基于隨機森林的低階數(shù)字調(diào)制識別算法研究*
2018-03-21 00:56:08譚正驕施繼紅胡繼峰
通信技術(shù) 2018年3期
關(guān)鍵詞:信號
譚正驕,施繼紅,胡繼峰
(云南大學(xué) 信息學(xué)院,云南 昆明 650500)
0 引 言
在復(fù)雜的無線通信環(huán)境中,如何對不同調(diào)制參數(shù)和不同調(diào)制方式的通信信號進行監(jiān)視和識別,一直是人們關(guān)注的焦點。對調(diào)制方式的識別,是非協(xié)作通信中一項不可或缺的關(guān)鍵技術(shù),是認知無線電、軟件無線電等領(lǐng)域研究的基礎(chǔ),在軍事和民用領(lǐng)域有著廣泛應(yīng)用,如信號監(jiān)控、干擾識別、電子對抗及軍事威脅分析等方面。目前,調(diào)制識別算法大致可分為兩大類:基于
似然比判決理論的方法和基于統(tǒng)計模式的方法[1]。基于似然比判決理論的方法在實際應(yīng)用中存在對先驗知識依賴性大、推導(dǎo)復(fù)雜、計算量大的問題。相較于判決理論的方法,統(tǒng)計模式的方法因其簡便易行且設(shè)計合理時可接近最優(yōu)而得到廣泛應(yīng)用。統(tǒng)計模式的方法因其使用特征參數(shù)的不同,可以分為多種具體算法。具體地,基于瞬時特征的算法是Nandi和Azzouz于1998年利用瞬時幅度、頻率和相位特征,對低階數(shù)字信號進行的識別[2]。文獻[3]提出了一種改進的瞬時特征識別算法,提高了低信噪比條件下的識別性能。該算法雖然易于實現(xiàn)、特征參數(shù)提取簡單、計算量小,但特征參數(shù)易受噪聲影響[4]。基于高階統(tǒng)計量的算法適合在低信噪比條件下對信號進行識別,且具有運算量小等優(yōu)點,但對多種信號進行識別時,由于高階統(tǒng)計量的相同或接近性,無法實現(xiàn)完全識別[5-6]。文獻[7]提出了一種基于星座圖的分類方法,具有計算復(fù)雜度低、性能穩(wěn)健等優(yōu)點,但隨著星座點數(shù)的增加性能有所下降,且加大了運算量。
對此,本文通過提取調(diào)制信號的5個瞬時特征——零中心歸一化瞬時幅度的譜密度最大值γmax、歸一化中心頻率的四階矩緊致性μ42f、遞歸歸一化瞬時幅度絕對值的均值A(chǔ)1、遞歸歸一化瞬時頻率絕對值的均值A(chǔ)f1和遞歸歸一化瞬時相位絕對值的均值A(chǔ)p1,輔助以隨機森林算法,對6種典型的低階數(shù)字調(diào)制信號進行調(diào)制識別。該算法克服了決策樹過擬合問題,具有特征參數(shù)提取簡單、計算量小、易于實現(xiàn)、對噪聲有較好容忍性的特點,在低信噪比環(huán)境下具有良好的識別效果。實驗仿真表明,在信噪比不小于-5 dB的條件下,所提算法對2FSK、BPSK、4FSK、QPSK的識別正確率可達78%以上;在信噪比不小于3 dB的條件下,所提算法的調(diào)制識別正確率可達到100%。
1 隨機森林(RF)算法
隨機森林(Random Forest,RF)是由美國科學(xué)家Leo Breiman于2001年提出的一種機器學(xué)習(xí)算法。它包含多個由Bagging集成學(xué)習(xí)技術(shù)訓(xùn)練得到的決策樹[8],最終分類結(jié)果由單個決策樹的分類結(jié)果投票決定,克服了決策樹過擬合問題,只需對給定的訓(xùn)練樣本進行學(xué)習(xí)訓(xùn)練分類規(guī)則而無需分類的先驗知識,且對噪聲和異常值有較好的容忍性[9]。當(dāng)前,隨機森林算法因其良好的性能表現(xiàn),被廣泛應(yīng)用于科學(xué)研究的眾多領(lǐng)域。
隨機森林決策樹的組合是從訓(xùn)練樣本集中利用Bootstrap抽樣生成新的訓(xùn)練集。對每個新的訓(xùn)練集利用隨機特征選取方法生成決策樹,而決策樹在生成過程中不進行剪枝[10]。單棵決策樹的訓(xùn)練過程如圖1所示。
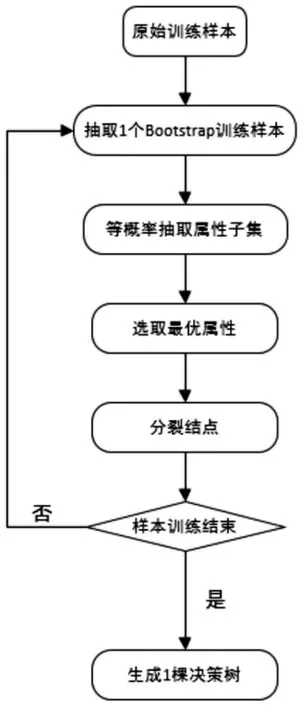
圖1 隨機森林單棵決策樹的生成過程
從圖1可以看出,在隨機森林單棵決策樹的生成過程中,首先從原始訓(xùn)練樣本中隨機抽取一個與原始訓(xùn)練樣本相同大小的Bootstrap訓(xùn)練樣本,然后等概率從屬性集合中抽取屬性子集,在屬性子集中選擇最優(yōu)屬性進行節(jié)點分裂,最終生成一棵決策樹。循環(huán)上述過程,直至生成K棵決策樹,構(gòu)成隨機森林。
本文基于CART算法生成隨機森林中的決策樹,而節(jié)點分裂時的規(guī)則選用Gini指標(biāo)最小原則。它的計算過程為:

其中Pi為類別Ci在樣本集S中出現(xiàn)的概率。將樣本集S分割成k個子集Sn(n=1,2,3,…,k),則劃分后的Gini系數(shù)為:
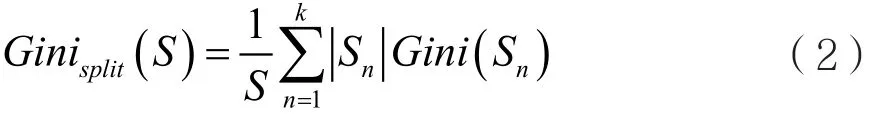
2 特征參數(shù)的提取及分析
2.1 特征參數(shù)提取
為了提取信號的時域特征參數(shù),需先對信號進行希爾伯特變換。設(shè)接收到的調(diào)制信號經(jīng)采樣后的采樣序列為S(n)(n=0,1,2,…,Ns),采樣頻率為fs,則進行希爾伯特變換后得到:
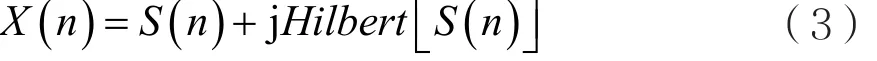
于是,瞬時幅度為:
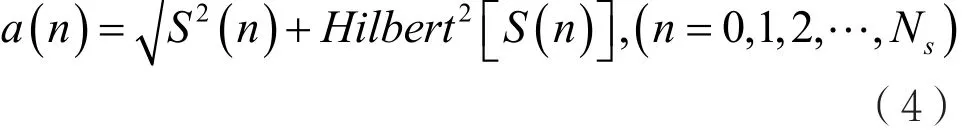
瞬時相位為:
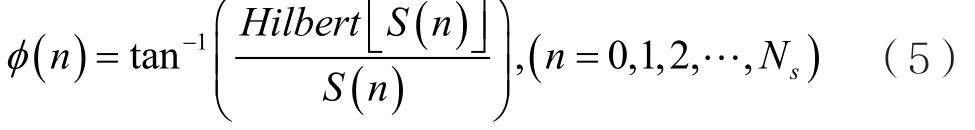
對相位序列 φ ( n )進行去相位卷疊和去線性相位運算后,得到真正的相位序列φNL,計算瞬時頻率為:
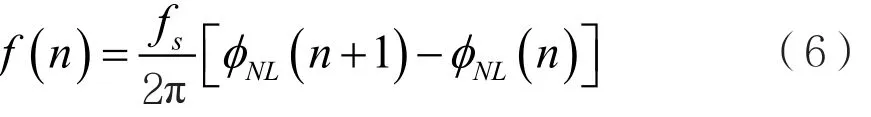
基于得到的瞬時幅度、相位和頻率,提取以下5個特征參數(shù)組成特征向量。
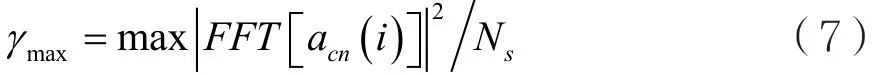
對信號進行歸一化處理,是為了消除信道增益的影響。其中,采樣速率為fs,Ns為信號樣本采樣點的樣本個數(shù),對acn(i)有如下定義:

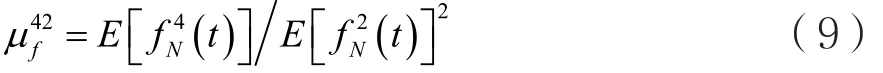


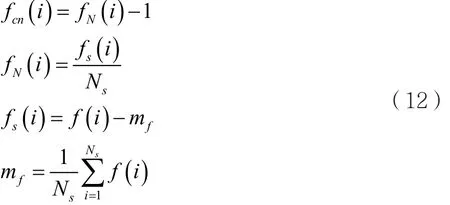

其中φ'(i )為對歸一化瞬時相位 φ (i)的歸一
NLNL化處理。φNL(i)具有如下定義:

2.2 識別原理
應(yīng)用上述提取的5個特征參數(shù)進行調(diào)制識別,其原理可用圖2簡單表示。
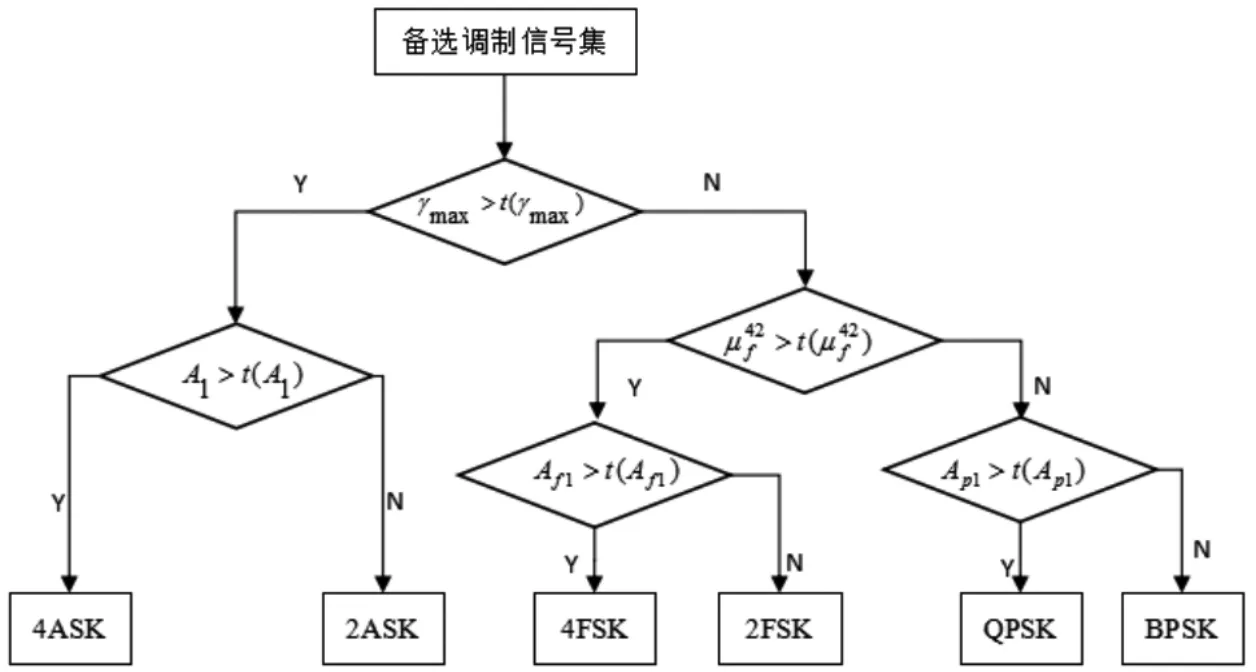
圖2 調(diào)制信號識別原理
γmax用于對MASK與MFSK、MPSK信號的類間區(qū)分;μ42f用于對MPSK與MFSK信號的類間區(qū)分;A1用于對2ASK與4ASK信號的類內(nèi)區(qū)分;Af1用于對2FSK與4FSK信號的類間區(qū)分;Ap1用于對2PSK與4PSK信號的類間區(qū)分。
2.3 基于隨機森林的調(diào)制識別算法及實現(xiàn)
本文基于隨機森林算法的低階數(shù)字信號調(diào)制識別模型,如圖3所示。
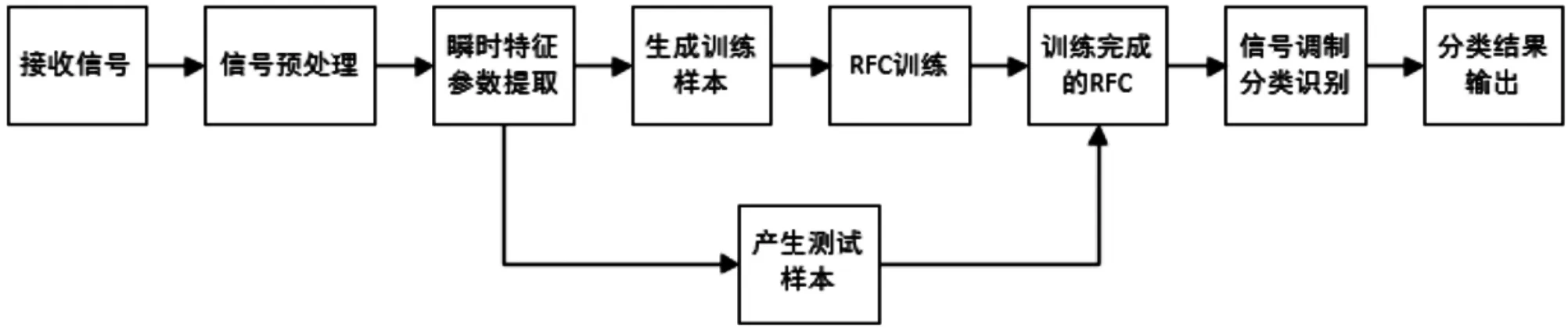
圖3 基于隨機森林算法的低階數(shù)字信號調(diào)制識別系統(tǒng)模型
在以上分析的基礎(chǔ)上,提取γmax、μ42f、A1、Af1、Ap1這5個能明顯區(qū)分各調(diào)制信號的特征參數(shù),作為信號的識別特征。通過在不同信噪比條件下提取各調(diào)制信號的上述5個特征,組成隨機森林的訓(xùn)練樣本和測試樣本。
調(diào)制識別算法的具體步驟如下:
(1)從訓(xùn)練樣本集中用Bagging的方法有放回地抽取一個Bootstrap訓(xùn)練樣本,作為一棵數(shù)訓(xùn)練樣本;
(2)每個Bootstrap訓(xùn)練樣本生成一棵不剪枝的決策樹;
(3)重復(fù)步驟(1)和步驟(2),直至生成ntree棵決策樹;
(4)由生成的ntree棵決策樹構(gòu)成森林,對未知類別的測試樣本進行分類,最終結(jié)果由各決策樹多數(shù)投票決定。
3 實驗仿真與結(jié)果分析
3.1 實驗仿真
為了驗證上述方法的可行性和有效性,選取2ASK、2FSK、BPSK、QPSK、4ASK和 4FSK共 6種典型的數(shù)字調(diào)制信號,在Matlab 2012a環(huán)境中進行仿真實驗。噪聲為高斯白噪聲,信號的碼元速率為5 kb/s,載頻為15 kHz,采樣頻率為120 kHz,載波幅度為1。在-10~20 dB的信噪比條件下,對各數(shù)字調(diào)制信號分別提取2 000組特征樣本,其中1 000組作為訓(xùn)練樣本,1 000組作為測試樣本。用訓(xùn)練樣本對隨機森林進行訓(xùn)練,將測試樣本輸入訓(xùn)練完成的隨機森林(ntree=100棵決策樹構(gòu)成,分裂節(jié)點的候選特征mtry=2)得到識別結(jié)果,則在不同信噪比條件下的識別正確率如表1所示。
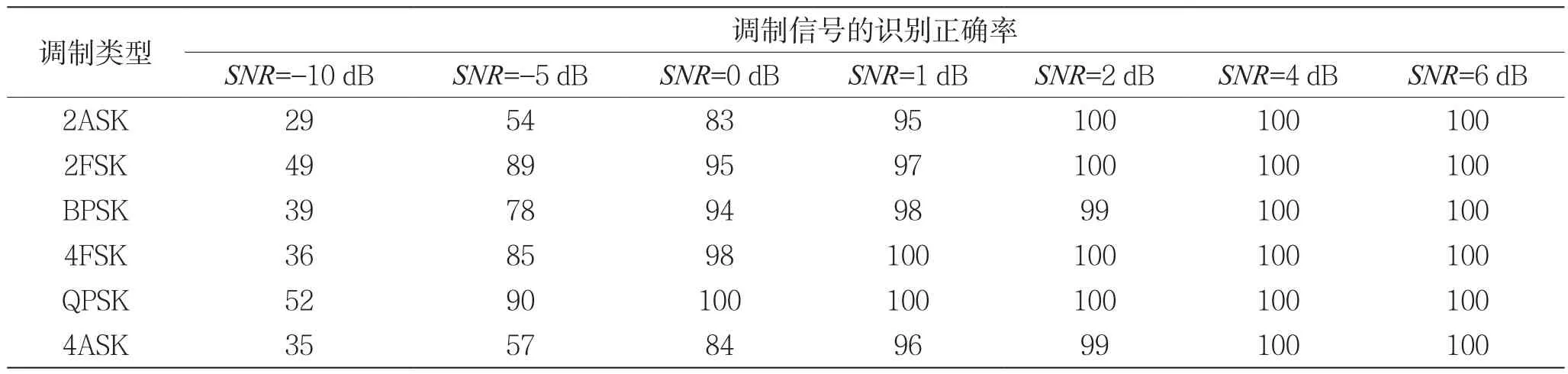
表1 各數(shù)字調(diào)制信號在不同信噪比條件下的識別正確率/(%)
在-10~20 dB的信噪比條件下,步長為1 dB,得到各數(shù)字調(diào)制信號的調(diào)制識別正確率,如圖4所示。
3.2 結(jié)果分析
從表1、圖4的結(jié)果可以看出,在信噪比不小于-5 dB的條件下,對2FSK、BPSK、4FSK、QPSK的識別正確率可達78%以上;在信噪比不小于3 dB的條件下,調(diào)制識別正確率達到100%。
對比文獻[12]采用的BP神經(jīng)網(wǎng)絡(luò)方法,所提算法的識別性能有較大改善,其中文獻[12]的識別結(jié)果如表2所示。
文獻[3]中采用傳統(tǒng)分類判決樹算法,在信噪比不小于5 dB時,識別正確率達到90%以上而在相同信噪比條件下,本文算法達到了100%的識別正確率。可見,本文所提算法的識別效果有了較大提高,且在較低信噪比條件下也能取得一定的識別效果。在信噪比0~5 dB時,文獻[13]中算法對2ASK、4ASK和文獻[14]中算法對4PSK、4ASK的平均識別正確率與本文所提算法的平均識別正確率,如圖5所示。可見,在信噪比0~5 dB時,文獻[13]中的算法對2ASK、4ASK信號的識別效果較差,但在信噪比大于10 dB的情況下,取得了95%以上的識別正確率。本文算法在1 dB以上時,對2ASK、2FSK、BPSK、QPSK、4ASK和4FSK的識別正確率均在95%以上。相較于文獻[14]的方法,本文算法對4PSK、4ASK信號的識別正確率也有了提高。
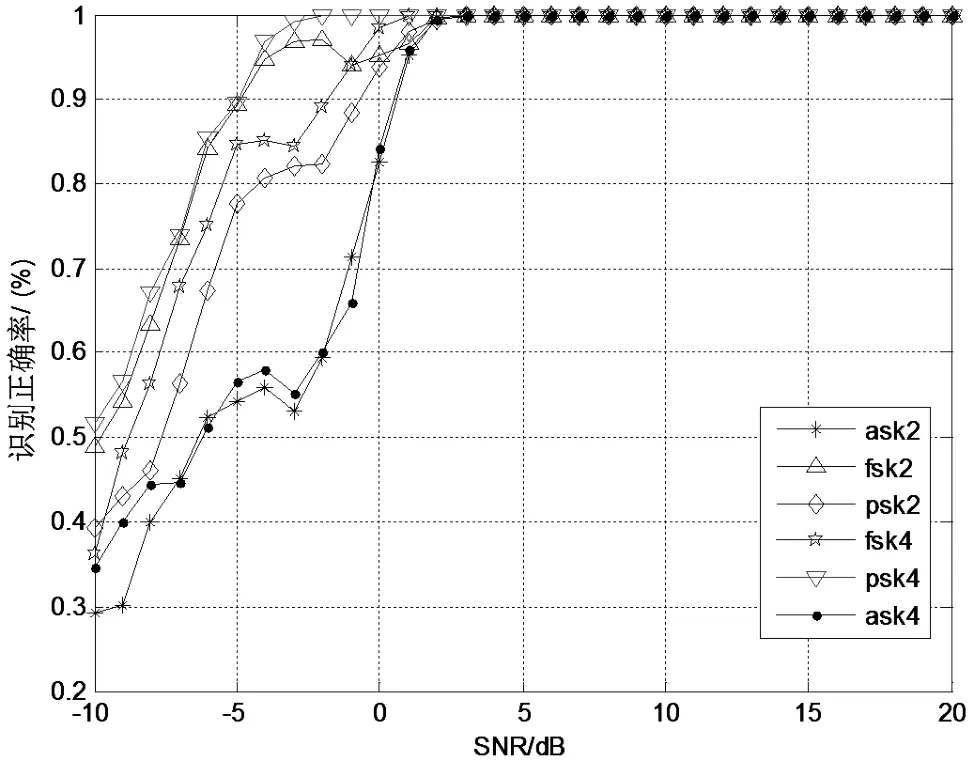
圖4 6種低階數(shù)字調(diào)制信號的調(diào)制識別正確率
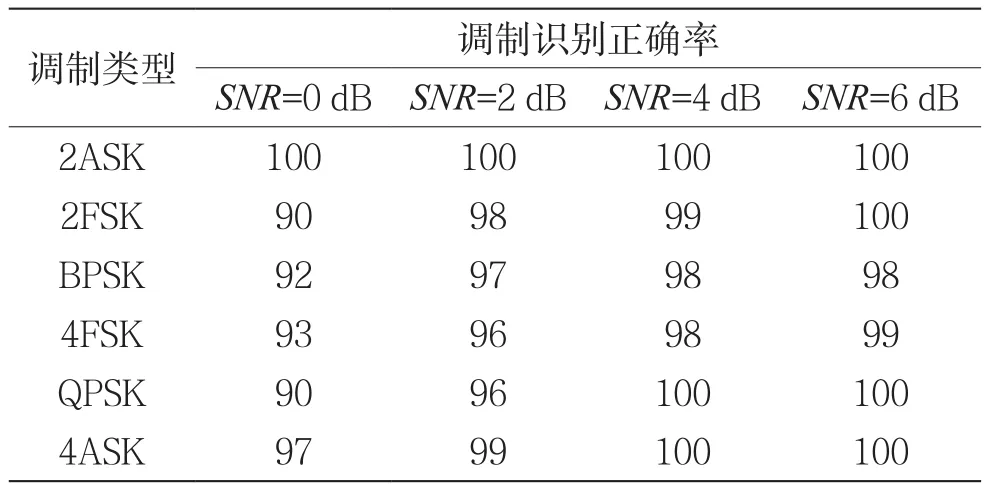
表2 BP神經(jīng)網(wǎng)絡(luò)在不同信噪比下的調(diào)制識別正確率/(%)
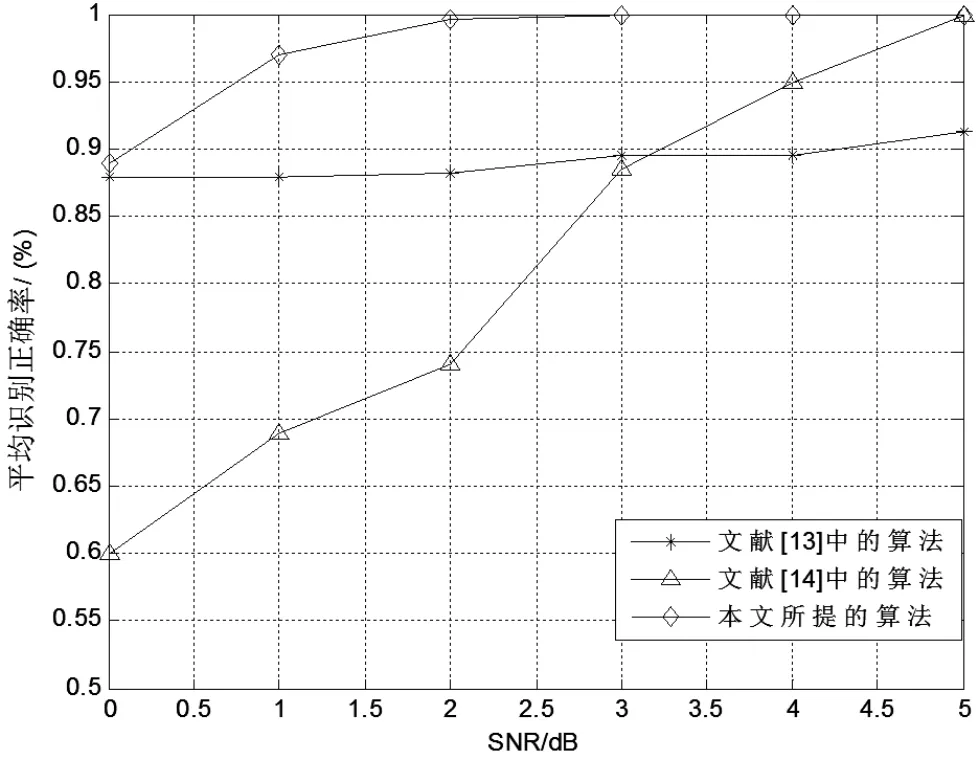
圖5 3種算法的平均調(diào)制識別正確率對比結(jié)果
4 結(jié) 語
本文采用隨機森林算法對數(shù)字調(diào)制信號的自動識別進行研究,通過分析2ASK、2FSK等6種典型低階數(shù)字調(diào)制信號的時域特征提取了5個特征參數(shù),輔助以隨機森林算法對其進行分類識別。實驗驗證表明,本文算法具有有效性和可行性,但未對更多不同調(diào)制方式的信號進行驗證。用隨機森林對數(shù)字調(diào)制信號進行自動識別,在較低信噪比條件下能取得良好的識別效果;隨機森林通過引入2個隨機性,使得隨機森林不容易陷入過擬合,具有很好的抗噪能力,且對數(shù)字信號的調(diào)制識別具有較高的精度和良好的穩(wěn)健性。
[1] 何繼愛,張文啟.通信信號調(diào)制識別技術(shù)及其發(fā)展[J].高技術(shù)通信,2016,26(02):157-165.HE Ji-ai,ZHANG Wen-qi.Communication Signal Modulation Recognition Technology and Its Development[J].High Technology Communication,2016,26(02):157-165
[2] Nandi A K,Azzouz E E.Algorithms for Automatic Modulation Recognition of Communication Signals[J].IEEE Transactions on Communications,1998,46(04):431-436.
[3] 位小記,謝紅,郭慧.基于瞬時特征參數(shù)的數(shù)字調(diào)制識別算法[J].傳感器與微系統(tǒng),2011,30(01):127-130.WEI Xiao-ji,XIE Hong,GUO Hui.Digital Modulation Recognition Algorithm Based on Instantaneous Characteristic Parameters[J].Sensors and Microsyste ms,2011,30(01):127-130.
[4] 郭彩麗,馮春燕,曾志民.認知無線電網(wǎng)絡(luò)技術(shù)及應(yīng)用[M].北京:電子工業(yè)出版社,2010.GUO Cai-li,FENG Chun-yan,ZENG Zhi-min.The Technology and Application of Cognitive Radio Network[M].Beijing:Electronic Industry Press,2010.
[5] BALDINI G,STURMAN T,BISWASi A R,et al.Security Aspects in Software Defined Radio and CognitiveRadio Networks:a Survey and a Way Ahead[J].IEEE Communications Surveys & Tutorials,2012,14(02):355-379.
[6] 張艷秋.基于高階累積量的數(shù)字信號調(diào)制識別[J].信息通信,2016,158(02):27-29.ZHANG Yan-qiu.Modulation Recognition of Digital Signal Based on High Order Cumulant[J].Information Co mmunication,2016,158(02):27-29.
[7] 崔旭,熊剛.一種基于星座圖模糊分析的數(shù)字調(diào)制識別方法[J].通信技術(shù),2016,49(09):1155-1158.CUI Xu,XIONG Gang.A Digital Modulation Recognition Method Based on the Fuzzy Analysis of Constellation[J].Communications Technology,2016,49(09):1155-1158.
[8] 夏齡.基于循環(huán)特征的調(diào)制模式識別[J].科學(xué)技術(shù)與工程,2012,12(31):8241-8246.XIA Ling.Modulation Pattern Recognition Based on the Feature of Circulation[J].Science and Engineeri ng,2012,12(31):8241-8246.
[9] 董師師,黃哲學(xué).隨機森林理論淺析[J].集成技術(shù),2013,2(01):1-7.DONG Shi-shi,HUANG Zhe-xue.A Brief Theoretical Overview of Random Forests[J].Journal of Integration Technology,2013,2(01):1-7.
[10] 方匡南,吳見彬,朱建平.隨機森林方法研究綜述[J].統(tǒng)計與信息論壇,2011,26(03):32-37.FANG Kuang-nan,WU Jian-bin,ZHU Jian-ping.A Review of Random Forest Methods[J].Statistics and Information Forum,2011,26(03):32-37.
[11] Nandi A K,Azzouz E E.Procedure for Automatic Recognition of Ainalogue and Digital Modulations[J].IEEE Proc. Commun,1996,143(05):259-266.
[12] 余嘉,陳印.基于BP神經(jīng)網(wǎng)絡(luò)的數(shù)字調(diào)制識別方法[J].傳感器與微系統(tǒng),2012,31(05):16-19.YU Jia,CHEN Yin.A Digital Modulation Recognition Method Based on BP Neural Network[J].Ensors and Microsystems,2012,31(05):16-19.
[13] 趙強,楊建波,劉鵬.一種新的聯(lián)合特征調(diào)制識別算法[J].通信技術(shù),2016,46(03):4-9.ZHAO Qiang,YANG Jian-bo,LIU Peng.A New Automatic Recognition Algorithm Based on Combined Feature Parameters[J].Communications Technology,2016,46(03):4-9.
[14] 張艷秋.基于高階累積量的數(shù)字信號調(diào)制識別[J].信息通信,2016,158(02):27-30.ZHANG Yan-qiu.Modulation Recognition of Digital Signal Based on High Order Cumulant[J].Information Co mmunication,2016,158(02):27-30.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
