基于多域的互聯網物理對象關聯分析方法研究
2018-04-13 01:06:54杜秀春劉華富
計算機技術與發展 2018年4期
張 毅,杜秀春,劉 欣,劉華富
(1.國防科學技術大學 計算機學院,湖南 長沙 410073;2.長沙學院 數學與計算機科學系,湖南 長沙 410003)
0 引 言
當今信息時代下,隨著互聯網技術應用的快速普及和發展,通信網絡不斷擴大,網絡之間的交互更加密集。物聯網技術的發展帶動了傳感器網絡技術的發展應用,博客、論壇、微博等應用帶動了社交網絡研究的熱潮。由于物聯網具有的廣泛的互聯性,在給人民生活帶來便捷的同時,也帶來了諸多的安全問題。相比于傳統的計算機網絡,物聯網絡中的物理設備沒有設置安全防御策略,如入侵檢測系統、防火墻等。這些物理設備直接暴露在了網絡空間中,可能被攻擊者發現和利用,給物理設備的安全構成了極大的威脅。
近年來,針對物聯網設備的攻擊事件頻發,使得人們認識到了對于網絡空間中相關物理對象研究分析的重要性。例如,繼針對伊朗核設施的工業控制系統破壞的“震網”(Stuxnet)蠕蟲病毒感染事件發生后,2011年,美國某安全公司發現了Stuxnet病毒的變種,該變種被稱為Duqu木馬病毒,該病毒的主要目標同Stuxnet一樣也是工業控制設備,但比Stuxnet病毒隱蔽性更強、危害更大[1];2014年,俄羅斯黑客組織“蜻蜓”開發的惡意病毒程序Havex對歐美一千多家能源企業進行了攻擊[2];2016年,美國相關安全部門發現了7名伊朗黑客針對位于紐約的鮑曼水壩控制系統的攻擊行為[3]。這些攻擊行為對于國家或地區直接或間接地產生了重大的網絡安全影響。
如今,計算機通信網絡、物聯網絡、社交網絡組成了當前的網絡新形態,而且它們之間相互貫通、密不可分。其中,物聯網絡技術融合了傳統計算機通信網絡和由此連接起來的物理對象,社交網絡則融合了傳統計算機通信網絡和由此連接起來的人或組織機構等,計算機通信網絡成為連接兩者的樞紐關節。信息物理社會系統(cyber-physical-social system,CPSS)[4]是當前研究網絡的新形態,主要關注的是物理對象在信息域的接口和社會域信息到信息域信息的映射以及這三者之間交互融合的過程。從多域的角度融合分析網絡空間中的物理對象能更加全面、準確地描繪物理對象的特征。相比于只從某個域的角度進行分析,多域信息是現實物理對象的真實表現,能清楚地反映物理對象之間的關聯情況。
網絡中的物理對象信息通常以網絡拓撲結構信息、IP物理地址信息、開放端口信息、運行協議以及網頁文本信息的形式存在。文中以Web服務器網頁文本中的鏈接為出發點,綜合分析相關語義信息,結合物理域信息分析物理對象之間的關聯特性。該方法對于分析和評估網絡中特定物理對象被攻擊后影響的范圍、產生的危害有重要的幫助作用。
1 相關工作
網絡空間中物理對象的種類多種多樣,如路由器、主機、服務器、打印機以及傳感器等。對于這些設備的感知探測工作現在已有研究,并有成熟化的產品投入應用,如Shodan[5]、ZoomEye[6]、Censys[7]、諦聽[8]等,這些工具結合MaxMind、IP2Location、Whois等工具展示物理對象的有關信息,但是這些系統沒有進一步綜合分析物理對象之間的關聯關系,而且給用戶提供的搜索結果信息并沒有提供關聯推薦結果,導致顯示效果較差。
Maltego[9]能從一個IP、Email、Twitter或者人物姓名找到一個人的社會域、信息域以及物理域的所有信息,然后將把這些有關信息相互關聯起來,以圖的形式展現給用戶。Maltego結合Shodan、Linkedin能搜索到的信息包括物理對象的地理位置信息、社交媒體等在線信息、網絡拓撲結構信息、ISP信息,主要功能包括多域數據抽取、多域數據分析、多域信息關聯展示等,但是Maltego只能以域名、郵箱、Twitter上的信息和URL為出發點對相關信息進行搜索,對研究物理對象多域融合有一定的參考意義,但是存在搜索的局限性、搜索結果的數量限制等多方面的問題。
在關聯分析研究方面,張魏斌等[10]以社會域中的關聯關系構建模型,測算社團的劃分和個體的社會效用。劉勘等[11]以搜索引擎返回的信息域中的信息為出發點,分析包含在頁面中的超鏈接信息,研究出度、入度、最短路徑和密度信息,最終得出結果信息的聚類。He Xiaofeng等[12]結合信息域中Web頁面的超鏈接信息、文本挖掘信息以及共引關系來建立網頁的聚類。郭景峰等[13]通過詞簇、鏈接向量來建立簇,并使用近鄰傳播算法建立簇與簇之間的關系,并基于這些關系做進一步的分析。
文中通過研究分析物理對象在多域中的屬性信息,建立物理對象在社會域、信息域、物理域中信息的關聯關系模型,結合各個域信息的完備性、準確性賦予它們之間不同的權重,最后結合改進的馬爾可夫聚類算法得出物理對象之間的關系。實驗結果表明,該算法在物理對象多域信息聚類中有著較好的效果,該聚類結果對于分析針對物聯網攻擊行為所產生的影響有著重要的參考意義。
2 多域融合的分析方法
在現實環境中,物理對象的信息涉及物理域信息(Physical,P)、信息域信息(Cyber,C)和社會域信息(Social,S)。其中物理域是物理對象自身或固有的相對穩定的屬性信息,如型號信息、地理位置信息等。信息域信息是物理對象在計算以及與其他物理對象通過互聯網進行通信中反映出來的信息,如開放端口、運行協議、路由信息等。社會域信息是與物理對象相關的人物、組織機構、事件等的信息,包含了物理對象相關人物或組織機構的信息。
通過網絡拓撲結構探測發現物理對象之間的關聯關系會受到防火墻抑制、網絡通信錯誤等影響,且相關關系不明確,存在很大的誤差。Web服務器中包含了大量信息,且訪問不受控制,網絡與網絡之間的屬性關聯關系可以通過包含大量信息的網頁為出發點來尋找。圖1中B和A是基于Web服務器中的鏈接指向和文本特性構成的鏈接圖,反映了網絡1和網絡2的關聯特性。
文中通過在信息域中分析各網絡間鏈接指向信息、文本語義特性和在社會域中的有關信息分析網絡間的關聯關系,并結合網絡中物理對象的地理位置信息提高融合關聯結果的準確性。
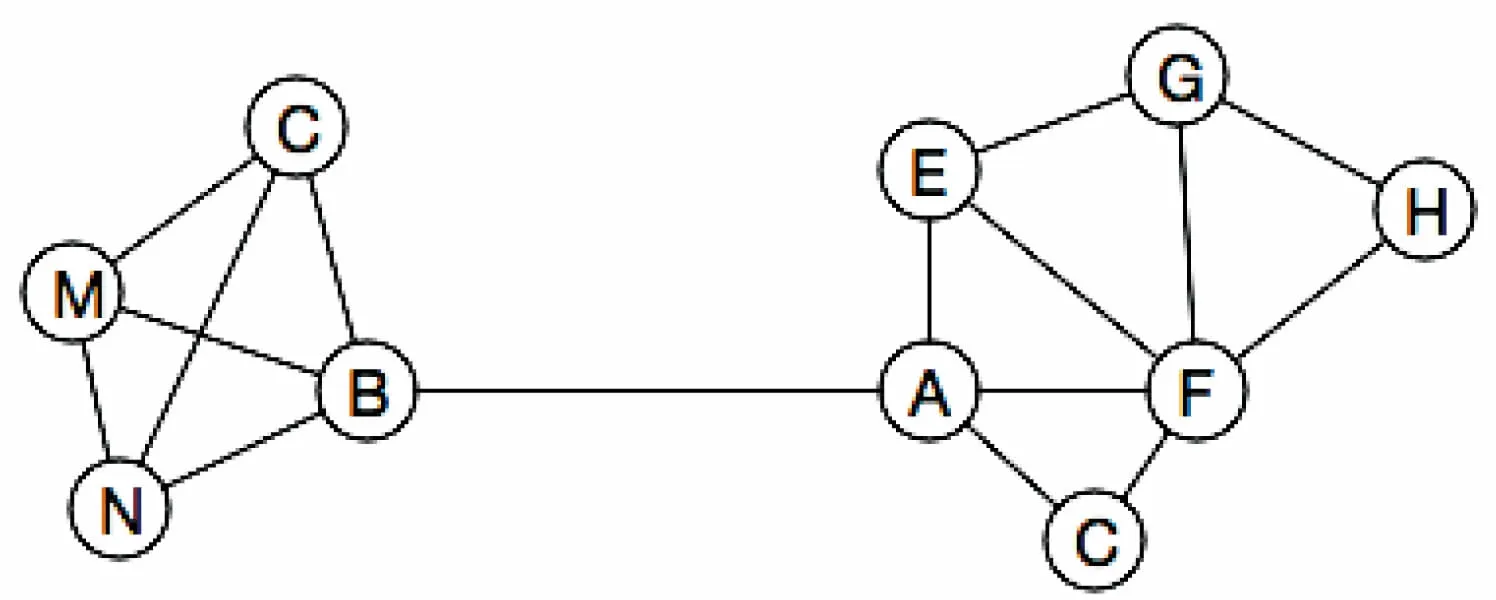
圖1 網絡連接圖
2.1 網絡鏈接分析與預處理
前期已經完成了對國內IP地址的掃描工作。通過建立與隨機生成的IP地址的偽連接判斷遠程物理對象的存活狀態和開放端口信息。爬取運行HTTP協議的物理對象的相關網頁并記錄網頁中包含的鏈接信息。文中基于網頁中的鏈接關系為網絡中離散的物理對象建立初始鏈接關系,并通過數據預處理清洗掉無關信息。詳細工作內容如下:
(1)統計和記錄運行HTTP協議的IP地址及其對應的域名信息,并為每個IP地址下存在的域名編號;
(2)分析網頁文本中包含的超鏈接信息,把這些超鏈接信息分為指向本域名的內部鏈接和指向其他域名的外部鏈接;
(3)在記錄網頁中的超鏈接信息時,超鏈接的抽取工作需要過濾掉頁面內的相對鏈接,只抽取指向其他域名下的外部鏈接,同時只記錄靜態超鏈接,不記錄動態超鏈接。這樣做的目的是防止在本域名下形成大的簇而影響實驗;
(4)基于鏈接關系構造二元組(FromId,ToId)。一個二元組在網絡圖中代表了一條邊,FromId代表邊的始發節點,ToId代表邊的終止節點,最后去除FromId的值等于ToId的值的節點,即去除指向本身的內部鏈接指向。
為清楚地表明Web頁面之間的連接情況,從數據集合中隨機選取了30 000個Web頁面的鏈接關系構造網絡連接圖,如圖2所示。

圖2 Web頁面鏈接構成的網絡圖
在Web頁面鏈接的出度、入度信息中,分析了30多萬個節點的出度和返回指向的入度。對于這些數據存在的冗余問題,根據文獻[13]得出Web頁面的鏡像頁面的出鏈接數應該大于8,如果兩個頁面之間共享出鏈接(out links)的數量比率超過80%,其中一個頁面可以作為鏡像頁面刪除。這里的8和80%都是根據經驗獲得的參數。
2.2 馬爾可夫聚類算法原理
馬爾可夫聚類(Markov cluster,MCL)算法由Dongen[14]提出,已成功運用到各種網絡圖、計算機圖形中。該算法屬于圖形聚類算法,通過圖聚類發掘節點之間的關系及其聚類中心,其實質是從一個節點出發通過隨機游走來確定群聚類中心。該算法基于隨機狀態轉移概率矩陣,不需要預先設定聚類數目,通過概率改變和反復修改矩陣以實現隨機流模擬。
MCL算法在構建基礎隨機矩陣的基礎上,通過擴大(Expand)和填充(Inflate)操作,再分別映射到自身,并且不停地重復上述Expand和Inflate兩個步驟直到矩陣收斂。其中,在每次Inflate操作之后需執行修剪(Prune)操作。設初始隨機矩陣為M,則M可定義為如下形式:
(1)
為解決從一個奇數路徑在執行擴大操作的過程中產生很大影響這一問題,需要在鄰接矩陣A中添加自循環的路徑。
Expand操作的表達式為:
Mexp=Expand(M)=Me
(2)
通常參數e為非負整數,且默認值為2。
Inflate操作的表達式為:
(3)
MCL計算之后,得到一個收斂的矩陣M。解釋聚類結果為:在矩陣M中,第j列中只有一個非零值,非零值對應的第i行表示節點vi是節點vj的吸引子,也即聚類的中心,與節點vj類似的節點一起構成同一個類。
2.3 多域分析與權重設定
物理對象的多域信息表示物理對象在各個域中的信息屬性,這些信息表示物理對象之間的聯系,如社會域中的人物和組織機構信息,同一機構的物理對象必定歸屬于同樣的管理人員或者組織機構。在信息域中,屬于同一組織的物理對象在信息域中有著較大的網絡通信流量,這些信息表示了物理對象在信息域中的關聯程度。同樣,在物理域中物理對象的地理位置信息從地理空間的角度展示了物理對象在地理上的分布情況,表現了物理對象屬于同一機構的可能性。
文中分別在社會域、信息域和物理域中分析了物理對象的關聯特性,然后融合這些信息為普通無向且無權重的關聯圖構建權重矩陣,最后得出物理對象間的關聯關系。
2.3.1 社會域分析
物理對象在社會域中的信息可以從Web文檔以及通過域名從Whois數據庫中獲取,Whois是用來查詢域名的IP及其所有者等信息的傳輸協議。Whois是一個在線的“請求/響應”型的服務,其運行在43端口,它會把相關信息如所有者、管理者、所在地、郵箱、電話等信息返回給查詢請求。
對于Web頁面中的人物姓名、組織機構、地理名稱等命名實體識別及其詳細信息的獲取有多種方式。對于人物姓名、組織機構等命名實體的識別的主要方法有基于隱馬爾可夫模型(hidden Markov model,HMM)的識別方法、基于最大熵模型(maximum entropy,ME)的識別方法、基于條件隨機場模型(conditional random fields,CRF)的識別方法[15]等。文中基于開源工具HanLP完成命名實體的識別工作。對于從Web文檔獲取的其他信息,如郵箱、電話等則使用基于規則的匹配方法。
為求解某兩個節點vi和vj相互之間在社會域上的關聯程度,可以為上述信息構造一個詞匯表,例如wk=(w1,w2,…,wk),統計兩個節點上每個詞出現的頻率并分別構造出詞匯矩陣A和B,通過向量空間余弦相似度計算公式計算兩個節點在社會域的關聯程度比值:
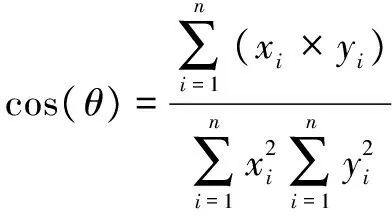
(4)
2.3.2 信息域分析
上述通過社會域中有關信息分析物理對象之間的關聯特性,在一定程度上有著較好的關聯分析效果,但也存在命名實體識別誤差和人物名稱對應問題。探測主機在獲取遠程物理對象物理域信息時由于受到防火墻、入侵檢測等安全措施的抑制,探測主機的訪問是一種外網訪問形式,使得這種訪問由于登錄認證、口令、訪問白名單的限制而很難獲得完整、全面的信息,但是物理對象信息域中的信息相比社會域和物理域中的信息有著獲取方式多樣、獲取途徑簡便、獲取內容全面可靠等優點。下面重點闡述物理對象在信息域中三種信息的處理方法:
(1)超鏈接信息表示物理對象之間的鏈接緊密程度,是物理對象關系圖構造的基礎,其定義如下:
(5)
(2)信息域中的網頁文本包含豐富的文本信息,這里通過計算兩個節點之間網頁文本的相似度來衡量兩者之間的關系。遍歷該節點下本域名內的所有Web文檔,主要工作是處理和提取文檔中的關鍵字信息。其中文檔關鍵字提取以常用的詞頻和逆文檔率來表示。在爬取的前n個頁面中,設詞項i在文檔j中的頻率為fij,則詞項頻率定義為:
(6)
假設詞項i在ni篇文檔中出現,其逆文檔率定義如下:
(7)
將TFij·IDFi作為詞項i在頁面j中的關鍵度衡量指標,取前30個單詞作為頁面的關鍵詞。對最后得出的單詞詞匯使用向量空間余弦相似度計算方法來計算相似性,用符號D(di,dj)來表示。
(3)共引用信息同樣也可以表征兩個物理對象之間的關系。共引用是指其他頁面都指向了這兩個頁面,則代表這兩個頁面可能存在著一定的關系。用Rij表示共同指向i和j這兩個頁面的個數。
最后綜合物理對象在信息域中的三種關系計算方法得到在信息域中物理對象關聯的結果:
(8)
2.3.3 物理域分析
文中在物理域信息中只使用了IP物理地址這一信息,IP物理地址這一信息在分析物理對象關聯中有著重要的作用。文中使用IP2Location、Maxmind、淘寶IP定位數據,這些數據庫的異構性和不準確性導致不同數據庫得到的地理度和地理介數的分布稍有不同。為解決這一問題,使用這三個來源的IP地理位置信息的中心位置作為所求物理對象IP的物理地理位置信息。
用歐幾里得距離計算兩個節點X和Y之間在物理域信息中的關聯程度:
(9)
其中,Xlon和Xlat,Ylon和Ylat分別表示該物理對象的經緯度信息。
最后得出兩個物理對象在物理域之間的關聯系數:
(10)
當且僅當dist(X,Y)小于10 000時上式成立,否則P設定為零。
2.4 基于多域融合改進的MCL聚類算法
上述內容分別從物理對象的社會域、信息域和物理域出發分析了物理對象在各個域中相互之間的關聯強度,并分別用符號S、C、P代表各個強度值,由此可以得到關聯矩陣的權重信息。綜合考慮物理對象在三個域中的情況得出下列權重計算公式:
W=0.4*S+0.5*C+0.1*P
(11)
考慮到在獲取社會域信息時存在的分詞偏差和存在人物不能正確對應的問題,設定社會域(S)的權重系數為0.4。信息域中的信息比較豐富,而且相對誤差較小,設定信息域中分析得出的信息給出最高權重系數為0.5。針對物理域信息相對單一,IP對應的物理地址存在很大誤差,同時由于內容分發網絡(content delivery network,CDN)技術的應用也增大了IP地址對應物理地址誤差的增大,因此這里設置物理域權重為0.1。
在MCL算法的多次迭代計算過程中,包含大量節點的矩陣圖結構會被逐步分解成若干小的子圖結構。在適當選擇的行和列的排列之后,這種圖形的相應矩陣包含對角線放置的非零值的密集塊,并且在這些塊之外的值都為零。利用這一特點可以提高算法的計算效率。在算法執行期間,發生在特定列和相似矩陣S的相應行保持單個非零值,該非零值位于矩陣的對角線上。對應于該特定行的節點可以被聲明為在聚類中單獨的隔離節點,在后續迭代中對其他節點沒有影響,可以從S中移除這樣的行和列,降低后續迭代的計算負載。這樣,當圖形在3~10次迭代之后發生分離子圖時,初始大矩陣可以重新組織成幾個小的二維位置的塊,在進一步處理中可以忽略具有相似性的塊之外的零值。
在聚類過程中包含兩種狀態結構,以任務隊列的形式保存矩陣子圖的計算結果的狀態:
狀態隊列1:位于該狀態隊列下的矩陣子圖表示矩陣需要進一步執行迭代操作。開始時,所有節點都位于該狀態中,當從狀態隊列1中分離矩陣子圖時,需要滿足對應分離子圖的矩陣塊具有高密度,則從該矩陣中分離該子圖,否則相應的節點保留在狀態隊列1中以用于進一步的迭代。該矩陣子圖將在下一次迭代中增長,或者子圖將進一步分解成較小的隔離子圖。
狀態隊列2:位于該狀態隊列下的矩陣子圖表示該矩陣已經處于迭代停止的狀態,無需進一步執行迭代操作,它包含屬于孤立子圖的那些節點,其相應的矩陣塊被視為單獨的矩陣,這些孤立子圖節點通常是從上一步狀態隊列1中分離得到的。它包含組織在孤立子圖中的一組節點,通常相應的相似矩陣小而密集。
當狀態隊列1處于空隊列時,說明整個迭代聚類求解過程已經結束。具體算法偽代碼如算法1所示。
算法1:基于多域信息改進型MCL聚類算法。
Input:物理對象多域信息,Expand中的參數e和Inflate中的參數r;
Output:物理對象之間關聯關系聚類矩陣。
1:由信息域中的超鏈接信息H構建初始關聯矩陣M
2:計算物理對象之間多域關聯系數S、C、P
3:得出權重矩陣W
4:結合矩陣W把初始關聯矩陣M轉換為無向有權重矩陣,并為每個節點添加自循環信息
5:初始化隊列1和隊列2
6:whileM矩陣不收斂:
7:對矩陣執行歸一化操作
8:基于參數e和r對M執行Expand和Inflate
9:執行Prune操作
10:if 矩陣M中包含可分離的矩陣m
11:將m加入隊列2并在M中相應位置零
12:end if
13:end while
14:解釋最終矩陣,分析聚類結果
3 實驗測試與結果分析
文中數據集的采集是利用多臺CPU為2核,內存為4 GB,硬盤容量為40 GB配置的阿里云服務器隨機生成IP地址并進行分布式探測來獲得的。采集的數據集共計313 287個,考慮到計算時間問題,實驗中分別從數據集中抽取了6組數據(見表1)做測試分析。
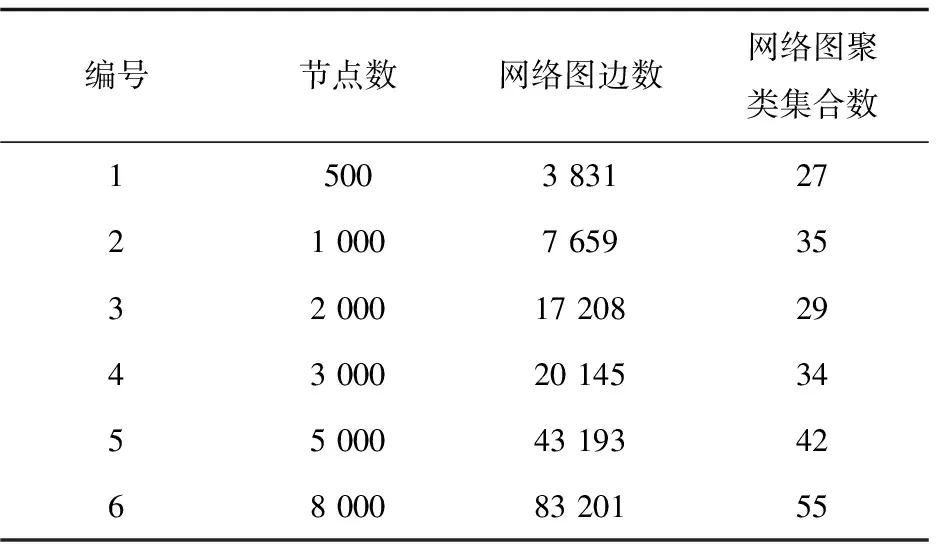
表1 實驗結果
圖3為對網絡空間中物理對象節點執行改進的馬爾可夫聚類算法后的聚類情況,總共把1 293個節點聚類成37個簇。

圖3 聚類后的簇圖
4 結束語
在當前物聯網安全狀況較為嚴峻的情形下,研究和分析互聯網中的物理對象,并為物理對象相關信息建立模型,能為物聯網安全的研究提供一定的幫助。以當前物聯網的安全形勢為背景,通過分析物理對象的多域屬性信息,為物理對象在各個域中的信息建立關聯特性計算模型,并結合馬爾可夫聚類算法為物理對象圖聚類建立關聯矩陣,基于隨機游走方法,通過迭代分析,最后得出物理對象關聯特性。實驗結果表明,該算法在物理對象關聯關系分析方面有著較好的效果。實驗結果的聚類中心節點是物聯網絡的核心節點,其脆弱性直接影響了其他物理對象節點的安全性。
在實驗過程中存在多域信息量大、計算時間復雜度高等問題,因此下一步需要繼續優化有關關聯計算模型的時間、空間復雜度,同時可結合分布式大數據處理工具如Hadoop、Spark等開展物理對象關聯聚類的研究工作。
參考文獻:
[1] FAISAL M,IBRAHIM M.STUXNET,DUQU and beyond[J].International Journal of Science and Engineering Investigations,2012,1(2):75-78.
[2] SCHLECHTENDAHL J,KEINERT M,KRETSCHMER F,et al.Making existing production systems industry 4.0-ready[J].Production Engineering,2015,9(1):143-148.
[3] THOMSON L L.Insecurity of the internet of things[J].Scitech Lawyer,2016,12(3):32-35.
[4] HUSSEIN D,PARK S,HAN S N,et al.Dynamic social structure of things:a contextual approach in CPSS[J].IEEE Internet Computing,2015,19(3):12-20.
[5] BODENHEIM R,BUTTS J,DUNLAP S,et al.Evaluation of the ability of the Shodan search engine to identify Internet-facing industrial control devices[J].International Journal of Critical Infrastructure Protection,2014,7(2):114-123.
[6] 白 潔.大數據應用[J].信息安全與通信保密,2013(10):13-16.
[7] DURUMERIC Z,ADRIAN D,MIRIAN A,et al.A search engine backed by Internet-wide scanning[C]//Proceedings of the 22nd ACM SIGSAC conference on computer and communications security.New York,NY,USA:ACM,2015:542-553.
[8] 袁 勝.“白環境”下的工控安全[J].中國信息安全,2016(4):74-75.
[9] SHALIN H J.Beyond surface relations:using Maltego to analyze electronic connectivity and hidden ties in the internet understructure[J].Journal of Vacuum Science & Technology A Vacuum Surfaces & Films,2014,26(2):205-211.
[10] 張魏斌,曾 鋒,伍澤全,等.移動群體感知中基于社會關系的路由算法[J].計算機應用研究,2016,33(10):3128-3131.
[11] 劉 勘,范 琴.鏈路結構的網頁聚類研究[J].小型微型計算機系統,2016,37(7):1450-1454.
[12] HE Xiaofeng,ZHA Hongyuan,DING C H Q,et al.Web document clustering using hyperlink structures[J].Computational Statistics & Data Analysis,2002,41(1):19-45.
[13] 郭景峰,馬 鑫,代軍麗.基于文本-鏈接模型和近鄰傳播算法的網頁聚類[J].計算機應用研究,2010,27(4):1255-1258.
[14] Dongen E S.A cluster algorithm for graphs[R].[s.l.]:[s.n.],2000.
[15] 曾冠明.基于條件隨機場的中文命名實體識別研究[D].北京:北京郵電大學,2009.
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
井岡教育(2022年2期)2022-10-14 03:11:44
保健醫苑(2022年1期)2022-08-30 08:39:14
當代陜西(2021年17期)2021-11-06 03:21:36
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
學苑創造·A版(2018年11期)2018-02-01 06:29:20
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
讀者(2017年5期)2017-02-15 18:04:18
中學生(2015年2期)2015-03-01 03:43:33
電腦愛好者(2011年11期)2011-06-22 08:20:18
