、教學行為等數據來直接說明教學效果,同時收集學生的學習成績、評教等數據,間接反映教師的教學成果。對數據的離群分析,主要用于鑒別優秀教師、篩選特色教師、加強評教有效性、提升教師素養、促進地區優秀師資共享等,使教師質量的評估結果更為準確、客觀。Farooqui等[11]在對教師的資質識別研究中主張提取離群點的特征,通過學生成績來識別成功的教學工作范例,其研究發現:某班級未能通過考試的學生比重高達 42%,這和教師素質以及教師能否與學生和諧相處有很大關系,因此該校制定相應措施,為學生配備相應的教師進行授課,使其水平得到更大程度的發揮,從而改善學習效果和課堂實踐。
3 教育資源離群
大數據背景下的教育資源來源復雜多樣,同時也產生了大量的劣質資源、同質資源,為使用者帶來了一定的不便,因此,資源的質量問題引起了廣大研究者的關注。利用離群點檢測技術發現離群數據,可以達到對信息的檢測和量化作用。教育資源離群主要通過收集資源內容、資源類型(文本、音頻、視頻、圖片、日志)、資源來源以及資源操作(資源下載、資源上傳、資源刪除、資源更新、資源分享、資源瀏覽、資源轉載、資源訂閱、資源收藏、資源評論)等數據,用于快速定位需求資源、檢測在線資源質量、分析資源熱度、擴散度以及淘汰指數等。如網絡上一些劣質資源、虛假信息以及與學習無關的資源,利用相關資源作掩護,以達到避免被過濾和淘汰的目的。而通過離群檢測可以發現資源內容異常、識別資源相關度,從而過濾掉不匹配的內容,為用戶提供與學習內容相關的優質資源。
4 學校離群
學校的辦學質量和水平是人們關注的重要指標,不同地區的學校在教育管理、教育教學等方面都有各自不同的特色,教學成績也存在較大差異。為了均衡學校之間的教學水平,凸顯優質學校特色,有必要對學校的辦學情況進行離群檢測。學校離群主要通過收集學校的教輔設施(種類、數量、能耗、新舊)、師資力量(職稱、獲獎情況、教學手段、管理手段、教學風格)、學生表現(學風學氣、考試成績、獲獎情況、畢業率)等數據,對學校的整體教育教學水平和校園安全隱患進行實時監測、統計和分析。徐琰等[12]對某高校的能耗情況進行了基于統計的離群點檢測,結合能耗監控系統發現和分析異常能耗數據,與校園能耗規律進行比較,最終得出該校能耗的異常情況并進行及時預警,以達到節約能耗的目的。
5 地區離群
教育的差異性在很大程度上影響了一個國家和地區的整體水平,為了對地區的教育發展水平進行整體性評估,有必要對區域的教育發展指數進行離群點檢測分析。地區離群主要通過收集地區的教育發展指數,包括兒童入學學齡、成人識字率、學生性別平等指數等區域性數據,將超出設定閾值的數據提取出來,發現教育高風險地區,并調查原因,有針對性地采取措施,實現區域間教育年齡的均衡發展。Jana等[13]通過離群檢測技術對印度35個州的教育發展進行了離群定位分析,以教育發展指數的四個指標作為基準,最終檢測到分值較低或較高的數據,對各項指標進行深入分析,找出具體的影響因素,為教育教育的區域發展制定相應的規劃和政策。
三 離群點檢測技術在教育教學中的應用流程
與一般數據挖掘技術不同,離群點檢測技術專門針對那些與一般常規數據相差甚遠的小規模數據。判斷一個對象是否離群,需要重視那些偏離正常模式的數據,進而發現隱藏的、有價值的信息來指導和發展教育。總的來說,離群點檢測技術在教育教學中的應用一般需要經過以下七個流程(如圖2所示):
①確定分析對象。離群分析對象包括學習者、教師、教育資源和學校以及地區等教育教學要素,而離群對象的確定取決于研究者的需求,對不同的研究對象進行離群分析,會得到不同的研究結論,從而為各層次、區域的教育教學提供相應的參考。
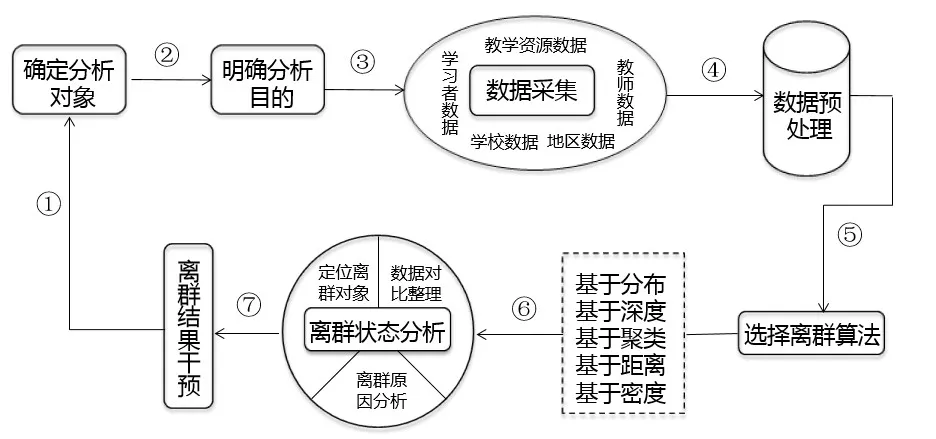
圖2 離群點檢測技術在教育應用中的流程
②明確分析目的。鎖定具體分析對象,根據研究者的關注點確定離群點檢測的目的,主要包括積極的離群點檢測和消極的離群點檢測,然后再將分析目的具體化,如對學生進行個性化指導、鑒別優質師資、剔除劣質資源、監控校園安全等。離群點檢測分析的目的直接決定了整個分析流程的趨勢,針對分析對象實際存在的問題并結合環境和背景,離群點檢測會對研究對象進行深入挖掘和定位,最終得到的檢測結果和采取的措施都是為分析目的而服務。
③數據采集。根據離群對象及其目的,充分考慮影響分析對象數據變化的各種因素,既包括教學活動、管理活動、科研活動、校園生活等正式環境下產生的學習數據,也包括家庭、社區、博物館、圖書館等非正式環境下的學習活動等數據。教育數據本身來源多元,數據的采集更具復雜性,應該合理使用數據采集技術,配置數據采集的范圍和類型,對數據全面、動態、自然地進行采集[14]。
④數據預處理。教育系統的數據類型復雜、多樣呈現,因此對于復雜的時間序列樣本、非數值型樣本以及多維數據樣本,需要按照統一的數據標準進行數據的預處理,主要任務包括數據清理、數據集成和數據變換等,在不丟失數據意義的條件下將數據轉換成規范的、適合離群點檢測的形式。
⑤選擇離群算法。根據數據對象的類型、結構、數量以及具體呈現的一般規律,選擇合適的離群算法,每種離群點檢測算法都有其特殊的適用范圍,如表1所示。陸柳生等[15]在研究中用基于密度的算法對學生的學習成績進行檢測,確定離群因子,根據公式確定疑似離群對象,定位可疑離群學生,結合相關的因素分析其學習狀態,準確找出學習狀態異常的學生予以干預。
⑥離群狀態分析。根據選擇的算法進行檢測,定位疑似離群對象,與正常狀態數據進行比較,結合實際背景單獨對離群對象進行深入分析,總結可能引起離群的具體原因。若存在錄入錯誤或偏差,應該及時修正,保證結果的客觀性與真實性。若不是由于錯誤導致的離群事件,需要更為嚴密的進行檢測,并且持續、動態地觀察離群對象與一般模式的偏離程度,探究其離群的存在意義。
⑦離群結果干預。對離群檢測對象進行深度挖掘和分析,根據分析存在的原因,結合具體的教學情境有針對性地采取措施,進行適當干預,對于積極的離群現象加以強化,對于消極的離群現象加以改進。

表1 常用離群點檢測方法優劣分析
四 離群點檢測技術在教育教學中應用面臨的挑戰
離群點檢測技術在教育領域有著廣泛的應用前景,近年來受到越來越多研究者的關注。由于教育數據本身在不斷地動態生成,且每個人的顯性、隱性數據都各有不同,其應用也不可避免地將面臨更為復雜的挑戰。利用離群點檢測技術對教育數據進行監督和評估,還需要綜合考慮多種相關問題。
1 離群點的范圍界定
在實際的教育教學情境中,涉及的教育教學數據繁多、復雜,并且隨著時間的推移在不斷動態生成。以教育要素作為研究對象進行離群點檢測,需要考慮到離群點的范圍和數量等重要問題。首先,離群點沒有一個明確的范圍界定,本身呈現出一定的主觀性和相對性,這就從根源上導致了離群數據范圍的模糊和不確定性,最后結果的科學性和準確性將會受到影響。其次,數據的存在形式多樣,可能隱藏在一定的模式、趨勢背后,往往不容易被發現,并且離群點的檢測算法多種多樣,不同的算法選擇會直接影響到離群點的確定。最后,在教育情境中存在很多不相關因素的干擾,雖然也是離群數據,但是跟研究目的和對象關系不大,這樣的檢測結果往往也是無效的。因此,判斷教育領域的離群數據,在檢測之前需要對離群點的范圍或者閾值進行清晰的界定和規劃,在充分分析離群目的、確定離群對象的基礎上,選擇合適的離群檢測方法,對離群數據進行合理的判斷和分析,作用于教育的決策制定。
2 離群點的認識誤區
離群點由于本身體量小、范圍極端,通常會被研究者認為是誤差或無效數據,有的還會影響研究對象整體的精確度,造成誤導,增加分析難度,故研究人員往往將離群點視為“消極點”或“壞值”。實際上,離群點這種少量的、特殊存在的極端數據,不僅僅是從誤差分析上給研究者提示,而且也會提供一些容易忽略的重要潛在信息。在教育領域,離群數據代表學習者的學習實際,反映了個體的獨有特征和偏好。在教育教學過程中會不可避免地出現偏離常規的數據,其學習規律和特征都值得深入探索。而探究這些離群現象及其背后潛藏的關聯因素,可以幫助學習者減少失敗風險,提高學習效率和質量。另外,離群數據也是打破常規、特立獨行、創新創造的體現,符合新時代的人才培養目標,對這樣的數據進行分析往往會獲得更大的價值。
3 離群點的后期處理
在對離群點進行判別和驗證后,需要對離群點進行后期處理,以便精準地服務于教育決策。首先,從技術的角度分析離群點的產生原因,若是因為技術失誤或人為錄入錯誤,就需要將這樣的離群數據剔除,以降低后期的操作難度、提升數據的精確度,盡可能地避免主觀因素的影響。其次,排除技術失誤的因素,采用合適的智能挖掘算法對離群點進行挖掘,構建分析模型,確定合適的離群范圍,盡可能地減少離群點的主觀性和相對性帶來的誤差影響。最后,將離群點的分析結果以可視化的形式呈現出來,以便結合具體的教育教學情境詳細分析離群點的產生原因,并有針對性地提出相關措施和規劃,以發揮出更為實用的應用價值。
[1]Macfadyen L P, Dawson S. Mining LMS data to develop an “early warning system” for educators: A proof of concept[J]. Computers & Education, 2010,(2):588-599.
[2]Wong L. Student engagement with online resources and its impact on learning outcomes[J]. Journal of Information Technology Education: Innovations in Practice, 2013,(12):129-146.
[3]Psaromiligkos Y, Orfanidou M, Kytagias C, et al. Mining log data for the analysis of learners’ behaviour in web-based learning management systems[J]. Operational Research, 2011,(2):187- 200.
[4]Munk M, Drlik M. Impact of different pre-processing tasks on effective identification of users’ behavioral patterns in web-based educational system[J]. Procedia Computer Science, 2011,(4):1640-1649.
[5]Morris L V, Finnegan C, Wu C C. Tracking student behavior, persistence, and achievement in online courses[J]. The Internet and Higher Education, 2005,(3):221-231.
[6]Romero C, Ventura S. Educational data mining: A review of the state-of-the-art[J]. IEEE Transactions on Systems Man & Cybernetics, 2010,(6):601-618.
[7]Han J W, Kamber M, Pei J著.范明,孟小峰譯.數據挖掘概念與技術(第三版)[M].北京:機械工業出版社,2012:351-352.
[8]Hawkins D M. Identification of outliers[M]. London: Chapman and Hall, 1980:1-3.
[9]薛安榮,鞠時光,何偉華,等.局部離群點挖掘算法研究[J].計算機學報,2007,(8):1455-1463.
[10]Cheng Y, Miao Y C, Tan P F, et al. Research on mining and detection method of abnormal learning behavior[A].International Conference on Information System and Artificial Intelligence[C]. Hong Kong: Conference Publishing Services, 2016:566-570.
[11]Farooqui T, Mustafa I, Christie T. Outliers in educational achievement data: Their potential for the improvement of performance[J]. Pakistan Journal of Statistics, 2014,(1):71-82.
[12]徐琰,肖基毅.離群點分析在高校能耗監控系統中的應用[J].南華大學學報(自然科學版),2014,(2):89-93.
[13]Jana M, Sar N. Modeling of hotspot detection using cluster outlier analysis and Getis-Ord Gi* statistic of educational development in upper-primary level, India[J]. Modeling Earth Systems and Environment, 2016,(2):60-61.
[14]楊現民,唐斯斯,李冀紅.發展教育大數據:內涵、價值和挑戰[J].現代遠程教育研究,2016,(1):50-61.
[15]陸柳生,余明暉.基于離群點檢測的學生學習狀態分析方法[J].計算機與現代,2016,(3):35-40.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
電子制作(2018年18期)2018-11-14 01:48:24
資源再生(2017年3期)2017-06-01 12:20:59
山東工業技術(2016年15期)2016-12-01 05:31:22
