基于PCA-SVM算法的醫院和患者行為選擇的演化分析
2018-06-23 10:12:24張金鑫湖北大學商學院湖北武漢430062
絲路藝術 2018年3期
張金鑫(湖北大學商學院,湖北 武漢 430062)
尤瑞(荊門市財政局,湖北 荊門 448000)
當前醫療衛生數據呈現種類多、數量大、特征混雜等特點,為數據挖掘分類帶來一定的挑戰[1]。同時,信息的高度不對稱是醫患雙方的重要特征[2]。醫療衛生領域的信息不對稱主要體現在患者對醫療信息很難掌握、對醫療服務質量和數量缺乏必要的了解,同時也無法準確的事先預知[3]。
本文利用PCA-SVM對海量的醫療衛生數據進行降維,用降維后的數據進行訓練,用最好的分類器對患者疾病指標進行準確的預測,這樣不僅使患者對自己的病情有一個基本的了解,還避免了掛錯號的情況、緩解了醫患信息不對稱的問題。然后通過醫患演化博弈模型分析,并給出一些相應的建議。本文主要分為以下幾個部分:第一部分主要是介紹PCA-SVM算法模型;第二部分是醫患演化博弈分析;第三部分是對本文的總結以及一些相應的建議。
一、PCA-SVM算法模型
大數據背景下,數據挖掘在醫療衛生領域的應用越來越廣,尤其是通過PCA(主成分分析法)將數據進行降維,主要集中在醫學質量管理、藥物的研發以及輔助診斷方面。近幾年,SVM(支持向量機)、人工神經網絡(ANN)、K-means(k-均值聚類算法)已經用在疾病的預測上。如SVM用于診斷缺血型心臟病、SVM和鑒別集的結合可以診斷老年癡呆、ANN算法用于進行動脈抽樣硬化和心血管疾病的早期預防[4]、利用k-means算法和SVM算法的結合去診斷乳腺癌[5]等。但是,對于海量的數據,有些數據可能對我們的實驗作用不是很大,反而在進行數據處理時加大了難度,所以就要先進行數據清洗和數據預處理。數據預處理的方法主要有:數據集成、數據清理、數據選擇、數據特征降維等。本文運用PCA首先對海量的醫療數據進行降維,然后使用SVM對選擇的特征進行有效地訓練,最后對患者的疾病進行精確地預測。
(一)利用PCA對數據進行預處理操作
假設有N個病人的某種疾病樣本,每個樣本有P個疾病指標,這些診斷指標很多,進行有效地降維操作,可以提高數據處理效率。進行主成分分析的步驟主要有:
(1)原始數據的標準化
現在有原始樣本矩陣 X=(Xij)n×P,i=1,2,…,n,表示 n 個病人樣本,j=1,2,…,P,表示每個樣本都有P個指標,Xij表示第i個病人的第j項指標值。
對原始數據進行標準化變換,使用Z-score法,變換公式如下:

其中,為病人樣本數據的均值,為病人樣本數據值得方差,i=1,2,…,n;j=1,2,…,p。
(2)指標數據的相關矩陣
計算主成分要從相關矩陣出發,有時候數據較多,如果各個指標的物理量綱不同,較為合理的方法就是計算相關矩陣。相關矩陣的計算公式如下:
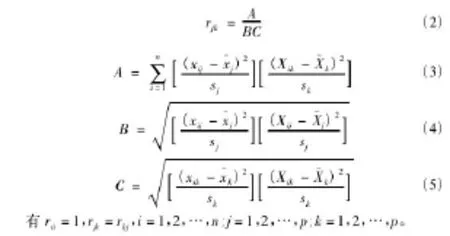
(3)根據相關矩陣提取主成分
由特征方程式 λIp-R =0,可知p個特征值。而且將這p個特征值按照從大到小的順序排列,λ1≥λ2≥λ3≥…≥λp,每一個特征值λi對應一個特征向量ti(i=1,2,…,p)。
在此,可以用標準化過的變量表示主成分,
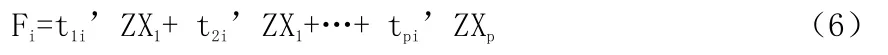
這里F1,F2,FP分別就是第一主成分、第二主成分、第p個主成分。
主成分的主要目的就是變量的降維以及對主成分的解釋。對高維的變量空間降維,即研究指標體系的少數幾個線性組合,并且這幾個線性組合將盡可能多的保留原來指標變量方面的信息。
一般情況下,我們提取k個主成分(k<p),提取的主成分個數k由方差貢獻率來確定,一般認為,方差累計貢獻率來確定。
(4)主成分回歸
在建立回歸分析模型時,如果自變量之間存在多重線性問題,將會使得回歸模型非常不理想,有時會使得明顯存在線性關系的兩個變量之間模型計算出來沒有關系。利用主成分的互不相關性來建立因變量與主成分的回歸,在理論上可以消除自變量的多重共線性問題。
設Y是一個隨機變量(因變量),X=(X1,X2,…,Xp)’為一個p維的解釋變量。
由以上問題已經求得主成分,建立因變量與主成分之間的回歸模型:

最終將公式(6)帶入公式(7)得到因變量Y與自變量X之間的回歸模型。
(二)利用SVM對病人數據樣本進行準確預測
SVM算法最初是由Vapnik等人在1995年提出的一種可訓練的機器學習算法。依據統計學習理論、VC維理論和結構風險最小化理論,從一定數目的樣本信息在學習能力和復雜度中找到折忠,以期獲得最好的推廣能力[6]。
SVM算法的基本步驟:
(1)數據集的準備:把原始數據集分為訓練集和測試集以及訓練集標簽和測試集標簽。
(2)選擇適當的核函數:常用的核函數主要有:線性分類器、多項式核函數以及徑向基核函數。
(3)帶入訓練集樣本得到SVM模型分類器。
(4)訓練得到較好的分類模型,然后對PCA處理過的數據集進行挖掘分析。
(5)將患者的一些疾病指標樣本輸入SVM,最終得到疾病的預測結果。
面對海量的醫療數據,有時維數較高,處理起來會十分不便,有些數據特征并不能對數據挖掘的結果起到積極的作用。PCA可以很好地對數據進行降維,去除那些對數據挖掘不重要的數據特征,有利于數據挖掘工作,提高了數據挖掘的質量和效率。SVM根據預處理后的訓練樣本訓練得到數據挖掘模型,通過調節參數得到最優的算法模型。綜合運用PCA和SVM可以對醫院的患者信息進行篩選及預測,這樣就可以讓醫院在解決醫患糾紛的博弈中占據信息的優勢。
二、不完全信息醫患演化博弈模型構建與求解
(一)模型假設
(1)博弈方:假設博弈的一方為智能推薦系統推薦的醫院,而另一方為患者。
(2)策略:推薦系統推薦的醫院可以提供高質量的服務,也可以提供低質量的服務,醫院的的戰略空間為{提供高質量的服務,提供低質量的服務};
患者對于推薦的醫院的服務可以選擇就診也可以選擇替代,所以患者的戰略空間{就醫,替代},所謂的替代并不是患者有病不去治療,而是患者沒有選擇智能系統推薦的醫院進行就診,選擇了其他的醫院進行就診。
(3)收益矩陣
信息不對稱情況下,患者對智能醫療推薦系統的醫院并不了解,醫院可以選擇提供高質量的服務也可以選擇提供低質量的服務;提供高質量的服務的醫院是指,醫療設備齊全、先進,專家技能高超,服務范圍全面的一些中心醫院、地市級醫院;而提供低質量的服務的醫院是指那些醫療設備不齊全,專家人數少,醫護服務差,提供的服務范圍窄的社區醫院。假設醫院提供高質量的服務的概率是y(0<y<1)。當醫院提供高質量的服務時,收益為π1,政府給予的資金支持為H1,醫院的運營成本為C1;當醫院提供低質量的服務時,收益為π2(π1>π2),政府給予的資金支持為 H2(H1>H2),醫院的運營成本為 C2(C1>C2)。
假設患者接受智能醫療推薦醫院的概率為x(0<x<1),患者接受智能醫療推薦醫院的服務進行就診時,付出的醫療費用為F,醫保報銷比例為P(0<P<1),所以患者實際支付的醫藥費用為F(1-P),當患者接受醫院提供的高質量服務就診時獲得的效用為V1,由于患者接受了高質量的服務時就相當于接受了專家的治療,不僅消除了心理上對醫療水平的質疑,而且患者得到了及時的治療,增強了患者對醫院的滿意程度,所以V1>F(1-P);當患者接受醫院提供的低質量的服務就診時獲得的效用為V2,由于患者接受低質量的服務時,不僅看不好病,拖延時間,而且使得患者對醫院的評價降低,患者會采取投訴的策略,這時,患者投訴成本為C3,投訴導致醫院的損失為L;假設患者不接受醫院的服務時用其他形式代替的效用為0。
根據以上假設,可以得到醫患雙方的收益矩陣,如表1所示:
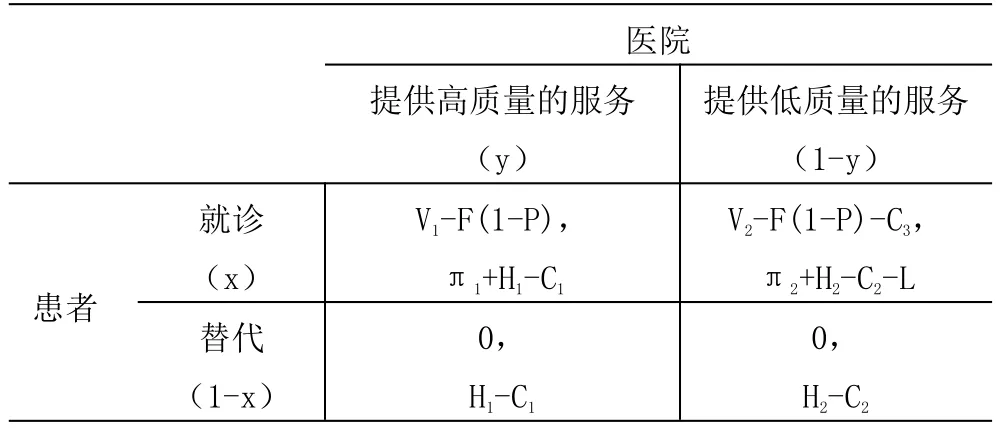
表1 醫患雙方的支付矩陣
(二)模型求解
(1)患者演化穩定策略分析
根據上述醫患博弈模型,U11、U12、U1分別表示患者接受醫院提供的服務就診時獲得的效用、患者不接受醫院提供的服務時用其他的形式代替的效用以及平均效用。
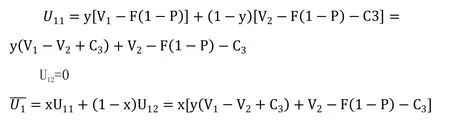
患者的復制動態方程為:

令解得x1*=0,x2*=1,
根據微分方程的穩定性定理,演化穩定策略可以表述為,在穩定狀態下,滿足
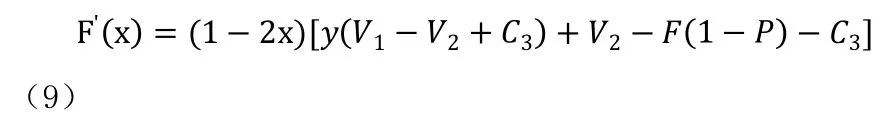
由公式(8)、(9)分析患者博弈的演化穩定策略如下:
當y=y*,恒等于0,則對于所有的x都是穩定狀態。
當y≠y*,時,x1*=0,x2*=1都是x的兩個穩定狀態點,需要分情況討論:
情況1:若則y*<0,y > y*成立,
所以x2*=1是穩定平衡點。
情況2:若分兩種情況討論:
(Ⅰ)y < y*時,所以x2*=1是穩定平衡點;
(Ⅱ)y < y*時,所以x1*=0是穩定平衡點。
上述幾種情況的x的變化的相位圖和穩定趨勢如下圖1所示:
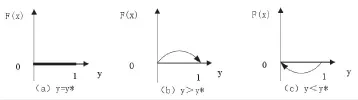
圖1 患者策略的復制動態相位圖
(2)醫院演化穩定策略分析
同理,醫院提供高質量的服務時的效用U21、提供低質量的服務的效用為U22、平均效用為U2,表達式如下:
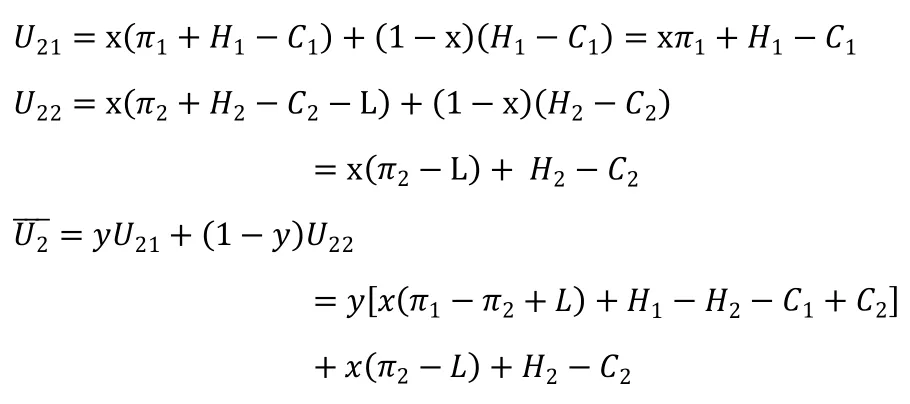
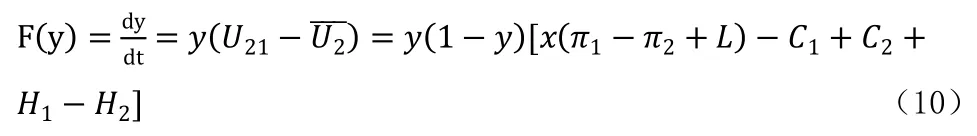
令解得y1*=0,y2*=1,
根據微分方程的穩定性定理,演化穩定策略可以表述為,在穩定狀態下,滿足
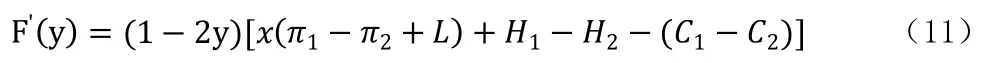
由公式(10)、(11)分析醫院博弈的演化穩定策略如下:
當x=x*,恒等于0,則對于所有的y都是穩定狀態。
當x>x*,y*=1是ESS均衡點。
當x<x*,y*=0是ESS均衡點。
上述3種情況的y的變化的相位圖和穩定趨勢如下圖2示:
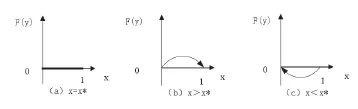
圖2 醫院策略的復制動態相位圖
(3)策略動態演化趨勢分析
情況1:當x*<0時,即C1-C2<H1-H2,政府給予醫院的資金支持增加額能夠彌補醫院的運營成本增加額,此時,最優均衡為(1,1),也就是說醫院提供高質量的服務的策略,患者選擇就診策略。
情況2:當0<x*<1時,即C1-C2>H1-H2,且此時,政府給予醫院的資金支持增加額已不足以彌補醫院的運營成本增加額,但是醫院提供高質量的服務所獲得的的收益增加額使得醫院能夠獲得一定的利潤。均衡點是(0,0)和(1,1)也就是醫院采取提供低質量的服務策略,患者選擇替代的策略;醫院選擇提供高質量的服務的策略,患者選擇就診策略。
情況3: 當x*>1,即C1-C2>H1-H2,且時,政府給予醫院的資金支持增加額已不足以彌補醫院的運營成本增加額,并且醫院提供高質量的服務所獲得的的收益增加額不能使醫院能夠獲得一定的利潤。此時,均衡點為(0,0)也就是說醫院選擇提供低質量的服務策略,患者相應的選擇替代策略。
三、結論及建議
本文先采用PCA-SVM對患者的病情進行預測,推薦相關的醫院給患者,然后再用演化博弈理論對醫患關系進行分析,為了引導醫院提供高質量的服務,患者及時的進行就診,提出了如下建議:
(1)在醫療智能推薦系統使用過程中,政府應該根據醫院提供的質量服務所帶來的利潤的增加額來適當調整對醫院提供高質量的服務的資金支持力度。
(2)政府部門應當鼓勵醫院提供高質量的服務,加大對醫院的資金支持,增加患者醫療報銷比例,使患者看得起病、能放心看病。
(3)為了合理的配備醫療資源,讓患者有病及時就診,政府部門應該盡快落實分級診療制度,加強基層醫療衛生人才隊伍建設;大力提高基層醫療衛生服務能力;全面提升縣級公立醫院綜合能力;整合推進區域醫療資源共享;加快推進醫療衛生信息化建設,加強醫患信息交流以緩解信息不對稱的情況。
[1]戴炳榮,王曉麗等.一種基于PCA-SVM的醫療衛生數據挖掘分類方法[J].計算機應用與軟件,2016,33(8):67-69.
[2]王勇等.再論醫患關系博弈模型[J].重慶大學學報,2006,29(6):135-139.
[3]朱效永.信息不對稱下的我國醫患關系博弈模型分析[D].對外經貿,2011,210(12):129-130.
[4]田宇馳,胡亮.基于SVM的一種醫療數據分析模型.東北師大學報,2015,47(1):77-81.
[5]Bichen Zheng,Sang Won Yoon.Breast cancer diagnosis based on feature extraction using a hybrid of K-means and support vector mechine algorithms.Expert System with Applications,41(2014):1476-1482.
[6]魏振.基于GPU的SVM算法在入侵檢測系統中的應用[D].長春:吉林大學,2013.
[7]弓憲文.信息不對稱下醫患關系博弈分析.重慶大學學報.2004,27(4):126-129.
[8張炎亮等.基于演化博弈的遠程醫療服務推廣策略分析.科技管理研究.16(2017):224-228.
[9]申笑顏.基于演化博弈的醫療服務費用控制監管分析[J].數理醫藥學雜志.2012,25(2):244-246.
[10]汪祥松等.遠程醫療背景下社區醫院和患者行為選擇的演化分析.2015,20(2):130-137.
猜你喜歡
當代陜西(2022年5期)2022-04-19 12:10:12
當代陜西(2021年1期)2021-02-01 07:18:02
當代陜西(2020年20期)2020-11-27 01:43:10
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
福建基礎教育研究(2019年3期)2019-05-28 23:47:21
兒童繪本(2018年10期)2018-07-04 16:39:12
數學大世界(2018年1期)2018-04-12 05:39:14
小朋友·快樂手工(2016年5期)2016-05-14 17:18:34
中國衛生(2015年8期)2015-11-12 13:15:20
