基于Multi-GPU平臺的大規模圖數據處理
2018-03-13 05:00:00張立波武延軍
計算機研究與發展 2018年2期
關鍵詞:優化
張 珩 張立波 武延軍
1(中國科學院軟件研究所 北京 100190)2(中國科學院大學 北京 100049)(zhangheng@nfs.iscas.ac.cn)
隨著單指令集多數據流(single instruction multiple data, SIMD)并行架構的流行,采用Multi-GPU架構的服務器節點來支持高性能計算已成為趨勢熱點.這類服務器節點通常由若干Host處理器(CPUs)和多個GPU設備組成,各設備間通過通信總線互聯(PCI-E總線或NVLink傳輸線),如圖1所示.這樣的架構相比單顆GPU服務器提供了更大規模的協處理器并行硬件環境和內存傳輸帶寬,從而帶來更高效的大規模數據聚合處理能力.
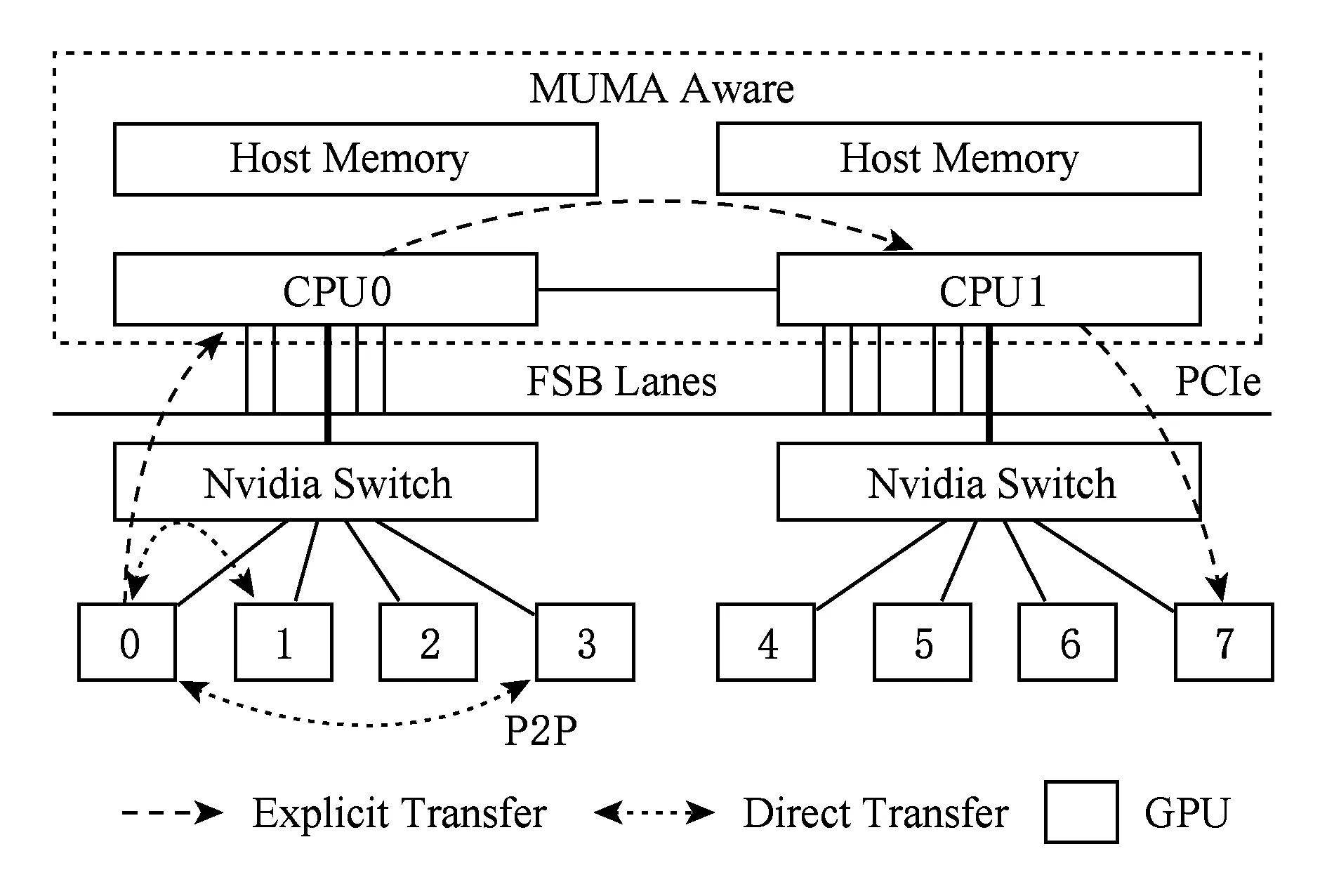
Fig. 1 The architecture of Multi-GPU platforms圖1 Multi-GPU平臺的硬件架構
近年來采用GPU服務器平臺對大規模圖數據進行處理已經日益成為研究熱點[1-2],提出了大量的算法優化和在GPU服務器上的圖數據處理系統設計,例如CuSha[3],MapGraph[4]和GunRock[5]等.根據所能支持圖數據的處理規模,我們將這類GPU圖數據處理系統分為了2個通用的類別:GPU設備訪存圖處理和外存(out-of-core)圖數據處理方案.其中,訪存內圖處理系統類研究工作集中于GPU線程的并行優化策略來提升存儲在設備訪存內的不規則的圖數據結構的訪問和計算性能,最大限度地挖掘GPU線程組的并行處理能力.另外,其他研究提出了在單節點上支持基于外存IO的大規模圖數據的處理,這類系統突破了GPU訪存大小的限制,通過利用圖數據切分策略,迭代式加載至GPU設備訪存,完成處理后利用主存和持久化存儲設備進行全局同步.GraphReduce[6]是第1個提出基于外存IO進行GPU下大規模圖數據計算的系統,其對圖數據采用混合型的稀疏矩陣壓縮CSR(compressed sparse row)和CSC(compressed sparse column)表示方式以降低迭代過程中隨機訪問開銷,進而對原圖數據進行均衡切分后,逐個加載分塊至設備內存處理.
然而,GraphReduce只支持單個GPU下的并行處理,這類基于外存IO的GPU下圖數據處理的系統在擴展到Multi-GPU平臺下仍然存在著挑戰:1)如何進行均衡的圖數據切分,以適用于Multi-GPU下各層級的內存存儲;2)在多個GPU和CPU之間進行協同處理過程中,如何有效地利用局限的傳輸帶寬(PCI-E)進行數據傳輸.
為了解決上述挑戰,本文對基于Multi-GPU平臺下的外存圖數據并行處理系統提出了優化策略,在以存儲順序IO優化前提下,將圖數據的屬性數據集合(節點狀態數據集,點邊權重數據集)先緩存于各GPU的設備訪存,后對圖分塊逐個順序傳輸至各GPU處理后同步.本文進一步設計并實現了GFlow,在Multi-GPU平臺上支持高效、可擴展的大規模圖數據處理系統.本文在GFlow系統中主要提出了2點優化策略:適用于Multi-GPU下的圖數據Grid切分策略和雙層滑動窗口算法.具體地,GFlow在對大規模圖數據進行Grid切分后,逐層從磁盤存儲加載至GPU設備內存,并針對同步過程中的隨機內存訪問開銷設計了Ring Buffer數據結構用以提升對各GPU并行處理過程所生成的Update消息數據集聚合傳輸和節點更新.
本文主要的創新和貢獻點有如下3點:
1) 提出了一種適用于Multi-GPU平臺圖數據Grid切分策略,在采用最大化存儲順序IO的Streaming圖切分的基礎上,根據主存、各GPU設備存儲的資源大小構建列分塊(strip-shard)和格分塊(grid-shard),優化PCI-E的IO傳輸的順序數據塊傳輸和各GPU之間的負載均衡;
2) 設計了雙層滑動窗口并行化數據傳輸和處理策略(2-level streaming window),動態地加載數據分塊從SSD存儲至GPU設備內存,并順序化聚合并應用處理過程中各GPU所生成的Updates;
3) 通過在4個圖基準算法和9個真實圖數據集上的實驗驗證,GFlow性能表現對比CPU下的GraphChi和X-Stream分別提升25.6X和20.3X,對比GPU下的GraphReduce單個GPU下提升1.3~2.5X,且可擴展性達到3.8~5.8X(6個GPU配置).
1 相關工作
隨著單指令流多數據流并行架構(SIMD)的流行,利用超大規模核處理器GPU處理單元(graphical processing unit)的高性能節點進行大規模圖數據的處理越來越為研究者們所關注.現實的圖數據具有規模巨大、增量迅速且數據表征差異多樣化的特點,在利用GPU對大規模圖數據進行處理過程中,需要考慮到各方面的并行計算因素,如圖結構數據的切分與遍歷策略、圖數據異構多線程并發的負載均衡以及圖數據的存儲和IO方式等.現階段,這類研究工作主要集中于圖數據處理的基本算法與系統類的研究.
在GPU加速的圖算法優化中,主流高性能領域的標準測試集Graph500[7]采用廣度優先遍歷算法(breadth first search, BFS)對高性能計算節點和集群以及并行算法的性能與能耗進行評估,因此利用GPU對BFS算法的高并行加速的研究日益成為熱點.其中,You等人[8]提出將自頂向下和自底向上的圖遍歷訪問方法綜合考量,根據遍歷算法的收斂程度動態選擇訪問方法,優化GPU線程對異構圖數據遍歷.Merrill等人[9]提出針對GPU下BFS遍歷的核心操作前綴求和(prefix sum)算法進行任務的細粒度化優化,降低多線程的訪問沖突,其遍歷性能達到單NVidia Tesla K40 GPU上33億條邊秒的TEPS訪問速度.Hong等人[10]提出了虛擬Warp(GPU的邏輯線程組并行執行單元)為中心編程的思想,對GPU的BFS 等圖算法并發執行過程中的負載不均衡和邏輯運算單元(arithmetic logic unit, ALU)負載過載問題進行優化.Liu等人[11]根據遍歷過程中的活躍節點集Frontier對GPU下的BFS算法提出3點優化:對GPU執行線程流水線化降低多線程競爭、根據點的出度情況調整動態負載來達到并行化負載均衡、GPU下的 BFS 遍歷方向優化.本文所設計的GFlow大規模圖數據處理方法,主要針對Multi-GPU平臺的大規模圖數據進行數據傳輸、并行計算方面優化.GFlow在設計的過程中借鑒了上述的GPU下的算法優化策略,如虛擬Warp線程組調度計算以及圖數據遍歷動態策略等.
另一方面,現有的大量研究工作開始轉向GPU平臺下圖處理的系統級設計[3-4,12-13],為圖算法方便實現提供簡化的編程接口API,支持各類圖算法的GPU并行執行.在這類系統性的工作中,Medusa系統[12]第1次提出并設計實現了用于GPU平臺的圖計算簡化編程系統,其提出了在CUDAC++編程框架基礎上簡化圖的GPU編程API接口,底層采用BSP(bulk-synchronous parallel)并行模型對GPU的大規模線程并發執行細節隱藏,從而簡化GPU下的圖算法編程實現.CuSha系統[3]著重對高稀疏性自然圖的切分及處理訪問方式進行性能提升,在塊切分基礎上對圖數據按照起點-終點索引、節點權重、邊權重進行數據分塊組織,構建連續窗口圖處理達到動態的調整各處理間隔的大小.Gunrock[5]進一步優化了GPU下的高性能圖處理接口,重構圖處理原語,提供Advance-Filter-Computation三個操作來分別進行節點訪問、過濾和計算的處理.為了在有限的單GPU訪存空間上支持更大規模的圖數據的處理,GraphReduce[6]第1次提出單GPU節點的外存下的圖數據處理,在規模無法存儲于GPU訪存的大圖數據采用固定大小切塊切分,并在GPU設備訪存與Host內存之間設計優化了異步傳輸與迭代計算.
本文工作在GraphReduce基礎上進行設計和實現GFlow圖數據處理系統,提升可擴展性利用Multi-GPU平臺以支持基于外存IO的大規模圖數據的并行計算模型,主要在2個方面設計了優化策略:圖數據的切分分塊以及各GPU在并行計算過程中的數據傳輸和結果集計算同步機制.相對比上述相關的研究系統,本文所設計實現的GFlow系統充分利用Multi-GPU節點的大規模并行環境的計算資源進行算法并行處理,在有限帶寬PCI-E總線資源下降低圖數據的同步和傳輸開銷.同時,GFlow沿用了傳統的GAS(Gather-Apply-Scatter)[14]的圖數據并行編程模型,并提供大規模圖數據的切分、存儲、傳輸和計算,支持各類圖計算的算法的GPU實現.
2 基于GPU下外存I/O的圖數據并行處理
在本節中,我們主要介紹針對面向單GPU下的圖結構上的方法應用.首先,對圖數據在GPU下迭代處理過程中的表現形式進行了描述,主要分為3個數組部分進行存儲,包括CSRCSC稀疏矩陣壓縮結構格式、應用定義數據以及節點狀態數據.其次,本文工作對單GPU下基于外存IO優化的大規模圖數據計算系統的執行流程進行了簡要描述.通過沿用傳統的以點為中心的并行計算GAS(gather-apply-scatter)模型[14],在對原始圖數據切塊后順序逐一載入GPU設備訪存處理后,進行節點更新結果集同步.
2.1 圖數據在GPU環境下的數據結構形式
考慮到GPU設備訪存的資源有限性,基于GPU的大規模圖數據處理研究工作沿用以CSR或CSC矩陣壓縮的表現形式對大規模圖數據進行格式化,降低了稀疏性圖數據的存儲開銷.在圖數據進行迭代化并行處理的過程中,主要分為如圖2所示的3種類型數據:
1) 圖數據的結構數據(topology data, TD).以CSR壓縮的格式數據由各點的出邊的索引數組(OutEdgeIdxs)和出邊的值數據(OutEdgeIndex)構成.
2) 應用數據(application data, AD).存儲圖的各節點的當前值的數組,根據不同的算法和應用對數據定義.
3) 狀態數據(state data, SD).標記了圖中各節點在當前迭代輪的狀態(0或1);標記為1表示節點狀態活躍參與下一個迭代輪計算,標記為0則不參與計算.狀態位的標記能夠有效降低圖數據并行化處理的無用計算.
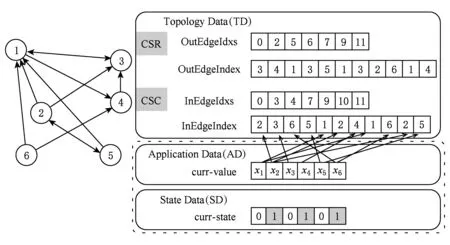
Fig. 2 Graph representation of CSRCSC based compression圖2 以CSRCSC格式為例的圖數據表現形式
2.2 單GPU外存計算的圖處理系統執行流程
在第1節中,現有的GPU下的大規模圖數據處理系統主要分為2類:訪存內(in-memory)計算系統和外存(out-of-core)計算系統.隨著圖數據規模的增大,基于GPU訪存內計算系統的執行受GPU設備訪存大小的限制,而導致無法應對更大規模的圖數據的并行處理.GraphReduce[6]系統第1次設計并支持了基于外存的單GPU下大規模圖數據的并行處理.本文所設計的GFlow沿用GraphReduce的設計原則,進一步優化提出Multi-GPU下的圖數據IO優化策略方案.本節對單GPU下支持外存圖數據處理的執行流程進行了簡要的歸納和總結,如圖3所示.通過采用分布式圖處理引擎PowerGraph[14]所設計的點為中心的GAS并行處理模型,GPU下外存圖數據處理主要分為4個主要處理階段,包括初始化數據加載、Gather階段、Apply階段和Scatter階段.
1) 第1階段(初始化數據加載,圖3中1a和1b階段).原始圖轉換為以CSR和CSC混合表示的圖模型,并將邊集切分為包含相等邊數的分塊Shard(入邊+出邊數量),進一步將各邊集分塊Shard以及對應的AD、SD數據塊加載至主存空間;
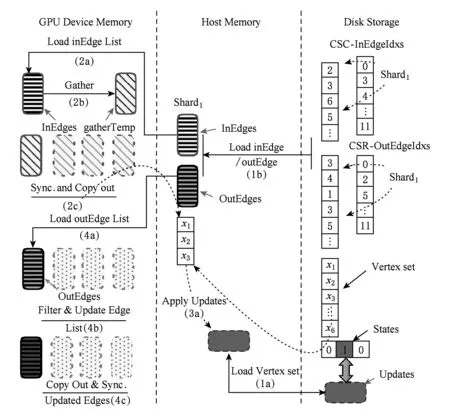
Fig. 3 Execution flow for large graph in single GPU圖3 單GPU下大規模圖數據處理流程
① https://sparse.tamu.edu/DIMACS10/coAuthorDBLP
② https://sparse.tamu.edu/Williams/webbase-1M
③ https://sparse.tamu.edu/SNAP/roadNet-CA
2) 第2階段(Gather,圖3中2a、2b和2c階段).逐個將包含in-edge(入邊)分塊Shard加載至GPU訪存后,對當前的對應活躍點集遍歷獲取對應的節點值,對所加載邊集執行用戶自定義gather.在對各個in-edge分塊處理完畢同步后,獲取本地化的gather操作結果更新(節點權值邊值)集合;并進一步拷貝更新集合值內存;
3) 第3階段(Apply,圖3中3a階段).對所聚合的局部updates集合執行apply操作,對磁盤存儲的全局updates數組的對應項進行更新并標記相應節點狀態位.
4) 第4階段(Scatter,圖3中4a,4b和4c階段).在逐一拷貝out-edge(出邊)分塊Shard以及所對應更新的節點值集合至GPU訪存后,執行scatter用戶自定義函數對邊集及其終點狀態進行更新.
其中,值得注意的是,在做邊集分塊Shard的過程中,分塊大小的確定以各分塊能夠完整存儲于GPU的設備訪存為準.另外,為了避免不必要的memcpy操作和kernel初始化開銷,我們采用了對活動點集進行動態記錄的策略,即首先調用CUDA指令any()探測在第1階段計算過程中是否存在活動節點需要傳輸,然后在warp線程組內和組外逐步規約(binary reduction)來獲取活躍節點集合.
3 支持Multi-GPU平臺的大規模圖數據處理
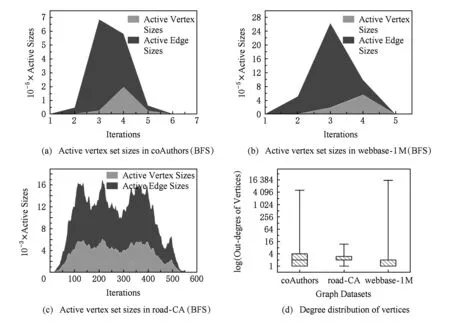
Fig. 4 Different representations for three graphs圖4 3個圖數據(coAuthor,webbase和road-CA)的不同特征
大規模圖數據的類型多樣化,包括社交網絡數據、路網數據、協作者網絡數據以及大量的Internet網頁鏈接數據等.這類現實中的復雜網絡所構建的圖數據類型特征各不相同,我們采用實驗中的數據對這類圖數據進行了特征分析.其中coAuthor①為論文合作者網絡,webbase②為網頁鏈接數據,road-CA③為路網數據.從圖4(a)~(c)中,各圖數據在進行BFS廣度優先遍歷過程中各輪迭代過程中參與計算的活躍點集數量不盡相同,同時迭代輪次數差距也較大,如coAuthors和webbase在5~6輪迭代之后完成,而road-CA路網半徑較大導致需要至少520輪迭代計算.進一步,我們對3個圖的各節點出度情況進行統計,從圖4(d)中可見,road-CA路網數據相比來看出度更為集中,大量節點的出度在2~4之間,這也反映了道路交通網絡的節點度均勻特征.
在構建圖數據處理系統過程中,為了支持多樣化的圖數據類型和各類圖數據算法,在設計上需要著重考慮如下2個方面的因素:大規模圖數據的均勻切分和圖數據的并行處理.首先,為了Multi-GPU環境下的各設備的計算負載均衡,對多樣化大規模圖數據的均衡切分能夠有效降低圖數據并行處理過程中straggler開銷問題;其次,在并行處理方面,GPU的外存數據傳輸開銷往往占用大量運行時時間,因此在并行化的數據傳輸和計算過程中,采取重疊式輪轉調度和異步式的數據傳輸能夠大幅降低外存數據的傳輸與同步開銷.
本節對GFlow支持Multi-GPU平臺的大規模圖數據的處理機制進行了詳細描述,主要在圖數據集均衡切分和基于窗口的異步并行處理2個方面提出了優化與改進.
3.1 GFlow系統設計思想和執行流程
在GPU服務器節點上,GPU的各層級內存由用于Warp單元間和線程塊間的數據通信的共享內存(shared memory,L1 cache)和用于所有SMX(streaming multiprocessor)的全局內存(global memory)以及少量的L2 Cache緩存構成,而CPU端以主存為主.在進行Multi-GPU平臺下的圖數據處理系統構建時規劃了各層內存的數據結構存儲如下所示(以Nvidia GTX 980型號GPU為例):
1) 共享內存(shard memory).48 KB,用于存儲各節點的狀態數組和各SMX本地節點分塊集合的應用執行結果集;
2) 全局內存(global memory).4 GB,用于存儲分塊圖結構數據集(Shard),包括點、邊數據,以及部分用作緩存(Buffer)存儲臨時結果集合.
3) Host主存(main memory).64 GB,用于存儲部分圖結構分塊數據集合,以及對應的AD應用數據和SD節點狀態數據集.
GFlow系統沿用GAS并行模型設計的思路,提供用戶GatherApplyScatter接口函數以實現并行圖算法.算法1~3分別給出了PageRank算法采用GatherApplyScatter函數的各自實現,其中,預定義邊數據結構體ED(PageRank的邊無權值)和點數據結構體VD包含節點權值rank和出邊數值numOutEdges.GFlow系統總體的流程分為4個階段:輸入(Input)、核心執行(Core)、結果集合并(Merge)以及輸出(Output).圖5給出了GFlow的整體執行流程示意圖.
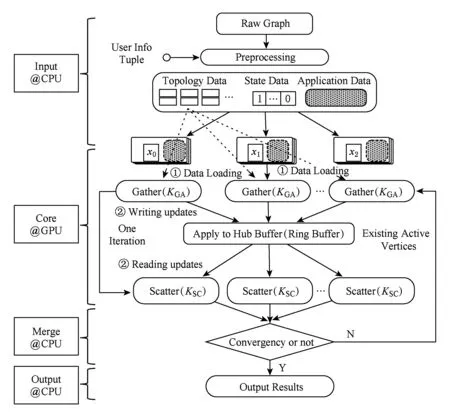
Fig. 5 Execution flow in GFlow of multi-GPU圖5 Multi-GPU下GFlow的執行流程示意圖
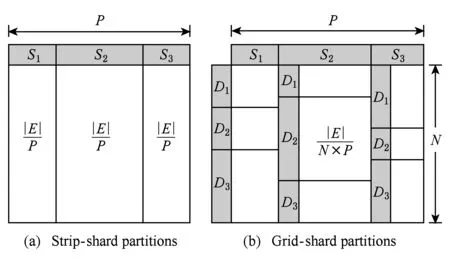
為了解決大規模圖數據集無法完整存儲于GPU設備內存的問題,本文采用了一種基于Grid切分策略對2.2節所提及的圖分塊(Shard)進行優化改進,主要設計目的在于以最大化PCI-E的IO傳輸的順序數據塊傳輸,優化各GPU之間的負載均衡同時保證了圖數據的預處理的高效.進一步,將各分塊對應的節點狀態位數組信息SD和應用數據AD共同進行封裝,以整體數據塊形式來進行數據傳輸拷貝(memcpy).所設計的圖數據Grid切分策略詳細流程如3.2節所述.
算法1. GFlow中PageRank的Gather函數KGA.
輸入:邊的起點數據Du、終點數據Dv、邊數據D(u,v);
輸出:邊的終點數據的累加更新.

算法2. GFlow中PageRank的Apply函數KAP.
輸入:當前節點數據Dv、累加聚合結果gather-Result;
輸出:更新后Dv的權值.
①α=0.85f; /*定義阻尼系數*/
②new_pr=1-α+α×gatherResult;
③ 更新Dv的權值rank=new_pr.
算法3. GFlow中PageRank的Scatter函數KSC.
輸入:節點更新數據Dv、邊數據D(u,v);
輸出:節點Dv的活躍狀態.
①THRESHOLD=0.01f;
/*定義節點活躍狀態閾值*/
② 計算Dv當前權值與原權值的絕對差值Δrank;
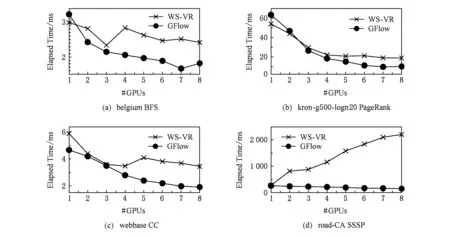
③ IF Δrank ④ return false; ⑤ ELSE ⑥ return true. 在CPU進行預處理過程之前,各個GPU設備各自分配初始化內存Buffer用于保存TD Buffer、SD Buffer、當前和生成的AD Buffer.接收Shard塊傳輸之后,各GPU設備并行化執行GAS并行計算模型.其中,KGA函數和KSC函數分別為用戶自定義實現的GPU的Kernel函數Gather和Scatter.在Gather執行完成后,GFlow分配全局的Hub Buffer保存各GPU節點生成的更新集合(updates),在計算完成對應的節點或邊的更新權值之后組裝成數據塊分配至對應的GPU設備.此過程中,為了降低數據IO傳輸和更新的同步開銷,GFlow著重對2個階段的數據傳輸進行了優化,如圖5所示的數據加載階段(data loading)和各GPU之間并行執行所生成的Updates的讀寫操作(writingreading updates).GFlow提出并設計了雙層數據讀寫滑動窗口對數據傳輸和并行計算階段進行階段,具體的實現細節介紹見3.3節. 在各GPU Kernel執行完畢之后,根據所生成的Updates集合對圖數據的節點SD狀態集標記,在Host Memory中更新合并,整體流程的迭代計算的收斂判斷是否還存在活躍點集或者達到指定的迭代次數. 為了滿足Multi-GPU下的各種類型不同的圖數據的處理需求,GFlow提出并設計了一種適配多層級內存資源的Grid切分策略.現有CPU下外存圖切分策略的研究[15-18]利用磁盤的順序讀取的高效性原理,在引入一定圖切分的預處理開銷下采取更為均衡和高效的圖數據順序化分塊存儲.GFlow借鑒其中Grid切分的思想[19],在對設備的內存層級資源探測后,構建適用于各層級內存存儲的數據結構.具體地,GFlow構建了2層數據分塊:列分塊(strip-shard)和格分塊(grid-shard). Fig. 6 Balanced grid-based graph partition in GFlow圖6 GFlow的均衡Grid圖切分 1) 列分塊.存儲于host memory大小,采用Streaming切分策略順序讀取所有節點的出邊集合,按照各節點的ID范圍Sn來分配,切分原則為各strip-shard的范圍S內的邊集大小相當. 2) 格分塊.用于GPU的設備內存計算,切分準則采用各個grid-shard所包含的邊個數相當.在對strip-shard進行二次切分為多個grid-shard,在綜合考慮各個節點的活躍狀態,各grid-shard在各迭代輪之間進行合理地調整,以對各GPU的負載進行均衡分布. 具體地,對邊集中的各條邊分別按照其起點和終點的范圍進行組織,這樣能夠在引入一定預處理開銷(O(|E|))的前提下獲取合理負載均衡的分塊.GFlow設計的切分算法在順序化磁盤讀取邊之后即可將各邊分配切分完成,因此其相對比其他外存系統(GraphReduce)能夠大幅度降低引入的預處理開銷.我們對基于Grid的圖分塊視圖采用了CSRCSC格式的節點的2個邊索引數組in-EdgeIdxs和out-EdgeIdxs進行圖數據的切分策略實現.根據各圖的CSR存儲,GFlow通過out-EdgeIdxs數組獲取各節點的度數組(d1,d2,…,dn).進而通過獲取節點上host memory,share memory和global memory的資源大小(分別標記為Mh,Ms,Mg),GFlow根據各節點的ID(i)和節點出度di來進行strip-shard和grid-shard的切分.GFlow在滿足各切分塊的對應AD和SD數據和各grid-shard分塊的邊集能夠存儲入全局內存中,沒有限制切分塊的數量.進一步,我們也采用了更為直接的策略對切分塊的數量進行了定義:給定GPU設備數量為N,主存、單個設備全局內存的大小分別為Mh,Mg,以及單個節點、邊的應用和狀態數據的大小均為U、節點ID大小B和點集和邊集數量|V|,|E|,則所切分的節點區間S的個數P為滿足strip-shard節點區間和對應grid-shard邊集合的存儲條件的最小整數中的較大者: 進一步,為了降低各shard內節點的索引查詢的開銷,我們對各點集范圍S內的節點采用連續存儲,只保存了第1個節點的偏移量(offset),將節點的狀態和屬性數據進行連續存儲.這樣有效地利用了CSRCSC存儲格式提升空間利用率. 不同于傳統的2-D的圖切分策略[19-20],GFlow適用于GPU節點多層級內存存儲,能夠最大限度提高各層級內存的存儲利用率和執行效率.另外,圖7給出了grid切分后順序讀寫過程.其中,在對同一strip-shard內的grid-shard執行過程中能夠對內部各分塊的起點范圍內的節點集Si的各節點的狀態和權值復用,而不需要頻繁對節點子集在內存緩存和磁盤間的換入換出,降低了不必要的數據讀寫開銷. Fig. 8 Experimental analysis in data movement strategies supported in Multi-GPU platform圖8 Multi-GPU下數據傳輸策略分析 在Multi-GPU平臺下,數據的傳輸在Host和各GPU之間可以通過H2D,D2H的CUDA接口定義進行數據拷貝(memcpy);而GPU與GPU設備之間的數據的交換和傳輸的方式能夠通過顯性傳輸定義(explicit transfer)和直接傳輸(GPUDirect)[21-23].為了進一步分析外存圖計算系統在Multi-GPU平臺下能夠高效地進行數據傳輸,我們對CUDA編程接口的2個技術進行分析:1) 采用cudaMemcpy接口和H2DD2H方式的顯性數據傳輸定義;2)由GPU硬件支持的統一虛擬地址技術(unified virtual addressing, UVA)所提供的GPUDirect直接數據傳輸.圖8中顯示采用顯性數據傳輸定義接口能夠先比UVA支持的GPUDirect策略能夠提升5~6倍的數據傳輸帶寬,同時Pinned分配的塊內存傳輸相比頁式內存更為高效.盡管UVA特性能夠對GPU之間的數據傳輸的細節隱藏,但是其由于支持直接內存地址傳輸帶來大量數據一致性訪問所需加鎖的開銷.因此,我們在設計GFlow的數據傳輸策略時,盡量考慮采用Pinned后內存數據塊的顯性數據傳輸策略,這樣也能在數據預取和GPU合并內存數據塊并行處理方面取得性能優勢. 在數據傳輸和計算執行過程中,GFlow將grid-shard數據塊與相對應的屬性數據(AD和SD)進行合并為結構化文件塊,通過PCI-E總線分配至各GPU設備內存.考慮到PCI-E數據傳輸效率遠低于GPU全局內存讀寫效率,因此本文提出并設計了基于順序塊IO的異步雙層滑動傳輸和計算窗口(2-level streaming windows),主要對GFlow執行過程中的2個方面的執行效率如圖5所示的數據加載階段(data loading)和各GPU之間并行執行所生成的中間結果集的讀寫操作(writingreading updates)階段優化設計. 首先,在①數據加載(data loading)階段,為了對磁盤存儲中的數據塊組織,我們構建了tile-window對strip-shard進行管理.每一個tile-window的大小由Host主存大小決定,通常我們設定內存閾值δ來對總體主存的使用率進行設置(默認δ=0.8),因此在tile-window滑動數據加載和執行過程中,GFlow按照Z折線順序化(zigzag order)逐列讀取每個strip-shard. 其次,GFlow在主存中構建stream-window的第2層文件讀寫窗口對strip-shard內的Grid結構進行分塊索引獲取.stream-window窗口主要對grid-shard和對應的屬性數據分塊加載到GPU設備和管理每輪迭代計算過程各GPU中的中間結果集(on-the-fly).具體地,stream-window的窗口大小由多個grid-shard組成,各GPU內設備總內存所決定,并根據各grid-shard的節點狀態數組(SD)調整所含大小邊集.進一步,GFlow以stream-window為單位對各GPU所生成的本地更新值(AD)存儲并進行同步至Host內存. 最后,在②中間結果集(updates)的讀寫操作階段,各GPU并行地執行生成updates的分配和讀寫,考慮到各GPU所生成的updates消息的稀疏性,GFlow采用Hub Buffer機制來對各update消息組進行緩存和同步.Hub Buffer中,update的消息數量相對巨大(O(|E|))且各GPU生成的每個部分在拷貝至Hub Buffer的數量大小不盡相同(如圖4所示活躍點集所決定).我們采用了一種固定大小、靜態分配的數據結構進行Hub Buffer的構建,即Ring Buffer.Ring Buffer數據結構能夠有效避免動態內存分配的開銷并為在處理單個stream-window中數據塊所生成的update消息提供高效的索引結構.具體地,Ring Buffer由一個大小為η的索引環數組(index ring array)和索引所指向的數據塊數組(block array)組成,η取決于stream-windows中grid-shard數量.索引環數組的每個項由3個指針組成,分別指向stream-window中的grid-shard以及其所對應的保存在數據塊數組(block array)中的AD和生成的update消息集合.每個數據塊數組(block array)采用固定大小頁對齊的文件塊組成(默認64 MB),一旦一個block填滿即可分配新的block.采用Ring Buffer,數據通過PCI-E鏈路傳輸能夠連續傳輸,大幅度提升了所生成的update的讀寫傳遞效率. 我們對本文策略在GPU環境下進行實現,使用Nvidia GPU的CUDA CC++環境進行算法實現,在實現過程中利用CUDA Stream Object特性對數據從Host到Device之間的傳輸和Kernel Function的執行流程上進行優化,盡量降低了數據傳輸所帶來的開銷,如圖9所示流程.進一步,GPU內線程組(warp)的各線程根據各節點的狀態進行執行,一旦SD獲取的vid對應的狀態為inactive,該線程則不需要進行處理,繼續獲取SD中的active的節點進行下一步處理,從而有效降低了GPU的空閑率.通過對GPU的優化實現,本文所實現的方法極大提高了大規模圖數據的處理性能和高并發的可擴展性,能夠支持大規模圖結構數據集的處理. Fig. 9 Asynchronized data movement and processing phases in GFlow圖9 GFlow的異步讀寫與并行處理步驟 算法4給出了GFlow的并行化執行流程.GFlow在將子圖分塊strip-shard的屬性數據(點的狀態數據SD,點邊權重數據AD)緩存于各GPU設備后,在啟動Stream滑動窗口進行圖的拓撲結構化數據(點邊集合)至各GPU,進而執行用戶Kernel函數,得到迭代計算結果.具體地,初始化的GPU設備緩沖區OVBuf,UVBuf,SDBuf分別保存原節點權值、更新節點權值以及節點狀態.tile_window載入strip-shard至主存中,并對標記為未執行的子圖塊初始化權值和狀態集合,構建點與分塊索引v2sMap和s2vMap(行④~⑩).進而stream_window讀取N個grid-shard載入各GPU訪存,執行KGA,KAP,KSC對邊集處理得到節點的權值聚合后更新寫入UVBuf, 狀態寫入SDBuf(行~).最后對各GPU設備的緩存導出,并同步更新各節點的最終應用權值和狀態值. 在該執行過程中,我們采用了CTA(coopera-tive thread array)的線程組管理(Modern GPU函數庫提供)[10,21].通過借鑒Virtual Warp[10]所設計的單個warp,在加載完成grid-shard后,我們將利用Share Memory緩存對應的SD數據,單個warp中的各線程對單個節點所有出邊進行同時處理.具體地,在對warp和內部線程的offset進行計算后,在遍歷到需要處理的節點時即分配warp對該節點的出邊進行線程處理,此外對各節點的聚合更新加入原子性操作(AtomicAdd),各線程處理完畢后采用__threadfence_block()對同一warp內線程同步. 在數據傳輸過程中,我們利用GPU CUDA Stream Object的特性對數據傳輸和各GPU之間的計算的重疊以提高并行效率的細節實現.該特性提供了一個GPU的操作隊列,使用Stream Object實現了任務級的并行,CUDA的運行時庫提供GPU在執行Kernel函數的同時,在Host Memory和Device Memory之間交換數據.在創建若干個Stream的對象管理GPU1:N的計算和Shard的傳輸后,傳入各Stream對象至調用Kernel函數和cudaMemcpyAsync.Stream根據程序的任務執行情況提供運行時優化,來維護該GPU的操作隊列的先后順序. 算法4. GFlow異步Multi-GPU并行處理主流程. 輸入:圖數據G=(V,E);KGA,KSC,KAP分別表示用戶自定義的Gather,Scatter和Apply函數. ① 為設備GPU1:N全局內存中device memory中分別分配EDBuf,OVBuf,UVBuf,SDBuf; ② 調用函數cudaMemcpyFromSymbol轉換KGA,KSC,KAP三個Kernel函數標記; ③ while active vertices exist do ④ fortile_window=next strip-shard IDi fromG ⑤ iftile_window標記為已處理 then ⑥ 根據起點狀態集合SDi過濾edges; ⑦ else ⑧ 獲取起點范圍Si權值ADi、狀態集合SDi; ⑨ 起點狀態集合SDi過濾edges; ⑩ end if 子圖; UVBuf; GPUj; UVBuf; stream_window; 在本節中,我們使用本文構建的基于Multi-GPU平臺的大規模圖數據處理系統GFlow,采用9個公開的現實數據集(如表1所示)進行了對比實驗,并且通過性能和GPU上執行情況衡量了算法的高效性和可擴展性. Table 1 The Evaluation Datasets表1 用于實驗驗證的網絡數據集 實驗環境采用8塊NVIDIA GTX 980 GPU工作站上完成測試,服務器配置2顆10核的Intel Xeon E5-2650 v3的CPU和64 GB大小的GDDR5內存,存儲為512 GB PCI-E的SSD硬盤RAID-0配置.考慮到X-Stream和GraphChi采用Direct IO讀寫數據,在實驗過程中,我們對讀寫過程中采用配置DirectIO避免內存頁緩存.操作系統采用Ubuntu 16.04(內核版本v4.4.0-38),配置版本v7.5的CUDA環境.所有的程序編譯采用-O3標志,配置目標GPU硬件的streaming多處理器生成器. 為了與現有的大規模圖數據處理系統作對比,我們選取了2類系統:1)支持CPU下外存圖計算的系統,其中最為廣泛應用的GraphChi[15](https:github.comGraphChigraphchi-cpp)和X-Stream[17](https:github.comepfl-labosx-stream);2)支持GPU的大規模圖數據計算的系統,此類系統中選擇了最新的支持外存圖數據計算的單GPU下的系統GraphReduce[6]和支持Multi-GPU下內存內計算的圖數據處理系統WS-VR[22]. 另外,在基準算法測試方面,我們采用了廣泛認可的PageRank[24]、廣度優先遍歷算法(BFS)、單源最短路徑算法(single source shortest path, SSSP)以及聯通子圖算法(CC). 下面我們分3個部分進行實驗的對比: 1) 對比常用的CPU下的外存計算系統Graph-Chi和X-Stream和支持單GPU下的外存圖數據處理系統GraphReduce; 2) 對比支持Multi-GPU平臺的圖數據處理系統WS-VR; 3) 對GFlow所設計的策略在Multi-GPU下的可擴展性進行驗證. 為了對GFlow在Multi-GPU平臺上的性能與可擴展性的驗證,本文在9個真實的網絡數據集(數據集來源http:snap.stanford.edudata)進行測試,其中,coAuthorsDBLP,belgium osm,kron-g500-logn20,amazon,road-CA和webbase-1M用于測試小規模的內存內圖數據的計算;其他3個圖kron-g500-logn21,uk-2002和twitter用于測試外存存儲圖數據的計算.這9個數據集合具備各自不同的特征,其中包括有社交網絡數據集、路網數據集、商品關聯數據集以及網頁鏈接數據集.例如,coAuthorsDBLP,twitter表述了社交網絡內的用戶的交互行為(協作、相互關注等);webbase-1M,uk-2002為網頁鏈接數據集;amazon代表了亞馬遜內的商品之間的關聯規則關系;road-CA為路網數據集.在第3節中我們對這些圖數據集的多樣性特征進行了分析,可以發現各類數據集的點邊分布以及稀疏程度都存在特征性的差異.下面我們利用這9個現實網絡圖數據集對GFlow進行性能的實驗對比分析. 我們以twitter圖數據在8 GB的Host Memory、4 GB設備訪存的服務器上為例對Shard的切分配置參數進行說明如下.twitter圖數據(1.4 billion邊規模,節點和應用數據大小取16 B)在8 GB可用主存下的分塊取區間個數P=10.通過8個GPU設備的分塊,總的grid-shard個數為80.設置的tile-window大小為閾值δ×8 GB=6.4 GB,stream-window為global memory總大小32 GB.在加載過程中,twitter圖的大小為52.4 GB(CSRCSC格式),對子圖分塊的索引占用一定的空間,通過tile-window加載一個5.2 GB的strip-shard子圖分塊到Host Memory后構建各索引(v2sMap和s2vMap)占用,切分為0.65 GB左右的grid-shard. Fig. 10 The comparison results for elapsed time of out-of-core graph parallel-processing systems and GFlow圖10 GFlow與其他外存圖數據計算系統的性能對比,限制節點內存為8 GB 在本節中,我們首先將GFlow與常用的CPU下的外存計算系統GraphChi和X-Stream的性能進行對比評估,其中GraphChi和X-Stream部署于多核CPU上進行實驗,2個系統采用16線程進行對比(X-Stream支持的多線程配比為2n);GraphReduce和本文所設計的GFlow系統部署于GPU平臺.為了驗證的公平性,GraphReduce只支持單個GPU的執行,我們在對比配置中將GFlow設置為單GPU下的運行狀態. 1) 對比X-Stream和GraphChi.如圖10所示,GFlow相比GraphChi和X-Stream分別平均能夠提升10.3X和3.7X的執行效率.首先,對BFS和SSSP的圖遍歷算法(圖10(a)(d)),GFlow相比其他系統的性能更優,最大的提升來自于uk-2002數據集,相比GraphChi和X-Stream在SSSP算法取得了21X和20.3X的加速比,在BFS算法取得20.8X和7.5X的加速比.同時GFlow在billion邊規模的twitter圖數據上總體執行時間85.2 s和35.2 s,相對比也能取得2.2~8.0X的執行效率提升.這些性能提升的原因主要來自于2個方面:①GPU的高并行運行時環境提供了GFlow在圖數據處理上的性能優勢;②通過利用重疊數據傳輸和計算開銷,GFlow充分得到了異步并行計算的性能優勢.在PageRank和CC算法上(圖10(b)(c)),GFlow仍然能夠得到一定的效率優勢,例如,在kron-g500-logn21和uk-2002數據集上,GFlow在CC算法上取得了3.8 s和212.2 s執行時間,對比GraphChi和X-Stream分別提升性能2.1~25.6X和4.3~6.5X.值得注意的是在kron-g500-logn21上的PageRank執行效率,GFlow略遜于X-Stream,其中原因在于kron-g500-logn21能夠完整地存儲于節點的主存中,X-Stream能夠充分利用本地性的數據的訪問,而GFlow加載到GPU設備內存帶來了大量的PCI-E的傳輸開銷,導致性能略有所降低. 2) 對比GraphReduce系統.從圖10中結果可以看出,GFlow在單個GPU的執行性能上能夠大部分領先于GraphReduce.在大部分的基準測試中,GFlow能夠對比GraphReduce得到1.3~2.2X的性能提升,所得到的最大提升性能來自于kron-g500-logn21數據集.這其中的性能優勢原因主要來源于GFlow在GPU執行上的性能優化策略,例如,采用Ring Buffer來降低動態Update數據塊的讀寫有效地提升PCI-E的吞吐;利用雙層順序讀寫窗口以加速數據加載和并行處理的策略等. 進一步,我們也將GFlow與GPU內存計算的圖數據系統WS-VR[22]進行了性能對比.WS-VR通過利用GPU內部Warp線程組的調度對GPU在CSR圖數據上的執行效率得到了大幅提升,同時提出了節點集約減來提高Multi-GPU上的可擴展性和執行效率.從圖11數據所示,我們分析了GFlow與WS-VR在Multi-GPU上的總體執行效率對比(WS-VR配置為Vertex Reduce模式優化).我們可以看出,GFlow的執行性能相對比WS-VR有一定的可對比性,尤其在擴展到采用多個GPU的平臺下.例如,在BFS算法belgium圖數據上,GFlow執行1.89 ms和1.67 ms在6和7個GPU配置下,相比WS-VR達到1.30~1.51X的加速比.需要注意的是,在多個基準測試算法上(belgium BFS和road-CA SSSP),WS-VR在GPU數量增大的情況下執行的性能反而降低,這也說明多個GPU所帶來的數據傳輸和同步開銷增大反而導致整體性能的降低.而GFlow相比來看能夠從動態活躍節點集和異步數據傳輸的策略上得到可擴展性的提升.另外,相比處理這類內存內的數據集,GFlow也能夠從所設計的數據結構上得到數據傳輸的性能提升,從而降低了PCI-E的傳輸開銷和達到多個GPU之間的負載均衡. Fig. 11 Execution time of in-memory system WS-VR and GFlow圖11 GFlow與GPU圖數據計算系統WS-VR在Multi-GPU上的執行時間對比 最后,我們對GFlow在Multi-GPU上的可擴展性進行了分析.對可擴展性的實驗選擇了4個圖數據集,包括內存內的和外存存儲數據集,以及PageRank,BFS和SSSP三個基準測試算法來驗證GFlow.從表2中數據可見,GFlow的可擴展性在1個GPU到6個GPU上表現良好.首先,在3個外存存儲的圖數據集kron-g500-logn21,uk-2002和twitter,隨著GPU個數的加速,能夠大幅降低整體的執行時間,提升了4.95~5.6X的性能.另外,在2個內存內圖數據集webbase,GFlow仍然取得了一定可比性的性能提升,在6個GPU配置下相比提升了3.8X. 綜合以上結果可以得到:本文所提出和實現的GFlow系統能夠很好地應用于Multi-GPU下的大規模圖數據處理應用上.該系統對GPU下圖數據的處理得到大幅度的性能提升,尤其在基于外存的大規模圖數據的處理上.相對比現有的CPU上的外存計算系統GraphChi和X-Stream,GFlow利用GPU的高性能計算達到了數十倍的性能提升.同時,相對比GPU環境下的GraphReduce和WS-VR,GFlow也能表現出相當的加速比,同時在Multi-GPU平臺下得到3.8~5.8X(6個GPU配置)的可擴展性性能提升. Table 2 Speedup of GFlow on Different Graph Applications and Datasets表2 算法在Multi-GPU上的可擴展性性能對比 Note: That speedup ratio is measured onN-GPU vs 1-GPU. 本文主要介紹了一個Multi-GPU平臺下高可擴展的大規模圖數據處理框架GFlow,支持在有限的計算資源(內存、處理器)下對大規模圖數據進行處理.GFlow提出了適用于Multi-GPU平臺多層級內存結構的Grid分塊存儲方式,將大規模圖數據轉換strip-shard和grid-shard分塊,利用順序數據塊的并行讀寫提升數據傳輸性能.同時,為了降低數據在PCI-E鏈路上傳輸和通信的開銷,GFlow設計并實現了雙層滑動窗口讀寫和處理策略以最大化圖分塊的順序數據傳輸,并采用Ring Buffer來合并各GPU所動態生成的Update和節點狀態數據從而以聚合的文件塊(block)形式提升消息數據的讀寫能力.從實驗驗證中可以看出,GFlow能夠大幅度提升GPU平臺下外存圖數據的吞吐和執行性能,并在多個GPU下可擴展性良好. [1]Cheng Xueqi, Jin Xiaolong, Wang Yuanzhuo, et al. Survey on big data system and analytic technology[J]. Journal of Software, 2014, 25(9): 1889-1908 (in Chinese)(程學旗, 靳小龍, 王元卓, 等. 大數據系統和分析技術綜述[J].軟件學報, 2014, 25(9): 1889-1908) [2]Yu Ge, Gu Yu, Bao Yubin, et al. Large scale graph data processing on cloud computing environments[J]. Chinese Journal of Computers, 2011, 34(10): 1753-1767 (in Chinese)(于戈, 谷峪, 鮑玉斌, 等. 云計算環境下的大規模圖數據處理技術[J]. 計算機學報, 2011, 34(10): 1753-1767) [3]Khorasani F, Vora K, Gupta R, et al. Cusha: Vertex-centric graph processing on GPUs[C] //Proc of the 23rd Int Symp on High-Performance Parallel and Distributed Computing. New York: ACM, 2014: 239-252 [4]Fu Z, Personick M, Thompson B. Mapgraph: A high level API for fast development of high performance graph analytics on GPUs[C] //Proc of Workshop on Graph Data Management Experiences and Systems. New York: ACM, 2014: 1-6 [5]Wang Y, Davidson A, Pan Y, et al. Gunrock: A high-performance graph processing library on the GPU[C] //Proc of the 21st ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2016: No.11 [6]Sengupta D, Song S L, Agarwal K, et al. GraphReduce: Processing large-scale graphs on accelerator-based systems[C] //Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2015: No.28 [7]Graph500. The Graph500 list[EB/OL]. [2017-11-03]. http://www.graph500.org/ [8]You Y, Bader D, Dehnavi M M. Designing a heuristic cross-architecture combination for breadth-first search[C]//Proc of the 43rd Int Conf on Parallel Processing (ICPP). Piscataway, NJ: IEEE, 2014: 70-79 [9]Merrill D, Garland M, Grimshaw A. Scalable GPU graph traversal[C] //Proc of the 17th ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2012: 117-128 [10]Hong S, Kim S K, Oguntebi T, et al. Accelerating CUDA graph algorithms at maximum warp [C] //Proc of the 17th ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2011: 267-276 [11]Liu H, Huang H H. Enterprise: Breadth-first graph traversal on GPUs[C]//Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2015: No.68 [12]Zhong J, He B. Medusa: Simplified graph processing on GPUs[J]. IEEE Trans on Parallel and Distributed Systems, 2014, 25(6): 1543-1552 [13]BenNun T, Sutton M, Pai S, et al. Groute: An asynchronous multi-GPU programming model for irregular computations[C] //Proc of the 22nd ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New Yor: ACM, 2017: 235-248 [14]Gonzalez J E, Low Y, Gu H, et al. Powergraph: Distributed graph-parallel computation on natural graphs[C] //Proc of the 10th USENIX Symp on Operating Systems Design and Implementation. Berkey, CA: USENIX, 2012: 17-30 [15]Kyrola A, Blelloch G, Guestrin C. Graphchi: Large-scale graph computation on just a PC [C] //Proc of the 10th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX, 2012: 31-46 [16]Cheng J, Liu Q, Li Z, et al. Venus: Vertex-centric streamlined graph computation on a single PC[C] //Proc of the 31st IEEE Int Conf on Data Engineering (ICDE). Piscataway, NJ: IEEE, 2015: 1131-1142 [17]Roy A, Mihailovic I, Zwaenepoel W. X-stream: Edge-centric graph processing using streaming partitions[C] //Proc of the 24th ACM Symp on Operating Systems Principles. New York: ACM, 2013: 472-488 [18]Cheng L, Kotoulas S. Scale-out processing of large RDF datasets[J]. IEEE Trans on Big Data, 2015, 1(4): 138-150 [19]Zhu X, Han W, Chen W. Gridgraph: Large-scale graph processing on a single machine using 2-level hierarchical partitioning[C] //Proc of USENIX Annual Technical Conf. Berkeley, CA: USENIX, 2015: 375-386 [20]Chi Y, Dai G, Wang Y, et al. Nxgraph: An efficient graph processing system on a single machine[C] //Proc of the 32nd IEEE Int Conf on Data Engineering (ICDE). Piscataway, NJ: IEEE, 2016: 409-420 [21]Zhang Jun, He Yanxiang, Shen Fanfan, et al. Two-stage synchronization based thread block compaction scheduling method of GPGPU[J]. Journal of Computer Research and Development, 2016, 53(6): 1173-1185 (in Chinese)(張軍, 何炎祥, 沈凡凡, 等. 基于2階段同步的GPGPU線程塊壓縮調度方法[J]. 計算機研究與發展, 2016, 53(6): 1173-1185) [22]Khorasani F, Gupta R, Bhuyan L N. Scalable SIMD-efficient graph processing on GPUs[C] //Proc of 2015 Int Conf on Parallel Architecture and Compilation (PACT). Piscataway, NJ: IEEE, 2015: 39-50 [23]Faraji I, Mirsadeghi S H, Afsahi A. Topology-aware GPU selection on multi-GPU nodes[C] //Proc of 2016 IEEE Int Parallel and Distributed Processing Symp Workshops. Piscataway, NJ: IEEE, 2016: 712-720 [24]Page L, Brin S, Motwani R, et al. The PageRank citation ranking: Bringing order to the Web[R]. Stanford, CA: Stanford InfoLab, 19993.2 適用于Multi-GPU下的圖數據Grid切分策略
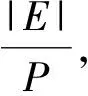
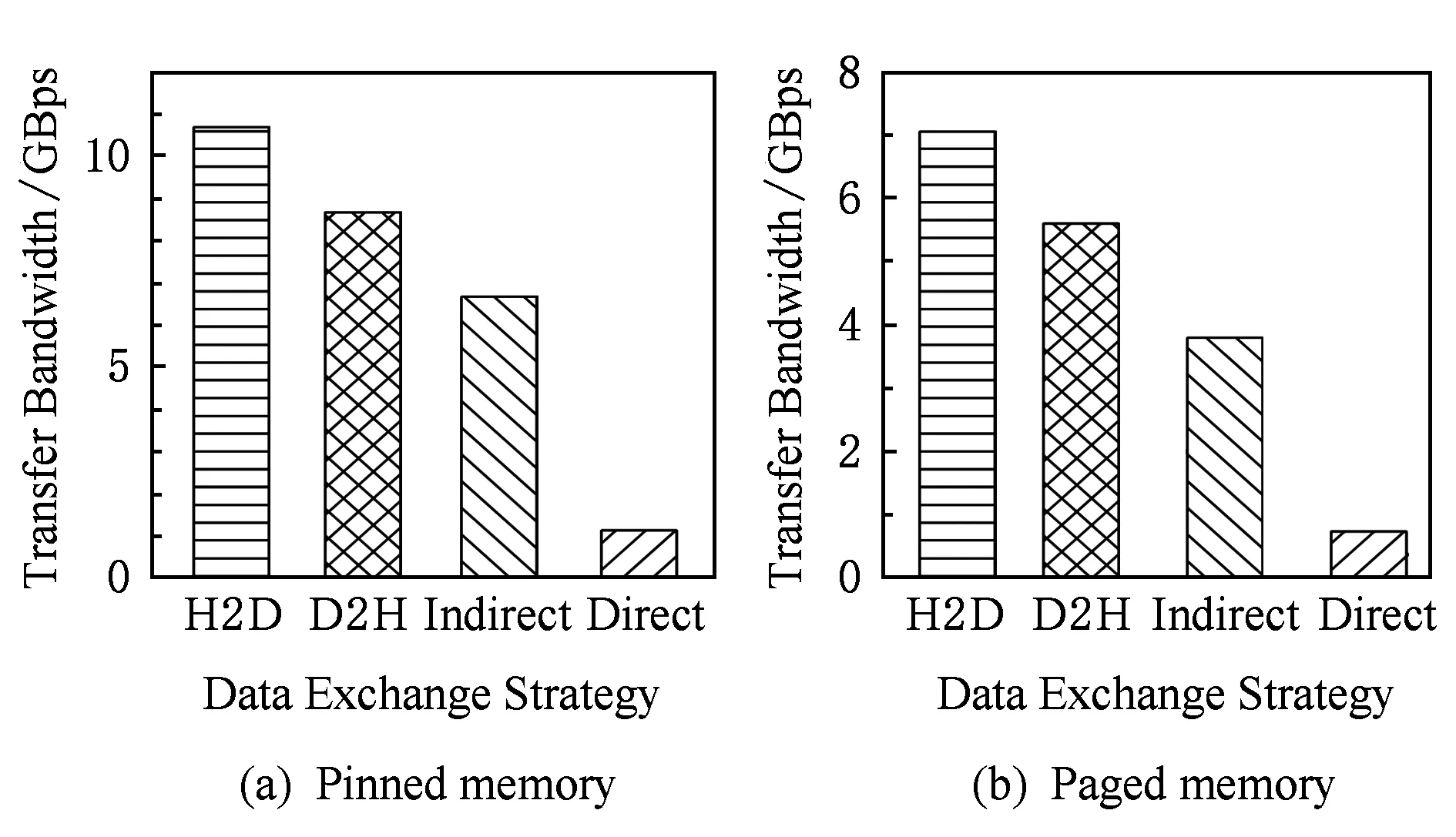
3.3 基于雙層滑動窗口的異步數據傳輸和計算
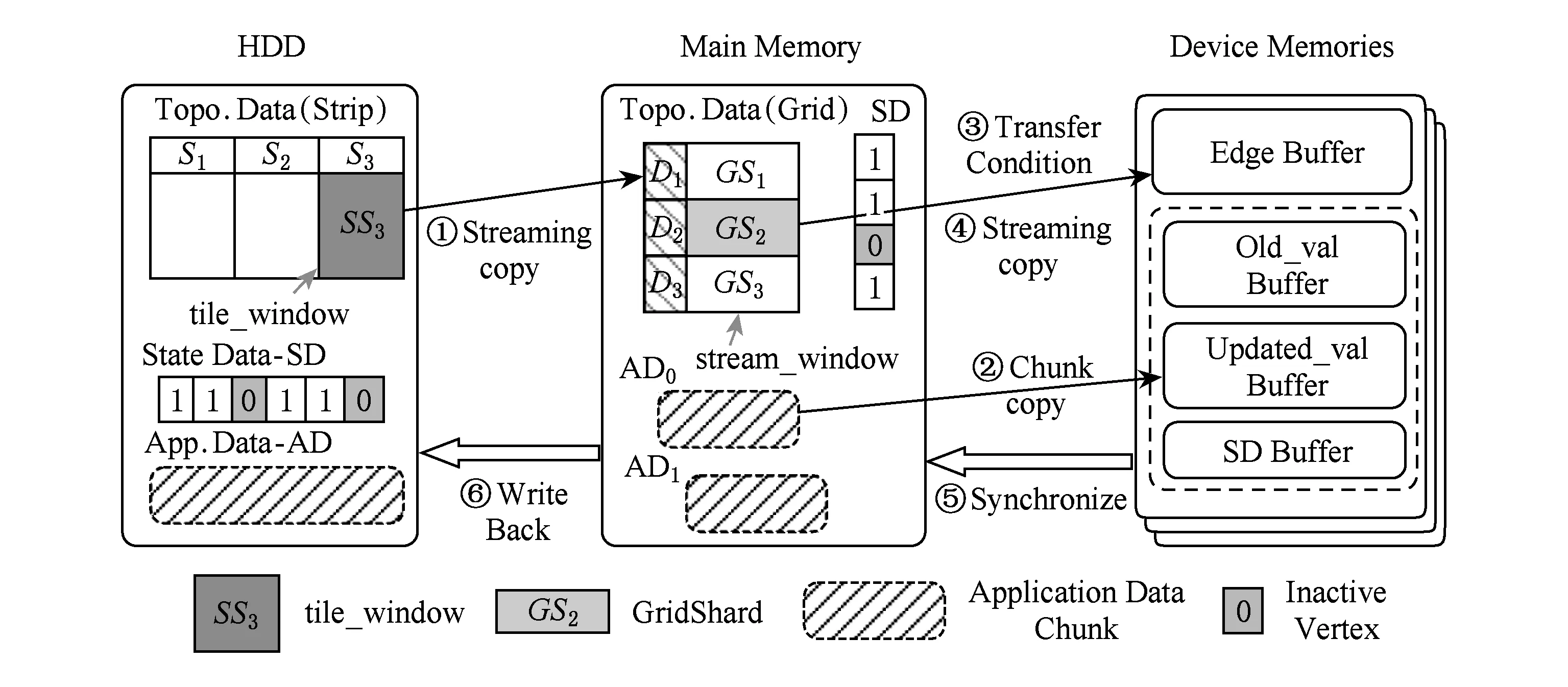
3.4 GFlow實現細節
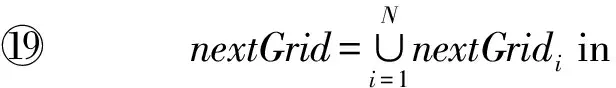
4 實驗與結果
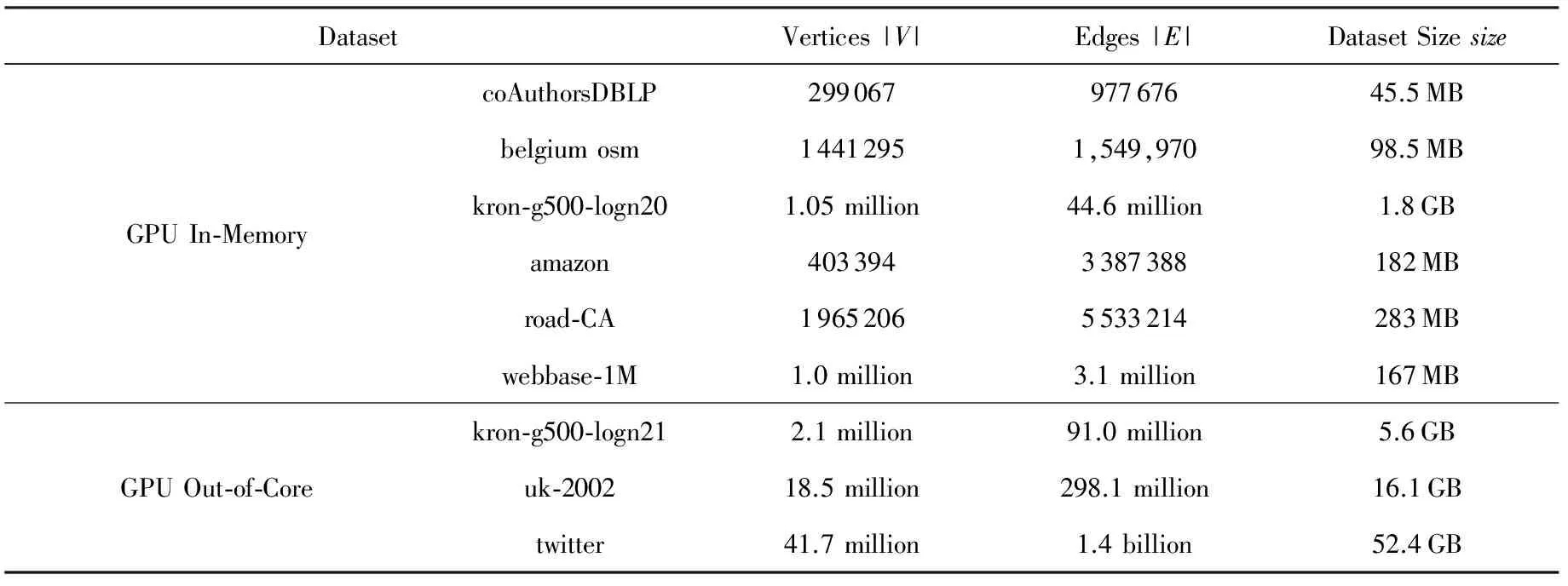
4.1 數據集
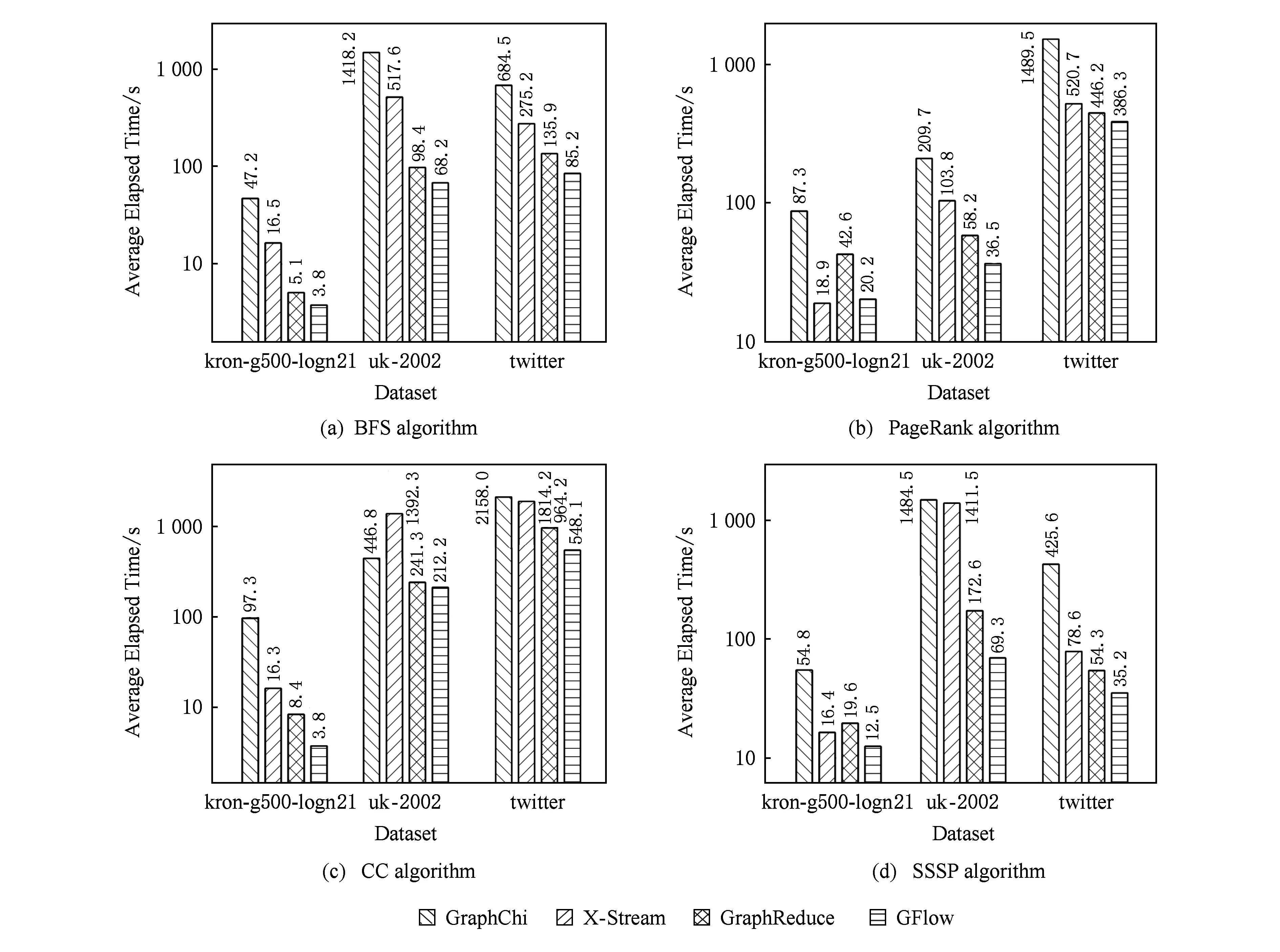
4.2 實驗和結果

5 總 結
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
