基于OLAP和聚類(lèi)分析的關(guān)聯(lián)規(guī)則挖掘方法
2018-05-22 07:35:44熊中敏朱春衛(wèi)郭振輝
計(jì)算機(jī)應(yīng)用與軟件 2018年5期
熊中敏 朱春衛(wèi) 郭振輝 陳 明
1(上海海洋大學(xué)信息學(xué)院 上海201306) 2(農(nóng)業(yè)部漁業(yè)信息重點(diǎn)實(shí)驗(yàn)室 上海 201306) 3(上海電子信息職業(yè)技術(shù)學(xué)院 上海 201411)
0 引 言
數(shù)據(jù)挖掘就是利用各種數(shù)理模型從數(shù)據(jù)庫(kù)中的海量數(shù)據(jù)中抽取隱藏的某種規(guī)律的一系列過(guò)程[1]。關(guān)聯(lián)規(guī)則挖掘能將數(shù)據(jù)庫(kù)中項(xiàng)與項(xiàng)之間的潛在關(guān)系挖掘出來(lái),比如利用超市的購(gòu)物單發(fā)現(xiàn)了購(gòu)買(mǎi)啤酒和尿布的強(qiáng)規(guī)則[2]。最經(jīng)典的關(guān)聯(lián)規(guī)則算法是 Apriori 算法[3],但它需要反復(fù)掃描事務(wù)數(shù)據(jù)庫(kù)并產(chǎn)生大量候選集,占用內(nèi)存大、運(yùn)行效率低。以下出現(xiàn)的是一些當(dāng)前關(guān)聯(lián)規(guī)則挖掘急需解決的挑戰(zhàn)性問(wèn)題[4]:
(1) 面臨當(dāng)前海量信息,提高關(guān)聯(lián)規(guī)則挖掘算法的效率常常又會(huì)導(dǎo)致降低了挖掘結(jié)果的可行性、新奇性。
(2) 在挖掘的過(guò)程中,大型數(shù)據(jù)庫(kù)挖掘出的規(guī)則集過(guò)大,導(dǎo)致用戶難以理解、難以選擇。
(3) 關(guān)聯(lián)規(guī)則算法中融合其他算法、解決單純的關(guān)聯(lián)規(guī)則算法無(wú)法解決的應(yīng)用問(wèn)題。好多挖掘方法看似和關(guān)聯(lián)規(guī)則算法沒(méi)有交集,若有機(jī)地融入算法中可揚(yáng)長(zhǎng)避短。
通過(guò)數(shù)據(jù)倉(cāng)庫(kù)的OLAP操作:切片、切塊、旋轉(zhuǎn)、上卷和下鉆,用戶既可以快速地察覺(jué)到宏觀變化,又可以從細(xì)節(jié)上觀察變化的詳細(xì)因素。聚類(lèi)是用戶用以觀察某一類(lèi)具有共同特性的數(shù)據(jù)集的利器。現(xiàn)有的關(guān)聯(lián)規(guī)則挖掘若結(jié)合OLAP和聚類(lèi)分析,用戶可以有預(yù)見(jiàn)性地選取有分析意愿的數(shù)據(jù)集,挖掘結(jié)果更符合用戶的分析意愿,使得挖掘出的關(guān)聯(lián)規(guī)則的數(shù)量大為減少、而用戶的滿意度卻大大增加。本文的研究工作將部分地解決上述關(guān)聯(lián)規(guī)則挖掘研究中的挑戰(zhàn)問(wèn)題,從而為數(shù)據(jù)倉(cāng)庫(kù)和數(shù)據(jù)挖掘技術(shù)的應(yīng)用普及做出貢獻(xiàn)。
1 相關(guān)知識(shí)
1.1 OLAP分析
用戶的決策分析在關(guān)系數(shù)據(jù)庫(kù)上需要經(jīng)過(guò)大量的計(jì)算,顯然簡(jiǎn)單的查詢的結(jié)果難以滿足這種決策需求。因此,E.F.Codd于1993年提出了OLAP的概念(即多維數(shù)據(jù)庫(kù)和多維分析)。
定義1[5]OLAP(聯(lián)機(jī)分析處理)是聯(lián)機(jī)查詢和分析某個(gè)具體的主題的數(shù)據(jù),從多維度、不同綜合層次上直觀地將數(shù)據(jù)狀態(tài)展示給使用者。
OLAP分析主要利用以下5種操作[5]:切片、切塊、聚合、鉆取、旋轉(zhuǎn)。將多維數(shù)據(jù)集上某個(gè)維度固定為一個(gè)維度成員區(qū)間(例如取“2000年至2014年”),就得到一個(gè)切塊。維度的層次結(jié)構(gòu)代表了數(shù)據(jù)的綜合程度,如地區(qū)維度可能由地區(qū)、省、市、區(qū)構(gòu)成。綜合程度越低則細(xì)節(jié)級(jí)別越高,粒度越小,數(shù)據(jù)量越大。在某個(gè)維度上將綜合層次低的數(shù)據(jù)匯總到高層次數(shù)據(jù)是上卷操作。反之為下卷操作。這兩種瀏覽數(shù)據(jù)的方式,提供給用戶宏觀和微觀角度觀察數(shù)據(jù)。旋轉(zhuǎn)既可交換行和列上的維度,也可以交換維度的不同層次,從而得到用戶習(xí)慣的數(shù)據(jù)展示形式。
OLAP是數(shù)據(jù)分析過(guò)程中的重要工具,它使數(shù)據(jù)分析能夠在數(shù)據(jù)立方體上以用戶習(xí)慣的視角迅速、一致、交互地瀏覽數(shù)據(jù),以便用戶能深入理解數(shù)據(jù)。
1.2 聚類(lèi)分析
與傳統(tǒng)統(tǒng)計(jì)分析及OLAP不同,數(shù)據(jù)挖掘采用計(jì)算機(jī)自動(dòng)處理算法在數(shù)據(jù)集上進(jìn)行自動(dòng)挖掘,從而找到潛在、有用的知識(shí)。將個(gè)體之間的相似性作為“距離”的測(cè)度,使得相互間距離比較小歸為一類(lèi)而不同類(lèi)的個(gè)體間距離比較大,俗稱(chēng)聚類(lèi)。聚類(lèi)反映的不僅有不同事物之間的差異性而且還有同類(lèi)事物的共同性。數(shù)據(jù)集通過(guò)聚類(lèi)被劃分為一系列子類(lèi),從而細(xì)化了人們的客觀認(rèn)識(shí),可以區(qū)分概念和偏差。當(dāng)前常見(jiàn)的聚類(lèi)算法有:劃分法[6]、層次法[7]、密度法[8]、網(wǎng)格法[9]和模型法[10]。
K-means算法[11]是比較典型的劃分法聚類(lèi)算法,每個(gè)數(shù)據(jù)點(diǎn)唯一地分配給一個(gè)且僅一個(gè)聚類(lèi),而且需要預(yù)先指定需要?jiǎng)澐志垲?lèi)的個(gè)數(shù),但方法簡(jiǎn)單、較容易實(shí)現(xiàn)。本文將采用它作為聚類(lèi)方法。K-means算法流程如下所示:
1) 選定數(shù)據(jù)空間中K個(gè)對(duì)象作為初始聚類(lèi)中心,每個(gè)對(duì)象代表一個(gè)類(lèi)別的中心。
2) 對(duì)于樣品中的數(shù)據(jù)對(duì)象,則根據(jù)它們與這些聚類(lèi)中心的歐氏距離,按距離最近的準(zhǔn)則分別將它們分配給與其最相似的聚類(lèi)中心所代表的類(lèi)。
3) 計(jì)算每個(gè)類(lèi)別中所有對(duì)象的均值作為該類(lèi)別的新聚類(lèi)中心,計(jì)算所有樣本到其所在類(lèi)別聚類(lèi)中心的距離平方和,即J(C)值。
4) 聚類(lèi)中心和J(C)值是否發(fā)生改變,若是則轉(zhuǎn)2),否則聚類(lèi)結(jié)束。
1.3 關(guān)聯(lián)規(guī)則
關(guān)聯(lián)分析的目的就是為了發(fā)現(xiàn)數(shù)據(jù)間發(fā)生一定關(guān)聯(lián)關(guān)系的規(guī)律,通常采用以下形式:(X?Y,支持度=s,置信度=c)。這里X稱(chēng)為規(guī)則的前件,Y稱(chēng)為規(guī)則的后件,支持度s是包含X的項(xiàng)在全體項(xiàng)集中出現(xiàn)的頻率,置信度c是X和Y同時(shí)出現(xiàn)的項(xiàng)在出現(xiàn)有X的項(xiàng)集中所占比例。
Apriori算法是最知名的關(guān)聯(lián)規(guī)則發(fā)現(xiàn)方法。大于最小支持度的項(xiàng)集稱(chēng)為頻繁項(xiàng)集,利用了頻繁集,Apriori算法分為兩個(gè)步驟[5]:
第一步:利用大于最小支持度和“Apriori性質(zhì)”找到所有頻繁項(xiàng)集;第二步:利用大于最小置信度將第一步找到的頻繁項(xiàng)集轉(zhuǎn)換為關(guān)聯(lián)規(guī)則。
算法使用迭代方法,利用“頻繁項(xiàng)集的所有非空子集都必須是頻繁的” Apriori性質(zhì)由“K-項(xiàng)集”產(chǎn)生“K+1-項(xiàng)集”,如此下去,直到找不到后繼的頻繁項(xiàng)集為止。
2 綜合OLAP和聚類(lèi)分析的關(guān)聯(lián)規(guī)則挖掘
2.1 OLAP分析對(duì)關(guān)聯(lián)規(guī)則挖掘的影響
首先我們以一個(gè)簡(jiǎn)單的例子來(lái)說(shuō)明數(shù)據(jù)集的選擇對(duì)關(guān)聯(lián)規(guī)則挖掘出的結(jié)果的影響。
例1假定在一個(gè)零售商品的數(shù)據(jù)庫(kù)中包含兩個(gè)商場(chǎng)A和B的購(gòu)物交易數(shù)據(jù),如表1所示。
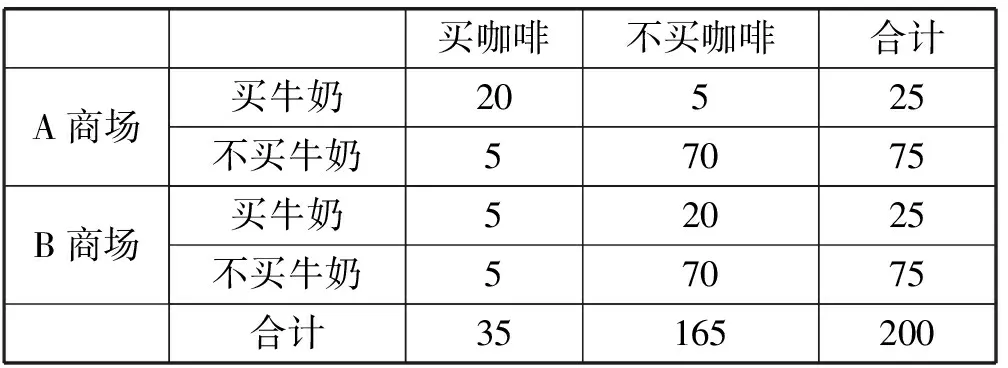
表1 交易集的分析
下面分別討論表1中事務(wù)集對(duì)關(guān)聯(lián)規(guī)則的支持度和置信度的影響。
1) 由表1可以了解到,如果設(shè)定minsupp=0.2,minconf=0.6,整個(gè)200個(gè)交易記錄構(gòu)成的事務(wù)集按照現(xiàn)有挖掘算法就可以得到如下關(guān)聯(lián)規(guī)則:
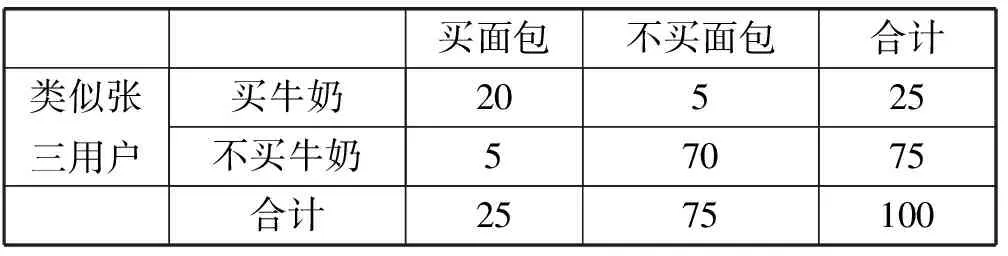
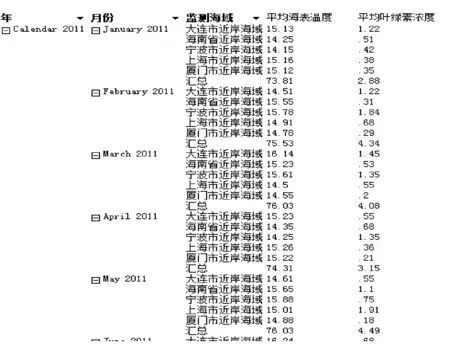
買(mǎi)牛奶→買(mǎi)咖啡s=25/200=0.125 故在整個(gè)交易記錄上上述規(guī)則因?yàn)椴粷M足設(shè)定的最小支持度在計(jì)算頻繁項(xiàng)集的時(shí)候就被舍棄。 2) 當(dāng)我們?cè)O(shè)定的最小支持度的閾值可以滿足,即可以有效通過(guò)頻繁項(xiàng)集的計(jì)算,該規(guī)則仍然可能因?yàn)樽钚≈眯哦炔粷M足導(dǎo)致被舍棄。 例如,在這個(gè)例子中如果我們?cè)O(shè)定minsupp=0.12,minconf=0.60,整個(gè)200個(gè)交易記錄構(gòu)成的事務(wù)集按照現(xiàn)有挖掘算法就可以得到如下關(guān)聯(lián)規(guī)則: 買(mǎi)牛奶→買(mǎi)咖啡s=25/200=0.125>minsupp 即在關(guān)聯(lián)規(guī)則挖掘算法Apriori的第一步的頻繁項(xiàng)集的計(jì)算當(dāng)中,該規(guī)則有效地包含在頻繁項(xiàng)集中。但在第二步生成關(guān)聯(lián)規(guī)則的時(shí)候,需要計(jì)算置信度: 買(mǎi)牛奶→買(mǎi)咖啡c=25/50=0.50 故在整個(gè)交易記錄上上述規(guī)則因?yàn)椴粷M足設(shè)定的最小置信度在算法第2步生成關(guān)聯(lián)規(guī)則的時(shí)候被舍棄。 3) 如果構(gòu)造了一個(gè)商品銷(xiāo)售分析的數(shù)據(jù)倉(cāng)庫(kù)的多維數(shù)據(jù)模型。比如在事實(shí)表中含度量值:銷(xiāo)售金額和銷(xiāo)售數(shù)量,將商場(chǎng)作為一個(gè)分析的維度,則在OLAP操作中既可通過(guò)上卷(也稱(chēng)之為上鉆)看到整個(gè)交易集(包含了A、B兩個(gè)商場(chǎng))中買(mǎi)咖啡的總數(shù)量為35,買(mǎi)牛奶的數(shù)量為50。同時(shí)也能通過(guò)下鉆操作分別看到A商場(chǎng)和B商場(chǎng)買(mǎi)咖啡的數(shù)量分別為25和10;買(mǎi)牛奶的數(shù)量分別為25和25。很明顯買(mǎi)咖啡的數(shù)量集中在A商場(chǎng)。如果管理者有意識(shí)地需要得到咖啡銷(xiāo)售情況的關(guān)聯(lián)規(guī)則分析,只需要關(guān)注A商場(chǎng)的銷(xiāo)售情況。即如果現(xiàn)在只是在表2所示事務(wù)集上做關(guān)聯(lián)規(guī)則分析,按照現(xiàn)有挖掘算法就可以得到如下關(guān)聯(lián)規(guī)則: 買(mǎi)牛奶→買(mǎi)咖啡s=20/100=0.2=minsupp c=20/25=0.8>minconf 表2 A商場(chǎng)交易集的分析 即設(shè)定minsupp=0.2,minconf=0.6,根據(jù)關(guān)聯(lián)規(guī)則挖掘算法能在面向商場(chǎng)A的數(shù)據(jù)分析上得到有效的關(guān)聯(lián)規(guī)則買(mǎi)牛奶→買(mǎi)咖啡。也就是這條關(guān)聯(lián)規(guī)則針對(duì)商場(chǎng)A有效,但對(duì)于整個(gè)交易記錄反而不成立。因?yàn)橘I(mǎi)咖啡的交易主要集中在商場(chǎng)A完成。 由此可見(jiàn)在數(shù)據(jù)倉(cāng)庫(kù)的多維數(shù)據(jù)集上的OLAP分析,我們能清晰地看出待挖掘的事務(wù)集中的項(xiàng)集在不同維度層次結(jié)構(gòu)上的分布的不同,而這種數(shù)據(jù)分布的傾向性極大地影響到關(guān)聯(lián)規(guī)則挖掘算法執(zhí)行時(shí)生成頻繁項(xiàng)集的支持度的計(jì)算和生成關(guān)聯(lián)規(guī)則過(guò)程中置信度的計(jì)算,并導(dǎo)致最終能否生成用戶關(guān)注的關(guān)聯(lián)規(guī)則集合。 2.2 聚類(lèi)分析對(duì)關(guān)聯(lián)規(guī)則挖掘的影響 基于多維數(shù)據(jù)集上直接的OLAP操作能輔助用戶對(duì)現(xiàn)有的多維數(shù)據(jù)集上的數(shù)據(jù)分布現(xiàn)狀的理解,形成用戶很清晰的數(shù)據(jù)分析對(duì)象的關(guān)注。 但上述數(shù)據(jù)理解方法仍然具有一定的局限性,從而妨礙了用戶需要的關(guān)聯(lián)規(guī)則的挖掘。這個(gè)問(wèn)題類(lèi)似如挖掘這樣的關(guān)聯(lián)規(guī)則:在上海浦東臨港地區(qū)農(nóng)工商超市現(xiàn)有不同類(lèi)別人群的購(gòu)物行為分析,或者是類(lèi)似于用戶張三的人群的購(gòu)物行為分析。很顯然,在數(shù)據(jù)倉(cāng)庫(kù)中沒(méi)有直接的這樣的購(gòu)物行為的事務(wù)集,因?yàn)檫@是關(guān)注于用戶的分析,而用戶是不確定的、動(dòng)態(tài)的,不像2.1節(jié)中有明顯的維度成員:商場(chǎng)類(lèi)別A和B。如果不能構(gòu)建滿足用戶意圖的事務(wù)集,而是在現(xiàn)有的數(shù)據(jù)倉(cāng)庫(kù)抽取到的整個(gè)事務(wù)集上做關(guān)聯(lián)規(guī)則數(shù)據(jù)挖掘,會(huì)很明顯出現(xiàn)和在2.1節(jié)中分析的結(jié)果一樣的問(wèn)題:針對(duì)特定數(shù)據(jù)分析對(duì)象的規(guī)則會(huì)因?yàn)橹С侄群椭眯哦炔粔蚨荒苡行У厣桑欢谝粋€(gè)大范圍內(nèi)產(chǎn)生的規(guī)則因?yàn)檫m用面太大而沒(méi)有針對(duì)性,也就是用戶真正想關(guān)注的關(guān)聯(lián)規(guī)則不能有效地生成。 下面講述如何實(shí)現(xiàn)本文中涉及到的基于個(gè)人信息的用戶聚類(lèi)分析,從而引證實(shí)現(xiàn)數(shù)據(jù)服務(wù)對(duì)象聚類(lèi)的可行性方法。因?yàn)閷?duì)用戶的聚類(lèi)需要用戶注冊(cè)的個(gè)人信息,而現(xiàn)在大的商場(chǎng)或商務(wù)網(wǎng)站都實(shí)行了會(huì)員制,所以用戶的個(gè)人信息數(shù)據(jù)可以很方便得到。同時(shí)還有網(wǎng)上購(gòu)物評(píng)價(jià)和相關(guān)論壇發(fā)帖,都能形成個(gè)人的信息,用于建立基于用戶個(gè)性特征和購(gòu)物興趣的數(shù)據(jù)來(lái)源,從而利用現(xiàn)有的劃分方法生成基于相似性度量的聚類(lèi)。本文采用最常用的K-means方法得到聚類(lèi)劃分,而對(duì)于購(gòu)物用戶的聚類(lèi)分析采用文獻(xiàn)[12]的技術(shù)方案,只要布置好數(shù)據(jù)利用SQL SERVER2008 R2中analysis service部件自帶的聚類(lèi)算法,選擇聚類(lèi)模型為K-means即可。 本文在此仍然以一個(gè)如表3所示的簡(jiǎn)單的例子來(lái)分析在應(yīng)用關(guān)聯(lián)規(guī)則挖掘時(shí)出現(xiàn)的上述問(wèn)題,并默認(rèn)本例中用戶已經(jīng)聚類(lèi)為兩類(lèi)。 表3 交易集的分析 下面分別討論表3中事務(wù)集對(duì)關(guān)聯(lián)規(guī)則的支持度和置信度的影響。 1) 由表3可以了解到如果設(shè)定minsupp=0.2,minconf=0.6,整個(gè)200個(gè)交易記錄構(gòu)成的事務(wù)集按照現(xiàn)有挖掘算法就可以得到如下關(guān)聯(lián)規(guī)則: 買(mǎi)牛奶→買(mǎi)面包s=25/200=0.125 故在整個(gè)交易記錄上上述規(guī)則因?yàn)椴粷M足設(shè)定的最小支持度在計(jì)算頻繁項(xiàng)集的時(shí)候就被舍棄。 2) 當(dāng)我們?cè)O(shè)定的最小支持度的閾值可以滿足,即可以有效通過(guò)頻繁項(xiàng)集的計(jì)算,該規(guī)則仍然可能因?yàn)樽钚≈眯哦炔粷M足導(dǎo)致被舍棄。 例如,在這個(gè)例子中如果我們?cè)O(shè)定minsupp=0.12,minconf=0.60,整個(gè)200個(gè)交易記錄構(gòu)成的事務(wù)集按照現(xiàn)有挖掘算法就可以得到如下關(guān)聯(lián)規(guī)則: 買(mǎi)牛奶→買(mǎi)面包s=25/200=0.125>minsupp 即在關(guān)聯(lián)規(guī)則挖掘算法Apriori的第一步的頻繁項(xiàng)集的計(jì)算當(dāng)中,該規(guī)則有效地包含在頻繁項(xiàng)集中。但在第二步生成關(guān)聯(lián)規(guī)則的時(shí)候,需要計(jì)算置信度: 買(mǎi)牛奶→買(mǎi)面包c(diǎn)=25/50=0.50 故在整個(gè)交易記錄上上述規(guī)則因?yàn)椴粷M足設(shè)定的最小置信度在算法第2步生成關(guān)聯(lián)規(guī)則的時(shí)候被舍棄。 3) 如果構(gòu)造了一個(gè)商品銷(xiāo)售分析的數(shù)據(jù)倉(cāng)庫(kù)的多維數(shù)據(jù)模型,比如在事實(shí)表中含度量值:銷(xiāo)售數(shù)量,將用戶作為一個(gè)分析的維度。為了挖掘這樣的關(guān)聯(lián)規(guī)則:類(lèi)似于用戶張三的人群的購(gòu)物行為分析,需要事先完成用戶的聚類(lèi)分析。我們將具體實(shí)現(xiàn)用戶聚類(lèi)的方法留在后面詳細(xì)闡述,先假定已經(jīng)完成了商品銷(xiāo)售分析中客戶聚類(lèi)。通過(guò)查詢張三所屬的用戶聚類(lèi),將交易集中的用戶分為“類(lèi)似張三用戶”,即張三所在的客戶聚類(lèi),而其他客戶聚類(lèi)則劃分為“不類(lèi)似張三用戶”。整個(gè)交易集(包含了類(lèi)似張三用戶、不類(lèi)似張三用戶)中買(mǎi)咖啡的總數(shù)量為35,買(mǎi)面包的數(shù)量為50,同時(shí)也能看到類(lèi)似張三用戶和不類(lèi)似張三用戶買(mǎi)面包的數(shù)量分別為25和10,買(mǎi)牛奶的數(shù)量均為25。很明顯,買(mǎi)面包的數(shù)量集中在類(lèi)似張三用戶。如果管理者有意識(shí)地需要得到面包銷(xiāo)售情況的關(guān)聯(lián)規(guī)則分析,只需要關(guān)注類(lèi)似張三用戶的銷(xiāo)售情況。即如果現(xiàn)在只是在表4所示事務(wù)集上做關(guān)聯(lián)規(guī)則分析,按照現(xiàn)有挖掘算法就可以得到如下關(guān)聯(lián)規(guī)則: 買(mǎi)牛奶→買(mǎi)面包s=20/100=0.2=minsupp c=20/25=0.8>minconf 表4 A商場(chǎng)交易集的分析 即設(shè)定minsupp=0.2,minconf=0.6,根據(jù)關(guān)聯(lián)規(guī)則挖掘算法能在面向類(lèi)似張三用戶的數(shù)據(jù)分析上得到有效的關(guān)聯(lián)規(guī)則買(mǎi)牛奶→買(mǎi)面包。也就是這條關(guān)聯(lián)規(guī)則針對(duì)類(lèi)似張三用戶有效,但對(duì)于整個(gè)交易記錄反而不成立。因?yàn)橘I(mǎi)面包的交易主要由類(lèi)似張三用戶完成。由此可見(jiàn)為了完成用戶需要得到的具有某一類(lèi)特征的數(shù)據(jù)分析對(duì)象的關(guān)聯(lián)規(guī)則,需要完成具有相似特性的數(shù)據(jù)分析對(duì)象的聚類(lèi),從而才能得到有針對(duì)性的關(guān)聯(lián)規(guī)則;否則,在整個(gè)事務(wù)集上的關(guān)聯(lián)規(guī)則分析,得不到用戶心中想得到的有針對(duì)性的分析。 2.3 綜合OLAP和聚類(lèi)分析的關(guān)聯(lián)規(guī)則挖掘算法 由于數(shù)據(jù)倉(cāng)庫(kù)環(huán)境下,用戶可以通過(guò)數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)特有的OLAP操作和MDX語(yǔ)言進(jìn)行多維數(shù)據(jù)分析。特別是上卷/下鉆功能可以在不同綜合細(xì)節(jié)和不同維度層次結(jié)構(gòu)上看到度量值的不同變化,從而用戶可以通過(guò)這些操作了解到感興趣的數(shù)據(jù)分析對(duì)象的分布狀況。而感興趣的數(shù)據(jù)分析對(duì)象集中分布的數(shù)據(jù)集通過(guò)本文的分析極大地影響到關(guān)聯(lián)規(guī)則挖掘的結(jié)果。 另外,在數(shù)據(jù)倉(cāng)庫(kù)環(huán)境中集成了與分析主題相關(guān)的多數(shù)據(jù)源的、海量歷史數(shù)據(jù)。這是一般為數(shù)據(jù)挖掘準(zhǔn)備的數(shù)據(jù)庫(kù)所不具備的有利條件,而且在數(shù)據(jù)倉(cāng)庫(kù)環(huán)境中已經(jīng)通過(guò)抽取、轉(zhuǎn)換和裝載(ETL)過(guò)程使這些數(shù)據(jù)達(dá)成了一致性和完備性,形成了很高質(zhì)量的數(shù)據(jù)。這些有利條件可以進(jìn)一步地將用于關(guān)聯(lián)規(guī)則挖掘的事務(wù)集中的數(shù)據(jù)進(jìn)行聚類(lèi)劃分,從而可以挖掘出針對(duì)某些具有相似特征的聚類(lèi)有效的關(guān)聯(lián)規(guī)則。而這些關(guān)聯(lián)規(guī)則常常對(duì)于整個(gè)事務(wù)集由于支持度和置信度不夠而被挖掘算法過(guò)濾掉。這就導(dǎo)致了用戶難以得到比較精確的數(shù)據(jù)分析結(jié)果,而這種有針對(duì)性的分析結(jié)果在當(dāng)前提出的主動(dòng)推薦技術(shù)和精準(zhǔn)網(wǎng)絡(luò)廣告上尤其重要。 定義2[5]數(shù)據(jù)庫(kù)中不可分割的最小單位信息,稱(chēng)為項(xiàng)目,用符號(hào)i表示。項(xiàng)的集合稱(chēng)為項(xiàng)集。設(shè)集合I={i1,i2,…,ik},項(xiàng)目的個(gè)數(shù)為K,則I稱(chēng)為K-項(xiàng)集。例如,集合{啤酒,尿布,牛奶}是一個(gè)3-項(xiàng)集。 定義3[5]若X,Y為項(xiàng)目集,且X∩Y=?,蘊(yùn)涵式X?Y稱(chēng)為關(guān)聯(lián)規(guī)則,X和Y分別稱(chēng)之為X?Y的前提和結(jié)論。 規(guī)則X?Y的支持度s是含有X的記錄在全體記錄中所占的比率,置信度c是同時(shí)含有X和Y的記錄數(shù)與含有X的記錄數(shù)的比率。顯然,支持度s表示規(guī)則的頻度,置信度c表示規(guī)則的強(qiáng)度,s和c均大于給定閾值的稱(chēng)為強(qiáng)規(guī)則,數(shù)據(jù)挖掘的主要興趣是強(qiáng)規(guī)則的發(fā)現(xiàn)。s的最小閾值記為minsupp,c的最小閾值記為minconf。 定義4將事務(wù)集中用戶感興趣的項(xiàng)(item)的集合稱(chēng)為用戶興趣項(xiàng)集,并記為Interest-itemset,其中的項(xiàng)稱(chēng)為用戶興趣項(xiàng)。 用戶興趣項(xiàng)一般為挖掘出的規(guī)則的后件即為分析對(duì)象,即用戶想知道提高感興趣的商品的銷(xiāo)售量的影響因素有哪些,而這些挖掘出的關(guān)聯(lián)規(guī)則的前提就是能提高作為規(guī)則后件的商品銷(xiāo)售量的影響因子。用戶興趣項(xiàng)也可以不是挖掘出的關(guān)聯(lián)規(guī)則的后件,即是聚類(lèi)因子,是用戶感興趣的需要聚類(lèi)的維度或維成員。 提出用戶興趣項(xiàng)的概念是為了表達(dá)用戶的分析意愿,從而對(duì)關(guān)聯(lián)規(guī)則的挖掘結(jié)果施加用戶挖掘目的性的影響。這樣不僅可以縮小待挖掘數(shù)據(jù)集的大小,提高挖掘算法的執(zhí)行效率,而且可以縮小挖掘出來(lái)的關(guān)聯(lián)規(guī)則的個(gè)數(shù)達(dá)到用戶可理解的程度、以便用戶做出自己的選擇。用戶興趣項(xiàng)是由用戶指定的,表達(dá)了用戶的分析需求。在2.1節(jié)中零售管理人員想分析客戶買(mǎi)咖啡和哪些購(gòu)買(mǎi)項(xiàng)有關(guān)聯(lián),則買(mǎi)咖啡是用戶的興趣項(xiàng),在最后的挖掘結(jié)果中作為關(guān)聯(lián)規(guī)則的后件出現(xiàn)。在2.2節(jié)中,用戶的分析意愿并沒(méi)有完全表達(dá)為關(guān)聯(lián)規(guī)則的后件,而是關(guān)注不同用戶群的購(gòu)買(mǎi)面包和哪些購(gòu)買(mǎi)項(xiàng)相關(guān)聯(lián)。這樣可以針對(duì)不同用戶的購(gòu)買(mǎi)行為制定促銷(xiāo)策略引導(dǎo)消費(fèi),在這里用戶的意愿中買(mǎi)面包是待挖掘的規(guī)則后件,數(shù)據(jù)倉(cāng)庫(kù)中的客戶維度則是聚類(lèi)因子。 定義5將多維數(shù)據(jù)集中影響用戶興趣項(xiàng)的度量值變化比較顯著的維度或維度層次上的成員值稱(chēng)為用戶興趣維度成員,并記為Interest-dim-Member,形成的集合記作Interest-dim-MemberSet。 在定義4的基礎(chǔ)上,我們進(jìn)一步提出了用戶興趣維度成員的概念,用戶興趣維度成員是通過(guò)OLAP的切片、切塊、上卷/下卷等操作觀察引起用戶興趣項(xiàng)的度量值變化比較顯著的維度成員值或維度層次上的成員值。比如在2.1節(jié)中我們通過(guò)下鉆操作發(fā)現(xiàn)用戶興趣項(xiàng)買(mǎi)咖啡的數(shù)量主要集中在商場(chǎng)維度的成員值“商場(chǎng)A”上;或在維度上進(jìn)行維度成員的聚類(lèi)劃分,選取用戶感興趣的維度成員的聚類(lèi)作為用戶興趣度成員。比如在2.2節(jié)中通過(guò)用戶聚類(lèi)后查詢“類(lèi)似張三用戶”的用戶聚類(lèi)和“不類(lèi)似張三用戶”用戶聚類(lèi),發(fā)現(xiàn)買(mǎi)面包的數(shù)量集中在“類(lèi)似張三用戶”群上,則“類(lèi)似張三用戶”的用戶聚類(lèi)中的客戶維度成員作為用戶的興趣維度成員。 算法1綜合OLAP和聚類(lèi)分析的關(guān)聯(lián)規(guī)則挖掘 Apriori-OLC(based on OLAP and Clusters) 輸入:聚類(lèi)個(gè)數(shù)K,事務(wù)集I,minsupp,minconf,用戶興趣項(xiàng)集Interest-itemset 輸出:關(guān)聯(lián)規(guī)則集Associate-ruleset Begin (1) For each i(Interest-itemset do { Ifi為用戶感興趣的關(guān)聯(lián)規(guī)則的后件 then通過(guò)OLAP上卷/下鉆操作或MDX語(yǔ)言發(fā)現(xiàn)與項(xiàng)i相關(guān)的Interest-dim-Member,并記入集合Interest-dim-MemberSet else i為用戶感興趣的聚類(lèi)因子,則根據(jù)聚類(lèi)個(gè)數(shù)K,調(diào)用K-平均值聚類(lèi)算法劃分聚類(lèi),并選擇符合用戶分析意愿的聚類(lèi)中的維成員并入Interest-dim-MemberSet; }; For eachj(Interest-dim-MemberSetdo { Where子句中將維成員j作選擇過(guò)濾條件; } 在交易數(shù)據(jù)庫(kù)中編寫(xiě)Select選擇語(yǔ)句,并選擇上述Where子句,查詢出來(lái)的結(jié)果作為交易事務(wù)集I; 根據(jù)minsupp,minconf,在事務(wù)集I上調(diào)用關(guān)聯(lián)規(guī)則挖掘算法Apriori,生成的關(guān)聯(lián)規(guī)則集記入Associate-ruleset; (2) Return(Associate-ruleset); END. 算法1即關(guān)聯(lián)規(guī)則挖掘算法 Apriori-OLC的理論基礎(chǔ)和對(duì)關(guān)聯(lián)規(guī)則挖掘的有效性在2.1節(jié)和2.2節(jié)已有很詳細(xì)的闡述。由此可見(jiàn)算法1可以提高關(guān)聯(lián)規(guī)則挖掘結(jié)果對(duì)于用戶的滿意度,也改善了當(dāng)前關(guān)聯(lián)挖掘結(jié)果集太大而用戶無(wú)所適從的應(yīng)用瓶頸,使得所挖掘的結(jié)果具有針對(duì)性從而能為用戶所想、亦為用戶所用。 3.1 算法評(píng)價(jià)指標(biāo)及分析 1) 基本評(píng)價(jià)指標(biāo)包括:支持度和置信度。 這是事先人為設(shè)定的,只有滿足大于最小支持度和最小置信度的規(guī)則才是最后挖掘出的強(qiáng)關(guān)聯(lián)規(guī)則,見(jiàn)本文1.3節(jié)的描述。通過(guò)本文2.1節(jié)和2.2節(jié)的分析可知:與基于Apriori算法的關(guān)聯(lián)規(guī)則挖掘算法比較,采用算法1通過(guò)支持用戶預(yù)先設(shè)定的用戶興趣項(xiàng)并經(jīng)過(guò)OLAP分析和聚類(lèi)分析得到用戶興趣維度成員,從而精簡(jiǎn)了待挖掘的數(shù)據(jù)集,提高了用戶感興趣的規(guī)則的支持度和置信度,挖掘出用戶真正感興趣的規(guī)則。而這些規(guī)則在沒(méi)有支持用戶興趣項(xiàng)挖掘的Apriori算法中常常因?yàn)闆](méi)有大于最小支持度或最小置信度而被舍棄。 2) 定性評(píng)價(jià)指標(biāo)包括:關(guān)聯(lián)規(guī)則的簡(jiǎn)潔度。 關(guān)聯(lián)規(guī)則的簡(jiǎn)潔度表現(xiàn)為規(guī)則個(gè)數(shù)和規(guī)則前件包含的項(xiàng)的數(shù)目。規(guī)則個(gè)數(shù)和前件中包含項(xiàng)的個(gè)數(shù)越少,規(guī)則越簡(jiǎn)潔,則用戶越容易理解。由于算法1相對(duì)于Apriori算法支持了用戶興趣項(xiàng)挖掘,挖掘出的規(guī)則更簡(jiǎn)潔,不包含與用戶興趣無(wú)關(guān)的規(guī)則。 3.2 實(shí)際分析項(xiàng)目中的實(shí)驗(yàn)驗(yàn)證 利用SQL SERVER 2008 R2提供的SQL Server Management Studio(SSMS)部件建立實(shí)驗(yàn)環(huán)境下的數(shù)據(jù)倉(cāng)庫(kù)以及SQL Server Business Intelligence Development Studio(BIDS)部件建立一個(gè)分析項(xiàng)目包括多維數(shù)據(jù)模型和OLAP分析及關(guān)聯(lián)規(guī)則挖掘。實(shí)驗(yàn)中使用的數(shù)據(jù)來(lái)源于海洋環(huán)境觀測(cè)數(shù)據(jù)。運(yùn)用Apriori關(guān)聯(lián)規(guī)則挖掘,得到如圖1所示結(jié)果。 圖1 關(guān)聯(lián)規(guī)則挖掘結(jié)果 挖掘出的關(guān)聯(lián)規(guī)則過(guò)多,通過(guò)設(shè)置參數(shù)可以調(diào)整挖掘的個(gè)數(shù),但用戶仍然不清楚這些規(guī)則對(duì)整個(gè)數(shù)據(jù)集的針對(duì)性,難以達(dá)到輔助用戶決策的目的。在多維數(shù)據(jù)集上,通過(guò)OLAP的下鉆操作得到如圖2所示的數(shù)據(jù)展示。 圖2 OLAP的下鉆操作結(jié)果 從圖2的OLAP下鉆操作結(jié)果,用戶很容易看出影響要分析的對(duì)象“平均葉綠素濃度”的因子是月份和監(jiān)測(cè)海域。因?yàn)樵路菰陉P(guān)聯(lián)規(guī)則挖掘的數(shù)據(jù)集中,所以用戶可以定義關(guān)于月份的一個(gè)劃分,來(lái)看在這個(gè)時(shí)間段區(qū)間里影響平均葉綠素濃度的關(guān)聯(lián)規(guī)則挖掘。比如可以限定監(jiān)測(cè)海域=大連市近岸海域、月份=2011/1~2011/3來(lái)選擇過(guò)濾數(shù)據(jù)集,則可以得到關(guān)聯(lián)規(guī)則:當(dāng)日期2011/1~2011/3?平均葉綠素濃度>1.22。由圖1在SQL SERVER2008中展示的關(guān)聯(lián)規(guī)則依賴關(guān)系圖可知,在整個(gè)數(shù)據(jù)集上可挖掘到關(guān)聯(lián)規(guī)則:當(dāng)日期<2011/2/21?平均葉綠素濃度<0.62。 可見(jiàn)當(dāng)用戶沒(méi)有通過(guò)OLAP分析對(duì)分析對(duì)象“平均葉綠素濃度”的值在不同影響因子上的分布情況有足夠的理解時(shí),根本得不到自己想要看到的關(guān)聯(lián)規(guī)則。而整個(gè)數(shù)據(jù)集上挖掘的關(guān)聯(lián)規(guī)則由于沒(méi)有針對(duì)性,用戶很難進(jìn)行解讀,也很難有助于用戶的決策分析。 將監(jiān)測(cè)海域作為聚類(lèi)對(duì)象,與之相關(guān)的所在月份及監(jiān)測(cè)的平均葉綠素濃度作為屬性數(shù)據(jù),采用歐式距離計(jì)算相似度并利用K-平均值進(jìn)行聚類(lèi),可得到以下聚類(lèi):1) 2011/1-2011/3,大連市近岸海域;2) 2011/2-2011/4,寧波市近岸海域;3) 2011/1-2011/4,上海市近岸海域。 對(duì)屬于不同聚類(lèi)上的數(shù)據(jù)集分別進(jìn)行關(guān)聯(lián)規(guī)則挖掘,得到: 1) 2011/1-2011/3,大連市近岸海域;當(dāng)日期2011/1-2011/3?平均葉綠素濃度>1.22。 2) 2011/2-2011/4,寧波市近岸海域;當(dāng)日期2011/2-2011/4?平均葉綠素濃度>1.35。 3) 2011/1-2011/4,上海市近岸海域;當(dāng)日期2011/1-2011/4?0.36<平均葉綠素濃度<1。 這些關(guān)聯(lián)規(guī)則遠(yuǎn)比在整個(gè)數(shù)據(jù)集上可挖掘到關(guān)聯(lián)規(guī)則(由圖1可知)“當(dāng)日期<2011/2/21時(shí)?平均葉綠素濃度<0.62”更有意義。因?yàn)檫@條規(guī)則針對(duì)以上任何一個(gè)聚類(lèi)都沒(méi)有實(shí)際指導(dǎo)意義,并且與規(guī)則1、規(guī)則2這兩個(gè)聚類(lèi)的實(shí)際相關(guān)的關(guān)聯(lián)規(guī)則表達(dá)的意義剛好相反。 為了克服當(dāng)前關(guān)聯(lián)規(guī)則挖掘方法得到的關(guān)聯(lián)規(guī)則集過(guò)大,而且因?yàn)闆](méi)有針對(duì)性導(dǎo)致用戶無(wú)法理解的現(xiàn)象,本文提出了用戶興趣項(xiàng)和用戶興趣維度成員的概念,用來(lái)表達(dá)用戶對(duì)事務(wù)集中數(shù)據(jù)分析對(duì)象的關(guān)注,從而將關(guān)聯(lián)規(guī)則挖掘算法和用戶的分析意愿結(jié)合在一起。并進(jìn)一步給出了基于數(shù)據(jù)倉(cāng)庫(kù)環(huán)境下OLAP操作和聚類(lèi)分析的關(guān)聯(lián)規(guī)則挖掘的技巧。新的關(guān)聯(lián)規(guī)則挖掘技巧較現(xiàn)有方法可以減少挖掘出的關(guān)聯(lián)規(guī)則的數(shù)量并真正挖掘出用戶所關(guān)注的數(shù)據(jù)分析對(duì)象的關(guān)聯(lián)規(guī)則。 參 考 文 獻(xiàn) [1] Agrawal R,Imieliński T,Swami A.Mining association rules between sets of items in large databases[C]//ACM SIGMOD International Conference on Management of Data.ACM,1993:207-216. [2] Agrawal R,Srikant R.Fast Algorithm for Mining Association Rules[J].Computer Engineering & Applications,1994,15(6):619-624. [3] Park J S,Chen M S,Yu P S.An effective hash-based algorithm for mining association rules[C]//SIGMOD’95 Proceedings of the 1995 ACM SIGMOD international conference on Management of data,1995:175-186. [4] 何月順.關(guān)聯(lián)規(guī)則挖掘技術(shù)的研究及應(yīng)用[D].南京航空航天大學(xué),2010. [5] 陳偉文.數(shù)據(jù)倉(cāng)庫(kù)與數(shù)據(jù)挖掘教程[M].北京:清華大學(xué)出版社,2011. [6] 征原,謝云.基于劃分的聚類(lèi)個(gè)數(shù)與初始中心的確定方法[J].計(jì)算機(jī)技術(shù)與發(fā)展,2017,27(7):76-78. [7] 余成進(jìn),趙姝,陳潔,等.復(fù)雜網(wǎng)絡(luò)中的層次結(jié)構(gòu)挖掘[J].南京大學(xué)學(xué)報(bào)(自然科學(xué)),2016,52(5):861-870. [8] 周夢(mèng)熊,葉巖明,任一支,等.基于密度聚類(lèi)的協(xié)作學(xué)習(xí)群組構(gòu)建方法[J].計(jì)算機(jī)工程與設(shè)計(jì),2016,37(10):2710-2716. [9] 繆裕青,高韓,劉同來(lái),等.基于網(wǎng)格聚類(lèi)的情感分析研究[J].中國(guó)科學(xué)技術(shù)大學(xué)學(xué)報(bào),2016(10):874-882. [10] 魏瑾瑞.一類(lèi)基于模型的聚類(lèi)方法[J].統(tǒng)計(jì)與信息論壇,2014,29(2):19-22. [11] 李衛(wèi)軍.K-means聚類(lèi)算法的研究綜述[J].現(xiàn)代計(jì)算機(jī)(專(zhuān)業(yè)版),2014(8):31-32,36. [12] 周粉妹.聚類(lèi)算法在客戶細(xì)分中的應(yīng)用[J].煙臺(tái)職業(yè)學(xué)院學(xué)報(bào),2006,12(2):46-49.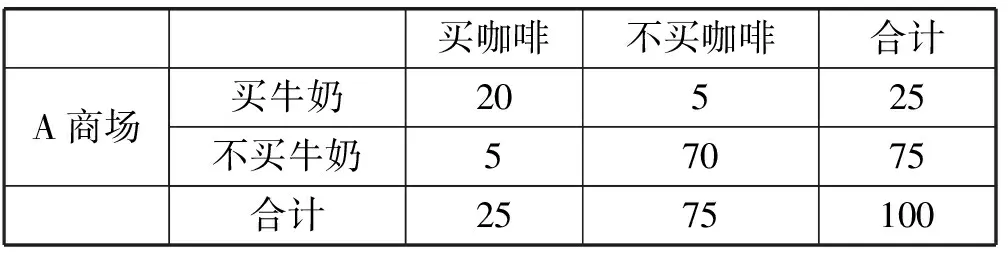

3 關(guān)聯(lián)規(guī)則挖掘項(xiàng)目設(shè)計(jì)及實(shí)驗(yàn)驗(yàn)證分析

4 結(jié) 語(yǔ)
猜你喜歡
小獼猴智力畫(huà)刊(2022年3期)2022-03-29 01:09:42當(dāng)代陜西(2021年17期)2021-11-06 03:21:36數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:26:14學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20Coco薇(2017年11期)2018-01-03 20:59:57讀者(2017年5期)2017-02-15 18:04:18暨南學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2016年9期)2017-01-15 13:52:02商用汽車(chē)(2016年11期)2016-12-19 01:20:16商用汽車(chē)(2016年6期)2016-06-29 09:18:54商用汽車(chē)(2016年4期)2016-05-09 01:23:12
