基于自動化測試的反爬蟲技術研究
——以天貓平臺為例
2018-05-18 05:52:01曹文斌張科靜
現代計算機 2018年11期
關鍵詞:程序
曹文斌,張科靜
(東華大學旭日工商管理學院,長寧 200051)
0 引言
伴隨著互聯網信息技術的發展,特別是UGC(User Generate Content)技術的興起,互聯網上信息呈現爆發式增長,各類信息雜亂交錯地分散在各大平臺。有效地收集整理這些多維、非結構化數據,是各大科研機構、互聯公司實現挖掘算法、挖掘“數據資產”的首要前提。
通過傳統的爬蟲機制,自定義數據獲取規則,能夠在一定程度上滿足個性化需求、獲得主題相關的數據,這在過去能夠滿足大部分的科研和生成的需求。然而,近年來社會步入大數據時代,越來越多的大平臺公司意識到數據是一家公司的重要資產。越來越多的公司投入大量的人力和物力構建反爬蟲屏障,通過反爬蟲技術區分正常使用的用戶訪問請求和通過爬蟲軟件密集地、反復地、大批量地訪問請求。因此,通過傳統的爬蟲手段獲取數據越來越困難,如何繞開這些反爬蟲的限制是快速獲取批量數據的一個難題。
本研究結合自動化測試技術和天貓平臺的搜索引擎,不僅克服了天貓平臺反爬蟲機制帶來的各種障礙,而且獲取的數據相關度較傳統的爬蟲手段獲取的數據要高。同時通過分析JSON數據結構,獲取的數據維度超過傳統的搜索引擎獲取的數據維度。數據的“多維性”對數據的進一步挖掘分析具有重要的作用。
1 爬蟲軟件的通常思路
網絡爬蟲(Web Crawler)是一種能夠根據事先設定的規則,自動地在網絡上像蜘蛛網絡一樣擴展并采集數據的運用程序或網頁腳本。人們也形象稱之為網絡蜘蛛,該程序能夠向蜘蛛織網一樣不斷擴展網頁鏈接,并遍歷采集網頁內容,是搜索引擎中必不可少的組成部分。爬蟲程序信息采集過程一般是從一個初始超鏈接(URL)集合,又稱種子集合開始,首先把種子集合放入待抓取數據的任務隊列中,再根據事先設定好的規則從中取出并訪問超鏈接,遍歷超鏈接指向的網頁分析提取數據,同時若發現新的鏈接則提取該鏈接放入待抓取數據的任務隊列中。再按規則取出任務隊列中的下一個鏈接,如此循環往復直至任務隊列為空或者滿足設定的終止條件,實現遍歷“蜘蛛網”的效果[1-2]。網絡爬蟲可以大致分為四種,分別是:聚焦網絡爬蟲、深層網絡爬蟲、增量式網絡爬蟲、通用網絡爬蟲四種,本課題的研究是一種增量式網絡爬蟲。增量式網絡爬蟲(Incremental Web Crawler)僅對已遍歷過的網頁中最新變動(產生新的內容或已有內容的更新)的部分進行數據分析提取,達到增量式效果[3],相對于通用型爬蟲程序具有更強的針對性,降低了訪問的盲目性。本課題每次爬取時僅抓取新增最近的新評論,避免抓取以前下載過的評論。
隨著信息技術的蓬勃發展,出現了各類爬蟲工具、爬蟲算法,各類爬蟲技術都有自身的特點,“以假亂真”的策略也很多,如模擬登錄、動態IP等,但爬蟲程序抓取數據的過程基本思路大體如圖1所示:
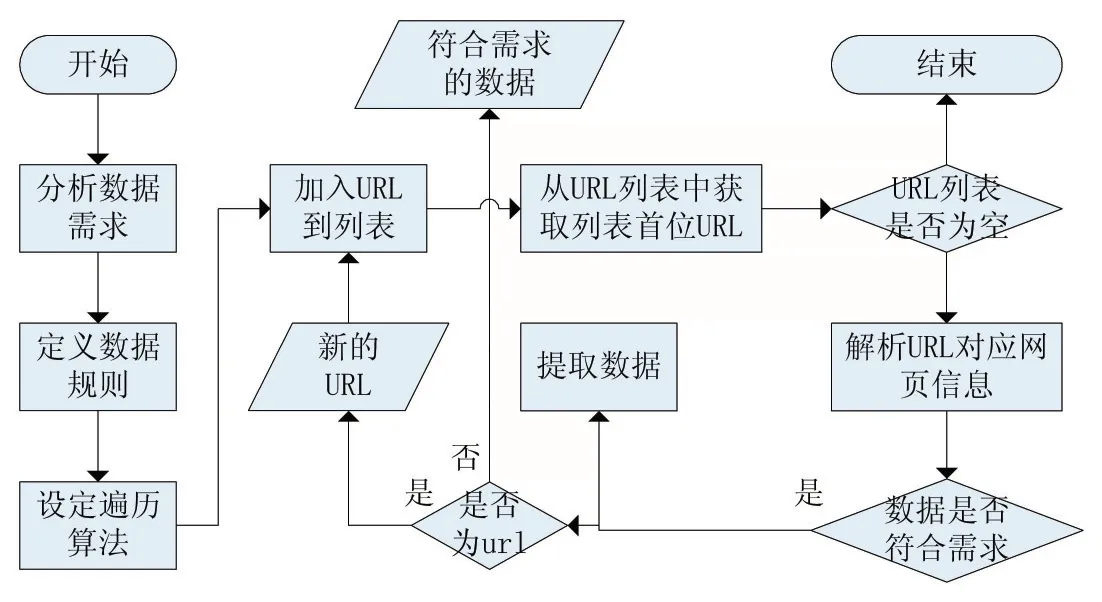
圖1 爬蟲機制的通常思路
(1)首先要調研了解數據需求。爬蟲是一個自動擴展遍歷網頁的過程,而網頁上的信息通常是多種多樣的、非結構化的,因此先要了解需求即明確爬蟲方向;
(2)根據步驟(1)中的需求定義數據規則。在本課題中是試用正則表達式來定義需求數據的規則,正則表達式是由一些特定的字符組成的規則字符串,規則字符串可以對網頁文本進行查找匹配、過濾篩選得到想要的數據;
(3)設定遍歷搜索的規則。爬蟲的本質是一次查找遍歷過程,遍歷的算法通常有深度優先、廣度優先等算法。我們可以把所有的網頁布局當作一幅有向圖,每個網頁相對于一個節點,超鏈接相對于有向圖的邊。這樣就能根據圖的深度優先或者圖的廣度優先進行遍歷搜索,在本課題中采用的是廣度優先搜素規則;
(4)根據數據規則匹配網頁文本。這是整個過程中最為核心的步驟,根據步驟(2)中定義的數據規則去查找網頁中的內容,匹配到的數據若為需要的數據,則提取存儲到本地數據庫里面。若為新的超鏈接,則把新發現的超鏈接加入到URL列表中,這樣就能像蜘蛛一樣展開。
2.1 置管部位 13例患兒均選擇頭部顳淺靜脈進行置管,其中經右側顳淺靜脈置管者10例,經左側顳淺靜脈置管者3例。
2 天貓反爬蟲機制阻擾
反爬蟲是使用相應的信息技術措施,阻止爬蟲程序批量獲取自己網站信息的一種方式。爬蟲和反爬蟲機制是一個對立統一的關系,相互依存、相互作用、相互轉換。反爬蟲機制因爬蟲技術而起,反爬蟲機制是應對爬蟲技術,進行數據保護的措施。在實踐過程中,爬蟲和反爬蟲技術相互促進,爬蟲技術的改進必然會驅使人類探究新的反爬蟲技術;同樣,新的反爬蟲技術出現必然促使數據保護方研究新的反爬蟲技術。
經實驗觀察發現,阿里巴巴天貓商城平臺基于安全考慮,相對于京東商城而言,平臺數據保護措施更為嚴格。在目前階段,各大電子商務平臺甚至包括國內在線旅行社OTA(Online Travel Agent)平臺、O2O平臺中,天貓商城平臺數據保護措施是最為嚴格的。主要有以下幾點:
(1)能夠通過鼠標操作路徑等方式區分真實用戶和爬蟲程序的訪問;
(2)對不同重要性的信息設置了不同級別的安全應對機制;
(3)能夠有選擇性地開放給搜索引擎(如百度、谷歌)檢索,百度公司都不能全面抓取天貓到的商品信息;
(4)天貓平臺對于關鍵信息,如評論、品屬性信息和搜索返回信息保護極為嚴格,都是動態生成數據,返回瀏覽器經過瀏覽器解析才行。返回的結果不能直接顯示在網頁上,需要在瀏覽器本地執行JavaScript發送請求到服務器,再返回JavaScript再瀏覽器本地執行,多次輪回執行結果拼裝組合而成。
3 自動化測試Selenium
自動化測試,就是再總結測試人員日常操作之后設計開發程序或者在測試工具中設定規則,啟動程序或工具能夠模擬人的操作,進而控制測試過程中的各種對象和類,達到輔助測試的效果,減輕測試人員的重復性工作[4]。軟件自動化測試能大大提高生產效率,提高測試的覆蓋率及可靠性,是手工測試的一種有益的補充。
(1)仿真性強,能夠像真實用戶操作一樣,直接在瀏覽器中運行;
(2)使用方便,提供API接口,供Java等多種高級程序設計語言調用;
(3)Selenium核心browser bot是用JavaScript實現的,有助于避開反爬蟲技術的限制。
本課題在充分了解天貓反爬蟲機制之后,結合瀏覽器自動化測試框架Selenium,編寫的Java評論采集程序,達到了模擬人的操作瀏覽器的效果。能夠通過Java程序自如地啟動關閉瀏覽器、切換瀏覽的網頁、輸入數據到網頁控件中、點擊網頁上的按鈕等操作,通過瀏覽器自如地和天貓平臺進行數據交互。
4 評論數據并發的獲取
本課題編寫的Java評論采集程序,突破了反爬蟲技術限制,解決了批量評論采集的難題。程序的運行邏輯如圖2所示:
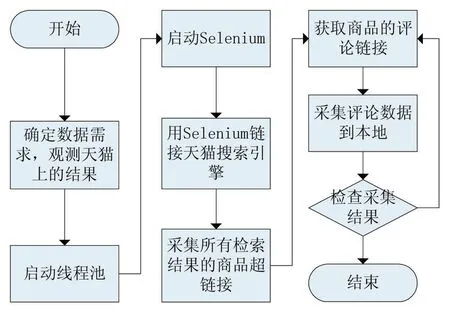
圖2 基于Selenium并發分布式抓取數據
第1步:首先在天貓上搜索目標商品,并記錄搜索結果頁碼數量和顯示搜索結果的URL。搜索結果的URL含有搜索關鍵詞信息和搜索結果顯示頁面的頁碼序號,根據頁碼遞增能夠遍歷所有的搜索結果;
第2步:把第一步記錄的URL和總頁碼數設置為程序參數,并根據需要采集數據量的大小設置線程池的最大線程數量,啟動程序運行;
第3步:保存搜索引擎搜索的結果。程序會啟動Selenium像人工操作一樣快速遍歷所有搜索結果,并記錄每個搜索結果商品的URL、單價、評價數、月銷售量,保持至本地數據庫;
第4步:根據搜索結果采集評論。根據第3步采集的商品URL采集該商品的評論,保持至本地數據庫。返回的評論數據是JSON類型,里面包含的商品評論屬性主要包括三大部分,分別是評論屬性集、顧客屬性集、交易屬性集。
5 評論數據的采集結果
本課題研究的實例是阿里巴巴天貓平臺,設計的程序在天貓上采集的每條網絡購物評論數據包含38個屬性,這些屬性可分為3個部分,評論屬性集、顧客屬性集、交易屬性集。每個屬性集的主要信息如下面的列表:
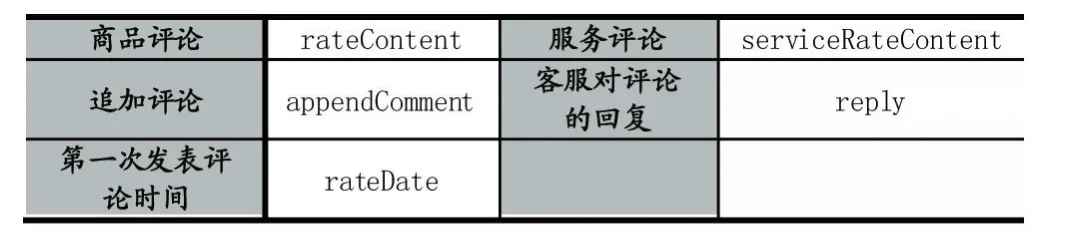
表1 基于Selenium的網絡評論采集結果之評論屬性集
商品評論是顧客對于商品本身體驗發表的意見觀點;服務評論是顧客對于購買商品過程的服務體驗點評,如對物流、客服等評價。商品評論、服務評論、追加評論、客服對評論回復是非結構化文本數據,其他屬性都是結構化數據。

表2 基于Selenium的網絡評論采集結果之顧客屬性集
顧客昵稱是網購商品評論區列表上顯示的評論用品昵稱。顧客等級對進一步挖掘評論數據的價值具有重要的意義,既可以按評論等級篩選數據,也可以研究不同等級下的用戶評論特征。

表3 基于Selenium的網絡評論采集結果之交易屬性集
交易結束時間是指顧客確認收貨的時間,可以根據這個屬性分析評論對象隨時間的變化;選購商品的屬性是指顧客購買商品時選擇的屬性,如購買衣服時選擇的款式、尺寸、顏色等屬性,可以通過該屬性分析不同顏色、款式的受歡迎程度。
6 結語
本課題研究在充分實驗觀察了天貓平臺頁面結構,了解了爬蟲和反爬蟲的機制后,結合自動化測試框架,構建了天貓平臺評論數據抓取的解決方案,并由Java高級程序設計語言實現了該方案,解決了反爬蟲機制封鎖的難題,獲得了38維的高維評論數據。該解決方案具有普遍的適用性,稍做調整即可用于其他互聯網平臺的數據抓取。本課題研究也有些值得進一步深入研究的地方,如何在抓取的海量評論數據基礎上,結合數據挖掘等相關領域的研究進行文本分析,挖掘出評論中的商業價值。
參考文獻:
[1]J.Cho.Crawling the web:Discovery and Maintenance of Large-scale Web Data[D].L.A.:Stanford University,2001.
[2]于娟,劉強.主題網絡爬蟲研究綜述[J].計算機工程與科學,2015,37(02):231-237.
[3]孟慶浩,王晶,沈奇威.基于Heritrix的增量式爬蟲設計與實現[J].電信技術,2014,(09):97-98+101+99-100.
[4]宋波,張忠能.基于系統功能測試的軟件自動化測試可行性分析[J].計算機應用與軟件,2005,22(12):31-33.
猜你喜歡
電腦愛好者(2020年6期)2020-05-26 09:27:33
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
信息安全與通信保密(2016年3期)2016-08-23 01:23:56
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:34
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:25
中國衛生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
