面向數據庫的持久化事務內存
2018-03-13 05:00:04HillelAvni王
計算機研究與發展 2018年2期
關鍵詞:數據庫
Hillel Avni王 鵬
(華為技術有限公司 廣東深圳 518129)(hillel.avni@huawei.com)
非易失性內存(nonvolatile memory, NVM)是一種新興的技術,有望在計算機內存領域掀起一場變革.
研究人員剛剛開始了解如何在配置了非易失性內存的機器上進行編程.非易失性內存的編程模型仍然在不斷變化中,但當前下列模型處于領先地位.系統可以僅使用NVM,也可以將DRAM和NVM組合使用.在任何時候數據都會異步刷新到NVM,該過程對程序員透明.程序員也可以通過顯式調用刷新原語(Flush)將數據刷新到NVM.而持久化屏障(persistence barrier)原語允許阻塞進程,直到已將數據刷新到NVM.
處理器的緩存和寄存器將滿足易失性還是非易失性仍存在重大爭議.一些研究人員正在研究如何在意外掉電時提供足夠的電能將這些數據刷新到非易失性內存中[1].這種方法使應用程序無需為持久化增加任何運行開銷,因為整個處理器的狀態是持久的.但是,硬件設計人員對其可行性持懷疑態度,他們擔心將處理器緩存刷新到NVM需要消耗很多電能,因為緩存容量非常大,處理器非常復雜而耗電.他們表示未來的硬件只能使用余電保存NVM控制器的易失性緩沖區中的數據.英特爾目前正在基于這個假設并考慮了NVM而設計新的高效的Flush指令CLWB和CLFLUSHOPT[2].這些新指令假設緩存為易失性,并允許刷新的數據保存在緩存中,以避免緩存缺頁.這些指令也將加速刷新到NVM.
我們考慮處理器緩存和寄存器不具備非易失性的系統.在這樣的系統中,關鍵挑戰是發生掉電并且緩存和寄存器被清除時仍能確保NVM總是處于一致的狀態.
另一個被稱為硬件事務內存(hardware trans-actional memory, HTM)的新技術最近在英特爾處理器中得以實現,該技術將數據庫中的事務概念引入共享內存(HTM也在IBM的生產系統和各種研究系統中得以實現,本文僅考慮英特爾的實現).HTM允許程序員在事務中執行任意代碼塊,這些代碼塊將以原子方式完成提交,或中止而不影響內存中原有的內容.英特爾的HTM實現采用盡力提交的方式,這意味著沒有事務可以保證提交.因此,當一個事務中止足夠多次后,必須由程序員指定并執行其非事務的回退路徑.最簡單的回退路徑是全局鎖定(即阻止其他進程執行事務)并重新執行事務.但是,這種方法不適用于NVM,因為任何修改后的數據都會異步地刷新到NVM(可能會違反原子性).
HTM的實現和NVM方案之間的相互作用特別復雜,因為事務必須是原子的,但是在回退路徑上執行的寫入可以在任何時間異步刷新到NVM.因此,必須仔細設計回退路徑,以避免在發生掉電故障時將正在進行的事務的部分結果暴露給其他進程.另一個復雜之處在于HTM不能直接修改主存,這樣事務對共享內存的任何修改都是在執行該事務的處理器核的本地緩存中的數據副本上執行的.這樣,在事務提交與從緩存刷新到NVM之間存在一個時間窗.在此時間窗內發生電源故障可能會導致部分或全部已提交事務的結果丟失.
Avni等人在最近的工作[3]中引入了PHTM算法,該算法允許硬件事務在包含NVM的系統中運行.必須修改現有的HTM實現以支持NVM,因為至少需要增加一個用于標記事務是否已提交的比特位作為HTM提交的一部分,與HTM一起原子性地刷新到NVM,否則,掉電故障可能導致已提交的事務丟失.Avni等人建議修改英特爾的HTM實現,允許將單個比特位作為事務提交的一部分原子性地刷新到NVM.PHTM使用此功能來維護重演日志(redo log),以確保已提交的事務不會丟失.具體來說,允許PHTM同時提交一個事務,并將NVM中的重演日志標記為已完成(completed),以便在掉電后當且僅當事務已提交時才進行重演.PHTM中的回退路徑是面向NVM設計的持久化軟件事務內存(persistent software transactional memory, PSTM),這是一種軟件事務內存.不幸的是,PSTM順序執行所有事務,并且該算法不支持硬件事務和軟件事務之間的并發.這消除了在回退路徑上執行時的所有并發性,并且使得該算法無法隨著HTM系統中處理器核數的增加而擴展.
事務內存(transactional memory, TM)的相關文獻引入了混合事務內存(hybrid transactional memory, Hybrid TM)以解決此類性能問題.混合事務內存通過使用在回退路徑上允許并發的軟件事務內存算法來提高性能,并設計快速路徑算法,以便硬件和軟件事務可以同時運行.然而,現有的混合事務內存算法不適用于NVM,所以需要新的算法.
本文介紹了第一種面向NVM的混合事務內存系統——PHyTM.與PHTM一樣,PHyTM通過重演日志進行掉電后的恢復.PHyTM提供了無死鎖、無活鎖的原子事務.它有3種執行路徑:1)快速HTM(fast HTM),具有不插樁的硬件讀取速度;2)慢速HTM(slow HTM),可以進行插樁的讀、寫;3)軟件事務內存,鎖定讀集合和寫集合,并緩沖所有的寫操作,直到事務提交時的寫回(write-back)階段.為了避免在極少數情況下發生活鎖,STM路徑上的事務可能會使用一個粗粒度的鎖排除STM路徑上的其他事務,但允許硬件事務繼續.
快速HTM和慢速HTM可以同時運行(因為兩者都使用HTM,因此硬件可以解決數據沖突),慢速HTM和STM也可以同時運行(因為慢速HTM像STM一樣獲取鎖).但是,由于快速HTM支持不插樁讀,因此不能在沒有額外機制能夠確定STM是否使存儲器處于不一致狀態的情況下與STM同時運行.因此,快速HTM上的每個事務T都需要訂閱一個計數器,該計數器記錄了STM路徑上處于寫回階段的事務數.如果在T執行期間計數器非零,那么T可能看到不滿足一致性要求的狀態,所以需要中止T的執行;如果T的中止次數過多,T將切換到STM路徑以保證得到處理.
諸如HANA(SAP),Hekaton(微軟),TimesTen(Oracle),MemSQL和VoltDB等內存數據庫(in-memory databases, IMDB)經常應用在單節點配置的數據分析系統中,以及響應時間至關重要的應用程序中,如電信網絡和實時金融服務.在此類實現中,內存數據庫使用同步機制的一部分來協調進程對內部數據結構的訪問.常見的同步機制包括兩階段鎖(2-phase locking, 2PL):樂觀并發控制(optimistic concurrency control, OCC)和多版本并發控制(multi-version concurrency control, MVCC).最近的研究表明,SAP HANA可以從當前的HTM實現[4]中獲得顯著的性能提升,并且聲稱通過NVM的實現[5]提升了容錯能力.因此,本文的一個有價值的應用方向就是將PHyTM作為內存數據庫新的同步機制,利用HTM的能力減少傳統方法的同步開銷,同時增加對NVM的支持.
為了證明這種方法的潛力,我們在支持HTM的英特爾系統上通過模擬NVM進行了實驗.本文使用Yahoo!的云服務基準測試(Yahoo! cloud serving benchmark,YCSB)和TPC-C進行基準測試,比較了使用4種不同的同步機制實現的簡單內存數據庫的性能:2PL,OCC,PHTM和PHyTM.結果表明,PHyTM效率高并且可擴展,往往明顯優于其他機制.
我們預測非易失性內存將成為標準,并可以適應通用應用程序.這些從未使用ACID事務的程序將必須在NVM中保持一致性,以保持系統的可恢復性.那時,PHTM和PHyTM可以用來維護數據庫、數據結構和數據庫上下文.
作為正在進行的和將來的工作,我們討論了分離事務執行(split transactions execution, STE)算法,本文在數據庫特定的同步協議內使用PHTM;本文也展示了在多數事務對PHTM而言過大的情況下,如何通過STE幫助PHTM獲得更簡單和更快速的解決方案.
1 模 型
本文考慮使用了HTM和NVM的多進程異步共享內存系統.
1.1 內 存
本文所考慮的內存體系結構在最底層由全NVM內存作為主存(如果系統中也包含了DRAM,邏輯內存空間一般被分割成持久化和非持久化地址空間,為了簡化問題,本文僅考慮無DRAM的情況).不失一般性,將緩存行定義為數據的最小粒度.最底層之上是緩存,包含了主存中緩存行的副本.緩存一致性協議確保了無論有多少個緩存副本各處理器都能獲得一致的主存數據.最高層為寄存器,即每個處理器內部用于暫存數據的特殊存儲.
一般而言,在內存系統低層中進行的操作比高層慢幾個數量級.NVM的寫操作比DRAM慢,讀操作速度則至少持平.
數據從緩存異步刷新到NVM,這一過程程序員無法感知.數據也可以通過硬件原語FLUSH,參數是內存地址,顯式刷新到NVM.FLUSH(addr)操作利用緩存一致性協議將最新的緩存行副本刷新到主存地址addr.
1.2 故 障
本文將考慮系統掉電后所有易失性內存的內容丟失的情況,而不考慮其他類型的故障,如進程崩潰或拜占庭式故障.所有的緩存和寄存器都是易失性存儲,掉電后僅NVM仍保存著數據.
掉電后系統通過單個恢復進程執行一系列特殊的恢復流程.這個恢復流程在其他進程恢復運行前修復數據.由于恢復進程單獨運行,因此具有相當大的自由度,可以進行危險操作,例如強制釋放其他進程在掉電前已持有的鎖.
1.3 硬件事務內存
考慮英特爾HTM的實現,進程p通過調用xbegin啟動事務,若處理器進入事務執行模式則xbegin返回OK,否則返回退出原因.在事務模式下,每一次p對某一地址進行讀或寫操作時,將該地址加入到該事務的讀地址集合(read-set)或寫地址集合(write-set).該事務的讀地址集合和寫地址集合的并集稱為數據地址集合(data-set).若一個事務的數據地址集合與其他并發事務的寫地址集合相交則存在數據沖突.HTM系統將中止相互沖突的至少一個事務.進程p也可以通過調用xabort主動退出當前事務的執行.
事務也會因其他原因而退出執行,例如系統調用、中斷,缺頁中斷或內部緩沖區溢出.特別地,由于事務存在可訪問內存地址數的限制,超過這一限制將因容量超限而退出.容量超限無法預測,而且硬件事務由于數據地址集合持續增長而更容易出現容量超限問題.為避免容量超限而退出事務執行,事務的數據地址集合必須最少滿足如下條件:適合L1緩存的大小、避免緩存的關聯沖突、避免將事務載入的緩存行換出.另外,當2個超線程在同一個核上運行時,該核的本地緩存由這2個超線程共享,這使得每一個線程的L1 緩存容量減半,容量超限退出問題也更嚴重.
無論何時進程p的事務T退出時,p停止該事務,控制流返回到調用xbegin之前(事務啟動前).因此p下一步是調用xbegin,這一次調用將返回退出的原因(如沖突、容量超限).這樣xbegin的典型調用模式為“ifxbegin()=OK then {transaction body} else {abort handler}”.
1.4 增加對NVM的支持
需要指出硬件事務并不直接修改主存,相反,所有的事務寫是在緩存中實施的,所有相關的緩存行在事務提交后一個接一個地刷入主存.緩存一致性協議確保了受影響的緩存行將在事務提交后原子性地刷入主存.但是若在刷入主存過程中發生了掉電故障,緩存的信息可能會喪失原子性.
避免這種問題的方法之一就是讓每個事務在提交前以日志記錄寫操作并刷新到NVM中,以便在恢復過程中有足夠的信息完成掉電前的任何事務.當然,這種方法要求已實現事務處理過程中的FLUSH(不中止事務).在接下來的Avni等人的研究中[3],我們假定透明刷新(TFLUSH)不會中止事務.此外,既然日志在事務提交前已刷新到NVM,恢復進程一定能夠檢查掉電前事務是否已提交.同樣地,類似文獻[3],我們假定xend通過擴展指令在NVM中設置一個標記位,可以在事務提交到緩存時原子性地設置該比特位并刷新到NVM中.在事務提交時原子性地將標記位刷新到NVM是對當前HTM協議的最小化修改.
2 持久化HTM
Herlihy和Moss定義了硬件事務內存(HTM)[6],用于充分利用硬件緩存一致性機制在多核芯片的可緩存共享內存中執行原子事務.其基本思想是每一個事務都在當前核的本地L1緩存中隔離.“原子性”是從數據庫系統中借用的概念[7],但是,數據庫的事務與HTM事務不同,數據庫的事務是持久化的,例如當一個事務成功提交后也將備份到持久化存儲中.
由于HTM發展緩慢,大量的相關研究集中在STM以獲得低開銷和無需硬件輔助的可擴展同步事務內存.英特爾公司最早的HTM實現在2013年上市,同時STM也已整合進GCC編譯器中[8-9].
內存技術的最新進展(如PCM,STT-RAM和憶阻器)展示了NVM設備可以如DRAM一樣高速進行字節尋址,比DRAM節能,還具有非易失性,并且和HDD一樣便宜.本節將提出一種通過利用NVM進行持久化存儲而非(補充)DRAM的HTM事務的方法,同時還能夠保持易失性緩存結構.
2.1 相關研究
Coburn等人[10]提出了一種可與NVM正確工作的軟件事務內存——NV-Heaps.其基本思想遵循DSTM[11],即事務對象存儲在NVM中,可以在寫入時打開,然后STM事務T將它復制到撤銷日志(undo log)中并鎖定.T為每個事務維護一個易失性讀日志和一個非易失性撤消日志.如果發生系統故障,則中止T并使用持久化的撤消日志來復原T所做的改變.
NV-Heaps是基于對象的,而同時發表的源自TinySTM[12]的Mnemosyne STM[13]是基于字的,但是這些算法背后的思想都是非易失性撤消日志和易失性讀日志,這是相同的.
雖然正確并且可行,但由于維護記錄的開銷和鎖的序列化,基于軟件的方法性能較弱.因此,雖然有些數據庫實現使用了HTM進行同步[14-15],但是,這些數據庫仍然使用硬盤進行持久化.
PMFS[16]使用NVM作為文件系統存儲,文獻[17]使用NVM在OLTP數據庫中進行持久化. PMFS確實使用了HTM,但僅用于管理文件系統元數據這一特定目的.
2.2 術 語
非易失性內存技術的已日趨成熟,這必將改變事務系統的構建方式.NVM設備如DRAM一樣快,同樣可以進行字節尋址,比DRAM更加節能,還具有非易失性,并且和HDD一樣便宜.因此,非易失性內存將消除傳統的多層內存體系的分層,這種分層是ACID事務持久性的保證.在主存中維持失效狀態可導致系統故障后無法恢復.因此,設計故障恢復(重啟)時的持久化方案需要一種全新設計的、并且考慮周全的方法,這將從NVM中受益.后續我們將使用如下術語.
1) HTM.原子性地提交事務的同步機制,并保持隔離性.一旦HTM事務T提交,所有新修改的數據都在易失性緩存中.
2) HTM事務TK.由處理器的核心Pk執行的事務.
3) NVM.非易失性,可字節尋址、可寫的內存.
4) 重啟.重新啟動的任務是使數據處于一致性狀態,消除未提交事務的影響,并恢復丟失的已提交事務.
這里考察的硬件模型包括無限的NVM,多核處理器并且無硬盤.所有的NVM都是可緩存的,緩存是易失的并且是一致的.該系統包括有限容量的DRAM.最后,我們使用術語持久化硬件事務內存(persistent HTM, PHTM)來指代現有HTM實現的概念,并納入NVM所需的最少硬件和軟件調整.PHTM系統包括軟件和硬件.
2.3 問題定義
隨著現代硬件中處理器核心數越來越多,NVM就會越來越難以滿足持久化要求. 一方面,由于數據在NVM中,因此不需要為其另外分配一個持久化存儲器,這減少了持久化的開銷. 但另一方面,向某一地址寫入時,新值必須以新的、一致的并且持久化的狀態原子性地對外暴露.保證這種原子性的一個方案是通過鎖.隨著核心數量的不斷增加,鎖必將成為瓶頸.實現免鎖原子性的一種方法是HTM,但HTM無法訪問物理內存.這樣,當前面臨的主要問題就是填補HTM與NVM之間的差距,并允許應用程序在NVM中保持一致和持久的狀態,而且不加鎖,不復制數據.
2.4 數據存儲流程
由HTM事務T寫入的數據項x(可尋址的字)的狀態如圖1所示.請注意,x可能緩存在易失性緩存中,或者只駐留在NVM中(就像任何其他可尋址的字一樣):
1) PrivateShared.Private表示x只在一個線程的L1緩存中,對其他線程不可見.當x是Shared時,緩存一致性使其新值對其他線程可見.
2) PersistentVolatile.Persistent意味著x最后寫入的值在NVM中,Volatile表示x的新值在緩存中,并且掉電時會消失.
3) LoggedClear.當x是Logged時,重啟將從非易失性日志中恢復x.如果x是Clear,重啟將不會對x執行任何操作,因為不存在相關的記錄.這可能在事務提交或中止之后發生.
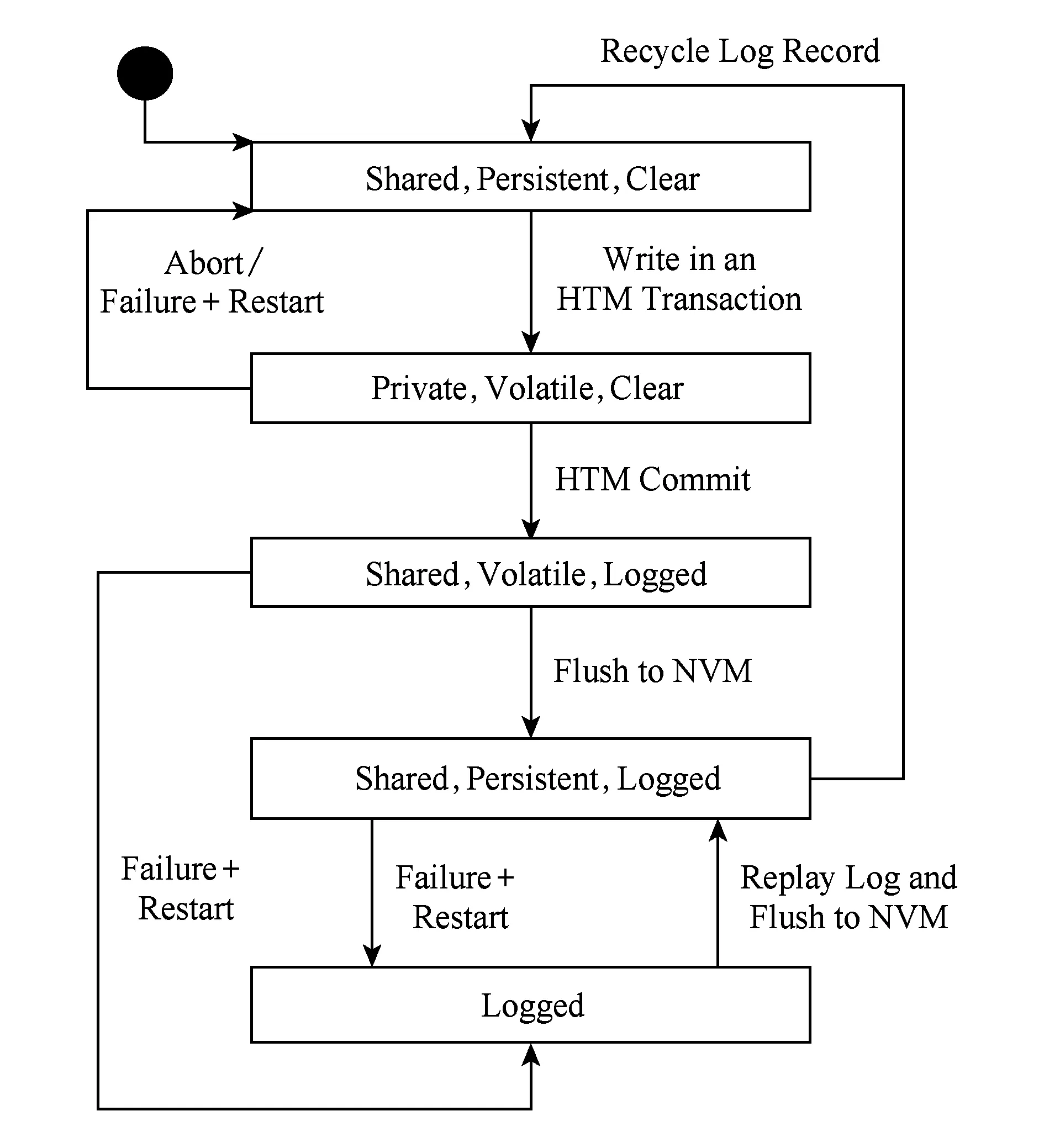
Fig. 1 State machine for a persistent transactional variable圖1 持久化事務的狀態機
盡管圖1說明了PHTM事務中單次寫入的狀態機,Logged狀態應該是針對整個事務的.也就是說,將單個事務的所有寫入從Clear轉變為Logged需要唯一的持久化寫.在PHTM提交中,所有寫入都由HTM暴露,并同時被記錄下來.每次寫入都必須生成一個持久化的日志記錄,但是直到成功提交之前,寫入操作不會被重啟進程重演.
當HTM事務Tk寫入變量x時,x在Pk的L1緩存中被標記為事務性的,并且是私有的(Private),即僅存儲在Pk的緩存中.它是易失(Volatile)的,因為它只在緩存中,而且是未記錄(Clear)的,即未記錄到日志中,因為事務還沒有被提交.在中止或掉電故障時,x的易失(Volatile)私有(Private)值將被丟棄,并將恢復到先前共享(Shared)和持久(Persistent)值.
在PHTM提交中,x的狀態改變了2次.首先變成共享的(Shared),即可見的,同時也被記錄(Logged)下來.這2次狀態改變都必須原子性地提交成功.成功提交后,PHTM將x的新值透明刷新到NVM,并清除x.如果系統發生故障并在x記錄時重新啟動,則恢復過程使用x的日志記錄來寫入提交的x值,然后清除x.
NVM中的日志不是典型的順序日志,相反,它僅保留無序的日志記錄,這些日志記錄僅用于正在運行的或已提交的事務,而且尚未回收其日志記錄.
有關PHTM實現的詳細信息,包括衍生硬件以及正確性證明,請參閱Avni等人的文獻[3].
2.5 評 估
本節使用紅黑樹的數據結構和復合基準程序測試PHTM的性能.該復合基準程序測試PHTM的開銷,以及PHTM和HTM大小限制的相關性.
測試在英特爾core i7-4770 3.4 GHz Haswell CPU上進行測試,共有4個核心,每核2個超線程,每個核心擁有本地L1和L2緩存,大小分別為32 KB 和256 KB,同時所有核心共享8 MB L3緩存.
2.5.1 硬件仿真
英特爾的Haswell處理器具備用于實驗的HTM特性.但是,NVM和PHTM仍未能在硬件上實現,所以需要仿真以進行評估.我們通過將電源開啟并僅將易失性區域(如日志標記)置零來模擬PHTM中掉電故障的影響.為了模擬tx_end_log,提交記錄在事務中寫入.由于這是事務的一部分,所以HTM本身使提交記錄在成功提交的同時可見.在TF仿真中,根據預期的NVM性能,通過加入100 ns的延遲來模擬NVM訪問時間.本文并未仿真互連流量,因為這個流量與解決方案中的互連流量(即持久化STM)相同.
2.5.2 對比算法
PHTM與標準HTM、模擬持久化的STM(per-sistent software transactional memory, PSTM)、無持久化的標準STM進行了比較.STM來自GCC[8-9],并使用最低優化級別.這是為了使所有4種算法能夠進行公平的比較,避免了用以減少訪問次數的編譯器優化.
與PHTM一樣,PSTM在持久化存儲中實現重演日志.在PSTM中寫入的開銷是提交之前的日志條目的一次刷新和提交之后的一次刷新,因此它與PHTM相當.PSTM基于Mnemosyne[13],但有少量修改.本文選擇實現重演日志和本地數據更新,以避免寫懲罰后巨大的讀操作.PHTM相對于STM的優勢在于以處理器的速度加載.為了公平比較,PSTM應該盡可能快地加載以挑戰PHTM.
PSTM的缺點源自STM,即與指令插樁、鎖和版本相關的開銷.PHTM的缺點源自HTM,即有限的事務大小.
2.5.3 性能基準
本文將在復合數組基準測試中對無爭用條件下的PHTM進行性能測試,然后在紅黑樹上測試爭用條件下的性能.檢查的算法包括HTM,PHTM,STM和PSTM.在圖2中,增加了HTM-CAP和PHTM-CAP行來統計HTM容量超限中止次數,并增加了HTM-CON以及HTM-CON和PHTM-CON行用以表示一些圖中因沖突而終止的次數.中止次數通過每秒中止的操作數進行統計.因沖突而中止并在加全局鎖之前需重新嘗試20次,但容量超限中止不會重試并立即加鎖,因為重試成功的可能性非常小.
2.5.3.1 數組負載
在這個負載中,所有的事務都具有相同的訪問次數以使其執行時間相當.該測試訪問一組連續的內存地址,所以緩存中無碎片.每個待訪問地址都在單獨的緩存行中.
1) 只讀(read-only)
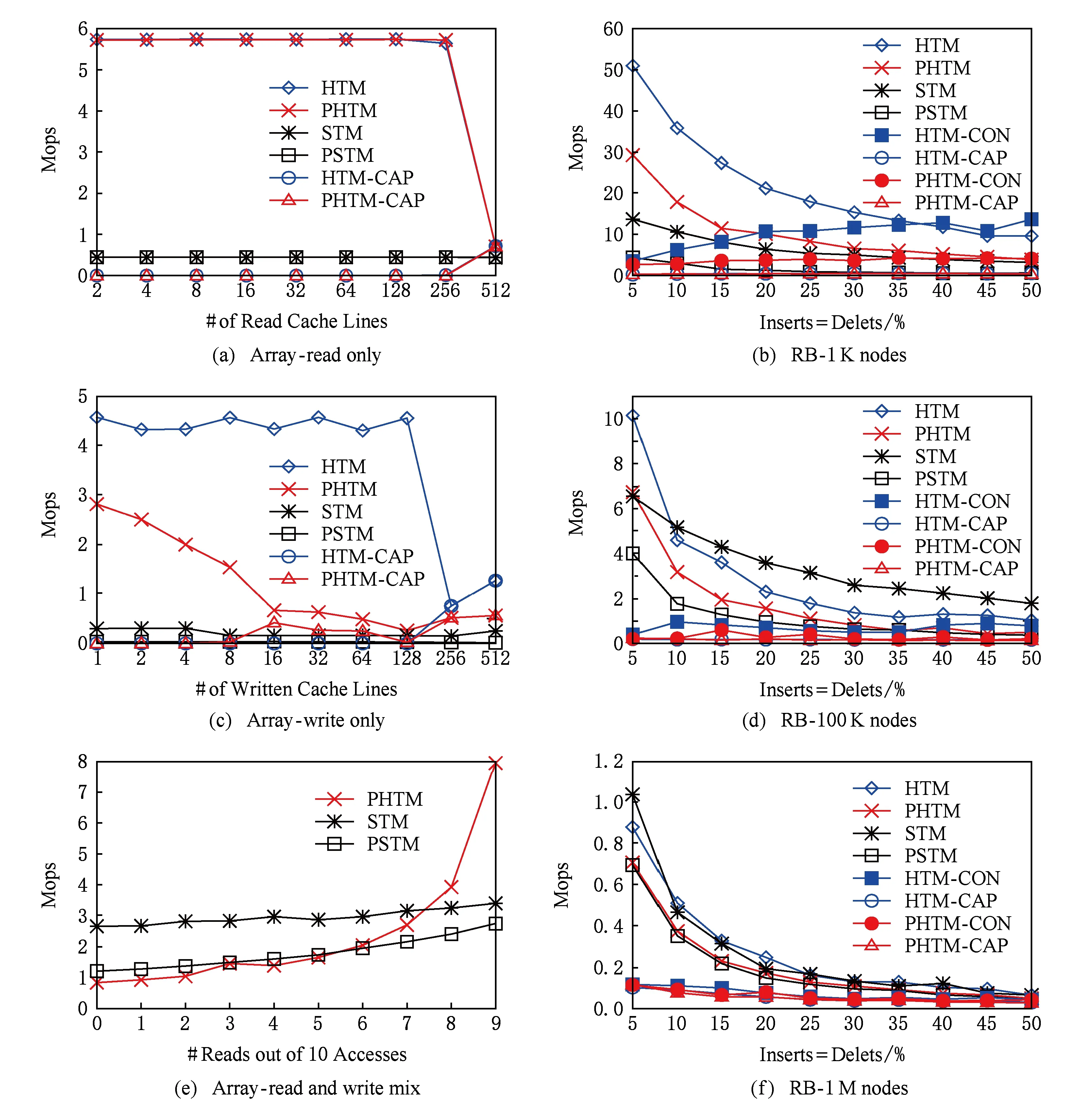
Fig. 2 Synthetic array and a red-black tree benchmarks圖2 數組和紅黑樹復合性能結果
首先觀察PHTM在只讀工作負載上的性能.這對于PHTM而言是最好的情況,因為PHTM以處理器的速度加載.在圖2(a)中,每個事務循環地執行512次加載指令到不同數量的連續緩存行.可以看到,只要避免HTM容量限制,PHTM和HTM的性能相同,并且比STM和PSTM高一個數量級.圖2(a)中的所有測試都在所有8個硬件線程上執行.由于存在超線程,每個線程的緩存大小是其核心緩存大小的一半,即16 KB或256個緩存行(每個緩存行64 B),所以當訪問集大小為512時,所有的HTM和PHTM事務都將觸及容量上限并中止退出.在這一點上,HTM和PHTM的性能等同于STM,因為它使用了撤回.如預期的那樣,STM和PSTM表現相當.
2) 只寫(write-only)
這個測試檢驗PHTM的寫入性能.圖2(c)中的性能結果與圖2(a)中的性能結果非常接近.每個事務循環地執行512次存儲指令到不同數量的連續緩存行.
可以看到,HTM性能未受到待訪問緩存行數量增加的影響,但PHTM接近PSTM的性能,因為刷新到NVM的速度決定了性能.必須強調的是,即使多次寫入緩存行,PHTM和PSTM也只能在事務中刷新一次緩存行.因此,如果事務只訪問一個緩存行,則它將512次寫入相同的緩存行,但僅刷新2次,一次在提交之后刷新數據,另一次在提交之前刷新日志.如果將TF置為非阻塞可以減小開銷.
當HTM和PHTM事務開始接近容量上限時,它們會加全局鎖,雖大大降低性能但可防止事務繼續擴大.PHTM在標準HTM之前達到容量限制.這是因為PHTM的每次寫入都要寫入一個日志條目,所以它可以訪問更多的內存.此外,日志條目不在連續內存中,所以即使在緩存已滿之前,它們也可能違反緩存關聯性.請注意,在一個真正的實現中,非事務性的存儲指令可以被用于日志,并且避免增加事務占用的空間.
3) 讀寫混合(read-write mix)
在不存在容量超限中止問題的情況下,即在小事務中,該測試檢查事務性加載指令與事務性存儲指令的數量如何影響PHTM,以及與STM和PSTM相比的性能.
在圖2(e)中,每個事務對10個相互獨立的緩存行訪問10次,并執行不同數量的寫操作.HTM并未在圖2中展示,因為它以大致相同的速度進行讀寫.圖2(e)表明直到只讀部分達到70%,STM都比PHTM快.但是當只讀部分達到90%時,PHTM已經是STM性能的2倍.如圖2(a)所示,當只讀部分達到100%時,PHTM比STM快12倍.
2.5.3.2 紅黑樹(RB-Tree)負載
為了評估爭用條件下的PHTM性能,本文使用了一種紅黑樹進行基準測試,所有事務都使用隨機鍵值訪問樹進行插入、刪除或查找操作.所執行的工作負載運行在8個核上,具有固定的鍵值范圍大小,更新的比例范圍從10%到100%.每棵樹從半滿開始,插入的數量等于刪除的數量以維持樹的大小.
第1組測試是在一個小的1 K個節點的樹上執行的.如圖2(b)所示,HTM和PHTM沒有因容量超限中止,出現了沖突退出,但可擴展性與STM相當.在這個測試中,PHTM比PSTM快大約6倍.圖2(d)中的第2組測試是在1 M個節點的樹上進行的,可以看到出現了容量超限中止,但仍較少.因此,PHTM只比PSTM快40%.盡管沖突中止率很高,但可擴展性仍然相同,這表明中止率與STM接近.為了進一步增加容量帶來的挑戰,我們原子性地在2個1 M個節點的樹上執行相同操作的事務.如圖2(f)所示,容量超限中止數上升,PHTM的性能下降到和PSTM相當.
正如預期的那樣,容量限制是HTM最大的問題,因為它會迫使事務序列化,而PHTM性能的最大障礙是它從HTM繼承的容量超限中止.在每個執行的測試中,PHTM在所有爭用水平上與HTM和來自STM的PSTM保持恒定的差異.不同之處在于工作負載中的寫入部分.樹越小,遍歷它的時間就越少,所以寫入部分相對增加,并且持久化算法的開銷相應增加.
3 持久化混合HTM
在PHyTM中,事務可以以如下3種路徑執行:快速HTM、慢速HTM和STM.每種路徑都提供了一個操作集用于啟動和提交事務,以及讀寫內存位置.這些操作并非直接由用戶代碼調用,相反,用戶簡單調用編譯器提供的操作以啟動和提交事務,編譯器將通過我們在操作集中提供的操作編譯用戶代碼,自動選擇合適的路徑執行事務.
3.1 STM路徑
本文所述STM算法通過遭遇時序(encounter-time order, ETO)實現了兩階段鎖.每一個事務首先鎖住所有它可能訪問的地址(以首次遭遇的順序),隨后可以在這些地址上進行所需操作,最后釋放所有的鎖.為避免死鎖而使用了try-lock,當無法獲取到鎖時立刻返回false,而非一般的阻塞.當一個進程獲取try-lock鎖失敗時,將釋放其持有的所有鎖并再次嘗試.存在一種罕見的情況;若一個進程獲取鎖時持續失敗,該進程將鎖住整個STM路徑.作為try-lock的備選方案,可以使用標準的死鎖檢查算法,但這樣會降低效率,尤其是在非常高競爭的場景下.
2PL和ETO的應用使得正確性的條件——不透明性[18]非常容易得以證明,不透明性可直觀表述為進程無法觀察到事務的部分結果.考慮一個要寫入一些地址的事務T,2PL和ETO要求T在訪問地址前鎖住所有這些地址,并持有鎖直到完成寫入.另外,其他任何嘗試讀取這些地址的事務T′均無法在T解鎖前操作.因此T′無法看到T的任何寫入,直到T的所有操作均已經完成.
STM將鎖住事務欲訪問的所有地址,完成讀操作并將寫操作記錄到日志中,隨后進入寫回階段.在寫回階段,事務將日志刷入NVM,完成所有的寫入操作,隨后將寫入結果刷入NVM.這種實現機制確保了日志刷入NVM的原子性,這使得恢復進程可以在提交時訪問日志(否則,已提交的事務可能丟失,未提交的事務也可能由恢復進程重演).
STM路徑提供了4種操作:用于啟動事務的STMBegin、用于替換標準內存讀的STMRead、用于替換標準寫的STMWrite、用于提交事務的STMFinalize.
STMBegin操作作為讀者獲取stmLock(若該事務嘗試次數未超限)或者作為寫者獲取(如果超限).作為寫者獲取stmLock將阻止其他事務在STM路徑上運行.
STMRead操作首先調用GetLockAddr(addr)來確定locks中的哪一個保護addr;然后調用TryReadLock(lock)以獲取讀鎖,讀取該地址,并將該地址(addr)保存在它的讀地址集合中.STMWrite操作也需要首先通過調用GetLockAddr(addr)來確定合適的lock,隨后調用TryWriteLock以獲取寫鎖.這樣做有2個目的:這個鎖授予待寫入地址的排他訪問權限,并且獨占地在寫日志(write-log)中存儲該地址.如果執行TryWriteLock的進程當前作為讀者持有鎖,并且沒有其他讀者,則TryWriteLock將讀鎖升級為寫鎖.接下來,STMWrite將addr和val添加到其寫日志條目中.請注意,STMWrite不會顯式刷新這些修改,但可能異步地寫入NVM.如果STMRead或STMWrite無法獲取鎖,則事務中止,釋放所有鎖并重試事務.
進程需要調用STMFinalize以提交STM事務.STMFinalize首先將寫日志條目刷新到NVM,然后通過調用numSTMWriteback上的FetchAnd-Increment表示事務已進入寫回階段(將會在3.3節中看到如何運用numSTMWriteback).然后設置并刷新日志條目中的logged位,這表示日志條目已準備好,可以在發生掉電故障時由恢復進程重演.當logged位刷入NVM時,事務為committed狀態.接下來,STMFinalize調用ReplayLogEntry函數來重演事務的日志條目,執行所有的寫操作并將其刷新到NVM.ReplayLogEntry也會清除并刷新logged位以表明該日志條目不再需要重演.在事務的所有寫操作完成并刷新后,STMFinalize將取numSTM-Writeback并進行減操作,以表明該事務不再處于寫回階段.最后,STMFinalize解鎖所有的鎖,并準備其日志條目以供進程的下一個事務重用.
3.2 慢速HTM路徑
與STM路徑一樣,慢速HTM需要在所有待寫入地址上獲取鎖,隨后在日志中記錄所有的寫,這將保證無法對同一地址重復記錄寫.但是慢速HTM和STM有2處不同:1)慢速HTM實際上在記錄到日志之后立刻執行寫操作(不需要等待日志重演).這在HTM中可以實現,因為所有寫操作都保留在處理器的私有緩存中直到事務提交.2)慢速HTM在讀取地址時不會獲取任何鎖,相反,它只是簡單地讀取每個地址的鎖的狀態.如果當前已由寫者鎖定(寫鎖),則事務將中止.讀取鎖狀態意味著HTM事務將訂閱這把鎖.這樣,如果在事務首次檢查其狀態時為未鎖定狀態,但在事務提交前的某個時間點被其他進程鎖定,則事務將中止.
慢速HTM訂閱它所讀取的地址的鎖,并鎖定它寫入的地址,記錄和執行其寫入,因為它鎖定了要寫入的每個地址.當所有的寫入操作完成后,將其日志刷新到NVM并通過xend原子性執行如下操作:提交事務并將其日志標記為已完成,以便恢復進程在發生掉電故障時進行重演.最后,慢速HTM重演其日志條目,將其所有寫入刷新到NVM,然后清除其日志條目.如果一個事務在慢速HTM上失敗了很多次,它將切換到STM路徑.
SlowHTMBegin操作調用xbegin來啟動硬件事務,然后判斷是否以事務模式執行(即xbegin返回OK).如果不是,那么跳轉到先前的慢速HTM事務中止時的代碼行.所以,SlowHTMBegin檢查是否已經到達嘗試次數上限.如果已到達嘗試次數上限,該事務就切換到STM路徑;否則,SlowHTMBegin再次嘗試在硬件中執行.
SlowHTMRead操作讀取待讀取地址的鎖的狀態,若有其他進程作為寫入者獲得鎖中止;否則,SlowHTMRead只是簡單地讀取地址并返回結果.SlowHTMWrite操作嘗試給一個地址加寫鎖,如果失敗則退出.該鎖授予對正在寫入的地址的獨占訪問權,并且獨占許可將該地址存儲在寫日志中.如果SlowHTMWrite獲取該鎖,則它將要寫入的地址和值添加到事務的寫日志條目中.最后執行實際的寫入.
為了在慢速HTM中提交一個事務,進程還需要調用SlowHTMFinalize.這會將寫日志條目刷新到NVM中,接下來還需要調用xend.調用xend將同時提交事務,并設置和刷新日志條目中的記錄位(表示如果發生電源故障,日志條目已準備好由恢復進程重演). 在此之后,SlowHTMFinalize調用ReplayLogEntry重演自己的日志條目,將寫操作刷新到NVM中.ReplayLogEntry也清除并刷新記錄下的比特位,表明該日志條目不再需要重演(與在STMFinalize中調用ReplayLogEntry不同,這個ReplayLogEntry的調用不需要執行事務的寫操作,因為它們已經作為硬件事務的一部分執行了).最后,SlowHTMFinalize解鎖所有的鎖,并準備其日志條目以供進程的下一個事務重用.
3.3 快速HTM路徑
每個事務都以快速HTM開始.快速HTM事務中的寫入和提交與慢速HTM事務中的寫入和提交相同.快速HTM事務的讀取效率更高,因為它們不需要訂閱鎖來保證事務處理看到一致的狀態(即它讀取的地址包含在事務處理過程中某些時刻看到的值),有2個原因:首先,HTM系統保證慢速HTM上的事務不會導致快速HTM上的事務看到不一致的狀態(反之亦然);其次,每個快速HTM事務首先驗證numSTMWriteback是否為零,若非零則中止.正如我們在3.1節看到的那樣,每當一個STM事務開始寫回,numSTMWriteback就會增加,并且每當一個STM事務完成寫回時遞減.因此,如果T在寫回階段與任何STM事務并行運行,它將中止.因此,FastHTMRead被實現為一個簡單的讀取,沒有額外的同步.
最后,我們描述FastHTMBegin.FastHTMBegin首先調用xbegin,然后驗證是否以事務模式執行的.若在事務模式下執行,則FastHTMBegin驗證numSTMWriteback是否為零,若非零則中止,然后返回.若非事務模式,則跳轉到之前的快速HTM事務中止時的代碼行.所以,FastHTMBegin檢查嘗試次數是否已經到了上限.若已到達上限,則快速HTM切換到慢速HTM;否則,FastHTMBegin再次嘗試在快速HTM上執行事務.
3.4 實驗結果分析
在本節中,我們將研究如何使用PHyTM降低各種工作負載下簡單內存數據庫的同步成本.
1) 工作負載
我們實現了一個非常簡單的內存數據庫(very simple IMDB, VSDB),并用它來運行Yahoo!云服務基準測試(Yahoo! cloud serving benchmark, YCSB)的一個子集.本文還使用DBx1000(來自文獻[19]的內存數據庫實現)研究了TPC-C基準.結果及其分析可以在文獻[20]中找到.我們簡單的YCSB基準測試證明了PHyTM的低同步成本,而TPC-C基準測試則以更復雜的事務來說明其性能.
2) 同步方法
我們使用不同的同步方法修改每個內存數據庫.在內存數據庫中,我們增加了對PHyTM和PHTM的支持.在VSDB中,我們實現了一個簡單的2PL方案,按照遭遇順序對高速緩存行進行細粒度的鎖定.由于我們使用的YCSB工作負載不會導致死鎖,所以并未實現2PL的死鎖檢測.DBx1000已經將2PL和樂觀并發控制(OCC)作為同步方法.2PL實現在行上執行細粒度鎖定,并結合死鎖檢測.已證明該2PL和OCC實現是可擴展的,在模擬器中模擬了超過一千個處理器[19].
3) 系統
我們使用帶有4個核心的Intel i7-4770 3.4 GHz處理器,每個處理器有2個超線程.每個核心都有專用的L1和L2緩存,大小分別為32 KB和256 KB.還有一個由所有核心共享的8 MB三級緩存.我們使用由硬件提供的HTM并模擬NVM.實驗中線程是固定的,每個邏輯處理器上運行一個線程.
4) 仿真
我們使用文獻[3]中采用的方法模擬對NVM的支持.原子性分配和對logged位的刷新是通過避免在HTM提交和設置該位之間的任何模擬電源故障來模擬的.由于預計NVM的寫入速度比寫入DRAM要慢,因此我們插入了延遲以模擬寫入NVM的所有同步方法.
5) YCSB
在我們所有的YCSB實驗中,使用了一個有2 000萬條記錄和1個單主鍵列的表.執行4種類型的事務:短距離查詢(short range queries, SRQ)、長距離查詢(long range queries, LRQ)、短距離更新(short range updates, SRU)和長距離更新(long range updates, LRU).短(或長)事務查找表中的16(或256)個隨機的鍵.查(或更新)事務選擇一個列(或寫入列).這些事務只是簡單地讀取或寫入列的內容,而不執行任何額外的計算.例如,查詢事務的SQL代碼可能是“SELECT name FROM customers WHERE id IN(1350,2107,…,571)”.更新事務的SQL代碼可能是“UPDATE customers SET orders=7 WHERE id=1350; UPDATE customers SET orders=4 WHERE id=2107; …”.所有事務都是相互獨立的.也就是說,事務的行為不依賴于前一個事務的結果.請注意,由于長事務訪問相當多的行,有可能導致容量超限而退出.
6) 結果
結果如圖3所示.一般而言,在終止退出較少時PHyTM的行為與PHTM相似.這是因為只要STM路徑上沒有事務處理,2種算法都沒有讀操作的開銷,寫入NVM的開銷將導致寫操作較多的工作負載存在性能差異.在寫操作較多的工作負載中,2PL的性能同樣由寫入NVM的開銷決定.對于基準測試中的所有算法而言,NVM的寫入開銷是相同的,因此它們在只寫測試中表現出相似的性能,如圖3(c)所示.然而,圖3(b)顯示PHTM和PHyTM的讀速度比2PL快一個數量級.
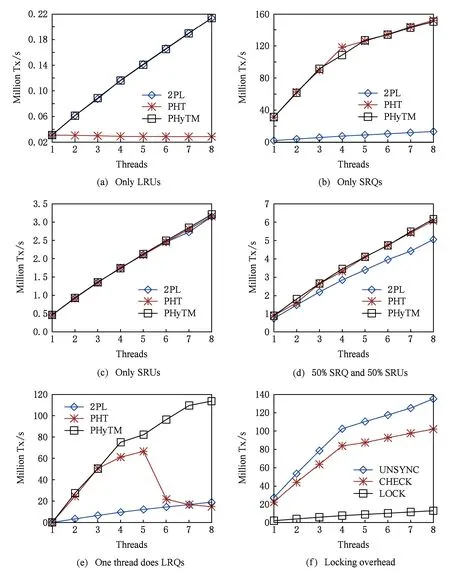
Fig. 3 YCSB workloads for different transaction mixes圖3 YCSB驗證結果
圖3(d)顯示執行50%SRQ和50%SRU的YCSB工作負載.在這種工作負載中,寫入NVM的開銷比任何算法相關的性能差異更顯著,所以2PL的性能與PHTM和PHyTM的性能相當接近.
HTM最大的缺點是事務規模受容量超限中止的限制.PHTM包含有一個STM回滾路徑以允許完成大型事務,但是該STM路徑需要進行全局鎖定,所以STM路徑上的事務被序列化.這是嚴重的性能瓶頸,特別是當HTM支持的系統中并發度越來越高時(支持數百個并發線程).
為了研究部分事務在硬件中執行失敗,接下來必須在軟件路徑中執行時會發生什么,我們增加了一個工作負載,其中包含有不太可能在硬件中提交的大事務.當所有事務都是LRU時,如圖3(a),我們可以看到PHTM根本不可擴展,而PHyTM與2PL一樣可擴展.PHyTM可擴展是因為STM事務可以與其他硬件事務同時運行.PHyTM在落入軟件路徑前樂觀地嘗試硬件事務所帶來的開銷并未使得其性能低于2PL的性能(從不中止退出),即使在這種包含眾多異常中止的工作負載下也是如此.我們認為這是因為PHyTM在提交之前避免了對NVM執行許多昂貴的寫入刷新操作.這樣,中止退出的事務避免了這種開銷.
在完全由LRU組成的工作負載中,PHyTM和2PL實現的吞吐量大致相同,并且比PHTM高一個數量級.在完全由SRQ組成的工作負載中,PHTM和PHyTM則實現了大致相同的吞吐量,并且比2PL高一個數量級.
當少量線程在STM路徑上運行事務,而大多數線程在HTM中成功提交事務時,PHyTM比PHTM和2PL的優勢變得明顯.如圖3(e)所示,其中一個線程正在執行LRQ(不太可能在硬件路徑中成功執行,通常需落入軟件路徑運行),其他線程執行能夠在硬件路徑上成功提交SRQ.在這種情況下,PHyTM比具有8個線程的競爭對手快一個數量級.PHTM的STM路徑執行讀取操作時沒有額外開銷,因此其在處理次數較少時比2PL(其必須獲取到鎖)要快得多.但是,由于PHTM的STM路徑需要獲取到全局鎖,因此無法擴展.2PL雖然可以通過將PHTM與8個并發線程聯系起來而在此類工作負載中擴展,但是受制于獲取鎖的高昂成本.只要沒有STM 事務在其寫回階段,PHyTM事務就可以在快速HTM上運行,這樣它們的讀取操作沒有額外開銷.此外,即使存在處于寫回階段的STM事務,PHyTM事務也可以在慢速HTM上運行,在這種情況下,讀操作可以簡單地讀取鎖的狀態而不需要獲取到鎖.
為了說明PHyTM減少了多少HTM的同步鎖成本,我們用PHyTM的3種不同版本運行了圖3(b)所示的只讀工作負載.在第1個版本(鎖方式)中,讀操作在所有路徑上需要獲取鎖(類似STM路徑);在第2個版本(檢查方式),在所有路徑上的讀操作只需檢查鎖的狀態(就像慢速HTM路徑一樣);在第3個版本(非同步方式),所有路徑上的讀操作都是簡單的不插樁讀(就像快速HTM路徑一樣).這些算法僅適用于只讀工作負載,結果如圖3(f)所示,檢查鎖狀態方式的速度比獲取鎖方式快5倍以上,而且不插樁讀的速度比檢查鎖狀態的方式快大約20%.
4 分離事務執行
4.1 相關工作
PHTM承諾更輕量的同步,但是2個固有的限制使得在數據庫中應用PHTM面臨巨大挑戰.一個限制是PHTM事務處理受到L1緩存大小的限制,對于完整的數據庫事務來說L1緩存大小通常太小.另一個是對沖突的過度反應,即使在低爭用水平下有時也會導致序列化執行.
我們將一個數據庫事務分離為多個滿足PHTM容量限制的較小塊,這樣不太容易發生爭用,隨后將它們重組為單個原子事務,以降低額外開銷.本文僅介紹利用PHTM的數據庫事務提交.
我們所在的華為數據庫實驗室還為并行數據庫的新型光纖解決方案的發展[21]以及實時分析型數據庫的發展作出了貢獻[22].
4.2 STE算法
STE由一組并發工作線程執行.每個工作線程都有一個唯一的ID(tid)和一個單調遞增的本地版本計數器(tv).另外還維護一個全局的最后提交版本數組(lca).數據庫事務由tid和tv唯一標識.
每個線程在lca中有一個槽位,并且在數據庫成功提交時在lca的槽位中寫入tv,即lca[tid]←tv,然后在本地增加tv.一個數據庫行同樣有屬性rid和rv,其值為最后一個事務T寫入的tid和tv.如果T未提交,則該行指向到prev的鏈接,即該行的最后提交版本,包括其rid,rv和數據.如前所述,prev鏈接僅在事務正在寫入行時設置.總的來說,prev鏈接指向數據庫事務T的回退集.
算法1. 驗證以及提交或終止.

我們將數據庫事務分離為訪問行進行讀取或寫入的小型PHTM事務,并使用另一個PHTM事務來執行數據庫事務的驗證和提交.最后一個HTM事務可能會更大,但它是只讀的,直到它最終寫入lca并立即提交.英特爾的HTM正在使用大型布隆過濾器來檢測沖突,同時允許從L1緩存中清除讀取設置的條目,而不中止HTM事務處理.這樣,HTM事務可以容納非常大的讀取集,并且可以支持大型只讀前綴.
4.3 生效和提交
為了驗證讀者看到滿足一致性的結果,即最后提交的值,我們進行了2步驗證.如果讀者記錄的此行所記錄的rv和rid不變,與在行⑤中所驗證的相同,則讀者看到最后提交的值.第2種情況下當前的rv和rid不同于日志中記錄的,但它們代表一個進行中的事務記錄,而日志中記錄的rv和rid是從prev鏈接的,所以記錄的數據仍然是最后提交的版本,在這種情況下讀仍然是有效的.
5 結 論
我們預計未來的系統將使用數千個處理器核心和PB級的NVM. 基于鎖的同步以及傳統的基于日志的持久性將在這些系統中引入不可接受的開銷. PHTM是向ACID事務邁出的第一步,避免鎖定并以面向NVM的方式提供持久性.
最近,數據庫已經開始棄用磁盤,成為完全的內存數據庫.高效持久的混合事務內存將使得內存數據庫能夠從事務內存相關文獻中積累的研究中受益. 另一種方法是基于PHTM定制的同步協議,如STE,利用PHTM加速不受限數據庫事務.
[1]Dushyanth N, Orion H. Whole-system persistence[J]. ACM SIGARCH Computer Architecture News, 2012: 40(1): 401-410
[2]Intel Corporation. Intel architecture instruction set extensions programming reference[EB/OL]. (2017-04-28)[2017-10-08]. https://software.intel.com/sites/default/files/managed/c5/15/architecture-instruction-set-extensions-programming-reference.pdf
[3]Avni H, Levy E, Mendelson A. Hardware transactions in nonvolatile memory[C] //Proc of the 29th Int Symp on DISC 2015. Berlin. Springer, 2015: 617-630
[4]Karnagel T, Dementiev R, Rajwar R, et al. Improving in-memory database index performance with Intel?transactional synchronization extensions[C] //Proc of the 20th IEEE Int Symp on High Performance Computer Architecture. Piscataway, NJ: IEEE, 2014: 476-487
[5]Schwalb D, Faust M, Dreseler M, et al. Leveraging non-volatile memory for instant restarts of in-memory database systems[C] //Proc of the 32nd IEEE Int Conf on Data Engineering (ICDE). Piscataway, NJ: IEEE, 2016: 1386-1389
[6]Herlihy M, Moss J E B. Transactional memory: Architectural support for lock-free data structures[J]. ACM Sigarch Computer Architecture News, 1993, 21(2): 289-300
[7]Bernstein P A, Hadzilacos V, Goodman N. Concurrency Control and Recovery in Database Systems[M]. Boston: Addison-Wesley Longman Publishing Co, Inc, 1987
[8]Torvald Riegel. Tm support in the GNU compiler collection[EB/OL]. (2012-02-06)[ 2017-10-08]. http://gcc.gnu.org/wiki/TransactionalMemory
[9]Riegel T. Software Transactional Memory Building Blocks[D]. Dresden: Technische Universit?t Dresden, 2013
[10]Coburn J, Caulfield A M, Akel A, et al. Nv-heaps: Making persistent objects fast and safe with next-generation, non-volatile memories[C] //Proc of the 16th Int Conf on ASPLOS. New York: ACM, 2011: 105-118
[11]Herlihy M, Luchangco V, Moir M, et al, Software transactional memory for dynamic-sized data structures[C] //Proc of the 22nd Annual Symp on Principles of Distributed Computing. New York: ACM, 1993: 92-101
[12]Felber P, Fetzer C, Riegel T. Dynamic performance tuning of word-based software transactional memory[C] //Proc of the 13th ACM SIGPLAN Sym on Principles and Practice of Parallel Programming. New York: ACM, 2008: 237-246
[13]Volos H, Tack A J, Swift M M. Mnemosyne: Lightweight persistent memory[J].ACM SIGARCH Computer Architecture News, 2011, 39(1): 91-104
[14]Leis V, Kemper A, Neumann T. Exploiting hardware transactional memory in main-memory databases[C] //Proc of the 30th IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE 2014: 580-591
[15]Wang Zhaoguo, Qian Hao, Li Jinyang, et al. Using restricted transactional memory to build a scalable in-memory database[C] //Proc of the 9th European Conf on Computer Systems. New York: ACM, 2014: 26
[16]Dulloor S R, Kumar S, Keshavamurthy A, et al. System software for persistent memory[C] //Proc of the 9th European Conf on Computer Systems. New York: ACM, 2014: 15:1-15:15
[17]DeBrabant J, Arulraj J, Pavlo A, et al. A prolegomenon on OLTP database systems for non-volatile memory[EB/OL]. (2017-09-01)[2017-10-08]. http://www.adms-conf.org/adms_2014.html
[18]Guerraoui R, Kapalka M. On the correctness of transactional memory[C] //Proc of the 13th ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2008: 175-184
[19]Yu X, Bezerra G, Pavlo A, et al. Staring into the abyss: An evaluation of concurrency control with one thousand cores[J]. Proceedings of the VLDB Endowment, 2014, 8(3): 209-220
[20]Brown T, Avni H. Phytm: Persistent hybrid transactional memory[J]. Proceedings of the VLDB Endowment, 2016, 10(4): 409-420
[21]Gasiunas V, Dominguez-Sal D, Acker R, et al. Fiber-based architecture for NFV cloud databases[J]. Proceedings of the VLDB Endowment, 2017, 10(12): 1682-1693
[22]Braun L, Etter T, Gasparis G, et al. Analytics in motion: High performance event-processing AND real-time analytics in the same database[C] //Proc of the 2015 ACM SIGMOD Int Conf. on Management of Data. New York: ACM: 251-264
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
