面向比特流的鏈路層未知幀分析技術(shù)綜述
2018-03-27 01:23:57曹成宏雷迎科
小型微型計算機系統(tǒng) 2018年2期
關(guān)鍵詞:關(guān)聯(lián)
曹成宏,雷迎科
(電子工程學院,合肥 230037)
1 引 言
在OSI協(xié)議體系結(jié)構(gòu)[1]中,鏈路層介于物理層和網(wǎng)絡(luò)層之間,高層協(xié)議識別工作必須建立在鏈路層協(xié)議解析的基礎(chǔ)上,因此對于偵察得到的比特數(shù)據(jù)流,首先要解決的就是如何識別分析出其使用的鏈路協(xié)議.當前研究在通信系統(tǒng)的不同層次實現(xiàn)了協(xié)議識別,但方法多局限于已知協(xié)議,如基于端口映射[2]和靜態(tài)特征匹配[3]的方法等,對已知協(xié)議識別方法的總結(jié)綜述較全面,但對實際的未知協(xié)議的相關(guān)研究不多,方法技術(shù)總結(jié)則更少.
近年來,國外對于協(xié)議分析的研究主要集中在基于測度的、基于固定字符串的和基于正則表達式的協(xié)議識別技術(shù).從2005年開始,Moore[4]等人給出了網(wǎng)絡(luò)流的249種屬性,通過幾個屬性的不同組合得到最簡潔的特征子集,作為后續(xù)研究的依據(jù).Bernaille[5]等按照數(shù)據(jù)包到達的先后順序?qū)⒚總€數(shù)據(jù)流中的前五個數(shù)據(jù)包的大小作為特征,采用無監(jiān)督算法進行聚類,但這種方法在協(xié)議識別中的準確率不高.在2010年,Cai[6]等人提出了基于機器學習和固定字符串匹配的協(xié)議識別方法,首先對數(shù)據(jù)流量進行分流處理,然后采用離線的方式進行訓練,提取出固定的字符串作為特征關(guān)鍵字,但是由于缺乏相應規(guī)范,對未知協(xié)議并不適用.Veritas[7]系統(tǒng)對抓取的協(xié)議消息實現(xiàn)3-gram劃分,將經(jīng)過篩選之后的單元進行拼接得到協(xié)議的關(guān)鍵詞,最終將協(xié)議關(guān)鍵詞作為模式實現(xiàn)了協(xié)議的類別劃分,但這種方法僅適用于單一協(xié)議.2011年,Y.Wang[8]等人提出的 Biprominer就是利用數(shù)據(jù)挖掘的相關(guān)技術(shù),提取比特流的特征信息,通過正則表達式,最終以有限狀態(tài)自動機的形式表現(xiàn)出來.Antunes[9]等人將生物信息中的序列比對算法用于協(xié)議識別中,通過偏序比對算法提取協(xié)議的正則表達式,建立自動機,進行協(xié)議識別,但過程中需要對構(gòu)建的自動機進行重復匹配,這樣會造成較大的資源消耗.
該文所研究的無線網(wǎng)絡(luò)數(shù)據(jù)環(huán)境是指通過偵察設(shè)備對無線信號進行物理層的截獲,并通過一系列解調(diào)、解碼和解密以后的比特流數(shù)據(jù).實際中,截獲數(shù)據(jù)多為加密的,針對加密算法識別及解密問題有專門的研究,文章未做考慮.該文所提的未知協(xié)議是指協(xié)議雙方商定的、未公開且具有一定固定格式的協(xié)議,這種協(xié)議并非完全沒有規(guī)律可尋,當同種未知協(xié)議的比特流數(shù)據(jù)大量積累時,尋找其中規(guī)律便成為可能.該文將鏈路未知協(xié)議分析分為頻繁序列統(tǒng)計、關(guān)聯(lián)規(guī)則挖掘、鏈路幀切分到獲取其他幀格式信息四個方面進行總結(jié),即總結(jié)了從數(shù)據(jù)的預處理到還原幀結(jié)構(gòu)整個過程的方法,國外最近的相關(guān)研究很少,因此該文主要總結(jié)了國內(nèi)的相關(guān)研究.
2 鏈路層協(xié)議知識和數(shù)據(jù)特點
2.1 鏈路數(shù)據(jù)成幀原理及結(jié)構(gòu)
依據(jù)OSI協(xié)議體系結(jié)構(gòu)理論,物理層和數(shù)據(jù)鏈路層屬于網(wǎng)絡(luò)底層,網(wǎng)絡(luò)數(shù)據(jù)傳輸過程中,發(fā)送方將網(wǎng)絡(luò)層的IP數(shù)據(jù)包傳送到數(shù)據(jù)鏈路層后,在數(shù)據(jù)的前后分別添加首部和尾部,封裝成幀如圖1,再交由物理層以比特流的形式傳輸出去,接收方從收到物理層上交的比特流后,在鏈路層就能根據(jù)首部和尾部的標記,從收到的比特流中識別出幀的開始與結(jié)束.

圖1 封裝成幀F(xiàn)ig.1 Encapsulated frame
幀格式一般包括幀頭部字段與數(shù)據(jù)字段.幀頭包含幀同步序列,以及地址域、控制域等常用域.一種鏈路協(xié)議的同步序列在通信過程中始終不變,地址域、控制域等常用域的長度以及在特定幀的幀頭中的位置通常是固定的.幀頭部字段如圖2,包含固定域與可變域,其中固定域是幀頭中內(nèi)容和位置均固定的比特字段,可變域的內(nèi)容在通信過程中往往會發(fā)生改變.這種在鏈路幀幀頭間隔出現(xiàn)固定域和可變域的現(xiàn)象普遍存在,這也是從比特流中識別鏈路幀頭結(jié)構(gòu)的基礎(chǔ).

圖2 數(shù)據(jù)幀幀頭結(jié)構(gòu)Fig.2 Data frame header structure
如圖3是簡單的以太網(wǎng)幀格式,其中有前導字段(包括同步碼和開始標識符等,用于幀同步)、目的地址字段、源地址字段、幀內(nèi)容(數(shù)據(jù)鏈路層所承載的信息)、校驗字段(用于差錯控制).

圖3 以太網(wǎng)幀格式Fig.3 Ethernet frame format
2.2 鏈路幀比特流數(shù)據(jù)特點
目前采取的各類解析幀結(jié)構(gòu)的方法都是要考慮到比特流數(shù)據(jù)特點[10]的,具體如下:
“01”性:即比特流中包含的元素非0即1,不可能出現(xiàn)其他元素.這是由通信和存儲介質(zhì)本身特點決定的,比紛繁復雜的數(shù)據(jù)庫信息要簡單得多.
有序性:由于比特流的傳輸遵循時間的順序,因此比特的出現(xiàn)順序是默認不可改的,體現(xiàn)為比特與比特之間的排列順序不滿足交換律.舉例來說,如序列“0101”不同于“1010”,也不能等同于“1100”.這對選取怎樣的算法統(tǒng)計頻繁序列很重要.比如數(shù)據(jù)挖掘中強調(diào)的是“集合”的概念,不對元素之間的順序做要求,{a,b}與{b,a}等都是等同的.
無界性:在獲得的比特流數(shù)據(jù)中,無法確定哪個比特是一個字節(jié)或一個幀的開始和結(jié)束.
關(guān)聯(lián)性:每段比特流數(shù)據(jù)承載不同的內(nèi)容,涉及到數(shù)據(jù)幀的同步序列、幀頭、負載、校驗等,其相互之間也存在著一定的關(guān)聯(lián)特性.
2.3 鏈路未知幀分類
本文總結(jié)當前學術(shù)界對于數(shù)據(jù)鏈路層的未知協(xié)議分析、解析工作的研究成果,將其分為兩類[11]:
1)基于經(jīng)典協(xié)議匹配庫的未知協(xié)議分析:對于給定的一串幀比特流且無法確定采用何種鏈路層協(xié)議,但可以肯定的是采用的這種協(xié)議是經(jīng)典的鏈路協(xié)議之一.這種情況在電子對抗場景中經(jīng)常發(fā)生,作為竊聽一方由于無法獲知通信雙方的預先溝通消息,缺乏通信的協(xié)議格式,這就需要與經(jīng)典的規(guī)范協(xié)議庫先做比對后判斷.
2)完全未知協(xié)議特征的未知協(xié)議分析:實際上,鏈路層協(xié)議種類復雜、數(shù)目繁多、數(shù)據(jù)量大,在軍方、商業(yè)應用中多是未被公布出的協(xié)議.對于由這類完全未知協(xié)議特征構(gòu)建的比特流數(shù)據(jù)在實際應用中越來越普遍,而基于經(jīng)典協(xié)議匹配庫的未知協(xié)議分析方法顯然不能奏效.即使這樣,對這種完全未知的協(xié)議仍有分析的必要,這也是今后研究的重點.
3 頻繁序列統(tǒng)計算法
3.1 模式匹配技術(shù)
從大量的“01”碼流數(shù)據(jù)中尋找特征序列或匹配關(guān)鍵字段最常用的方法就是模式匹配技術(shù),這也是檢索方法中最基本的策略.模式匹配算法就是在目標串中查詢出指定模式串出現(xiàn)的位置的算法,結(jié)合比特流數(shù)據(jù)特點的定義,就是在物理層處理后獲取的鏈路幀數(shù)據(jù)中查詢出特征序列.模式匹配算法由于使用需求不同可分為三類:精確匹配算法、近似匹配算法和正則表達式匹配算法.在協(xié)議分析研究實際中,默認模式串集合是已知的,目標串中也存在與之完全相同的目標子串,因此釆用的是精確匹配算法,其中又包括單模式匹配和多模式匹配.
1)單模式匹配:比較經(jīng)典且適用的有BF、KMP、BM算法,同時王和洲等人在2014年提出更高效、更適用于比特流數(shù)據(jù)的QS算法,關(guān)于四種算法的具體內(nèi)容不再贅述,主要對四種算法從算法思路、時空間復雜度、算法效率三個方面作總結(jié)比較如表1.時空復雜度由C代碼實現(xiàn)算法后計算得出,算法效率由4組仿真實驗,即2元字符集組、4元字符集組、20元字符集組以及自然語言字符集組驗證.(注:目標串長度為n,模式串長度為m,σ為目標串和模式串字符集大小)
然而,單模式匹配對于已知協(xié)議的分析具有較好的效果,而未知協(xié)議的特征尋找由于有大量模式串要匹配,單模式匹配算法需要重復掃描源數(shù)據(jù),效率很低,不能適用.
2)多模式匹配:多模式匹配算法主要有Aho-corasick、 Wu-Manber,即AC和WM兩種算法,前者是基于有限自動機,后者基于Hash函數(shù).詳細比較如表2(注:M表示所有模式串長度總和,B為塊字符長度,n,m同表1)
未知協(xié)議的比特流特征尋找最大特點就是多候選模式,與多模式匹配算法所解決的問題完全一致.利用成熟的多模式匹配算法,可以通過一遍掃描得到各候選序列出現(xiàn)的位置以及次數(shù),以便進一步篩選.但要應用于比特數(shù)據(jù)流環(huán)境,則需要對它們進行改進.
3.2 改進的多模式匹配算法
改進的多模式匹配算法更專注于如何快速、準確且適合比特流數(shù)據(jù)進行匹配.如文獻[12]中提出的AC-BM算法,就是將經(jīng)典的AC算法和BM算法結(jié)合,它綜合了兩個算法的特點,即沿用AC算法建立模式樹,而樹的檢索方法則是BM算法.在之后的文獻[13],張楠等則繼續(xù)對AC-BM算法進行改進以適應協(xié)議分析的數(shù)據(jù)環(huán)境.
2011年上海交通大學金凌等人提出從減少數(shù)據(jù)庫操作次數(shù)和對頻繁序列篩選的兩方面考慮,融入剪枝思想,考慮在統(tǒng)計過程中對有限狀態(tài)自動機進行“剪枝”,進而提出了面向比特流的枚舉樹剪枝算法.算法分為幾個主要環(huán)節(jié):建樹、計數(shù)和剪枝,是一個自我調(diào)節(jié)的反饋過程.通過剪枝達到了兩個目的:
1)盡早排除一些不可能是頻繁序列的模式,以減少以后統(tǒng)計過程中的數(shù)據(jù)庫操作次數(shù),提高統(tǒng)計的效率.
2)統(tǒng)計結(jié)束的同時給出頻繁序列的挖掘結(jié)果,不必進行二次計算,當然該算法也存在缺點,即如果剪枝過早,容易造成頻繁序列丟失,剪枝過晚提升效率又不明顯.
表1 四種單模式匹配算法
Table 1 Four kinds of single pattern matching algorithm

四種算法算法思路時/空間復雜度算法效率BF算法該算法是使用內(nèi)外兩重循環(huán)對數(shù)據(jù)進行遍歷.外層循環(huán)控制窗口在目標串中從左向右移動,該窗口與模式串長度等長,窗口從目標串中獲得目標子串,內(nèi)層循環(huán)用于逐位比較目標子串與模式串是否相同.缺點:沒有利用到每次內(nèi)循環(huán)已匹配部分的信息,有重復的字符比較,導致效率低.最好時空間復雜度分別為On(),O1().最壞情況下時空間復雜度分別為Omn(),Om()效率最差KMP算法鑒于BF算法缺點,避免重復比較,定義“前綴”:模式串中發(fā)生不匹配字符的前面那一段字符中最長的重復子字符串.算法利用程序外循環(huán)控制窗口移動,內(nèi)循環(huán)比較模式串與目標子串;內(nèi)循環(huán)從左向右匹配過程中,如發(fā)生失配,通過查詢“前綴”確定外部循環(huán)推進步伐.時空間復雜度分別為Om+n(),Om()次于BM,好于BFBM算法算法提出在匹配的過程中,采用從后向前比較的方式,對模式串的后綴進行匹配,在完成一次(包括匹配失敗或成功)后,利用兩個根據(jù)模式串預處理好的移動表壞字符移動與好后綴移動來進行位置后移.最好時空間復雜度分別為Om/n(),Om+σ()最壞時間復雜度On-m+1()m+σ)次于QS,好于KMPQS算法算法思想核心與KMP、BM算法類似,不同的是發(fā)生失配時,不是去找匹配中失配字符在模式串的位置、子串(前綴、后綴)的自包含,而是直接尋找當前窗口在目標串中右一位的那個字符在模式串的位置,利用這個字符的信息進行跳躍.時空間復雜度為O(n/(m+1)),Om+σ().最壞時間復雜度為Omn()QS最優(yōu)
表2 兩種多模式匹配算法
Table 2 Two multi pattern matching algorithms
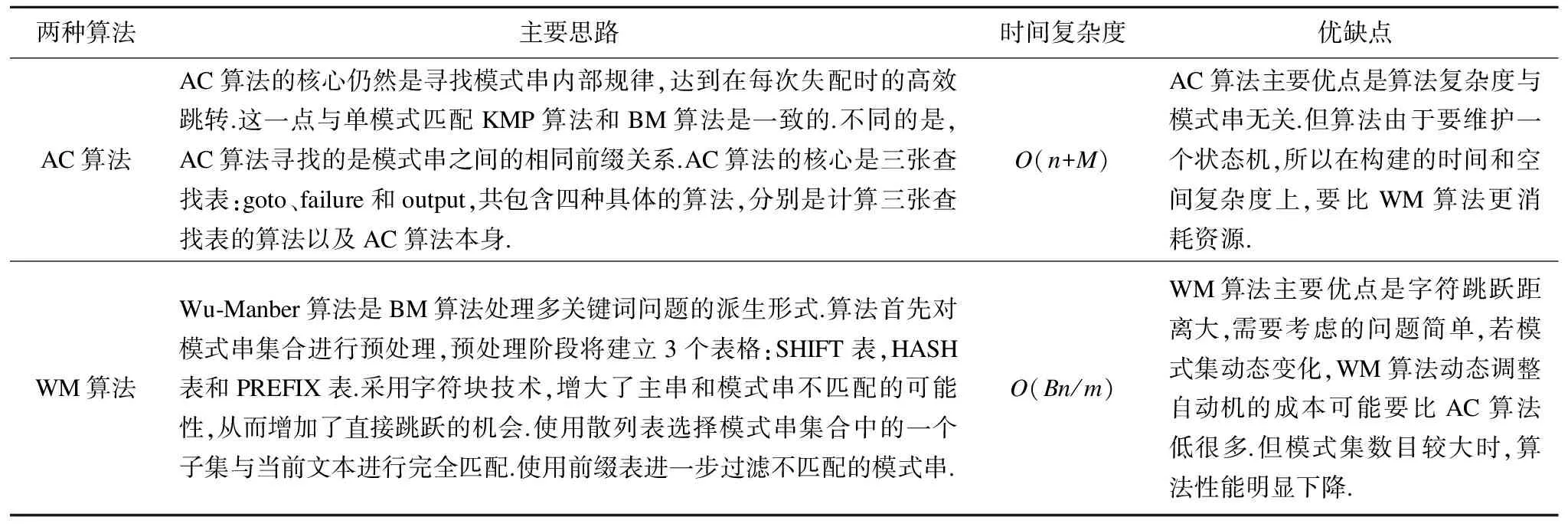
兩種算法主要思路時間復雜度優(yōu)缺點AC算法AC算法的核心仍然是尋找模式串內(nèi)部規(guī)律,達到在每次失配時的高效跳轉(zhuǎn).這一點與單模式匹配KMP算法和BM算法是一致的.不同的是,AC算法尋找的是模式串之間的相同前綴關(guān)系.AC算法的核心是三張查找表:goto、failure和output,共包含四種具體的算法,分別是計算三張查找表的算法以及AC算法本身.O(n+M)AC算法主要優(yōu)點是算法復雜度與模式串無關(guān).但算法由于要維護一個狀態(tài)機,所以在構(gòu)建的時間和空間復雜度上,要比WM算法更消耗資源.WM算法Wu?Manber算法是BM算法處理多關(guān)鍵詞問題的派生形式.算法首先對模式串集合進行預處理,預處理階段將建立3個表格:SHIFT表,HASH表和PREFIX表.采用字符塊技術(shù),增大了主串和模式串不匹配的可能性,從而增加了直接跳躍的機會.使用散列表選擇模式串集合中的一個子集與當前文本進行完全匹配.使用前綴表進一步過濾不匹配的模式串.O(Bn/m)WM算法主要優(yōu)點是字符跳躍距離大,需要考慮的問題簡單,若模式集動態(tài)變化,WM算法動態(tài)調(diào)整自動機的成本可能要比AC算法低很多.但模式集數(shù)目較大時,算法性能明顯下降.
目前采用較多的是張楠提出的改進AC算法,使其按位讀取原始數(shù)據(jù),非常好的適應了二進制比特流環(huán)境.改進AC算法之后,原始的根節(jié)點root仍保持為空,保留AC算法的轉(zhuǎn)移函數(shù),但失效函數(shù)不再使用,由于比特流數(shù)據(jù)的單一性,只存在“0”和“1”,且改進后建立的AC字典樹包含了所有的n位以內(nèi)的狀態(tài),不會出現(xiàn)匹配失效的情況.同樣,不再需要輸出函數(shù).改進后的AC算法是按比特位讀取數(shù)據(jù)的,第一步起始讀入1位比特序列后,根據(jù)讀入內(nèi)容,轉(zhuǎn)入相應的狀態(tài),然后每讀入一位都根據(jù)讀入內(nèi)容轉(zhuǎn)移狀態(tài),直到轉(zhuǎn)移到字典樹的最末端葉子節(jié)點時,在其狀態(tài)相應的序列出現(xiàn)次數(shù)加1.但基于改進AC算法的比特流頻繁序列挖掘方法僅適用于長度較短的頻繁模式,當候選模式長度m較大時,便無法進行.
最近,琚玉建[14]等提出一種基于Trie樹結(jié)構(gòu)的頻繁統(tǒng)計方法,為了減少幀數(shù)據(jù)段冗余的干擾并考慮到處理大量數(shù)據(jù)時帶來的時空復雜度,同時保證算法的有效性,琚玉建提出利用Trie樹[15]結(jié)點對應路徑字符串的特性存儲統(tǒng)計比特流數(shù)據(jù).利用Trie樹結(jié)構(gòu)改進對比特流進行存儲統(tǒng)計,在兼顧比特流數(shù)據(jù)特點、保證算法有效性的同時,降低算法復雜度,掃描一次源數(shù)據(jù)即可獲得所有的序列及其統(tǒng)計結(jié)果.具體算法描述:輸入比特流數(shù)據(jù)、最短序列長度min、最長序列長度max;輸出序列集合、出現(xiàn)次數(shù)、出現(xiàn)的位置;流程:1)枚舉符合長度的待統(tǒng)計序列,建立深度為max的Trie樹.2)分別建立長度為length=min,min+1,…,max的buffer,存儲長度為length的最新序列.3)讀入下一比特,更新buffer和Trie樹中的節(jié)點計數(shù)count(即該buffer序列出現(xiàn)的次數(shù)),并以數(shù)組形式存儲序列首位位置.
4 頻繁模式和關(guān)聯(lián)規(guī)則挖掘
從比特流數(shù)據(jù)統(tǒng)計出特征序列,包括基本的特征位如4位、8位和16位的出現(xiàn)次數(shù),緊接著就是要挖掘出頻繁序列,判定尋找合適的頻繁序列集,然后通過關(guān)聯(lián)拼接獲得長頻繁序列,進一步篩選有效的頻繁序列并擴充長度;最后通過基于位置差的關(guān)聯(lián)規(guī)則驗證,尋找上述頻繁序列之間種最有效的關(guān)聯(lián),并作為同步特征切割比特流數(shù)據(jù).
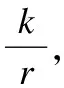
關(guān)聯(lián)規(guī)則作為數(shù)據(jù)挖掘的主要技術(shù)之一,主要用于在數(shù)據(jù)庫的大量數(shù)據(jù)中發(fā)現(xiàn)有價值的數(shù)據(jù)項之間的相關(guān)關(guān)系,找到頻繁項集,其次是挖掘出滿足設(shè)定置信度的關(guān)聯(lián)規(guī)則.關(guān)聯(lián)規(guī)則是形如X?Y的蘊含式,X、Y是數(shù)據(jù)庫中的項,在比特流中則為模式串.其置信度[17]計算如下:
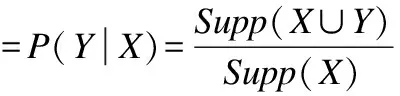
(1)
當置信度在用戶設(shè)定的最小置信度閾值與最大置信度閾值之間時,則認為該關(guān)聯(lián)規(guī)則是有趣的,即該關(guān)聯(lián)關(guān)系有效.目前主流的有Apriori算法[18]與FP-growth算法[19].孫海霞[20]使用關(guān)聯(lián)規(guī)則中的經(jīng)典算法Apriori算法來提取候選特征碼,從而建立了網(wǎng)絡(luò)數(shù)據(jù)的流量識別模型.但算法在關(guān)聯(lián)規(guī)則挖掘中,會產(chǎn)生大量的頻繁集,并會重復的掃描,執(zhí)行效率很低且造成很大的I/O開銷.J.Han[21]等人于2000年提出FP-Growth算法,FP-growth算法采用一種分治策略,將代表頻繁項集的數(shù)據(jù)庫壓縮到一棵頻繁模式樹(FP-tree),以避免代價較大的候選產(chǎn)生過程.采用自底向上的搜索策略,對FP-tree各分支所包含的頻繁模式進行搜索,該算法不產(chǎn)生候選頻繁項集.文獻[22]中就基于FP-tree研究了最大項集挖掘算法DMFIA,文獻[23]中為FP-Growth總結(jié)出了三條發(fā)展方向,其中挖掘最長頻繁項集被廣泛應用于數(shù)據(jù)流的挖掘中.而文獻[24]中就根據(jù)數(shù)據(jù)流的特點,將FP-tree改進后應用于數(shù)據(jù)流的關(guān)聯(lián)規(guī)則挖掘中,同理還有文獻[25]和文獻[26].
5 數(shù)據(jù)幀切分
從未知的鏈路層比特流中尋找能指示幀起始的序列標識,其目的就是能夠?qū)Ρ忍亓麈溌穾M行準確切分,切分幀頭.只有準確切分數(shù)據(jù)幀,才使得后續(xù)對未知幀的解析成為可能.因此,關(guān)于幀切分的方法總結(jié)也是該文的重點.
吳艷梅[27]等詳細介紹了基于相關(guān)法、基于最大自然法、基于似然比檢驗三種主流的方法,但其針對的是幀同步碼已知的情況.目前較為主流的方法還是上文提到的基于頻繁模式挖掘與關(guān)聯(lián)規(guī)則挖掘的方法挖掘幀同步序列,該方法具有普遍適用性,尤其是針對格式未知的協(xié)議.文獻[28]能夠提取出幀同步序列,針對設(shè)定的結(jié)果門限給出了多種可能的幀切分方案.楊曉靜[29]等人提出了基于偏三階相關(guān)函數(shù)峰值特性的識別方法分析和判斷幀長,該方法首先對同步碼各位上的序列進行偏三階相關(guān)函數(shù)運算,然后利用m-序列采樣后的偏三階相關(guān)函數(shù)峰值相似度高的特性區(qū)分信息碼和同步碼,最后通過進一步運算得到同步碼的碼長和起始位,并通過仿真實驗表明了該方法能夠利用較少的數(shù)據(jù)快速準確地識別出幀同步碼,具有良好的容錯性能,但僅局限在對m-序列幀同步碼的分析識別.該文著重總結(jié)了電子科學技術(shù)大學溫愛霞[30]等人在2015年提出的基于生成n-gram的幀切分技術(shù)及2016年中國科學技術(shù)大學薛開平[31]等人提出的在數(shù)據(jù)挖掘的基礎(chǔ)上利用有向圖構(gòu)建多重關(guān)聯(lián)規(guī)則進行幀切分的方法,并進行了實驗驗證.
基于生成n-gram的幀切分.該方法關(guān)鍵的兩個問題是n值的確定和n-grams的篩選,對應的兩個解決方案分別是齊夫分布和Jaccard參數(shù),采用齊夫分布來確定合適的n值,首先對n取(1,2,3,4)不同值時分別對原始數(shù)據(jù)集進行切分,對每個n-gram按其出現(xiàn)的次數(shù)進行排序,出現(xiàn)次數(shù)最多的排名為1,其次為2,一直到排名最后.用x軸表示n-gram的排序,y軸表示對應n-gram出現(xiàn)的次數(shù),兩個軸都用對數(shù)來表示,根據(jù)畫出的曲線來決定n值的大小.根據(jù)齊夫分布,選擇更接近于直線的n值.對于所得到的grams,為了防止拼接過程中產(chǎn)生過多的冗余串,需要對其進行篩選.該方法利用Jaccard參數(shù)作為選擇閾值的指標.首先將原始數(shù)據(jù)集隨機的平均分成A,B兩部分,用n-gram進行切分,分別統(tǒng)計每一部分中每一個n-gram出現(xiàn)的次數(shù),進行排序,利用Jaccard參數(shù)選擇出來的閾值對所有的n-grams進行過濾.計算Jaccard值的公式如下所示:
(2)
T1i和T2i分別表示A和B中的第i個特征.通過改變閾值來計算不同的Jaccard值,將第一次達到最高點的Jaccard值所對應的閾值作為所求,利用該閾值對所得到的grams進行過濾即可得到所需要的grams.
利用有向圖構(gòu)建多重關(guān)聯(lián)規(guī)則進行幀切分.主要步驟是:
1)設(shè)定頻繁度門限區(qū)間,從比特流中篩選出滿足頻繁度要求的序列,然后兩兩考察頻繁序列,尋找序列間的關(guān)聯(lián)規(guī)則;
2)為充分考慮關(guān)聯(lián)規(guī)則間的聯(lián)系,將得到的所有關(guān)聯(lián)規(guī)則按一定方式組織成有向圖;
3)為有向圖的序列節(jié)點分配坐標,整合參與形成有向圖的二重關(guān)聯(lián)規(guī)則,獲得多重關(guān)聯(lián)規(guī)則;
4)根據(jù)多重關(guān)聯(lián)規(guī)則在比特流中出現(xiàn)的頻率判斷其合理性,根據(jù)判斷結(jié)果調(diào)整頻繁度門限區(qū)間,確保獲得的結(jié)果正確可信.

圖4 實驗幀切分1Fig.4 Experimental of frame segmentation 1
該文采用wireshark抓取以太網(wǎng)實際測試數(shù)據(jù)對該方法進行實驗驗證,獲取的每幀數(shù)據(jù)轉(zhuǎn)為二進制后幀頭部添加7*10101010+10101011字段作為前導碼,合成64幀數(shù)據(jù)保存入Ethernet.txt.頻繁度下限設(shè)為0.5,上限設(shè)為0.65,使用QtCreator平臺實現(xiàn)算法,如圖4和圖5結(jié)果正確切分成64幀.

圖5 實驗幀切分 2Fig.5 Experimental of frame segmentation 2
6 解析其他幀格式信息
由圖3可知解析幀格式信息包括很多內(nèi)容,但從網(wǎng)絡(luò)攻擊的角度說最重要就是地址信息,目前研究也多集中在幀地址解析上.當然經(jīng)過幀切分后的不完整數(shù)據(jù)幀,由于是混合的未知多協(xié)議,首先要進行的就是將其分離成單幀協(xié)議,再繼續(xù)尋址.鄭杰[32]提出用聚類算法中的Kmeans將混合未知多協(xié)議數(shù)據(jù)幀分為單協(xié)議,并用評估算法確定所得到的類簇是比較可信的單協(xié)議數(shù)據(jù)幀,后構(gòu)造多維矩陣求解地址信息,該方法有效地簡化地址信息尋找流程,減少了頻繁計數(shù)和判斷過程,大大節(jié)省了尋找地址信息所需要的時間,經(jīng)實驗驗證,采用該方法可以對ARP數(shù)據(jù)幀的地址列信息達到2/3以上的匹配,同時,對TCP數(shù)據(jù)幀的地址列信息的識別達到100%.溫愛霞等采用基于機器學習的無監(jiān)督聚類算法實現(xiàn)數(shù)據(jù)幀的歸類操作,將數(shù)據(jù)幀的 MAC地址作為聚類的特征集,用實際數(shù)據(jù)設(shè)計對比實驗,比較了幾種常用的如Kmeans、DBSCAN、EM算法的性能.針對聚類算法對未知混合多協(xié)議分類,林榮強[33]提出了基于半監(jiān)督聚類集成,該方法利用流的相關(guān)性實現(xiàn)對標記樣本的擴展,提高標記樣本比例,引入集成學習輔助半監(jiān)督聚類對擴展后訓練集進行聚類分析,實現(xiàn)對未知協(xié)議樣本的識別,最后對得到的混合未知協(xié)議樣本集進行細分類,并實際網(wǎng)絡(luò)數(shù)據(jù)集進行仿真實驗,有效地識別未知協(xié)議數(shù)據(jù)并實現(xiàn)細分類,提高了聚類結(jié)果的穩(wěn)定性.
目前對幀地址的解析主要思路都是先采用聚類算法將切分后多數(shù)據(jù)幀進行分離,對單幀協(xié)議再進行尋址分析.但對于協(xié)議的其他信息如類型、校驗位等則沒有研究的方法,結(jié)合聚類算法的思想,該文認為可以對切分后的數(shù)據(jù)幀分別以不同字段信息的特征為簇聚類中心進行聚類,最后解析出其他幀格式信息.
7 今后研究方向展望
隨著無線網(wǎng)絡(luò)通信技術(shù)的不斷發(fā)展,未知協(xié)議在軍民上的應用也越來越廣泛.作為偵察方,尋找解析出未知協(xié)議的方法的需要也越來越強烈,該文從最初的鏈路層比特流未知幀的數(shù)據(jù)處理出發(fā)到解析出幀格式信息,歸納總結(jié)了解析過程中每一部分的研究方法、技術(shù),但對于鏈路層未知協(xié)議的解析仍有很多問題亟待解決,關(guān)于今后的研究方向概略總結(jié)如下:
1)數(shù)據(jù)挖掘的準確性問題.幀切分和幀格式信息的解析前提都是要有準確的頻繁序列和關(guān)聯(lián)規(guī)則挖掘,要提高準確率就需要挖掘大量的比特流數(shù)據(jù),這無疑會損耗巨大的計算資源,但同時又要保證計算效率,因此剪枝算法等被提出,這樣準確率又會受到影響,目前主要還是靠人工經(jīng)驗提高挖掘準確率,這存在很大的隨機性.在今后的的研究中需要考慮如何實現(xiàn)自動的調(diào)整來代替人工經(jīng)驗.
2)加強其他格式信息解析的算法研究.當前的幀格式分析多集中在尋址上,但協(xié)議的其他字段同樣重要,比如協(xié)議類型等,對于完整的還原幀結(jié)構(gòu)很關(guān)鍵.同時協(xié)議包括語義和語法信息,現(xiàn)有的研究屬于基本的語義解析,考慮到構(gòu)建協(xié)議語法的邏輯模型和協(xié)議各消息之間存在的邏輯關(guān)系,后續(xù)還需要分析協(xié)議的語法信息以及幀數(shù)據(jù)段的內(nèi)容.
8 結(jié)束語
面向比特流的鏈路層未知幀,如何在缺乏先驗知識的情況下,獲取其中承載的有用信息是一項重要的研究課題.該文確定研究的無線網(wǎng)絡(luò)數(shù)據(jù)環(huán)境主要是指通過偵察設(shè)備對無線信號進行物理層的截獲,且通過一系列解調(diào)、解碼和解密以后,得到的比特流數(shù)據(jù)這一對象后,從頻繁序列統(tǒng)計、關(guān)聯(lián)規(guī)則挖掘、鏈路幀切分到解析其他幀格式信息4個方面總結(jié)歸納了相關(guān)的研究算法及最新的研究成果.給出了各算法優(yōu)缺點,對部分算法進行了實際數(shù)據(jù)實驗驗證.同時指出了當前研究算法一些亟需解決的問題,如頻繁序列挖掘中的閾值選擇對挖掘準確率的影響問題等.最后給出了鏈路層未知協(xié)議解析領(lǐng)域進一步的研究方向.
[1] Xie Xi-ren.Computer network (Sixth Edition)[M].Beijing:Electronic Industry Publishing House Press,2007.
[2] Wu Peng-chong.Research and implementation of non default port network protocol identification system [D].Beijing:Beijing University of Posts and Telecommunications,2009.
[3] Madhukar A,Williamson C.A longitudinal study of P2P traffic classification[C].The 14th IEEE International Symposium on Modeling,Analysis,and Simulation of Computer and Telecommunication Systems,Washington,2006:179-188.
[4] Kim M S,Won Y J,Hong J W K.Application-level traffic monitoring and an analysis on IP networks[J].Journal of Electronics Telecommunications Research Inst,2005,27(1):22-42.
[5] Bernaille L,Teixeira R,Akodkenou I,et al.Traffic classification on the fly[J].ACM SIGCOMM Computer Communication Review,2006,36(2):23-26.
[6] Cai X,Zhang R,Wang B.Machine learning and keyword-matching integrated protocol identification [C].The 3th IEEE International Symposium on Broadband Network and Multimedia Technology,Beijing,2010:164-169.
[7] Wang Y,Zhang Z,Yao D,et al.Inferring protocol state machine from network traces:a probabilistic approach[M].Springer Berlin Herdelberg,2011,67(15):1-18.
[8] Wang Y,Li X,Meng J,et al.Biprominer:automatic mining of binary protocol features[C].The 12th International Conference on Parallel and Distributed Computing,Applications and Technologies,Gwangju,2011:179-184.
[9] J.Antunes N Neves,Verissimo P.Reverse engineering of protocols from network traces [J].IEEE Computer Society 2011,5(21):169-178.
[10] Jin Ling.Study on bit stream oriented unknown frame head identification [D].Shanghai:Shanghai Jiao Tong University,2011.
[11] Wang He-zhou,Xue Kai-ping,Hong Pei-lin,et al.The bit- stream cutting algorithm for unknown link-layer protocol based on frequent statistics and association rules [J].Journal of University of Science & Technology of China,2013,43(7):554-560.
[12] Cole R.Tight bounds on the complexity of the Boyer-Moore string matching algorithm[J].SIAM Journal on Computing,1994,23(5):1075-1091.
[13] Zhang Nan.Identification and analysis of unknown protocol fingerprint characteristics in wireless network environment [D].Chengdu:University of Electronic Science and Technology of China,2014.
[14] Ju Yu-jian,Xie Shao-bin,Zhang Wei.Fingerprint identification and discovery of data based on the adaptive weight data[J].Computer Measurement and Control,2014,22(7):2288-2294.
[15] Fredkin E.Trie memory[J].Communication of the ACM,1960,3(9):490-499.
[16] Lei Dong,Wang Tao,Zhao Jian-peng,et al.Survey of bit stream oriented unknown protocol identification and analysis techniques [J].Application Research of Computers,2016,33(11):3206-3210.
[17] Chen Geng,Zhu Yu-quan,Yang He-biao,et al.Study of some key techniques in mining association rule references[J].Computer Research and Development,2005,42 (10):1785-1789.
[18] Liu Qi,Bu Jun-jia,Chen Chun.Application of keyword recommendation based on apriori algorithm in topic oriented user personalized search [J].Pattern Recognition and Artificial Intelligence,2006,19 (2):186-190.
[19] Gast M S.802.11 wireless networks - the definitive guide:creating and administering wireless networks[M].Digital Bibliography & Library Project,2002.
[20] Sun Hai-xia.Research on traffic identification method based on association rules [D].Hefei University of Technology,2009.
[21] Han J,Kamber M.Data mining:concepts and techniques(2nd ed)[M].Morgan Kaufmann,Machine Press,2007.
[22] Song Wei-lin.Research on data mining association rules algorithm based on maximal frequent item sets [D].Beijing:Beijing University of Posts and Telecommunications,2006.
[23] Hu Jun.Association rule mining algorithm based on FP- tree [J].Silicon Valley,2010,10(21):175.
[24] Yang Yi-zhi.Research on association rule mining method based on data stream [D].Xi′an: Xi′an University of Science and Technology,2011.
[25] Huang Wei.Data stream frequent pattern mining algorithm research [D].Xi′an: Xi′an University of Science And Technology,2010.
[26] Chen Yan.Data stream of the largest frequent pattern mining research [D].Xi′an: Xi′an University of Science and Technology,2010.
[27] Wu Yan-mei.Positioning and characteristic analysis of bit stream protocol in wireless environment [D].Chengdu: University of Electronic Science and Technology of China,2014.
[28] Wang He-zhou,Xue Kai-ping.Research on bit-stream oriented link protocol identification and analysis techniques [D].Hefei: University of Science & Technology China,2014.
[29] Bai Yu,Yng Xiao-jing,Zhang Yu.A recognition method of m-sequence synchronization codes using higher-order statistical processing[J].Journal of Electronics & Information Technology,2012,34(1):33-37.
[30] Wen Ai-xia.Research on feature discovery technology of unknown protocol in bit-stream data [D].Chengdu: University of Electronic Science and Technology of China,2015.
[31] Xue Kai-ping,Liu Bin,Wang Jin-song,et al.Unknown frame correlation analysis for link bit streams [J].Journal of Electronics and Information Technology,2016,39 (2):374-380.
[32] Zheng Jie,Zhu Qiang.Analysis and research on addresses of unknown single protocol data frames [J].Computer Science,2015,42 (11):184-187.
[33] Lin Rong-qiang,Li Ou,Li Qing,et al.Unknown network protocol identification method based on semi-supervised ensemble [J].Journal of Chinese Computer Systems,2016,37 (6):1234-1239.
附中文參考文獻:
[1] 謝希仁.計算機網(wǎng)絡(luò)(第六版)[M].北京:電子工業(yè)出版社,2007.
[2] 吳鵬沖.非默認端口網(wǎng)絡(luò)協(xié)議識別系統(tǒng)的研究與實現(xiàn)[D].北京:北京郵電大學,2009.
[10] 金 凌.面向比特流的未知幀頭識別技術(shù)研究[D].上海:上海交通大學,2011.
[11] 王和洲,薛開平,洪佩琳,等.基于頻繁統(tǒng)計和關(guān)聯(lián)規(guī)則的未知鏈路協(xié)議比特流切割算法[J].中國科學技術(shù)大學學報,2013,43(7):554-560.
[13] 張 楠.無線網(wǎng)絡(luò)環(huán)境下未知協(xié)議指紋特征識別與分析[D].成都:電子科技大學,2014.
[14] 琚玉建,謝紹斌,張 薇.基于自適應權(quán)值的數(shù)據(jù)報指紋特征識別與發(fā)現(xiàn)[J].計算機測量與控制,2014,22(7):2288-2294.
[16] 雷 東,王 韜,趙建鵬,等.面向比特流的未知協(xié)議識別與分析技術(shù)綜述[J].計算機應用研究,2016,33(11):3206-3210.
[17] 陳 耿,朱玉全,楊鶴標,等.關(guān)聯(lián)規(guī)則挖掘中若干關(guān)鍵技術(shù)的研究[J].計算機研究與發(fā)展,2005,42(10):1785-1789.
[18] 劉 琦,卜俊佳,陳 純.基于Apriori算法的關(guān)鍵詞推薦在面向主題的用戶個性化搜索中的應用[J].模式識別與人工智能,2006,19(2):186-190.
[20] 孫海霞.基于關(guān)聯(lián)規(guī)則的流量識別方法研究[D].合肥:合肥工業(yè)大學,2009.
[22] 宋衛(wèi)林.基于最大頻繁項目集的數(shù)據(jù)挖掘關(guān)聯(lián)規(guī)則算法研究[D].北京:北京郵電大學,2006.
[23] 胡 俊.基于FP-樹的關(guān)聯(lián)規(guī)則挖掘算法淺談[J].硅谷,2010,10 (21):175-175.
[24] 楊溢之.基于數(shù)據(jù)流的關(guān)聯(lián)規(guī)則挖掘方法的研究[D].西安:西安科技大學,2011.
[25] 黃 威.數(shù)據(jù)流的頻繁模式挖掘算法研究[D].西安:西安科技大學,2010.
[26] 陳 艷.數(shù)據(jù)流的最大頻繁模式挖掘研究[D].西安:西安科技大學,2010.
[27] 吳艷梅.無線環(huán)境下比特流協(xié)議幀定位與特征分析[D].成都:電子科技大學,2014.
[28] 王和洲.面向比特流的鏈路協(xié)議識別與分析技術(shù)[D].合肥:中國科學技術(shù)大學,2014.
[29] 白 彧,楊曉靜,張 玉.基于高階統(tǒng)計處理技術(shù)的m-序列幀同步碼識別[J].電子與信息學報,2012,34(1):33-37.
[30] 溫愛霞.比特流數(shù)據(jù)未知協(xié)議特征發(fā)現(xiàn)技術(shù)研究[D].成都:電子科技大學,2015.
[31] 薛開平,柳 彬,王勁松,等.面向鏈路比特流的未知幀關(guān)聯(lián)分析 [J].電子與信息學報,2016,39 (2):374-380.
[32] 鄭 杰,朱 強.未知單協(xié)議數(shù)據(jù)幀的地址分析與研究[J].計算機科學,2015,42(11):184-187.
[33] 林榮強,李 鷗,李 青,等.基于半監(jiān)督聚類集成的未知網(wǎng)絡(luò)協(xié)議識別方法[J].小型微型計算機系統(tǒng),2016,37(6):1234-1239.
猜你喜歡
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
原道(2020年2期)2020-12-21 05:47:06
當代陜西(2019年15期)2019-09-02 01:52:00
中國非營利評論(2018年2期)2018-06-18 10:48:50
學苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
自動化學報(2017年1期)2017-03-11 17:31:17
讀者(2017年5期)2017-02-15 18:04:18
西藏科技(2016年5期)2016-09-26 12:16:39
振動工程學報(2015年1期)2015-03-01 01:15:42
