基于交易數(shù)據(jù)的信用評估方法
2018-05-22 07:35:53周繼恩杜金泉
計算機應用與軟件 2018年5期
陳 煜 周繼恩 杜金泉
(中國銀聯(lián)股份有限公司 上海 200135)
0 引 言
隨著大數(shù)據(jù)時代的到來,各種各樣的用戶數(shù)據(jù)都可以用于轉化,評估,體現(xiàn)個人數(shù)據(jù)。日常消費數(shù)據(jù)還有很大的挖掘價值。學術研究方面,國內學者從定性和定量的角度對個人信用評估進行了一系列的研究[5],但是目前為止尚未形成一種針對銀行卡交易數(shù)據(jù)的個人信用評估模型及體系。因此本文以個人信用評估方法為研究中心,結合銀行卡交易數(shù)據(jù),構建一個新的個人信用評估模型。
1941年,Divid Durand采用評分形式來評估個人信用,建立了經(jīng)典的消費信貸評分標準。隨著計算機技術的不斷發(fā)展,越來越多的計量方法應用到了信用評估領域,比如統(tǒng)計學中的線性回歸方法和Logisitic回歸[6],機器學習中的神經(jīng)網(wǎng)絡[3]、集成學習[8]、支持向量機[2]等,這些方法不斷完善著信用評估系統(tǒng)。
1 信用模型構建
首先,本文著眼于個人信用模型的建立,采用的數(shù)據(jù)來源于線下刷卡、網(wǎng)上消費等產(chǎn)生的交易數(shù)據(jù)。然后,針對問題,提取有效的特征集,篩選特征并用于信用模型的訓練。最后,對訓練完成的信用評估模型驗證,解釋結果,并做出相應的決策建議。
1.1 信用特征計算方法
特征是指區(qū)分不同類型的本質特點,在信用評估的問題下,更偏向尋找,計算那些能夠用于區(qū)分信用好的用戶及信用差的用戶的特征,用戶的信用畫像由這些信用相關的特征組成。因此特征提取在提高分類的準確性中起著非常關鍵的作用。
交易數(shù)據(jù)中包含的要素有:交易金額、交易時間、交易渠道、商戶代碼、交易地區(qū)、交易類型、商戶類型、卡類型、卡介質、發(fā)卡機構、收單機構等。在研究中,本文根據(jù)交易數(shù)據(jù),提取了眾多的特征,大體的方法主要分為三類:
(1) 基于統(tǒng)計方法的特征提取 每個人所持有的卡數(shù)和產(chǎn)生交易的次數(shù)都不同。本文基于統(tǒng)計的方法提取了大部分特征。提取特征的常見方法有均值、方差、最大值、最小值、時率、占比等。基本上交易中絕大部分要素都可以通過統(tǒng)計的方法衍生出眾多的特征。
(2) 利用聚類方法,計算行為特征模型 有些人偏愛消費,有些人偏愛存取。依據(jù)每個人不同的行為偏好,采用聚類的方法將目標用戶分為幾類,利用聚類方法針對不同群體計算行為特征。聚類的場景可以是交易時間、交易渠道、交易金額、交易次數(shù)、交易頻率等。例如,消費行為聚類特征,將交易渠道分為四類{ POS ,ATM,電腦互聯(lián)網(wǎng)消費,其他},計算每個持卡人各個渠道的交易占比,以此4個特征作為聚類特征,利用Kmeans算法,將樣本用戶劃分為幾類。
(3) 依據(jù)經(jīng)驗知識,刻畫信用特征 構造用戶畫像主要是依靠內部和外部的信用經(jīng)驗,抽象出影響個人信用風險的關鍵性因素,依據(jù)交易數(shù)據(jù)實現(xiàn)關鍵因素的計算。在信用領域、還款能力、還款意愿,資金管理能力等都是影響信用評估的關鍵。
1.2 特征篩選
通過以上三種方法,計算了大約2 000多特征。這里有許多特征對于信用評估是無用的,甚至有負面作用。特征選擇減少特征的數(shù)量,使模型泛化能力更強。本文采用特征選擇的方法有:
(1) IV值 IV值,即information value,中文表述為信息量或信息值,其主要作用就是當我們在用決策樹或邏輯回歸構建分類模型時對變量進行篩選。IV值就是衡量自變量對于標簽特征的區(qū)分能力,IV值越大,區(qū)分能力越強。本文設置IV值的閾值為0.04,篩選掉IV值小于0.04的特征變量。
(2) 相關性過濾 相關系數(shù)用于考察兩個變量或特征之間的相關程度。如果相關性過高,會導致模型重復計算。因此,需要過濾掉相關性過高的特征,本文設定線性相關性閾值為0.5.當兩個變量相關性大于0.5時,保留IV值較大的特征變量。
2 信用評分模型
一般的分類算法,輸出的并不是一個評分,而是一個類別。信用評分的優(yōu)勢在于可以在實際評估審核用戶的貸款資格時,依據(jù)其他信息,狀況做出更切實的調整;并且信用狀況本身通過二分類問題簡單描述,并不完全適合。因此本文通過集成學習方法,訓練多個成員分類器,通過設計融合函數(shù),達到評分的效果。
決策樹是一種實用,高效的學習算法。它有著許多良好的特性,比如訓練時間負責度低,預測時間短等,但同時,單獨一棵決策樹也有許多缺點,比如容易過度擬合。通過集成學習方法,可以大大減少單決策樹帶來的負面影響。隨機森林是集成學習的一種方法,本文采用隨機森林的方法,利用上一步計算篩選所得的特征,引入隨機代價矩陣,學習和訓練模型。
2.1 引入隨機性
一般而言,在信貸領域將客戶分為兩部分,一部分是信貸行為較好的用戶,我們將客戶在借貸后,按期還款,視為“好客戶”;有一些客戶在借款后,未能按期還款,拖延達一定日期后,我們認定這類客戶為“壞”客戶。為方便起見,定義“壞”客戶為正樣本,“好”客戶為負樣本。樣本中正樣本和負樣本比例不均衡。同樣一個正例帶來的損失遠遠大于好客戶帶來的收益。因此在訓練成員分類器時,設置代價敏感矩陣。
(1)
式中:vbad是一個壞客戶被誤判為好客戶所造成的的損失,vgood是對于好客戶誤判造成的損失,正確分類的代價為0。
隨機森林是由多個決策樹組成的分類器,為了確保成員分類器之間的差異性,隨機選擇F個輸入特征來對決策樹的結點進行分裂。隨機森林的相關性取決與F的大小。F越小,成員樹之間的相關性越弱。
集成學習對于弱分類器有提升效果,保證了成員分類器之間具有一定的差異性。本文設計隨機代價敏感矩陣向量,以提升成員分類器的差異性。設λ為均勻分布,記為λ~U(1/a,a)(a>1),隨機代價矩陣表示為:
(2)
針對每一個成員分類器產(chǎn)生一個隨機代價矩陣,從而形成隨機代價向量。隨機代價向量表示為:
CV={cv1,cv2,…,cvm}
(3)
本文所提算法RCV-RF算法流程如下
算法1,RCV-RF
輸入:訓練樣本集X=[x1,x2,…,xn]
步驟1從訓練集X中,采用booststrap方法有放回地隨機抽取m個樣本集,構成新的樣本集X={X1,X2,…,Xm}。
步驟2引入隨機代價敏感向量CV,設置每個子樹訓練的代價敏感矩陣。
步驟3設n個特征,則在每一棵樹的每個節(jié)點處隨機抽取F個特征,進行節(jié)點分裂。
步驟4將生成的多棵樹組成隨機森林。
2.2 融合函數(shù)
通過訓練產(chǎn)生m個成員分類器,在模型決策時,需要將每個成員分類器預測的結果進行融合,輸出一個評分。信用評分可以表示為多個成員分類器中認為是好客戶的占比。信用評分可以表示為:
(4)
式中:Cj(x)為第j個成員分類器預測的結果,δ(·)為指示函數(shù),如果Cj(x)輸出等于good為1,否則為0。
信用評分是由多個分類器投票產(chǎn)生,可能造成低分段和高分段的人數(shù)聚集過多,中間分段的人數(shù)過少。遇到這種情況,可以通過調大均勻分布的范圍來達到分值覆蓋人數(shù)相對均勻的目的。
3 實驗對比
本文采用的數(shù)據(jù)包含兩部分,一部分是使用過信用產(chǎn)品的客戶信息及還款情況,另一部分是相關客戶在銀聯(lián)渠道的交易數(shù)據(jù)。本文只采集借款之前的交易數(shù)據(jù),借款之后的交易數(shù)據(jù)不參與建模。模型用于客戶申請貸款的資格核準。客戶借貸的場景為互聯(lián)網(wǎng)消費金融,用戶通過手機認證,無抵押貸款,貸款數(shù)額在3 000~15 000之間。
由于逾期的時間不同,所以“壞”可以是不同程度的,從拖延少于15天,15天到30天,一直到30天以上。“壞”客戶為逾期超過30天的客戶,“好”客戶為逾期小于3天的客戶。數(shù)據(jù)集中有2 643個壞客戶,34 028個好客戶,客戶使用信用產(chǎn)品的時間在3~8月份之間。
本文依據(jù)時間將數(shù)據(jù)集分為訓練集與測試集,3~6月為訓練集,訓練集用于訓練信用模型,7~8月份客戶測試集用于評估模型的效果。

表1 訓練集與測試集大小
為評估特征計算方法有效性,采用IV值作為評價指標,對一些典型的特征做分析。為了比較提出的算法RCV-RF優(yōu)劣性,本文選擇對比的算法有RF,GBDT,Adaboost。采用ROC、AUC、K-S作為評價指標,對比算法結果。
3.1 特征分析
前文中提到,課題通過不同的方法,計算信用相關的特征變量,從而構造用戶畫像。本節(jié)首先分析一些典型的用戶畫像特征。
從表2可以看出,交易行為,消費金額的特征對于逾期風險有著較強的相關性。往往消費金額越大,在消費金融信貸產(chǎn)品上逾期的風險就會越低。經(jīng)常出現(xiàn)刷卡余額不足的情況,說明了客戶缺乏對資金管理的意識,潛在地提升了逾期的風險。這些特征對于好壞客戶有著較為明顯的區(qū)分度,并且絕大部分特征對于壞客戶占比都呈現(xiàn)單調性。為本文后續(xù)建模提供了有力的支持。依據(jù)IV值和相關性等方法,特征選擇出115維特征。

表2 部分特征的IV值
3.2 實驗結果對比
本文選擇了GBDT、RF、Adaboost三種經(jīng)典的集成學習算法作為比較算法,所有算法均采用上文計算篩選所得特征集,使用3~6月份的數(shù)據(jù)做訓練,7~8月份數(shù)據(jù)做測試,且使用相同的數(shù)據(jù)集訓練與評估。如表3所示。
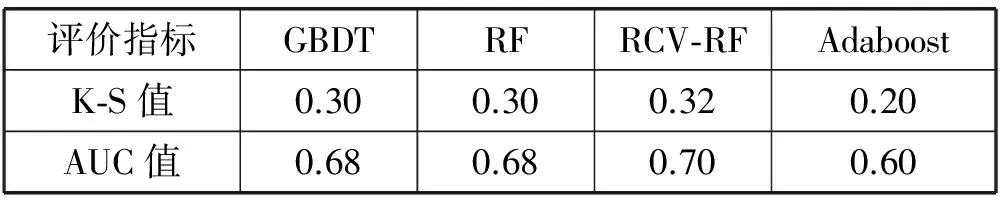
表3 模型的KS值對比
如圖1所示,是本文算法和常用集成學習算法的ROC對比圖。從圖中可以看出,本文所提算法RCV-RF的AUC值為0.70略高于RF,GBDT算法,Adaboost算法效果與其他三種算法效果差距明顯。通過KS值比較,RCV-RF算法亦優(yōu)于其他算法。

圖1 模型效果ROC圖
4 結 語
本文基于銀行卡的交易數(shù)據(jù),針對互聯(lián)網(wǎng)消費信貸場景進行分析,提取有效的特征集,建立一個用于信用評估的模型,并通過與其他常用算法對比,驗證本文所提算法的有效性。本文主要分為兩部分。首先,本文通過三種計算方式,提取在信用評估上具價值的特征變量,構建了基于交易數(shù)據(jù)的用戶信用畫像,這些特征對于模型訓練起到了關鍵的作用。其次,本文算法通過引入隨機代價敏感向量的方式,增強了成員分類器之間的差異性,并且通過評分融合函數(shù)使信用評分更為合理、有效。
參 考 文 獻
[1] 石勇,孟凡.信用評分基本理論及其應用[J].大數(shù)據(jù),2017(1):19-26.
[2] 陳云,石松,潘彥,等.基于SVM混合集成的信用風險評估模型[J].計算機工程與應用,2016,52(4):115-120.
[3] 胡來豐.基于粗糙集BP神經(jīng)網(wǎng)絡個人信用評估模型[D].電子科技大學,2015.
[4] 葉菁菁,吳斌,董敏.P2P網(wǎng)貸個人信用評估國內外研究綜述[J].商業(yè)時代,2015(31):109-111.
[5] 李孟來.我國個人信用評分模型的應用探討[J].金融管理與研究:杭州金融研修學院學報,2009(2):52-54.
[6] 馬海英.基于神經(jīng)網(wǎng)絡及Logistic回歸的混合信用卡評分模型[J].華東理工大學學報(社會科學版),2008,23(2):49-52.
[7] 沈翠華,鄧乃揚,肖瑞彥.基于支持向量機的個人信用評估[J].計算機工程與應用,2004,40(23):198-199.
[8] 姜明輝,謝行恒,王樹林,等.個人信用評估的Logistic-RBF組合模型[J].哈爾濱工業(yè)大學學報,2007,39(7):1128-1130.
[9] King G,Zeng L.Logistic Regression in Rare Events Data[J].Political Analysis,2001,9(2):137-163.
[10] Shuang C,Wei X.Design and Selection of Construction,Parameters and Training Method of BP Network[J].Computer Engineering,2001,92:336-337.
[11] Osuna E,Freund R,Girosi F.Training svm:An Application to Face Detection[C]//Proceedings of CVPR’97,June 17-19,1997.
[12] Orgler Y E.A Credit Scoring Model for Commercial Loans[J].Journal of Money Credit & Banking,1970,2(4):435-445.
[13] Huang C L,Chen M C,Wang C J.Credit Scoring with A Data mining Approach Based on Support Vector Machines[M].Pergamon Press,Inc.2007.
[14] Chen C,Breiman L.Using Random Forest to Learn Imbalanced Data[J].2004.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
