基于特征參數向量關聯規則挖掘的雷達輻射源識別
2018-06-19 08:06:10唐文杰程遠國
艦船電子對抗 2018年2期
唐文杰,程遠國
(海軍工程大學,湖北 武漢 430032)
0 引 言
雷達輻射源識別是電子對抗領域的關鍵技術之一,其目的在于根據截獲的雷達輻射源信號,得到能夠描述輻射源的特征參數,從而獲取該雷達輻射源的體制、用途和型號等信息。傳統的識別方法是根據載頻(CF)、脈沖寬度(PW)、脈沖幅度(PA)、到達時間(TOA)、到達角(AOA)等構成的脈沖描述字(PDW)對輻射源進行識別[1]。隨著技術的發展,復雜體制雷達的應用越來越廣泛。由于復雜體制雷達工作模式較多,信號參數變化大,PDW不能很好地描述雷達輻射源信息。研究人員轉而向雷達輻射源脈內特征進行挖掘[2-3]。例如文獻[4]根據模糊函數(AF)主脊切片特征對不同輻射源進行唯一表示,然后通過奇異值分解降噪,實現了輻射源的識別。文獻[5]將屬性測度與D-S證據理論相結合,并通過屬性測度計算方法構造證據理論中的基本概率賦值函數,實現了雷達輻射源的用途和體制識別。
除此之外,當前信號環境越來越復雜,偵察數據庫逐漸龐大,但其中數據價值參差不齊,其中不乏存在潛在價值的信息,對這些潛在價值的挖掘勢在必行。頻繁模式挖掘是指通過Apriori等算法對數據庫中頻繁出現且具有突出性質的模式(如項集、序列等)進行挖掘,從而獲取有價值的信息[6-7]。在輻射源識別領域,不管信號樣式、參數如何多變,但目標平臺所搭載的輻射源種類、數量是固定的,各信號間必然存在強關聯規則。對這些關聯規則的挖掘能夠為輻射源識別提供支持。本文以偵察數據庫中信號的幾項常規參數為基礎構建特征向量,通過Apriori算法對特征向量庫進行處理,從而實現了基于特征參數向量的頻繁模式挖掘。結合其他來源的數據信息,可生成信號與信號之間以及與輻射源之間的關聯規則。將偵獲信號與關聯規則相匹配,可為輻射源的識別提供依據。模擬數據的仿真實驗表明,該方法具有一定的可行性和有效性。
1 數據模型及關聯規則挖掘算法
1.1 數據模型
將偵察數據庫中各信號的參數進行整合處理,由于載頻、脈寬、脈幅和脈沖重復間隔(PRI)能夠較為明顯地反映雷達用途,而且參數獲取較容易,故采用CF、PW、PA、PRI 4個參數組成特征向量Si:
Si={Fci,Wpi,Api,fPRIi}
(1)
式中:腳標i為序列號,即每一組參數構成一個特征向量。
根據復雜體制雷達的實際情況,即每種工作模式對應多種不同的信號,構建輻射源信號組成模型:
Rk={Sk1,Sk2,…,Skj},1≤k≤m,1≤j≤n
(2)
式中:k為輻射源編號;m為輻射源數量;j為輻射源所包含信號編號;n為信號數量。
1.2 關聯規則挖掘算法
本文使用經典的Apriori算法進行關聯規則挖掘。Apriori算法是Agrawal和R.Srikant于1994年提出的,是布爾關聯規則挖掘頻繁模式的原創性算法。該算法使用逐層搜索的迭代方法從數據庫中找出項目的關系。使用k項集用于搜索(k+1)項集(其中k=1,2,…),循環迭代至無法生成更高的頻繁k項集為止。
對特征參數向量關聯規則挖掘的具體步驟如下:
(1) 根據實際情況,設置好最小支持度(min_sup)和最小置信度(min_conf),支持度-置信度框架是評價關聯規則是否有價值的標準。掃描偵察數據庫,第1次迭代,數據庫中的每個項都是候選1-項集的集合C1的成員,即所有信號特征參數向量均存入候選1-項集C1。算法記錄每個項出現的次數,即每個項的支持度,大于min_sup的項組成頻繁1-項集L1。
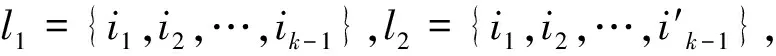
(3) 剪枝步:根據性質“任何非頻繁的(k-1)項集都不是頻繁k項集的子集”對候選頻繁k項集Ck進行修剪。即如果1個候選k項集的(k-1)項子集不在Lk-1中,則該候選也不可能是頻繁的,從而應在Ck中刪除。
(4) 掃描數據庫,記錄Ck中各項集的頻度,即支持度。支持度大于min_sup的項集組成頻繁k項集Lk。循環運行(2)、(3)至無法生成更高的頻繁k項集時,輸出產生的頻繁項集∪Lk。
(5) 由頻繁項集產生關聯規則。對每一個頻繁項集L產生其所有非空真子集,對于每個真子集s,當滿足式(3)時,輸出規則“s→(L-s)”,并給出置信度。
(3)
式中:count()表示包含對應項集的事務數。
算法偽代碼略。
2 示例分析
2.1 偵察數據庫模擬
為便于進行示例分析且盡可能模擬實際情況,式(2)中m取值為3,n分別取值2,3,4,即共有3部雷達輻射源,分別擁有2,3,4種工作信號。而在偵察數據庫中,由于信號所屬雷達未知,故采用Sx(x=1,2,…,9)表示。表1為模擬偵察數據庫,其中事物T代表以實時態勢為依據劃分的不同時間段。信號種類模擬以雷達工作情況和潛在邏輯關系為依據。
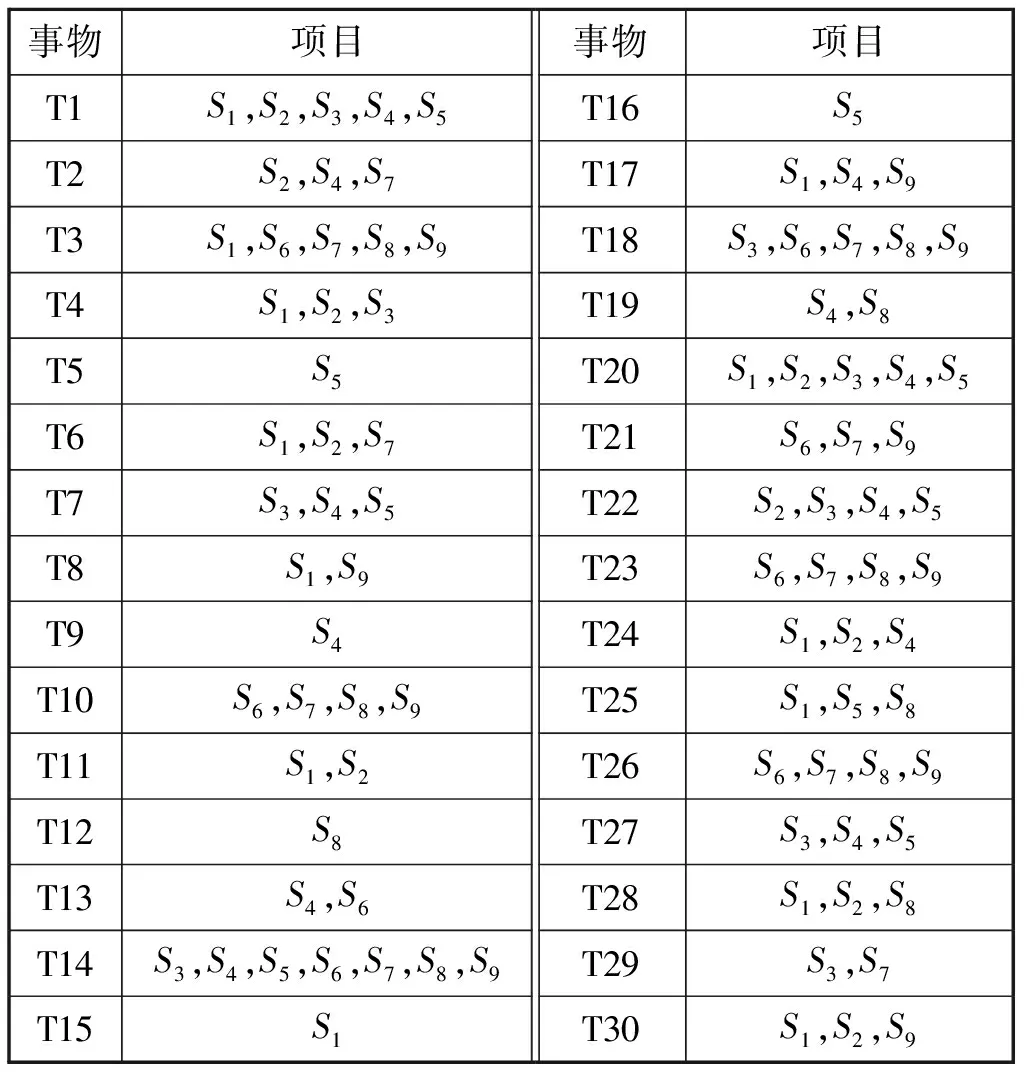
表1 偵察數據庫
以時間段作為事務,特征向量作為項集,運用Apriori算法進行頻繁模式挖掘,根據所得頻繁項集L和其他來源的輻射源信息可生成所需的信號與輻射源之間的關聯規則。
2.2 示例數據處理結果及分析
根據模擬的偵察數據庫,設置最小支持度為20%,最小置信度為80%,運行Apriori算法可產生不同項目數的頻繁項集。由于頻繁1-項集參考價值較低,這里不做論述。表2、表3、表4分別為所得頻繁2-項集、3-項集、4-項集以及其對應的支持度。
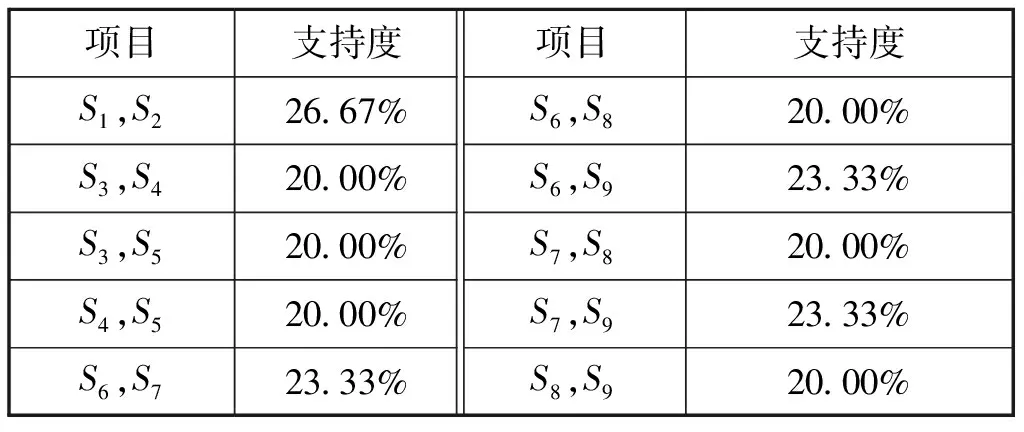
表2 頻繁2-項集及支持度
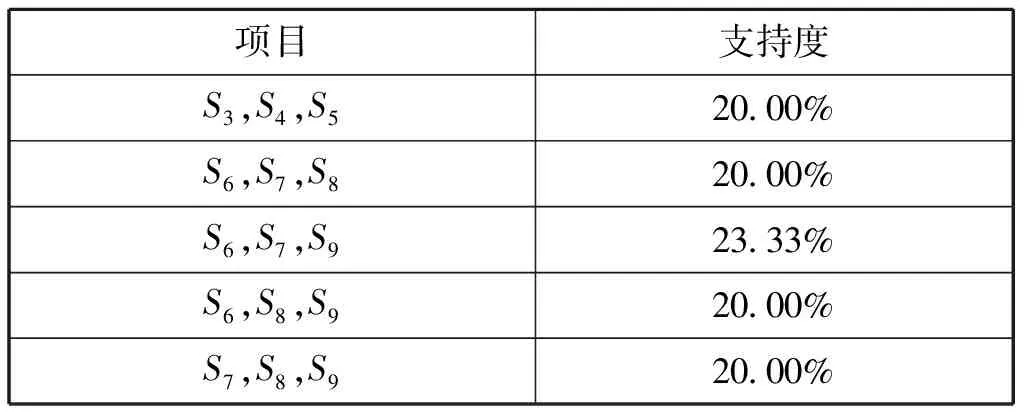
表3 頻繁3-項集及支持度

表4 頻繁4-項集及支持度
分析上述3個表格的數據結果,可以看出,S1和S2,S3、S4和S5,S6、S7、S8和S9具有一定的布爾規則關聯性,結合數據庫中的方位信息以及其他來源的數據信息,在一定的支持度-置信度水平下,可認為這3組信號分別來自于3個不同輻射源,即滿足如下規則:
R1={S1,S2}support=26.67%
(4)
R2={S3,S4,S5}support=20.00%
(5)
R3={S6,S7,S8,S9}support=20.00%
(6)
在最小置信度80.00%的水平下,算法共生成29條關聯規則。表5所列為包含4項的關聯規則。
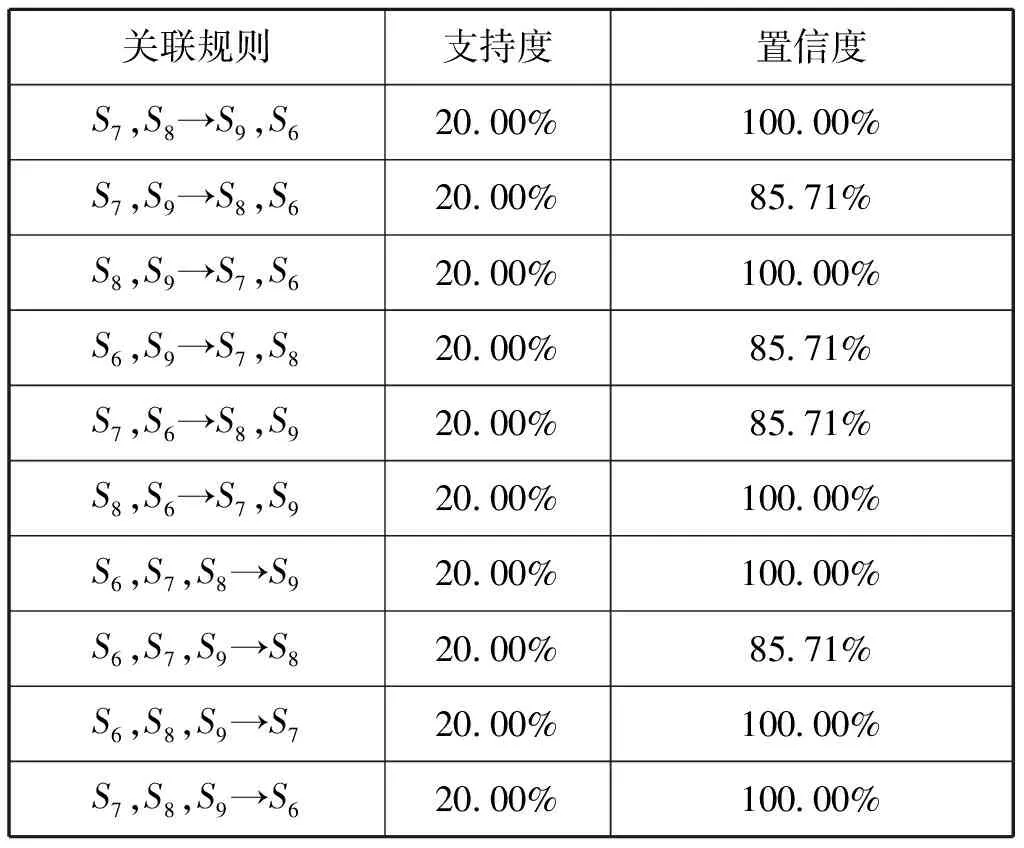
表5 產生的4-項關聯規則
以“S6,S7,S9→S8”為例,表示當S6,S7,S9信號存在的情況下,置信度為85.71%的水平下可認為會有S8信號存在。結合信號特征分析,這能夠為輻射源可能進行的行為預測提供支持。
3 結束語
本文提到的通過關聯規則識別輻射源能夠進一步挖掘現有信息數據庫的潛在價值,是對海量數據信息有效處理運用的體現。首先整合偵察數據庫中信號的參數信息,形成特征向量。然后對特征向量運用Apriori算法進行關聯規則挖掘。將信號間的布爾關聯規則同其他來源的雷達輻射源信息進行匹配并建立關聯規則數據庫,可為偵獲信號的雷達輻射源識別提供支持。但是算法對設備運算能力和存
儲能力要求較高,進行工程實現還需要進一步提高算法的時間-空間效率。另一方面,通過聚類等其他方式對數據進行預處理也是必要的,對壓縮后的數據進行挖掘能夠更快速有效地獲得關聯規則。
[1] WILEY R G.Electronic Intelligence:The Analysis of Radar Signals[M].New York:Artech House,1993:36-37.
[2] 周志文,黃高明,陳海洋,等.雷達輻射源識別算法綜述[J].電訊技術,2017,57(8):973-980.
[3] 沈家煌,黃建沖,朱永成.雷達輻射源信號快速識別綜述[J].電子信息對抗技術,2017,32(5):5-10.
[4] GUO Q,NAN P L,ZHANG X Y,et al.Recognition of radar emitter signals based on SVD and AF main ridge slice[J].Journal of Communications and Networks,2015,17(5):491-498.
[5] 何友,關欣,衣曉.基于屬性測度的輻射源識別方法研究[J].中國科學E輯:信息科學,2004,34(12):1329-1336.
[6] HAN J,KAMBER M,PEI J.數據挖掘:概念與技術[M].3版.范明,孟小峰譯.北京:機械工業出版社,2017.
[7] 張一梅.基于數組的關聯規則挖掘算法的改進研究[D].太原:太原理工大學,2008.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
財經(2017年2期)2017-03-10 14:35:35
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
