CPU和DRAM加速任務劃分方法:大數據處理中Hash Joins的加速實例
2018-03-13 05:00:00吳林陽郭雪婷
計算機研究與發展 2018年2期
吳林陽 羅 蓉 郭雪婷 郭 崎
(中國科學院計算技術研究所 北京 100190)(wulinyang@ict.ac.cn)
在設計現代計算機系統時首先要考慮的因素是能效.為了提高系統能效,諸如FPGA,GPU和定制加速器等硬件加速器已被廣泛應用于工業領域.使用硬件加速器的典型案例有:微軟組建FPGA服務器用于加速大規模的數據中心服務[1];亞馬遜于2010年開始部署GPU云服務器;惠普實驗室為Memcached定制加速器[2].通常,硬件加速器集成在處理器芯片中(例如SIMD單元、卷積引擎[3]、IBM的PowerEN[4]),或部署為一個獨立的芯片(例如GPU顯卡、FPGA板卡和Xeon Phi協處理器),通過PCI-E與主處理器進行通信.
隨著靠近數據的處理(near-data processing)技術的出現,將硬件加速器集成到DRAM堆棧中以降低數據移動的成本成為一種新的系統設計思路.其基本思想是利用3D堆疊技術,將一些包含加速器的邏輯die和多個DRAM die垂直集成到一個芯片中[5-7].然而,由于3D堆疊DRAM在面積、功耗、散熱和制造等方面的限制,能夠集成到DRAM中的加速器的數量和類型是有限的.因此,給定一個需要加速的目標應用,確定其中哪些部分最適合在DRAM中加速是至關重要的.
理想的加速目標應該是內存帶寬受限的,因為3D堆疊DRAM具有比現有系統高一個數量級的高內存帶寬.一個最典型的例子是數據重組操作,它是許多應用領域的關鍵組成部分,如高性能計算、信號處理和生物信息學.數據重組只包含CPU和DRAM之間的往返數據移動,它不消耗浮點運算周期.因此,在DRAM中加速數據重組是很自然的想法,文獻[8]中論證了這項工作.但是對于大多數真實應用程序來說,它們混合了計算和數據移動,情況更為復雜.
在本文中,我們進行了一個hash joins的案例研究,探索如何將它在CPU和DRAM之間進行合適的加速任務劃分.選擇hash joins有3個原因:1)hash joins不僅是傳統數據庫系統的基本操作,還是諸如Spark[9]等主流大數據系統的關鍵操作;2)很多文獻都對hash joins做了充分研究[10-15],因此加速的baseline已經高度優化;3)最先進的hash joins: optimized version of radix join algorithm(PRO)[11,15]是帶寬資源受限的,它可能會從內存加速中受益.我們對PRO以及PARSEC benchmark suite中具有代表性的多線程應用程序分別進行了帶寬分析,如圖1所示.平均來看,PRO對帶寬的需求比使用8線程的PARSEC benchmark高3.6倍.與PARSEC benchmark suite中帶寬資源受限最嚴重的streamcluster相比,在2,4和8線程下,PRO仍多消耗143%,117%和18%的帶寬資源.
為了研究在PRO中內存訪問對總能耗的貢獻,我們對PRO的3個不同階段:partition,build和probe,進行了詳細的能耗分析.雖然所有階段的內存帶寬都趨于飽和,但各個階段中計算所消耗的能量差異是很大的.在partition階段,計算消耗的能量還不到該階段總能量的50%;而在build和probe階段,計算消耗的能量占總能量的85%以上.換句話說,數據移動消耗的能量是partition階段能耗的主要部分.主要的原因是在partition階段有許多高代價的非規則內存訪問,而其他2個階段只有常規的內存訪問.因此,僅在DRAM端加速partition階段,在CPU端加速其余階段是有意義的.為了加速partition階段,我們構建了適合于3D堆疊結構的hash分區加速器(hash partition accelerator, HPA).為了加快build和probe階段,我們采用傳統的SIMD加速單元來提高計算效率.

Fig. 1 Memory bandwidth of PARSEC benchmarks and Radix hash join圖1 PARSEC benchmarks和Radix hash join的內存帶寬分析
本文的創新點和貢獻可以概括如下:
1) 以數據移動為驅動的加速任務劃分方法.我們提出了一種以數據移動為驅動的方法來劃分CPU和DRAM之間的加速任務,使得我們能夠在滿足3D堆疊DRAM面積、功耗、發熱的嚴格限制條件下,充分挖掘其加速性能.
2) 最先進的hash joins的詳細分析.我們對最先進的hash joins算法進行了詳細的性能和能耗分析.性能分析結果顯示,最先進的hash joins(PRO)本質上是內存受限的.我們的能耗分析結果顯示,在partition階段,總能量的50%以上被數據移動和流水線阻塞所消耗,這可以通過在內存端進行加速得到顯著緩解.在build和probe階段,只有大約15%的能量被數據移動和流水線阻塞所消耗,這仍然可以利用現有的CPU端加速單元(如SIMD單元)進行加速.
3) hash分區加速器的設計.我們設計了一個hash分區加速器(HPA),并將其集成到3D堆疊DRAM的邏輯層中.HPA包含3個主要的部件:hash unit, histogram unit和shuffle unit.此外,我們探索了設計空間,使得我們能夠在多種3D堆疊DRAM配置中找到HPA的最佳設計方案.實驗結果表明,與現有系統相比,HPA提高了3個數量級的能效.
4) 針對hash joins的混合加速系統.我們建立了一個混合加速系統,該系統包含內存端定制的加速器和處理器端SIMD加速器,這個系統能提高hash joins的整體能效.實驗結果表明,平均而言,該系統在英特爾Haswell和Xeon Phi處理器上分別提高了48倍和20倍的能效.
1 背景介紹
1.1 hash joins
join操作是將2個或多個關系表中的元組組合起來的基本數據庫操作,hash joins被認為是內存數據庫管理系統中最流行的join算法之一.此外,hash joins也被廣泛應用在Spark等大數據平臺中.現有的hash joins算法大致可以分為2類,即不考慮硬件結構的hash joins和考慮硬件結構的hash joins[11].
1) 不考慮硬件結構的join.該類join算法不關心運行算法的底層硬件結構.簡單hash joins算法(SHJ)就是一種典型的不考慮硬件結構join算法,它包括2個階段:build和probe.在build階段,掃描較小的關系表R,建立一個hash表;然后在probe階段,遍歷S關系表中的每個元組,在hash表中找到與之匹配的R關系表中的元組.文獻[10]提出了SHJ的并行版本:no partition algorithm (NPO),用以挖掘多核架構的并行性.NPO的關鍵是把輸入關系表R和S分成相等大小的部分,每個部分被分配到一個工作線程進行處理.然而,由于NPO的hash過程中存在大量的隨機內存訪問,可能導致大量的cache miss,使得能效下降.這就是不考慮硬件結構的join算法的缺點.
2) 考慮硬件結構的join.為了更好地利用高速緩存的層次結構,考慮硬件結構的join算法被大量研究.文獻[16]提出了一種新的可以充分利用高速緩存的磁盤連接算法DBCC-join.它將執行過程分成了2個階段:JPIPT構建階段和結果輸出階段,并在JPIPT構建階段構建索引時充分考慮了高速緩存的特性.此外,為了充分利用高速緩存和TLB的局部性,radix partition被廣泛采用[17].PRO[11,15]是目前最先進的一種hash joins算法.PRO算法分為3個階段:partition,build和probe.
① partition.圖2給出了PRO的partition階段.該階段可以進一步分為4個階段:local histogram, prefix sum, output addressing, data shuffling.其中,local histogram和data shuffling階段占總執行時間的99%以上.在local histogram階段,掃描分塊的輸入關系表(R或S)rel,建立一個histogram數組my_hist;在data shuffling階段,rel中的元組根據存儲在dst數組中的位置被復制到目標分組tmp,完成對關系表rel的劃分.

Fig. 2 The partition phase of PRO
圖2 PRO的partition階段
② build.圖3給出了PRO的build階段.在這一階段中掃描較小的關系表R,建立next和bucket數組.next數組用于追蹤被hash到同一個簇中的上一個R元組;而bucket數組用于追蹤被hash到當前簇的最后一個R元組.

Fig. 3 The build phase of PRO
圖3 PRO的build階段
③ probe.圖4給出了PRO的probe階段.關系表S中的每一個元組hash成一個bucket數組的索引.然后檢索bucket和next,嘗試找到與該S元組匹配的R元組.

Fig. 4 The probe phase of PRO
圖4 PRO的probe階段
1.2 內存端加速
作為減少計算單元與內存之間通信開銷的一種有前景的技術,內存中處理(PIM)在過去幾十年受到了廣泛關注.PIM的基本思想是將簡單的處理邏輯集成到傳統的DRAM或嵌入式DRAM(eDRAM)陣列中[18].比如,可以將SIMD加速單元集成到DRAM die中[19-20];還可以將可重構計算邏輯集成到DRAM die中,構建ActivePage[21].然而,PIM技術的實現面臨一個主要障礙:內存加工工藝與邏輯單元加工工藝有很大的不同.用同樣的工藝制造出單個芯片不能充分發揮出PIM的優勢.
垂直3D die堆疊技術允許將多個存儲器die直接疊加在處理器die上,從而提高內存帶寬[22-25].這些 die與短、快速、密集的TSV集成在一起,提供了非常高的內部帶寬.雖然發熱問題是異構die堆疊的一個主要問題,但是仍然出現了一些3D堆疊內存產品,比如三星、Tezzaron、Micron生產的3D堆疊內存.以Micro的Hybrid Memory Cube(HMC)為例,它在邏輯層之上堆疊多個DRAM die,邏輯層中包含能夠訪問垂直bank的vault controller,以及與其他處理單元和stack通信的link controller.通過在HMC的邏輯層直接集成加速器來獲得極高的內部帶寬,可以避免在計算單元和內存之間進行來回的數據搬運.
雖然有一些關于集成加速單元的文獻,如高能效處理器核[26]、可編程GPU[5]、SIMD單元[7]和定制的加速器[6,27],但當給定一個應用程序時,CPU和DRAM之間的執行任務的劃分仍舊是一個值得研究的問題,因為CPU在這些系統中仍然是不可或缺的.
2 hash joins分析
這一部分,我們在商用多核處理器上對hash joins操作的訪存和能耗進行了詳盡的分析.
2.1 分析方法
我們對最先進的hash joins算法PRO進行了詳細的性能分析和能耗分析,該算法針對現代多核系統進行了特殊的優化.我們建立了如表1所示的多核評測系統.為了收集如訪存帶寬、cache miss和功耗等執行細節,我們使用了Intel的Performance Counter Monitor(PCM)2.8提供的編程接口.在該評測平臺上,我們可以收集L1L2緩存未命中率、內存控制器的讀寫字節數等關鍵信息.此外,通過查看Intel的RAPL(Runtime Average Power Limit)[28]提供的計數器,我們也可以獲得處理器和DRAM的能耗信息.

Table 1 The Hardware System Used for Evaluation表1 用作評估的硬件系統
2.2 訪存分析
雖然hash joins算法的性能瓶頸已經得到了很好的研究,但是在分析hash joins訪存行為細節方面仍然缺乏研究工作.
如圖1所示,雖然PRO整體的內存帶寬要求高于傳統的多線程應用程序(比如PARSEC benchmark),但我們將進一步研究PRO是否受限于可用的內存帶寬.如表2所示,根據內存設備的物理特性計算,系統的理論最大帶寬為21.2 GBps,但是在實際應用中理論帶寬是難以達到的.對于實際應用來說,一種充分挖掘內存帶寬的方法是采用流式(stream)訪存.在高性能計算領域中,STREAM benchmark[29]被廣泛用于測量系統的可持續內存帶寬.使用STREAM benchmark對我們的評測平臺進行測試,發現平臺的可持續內存帶寬約為18.49 GBps.在運行8線程的PRO中,我們測得實際內存帶寬為17.24 GBps,約為可持續帶寬的93.2%.換句話說,PRO幾乎使評測平臺的可持續內存帶寬達到飽和.

Table 2 Bandwidth Measurement表2 帶寬評估
PRO包含partition,build和probe這3個主要執行階段,我們進一步測量每個階段的訪存帶寬.如圖5(a)所示,在8個線程下,partition階段的內存帶寬為17.2 GBps,其余2個階段的內存帶寬約為15.6 GBps.這一觀察結果表明,在PRO的整個執行過程中,內存帶寬利用率始終很高.但是,如表3所示,partition階段的最后一級cache未命中率遠遠高于其他2個階段.從內存帶寬利用率和cache miss兩個不同角度觀察,我們發現導致PRO不同階段都有如此高的帶寬利用率的根本原因是不同的.由于partition階段中data shuffling過程(參見圖2)存在大量隨機訪存行為,導致大量cache miss,從而使得帶寬利用率看起來很高,但實際的數據移動效率卻較低;而build和probe階段是流式訪存,所以帶寬利用率和數據移動效率都較高.
我們進一步研究partition階段,其中local histogram(LH)和data shuffling(DS)的執行時間占總執行時間的99%以上.如圖5(b)顯示,當使用4個線程運行時,LH階段受到可用內存帶寬的限制,原因是關系表的順序訪存容易使內存帶寬達到飽和.對于DS的階段,在運行8個線程時內存帶寬達到峰值.我們可以看到,DS階段內存帶寬低于LH階段.究其原因,是由于鍵(key)在各自位置上的分布性,在DS階段存在很多不規則的訪存.

Fig. 5 Detailed bandwidth analysis of PRO圖5 PRO的詳細帶寬分析

Table 3 L3 Cache Miss Ratio of PRO表3 PRO的cache miss率
基于以上分析,我們認為由于密集的訪存行為(規則的和不規則的),最先進的hash joins算法在商用多核結構上被可用帶寬所限制.這種密集的訪存行為不僅會導致性能下降,而且具有較高的能耗.在hash joins算法中,計算部分相對簡單,比如位操作、hash(如圖2中的行③)、數組索引(如圖2中的行)和整數增量(如圖2中的行).因此,預計移動數據產生的能耗比計算本身更為嚴重.為了驗證這一假設,我們進行進一步的實驗來確定hash joins算法的能耗瓶頸.
2.3 能耗分析
我們從2個級別來進行能耗分析:粗粒度級別和細粒度級別.在粗粒度級別,我們分析了partition,build+probe階段的能耗.在細粒度級別,我們將能消耗分為3類:數據移動、流水線阻塞和計算能耗,我們采用了文獻[30-31]中提出的評測方法.
1) 粗粒度級別分析結果.圖6給出了在不同輸入大小(32~256 M)和線程數(1~4)情況下,partition和build+probe階段的能耗比較.平均來看,partition階段能耗約占總能耗的86.4%.因此,對于CPU和DRAM來說,有必要降低partition階段的能耗.
2) 細粒度級別分析結果.圖7展示了整個hash joins過程的細粒度能耗分解.我們測量由數據移動和流水線阻塞帶來的能耗,流水線阻塞主要是由數據移動操作和功能單元的爭搶引起的,剩余的能耗是由計算和其他原因導致的.

Fig. 6 Energy of the partition and build+probe圖6 partition階段和build+probe階段的能耗

Fig. 7 Energy breakdown of the hash joins operation圖7 hash joins操作的能耗分解
對于build+probe階段,由數據移動引起的能耗相對較小,僅占總能耗的1.8%.相比之下,計算引起的能耗約占總能耗的11%,是數據移動能耗的6.4倍.與build+probe階段相比,partition階段能耗情況則完全不同.
在運行1個工作線程時,在數據移動、流水線阻塞和計算+其他方面消耗的能量分別為18.6%,31.9%和35.8%.可以看出,數據移動和流水線阻塞對整體能耗有很大的貢獻.
雖然hash joins的所有階段幾乎使內存帶寬飽和(參考3.2節),但partition和build+probe階段的數據移動能耗有著顯著的不同.在partition階段,數據shuffle過程存在大量高代價的不規則的訪存行為,導致數據移動開銷大.而在build+probe階段,只有常規的流式訪存,使得數據移動成本可以忽略不計.因此,設計DRAM中加速器的首要考慮的因素是數據移動的成本,而不是內存帶寬.
現代處理器為了降低內存訪問延遲,設計了多個層次的存儲結構,因此數據移動操作可以進一步分為4類:L1到寄存器、L2到寄存器、L3到寄存器和內存到寄存器.這4類操作的能耗分布如圖8所示.從DRAM到寄存器數據移動的能耗約占總能耗的60%,而處理器內的移動數據(包括L1到寄存器、L2到寄存器和L3到寄存器)的能耗約占總能耗的40%.因此,有必要同時從CPU和DRAM兩端降低數據移動的能耗.

Fig. 8 Breakdown of energy caused by data movement in the partition phase圖8 partition階段數據移動帶來的能耗分解

Fig. 9 The overview of proposed hybrid accelerated system圖9 混合加速系統的總體架構
綜上,雖然最好的hash joins算法是內存受限的,但由于partition階段有著不規則的內存訪問,大部分的能耗是由流水線阻塞和數據移動產生的;而對于訪存有規律的build+probe階段,大部分能量消耗在計算上.為了在面積、功耗、散熱受限的DRAM邏輯層上提高整體的能效,我們建議只在DRAM中加速partition階段,而把build+probe階段的加速留給CPU.
2.4 在DRAM中加速的收益
通過將加速器集成到DRAM中,可以從各個方面減少partition階段的能耗,從而減少總體能耗.
1) 數據移動的能耗.通過將加速器集成到DRAM中,可以避免CPU和DRAM之間高代價的往返數據傳輸,從而直接降低數據移動能耗.
2) 流水線阻塞的能耗.由于相當緩慢的內存訪問導致了大量的流水線阻塞,因此數據訪問的改進(通過將計算移動到更接近數據位置)也有助于減少流水線阻塞帶來的能耗.
3) 計算的能耗.使用自定義hash分區加速器(HPA)可以顯著降低計算能耗.
3 系統概覽
圖9展示了hash joins混合加速系統的總體結構,包括多眾核的主機處理器和一個或多個3D DRAM stack.在每個DRAM stack的邏輯層中,我們將hash分區加速器(HPA)集成到每個vault controllor上,使HPA可以充分利用3D DRAM中極高的內部帶寬.
1) 主機處理器.主機處理器是一個傳統的多眾核處理器,例如Intel的Haswell或Xeon Phi處理器.它通過高速連接(用于傳統的HMC系統中)或者interposer(用于Intel的Knights Landing中)與3D DRAM stack進行通信.主機處理器可以通過引入SIMD單元、定制的加速器或GPU等加速器增強自身性能,從而提高大多數應用的性能.在我們的混合系統中,主機處理器主要側重于利用SIMD單元來加速build和probe階段.
2) 集成加速器的3D堆疊DRAM.針對每個3D DRAM stack,我們集成多個HPA來充分利用其高內存帶寬,從而降低整體的能耗.由于每個3D DRAM stack包含多個vault,并且每個vault都由邏輯層的vault controller訪問,所以我們將一個HPA集成到vault controller上.
為加速partition階段而設計的hash分區加速器(HPA)包含3個主要部件:hash unit,histogram unit和shuffle unit.這些單元通過vault controller訪問DRAM層,并且與開關電路相連.
4 hash分區加速器
在這一部分,我們首先介紹HPA的設計架構.然后,探索可能的設計空間來找到最優的設計方案.
4.1 加速器設計
每個HPA的詳細架構如圖10所示.HPA通過vault controller訪問DRAM.
1) hash unit.如圖10(a)所示,我們以一個處理并行度為4的hash unit為例,介紹hash unit的架構.它以流式訪問的方式從DRAM中讀取關系表中的多個元組,然后并行地處理它們的keys,以位移或者掩碼的方式來產生hash索引.由于hash unit會被histogram unit和shuffle unit復用,所以加入了多路選擇器(MUX)用于決定hash索引的輸出目標.
2) histogram unit.圖2中的原始histogram算法應該串行執行.為了增加histogram操作的并行度,我們采用本地存儲器(local memory, LM)來保存my_hist的多個副本,每個副本都由單獨的處理單元處理.如圖10(b)所示,并行的histogram操作被分解為2個階段:并行增量階段(INC)和串行歸約階段(RED).在INC階段,hash unit產生的hash索引idx用于更新對應的LM當前的histogram值.在處理完從DRAM中讀取的所有鍵后,最后的RED階段進行所有LM的整合,以獲得一個完整且保持數據一致性的my_hist.
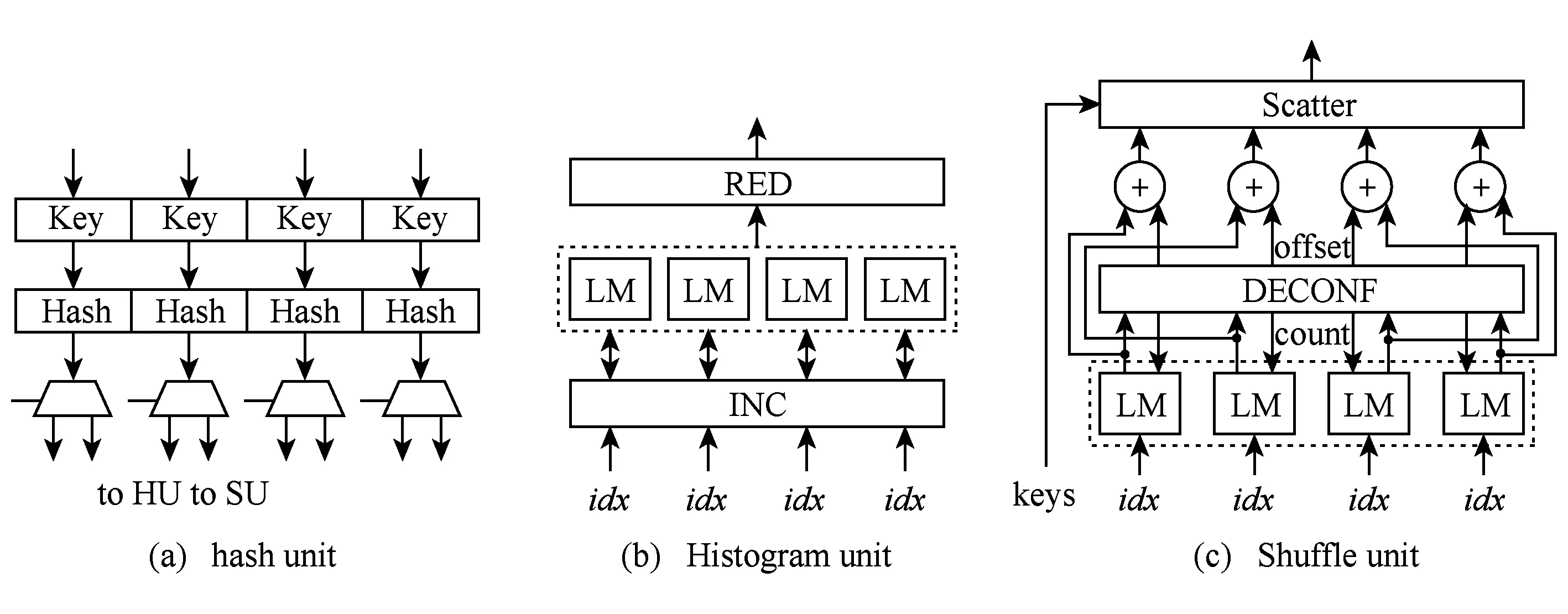
Fig. 10 The architecture of HPA圖10 HPA的架構
histogram unit設計中需要關心的是LM的功耗和面積.LM的數量越多,處理my_hist的并行度越高,但是相應地會增加面積和功耗.同時為了減少TLB miss,LM的大小還受到TLB項數量的限制[11].具體來說,每個my_hist副本大小最好與TLB項數量相等.在現代處理器中針對L1設計的數據TLB通常是64或128項.因此,給定一個很高的并行度,比如512,LM的總大小為256 KB(512×128×4).當然,我們應該謹慎選擇并行度,在性能、功耗和面積之間做設計權衡.
3) shuffle unit.與 histogram unit的并行設計思路類似,shuffle unit的設計的挑戰是如何將多個元組同時寫入到各自在tmp數組中的目標地址(tmp[dst[idx]]),然后更新dst數組中的目標地址(如圖2所示).如果多個處理路徑中具有相同目的地址的元組,還需要處理目標地址沖突問題.
我們提出的并行shuffle unit由4個階段組成:第1階段(DIST)是根據hash索引(idx)從dst數組中并行地讀取多個目標地址(圖2的第行).第2階段(DECONF)用于檢測多個處理路徑之間有沖突的目的地址.DECONF階段產生基于原始目標地址的偏移,從而確定在tmp數組中正確的目的地址.同時DECONF階段也產生相同目的地址的計數值來更新idx數組.第3階段(SCATTER)將元組移動到正確的位置,正確的位置根據DECONF階段產生的偏移和DIST階段產生的存儲在tmp數組的原始目的地址聯合計算得出.最后一個階段(UPDATE)根據DECONF階段產生的計數值更新目的地址.
DECONF本質上是一個在原始目的地址上執行XNOR操作的XNOR網絡.圖11給出了XNOR網絡的結構示例,在此示例中,4個目的地址的數值d0,d1,d2和d3從dst數組中并行的讀出.為了計算d0的總數量count(d0),首先d0分別與d1,d2和d3進行同或操作,然后所有同或的數值進行求和.同樣地,通過對xnor(d1,d0), xnor(d1,d2)和xnor(d1,d3)求和計算得出count(d1).計算目標地址偏移也可以通過復用XNOR網絡來實現.例如,offset(d1)是xnor(d1,d2)和xnor(d1,d3)的和.

Fig. 12 The throughput and power of the histogram operation圖12 histogram操作的吞吐率和功耗

Fig. 11 XNOR network圖11 XNOR網絡圖示
4.2 設計空間探索
在HPA的設計過程中,在并行度和頻率上存在多種選擇,同時3D堆疊DRAM也可以選擇不同的配置.表4列出了3種可能的3D堆疊DRAM配置:HI,MD和LO,它們的內部帶寬在860 GBps~360 GBps之間.我們探索了由每個vault的并行度(1~512)、操作頻率(0.4~2.0 GHz)和DRAM配置組成的設計空間,嘗試在在并行度和功耗之間進行設計權衡.更多的細節和評估方法論可以在第6節中找到.

Table 4 3D-Stacked DRAM Configurations表4 3D堆疊內存配置
4.2.1 histogram操作
圖12顯示了使用HI和LO DRAM配置,在不同的頻率和并行度下histogram操作的吞吐率和功耗.第1個觀察結果是吞吐率隨著并行度和頻率的增加而增加,這充分說明了我們設計的可伸縮性.針對HI配置,在2 GHz下當并行度從8增加到16,相應的吞吐率也增加了約2倍.然而,隨著頻率和并行度的不斷增加,所需的內存帶寬也會增加,從而使吞吐率受到可用內存帶寬的限制.在另一個例子中,給定0.4 GHz的頻率,雖然并行度從32增加到64時,吞吐率增加了約2倍,但是當并行度從64增加到128時,吞吐率只有1.6倍的增加.另外,當并行度從256增加到512時,吞吐率的增益僅為1.06.針對不同的頻率,在不同并行度下,HI和LO配置的吞吐率最終會分別收斂到840 GBps和450 GBps.
至于功耗,除了直觀地觀察到功耗隨并行度和頻率增加外,我們還觀察到不同頻率之間的功耗差距會隨著并行度的變化而變化.對HI配置,當并行度是16時,最大功耗(在2 GHz時)比最小功耗(在0.4 GHz時)高2.54倍,而當并行度是64時,功耗差距只有1.26倍.這是由于DRAM在相對較小的并行度的情況下,不同頻率之間的功耗有一個較大的差距.

Fig. 15 The throughput and power of the shuffle operation圖15 shuffle操作的吞吐率和功耗
為了詳細說明功耗,圖13顯示了HI配置下的histogram操作的功耗分解.我們可以看到,隨著并行度的增加,DRAM的功耗所占比例(例如DRAM_RD)也隨之增加.然而,當并行度大于32時,DRAM功耗所占的比例減小,因為內存帶寬幾乎飽和,同時HASH和INC功耗顯著增加.在2 GHz下,并行度是512時,HASH和INC功耗甚至高于DRAM功耗.

Fig. 13 The power breakdown of the histogram operation圖13 histogram操作功耗分解
我們還在圖14中,以能量-延遲積(EDP)為標準,展示了在不同設計方案下的每個vault的能效.在所有的DRAM配置下,隨著并行度的增加,EDP并沒有顯示出單調下降的趨勢.特別值得注意的是,在并行度在32左右時,所有DRAM配置的EDP達到了最優值.舉例來說,使用HI配置,在1.2 GHz操作頻率下,達到最優的EDP需要64的并行度.一般來說,相比HI配置,MD和LO DRAM配置具有更好的能效(每個vault),隨著并行度的增大變得尤為明顯.圖14還顯示了不同設計選擇下的面積.可以看出,隨著并行度的增加面積會顯著增加.在每個vault中每一個HPA的最大面積大約為1.4 mm2,這是因為HPA需要更多的處理單元.

Fig. 14 Energy-delay product (EDP) of different design options for the histogram operation圖14 不同設計下histogram操作的能量-延遲積
4.2.2 shuffle操作
圖15展示了使用HI和LO DRAM配置,在不同的頻率和并行度下shuffle操作的吞吐率和功耗.一般來說,吞吐率會隨著并行度和頻率的提高而增加,在HI和LO的配置下,它最終分別收斂到91 GBps和29 GBps.最大吞吐率主要受SCATTER階段的限制,在該階段中是以相對隨機的方式進行內存訪問的.隨著并行度和頻率的增加,功耗也會隨之增長.在2 GHz下,在HI和LO配置中最大功耗分別達到了216 W和54 W.
圖16展示了shuffle操作下的功耗分解.當并行度很小時,比如1~16,DRAM的靜態功耗占主要部分.隨著并行度的增加,HASH和SCATTER的功耗顯著增加,最終超過了DRAM的靜態功耗.

Fig. 16 The power breakdown of the shuffle operation圖16 shuffle操作的功耗分解
圖17展示了每個vault的shuffle操作能效(EDP)和面積.達到最優EDP的并行度是在32~128之間.例如,在2 GHz下,并行度為32的EDP比并行度為512的EDP好1.77倍.在所有的這些配置中,獲得最優EDP的配置為并行度=64、頻率=1.2 GHz和DRAM配置=LO.最優配置所需要的面積為0.18 mm2(每vault).

Fig. 17 Energy-delay product (EDP) of different design options for the shuffle operation圖17 不同設計下shuffle操作的能量-延遲積
4.2.3 設計決策
要做出HPA的最優設計決策,我們必須綜合考慮histogram和shuffle兩個操作的性能、功耗和面積.我們通過對比不同配置下這2個操作的總EDP決定最優的HPA配置.我們得出結論是:當輸入的大小是128 M時,HPA的最優配置是并行度=16、頻率=2.0 GHz、DRAM配置=HI.相應的面積只有1.78mm2,加速器的功耗(不含DRAM功耗)只有7.52 W.
5 軟件設計
軟件設計包括用于調用HPA(hash分區加速器)的編程接口和用于加速build和probe階段的SIMD指令.
5.1 HPA編程接口
我們采用的編程接口是在文獻[6]中提出的編程庫上進行搭建的.所使用的庫函數包括內存管理庫函數malloc和free,以及加速器控制庫acc_plan(用于配置加速器)和acc_execute(用于調用已配置的加速器).我們對acc_plan函數進行擴展,使它支持2個新的操作:HIST和SHUF,分別用來控制HPA執行histogram和shuffle操作.在這些庫函數的幫助下,程序員可以很容易地在程序中使用HPA.此外,我們使用的編程接口本質上是一個順序編程模型,所以可以減輕異構系統的編程負擔.
然而,加速代碼(如histogram和shuffle操作)是一個并行執行范式,其中每個工作線程都需要處理自己的數據分塊.為了縮小順序編程模和并行編程模型之間的差距,我們在每個工作線程調用HPA之前添加barrier操作,然后只有1個線程通過acc_plan和acc_execute調用HPA,同時所有其他線程都在等待HPA執行(histogram或shuffle操作)完成.在HPA完成執行之后,每個工作線程恢復各自的執行流,進行后續操作.
5.2 針對build+probe階段的SIMD加速
近年來,為提高hash joins的執行效率,針對SIMD和向量化有很好的研究.我們采用了在文獻[13,15]中提出的SIMD算法,在多核(例如Intel Haswell)和眾核(如Intel Xeon Phi)處理器上加速build和probe階段.
圖18展示了在支持512-bit SIMD的Xeon Phi處理器上用SIMD執行build階段的基本思想.直觀來看,多個hash操作可以并行執行(參考圖3中的行③).在圖18行④中,gather操作從元組中選擇鍵.在行⑤中,基于SIMD的hash操作(包括SIMD按位與和移位)并行地進行多個鍵的hash處理.在行⑥中,將hash處理的結果寫回extVector.extVector
① 單位為元組的個數,數據的總大小是0.5 GB~4 GB (256 M×8×2 B=4 GB)
中包含16個idx(參考圖3),用于順序更新bucket數組.probe階段的SIMD執行類似于build階段.

Fig. 18 The basic idea of 512-bit SIMD execution of the build phase
圖18 512-bit SIMD執行build階段的基本思想
6 實 驗
在本節中,我們展示了混合加速系統的能效,并將其與支持SIMD的商用多眾核處理器進行比較.
6.1 評測方法
1) 評測基礎設施.我們采用了文獻[6]中提出的混合評價方法論來評估我們的系統.這種評估方法的主要優點是真正的執行行為可以被如實地模擬.
2) 主機處理器.表5列出了用于評估的主處理器,其中Intel Haswell和Intel Xeon Phi處理器分別是商用多核和眾核處理器.我們在主機處理器上運行PRO算法,并測量不包括加速部分(partition階段的histogram和shuffle操作)程序的性能和功耗.我們還測量了使用主處理器把加速部分任務分派到HPA加速器的開銷(包括加速器控制帶來的開銷和刷新緩存以保證數據一致性帶來的開銷).
3) 加速器仿真.通過各種仿真工具對hash分區加速器(HPA)的性能、功耗和面積行評估.該加速器的性能是由一個內部的、C-level、周期精準的模擬器估計的.DRAM的訪存延遲是由一個周期精準的3D堆疊DRAM模擬器獲得的[8].我們采用32 nm的庫和編譯器來評估HPA的功耗和面積.
4) Baseline.為了展現混合加速系統的優勢,我們對比了Intel Haswell和Xeon Phi處理器和我們的系統.如表5所示,它們的內存帶寬的峰值分別為21.2 GBps和320 GBps.我們在這2個平臺上全面的測量了hash joins算法的性能和功耗.
5) HPA配置和輸入數據集.如第4節所探討的,HPA的最佳頻率和并行度分別為2.0 GHz和16.3D堆疊DRAM是HI配置,它包含16個vault,最大的內部帶寬為860 GBps(如表4所示).關于輸入數據集,我們將輸入關系表的元組數目作為可調整的變量,從32 M~256 M①進行了測試.

Table 5 The Baseline Host Processors表5 基準主處理器
6.2 實驗結果
我們用不同大小的輸入數據集,在性能、能耗和EDP這3個方面將我們提出的混合系統和Haswell和Xeon Phi處理器進行了比較,結果如圖19所示.與Haswell處理器相比,混合系統在性能、功耗和EDP上分別優化了6.70,7.08和47.52倍.與Xeon Phi處理器相比,混合系統在性能、功耗和EDP上分別優化了4.17,4.68和19.81倍.我們觀察到,Xeon Phi處理器的收益比Haswell處理器的收益要小.原因是在Xeon Phi上,build和probe階段執行所占的比例比Haswell更大.
如圖20所示,針對hash partition操作,我們比較了HPA與基準平臺的性能、能耗和EDP.平均而言,與Intel Haswell處理器相比,HPA的性能、功耗和EDP分別優化了30,90和2 725倍.與Xeon Phi處理器相比,EDP優化甚至超過了6 000倍.性能和能效的顯著提高主要來源于定制加速器和由3D堆疊DRAM提供的高內存帶寬.
為了更詳細地分析實驗結果,我們在圖21中給出了Intel Haswell處理器的執行過程分解.根據圖21(a)中執行時間的分解,HPA只占整個執行時間的19.2%.相比之下,加速前的partition階段的執行時間大約是整個執行時間的90%,這表明partition階段已經被加速了大約30倍.此外,當輸入數據集很小時(比如32 M),HPA的調用成本是巨大的,占總執行時間的8.6%.當輸入數據的大小增加時,調用成本逐漸變得可以忽略,例如,當輸入數據大小是256 M時,調用成本只是總執行時間的1%.

Fig. 19 Overall comparison with the Intel Haswell and Xeon Phi processor圖19 與Intel Haswell和Xeon Phi處理器總體對比

Fig. 20 Comparison with the Intel Haswell and Xeon Phi processor for the hash partition operation圖20 與Intel Haswell和Xeon Phi處理器在partition操作上的對比

Fig. 21 Breakdown of execution time and energy on the hybrid system and Intel Haswell processor圖21 混合系統以及Intel Haswell處理器的執行時間和功耗分解
在圖21(b)中,功耗的分解進一步證明了HPA的優勢.平均來說,HPA功耗只占總功耗的6.2%.同時,在Haswell上實際計算的功耗遠遠高于調用HPA的功耗.平均而言,Haswell計算和調用HPA的功耗比率分別為92.7%和1.1%.
6.3 功耗和面積總結
我們在表6中展示了混合系統的功耗和面積,該系統由HPA,DRAM和主機處理器(Haswell)組成.就面積而言,HPA(由hash、histogram和shuffle unit組成)的總面積僅為Micron的Hybrid Memory Cube (HMC)總尺寸的2.6%.因此,HMC的邏輯層很容易容納HPA.此外,HPA的面積只占由DRAM和CPU組成的整個系統的0.72%.
在功耗方面,HMC只給3D堆疊DRAM增加了7.52 W的功耗,在DRAM中使用HPA的總功耗為28.43W.由于DRAM也被主機處理器(如Haswell)訪問,我們還測量了由Haswell處理器訪問引起的DRAM功耗,相應的DRAM功耗是9.79 W.由于DRAM不能被HPA和Haswell同時訪問,所以DRAM的總功耗不會超過18.64 W.對于主要用來執行build和probe階段Haswell處理器,測得其總功耗為89.75 W.

Table 6 Power and Area Consumption of the Entire System表6 整個系統的功耗和面積消耗
7 相關工作
在本節中,我們列出了針對數據庫操作、算法、應用而使用新型硬件的相關工作.
1) SIMD擴展.在過去10年中,為了加速數據庫的原語,已經廣泛部署SIMD擴展.Zhou等人在文獻[32]中首先用SIMD指令來加速基本的數據庫操作,如索引掃描和嵌套循環聯接.Willhalm等人在文獻[33]中使用向量處理單元在數據掃描中進行解壓縮.Schlegel等人在文獻[34]中使用SIMD支持在Xeon Phi處理器上實現了一個可擴展的頻繁項集挖掘算法.Polychroniou等人在文獻[14]中使用SIMD指令重寫了內存數據庫操作,其中包含掃描、hash、篩選和排序.
2) FPGAs.已經有很多用FPGA加速數據庫查詢操作的工作.比如IBM Netezza,它是一個結合了Xeon服務器和FPGAs的商用系統,可以提高數據庫查詢的性能.Sukhwani等人在文獻[35]中利用FPGA對傳統DBMS進行數據解壓和謂詞評價.Chung等人在文獻[36]中提出了一種框架,將查詢語言LINQ映射到硬件模板,該模板可以由FPGA或ASIC實現.由ARM A9處理器和FPGA組成的SoC系統可以提高30.6倍的能效.
3) GPUs.圖處理單元也被廣泛用于加速通用數據查詢[37]和數據庫操作原語,如索引[38]、排序[39]和連接[40-41].
4) 自定義的邏輯單元.在數據庫領域自定義加速器也被廣泛地使用.Kocberber等人在文獻[42]中為hash索引查找建立了on-chip加速器.Wu等人在文獻[43]中首先提出了一種用于range partitioning的硬件加速器:HARP.為了充分利用HARP的計算能力,他們還提出了一個硬件-軟件流式框架,用于CPU和HARP之間的通信.與他們的工作相比,我們更關注hash分區,并且我們在最先進的hash joins(即PRO)中發現hash分區是內存受限的.因此,將加速過程集成到DRAM中可以使hash分區獲得巨大的收益.為了實現這個目標,我們設計了一個hash分區加速器(HPA),它可以適應3D堆疊DRAM架構.Wu等人在文獻[44]中進一步提出了Q100數據庫處理單元(DPU),以有效地處理數據庫原語,如聚合、連接和排序.
隨著靠近數據的處理技術出現,也有一些將自定義邏輯集成到DRAM中進行數據庫處理的研究.Xi等人在文獻[45]中設計了JAFAR加速器,他們將選擇操作附加到DRAM中,獲得了9倍的加速.Seshadri等人在文獻[46]中提出在DRAM中實現位操作(AND和OR),進而加速各種數據庫操作(例如索引).
8 總 結
盡管3D-die的堆疊技術使得計算單元可以集成到3D堆疊DRAM中,但由于其嚴格的面積、功耗、散熱的限制,使得我們在架構設計時應該謹慎地考慮如何在3D堆疊DRAM中加入最合適的邏輯單元.在本文中,我們以數據移動為驅動,對CPU和DRAM之間的加速任務進行劃分.基于這種方法,我們設計了一種混合加速系統,用于加速數據庫和大數據系統中的基本操作hash joins.該系統包含一個內存端定制的hash分區加速器(HPA)和處理器端的SIMD單元.內存端的加速器用于加速數據移動受限的執行階段,而處理器端SIMD加速單元則用于加速數據移動開銷較低成本的執行階段.實驗結果表明,該系統與Intel Haswell和Xeon Phi處理器相比,僅僅用7.52W額外的功耗,將能效分別提升了47.52和19.81倍.同時我們的設計方法可以很容易地被應用到其他應用程序的加速設計中.
[1]Putnam A,Caulfield A M, Chung E S, et al. A reconfigurable fabric for accelerating large-scale datacenter services[C] //Proc of the 41st Annual Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2014: 13-24
[2]Lim K, Meisner D, Saidi A G, et al. Thin servers with smart pipes: Designing SoC accelerators for Memcached[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 36-47
[3]Qadeer W, Hameed R, Shacham O, et al. Convolution engine: Balancing efficiency & flexibility in specialized computing[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 24-35
[4]Krishna A, Heil T, Lindberg N, et al. Hardware acceleration in the IBM PowerEN processor: Architecture and performance[C] //Proc of the 21st Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2012: 389-400
[5]Zhang D, Jayasena N, Lyashevsky A, et al. TOP-PIM: Throughput-oriented programmable processing in memory[C] //Proc of the 23rd Int Symp on High-performance Parallel and Distributed Computing. New York: ACM, 2014: 85-98
[6]Guo Q, Alachiotis N, Akin B, et al. 3D-stacked memory-side acceleration: Accelerator and system design[C] //Proc of the 2nd Workshop on Near-Data Processing in Conjunction with the 47th IEEE/ACM Int Symp on Microarchitecture. Workshop on Near-data Processing. Piscataway, NJ: IEEE, 2014
[7]Nair R, Antao S, Bertolli C, et al. Active memory cube: A processing-in-memory architecture for exascale systems [J]. IBM Journal of Research and Development, 2015, 59(2/3): No.17
[8]Akin B, Franchetti F, Hoe J C. Data reorganization in memory using 3D-stacked DRAM[C] //Proc of the 42nd Annual Int Symp on Computer Architecture. New York: ACM, 2015: 131-143
[9]Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[J]. USENIX Conf on Networked Systems Design and Implementation, 2012, 70(2): 2-2
[10]Blanas S, Li Y, Patel J M. Design and evaluation of main memory hash join algorithms for multi-core CPUs[C] //Proc of the 2011 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2011: 37-48
[11]Teubner J, Alonso G, Balkesen C, et al. Main-memory hash joins on multi-core CPUs: Tuning to the underlying hardware[C] //Proc of the 2013 IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2013: 362-373
[12]He J, Lu M, He B. Revisiting co-processing for hash joins on the coupled CPU-GPU architecture [J]. VLDB Endowment, 2013, 6(10): 889-900
[13]Jha S, He B, Lu M, et al. Improving main memory hash joins on intel Xeon Phi processors: An experimental approach [J]. VLDB Endowment, 2015, 8(6): 642-653
[14]Polychroniou O, Raghavan A, Ross K A. Rethinking SIMD vectorization for in-memory databases[C] //Proc of the 2015 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2015: 1493-1508
[15]Balkesen C, Teubner J, Alonso G, et al. Main-memory hash joins on modern processor architectures [J]. IEEE Trans on Knowledge & Data Engineering, 2015, 27(7): 1754-1766
[16]Han Xixian, Yang donghua, Li jianzhong. DBCC-Join a novel cache-conscious disk-based join algorithm [J]. Chinese Journal of Computers, 2010, 33(8): 1501-1511 (in Chinese)(韓希先, 楊東華, 李建中. DBCC-Join:一種新的高速緩存敏感的磁盤連接算法[J]. 計算機學報, 2010, 33(8): 1501-1511)
[17]Manegold S, Boncz P, Kersten M. Optimizing main-memory join on modern hardware [J]. IEEE Trans on Knowledge & Data Engineering, 2002, 14(4): 709-730
[18]Balasubramonian R, Chang J, Manning T, et al. Near-data processing: Insights from a micro-46 workshop [J]. IEEE MICRO, 2014, 34(4): 36-42
[19]Elliott D, Snelgrove W, Stumm M. Computational RAM: A memory-SIMD hybrid and its application to DSP[C] //Proc of the IEEE Custom Integrated Circuits Conf. Piscataway, NJ: IEEE, 1992: 30.6.1-30.6.4
[20]Gokhale M, Holmes B, Iobst K. Processing in memory: The terasys massively parallel PIM array [J]. Computer, 1995, 28(4): 23-31
[21]Oskin M, Chong F T, Sherwood T. Active pages: A computation model for intelligent memory[C] //Proc of the Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 1998: 192-203
[22]Loi G L, Agrawal B, Srivastava N, et al. A thermally-aware performance analysis of vertically integrated (3-D) processor-memory hierarchy[C] //Proc of the 43rd Annual Design Automation Conf. New York: ACM, 2006: 991-996
[23]Loh G H. 3D-stacked memory architectures for multi-core processors[C] //Proc of the 35th Annual Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2008: 453-464
[24]Woo D H, Seong N H, Lewis D, et al. An optimized 3D-stacked memory architecture by exploiting excessive, high-density TSV bandwidth[C] //Proc of the 16th IEEE Int Symp on High Performance Computer Architecture. Piscataway, NJ: IEEE, 2010: 1-12
[25]Kim D H, Athikulwongse K, Healy M, et al. 3D-maps: 3D massively parallel processor with stacked memory[C] //Proc of Solid-State Circuits Conf Digest of Technical Papers. ISSCC, 2012: 188-190
[26]Pugsley S H, Jestes J, Zhang H, et al. NDC: Analyzing the impact of 3D-stacked memory+logic devices on mapreduce workloads[C] //Proc of the Int Symp on Performance Analysis of Systems and Software. Piscataway, NJ: IEEE, 2014: 190-200
[27]Low T M, Guo Q, Franchetti F. Optimizing space time adaptive processing through accelerating memory-bounded operations[C] //Proc of IEEE High Performance Extreme Computing Conf. Piscataway, NJ: IEEE, 2015: 1-6
[28]H?hnel M, D?bel B, V?lp M, et al. Measuring energy consumption for short code paths using RAPL [J]. ACM Sigmetrics Performance Evaluation Review, 2012, 40(3): 13-17
[29]McCalpin J D. Memory bandwidth and machine balancein current high performance computers[N]. IEEE Technical Committee on Computer Architecture Newsletter, 1995: 19-25
[30]Kestor G, Gioiosa R, Kerbyson D, et al. Quantifying the energy cost of data movement in scientific applications[C] //Proc of IEEE Int Symp on Workload Characterization. Piscataway, NJ: IEEE, 2013: 56-65
[31]Pandiyan D, Wu C J. Quantifying the energy cost of data movement for emerging smart phone workloads on mobile platforms[C] //Proc of IEEE Int Symp on Workload Characterization. Piscataway, NJ: IEEE, 2014: 171-180
[32]Zhou J, Ross K A. Implementing database operations using SIMD instructions[C] //Proc of the 2002 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2002: 145-156
[33]Willhalm T, Popovici N, Boshmaf Y, et al. SIMD-scan: Ultra fast in-memory table scan using on-chip vector processing units [J]. VLDB Endowment, 2009, 2(1): 385-394
[34]Schlegel B, Karnagel T, Kiefer T, et al. Scalable frequent itemset mining on many-core processors[C] //Proc of the 9th Int Workshop on Data Management on New Hardware. New York: ACM, 2013: 3:1-3:8
[35]Sukhwani B, Min H, Thoennes M, et al. Database analytics acceleration using FPGAs[C] //Proc of the 21st Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2012: 411-420
[36]Chung E S, Davis J D, Lee J. Linqits: Big data on little clients[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 261-272
[37]Bakkum P, Skadron K. Accelerating SQL database operations on a GPU with CUDA[C] //Proc of the 3rd Workshop on General-Purpose Computation on Graphics Processing Units. New York: ACM, 2010: 94-103
[38]Kim C, Chhugani J, Satish N, et al. Fast: Fast architecture sensitive tree search on modern CPUs and GPUs[C] //Proc of the 2010 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 339-350
[39]Satish N, Kim C, Chhugani J, et al. Fast sort on CPUs and GPUs: A case for bandwidth oblivious SIMD sort[C] //Proc of the 2010 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 351-362
[40]Pirk H, Manegold S, Kersten M L. Accelerating foreign-key joins using asymmetric memory channels[C] //Proc of Int Workshop on Accelerating Data Management Systems Using Modern Processor and Storage Architectures. New York: ACM, 2011: 27-35
[41]Kaldewey T, Lohman G, Mueller R, et al. GPU join processing revisited[C] //Proc of the 8th Int Workshop on Data Management on New Hardware. New York: ACM, 2012: 55-62
[42]Kocberber O, Grot B, Picorel J, et al. Meet the walkers: Accelerating index traversals for in-memory databases[C] //Proc of the 46th Annual IEEE/ACM Int Symp on Microarchitecture. New York: ACM, 2013: 468-479
[43]Wu L, Barker R J, Kim M A, et al. Navigating big datawith high-throughput, energy-efficient data partitioning[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 249-260
[44]Wu L, Lottarini A, Paine T K, et al. Q100: The architecture and design of a database processing unit[C] //Proc of the 19th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2014: 255-268
[45]Xi S L, Babarinsa O, Athanassoulis M, et al. Beyond the wall: Near-data processing for databases[C] //Proc of the Int Workshop on Data Management on New Hardware. New York: ACM, 2015: 2-2
[46]Seshadri V, Hsieh K, Boroumand A, et al. Fast bulk bitwise AND and OR in DRAM [J]. IEEE Computer Architecture Letters, 2015, 14(2): 127-131
