USPTO專利發明人重名辨識方法綜述
2018-03-03 05:51:34于永勝韓紅旗
天津科技 2018年2期
于永勝,董 誠,韓紅旗,李 仲
(中國科學技術信息研究所 北京100038)
0 引 言
專利數據具有重要的科研應用價值。專利數據集技術情報、法律情報和經濟情報于一體[1],是一種重要的競爭情報信息分析來源,它還可以用于發明人遷移[2]、創新經濟[3]和創新合作網絡影響力分析[4]等研究領域。
嚴重的專利發明人重名現象影響著專利數據的科研應用。美國專利商標局(USPTO)一直沒給專利發明人或專利權人分配一個獨一無二的身份識別號,隨著專利文獻數量越來越多,具有同名或近似名的專利發明人重名現象因為姓名縮寫、中間名缺失、拼寫錯誤等原因更加嚴重,該現象給專利數據在技術應用和科學研究等領域的應用造成很大阻礙[5]。
本研究將造成專利發明人重名辨識越來越困難的原因歸納為 4類:①專利數據規模龐大,現有專利發明人重名辨識方法計算成本太高。USPTO在2013年就擁有超過800萬件專利和3,200萬億對記錄,這使得人工處理方法不再可行,現有專利發明人重名辨識方法計算成本太高[6]。②專利發明人姓名存在縮寫、后綴、拼寫錯誤、中間名缺失等情況,增加了發明人重名辨識難度。在美國專利中,專利發明人中間名缺失率為 51.10%,[7]。③USPTO專利發明人大量使用常用名,如:John Smith。根據統計,美國約有16.4%,的人口使用常用名,數量約為5,271萬人[8]。④學科領域信息不能有效區分重名專利發明人。USPTO專利大多為合作發明且跨學科領域,這使得學科領域不能作為區分重名發明人的主要依據,增加了專利發明人重名辨識的難度[9]。
專利發明人重名辨識方法是為解決上述現象而提出的,其目的是促進專利數據在科研和情報分析領域的應用[10]。這類方法根據專利發明人記錄的成對比較結果,區分專利數據庫中具有相同或相近姓名的發明人,并將每個發明人與其專利對應起來。
現有的專利發明人重名辨識方法主要包括:基于規則的方法、基于機器學習生物方法。基于規則的方法穩定性差,不能有效適應不同的專利發明人重名辨識環境;基于機器學習的方法能夠較好適應不同的專利發明人重名辨識環境,并具有較好的重名辨識效果,但該方法在大規模專利數據集上運行時間成本較高[11]。
1 姓名歧義性
姓名歧義性是指不同來源的實體對象共用同一個姓名,尤其是在整合不同的網頁和數據庫時,姓名歧義現象會因姓名縮寫或假名等更加嚴重,造成數據庫檢索結果不準確[9]。專利發明人姓名歧義是指當數據庫查詢或關聯某個發明人的專利時,往往會將所有同名發明人的專利返回或將某個發明人與其他發明人的專利相連接,使得基于專利發明人的科研技術研究結果出現偏差。
USPTO專利發明人重名辨識方法研究,來源于國家科技支撐計劃課題“面向科技情報分析的信息服務系統研發與應用示范”項目研究計劃。該項目通過構建專利發明人科研合作網絡,進行創新團隊競爭與合作關系挖掘,而專利發明人重名辨識是該項目中的一項基礎研究。
2 重名辨識方法研究現狀
本研究主要介紹專利發明人重名辨識方法研究現狀,對現有的研究方法進行分析,主要包括:基于規則的方法、基于機器學習的方法、基于語義指紋的方法和基于唯一標識的方法。
2.1 專利發明人重名辨識方法分類
專利發明人重名辨識方法是記錄連接方法(Record Linkage)在專利領域中的子應用[10]。1969年,Fellegi和 Sunter[12]基于單一數據源中記錄屬于單一個體的假設,提出了第一個用于記錄連接的數學統計模型。而發明人重名辨識方法主要用于區分專利數據庫中同名而不同發明的人的專利。
本研究具體方法分類如圖1所示。
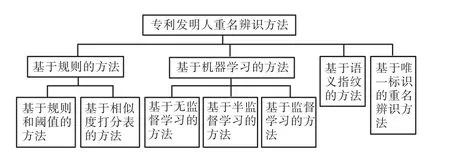
圖1 專利發明人重名辨識方法分類Fig.1 Classification of name disambiguation methods for patent inventors
2.2 基于規則的專利發明人重名辨識方法
基于規則的專利發明人重名辨識方法包括基于規則和閾值的重名辨識方法、基于相似度打分表的重名辨識方法,主要依據人為設置的規則、閾值或相似度分值,來進行專利發明人記錄的成對比較,判斷兩個同名專利發明人是否屬于同一個人。
2.2.1 基于規則和閾值的重名辨識方法
Singh[13]根據從專利數據中抽取發明人姓和地區字段,利用if-else判定規則和字符串精確匹配來判定專利發明人記錄對是否正確匹配。Fleming[4]通過專利發明人的專利權人和地區合并字段,利用“if-elsethen”匹配規則和字符串精確匹配進行發明人重名辨識,然后通過一個預設的閾值,判斷兩條專利發明人記錄是否屬于同一個人。Milojevi[14]在模擬的題錄數據庫中,利用專利發明人姓(last name)和名的首字母(initial of last name)代替其他字段進行專利發明人重名辨識,獲得的專利發明人姓名識別結果更加準確。Morrison[15]提出了一套基于高分辨率地理位置的專利權人和專利發明人重名辨識方法,該方法主要針對歐洲專利數據,將歐洲專利數據中的地理街道位置轉化成經緯度進行相似發明人或專利權人姓名聚類,然后通過制定規則和編輯距離閾值進行專利發明人重名辨識。
2.2.2 基于相似度打分表的重名辨識方法
基于相似度打分表的專利發明人重名辨識方法是介于規則方法和無監督學習方法之間的一種方法,該方法通過人為制定專利發明人比較字段的相似度打分表,計算兩條專利發明人記錄的相似度分值,然后通過一個預設的閾值判斷這兩條發明人記錄是否屬于同一個人。Miguelez[3]通過桑迪克斯編碼系統(Soundex-code)對專利發明人姓名進行重新編碼以聚集相似的發明人姓名,然后用相似度打分表計算每對專利發明人的相似度分值并判斷其是否匹配。Pezzoni等[16]采用基于編輯距離的詞牌方法將專利發明人相似姓名分組,然后根據相似度打分表計算發明人記錄對的相似度分值,并進行閾值判斷。
2.3 基于機器學習的專利發明人重名辨識方法
機器學習是指利用統計學原理,讓計算機模擬人類思維,根據對以往數據或經驗的學習,達到替人進行數據處理和分析的目的[17]。
目前,基于機器學習的專利發明人重名辨識方法主要包括 3個階段:數據處理階段、匹配階段和過濾階段[3,16,18]。數據處理階段,主要包括停用詞過濾、字母小寫轉化、專利發明人字段拆分、噪音數據刪除等,為專利發明人重名辨識準備好結構化數據;匹配階段是專利發明人重名辨識方法的核心,是指通過機器學習方法判斷專利發明人記錄對是否屬于同一個人或者計算專利發明人記錄對的相似度分值,為過濾階段的相似發明人聚類做準備;過濾階段,通常根據參數估計獲得的閾值,利用聚類算法區分存在姓名歧義的專利發明人。
2.3.1 基于無監督學習的重名辨識方法
基于無監督學習的專利發明人重名辨識方法根據相似度計算方法在無標簽訓練數據集中進行聚類,將低于相似度閾值或距離的專利發明人記錄對作為相似發明人,根據相似度計算方法不同,聚類算法可以分為距離聚類、原型聚類、密度聚類和層次聚類。Nicolas[19]使用無監督貝葉斯方法在歐洲專利數據集上識別獨特發明人,該方法創新之處在于,它將專利發明人重名辨識表示為一個相似度概率模型,即用相似度概率表征每對專利發明人記錄間的相似程度。朱亮亮[20]利用改進的 k-means算法進行文獻著者姓名消歧,根據最大最小原則選取初始聚類中心,克服了傳統 k-means聚類算法隨機選擇初始聚類中心可能會導致局部收斂的問題。
2.3.2 基于半監督學習的重名辨識方法
基于半監督學習的專利發明人重名辨識方法通常使用小數據量標簽數據集和大數據量無標簽數據集來訓練模型,用于判斷專利發明人記錄對是否屬于相同實體。Torvik和 Smalheiser[21]通過將數學統計概念引入到MEDLINE數據庫作者姓名消歧中,獲得了一批準確度較高的人造標簽數據,可以用于訓練分類模型,然后在貝葉斯框架下使用邏輯回歸預測MEDLINE作者記錄對是否正確匹配。其意義在于可以通過統計獲得準確度較高的人造標簽數據集,解決了監督學習方法中分類器訓練數據不足的問題,但是人造標簽數據集中任何誤差或錯誤假設都會影響到分類模型準確性。Swapnil[10]根據 Torvik和Smalheiser[12]的方法獲得人造標簽數據集,分別生成專利發明人姓名、地址和技術類的相似度分值,然后通過支持向量機和邏輯回歸方法證明簡單的機器學習方法可以用于代替較復雜的專利發明人重名辨識方法。Li等[22]也是借助于 Torvik和 Smalheiser[21]的方法,通過統計產生準確度較高的人造標簽數據集,并在貝葉斯框架下使用邏輯回歸方法判斷專利發明人記錄對的匹配情況。
2.3.3 基于監督學習的重名辨識方法
基于監督學習的專利發明人重名辨識方法通過標簽數據集訓練分類器,用于判斷專利數據庫中發明人記錄對是否匹配。Ventura[23]提出了性能更優的基于隨機森林的條件森林(Conditional Forest of Random Forest,CFoRF)算法用于專利發明人重名辨識,針對專利發明人數據中間名缺失等情況構建不同的條件子集,并在這些條件子集上分別訓練不同的隨機模型,最后通過集成這些模型的分類結果預測專利發明人記錄對的匹配概率。為了降低計算成本,Ventura[5]之后提出了基于隨機森林的森林(Forest of Random Forest,FoRF)和層次聚類算法用于重名辨識專利發明人,并將該方法應用于數據密集型專利發明人重名辨識,通過在 50,000條美國專利數據上進行實驗,證明了該方法具有良好性能。類似的,Ventura[11]采用基于隨機森林和層次聚類的方法進行發明人重名辨識,結果顯示該方法的誤分率(spliting error rate)和誤合率(lumping error rate)均低于規則方法和半監督方法;Yang等[18]提出了基于混合分類器和圖聚類的方法進行專利發明人重名辨識,并取得了USPTO專利發明人姓名消歧競賽第二名的好成績,其中混合分類器是由 Bootstrap監督學習方法、概率記錄連接和規則方法融合而成;Kim 等[8]采用基于隨機森林和 DBSCAN聚類的方法,在 USPTO專利發明人姓名消歧競賽訓練數據上進行測試,其實驗結果不僅優于2015年USPTO專利發明人姓名消歧競賽結果,而且其方法運行時間也比競賽方法運行時間節省半小時,證明了該方法能夠更好地進行專利發明人重名辨識。
2.4 基于語義指紋的重名辨識方法
語義指紋具有不同的定義:吳軍[24]將語義指紋(也稱為信息指紋)定義為將一段信息(文字、圖片、音頻、視頻等)隨機地映射到一個多維二進制空間中的一個點(一段二進制數字);Webber[25]將語義指紋定義為基于語義折疊理論編碼明確、包含意義和語境信息的數據表示,即用一段數字表征隱藏在自然語言背后的含義;Ibriyamova[26]認為語義指紋是一種在大量文本內容上進行訓練,并能夠表征文本中詞與詞之間關聯關系的概念。綜上所述,本文將語義指紋定義為基于文本摘要技術,能夠表示文本特征和差異,并且將文本內容映射為二進制哈希值的一種算法。語義指紋算法根據文本特征權重對這些哈希值進行加權求和、壓縮,生成能夠表征大量文本內容特征和差異的一段 64位或 128位二進制數字串,比較有代表性的指紋算法有shingling指紋算法[27]、Simhash語義指紋算法[28]。其中,文本摘要技術,即哈希函數,是指將文本內容通過一個散列函數或哈希表映射為固定長度的數字串,比較有代表性的哈希函數有Minhash 函數[29]、Rabin 哈希[30]、SDBM 哈希[31]、MD5 哈希[32]、SHA-1 哈希[33]。
Han[34]通過 Simhash語義指紋算法,將論文文本特征映射為一段 64位二進制語義指紋,并結合文獻合著者、機構、郵箱等信息,進行論文著者姓名消歧,結果證明語義指紋方法性能要優于傳統 K-means聚類消歧方法。在專利數據中,專利發明人一直存在特征稀疏等問題[35],現有的專利發明人重名辨識方法一直基于專利元數據特征進行分析,占專利內容比例較高的文本數據卻一直沒有用于發明人重名辨識研究,而語義指紋算法卻可以將文本特征歸并到語義指紋中,用于專利發明人相似度判斷。
2.5 基于唯一標識的重名辨識方法
基于唯一標識的重名辨識方法是指通過給每一位科研人員分配一個獨特且唯一的身份標識號,并將其與科研人員的科研產出相關聯,進而消除科研人員姓名歧義現象。早在 2009年,湯森路透公司就推出了 ResearcherID[36]用戶注冊平臺,每位科研人員可以通過用戶注冊獲得一個獨特且唯一的身份標識號,每當個人科研成果需要出版發表時,每位科研人員需要同時提供自己的身份標識號,以便在ResearcherID有效范圍內規避科研人員姓名歧義現象。ORCID[37](Open Researcher and Contributor ID,科研人員與投稿身份識別開放項目)是由湯森路透公司和自然出版集團等多家單位在 2009年聯合發起的項目,與科技文獻 DOI類似,ORCID可以給全球每位科研人員分配一個獨立唯一性的國際學術標識符,該標識符是由一套免費、全球唯一的 16位身份識別碼構成。在2014年,中國科學院文獻情報中心[38]與ORCID簽署合作協議,推出中國科學家在線(iAuthor)平臺作為ORCID的中國服務平臺,將更加方便地服務中國科研人員使用ORCID,管理個人科研成果。
基于唯一標識的重名辨識方法非常簡單有效、省時省力,因此國內外許多出版機構都在制定和推出一套獨特的身份標識系統,用于科研人員身份識別。但是,在實際執行過程中,基于唯一標識的專利發明人重名辨識系統會遇到以下幾個困難:①Smalhesier[9]提到,國外價值觀念中非常重視個人隱私信息,例如身份證號、社保號、唯一性身份識別號等能夠唯一標識個人身份的信息經常被反對公開,這也是 USPTO沒有給專利發明人分配唯一性身份識別號的原因之一;②唯一性身份標識系統由科研出版機構等聯合推行,系統維護及資金來源難以保證長期穩定有效;③ORCID、ResearcherID、百度ScholarID等都是面向大范圍各個行業領域的身份標識系統,難以在行業內部形成統一規范的行業體系和執行標準,而且每個科研人員可能擁有多個唯一性身份標識符,或者在同一個標識系統中擁有多個 ID,造成另一種意義上的“歧義”現象;④對于已有專利文獻的重名辨識,唯一標識系統無法解決這個問題,而現有文獻資料具有重要的研究價值和參考意義,所以其他重名辨識方法有一定的研究意義。
3 總 結
本研究以機器學習方法缺點作為研究出發點,為在較短時間內有效完成發明人重名辨識,對專利發明人重名辨識方法進行展望:①本文建議將深度學習算法融入到重名辨識方法中,以便更加準確地進行發明人重名辨識。②本文建議將語義指紋算法融入到重名辨識方法中,以便更加高效地進行發明人重名辨識。■
[1]鄧要武. 科技報告、專利文獻和標準文獻資源檢索與利用[J]. 圖書館工作與研究,2008(7):71-74.
[2]Doherr T. Inventor mobility index:A method to disambiguate inventor careers [J]. New Discussion Papers,2008(5):251-262.
[3]Miguelez E,Gomez-miguelez I. Singling out individual inventors from patent data [J]. Ssrn Electronic Journal,2011(23):69-74.
[4]Fleming L,King C,Juda A I. Small worlds and re-gional innovation [J]. Social Science Electronic Publishing,2007,18(6):938-954.
[5]Ventura S L,Nugent R. Hierarchical Linkage Clustering with Distributions of Distances for Large-Scale Record Linkage[M]. Switzerland:Springer International Publishing,2014.
[6]Ventura S L,Nugent R,Fuchs E R. Methods matter:Rethinking inventor disambiguation with classification &labeled inventor records [J]. Academy of Management Annual Meeting Proceedings,2013,2013(1):14537-14537.
[7]Akinsanmi E O,Fuchs E,Reagans R E. Economic downturns,technology trajectories and the careers of scientists [J]. Georgia Institute of Technology,2011(9):52-74.
[8]Kim K,Khabsa M,Giles C L. Random forest DBSCAN for USPTO inventor name disambiguation [J].arXiv:1602. 01792v2,2016(2):37-49.
[9]Smalheiser N R,Torvik V I. Author name disambiguation [J]. Annual Review of Information Science & Technology,2015,43(1):1-43.
[10]Swapnil M U. Inventor disambiguation for patents filed at USPTO [J]. CiteSeerX,2013(5):83-102.
[11]Ventura S L,Nugent R,Fuchs E R H. Seeing the nonstars:(Some)sources of bias in past disambiguation approaches and a new public tool leveraging labeled records[J]. Research Policy,2015,44(9):1672-1701.
[12]Fellegi I P,Sunter A B. A theory for record linkage [J].Journal of the American Statistical Association,1969,64(328):1183-1210.
[13]Singh J. Collaborative networks as determinants of knowledge diffusion patterns [J]. Management Science,2005,51(5):756-770.
[14]Milojevi S. Accuracy of simple,initials-based methods for author name disambiguation [J]. Journal of Informetrics,2013,7(4):767-773.
[15]Morrison G,Riccaboni M,Pammolli F. Disambiguation of patent inventors and assignees using highresolution geolocation data [J]. Social Science Electronic Publishing,2015(12):46-71.
[16]Pezzoni M,Lissoni F,Tarasconi G,. How to kill inventors:Testing the Massacrator algorithm for inventor disambiguation [J]. Scientometrics,2014,101(1):477-504.
[17]周志華. 機器學習:Machine Learning [M]. 北京:清華大學出版社,2016:1-2.
[18]Yang G C,Liang C,Jing Z,et al. A mixture record linkage approach for US patent inventor disambiguation[C]. 2017. Advanced Multimedia and Ubiquitous Engineering,MUE/FutureTech,2017:331-338.
[19]Nicolas C,Lorenzo C. Who’s Who in Patents. A Bayesian approach [J]. Working Papers,2009(7):104-121.
[20]朱亮亮. 利用改進的 K-means算法實現文獻著者人名消歧[J]. 軟件導刊,2013,12(5):63-66.
[21]Torvik V I,Smalheiser N R. Author name disambiguation in MEDLINE. [J]. Acm Transactions on Knowledge Discovery from Data,2009,3(3):1-29.
[22]Li G C,Lai R,D’Amour A,et al. Disambiguation and co-authorship networks of the U. S. patent inventor database(1975—2010)[J]. Research Policy,2014,43(6):941-955.
[23]Ventura S L,Nugent R,Fuchs E R H. Methods matter:Revamping inventor disambiguation algorithms with classification models and labeled inventor records[J]. Academy of Management Annual Meeting Proceedings,2013(1):14537-14537.
[24]吳軍. 數學之美[M]. 2版. 北京:人民郵電出版社,2014:142-152.
[25]Webber F D S. Semantic folding theory and its application in semantic fingerprinting[J]. Computer Science,2015(11):51-110.
[26]Ibriyamova F,Kogan S,Salganikshoshan G,et al.Using semantic fingerprinting in finance[J]. Social Science Electronic Publishing,2016(5):10-38.
[27]Broder A Z,Glassman S C,Manasse M S,et al. Syntactic clustering of the Web[J]. Computer Networks &Isdn Systems,1997,29(8-13):1157-1166.
[28]Charikar M S. Similarity estimation techniques from rounding algorithms[C]. Thiry-Fourth ACM Symposium on Theory of Computing. New Jersey,2002:380-388.
[29]Broder A Z. On the resemblance and containment of documents[C]. Compression and Complexity of Sequences 1997. Proceedings,2002:21-29.
[30]Rabin M O. Fingerprinting by Random Polynomials[EB/OL]. https://www. docketalarm.com/cases/PTAB/IPR2013-00086/Inter_Partes_Review_of_U.S._Pat._794 9662/12-16-2012-Petitioner/Exhibit-1015-Rabin%2C_Fingerprinting_by_Random_Polynomials%,2C_Center_for_Research_in_Computing_Technology%,2C_Harvard_University%,2C_Report_TR_15_81/.
[31]Jain S,Pandey M. Hash table based word searching algorithm[J]. International Journal of Computer Science& Information Technologies,2012(3):4385-4388.
[32]Rivest R. The MD5 Message-Digest Algorithm[M].United States:RFC Editor,1992:492.
[33]Stallings W. Secure hash algorithm[J]. Cryptography &Network Security Principles & Practice,2007:1116.
[34]Han H,Yao C,Fu Y,et al. Semantic fingerprintsbased author name disambiguation in Chinese documents[J]. Scientometrics,2017,111(3):1879-1896.
[35]蔡云雷. 基于潛在語義分析的專利文本分類技術研究[D]. 沈陽:沈陽航空航天大學,2011:3-4.
[36]Manjunath A. ResearcherID:An unique identifier[EB/OL]. http://dspace.rri.res.in/bitstream/2289/5582/1/ResearcherID.pdf.
[37]Haak L L,Fenner M,Paglione L,et al. ORCID:a system to uniquely identify researchers[J]. Learned Publishing,2012,25(4):259-264.
[38]中國科學院文獻情報中心中國科學引文數據庫. iAuthor:國際研究者辨識系統[J]. 中華普外科手術學雜志電子版,2015(3):255.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
兒童故事畫報(2019年5期)2019-05-26 14:26:14
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
