一種基于多字互信息與鄰接熵的改進(jìn)新詞合成算法
2018-05-18 05:51:48王欣
現(xiàn)代計(jì)算機(jī) 2018年11期
關(guān)鍵詞:方法
王欣
(重慶師范大學(xué)計(jì)算機(jī)與信息科學(xué)學(xué)院,重慶 401331)
0 引言
隨著互聯(lián)網(wǎng)的發(fā)展,網(wǎng)絡(luò)不斷改變著人類(lèi)的交流方式和表達(dá)方式,因此,產(chǎn)生了大量的新詞。作為大數(shù)據(jù)時(shí)代最熱門(mén)的社交網(wǎng)絡(luò)媒體,微博成為了互聯(lián)網(wǎng)上新詞誕生和高速流傳的重要平臺(tái)。因?yàn)閷?duì)新詞的識(shí)別不夠充分,很大程度上影響了中文分詞的準(zhǔn)確性。所以,基于微博短文本的新詞發(fā)現(xiàn)具有十分重要的研究意義與價(jià)值。
雖然現(xiàn)在對(duì)于新詞的研究已經(jīng)逐漸深入,但是關(guān)于新詞的界定還沒(méi)有一個(gè)準(zhǔn)確的定義。目前,主流的新詞概念有兩種,未登錄詞和新詞。未登錄詞(Unknown Word)是指沒(méi)有收錄在詞典中的詞語(yǔ)[1];新詞(New Word)是指隨著時(shí)代的發(fā)展而出現(xiàn)的具有新的構(gòu)詞規(guī)則、新的使用方法或新的意義的詞語(yǔ)[2]。
新詞發(fā)現(xiàn)的方法按處理的候選字符可以分為:基于重復(fù)字符串的方法和基于分詞的方法。基于重復(fù)字符串的方法是先從語(yǔ)料中按不同長(zhǎng)度依次切割得到候選字符串,然后再判斷候選字符串是不是新詞。基于分詞的方法則是在對(duì)預(yù)料進(jìn)行分詞的基礎(chǔ)上,在切分成多個(gè)詞的字符串中發(fā)現(xiàn)新詞。
基于重復(fù)字符串的方法簡(jiǎn)單易懂,且容易實(shí)現(xiàn),但是由于逐字滑動(dòng)切割固定長(zhǎng)度的字符串,會(huì)產(chǎn)生大量的重復(fù)串,效率比較低。孫立遠(yuǎn)等人[3]采用N元遞增算法(N-gram)獲取所有2-5字組成的漢字符串作為候選字符串,用詞頻和詞語(yǔ)靈活度對(duì)候選詞進(jìn)行過(guò)濾得到新詞。Du Y等人[4]提出了一種結(jié)合傳統(tǒng)N-gram算法和基于詞向量的相似度剪枝方法進(jìn)行新詞識(shí)別。唐波等人[5]采用廣義后綴樹(shù)的數(shù)據(jù)結(jié)構(gòu)存儲(chǔ)字符串及其前后綴,通過(guò)構(gòu)詞能力提取候選詞。鄭家桓等人[6]用新詞的構(gòu)規(guī)則總結(jié)歸納了適用于網(wǎng)絡(luò)新詞發(fā)現(xiàn)的構(gòu)詞規(guī)則庫(kù),取得很好的效果,但構(gòu)詞規(guī)則的制定需要大量人工標(biāo)注,且可移植性比較差。Su Q L等人[7]針對(duì)微博文本特點(diǎn)和統(tǒng)計(jì)手段的缺陷,分析了5種經(jīng)典統(tǒng)計(jì)量,在此基礎(chǔ)上改進(jìn)了鄰接熵,通過(guò)計(jì)算加權(quán)相對(duì)臨界熵,新詞抽取能力提升且對(duì)詞頻不敏感。夭榮明等人[8]提出了一種MBN-gram算法,用多個(gè)統(tǒng)計(jì)量過(guò)濾重復(fù)字符串得到候選項(xiàng),基于改進(jìn)互信息和鄰接熵對(duì)候選項(xiàng)進(jìn)行擴(kuò)展和過(guò)濾,從中篩選出新詞,并在不同語(yǔ)料規(guī)模上進(jìn)行實(shí)驗(yàn),均有效可行。梁韜等人[9]根據(jù)詞語(yǔ)信息量特征和條件隨機(jī)場(chǎng)進(jìn)行新詞發(fā)現(xiàn),取得了一定的效果。邢恩軍等人[10]提出了一種基于上下文詞頻詞匯量的統(tǒng)計(jì)指標(biāo),基于改進(jìn)信息熵公式和鄰接關(guān)系的字符串連接方法發(fā)現(xiàn)新詞,改善了左右信息熵在識(shí)別新詞時(shí)特征不明顯和N-gram固定滑窗缺陷。
基于分詞的方法是雖然效率有所提高,不會(huì)產(chǎn)生過(guò)多的重復(fù)串,但對(duì)分詞器的效果有較強(qiáng)的依賴(lài)。張華平等人[11]針對(duì)社會(huì)媒體的特征,提出一種基于條件隨機(jī)場(chǎng)實(shí)現(xiàn)的字符標(biāo)注分詞算法,結(jié)合基于全局特征的過(guò)濾方法進(jìn)行新詞識(shí)別,算法所有步驟均為線性時(shí)間復(fù)雜度,速度有所提升,實(shí)驗(yàn)效果也較好。周霜霜等人[12]融合構(gòu)詞規(guī)則、改進(jìn)的C/NC-value算法和條件隨機(jī)場(chǎng)模型進(jìn)行微博新詞抽取,提高新詞識(shí)別準(zhǔn)確率以及對(duì)低頻微博新詞的識(shí)別率。Chen F等人[13]利用條件隨機(jī)場(chǎng)和多個(gè)詞邊界統(tǒng)計(jì)特征進(jìn)行開(kāi)放領(lǐng)域的新詞發(fā)現(xiàn)。雷一鳴等人[14]采用互信息統(tǒng)計(jì)模型對(duì)最小搭配單元的候選詞進(jìn)行向右擴(kuò)展統(tǒng)計(jì)并去除低頻詞以獲得新詞,規(guī)避了N元重疊問(wèn)題。周超等人[15]根據(jù)字符串頻率、成詞規(guī)則和鄰接域變化特性篩選新詞,在COAE2014評(píng)測(cè)任務(wù)上取得了較好的成績(jī),但對(duì)低頻詞不友好,且垃圾串并未完全過(guò)濾。李文坤等人[16]針對(duì)分詞后的散串,結(jié)合詞內(nèi)部結(jié)合度和邊界自由度進(jìn)行新詞發(fā)現(xiàn),該方法在大規(guī)模語(yǔ)料上有效,但對(duì)低頻詞的識(shí)別并不是很有效。
本文在進(jìn)行了相關(guān)理論研究的條件下,對(duì)新詞發(fā)現(xiàn)方法進(jìn)行分析和討論。針對(duì)現(xiàn)有方法中對(duì)低頻新詞不敏感、新詞合成算法發(fā)現(xiàn)的新詞內(nèi)凝聚度不夠穩(wěn)固等問(wèn)題,改進(jìn)了一種結(jié)合統(tǒng)計(jì)、規(guī)則和改進(jìn)的新詞合成算法發(fā)現(xiàn)新詞的方法。通過(guò)設(shè)計(jì)對(duì)比的實(shí)驗(yàn)證明,這種方法能夠提高新詞發(fā)現(xiàn)的效率。
1 新詞特征選擇
判斷兩個(gè)漢字是否能構(gòu)成一個(gè)詞語(yǔ),需要判斷兩個(gè)漢字之間結(jié)合的緊密程度,詞內(nèi)凝聚度可以用來(lái)衡量?jī)蓚€(gè)漢字構(gòu)成詞語(yǔ)的可能性。詞內(nèi)凝聚度越大,表明漢字之間的結(jié)合程度越緊密,構(gòu)成詞語(yǔ)的可能性越大。當(dāng)詞內(nèi)凝聚度大于一定的閾值時(shí),就可以認(rèn)為它們能構(gòu)成一個(gè)詞語(yǔ)。
互信息是常用的表示詞內(nèi)凝聚度的統(tǒng)計(jì)量,可以用來(lái)推斷多個(gè)特征關(guān)聯(lián)程度的大小,通常用來(lái)衡量?jī)蓚€(gè)信號(hào)之間的依賴(lài)程度[16]。在做文本分類(lèi)時(shí),可能會(huì)判斷一個(gè)詞和某類(lèi)的相關(guān)程度,但是在計(jì)算時(shí)未必會(huì)考慮詞頻的影響。所以,在計(jì)算兩個(gè)詞語(yǔ)共同出現(xiàn)的概率時(shí),更多的是使用點(diǎn)互信息(Pointwise Mutual Information,PMI)來(lái)度量?jī)蓚€(gè)詞內(nèi)部結(jié)合的緊密程度。點(diǎn)互信息越大,說(shuō)明詞的詞內(nèi)凝聚度越大,成為新詞或者新詞的一部分的可能性就越大。計(jì)算公式見(jiàn)式(1)。
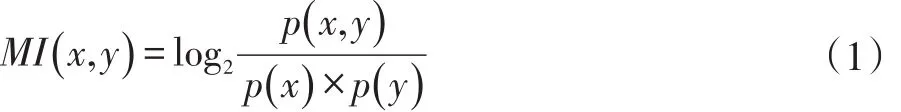
其中,p(x,y)是字符x和y在語(yǔ)料里同時(shí)出現(xiàn)的概率;p(x)是字符x單獨(dú)出現(xiàn)的概率;p(y)是字符y單獨(dú)出現(xiàn)的概率。當(dāng)MI(x,y)?0時(shí),表明x和y是高度相關(guān)的,他們經(jīng)常同時(shí)出現(xiàn),字符串xy就很有可能構(gòu)成新詞;當(dāng)MI(x,y)=0時(shí),表明x和y是相互獨(dú)立分布的;當(dāng)MI(x,y)?0時(shí),表明x和y是互不相關(guān)分布的。
點(diǎn)互信息對(duì)于二元詞組的計(jì)算有很好的效果,但是對(duì)大于兩個(gè)字的多字詞如何劃分成兩部分是比較困難的,針對(duì)這個(gè)問(wèn)題,本文采用多字點(diǎn)互信息計(jì)算公式[17],見(jiàn)式(2)、式(3)和式(4)。
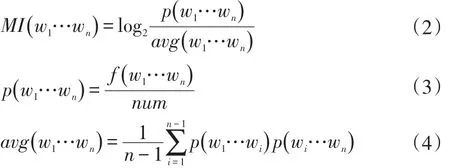
其中,w1…wn為多字字符串,p(w1…wn)是字符串w1…wn在語(yǔ)料中出現(xiàn)的概率;f(w1…wn)表示字符串w1…wn在語(yǔ)料里出現(xiàn)的次數(shù);num表示語(yǔ)料里的總字?jǐn)?shù);avg(w1…wn)表示多字字符串不同組合的平均概率。改進(jìn)后的計(jì)算公式能夠計(jì)算多字詞語(yǔ)之間的點(diǎn)互信息,本文算法所使用的是多字點(diǎn)互信息。
兩個(gè)漢字是否能夠構(gòu)成一個(gè)詞語(yǔ),除了推斷漢字之間的結(jié)合程度外,詞語(yǔ)相鄰字的多樣性也是一個(gè)衡量標(biāo)準(zhǔn)。邊界自由度是指與一個(gè)字符串相鄰的所有字符種類(lèi)的數(shù)量。邊界自由度越大,表示字符串的相鄰字符集合中的字符類(lèi)別就越多,與該字符串相鄰的字符就越豐富多樣,那么該字符串的邊界就越明確,這個(gè)字符串成為詞語(yǔ)的可能性就越大。目前常用的外部統(tǒng)計(jì)量包括鄰接熵[18]和鄰接類(lèi)別[19](Accessor Variety,AV)。通過(guò)已有的對(duì)比方法發(fā)現(xiàn)鄰接熵比鄰接類(lèi)別的準(zhǔn)確率要高,所以大多數(shù)研究都是以信息熵作為衡量字符串成詞概率的外部統(tǒng)計(jì)量。
在新詞發(fā)現(xiàn)任務(wù)中,確定詞語(yǔ)的左邊界和右邊界的統(tǒng)計(jì)量通常是左右信息熵。一個(gè)候選詞組的左信息熵是指該候選詞組和與它左邊所有相鄰的字結(jié)合的信息熵之和,用來(lái)判斷該候選詞組的左鄰接字的多樣性。左信息熵越大,說(shuō)明該候選詞組左邊相鄰的字的種類(lèi)越多,那么該候選詞組成為某個(gè)詞語(yǔ)的左邊界的可能性越大;反之,左信息熵越小,該候選詞組左邊相鄰的字的種類(lèi)越少,它不是某個(gè)詞語(yǔ)的左邊界的情況就越肯定,那么就應(yīng)該對(duì)該候選詞組向左擴(kuò)展直到左邊界確定為止。式(5)為候選詞左信息熵的計(jì)算公式。
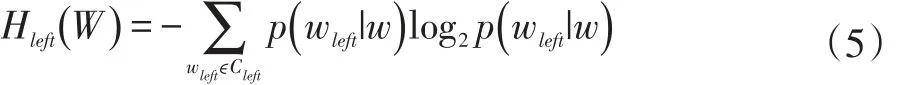
其中,Hleft(W)是候選詞語(yǔ)w的左信息熵,Cleft是候選詞w的左鄰接字集合,p(wleft|w)是候選詞w出現(xiàn)的情況下它左邊的鄰接字是wleft的條件概率。如果N(wleft)是左鄰接字wleft和候選詞w共同出現(xiàn)的概率,N(w)是候選詞w單獨(dú)出現(xiàn)的概率,p(wleft|w) 的計(jì)算公式如式(6)所示。

同理,右信息熵用來(lái)推斷詞語(yǔ)的右邊界,候選詞的右信息熵計(jì)算公式見(jiàn)式(7)。

其中,Hright(W) 是候選詞w的右信息熵,Cright是候選詞的w的右鄰接字集合,p(wright|w)是候選的詞w出現(xiàn)的情況下其右鄰接字是wright的條件概率。如果N(wright)是wright和w同時(shí)出現(xiàn)的概率,N(w)是w單獨(dú)出現(xiàn)的概率,那么p(wright|w)的計(jì)算公式見(jiàn)式(8)。

因此,若Hleft(W)大于指定的閾值,則左邊界確定;若Hright(W)大于制定的閾值,則右邊界確定[20]。
2 新詞合成算法
基于規(guī)則和統(tǒng)計(jì)的新詞發(fā)現(xiàn)是一種有效的新詞抽取方法,目前己經(jīng)提出了很多融合的方法,基于詞內(nèi)部凝結(jié)度和邊界自由度的新詞發(fā)現(xiàn)算法是目前比較常用的信息發(fā)掘方法,本文對(duì)該類(lèi)算法進(jìn)行了全面的分析,并基于此改進(jìn)了適合微博新詞發(fā)現(xiàn)的方法。
現(xiàn)有的多種基于詞內(nèi)部凝結(jié)度和邊界自由度的新詞發(fā)現(xiàn)算法之間的不同之處通常體現(xiàn)在候選詞串的選擇上。一種是通過(guò)N-gram算法對(duì)文本語(yǔ)料進(jìn)行切分,選擇頻率達(dá)到閾值并滿足條件的詞作為候選詞。N-gram算法最大的優(yōu)勢(shì)是具有語(yǔ)言無(wú)關(guān)性,不需要對(duì)文本語(yǔ)料進(jìn)行語(yǔ)法規(guī)則和專(zhuān)業(yè)詞典等語(yǔ)言學(xué)方面的處理,對(duì)于書(shū)寫(xiě)錯(cuò)誤也有很強(qiáng)的容錯(cuò)性。雖然N-gram算法簡(jiǎn)單易實(shí)現(xiàn),但是效率并不高,不適合針對(duì)規(guī)模較大的文本進(jìn)行新詞挖掘。另一種是利用分詞工具對(duì)文本語(yǔ)料進(jìn)行分詞,統(tǒng)計(jì)分詞后的文本中散串,針對(duì)散串進(jìn)行新詞發(fā)現(xiàn)。所謂散串,是指經(jīng)過(guò)分詞軟件分詞以后,連續(xù)多個(gè)單字(不包括標(biāo)點(diǎn)符號(hào))組成的字符串[16]。雖然大多數(shù)新詞都以散串的形式出現(xiàn),但是個(gè)別詞會(huì)被分詞工具切分成雙字或多字的形式,影響新詞識(shí)別的召回率。常用的新詞發(fā)現(xiàn)算法流程如圖1所示。
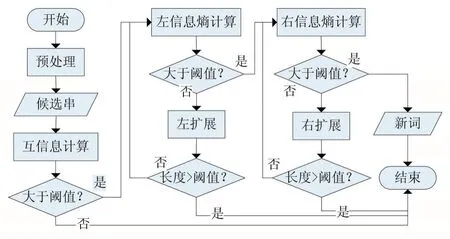
圖1 新詞合成算法流程
考慮到現(xiàn)有的基于詞內(nèi)部凝結(jié)度和邊界自由度的新詞發(fā)現(xiàn)算法存在的不足之處,為了改善更多新詞存在的情況以及對(duì)結(jié)合后的新詞內(nèi)凝聚度不充足的問(wèn)題,本文在NLPIR分詞工具[21]對(duì)已經(jīng)預(yù)處理好的語(yǔ)料進(jìn)行分詞后,采用改進(jìn)的新詞合成算法對(duì)全文進(jìn)行新詞發(fā)現(xiàn),改進(jìn)的新詞合成算法的算法流程如圖2所示。
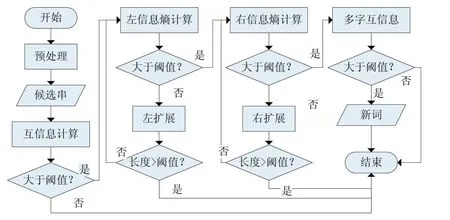
圖2 改進(jìn)新詞合成算法流程
3 實(shí)驗(yàn)結(jié)果及分析
①實(shí)驗(yàn)數(shù)據(jù)
語(yǔ)料:本實(shí)驗(yàn)選用的是NLPCC2014任務(wù)1提供的評(píng)測(cè)數(shù)據(jù),其中情緒表達(dá)抽取子任務(wù)的訓(xùn)練集包含1000條微博,共3454個(gè)句子;測(cè)試集包含10000條微博,共36005句。
符號(hào)過(guò)濾表:利用正則表達(dá)式從語(yǔ)料中挑選的標(biāo)點(diǎn)符號(hào)和特殊符號(hào)。
標(biāo)準(zhǔn)新詞集:從訓(xùn)練語(yǔ)料中人工抽取新詞,作為標(biāo)準(zhǔn)新詞集。在本研究任務(wù)中,新詞是指有一定使用頻率、被分詞工具切分錯(cuò)誤且不在常用詞典中的未登錄詞。本文人工標(biāo)注了該數(shù)據(jù)集中情緒表達(dá)抽取子任務(wù)訓(xùn)練集的新詞共150個(gè)。
工具:NLPIR分詞工具、Python3.6。
②評(píng)價(jià)指標(biāo)
對(duì)于新詞發(fā)現(xiàn)任務(wù)的訓(xùn)練集,采用PRF值即正確率(Precision)、召回率(Recall)和 F 值(F-measure)來(lái)評(píng)價(jià)各個(gè)新詞發(fā)現(xiàn)的性能,PRF計(jì)算公式如下:

其中,GN表示新詞發(fā)現(xiàn)方法正確識(shí)別出來(lái)的新詞個(gè)數(shù),N表示新詞發(fā)現(xiàn)方法識(shí)別出的詞語(yǔ)總數(shù),M表示在語(yǔ)料中人工標(biāo)注的新詞總數(shù)。
③新詞合成算法對(duì)比實(shí)驗(yàn)
根據(jù)上一部分實(shí)驗(yàn)的分析,在語(yǔ)料庫(kù)上進(jìn)行實(shí)驗(yàn),將點(diǎn)互信息與鄰接熵結(jié)合的新詞發(fā)現(xiàn)作為基線(PMI+BE)實(shí)驗(yàn),對(duì)比多字點(diǎn)互信息與鄰接熵結(jié)合的新詞發(fā)現(xiàn)(nPMI+BE,即本文方法)進(jìn)行對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表所示。
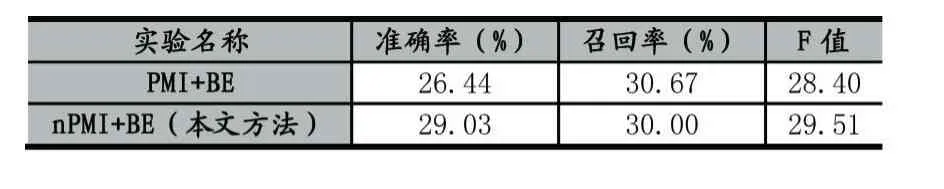
表1 新詞合成算法對(duì)比實(shí)驗(yàn)
實(shí)驗(yàn)結(jié)果分析:通過(guò)改變點(diǎn)互信息可以提高微博新詞的識(shí)別精度。本文在進(jìn)行左信息熵和右信息熵計(jì)算之后,對(duì)擴(kuò)展的候選詞進(jìn)行二次互信息計(jì)算,可以得到詞內(nèi)凝聚度更高的候選新詞,減少因成詞概率低導(dǎo)致的錯(cuò)誤結(jié)合,一定程度上提高了新詞識(shí)別的準(zhǔn)確率。
4 結(jié)語(yǔ)
本文就微博新詞發(fā)現(xiàn)和新詞的情感極性判斷問(wèn)題進(jìn)行了研究,首先分析了現(xiàn)有新詞發(fā)現(xiàn)方法仍存在的問(wèn)題,針對(duì)被分詞工具錯(cuò)分成多個(gè)詞的新詞,結(jié)合多字點(diǎn)互信息和左右鄰接熵以及本文改進(jìn)的新詞合成算法對(duì)相鄰詞進(jìn)行合并,得到候選新詞;再對(duì)候選新詞集合進(jìn)行低頻詞、首尾停用詞、構(gòu)詞規(guī)則、常用詞典等規(guī)則與統(tǒng)計(jì)相結(jié)合的過(guò)濾方法,去除不符合要求的字符串,最后得到新詞集合。并通過(guò)在NLPCC2014會(huì)議任務(wù)提供的評(píng)測(cè)數(shù)據(jù)上的新詞發(fā)現(xiàn)對(duì)比實(shí)驗(yàn)驗(yàn)證了該方法的可行性和有效性。但同時(shí),本文方法還有一些需要改進(jìn)的地方,可以深入分析新詞識(shí)別中的結(jié)果錯(cuò)誤,多角度分析與總結(jié)結(jié)合錯(cuò)誤的字符串的特點(diǎn)與規(guī)律,找到更通用的過(guò)濾方法。發(fā)掘更多的統(tǒng)計(jì)量特征,提出新的統(tǒng)計(jì)算法,找到有效的方法實(shí)現(xiàn)對(duì)新詞快速準(zhǔn)確的抽取,以及探尋新的新詞發(fā)現(xiàn)方法,提高新詞發(fā)現(xiàn)的效率。
參考文獻(xiàn):
[1]Ling G C,Asahara M,Matsumoto Y.Chinese Unknown Word Identification Using Character-Based Tagging and Chunking[J].Proceedings of Annual Meeting on Association for Computational Linguistics,2003:197-200.
[2]鄒綱,劉洋,劉群,等.面向 Internet的中文新詞語(yǔ)檢測(cè)[J].中文信息學(xué)報(bào),2004,18(6):1-9.
[3]孫立遠(yuǎn),周亞?wèn)|,管曉宏.利用信息傳播特性的中文網(wǎng)絡(luò)新詞發(fā)現(xiàn)方法[J].西安交通大學(xué)學(xué)報(bào),2015,49(12):59-64.
[4]Du Y,Yuan H,Qian Y.A Word Vector Representation Based Method for New Words Discovery in Massive Text[J].Springer International Publishing,2016,10102:76-88.
[5]唐波,陳光,王星雅,王非,陳小慧.微博新詞發(fā)現(xiàn)及情感極性判斷分析[J].山東大學(xué)學(xué)報(bào)(理學(xué)版),2015,50(01):20-25.
[6]鄭家恒,李文花.基于構(gòu)詞法的網(wǎng)絡(luò)新詞自動(dòng)識(shí)別初探[J].山西大學(xué)學(xué)報(bào)(自然科學(xué)版),2002(02):115-119.
[7]Su Q L,Liu B Q.Chinese New Word Extraction from MicroBlog Data[C].International Conference on Machine Learning and Cybernetics.IEEE,2014:1874-1879.
[8]夭榮朋,許國(guó)艷,宋健.基于改進(jìn)互信息和鄰接熵的微博新詞發(fā)現(xiàn)方法[J].計(jì)算機(jī)應(yīng)用,2016,36(10):2772-2776.
[9]梁韜,張瑞.基于詞語(yǔ)條件信息量的新詞發(fā)現(xiàn)[J].電子技術(shù)與軟件工程,2014,(11):181-182.
[10]邢恩軍,趙富強(qiáng).基于上下文詞頻詞匯量指標(biāo)的新詞發(fā)現(xiàn)方法[J].計(jì)算機(jī)應(yīng)用與軟件,2016,33(6):64-67.
[11]張華平,商建云.面向社會(huì)媒體的開(kāi)放領(lǐng)域新詞發(fā)現(xiàn)[J].中文信息學(xué)報(bào),2017,31(03):55-61.
[12]周霜霜,徐金安,陳鈺楓,張玉潔.融合規(guī)則與統(tǒng)計(jì)的微博新詞發(fā)現(xiàn)方法[J].計(jì)算機(jī)應(yīng)用,2017,37(04):1044-1050.
[13]Chen F,Liu YQ,Wei C,Zhang YL,Zhang M,Ma SP.Open Domain New Word Detection Using Condition Random Field Method.Journal of Software,2013,24(5):1051-1060(in Chinese).
[14]雷一鳴,劉勇,霍華.面向網(wǎng)絡(luò)語(yǔ)言基于微博語(yǔ)料的新詞發(fā)現(xiàn)方法[J].計(jì)算機(jī)工程與設(shè)計(jì),2017,38(03):789-794.
[15]周超,嚴(yán)馨,余正濤,洪旭東,線巖團(tuán).融合詞頻特性及鄰接變化數(shù)的微博新詞識(shí)別[J].山東大學(xué)學(xué)報(bào)(理學(xué)版),2015,50(03):6-10.[16]李文坤,張仰森,陳若愚.基于詞內(nèi)部結(jié)合度和邊界自由度的新詞發(fā)現(xiàn)[J].計(jì)算機(jī)應(yīng)用研究,2015,32(8):2302-2304.
[17]Ye Y.M,Wu Q.Y,Li Y,et al.Unknown Chinese Word Extraction Based on variety of Overlapping Strings[J].Information Processing&Management,2013,49(2):497-512.
[18]Huang J H,Powers D.Chinese Word Segmentation Based on Contextual Entropy[C].Proceedings of the 17th Asian Pacific Conference on Language Information and Computation,2003:152-158.
[19]Feng H,Chen K,Deng X,et al.Accessor Variety Criteria for Chinese Word Extraction[J].Computational Linguistics,2004,30(1):75-93.
[20]Thomas M.Cover,Joy A.Thomas著.信息論基礎(chǔ)(原書(shū)第2版)[M].阮吉壽,張華譯.北京:機(jī)械工業(yè)出版社,2007:9-16.
[21]張華平.漢語(yǔ)分詞系統(tǒng)[EB/OL].http://www.nlpir.org/.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫(huà)報(bào)(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫(huà)報(bào)(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
