邊緣計算:平臺、應用與挑戰
2018-03-13 07:23:35趙梓銘蔡志平
計算機研究與發展 2018年2期
趙梓銘 劉 芳 蔡志平 肖 儂
(國防科技大學計算機學院 長沙 410073)(zhaoziming93@aliyun.com)
近年來,大數據、云計算、智能技術的快速發展,給互聯網產業帶來了深刻的變革,也對計算模式提出了新的要求.
大數據時代下每天產生的數據量急增,而物聯網等應用背景下的數據在地理上分散,并且對響應時間和安全性提出了更高的要求.云計算雖然為大數據處理提供了高效的計算平臺,但是目前網絡帶寬的增長速度遠遠趕不上數據的增長速度,網絡帶寬成本的下降速度要比CPU、內存這些硬件資源成本的下降速度慢很多[1],同時復雜的網絡環境讓網絡延遲很難有突破性提升.因此傳統云計算模式需要解決帶寬和延遲這兩大瓶頸[2].
在這種應用背景下,邊緣計算(edge computing)應運而生,并在近兩年得到了研究者的廣泛關注.邊緣計算中的邊緣(edge)指的是網絡邊緣上的計算和存儲資源,這里的網絡邊緣與數據中心相對,無論是從地理距離還是網絡距離上來看都更貼近用戶.邊緣計算則是利用這些資源在網絡邊緣為用戶提供服務的技術,使應用可以在數據源附近處理數據.如果從仿生的角度來理解邊緣計算,我們可以做這樣的類比:云計算相當于人的大腦,邊緣計算相當于人的神經末端.當針刺到手時總是下意識的收手,然后大腦才會意識到針刺到了手,因為將手收回的過程是由神經末端直接處理的非條件反射.這種非條件反射加快人的反應速度,避免受到更大的傷害,同時讓大腦專注于處理高級智慧.未來是萬物聯網的時代,思科預計2020年將有500億的設備接入互聯網[3],我們不可能讓云計算成為每個設備的“大腦”,而邊緣計算就是讓設備擁有自己的“大腦”.
相比于云計算,邊緣計算可以更好地支持移動計算與物聯網應用,具有以下明顯的優點:
1) 極大緩解網絡帶寬與數據中心壓力.思科在2015—2020年全球云指數[4]中指出,隨著物聯網的發展,2020年全球的設備將會產生600 ZB的數據,但其中只有10%是關鍵數據,其余90%都是臨時數據無需長期存儲.邊緣計算可以充分利用這個特點,在網絡邊緣處理大量臨時數據,從而減輕網絡帶寬與數據中心的壓力.
2) 增強服務的響應能力.移動設備在計算、存儲和電量等資源上的匱乏是其固有的缺陷,云計算可以為移動設備提供服務來彌補這些缺陷,但是網絡傳輸速度受限于通信技術的發展,復雜網絡環境中更存在鏈接和路由不穩定等問題,這些因素造成的延遲過高、抖動過強、數據傳輸速度過慢等問題嚴重影響了云服務的響應能力[5].而邊緣計算在用戶附近提供服務,近距離服務保證了較低的網絡延遲,簡單的路由也減少了網絡的抖動,千兆無線技術的普及為網絡傳輸速度提供了保證,這些都使邊緣服務比云服務有更強的響應能力[6].
3) 保護隱私數據,提升數據安全性.物聯網應用中數據的安全性一直是關鍵問題,調查顯示約有78%的用戶擔心他們的物聯網數據在未授權的情況下被第三方使用[7].云計算模式下所有的數據與應用都在數據中心,用戶很難對數據的訪問與使用進行細粒度的控制.而邊緣計算則為關鍵性隱私數據的存儲與使用提供了基礎設施,將隱私數據的操作限制在防火墻內,提升數據的安全性.
邊緣計算因為其突出的優點,滿足未來萬物聯網的需求,從2016年開始迅速升溫,引起國內外的密切關注.ACM和IEEE從2016年開始聯合舉辦邊緣計算的頂級會議SEC(IEEEACM Symposium on Edge Computing),一些重要國際會議也都開始舉辦邊緣計算的Workshop,例如2017年的ICDCS(IEEE International Conference on Distributed Computing Systems),MiddleWare等.
本文總結了邊緣計算的相關概念,對比分析了邊緣計算的相關平臺,介紹了相關應用,并綜述了邊緣計算的發展趨勢和面臨挑戰.
1 邊緣計算概念
1.1 邊緣計算定義
邊緣計算目前還沒有一個嚴格的統一的定義,不同研究者從各自的視角來描述和理解邊緣計算.美國卡內基梅隴大學的Satyanarayanan教授[8]把邊緣計算描述為:“邊緣計算是一種新的計算模式,這種模式將計算與存儲資源(例如:Cloudlet、微型數據中心或霧節點等)部署在更貼近移動設備或傳感器的網絡邊緣.”美國韋恩州立大學的施巍松等人[9-10]把邊緣計算定義為:“邊緣計算是指在網絡邊緣執行計算的一種新型計算模式,邊緣計算中邊緣的下行數據表示云服務,上行數據表示萬物互聯服務,而邊緣計算的邊緣是指從數據源到云計算中心路徑之間的任意計算和網絡資源.”
這些定義都強調邊緣計算是一種新型計算模式,它的核心理念是“計算應該更靠近數據的源頭,可以更貼近用戶”.這里“貼近”一詞包含多種含義.首先可以表示網絡距離近,這樣由于網絡規模的縮小帶寬、延遲、抖動這些不穩定的因素都易于控制與改進.還可以表示為空間距離近,這意味著邊緣計算資源與用戶處在同一個情景之中(如位置),根據這些情景信息可以為用戶提供個性化的服務(如基于位置信息的服務).空間距離與網絡距離有時可能并沒有關聯,但應用可以根據自己的需要來選擇合適的計算節點.
網絡邊緣的資源主要包括移動手機、個人電腦等用戶終端,WiFi接入點、蜂窩網絡基站與路由器等基礎設施,攝像頭、機頂盒等嵌入式設備,Cloudlet,Micro Data Center等小型計算中心等.這些資源數量眾多,相互獨立,分散在用戶周圍,我們稱之為邊緣節點.邊緣計算就是要把這些獨立分散的資源統一,為用戶提供服務.
綜上所述,我們把邊緣計算定義為:“邊緣計算是一種新的計算模式,將地理距離或網絡距離上與用戶臨近的資源統一起來,為應用提供計算、存儲和網絡服務.”
1.2 邊緣計算、云計算、霧計算
邊緣計算是一種新型的計算模式,從邊緣計算的定義可以看出,邊緣計算并不是為了取代云計算,而是對云計算的補充,為移動計算、物聯網等提供更好的計算平臺.邊緣計算可以在保證低延遲的情況下為用戶提供豐富的服務,克服移動設備資源受限的缺陷;同時也減少了需要傳輸到云端的數據量,緩解了網絡帶寬與數據中心的壓力.目前,移動應用越來越復雜,接入互聯網的設備越來越多,邊緣計算的出現可以很好地應對這些趨勢.但并不是所有服務都適合部署在網絡邊緣,很多需要全局數據支持的服務依然離不開云計算.例如電子商務應用,用戶對自己購物車的操作都可以在邊緣節點上進行,以達到最快的響應時間,而商品推薦等服務則更適合在云中進行,因為它需要全局數據的支持.邊緣計算的架構是“端設備—邊緣—云”3層模型,3層都可以為應用提供資源與服務,應用可以選擇最優的配置方案.
霧計算[11](fog computing)是另一個與邊緣計算相關的概念,它由思科公司在2012年提出,以應對即將到來的萬物聯網時代.同邊緣計算一樣,霧計算也是將數據、數據相關的處理和應用程序都集中于網絡邊緣的設備,而不是全部保存在云端.霧計算的名字也源自于此——霧比云更貼近地面.與邊緣計算不同的是,霧計算更強調在數據中心與數據源之間構成連續統一體(cloud-to-things continuum)來為用戶提供計算、存儲與網絡服務,使網絡成為數據處理的“流水線”,而不僅僅是“數據管道”.也就是說,邊緣和核心網絡的組件都是霧計算的基礎設施.而邊緣計算更強調用戶與計算之間的“距離”.目前,思科對霧計算的實現是它推出的IOx系統[12].IOx運行在路由器、交換機這些網絡設備上,可以使開發人員輕松的在這些設備上開發應用,部署服務.
雖然霧計算與邊緣計算不盡相同,但他們都體現出了萬物聯網時代對計算模式的要求,實時的服務響應、穩定的服務質量已經漸漸成為用戶關注的焦點.從這一點上來看,兩者是對同一目標的兩種不同的實現方法.邊緣計算、霧計算與云計算的對比如表1所示:

Table 1 Comparison of Cloud Computing and Edge Computing表1 邊緣計算、霧計算與云計算比較
2 邊緣計算平臺
邊緣計算利用數據傳輸路徑上的計算、存儲與網絡資源為用戶提供服務,這些資源數量眾多且在空間上分散,邊緣計算平臺將對這些資源進行統一的控制與管理,使開發者可以快速地開發與部署應用,成為邊緣計算的基礎設施.目前關于邊緣計算平臺的研究有很多,ParaDrop,Cloudlet,PCloud是其中比較有代表性的3個項目,其中從Cloudlet還演化出了Open Edge Computing聯盟[13].
2.1 ParaDrop
ParaDrop[14-15]是威斯康星大學麥迪遜分校WiNGS實驗室的研究項目,無線網關可以在ParaDrop的支持下擴展為邊緣計算平臺,可以像普通服務器一樣運行應用.ParaDrop適用于物聯網應用,例如智能電網(smart grid)、車聯網(connected vehicles)、無線傳感執行網絡(wirless sensor and actuator network)等,可以作為物聯網的智能網關平臺.在物聯網應用中,傳感器數據都會匯集到物聯網網關中,再傳輸到云中進行分析.而ParaDrop則在物聯網網關中植入單片機使其具備通用計算能力,并通過軟件技術使得部署在云端的應用與服務都可以遷移到網關,開發者可以動態定制網關上運行的應用.
ParaDrop的整體結構如圖1所示.ParaDrop使用容器技術來隔離不同應用的運行環境,因此1個網關上可以運行多個租戶的應用.網關上所有應用的安裝、運行與撤銷都由云端的后臺服務控制,并對外提供1組API,開發者通過API來控制資源的利用及監控資源的狀態,而用戶通過Web頁面與應用進行交互.ParaDrop將Web的服務與數據分離,Web服務由云端的后臺服務提供,而傳感器采集的原始數據則都存儲在網關上,用戶可以對云端訪問的數據進行控制,保護了用戶的數據隱私.
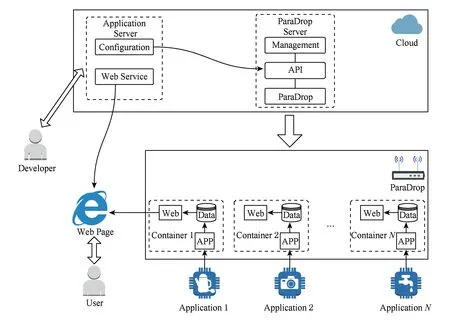
Fig. 1 The full ParaDrop platform圖1 ParaDrop平臺結構圖
ParaDrop的優勢主要有:1)敏感數據可以在本地處理,不必上傳云端,保護了用戶隱私;2)WiFi接入點距離數據源只有一跳,具有低且穩定網絡延遲,在WiFi接入點上運行的任務有更短的響應時間;3)減少傳輸到互聯網上的數據量,只有被用戶請求的數據才會通過互聯網傳輸到用戶設備;4)網關可以通過無線電信號獲取一些位置信息,如設備之間的距離、設備的具體位置等,利用這些信息可以提供位置感知的服務;5)遇到特殊情況,無法連接互聯網時,應用的部分服務依然可以使用.目前,ParaDrop得到了很好的發展,軟件系統已經全部開源,支持ParaDrop的硬件設備也已經準備對外銷售.
2.2 Cloudlet
2009年卡內基梅隴大學提出Cloudlet[16]的概念,Cloudlet是一個可信且資源豐富的主機或機群,它部署在網絡邊緣與互聯網連接并可以被周圍的移動設備所訪問,為設備提供服務.Cloudlet將原先移動計算的2層架構“移動設備—云”變為3層架構“移動設備—Cloudlet—云”. Cloudlet也可以像云一樣為用戶提供服務,所以它又被稱為“小云”(data center in a box). 雖然Cloudlet項目不是以邊緣計算的名義提出并運行,但它架構和理念契合邊緣計算的理念和思想,可以被用來構建邊緣計算平臺.
Cloudlet主要用來支持移動計算中的游牧服務[17](cyber foraging),游牧服務是解決移動設備計算資源不足的重要手段,通過游牧服務移動設備可以將繁重的計算任務卸載到其他資源上.云計算一直是充當這類資源的最佳角色,而Cloudlet的出現為用戶提供了新的選擇. Cloudlet的軟件棧分為3層:第1層由操作系統和Cache組成,其中Cache主要是對云中的數據進行緩存;第2層是虛擬化層,將資源虛擬化,并通過統一的平臺OpenStack++[18]對資源進行管理;第3層是虛擬機實例,移動設備卸載的應用都在虛擬機中運行,這樣可以彌補移動設備與Cloudlet應用運行環境(操作系統、函數庫等)的差異.
與云不同,Cloudlet部署在網絡邊緣,只服務附近的用戶,但Cloudlet也支持應用的移動性,設備可以隨著移動切換到最近的Cloudlet.如圖2所示,Cloudlet對應用移動性的支持主要依賴3個關鍵步驟:
1) Cloudlet資源發現(cloudlet discovery).移動中的移動設備可以快速發現周圍可用的Cloudlet,并選擇最合適的作為卸載任務的載體.
2) 虛擬機配給(VM provisioning)[19].在選定的Cloudlet上啟動運行應用的虛擬機,并配置運行環境.
3) 資源切換(VM handoff)[20].將運行應用的虛擬機遷移到另一個Cloudlet上.
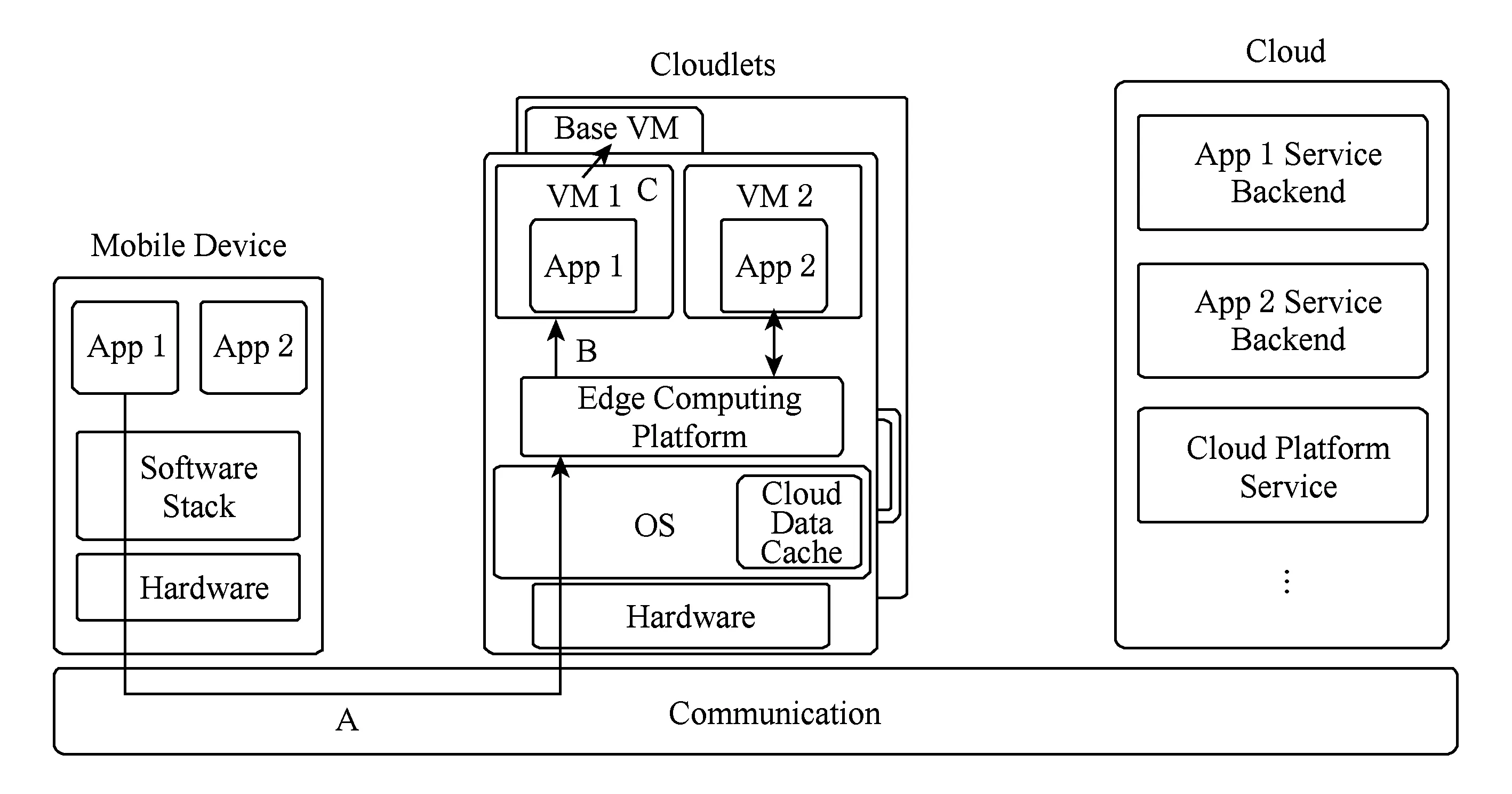
A: Cloudlet discovery; B: VM provisioning; C: VM handoffFig. 2 Cloudlet component overview and functions that support application mobility圖2 Cloudlet組件總覽及應用移動性機制
動態虛擬機合成(dynamic VM synthesis)[16]是Cloudlet支持移動性的關鍵技術,可以將虛擬機鏡像拆分為基底(base)與覆蓋層(overlay),基底與覆蓋層可以重新組合為新的虛擬機鏡像.基底包含虛擬機的操作系統、函數庫等基礎軟件,這一部分在虛擬機鏡像之間都是重復的,且占用空間大;而覆蓋層是一個很小的二進制增量文件,只包含用戶在原始虛擬機上的一些定制信息,占用空間小.在虛擬機配置和資源切換時,使用動態虛擬機合成技術可以只傳輸輕量的覆蓋層,減少了數據傳輸量,加快了虛擬機配置和資源切換的速度,保證了應用在Cloudlet中能得到及時的資源供給.
Cloudlet的主要優勢有:對應用開發者沒有任何約束,現有程序基本不需要修改就能在Cloudlet中運行;加快了很多復雜移動應用的響應速度.隨著研究不斷完善,Cloudlet在認知輔助系統(cognitive assistance system)[21]、眾包(crowdsourcing)[22]、敵對環境(hostile environments)[23]等方面都有很好的應用.為了推動Cloudlet的發展,CMU聯合Intel,Huawei等公司建立了Open Edge Computing聯盟,為基于Cloudlet的邊緣計算平臺制定標準化API.目前,該聯盟正在將OpenStack擴展到邊緣計算平臺,使分散的Cloudlet可以通過標準的OpenStack API進行控制和管理.
2.3 PCloud
PCloud[24]是佐治亞理工學院Korvo研究組在邊緣計算領域的研究成果.PCloud可以將我們周圍的計算、存儲、輸入輸出設備與云計算資源整合,使這些資源可以無縫的為移動設備提供支持.
PCloud的結構圖如圖3所示.在PCloud中,本地、邊緣以及云上的資源通過網絡連接,并由特殊的虛擬化層STRATUS[25]將資源虛擬化,構成資源池;系統運行時從資源池中挑選與組合需要的資源.PCloud將資源池化后,由運行時機制負責資源的申請與分配;該機制提供資源描述接口,可以根據應用的要求選擇合適的資源并進行組合.資源組合后,PCloud就相當于產生了1個新的實例,該實例可以為外界應用提供服務;雖然該實例的計算資源可能來自多個物理設備,但對于外界應用來說卻相當于一體的計算設備.
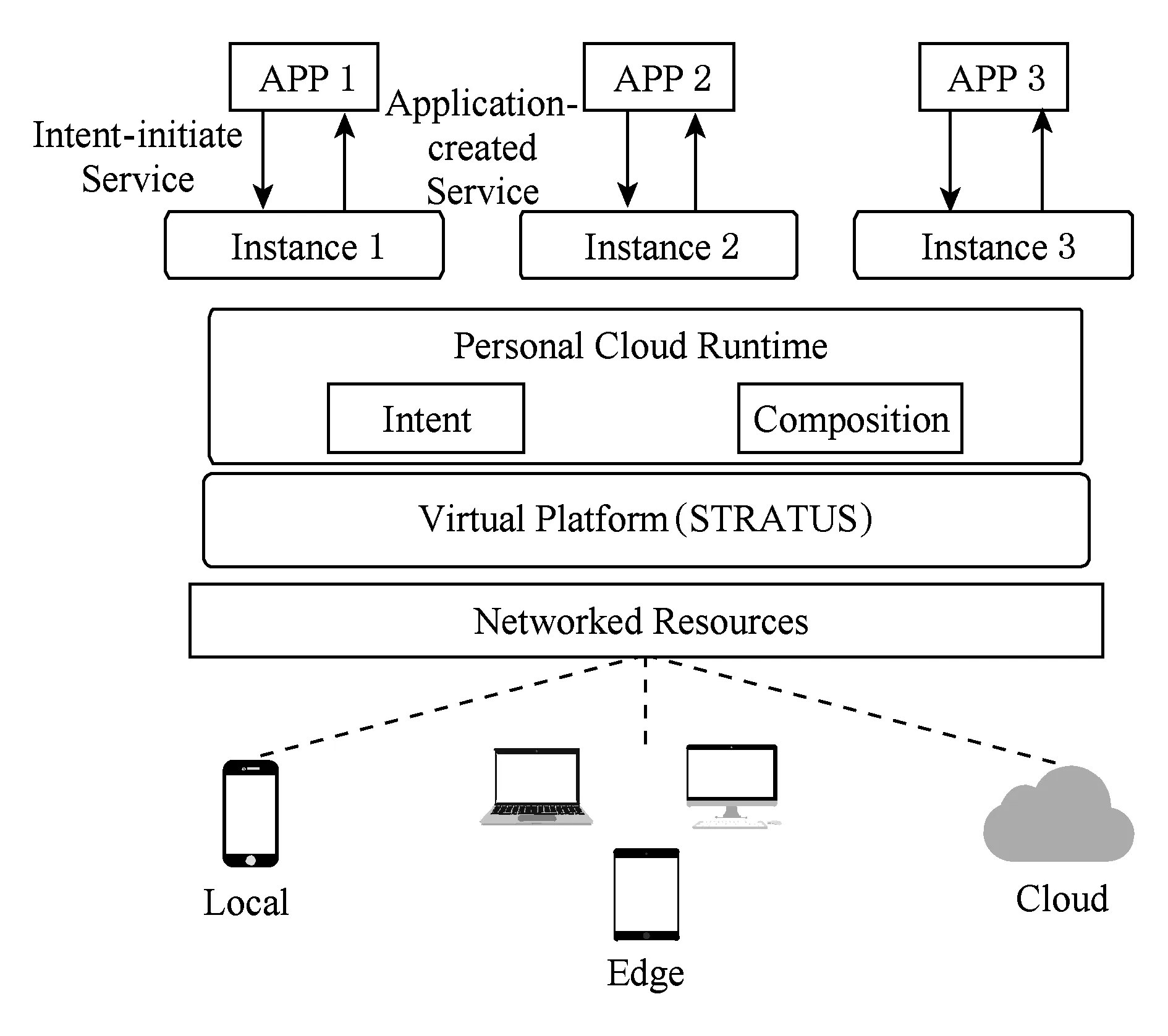
Fig. 3 PCloud architecture圖3 PCloud結構圖
實際運行過程中,移動應用通過接口向PCloud描述需要的資源,PCloud會根據該描述與當前可用資源給出最優資源配置,生成實例為應用提供相應的服務.資源評價指標主要包括計算能力和網絡延遲等因素,如果是輸入輸出設備可能還包括屏幕大小、分辨率等因素.
PCloud將邊緣資源與云資源有機的結合,使2者相輔相成,優勢互補.云計算豐富的資源彌補了邊緣設備計算、存儲能力上的不足,而邊緣設備因為貼近用戶可以提供云計算無法提供的低延遲服務.同時也增強了整個系統的可用性,無論是網絡故障還是設備故障都可以選擇備用資源.基于PCloud平臺,Korvo研究組構建了很多應用(例如:SOUL[26])獲得了廣泛的關注.
2.4 小 結
從應用領域、服務移動性、服務狀態、虛擬化技術這4個方面對邊緣計算平臺進行比較,并總結為表2.
1) 應用領域.雖然這3個平臺都可以在網絡邊緣為用戶提供服務,但是他們在設計時所針對的應用領域存在差異.Cloudlet,PCloud針對延遲敏感的移動應用,而ParaDrop則針對物聯網應用.
2) 服務的移動性.應用領域的不同導致這2個平臺對服務移動性的支持不同.Cloudlet是為移動應用的后臺服務提供臨時的部署點,為了保證低且穩定的網絡延遲,設備的移動會使后臺服務也要移動到就近的Cloudlet;就近服務的特性使Cloudlet對移動性的支持特別困難,需要資源發現、虛擬機配置、資源切換這3步相結合,同時還要保證實時性.而在物聯網應用中,大多數應用的流程是傳感器采集原始數據匯集到無線網關進行初步處理,處理結果上傳到云端進行進一步的分析;傳感器與無線網關的連接關系一般保持不變,因此ParaDrop不考慮服務移動性問題.PCloud主要是將用戶周圍的設備與云結合,當用戶移動時,周圍的設備也可能發生動態變化;PCloud允許邊緣設備的動態加入和退出,但設備退出時不能有正在運行的任務,對移動性的支持并不完善.
3) 服務狀態.移動應用雖然能將后臺服務部署在Cloudlet上,但這種部署只有短暫的一段時間,Cloudlet不會長久保存服務的狀態信息,重要的信息都要傳輸到云端保存,一旦應用離開Cloudlet的服務范圍,這些數據會被清除.而ParaDrop則直接存儲傳感器的原始數據,Web服務需要的數據都需要從本地獲取.在PCloud中,邊緣設備與云都被看作是統一的計算資源,都會保存和維護應用的相關數據.
4) 虛擬化技術.虛擬化技術方便了資源的管理,是邊緣計算平臺的必然選擇.Cloudlet,PCloud使用虛擬機來虛擬化資源,而ParaDrop則使用容器.主要的原因是移動應用后臺服務的執行環境多種多樣,無論是基于Windows或是Linux系統的后臺服務都應該可以快速遷移到同一個Cloudlet上.虛擬機是對物理機器的虛擬化,可以很好地應對執行環境的變化;容器則依賴特定的操作系統.而物聯網應用的后臺服務一般不需要靈活的執行環境,邊緣計算平臺的執行環境與云端保持一致,因此使用容器就可以滿足需求,同并且還具備占用資源少、啟動快等優點.PCloud使用虛擬機的原因是基于超管理器(hypervisor)的虛擬機技術可以在CPU、硬盤等更細粒度的層次上進行虛擬化,便于資源的拆分利用.
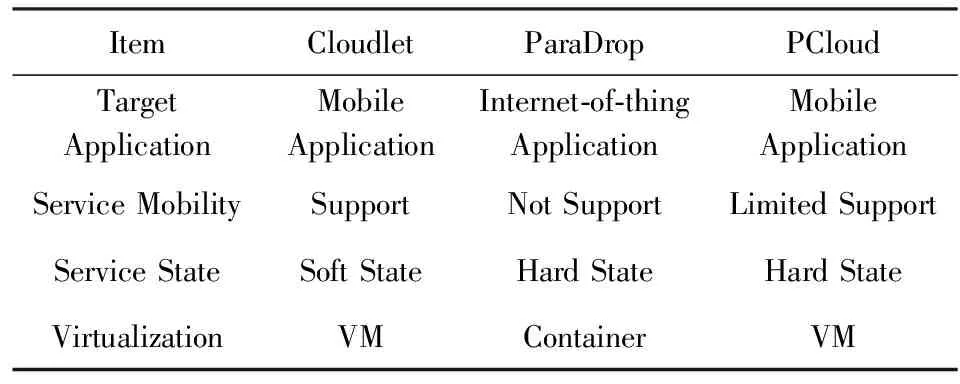
Table 2 Comparison of Cloudlet, ParaDrop and PCloud表2 Cloudlet,ParaDrop與PCloud比較
3 應用案例
邊緣計算在數據源附近提供服務,使其可以在很多移動應用和物聯網應用上發揮出巨大優勢.本節將列舉一些典型的應用案例,結合這些案例可以幫助我們理解邊緣計算的優勢.
3.1 增強現實
增強現實技術將現實世界的場景與虛擬信息高度集成,生成被人類感官所感知的信息,來達到超越現實的感官體驗.增強現實技術可以使用在智能手機、平板電腦與智能眼鏡等移動設備上,來支持新的應用與服務,如虛擬游戲、3D觀影等.增強現實技術需要對視頻、圖像數據進行處理,這些任務復雜性高,而需要與用戶進行互動的特點又對實時性有了很高的要求.
CMU與Intel實驗室在2014年開發了一個基于增強現實技術的認知輔助系統(cognitive assistance system)[21],通過谷歌眼鏡來增強某些病人的認知能力.實現系統需要解決的關鍵問題是如何將處理任務的延遲控制在幾十毫秒,讓感知缺陷的病人也擁有正常人一樣的反應速度.考慮到重量、大小、續航等因素,可穿戴設備的計算能力很差,處理任務的時間是一般服務器的數倍,直接使用設備內部的資源進行計算是不可行的.將應用部署到云中可以加快任務的處理速度,但端設備到云端的網絡延遲很高且極不穩定,很可能成為整個系統的瓶頸.為了解決這個問題,系統使用了邊緣計算技術,將延遲敏感的計算任務卸載到附近的Cloudlet來降低任務的處理延遲.同時為了保證系統在無法連接網絡時依然可以使用,系統也支持通過藍牙等通信方式將任務卸載到附近的個人設備(如隨身攜帶的筆記本、平板電腦等).
網絡的延遲與設備性能、能耗的瓶頸是很多移動應用都會遇到的問題,而邊緣計算可以幫助移動應用突破這些瓶頸,讓應用具有更快的響應速度,使用更復雜的算法.
3.2 圖像識別
美國里海大學與IBM提出了一個基于深度學習的自適應物體識別框架DeepCham[27],該框架適用于移動設備上的物體識別應用,可以大幅提高物體識別的準確率.DeepCham將邊緣計算節點作為master來控制附近的移動設備訓練深度模型;采用眾包的思想,深度模型訓練所使用的數據集與數據的標記都是由周圍的移動設備提供.這種方式使其可以獲取大量有標記的數據集,進行有監督學習.
在一個特定視域(圖像的光線、背景、視角等)內采集圖像用來訓練深度模型,得到的深度模型對該視域內對象的識別準確率更高.DeepCham充分利用這一點,在同一個邊緣計算節點周圍采集圖片來訓練模型,并通過圖片的元數據信息(位置、天氣和時間等)來區分不同的視域.這使模型很好地適應周圍的視域,從而使DeepCham可以自適應視域的轉換.
適用于特定功能的識別模型要比通用識別模型更好訓練,也有更高的準確性.邊緣計算模式可以在一定程度上減小對模型適用范圍的要求,也為深度學習收集大量特定的學習數據,訓練更加個性化的識別模型.
3.3 網站性能優化
網站性能優化(Web performance optimization)是用來提高用戶瀏覽器的網站加載和顯示速度的技術.隨著用戶體驗的重要性不斷增強和用戶對速度的需求日益增長,網站性能優化行業得到快速發展,很多互聯網公司都對外提供網站性能優化的服務與工具,如雅虎的YSlow與谷歌的PageSpeed Tools.在用戶請求網頁的過程中,80%~90%的響應時間都發生在前端(下載組件、頁面的渲染與執行等),在網絡邊緣上的優化才是提高網站性能的關鍵.傳統的網站優化方案是在Web服務器上利用固定規則優化網站頁面,再通過內容分發網絡加速傳輸.這種方法沒有充分利用邊緣網絡資源,優化方法對所有用戶都是一樣的,沒有考慮到用戶的網絡狀態情況;內容分發網絡雖然是在邊緣網絡上的優化技術,但是它只能加快組件的下載速度,頁面渲染、執行的速度依然取決于設備的計算能力.
為了充分利用邊緣網絡資源,日本電報電話公司(NTT)設計了一種基于邊緣計算的網站加速平臺EAWP(edge accelerated Web platform)[28],為Web應用開發者提供情景感知的網站優化服務與工具.這個方案中,邊緣服務器與WIFI接入點、蜂窩網基站等通信設施結合,可以獲取用戶接入網的狀態信息來對網站進行優化.比如,當發現用戶所在的邊緣網絡出現擁塞時,邊緣服務器可以降低頁面質量(如使用低分辨率圖片)來優化訪問的響應時間.同時,為了彌補移動設備計算能力的不足,平臺支持將頁面內容的執行、渲染等復雜的工作卸載到邊緣服務器中執行.EAWP為其他支持HTML標準的Web引擎提供等效的運行環境,現有的應用程序可以不需要更改直接在平臺上運行.
3.4 智慧城市
智慧城市是一種現代化城市模型,運用信息技術與物聯網技術對城市資源做出智能化的管理.智慧城市在近幾年得到了快速發展,IBM,Intel,Google等公司都開始將他們的產品與服務整合到智慧城市的框架中.智慧城市系統要隨時感測、分析、整合城市的各項關鍵信息,會產生大量的原始數據,一座100萬人的城市,平均每天會產生200 PB的數據[4].同時,這些數據在地理上廣泛分布,且大部分數據存儲在本地,這為數據的查找與分析帶來了極大的困難.如果沒有一種高效的解決方案,很容易使城域網被大量的數據堵塞.
Tang等人[29]提出了一種以智慧城市為背景的大數據分析框架,對處理在地理上廣泛分布的數據有很好的效果.數據分析框架分為4層:1)第1層是傳感器網絡,由分散在城市中的傳感器構成,晝夜不停的生成大量原始數據;2)第2層由邊緣節點組成,每個邊緣節點都要控制本地的1組傳感器,邊緣節點可以根據預先設定的模式分析和處理傳感器數據,還可以控制執行器處理任務;3)第3層由中間計算節點組成,每個中間節點要控制一組邊緣節點,將邊緣節點上傳的信息與時空信息相結合來識別一些潛在的突發事件,當突發事件發生時,中間節點還要控制下層設備做出應急反應;4)第4層是云計算中心,對全市的狀態進行監控并進行中心控制,在這一層進行長期的、全市范圍的行為分析.
這個分析框架使用了邊緣計算技術,第2~3層構成了邊緣計算平臺.邊緣計算平臺充分利用了數據傳輸路徑上的計算設備,將眾多互不相關的輕量級任務分配到各個節點,使得任務可以并行執行;同時,原始數據在這兩層加工后已被精煉化,在核心網絡上傳輸的數據量大大減小.邊緣計算技術保證了分析框架的高效運行,減少了需要上傳到云中的數據量,是整個框架高效運行的關鍵.
3.5 車聯網
車聯網將汽車接入開放的網絡,車輛可以將自己的狀態信息(如油耗、里程等)通過網絡傳到云端進行分析,車輛間也可以自由交換天氣、路況、行人等信息,并進行實時的互動.
韋恩州立大學在GENI Racks上構建了一個邊緣計算平臺[30],并在上面部署了實時3D校園地圖、車量狀態檢測、車聯網仿真3個應用.3D校園地圖通過將校園內監控錄像與行駛車輛的錄像數據融合,通過處理后可以增強為實時3D地圖,校園安保人員可以無縫地監控校園狀態;車量狀態檢測可以實時記錄車輛的引擎轉速、里程、油耗等狀態,并對數據進行分析,從而檢測車輛的性能,發現車輛的故障;車聯網仿真將眾多的車輛狀態信息匯總,利用這些真實的交通信息可以進行車聯網應用的仿真實驗.
這些應用都會產生大量的傳感器數據,很多數據都需要進行實時處理,而邊緣計算可以在數據源附近對數據進行處理,減少了不必要的網絡傳輸,并提高了應用的響應速度.
4 邊緣計算面臨的挑戰
目前,關于邊緣計算的研究才剛剛起步,雖然已經取得了一定成果,但從實際應用來說,還存在很多問題需要研究,下面對其中的幾個主要問題進行分析.
4.1 多主體的資源管理
邊緣計算資源分散在數據的傳輸路徑上,被不同的主體所管理和控制,比如用戶控制終端設備、網絡運營商控制通信基站、網絡基礎設施提供商控制路由器、應用服務供應商控制邊緣服務器與內容傳輸網絡.云計算中的資源都是集中式的管理,因此云計算的資源管理方式并不適用管理邊緣計算分散的資源,而目前關于邊緣計算的研究[31-32]也主要集中在對單一主體資源的管理和控制,還未涉及多主體資源的管理.一種比較直觀的解決方式是各個主體對資源自我管理,然后通過中間服務(broker service)[33]來進行資源供給.但這種方式只能提供基本的功能,如果要滿足使用者的特殊需求(如自動供給),中介層則需要自己實現部分IaaS(infrastructure as a service)平臺功能.這需要依賴各個主體提供的API,只要有1個主體提供的API不夠靈活,就很難實現,因此實現靈活的多主體資源管理是一個十分富有挑戰性的問題.
4.2 應用的移動管理
邊緣計算依靠資源在地理上廣泛分布的特點來支持應用的移動性,一個邊緣計算節點只服務周圍的用戶.應用的移動就會造成服務節點的切換.而云計算對應用移動性的支持則是“服務器位置固定,數據通過網絡傳輸到服務器”, 所以在邊緣計算中應用的移動管理也是一種新模式,主要涉及以下2個問題:
1) 資源發現.應用在移動的過程中需要快速發現周圍可以利用的資源,并選擇最合適的資源.當前雖然也有很多成熟的資源發現技術,在云監控(cloud monitor)[34-35]與云中介(service brokerage)[36]中被廣泛運用,但邊緣計算的資源發現需要適應異構的資源環境,還需要保證資源發現的速度,才能使應用不間斷地為用戶提供服務.
2) 資源切換.用戶移動時,移動應用使用的計算資源可能會在多個設備間切換,而資源切換要將服務程序的運行現場遷移.熱遷移技術可以解決這個問題,但是傳統熱遷移技術的目標是最小化停機時間,而資源切換需要最小化總遷移時間,因為在遷移的過程中用戶要忍受升高的延遲.另外,傳統的虛擬機遷移是在數據中心的內部進行,設備的計算能力與網絡帶寬比較固定,而邊緣計算資源的異構性與網絡的多樣性,需要遷移過程自適應設備計算能力與網絡帶寬的變化.所以,邊緣計算需要一套自適應的快速熱遷移方案,來滿足移動應用資源切換的需求.
4.3 虛擬化技術
為了方便資源的有效管理,邊緣計算需要虛擬化技術的支持,為系統選擇合適的虛擬化技術是邊緣計算的一個研究熱點.邊緣計算對虛擬化技術的要求體現在如下3個方面:1)邊緣計算資源是一種基礎設施,要盡可能地保持通用性,所以虛擬化技術應該實現最小化對應用程序運行時環境的約束,不應強制應用使用特定的操作系統、函數庫等;2)邊緣計算資源的能力有限,不能像計算中心一樣為應用提供充足的資源,虛擬化技術應最大化資源利用率,使有限的資源在同一時間內滿足更多的請求;3)有些邊緣計算資源在處理用戶任務的同時還要對外提供其他服務,虛擬化技術應將不同的任務徹底隔離,一個應用的崩潰、內存溢出、高CPU占用不會對其他的任務造成影響.例如在移動邊緣計算[37]中,基站能夠處理用戶的任務,但是這些任務不能影響基站最基本的無線接入功能.這3個方面可能會出現沖突,系統要根據自己的需求在這之間做出權衡.目前,新型的虛擬化技術層出不窮,其中有很多打破了虛擬機和容器的規則與界線,將兩者充分融合,同時具備兩者的優勢,如LXD,Hyper,Rancher OS等.所以,不拘泥于虛擬化技術現有的規則與界線,設計適應邊緣計算特點的虛擬化技術也是一大挑戰.
4.4 數據分析
數據分析的數據量越大,往往提取出的價值信息就越多.但是收集數據需要時間,價值信息往往也具有時效性,沒有人會關注昨天的天氣預報.邊緣計算使數據可以在匯集的過程中被處理與分析,很多數據如果被過早地分析,可能會丟失很多有價值的信息,所以如何權衡提取信息的價值量與時效性是一個關鍵性問題.
邊緣計算利用的計算節點數量眾多,但節點的計算資源有限,很多都是單片機或片上系統,例如Intel小型蜂窩基站上配備T3K片上系統擁有4核ARM處理器和2 GB的內存[38];而目前流行的Hadoop,Spark等數據分析模型利用的計算資源特點卻是“數量相對較少,但資源十分豐富”, 高效運行的Spark需要8核CPU與8 GB內存的計算節點支持,因此Hadoop,Spark等數據分析框架不適應邊緣計算的資源環境.現有很多計算框架適用于資源有限的計算節點,如實時數據處理框架Apache Edgent,深度學習框架TensorFlow等,但仍不成熟,有很多問題需要解決.例如Apache Edgent只支持類似過濾,聚集這樣的簡單操作,而TensorFlow目前的版本只能用于單PC或單移動設備上的計算.
4.5 編程模型
邊緣計算資源動態、異構與分散的特性使應用程序的開發十分困難,為減少應用的開發難度,需要可以適應邊緣計算資源的編程模型.Hong等人[39]提出了一個邊緣計算編程模型,針對地理空間分布的延遲敏感的大規模應用,該模型適應分散、異構的資源環境,并使程序可以根據負載動態伸縮.但是該模型假設資源之間的網絡拓撲必須是樹狀的,無法適應邊緣計算資源的動態性.Sajjad等人[40]研究了流處理應用的編程模型,該模型利用空間上分散的計算資源處理數據,將任務區分為本地任務和全局任務,本地任務可以在更靠近數據源的計算節點上執行,從而減少應用在網絡上傳輸的數據量.
5 總結與展望
邊緣計算利用數據傳輸路徑上的資源為用戶提供服務,作為一種新型的計算模式,邊緣計算在很多應用領域都具有巨大的潛力,并對未來萬物聯網的趨勢有著巨大的推動作用.本文介紹了邊緣計算的優勢,并從計算資源、數據以及與云計算的關系這3方面出發對邊緣計算做出定義,也對邊緣計算的相關概念進行了分析與比較;隨后,介紹了邊緣計算的基礎設施——邊緣計算平臺,主要從Cloudlet,ParaDrop,PCloud這3個具有代表性的平臺入手,從應用領域、服務移動性、服務狀態、虛擬化技術這4個方面進行了分析與比較;接著,通過列舉代表性應用,分別展示出邊緣計算在物聯網應用和移動應用上的優勢;最后,梳理了當前邊緣計算所面臨的一些挑戰.
致謝美國韋恩州立大學的施巍松教授對論文進行審閱并提出一些寶貴的建議.在此表示衷心的感謝!
[1]Gray J. Distributed computing economics[J]. Queue, 2004, 6(3): 63-68
[2]Armbrust M, Fox A, Griffith R, et al. Above the clouds: A Berkeley view of cloud computing, UCB/EECS-2009-28[R]. Berkeley: EECS Department, 2009
[3]Evans D. The Internet of Things how the next evolution of the Internet is changing every thing[EB/OL]. [2017-08-15]. https://www.cisco.com/c/dam/en_us/about/ac79/docs/innov/IoT_IBSG_0411FINAL.pdf
[4]Cisco Visual Networking. Cisco global cloud index: Forecast and methodology 2015-2020[EB/OL]. [2017-08-15]. https://www.cisco.com/c/dam/en/us/solutions/collateral/service-provider/global-cloud-index-gci/white-paper-c11-738085.pdf
[5]Ha K, Pillai P, Lewis G, et al. The impact of mobile multimedia applications on data center consolidation[C] //Proc of the 1st IEEE Int Conf on Cloud Engineering. Piscataway, NJ: IEEE, 2012: 166-176
[6]Hu Wenlu, Gao Ying, Ha K, et al. Quantifying the impact of edge computing on mobile applications[C] //Proc of the 7th ACM Sigops Asia-Pacific Workshop on Systems. New York: ACM, 2016: 45-52
[7]Groopman J, Etlinger S. Consumer perceptions of privacy in the Internet of Things: What brands can learn from a concerned citizenry[R]. San Francisco: Altimeter Group, 2015
[8]Satyanarayanan M. The emergence of edge computing[J]. Computer, 2017, 50(1): 30-39
[9]Shi Weisong, Sun Hui, Cao Jie, et al. Edge computing——An emerging computing model for the Internet of everything era[J]. Journal of Computer Research and Development, 2017, 54(5): 907-924 (in Chinese)(施巍松, 孫輝, 曹杰, 等. 邊緣計算: 萬物互聯時代新型計算模型[J]. 計算機研究與發展, 2017, 54(5): 907-924)
[10]Shi Weisong, Cao Jie, Zhang Quan, et al. Edge computing: Vision and challenges[J]. IEEE Internet of Things Journal, 2016, 3(5): 637-646
[11]Bonomi F, Milito R, Zhu Jiang, et al. Fog computing and its role in the Internet of Things[C] //Proc of the 1st Edition of the MCC Workshop on Mobile Cloud Computing. New York: ACM, 2012: 13-16
[12]Cisco DEVNET. Cisco IOx[EB/OL]. [2017-08-15]. https://developer.cisco.com/site/iox/
[13]Open Edge Computing Initiative. Open edge computing [EB/OL]. [2017-08-15]. http://openedgecomputing.org/
[14]Liu Peng, Willis D, Banerjee S. ParaDrop: Enabling lightweight multi-tenancy at the network’s extreme edge[C] //Proc of the 1st IEEE/ACM Symp on Edge Computing. Piscataway, NJ: IEEE, 2016: 1-13
[15]Willis D, Dasgupta A, Banerjee S. Paradrop: A multi-tenant platform to dynamically install third party services on wireless gateways[C] //Proc of the 9th ACM Workshop on Mobility in the Evolving Internet Architecture. New York: ACM, 2014: 43-48
[16]Satyanarayanan M, Bahl P, Caceres R, et al. The case for VM-based cloudlets in mobile computing[J]. IEEE Pervasive Computing, 2009, 8(4): 14-23
[17]Satyanarayanan M. A brief history of cloud offload: A personal journey from odyssey through cyber foraging to cloudlets[J]. GetMobile: Mobile Computing and Communications, 2015, 18(4): 19-23
[18]Ha K, Satyanarayanan M. Openstack++ for cloudlet deployment,CMU-CS-15-123[R]. Pittsburgh: CMU School of Computer Science, 2015
[19]Ha K, Pillai P, Richter W, et al. Just-in-time provisioning for cyber foraging[C] //Proc of the 11th Int Conf on Mobile Systems, Applications, and Services. New York: ACM, 2013: 153-166
[20]Ha K, Abe Y, Chen Zhuo, et al. Adaptive vm handoff across cloudlets,CMU-CS-15-113[R]. Pittsburgh: CMU School of Computer Science, 2015
[21]Ha K, Chen Zhuo, Hu Wenlu, et al. Towards wearable cognitive assistance[C] //Proc of the 12th Int Conf on Mobile Systems, Applications, and Services. New York: ACM, 2014: 68-81
[22]Simoens P, Xiao Yu, Pillai P, et al. Scalable crowd-sourcing of video from mobile devices[C] //Proc of the 11th Int Conf on Mobile Systems, Applications, and Services. New York: ACM, 2013: 139-152
[23]Satyanarayanan M, Lewis G, Morris E, et al. The role of cloudlets in hostile environments[J]. IEEE Pervasive Computing, 2013, 12(4): 40-49
[24]Jang M, Schwan K, Bhardwaj K, et al. Personal clouds: Sharing and integrating networked resources to enhance end user experiences[C] //Proc of the 33rd IEEE INFOCOM. Piscataway, NJ: IEEE, 2014: 2220-2228
[25]Jang M, Schwan K. STRATUS: Assembling virtual platforms from device clouds[C] //Proc of the 4th IEEE Int Conf on Cloud Computing. Piscataway, NJ: IEEE, 2011: 476-483
[26]Jang M,Lee H, Schwan K, et al. SOUL: An edge-cloud system for mobile applications in a sensor-rich world[C] //Proc of the 1st IEEE/ACM Symp on Edge Computing. Piscataway, NJ: IEEE, 2016: 155-167
[27]Li Dawei, Salonidis T, Desai N V, et al. DeepCham: Collaborative edge-mediated adaptive deep learning for mobile object recognition[C] //Proc of the 1st IEEE/ACM Symp on Edge Computing. Piscataway, NJ: IEEE, 2016: 64-76
[28]Takahashi N, Tanaka H, Kawamura R. Analysis of process assignment in multi-tier mobile cloud computing and application to edge accelerated Web browsing[C] //Proc of the 3rd IEEE Int Conf on Mobile Cloud Computing, Services, and Engineering. Piscataway, NJ: IEEE, 2015: 233-234
[29]Tang Bo, Chen Zhen, Hefferman G, et al. A hierarchical distributed fog computing architecture for big data analysis in smart cities[C] //Proc of the 15th ASE BigData & SocialInformatics 2015. New York: ACM, 2015: 135-143
[30]Gosain A, Berman M, Brinn M, et al. Enabling campus edge computing using GENI racks and mobile resources[C] //Proc of the 1st IEEE/ACM Symp on Edge Computing. Piscataway, NJ: IEEE, 2016: 41-50
[31]Bhardwaj K, Shih M W, Agarwal P, et al. Fast, scalable and secure onloading of edge functions using AirBox[C] //Proc of the 1st IEEE/ACM Symp on Edge Computing. Piscataway, NJ: IEEE, 2016: 14-27
[32]Nastic S, Truong H L, Dustdar S. A middleware infrastructure for utility-based provisioning of IoT cloud systems[C] //Proc of the 1st IEEE/ACM Symp on Edge Computing. Piscataway, NJ: IEEE, 2016: 28-40
[33]Loreto S, Mecklin T, Opsenica M, et al. Service broker architecture: Location business case and mashups[J]. IEEE Communications Magazine, 2009, 47(4): 97-103
[34]Chaves S A D, Uriarte R B, Westphall C B. Toward an architecture for monitoring private clouds[J]. IEEE Communications Magazine, 2011, 49(12): 130-137
[35]Povedano-Molina J, Lopez-Vega J M, Lopez-Soler J M, et al. DARGOS: A highly adaptable and scalable monitoring architecture for multi-tenant Clouds[J]. Future Generation Computer Systems, 2013, 29(8): 2041-2056
[36]Grozev N, Buyya R. Inter-Cloud architectures and application brokering: Taxonomy and survey[J]. Software Practice & Experience, 2014, 44(3): 369-390
[37]Ahmed A, Ahmed E. A survey on mobile edge computing[C] //Proc of the 10th IEEE Int Conf on Intelligent Systems and Control. Piscataway, NJ: IEEE, 2016: 1-8
[38]Intel. LTE/dual-mode small cell SoC[EB/OL]. [2017-08-15]. https://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/transcede-t3k-product-brief.pdf
[39]Hong K, Lillethun D, Ramachandran U, et al. Mobile fog:A programming model for large-scale applications on the Internet of Things[C] //Proc of the 2nd ACM SIGCOMM Workshop on Mobile Cloud Computing. New York: ACM, 2013: 15-20
[40]Sajjad H P, Danniswara K, Al-Shishtawy A, et al. SpanEdge: Towards unifying stream processing over central and near-the-edge data centers[C] //Proc of the 1st IEEE/ACM Symp on Edge Computing. Piscataway, NJ: IEEE, 2016: 168-178
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
電子制作(2018年11期)2018-08-04 03:26:08
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
工業設計(2016年12期)2016-04-16 02:52:00
