高鐵列車停靠站客票收入率分類及收入預(yù)測研究
2018-04-27 06:38:58朱建生呂曉艷賈新茹王煒煒中國鐵道科學(xué)研究院研究生部北京0008中國鐵道科學(xué)研究院電子計(jì)算技術(shù)研究所北京0008
鐵道學(xué)報(bào) 2018年3期
關(guān)鍵詞:分類
張 永, 朱建生, 呂曉艷, 賈新茹, 王煒煒(. 中國鐵道科學(xué)研究院 研究生部, 北京 0008; . 中國鐵道科學(xué)研究院 電子計(jì)算技術(shù)研究所, 北京 0008)
在鐵路實(shí)際客票收入清算工作中,管理部門依據(jù)列車歷史收入情況估算出新的運(yùn)行圖中列車各分站客票收入,作為這個鐵路局下一階段的收入目標(biāo)。同時,為了使各站收入目標(biāo)具有說服力,管理部門會依據(jù)列車和其停靠站屬性設(shè)計(jì)決策表,明確標(biāo)注不同屬性組合的列車的停靠站收入情況。
在清算系統(tǒng)設(shè)計(jì)過程中并未考慮上述功能[1-5],只是根據(jù)清算指標(biāo)和運(yùn)營數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析。在現(xiàn)有的客票收入影響因素分析和預(yù)測的研究中[6-8],研究者通過影響列車整體客票收入的因素對未來收入進(jìn)行經(jīng)驗(yàn)推測或簡單的回歸計(jì)算,沒有考慮列車分站信息對收入的影響,也沒有考慮將這些信息進(jìn)行歸納和分類。因此在決策表構(gòu)建過程中會出現(xiàn)如下問題:首先目前對與分站收入相關(guān)的信息進(jìn)行離散化處理時,使用等頻或人工干預(yù)方法,易造成大量數(shù)據(jù)不一致現(xiàn)象,影響預(yù)測結(jié)果;另外傳統(tǒng)做法不能從離散化的分類結(jié)果中得到準(zhǔn)確合理的收入率取值,無法滿足業(yè)務(wù)需求。本文利用2016年1月至10月中國鐵路總公司下發(fā)的客運(yùn)運(yùn)行圖中直通高鐵列車分站信息,提出高鐵列車停靠站客票收入率分類及客票收入預(yù)測模型,并以2016年11月新運(yùn)行圖中的高鐵列車各停站日均客票收入率及其沿途各站所屬鐵路局收入總和為校驗(yàn)數(shù)據(jù),驗(yàn)證了本文方法的分類及預(yù)測精度。
1 數(shù)據(jù)的離散化處理
第i趟列車日均客票總收入為Pi(i=1,2,…,N),其中N為總開行列車數(shù)。分站收入為pij(j=1,2,…,Ki)其中Ki為第i趟列車的總停站個數(shù)。則列車停靠站收入率ri為
ri=pij/Pi
( 1 )
目前鐵路客票營銷系統(tǒng)中與高鐵列車停靠站收入率相關(guān)的信息有4個:停靠站距終到站距離、停靠站等級(停靠站日均發(fā)送量)、停靠站站序和列車離開停靠站時刻。將這4類影響因素作為因素變量,將客票收入率作為目標(biāo)變量。為滿足分類算法要求,需要將上述連續(xù)變量離散化,同時,數(shù)據(jù)離散化可以有效克服數(shù)據(jù)中隱藏的缺陷,避免極端值影響結(jié)果。
離散化算法分為無監(jiān)督和有監(jiān)督算法[9]。這兩種算法主要的區(qū)別是有監(jiān)督算法在進(jìn)行離散化的過程中參考了目標(biāo)變量,無監(jiān)督算法則沒有。無監(jiān)督離散化算法有等頻、WPKID和基于聚類的算法等;有監(jiān)督學(xué)習(xí)算法有CACC算法、ChiMerge算法、Hellinger算法和基于信息熵的離散化算法等。
1.1 目標(biāo)變量離散化
目標(biāo)變量只能通過無監(jiān)督算法進(jìn)行離散化,但是上述無監(jiān)督離散化算法忽略了數(shù)據(jù)分布信息,區(qū)間邊界的確定不具有代表性,會影響因素?cái)?shù)據(jù)進(jìn)行監(jiān)督離散化處理的過程中切分點(diǎn)的確定。對于上述問題,本文提出一種基于K-means和類-屬性相關(guān)離散化[10]CACC(Class-Attribute Contingency Coefficient)算法的無監(jiān)督離散化模型,K-means-CACC模型。CACC是一個自底向上的算法,它充分考慮了數(shù)據(jù)的分布,通過下式,計(jì)算各個待選區(qū)間中目標(biāo)變量分布的相關(guān)性
( 2 )
式中:M為樣本總數(shù);n為切分區(qū)間的個數(shù);qir為目標(biāo)變量第i類,切分區(qū)間[dr-1,dr]中的樣本數(shù);Mi+為目標(biāo)變量i中的樣本數(shù);M+r為切分區(qū)間[dr-1,dr]中的樣本數(shù);S為目標(biāo)變量分類個數(shù)。算法具體步驟
Step1將待切分連續(xù)數(shù)據(jù)集升序排序,將相鄰點(diǎn)的中值作為備選切分點(diǎn)放入集合B中;切分點(diǎn)結(jié)果集為D。設(shè)置全局CACC相關(guān)性變量,記為G,其初始值為0;設(shè)置最大切分點(diǎn)個數(shù)為M/(3·S)。
Step2迭代階段:如果B中切分點(diǎn)不在D中,根據(jù)式( 2 )計(jì)算此點(diǎn)切分點(diǎn)兩側(cè)區(qū)間的相關(guān)性。將相關(guān)性最大的切分點(diǎn)插入到D中,并且將此相關(guān)性結(jié)果更新到全局變量G。
Step3當(dāng)Step2中計(jì)算的相關(guān)性結(jié)果不再變化或者切分點(diǎn)個數(shù)大于等于設(shè)置的最大切分點(diǎn)時,算法結(jié)束。
模型的主要思想和流程如下:首先,將收入率進(jìn)行等寬分割,本文中選取的寬度為0.01。然后,將收入率切分點(diǎn)與在這個范圍內(nèi)的樣本密度作為輸入,利用K-means進(jìn)行聚類,這樣有利于將具有不同數(shù)據(jù)密度的收入率區(qū)間區(qū)分開來。利用calinski-harabasz[11]指數(shù)確定K值,此指數(shù)從簇內(nèi)的稠密度和簇間的離散度來評估聚類的效果,指數(shù)最大值所對應(yīng)的聚類個數(shù)為最優(yōu)聚類個數(shù)。本文運(yùn)用Python2.7和science-kit機(jī)器學(xué)習(xí)算法包分別實(shí)現(xiàn)CACC算法和K-means算法。
聚類結(jié)束后,將所得到的聚類標(biāo)簽和收入率作為CACC的輸入,這是對聚類結(jié)果的一次修正,使其聚類邊界更加明確,這可以保證收入率與聚類標(biāo)簽相關(guān)性最大的被劃分為一組。表1為目標(biāo)變量離散化結(jié)果。
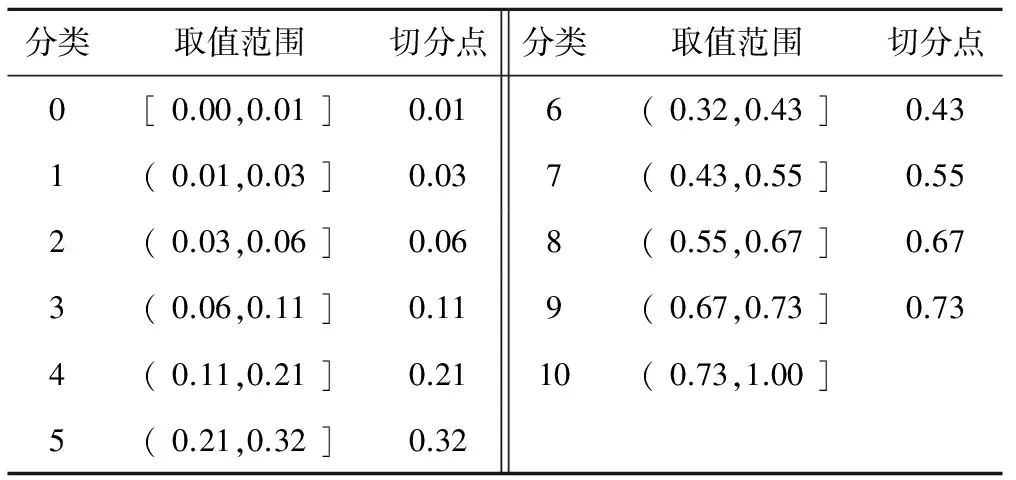
表1 目標(biāo)變量離散化結(jié)果及切分點(diǎn)
1.2 因素變量離散化
根據(jù)目標(biāo)變量離散化結(jié)果,采用CACC[10]算法可對因素?cái)?shù)據(jù)進(jìn)行監(jiān)督的離散化,該算法被證明在后續(xù)的決策樹算法中準(zhǔn)確率更高[9]。
在對因素?cái)?shù)據(jù)進(jìn)行離散化處理之前,先處理列車離開停靠站時間這一數(shù)據(jù):過了整點(diǎn)沒有到半點(diǎn)的時刻,如08:13,記為8.5;而過了半點(diǎn)沒到整點(diǎn)的時刻,如08:57,記為9。表2為因素?cái)?shù)據(jù)離散化結(jié)果。
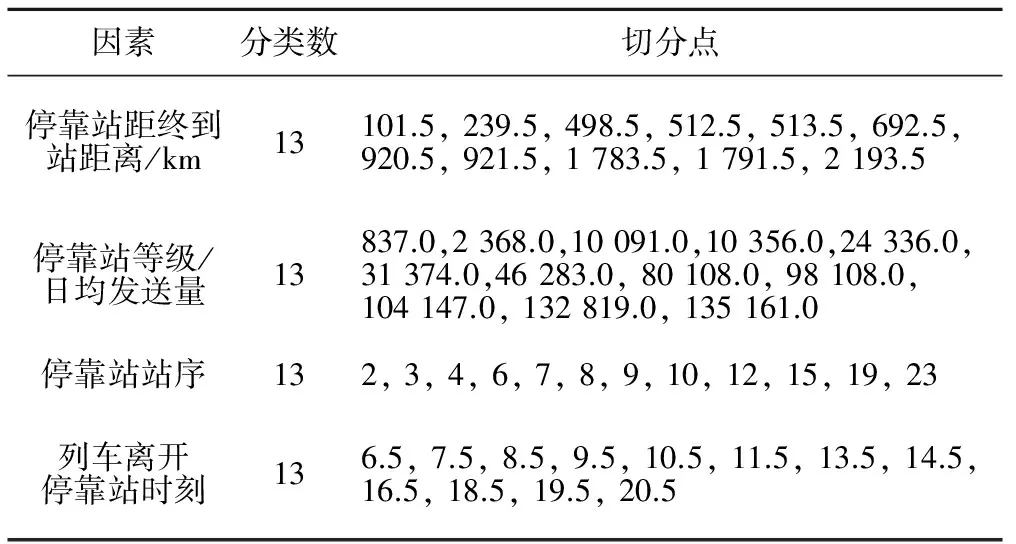
表2 高鐵列車因素變量離散化結(jié)果及切分點(diǎn)
2 基于誤差區(qū)間交集和樣本密度的最優(yōu)收入率選取
為滿足業(yè)務(wù)部門需求,還需在每個收入率分類中,選取能滿足一定誤差范圍的最優(yōu)收入率準(zhǔn)確取值,這一取值應(yīng)使一個分類中,在誤差范圍內(nèi)樣本數(shù)達(dá)到最大。本文設(shè)計(jì)了一個基于誤差區(qū)間交集和樣本密度的最優(yōu)收入率選取算法,其在給定的誤差范圍內(nèi),計(jì)算每個類中每個值的誤差范圍,并對它們進(jìn)行交集運(yùn)算,統(tǒng)計(jì)其中的樣本數(shù),最終得到數(shù)據(jù)密度最大的區(qū)間,計(jì)算其中值,便可以得到這個最優(yōu)值。具體來說,設(shè)在第k個收入率分類中,對應(yīng)N個實(shí)際收入率,即y0,k,y1,k,…,yj,k,…,yN,k和對應(yīng)收入率的樣本個數(shù)m0,k,m1,k,…,mj,k,…,mN,k,每一個收入率都存在一個值x0,k,x1,k,…,xj,k,…,xN,k,使得其在誤差范圍[b,a]內(nèi),滿足相對誤差,即
b≤xj,k-yj,k≤a
( 3 )
得x0,k,x1,k,…,xj,k,…,xN,k滿足如下集合
A={xj,k|xj,k∈[b+yj,k,a+yj,k]}
( 4 )
顯然如果兩個集合存在交集,則滿足交集部分的取值覆蓋了兩個集合所有的樣本數(shù)。因此,在一個目標(biāo)變量分類中,只需要計(jì)算式( 4 )中各個取值區(qū)間的交集中覆蓋收入率樣本密度最大的那個交集即可。算法步驟為:
Step1第一重迭代開始,在{A0,k,A1,k,…,Aj,k,…,AN,k}中逐次取Aj,k;
Step2Aj,k為此次迭代的初始化交集初始集合;
Step3計(jì)數(shù)器初始化為集合Aj,k所對應(yīng)的樣本數(shù);
Step4i=j+1;
Step5第二重迭代開始,在{Ai,k,…,AN,k}中取Ai,k;
Step6初始集合Ai,k的交集存在,則用交集更新初始化集合,計(jì)數(shù)器累加所對應(yīng)的樣本數(shù)Nj,k;
Step7更新和保存計(jì)數(shù)器值最大的交集;
Step8第二重迭代結(jié)束后,計(jì)數(shù)器歸零,返回Step1;
Step9所有迭代結(jié)束后,得到一個交集的集合,如果初始化時每個收入率對應(yīng)的樣本數(shù)相同,且計(jì)數(shù)器最終得到的值也為這個樣本數(shù),則表明在誤差范圍內(nèi)數(shù)據(jù)無交集,計(jì)數(shù)器沒有累加,最優(yōu)值為全部數(shù)據(jù)的均值;否則,利用交集覆蓋的區(qū)間樣本數(shù)除以它所覆蓋區(qū)間的長度得到樣本密度,樣本密度最大的為最優(yōu)值所在的交集,本文取中值為最優(yōu)值。
利用訓(xùn)練集計(jì)算出每個分類對應(yīng)的最優(yōu)值,當(dāng)利用測試集進(jìn)行驗(yàn)證時,使預(yù)測分類與這些最優(yōu)值相對應(yīng),這樣不僅可以為決策者提供一個參考的分類(離散化后為收入率取值范圍),也為其提供了一個參考的收入率取值。本文利用Python2.7實(shí)現(xiàn)上述算法,并根據(jù)業(yè)務(wù)需求將誤差設(shè)定為[-5%,5%]。表4為最優(yōu)收入率的選取結(jié)果。
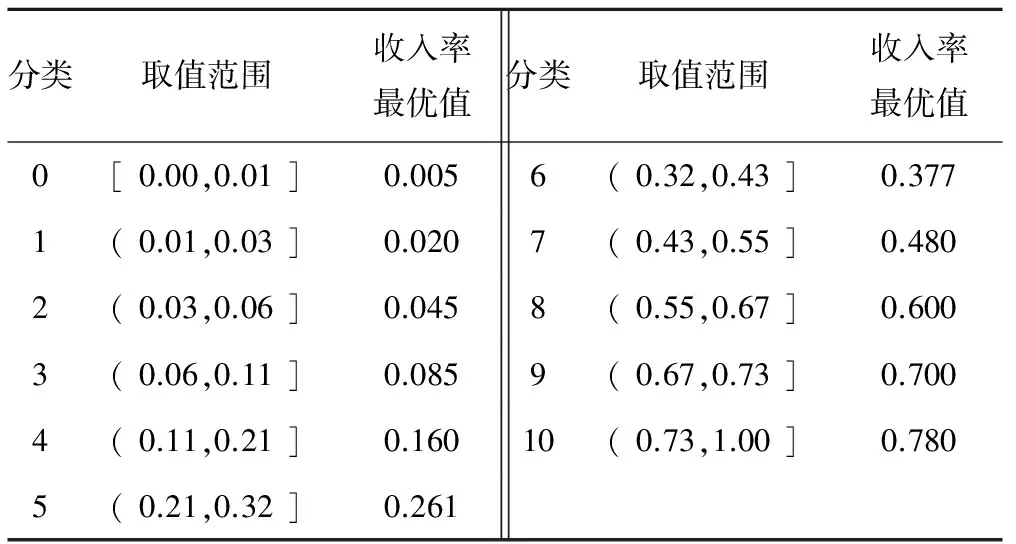
表4 每類中最優(yōu)收入率選取結(jié)果
3 隨機(jī)森林算法
隨機(jī)森林算法是由Leo Breiman[12]于2001年提出來的。這個算法主要是通過隨機(jī)重采樣技術(shù)bootstrap進(jìn)行行采樣和隨機(jī)子空間的思想進(jìn)行特征的選取,構(gòu)建多個互相沒有關(guān)聯(lián)的決策樹,通過投票得到最終分類結(jié)果。具體算法流程為:
Step1當(dāng)訓(xùn)練集進(jìn)入算法之前,利用bootstrap方法進(jìn)行行隨機(jī)采樣,對于大小為N的樣本,隨機(jī)地有放回地選取大小為k(k?N)的樣本,隨機(jī)選取多個這樣的樣本就構(gòu)建多個決策樹。
Step2在全部的M個特征中,每一顆樹的每一個節(jié)點(diǎn)隨機(jī)抽取m(m?M)作為決策樹的決策屬性,每次樹進(jìn)行分裂時,從這m個特征中選擇最優(yōu)的。
Step3利用決策樹算法C4.5[13]對每棵決策樹進(jìn)行分類,使決策樹進(jìn)行最大限度的增長,不做任何剪枝操作。使用C4.5算法的主要原因是,其利用信息增益率進(jìn)行節(jié)點(diǎn)的分裂,防止了選擇屬性時偏向選擇取值多的屬性的不足。
Step4將生成的多棵分類樹組成隨機(jī)森林,用隨機(jī)森林算法分類器對新的數(shù)據(jù)進(jìn)行判別與分類,分類結(jié)果按樹分類器的投票多少而定。分類器投票式為
( 5 )
式中:H(x)為組合分類模型;hi(x)為單個決策樹模型;Y為目標(biāo)變量;I(·)為示性函數(shù)。
本文將前面訓(xùn)練集中因素和目標(biāo)變量離散化的結(jié)果作為隨機(jī)森林算法的輸入,構(gòu)建一個分類模型。測試集因素變量離散化結(jié)果輸入到模型,得到預(yù)測分類結(jié)果。
在分類模型的構(gòu)建過程中,筆者還計(jì)算了輸入因素的重要性。在每次構(gòu)建決策樹后利用未被選中的樣本進(jìn)行預(yù)測,得到誤差ri;之后加入未被選中的因素加入決策樹,利用同樣的樣本進(jìn)行預(yù)測,得到誤差rj;則因素重要性指數(shù)I為(ntree為決策樹的個數(shù))
I=∑(ri-rj)/ntree
( 6 )
經(jīng)過計(jì)算,可以得到4個因素的重要性排名,見表5。
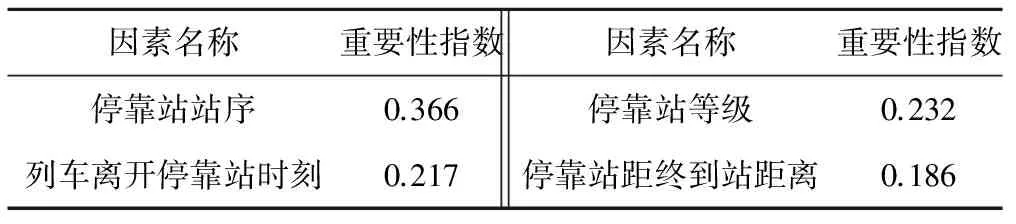
表5 因素重要性排名
由表5可知停靠站站序?qū)τ谑杖肼史诸惖挠绊懽畲螅浯问峭?空镜燃壓土熊囯x開停靠站的時刻,而停靠站距終到站距離對結(jié)果的影響最弱。
在預(yù)測結(jié)束后,其分類結(jié)果與訓(xùn)練集目標(biāo)分類相對應(yīng),得到相應(yīng)的最優(yōu)收入率,比如預(yù)測收入率分類為第2類,在訓(xùn)練集中收入率的第2類最優(yōu)收入率為0.045,則預(yù)測結(jié)果中此類的最優(yōu)收入率為0.045。
近幾年,隨機(jī)森林算法在很多領(lǐng)域都發(fā)揮了重要的作用[14]。在本文中,筆者利用隨機(jī)森林算法主要是考慮了其自身的一些優(yōu)點(diǎn):(1)由于在每次迭代之前引入隨機(jī)采樣,這使得算法不容易陷入過擬合并且具有很好的抗噪能力。同時,由于很好地解決了過擬合問題,在算法執(zhí)行之前和結(jié)束不用再進(jìn)行前或后的剪枝處理。(2)由于采取了隨機(jī)子空間的方法進(jìn)行特征選取,使得在進(jìn)入算法前不必再進(jìn)行影響因素選擇等預(yù)處理。
4 算法有效性驗(yàn)證
為了驗(yàn)證本文中利用和提出的算法有效性,從三個方面對離散化算法、分類算法和最優(yōu)收入率選取算法進(jìn)行有效性和精度的對比驗(yàn)證。
(1) 分類精度評估
利用Kappa指數(shù)[15]評估分類精度。Kappa指數(shù)可用來檢驗(yàn)分類的精度是否在可接受范圍內(nèi),計(jì)算為
( 7 )
此算法利用實(shí)際收入率分類和預(yù)測的收入率分類頻數(shù)建立一張二維表,Pii為對角線二者完全一致占樣本數(shù)的比值,Pi+和P+i分別為第i個檢驗(yàn)數(shù)據(jù)點(diǎn)的合計(jì)數(shù)和列合計(jì)數(shù)占總樣本數(shù)的比值。在Landis和Koch的論文中[15],他們提出Kappa值在0.21至0.40之間被認(rèn)為是可接受的;在0.40至0.60之間被認(rèn)為是中等的;在0.61至0.80之間被認(rèn)為是精度較大的;大于0.81被認(rèn)為是完美的分類。
(2) 分站收入率預(yù)測精度評估
利用第2節(jié)提出的基于誤差區(qū)間交集和樣本密度的最優(yōu)收入率選取算法得到各類中最優(yōu)收入率。從業(yè)務(wù)需求角度出發(fā),在全部的10 369個高鐵列車分站樣本中,分站收入率預(yù)測精度為預(yù)測的各站客票收入率與實(shí)際客票收入率的絕對誤差在[-3%,3%]以內(nèi)的樣本數(shù)占總樣本數(shù)的比例。
(3) 各個鐵路局收入預(yù)測精度評估
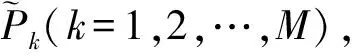
( 8 )
根據(jù)式( 8 )計(jì)算相應(yīng)分站收入,并且根據(jù)分站不同所屬鐵路局(開行高鐵的13個鐵路局)對收入進(jìn)行求和。在對比部分,筆者也考慮了在不同算法下,各個停靠站所屬局獲得的實(shí)際總收入與預(yù)測總收入的百分誤差。
4.1 離散化算法有效性驗(yàn)證
4.1.1 目標(biāo)變量離散化算法有效性驗(yàn)證
為了驗(yàn)證模型的有效性,保持模型中的其他模塊方法不變,只是將目標(biāo)變量離散化的方法分別替換成對比實(shí)驗(yàn)中的等頻,WPKID和聚類算法這3種無監(jiān)督離散化方法。為了驗(yàn)證CACC能否改進(jìn)K-means聚類算法的離散化精度,保持?jǐn)?shù)據(jù)中的分布信息,在對照的聚類離散化方法中選取K-means聚類算法。
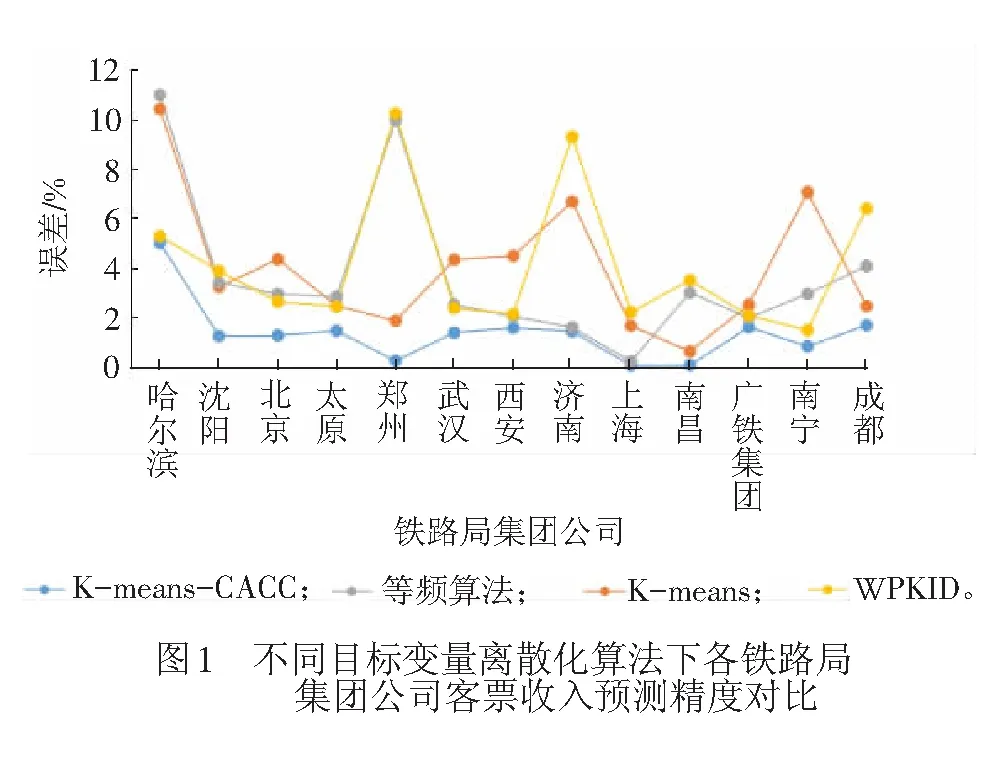
由表6和圖1可知,就本文討論的問題而言,K-means-CACC目標(biāo)變量離散化方法相比于其他方法能夠提高預(yù)測的分類精度、收入率和收入預(yù)測精度。也可以看出,K-means聚類算法經(jīng)過CACC的優(yōu)化,離散化準(zhǔn)確度得到提高。
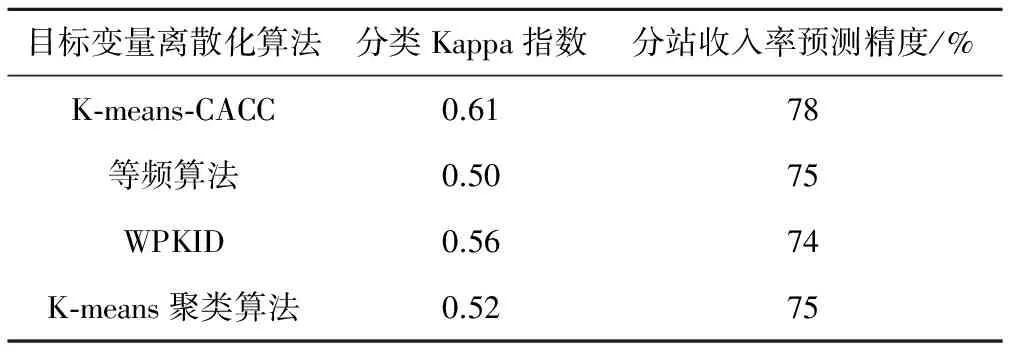
表6 目標(biāo)變量離散化算法預(yù)測結(jié)果對比
4.1.2 因素變量離散化算法有效性驗(yàn)證
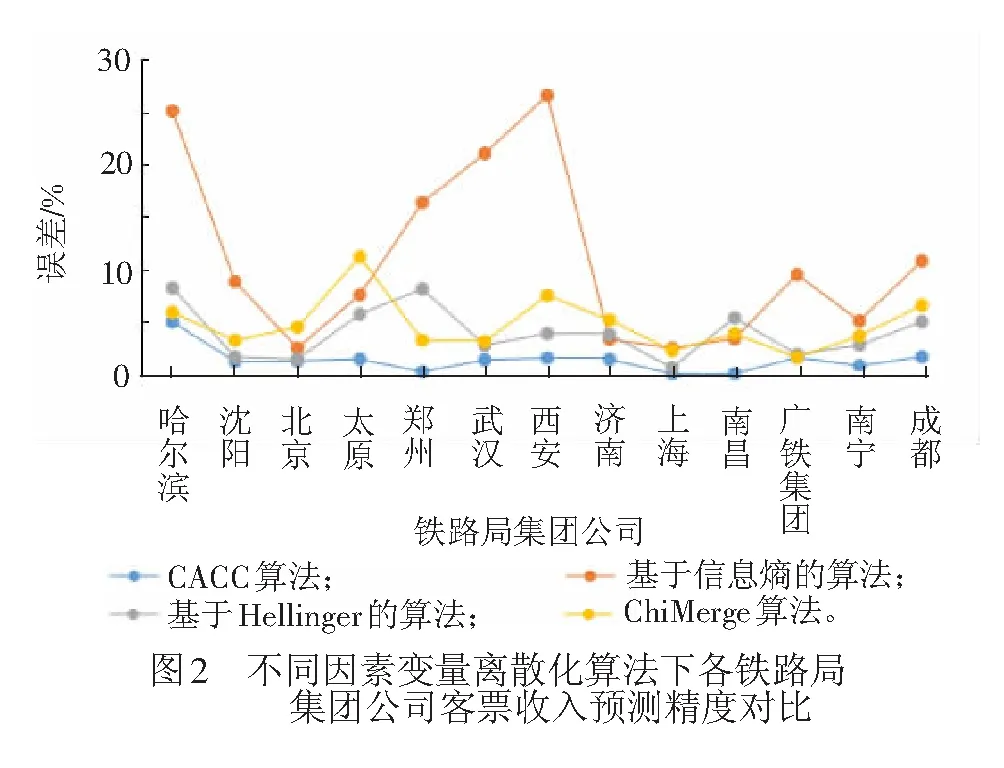
雖然文獻(xiàn)[9]驗(yàn)證了CACC算法在決策樹算法中的優(yōu)勢,但對于本文討論的問題,本節(jié)再一次進(jìn)行驗(yàn)證,將CACC算法分別與ChiMerge算法、基于信息熵的離散化算法、基于Hellinger的算法等相比較,結(jié)果見表7。
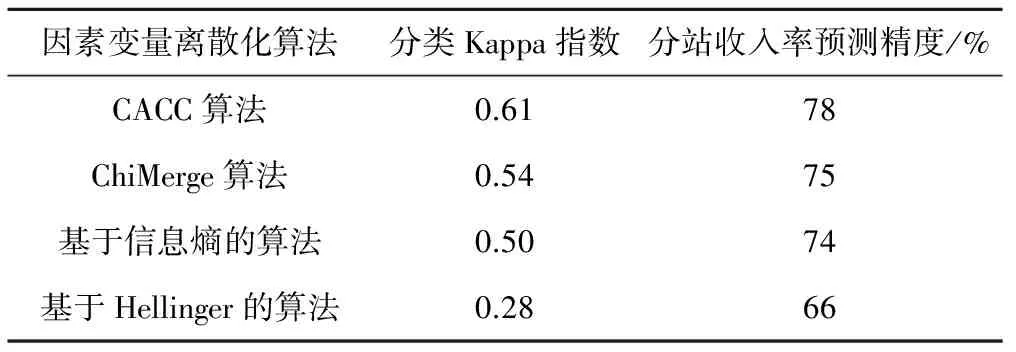
表7 因素變量離散化算法預(yù)測結(jié)果對比
由表7和圖2可知,CACC算法較其他監(jiān)督的離散化算法在分類精度和收入預(yù)測精度上表現(xiàn)更優(yōu)異。
4.2 分類算法有效性驗(yàn)證
為了驗(yàn)證文中隨機(jī)森林算法的使用是否合理,是否較其他分類算法能突出其優(yōu)點(diǎn),具體做法是將隨機(jī)森林算法的分類預(yù)測結(jié)果的Kappa指數(shù)分別與SVM算法、C4.5決策樹算法和Adaboost分類算法的結(jié)果的Kappa指數(shù)相比較。表8是驗(yàn)證結(jié)果。
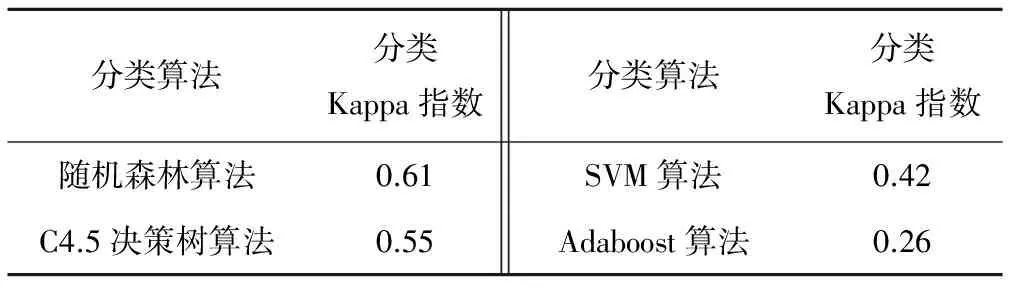
表8 不同分類算法預(yù)測精度對比
由表8可知,相對于其他分類算法,隨機(jī)森林算法在分類預(yù)測方面有著較高的精度。特別是相對于C4.5決策樹算法,隨機(jī)森林算法的特征隨機(jī)選取過程和投票機(jī)制是一種改進(jìn)和優(yōu)化。
4.3 最優(yōu)收入率選取算法有效性驗(yàn)證
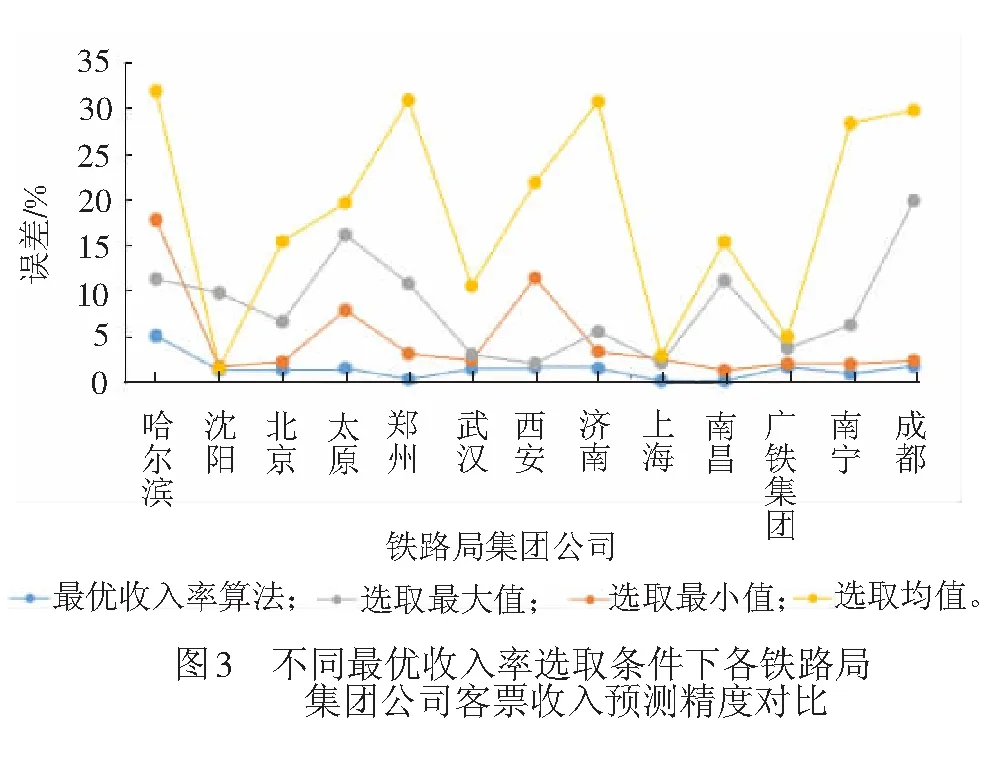
為了驗(yàn)證本文最優(yōu)收入率選取算法的有效性,選取訓(xùn)練集中各個目標(biāo)變量分類范圍內(nèi)的收入率最大值、最小值和均值分別作為最優(yōu)收入率,并將利用它們計(jì)算的分站收入率和鐵路局收入結(jié)果與本文的收入率計(jì)算結(jié)果進(jìn)行對比,結(jié)果見表9。

表9 不同最優(yōu)收入率選取預(yù)測結(jié)果精度對比
由表9和圖3可知,本文提出的最優(yōu)收入率選取方法可以較為準(zhǔn)確地預(yù)測分站收入率和鐵路局收入。特別是相比于傳統(tǒng)的取均值的方法,本文提出的算法能夠顯著提高預(yù)測準(zhǔn)確度。
5 結(jié)束語
本文通過對目標(biāo)變量、因素變量的離散化處理,及分類后最優(yōu)收入率選取的基礎(chǔ)上,以收入率為目標(biāo)對列車停靠站信息進(jìn)行分類預(yù)測。從實(shí)驗(yàn)結(jié)果上看,本文中,改進(jìn)、提出和采用的算法對于客票收入率分類和客票收入預(yù)測具有較高的操作性和有效性。此模型不僅能為管理部門提供一張清晰的決策表指導(dǎo)未來收入計(jì)劃的下達(dá)。同時,這也能為運(yùn)輸部門高鐵列車開行計(jì)劃的制定起到一定的參考作用。隨著12306旅客信息收集工作的逐步進(jìn)行,在下一步的研究中,針對不同運(yùn)輸通道旅客出行行為[16]對列車分站收入進(jìn)行更準(zhǔn)確的預(yù)測。
參考文獻(xiàn):
[1] 劉春煌,王麗華,李聚寶,等.鐵路運(yùn)輸企業(yè)收入清算系統(tǒng)總體方案的研究及旅客運(yùn)輸清算系統(tǒng)的實(shí)施[J].中國鐵道科學(xué),2003,24(1):12-18.
LIU Chunhuang,WANG Lihua,LI Jubao,et al. Researches on Overall Scheme of Revenue Clearing System for Railway Transportation Enterprises and Implementation on Passengers Transportation Clearing Sub-system[J].China Railway Science,2003,24(1):12-18.
[2] 汪學(xué)文,樊曉平.鐵路客票收入清算復(fù)核系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)[J].計(jì)算機(jī)與現(xiàn)代化,2007(6):120-122.
WANG Xuewen, FAN Xiaoping. Design and Implementation of Income Liquidation and Checking System for Railway Tickets[J].Computer and Modernization,2007(6):120-122.
[3] 王麗華,劉賀文,張晨陽,等.鐵路旅客運(yùn)輸清算系統(tǒng)[J].鐵路技術(shù)創(chuàng)新,2012(4):52-56.
WANG Lihua,LIU Hewen,ZHANG Chenyang,et al.Railway Passenger Transport Clearing System[J].Railway Technical Innovation,2012(4):52-56.
[4] 趙弇南.鐵路客運(yùn)清算系統(tǒng)的現(xiàn)狀、完善與發(fā)展[D].北京:北京交通大學(xué),2005.
[5] 李岱安, 方圓, 李靜華,等.中國鐵路旅客運(yùn)輸清算系統(tǒng)的研究與實(shí)施[C]//北京:中國鐵道學(xué)會鐵道信息化建設(shè)青年科技研討會暨中國鐵道學(xué)會青年學(xué)術(shù)會議.北京:中國鐵道學(xué)會,2003.
[6] 史森林.鐵路客票收入影響因素分析[J].鐵道運(yùn)輸與經(jīng)濟(jì),2004,26(8):37-40.
SHI Senlin. Analysis upon the Affecting Factors for Railway Ticket Income[J].Railway Transport and Economy,2004,26(8):37-40.
[7] 史森林.對鐵路客票收入彈性預(yù)算原理的研究[J].中國鐵路,2004(5):60-62.
SHI Senlin. Study on the Principle of Flexible Budget of Railway Passenger Ticket Income.[J].Chinese Railway,2004(5):60-62.
[8] 方偉.鐵路局營業(yè)收入預(yù)測方法研究[J].產(chǎn)業(yè)與科技論壇,2012,11(7):110-111.
FANG Wei. Research on the Forecasting Method of Railway Administration Revenue[J].Industrial & Science Tribune,2012,11(7):110-111.
[9] 張鈺莎,蔣盛益.連續(xù)屬性離散化算法研究綜述[J].計(jì)算機(jī)應(yīng)用與軟件,2014,31(8):6-8,140.
ZHANG Yusha,JIANG Shengyi. Survey on Continuous Feature Dicretisation Algorithm[J].Computer Applications and Software,2014,31(8):6-8,140.
[10] TSAI C J,LEE C I,YANG W P. A Discretization Algorithm Based on Class-Attribute Contingency Coefficient[J]. Information Sciences,2008,178(3):714-731.
[11] LUKASIK S,KOWALSKI P A,CHARYTANOWICZ M,et al. Clustering Using Flower Pollination Algorithm and Calinski-Harabasz Index[C]//Evolutionary Computation. New York:IEEE,2016,24-29.
[12] BREIMAN L. Random Forests[J].Machine Learning,2001,45(1):5-32.
[13] QUINLAN J R. C4.5: Programs for Machine Learning[M].Boston:Morgan Kaufmann Publishers,1993,71-80.
[14] 方匡南,吳見彬,朱建平,等.隨機(jī)森林方法研究綜述[J].統(tǒng)計(jì)與信息論壇,2011,26(3):32-38.
FANG Kuangnan,WU Jianbin,ZHU Jianping,et al.A Review of Technologies on Random Forests[J].Statistics & Information Forum,2011,26(3):32-38.
[15] LANDIS J R,KOCH G G. The Measurement of Observer Agreement for Categorical Data[J]. Biometrics,1977,33(1):159-174.
[16] 葉玉玲,王藝詩.滬杭運(yùn)輸通道內(nèi)旅客出行方式選擇行為研究[J].鐵道學(xué)報(bào),2010,32(4):13-17.
YE Yuling,WANG Yishi.Research on Travel Model Choice Behavior in Shanghai-Hangzhou Transport Corridor[J].Journal of the China Railway Society,2010,32(4):13-17.
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
