基于Python的圖片爬蟲程序設計
2018-02-26 12:23:22云洋
電子技術與軟件工程 2018年17期
關鍵詞:程序
云洋


摘要
互聯網中包含大量有價值的數據,網絡爬蟲通過既定規則可以自動地抓取互聯網數據并下載至本地存儲。研究網絡爬蟲的工作原理和基于Python網絡信息爬取技術模塊功能,基于Requests-BeautifulSoup技術構建圖片爬蟲實現網頁圖片爬取,詳細闡述了百度貼吧美圖吧圖片爬蟲程序的采集、解析、爬取和存儲過程,實驗結果證明基于即thon的Requests-BeautifulSoup技術可快速構建圖片爬蟲程序實現對網頁圖片數據的自動解析和爬取,程序簡單有效并且數據采集速度快。
【關鍵詞】Python語言 網絡爬蟲 Request-BeautifulSoup 圖片爬取
網絡爬蟲(Web Crawler)又稱網絡蜘蛛(Web Spider)是一個能夠根據既定規則自動提取網頁信息的程序,它模仿瀏覽器發出HTTP請求訪問網絡資源,自動獲取用戶需要的網頁數據。已有一些定向網站的網絡爬蟲,如QQ空間爬蟲一天可抓取400萬條日志、說說、個人信息等數據;知乎爬蟲爬取各種話題下的優質答案;淘寶商品比價定向爬蟲爬取商品、評論及銷售數據。
Python是一種面向對象、解釋型、帶有動態語義的高級程序設計語言,其語法簡潔清晰,并具有豐富和強大的類庫,Python語言支持覆蓋信息技術各領域的10萬個函數庫,依靠開源快速開發,形成了全球最大的編程社區。2017年7月IEEE發布的編程語言排行榜中Python高居首位,基于Python的應用也在計算機各領域大放異彩。Python包含優秀的網絡爬蟲框架和解析技術,Python語言簡單易用且提供了與爬蟲相關的urllib、requests、BeautifulSoup、Scrapy等模塊。urllib模塊提供了從萬維網中獲取數據的高層接口,Requests模擬瀏覽器自動發送HTTP/HTTPS請求并從互聯網獲取數據,BeautifulSoup解析HTML/XML頁面獲取用戶需要的數據。本文基于Python的Requests-BeautifulSoup技術構建圖片爬蟲程序實現對百度貼吧美圖圖片的快速爬取,并將這些圖片保存在本地,方便用戶離線瀏覽和進一步使用。
1 網絡爬蟲工作原理與Python爬蟲技術模塊功能
網絡爬蟲是按照一定規則能自動抓取互聯網數據的程序或者腳本。網絡爬蟲通過網絡請求從Web網站首頁或指定頁面開始解析網頁獲取所需內容,并通過網頁中的鏈接地址不斷進入到下一個網頁,直到遍歷完這個網站所有的網頁或滿足爬蟲設定的停止條件為止。Python語言第三方網絡請求庫Requests模擬瀏覽器自動發送HTTP/HTTPS請求并從互聯網獲取數據。BeautifulSoup解析獲取的HTML/XML頁面為用戶抓取需要的數據,Beautiful Soup自動將輸入文檔轉換為Unicode編碼,將輸出文檔轉換為utf-8編碼,從而節省編程時間。
1.1 網絡爬蟲的工作原理
網絡爬蟲爬取頁面就是模擬使用瀏覽器獲取頁面信息的過程,其爬取流程一般包含如下4個步驟:
(1)模擬瀏覽器發起請求:通過目標URL向服務器發起request請求,請求頭header一般包含請求類型、cookie信息以及瀏覽器類型信息等;
(2)獲取服務器頁面響應:在服務器正常響應的情況下,用戶會收到所請求網頁的response,一般包含HTML、Json字符串或其他二進制格式數據(如視頻,圖片)等;
(3)獲取頁面內容解析:用相應的解析器或轉換方法處理獲取的網頁內容,如用網頁解析器解析HTML代碼,如果是二進制數據(如視頻、圖片),則保存到文件進一步待處理;
(4)存儲數據:網頁解析獲取的數據可以用CSV、Json、text、圖片等文件存儲,也可以sqlite、MySQL或者MongoDB等數據庫存儲。
1.2 Python第三方庫Requests模塊
Requests是用Python語言編寫,使用Apache2 Licensed許可證的HTTP庫。Python標準庫中自帶的urllib2模塊和httplib模塊提供了所需要的大多數HTTP功能,Requests使用URllib3模塊,支持HTTP連接保持和連接池,支持使用cookie保持會話,支持文件上傳,支持自動確定響應內容的編碼,支持國際化的URL和POST數據自動編碼。
通過pip命令($pip install requests)安裝Requests模塊。URllib提供了一系列用于操作URL的功能,URllib的request模塊可以方便地訪問抓取URL(統一資源定位符)內容,URllib.request模塊中常用的函數方法如表I所示。使用requests方法后,會返回一個response對象存儲服務器響應的內容,如r.status_code(響應狀態碼)、r.text(字符串方式的響應體,會自動根據響應頭部的字符編碼進行解碼)、r.Json(Requests中內置的JSON解碼器)、r.content(字節方式的響應體,會自動為你解碼gzip和deflate壓縮)等。
1.3 Python第三方庫Beautiful Soup模塊
Beautiful Soup是用Python寫的一個HTML/XML的解析器,它可以處理不規范標記并生成分析樹(parse tree),同時提供了簡單的python函數處理導航(navigating)、搜索并修改分析樹。
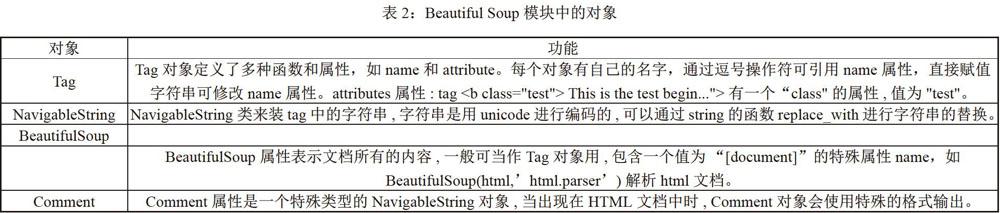
通過pip命令安裝($pip installbeautifulsoup4)Beautiful Soup模塊。BeautifulSoup將HTML文檔轉換成一個樹形結構,每個節點都是Python的對象,所有對象可歸納為4種,如表2所示。
2 貼吧圖片爬蟲程序設計
百度貼吧是全球最大的中文社區。貼吧是一種基于關鍵詞的主題交流社區,貼吧結合搜索引擎建立一個在線的交流平臺,讓那些對同一個話題感興趣的人們聚集在一起,方便地展開交流和互相幫助。設計爬蟲程序爬取百度帖吧(http://tieba.baidu.com)內的美圖吧圖片,運行爬蟲程序時提示用戶輸入想要爬取網站的url,爬蟲程序修改請求頭信息,模擬瀏覽器對貼吧內的帖子依次使用get請求,進入帖子后根據規則找到所有圖片標簽,獲取帖子內的圖片資源url,并將其依次下載到本地存儲,所有帖子爬取完成后按enter退出,運行中途也可以使用ctrl+c強制退出程序。
基于Python的Requests-BeautifulSoup技術構建圖片爬蟲程序,使用requests模擬瀏覽器請求網頁,用random生成隨機數選取模擬的瀏覽器,用BeautifulSoup支持的Python內置標準HTML解析庫解析請求網頁返回的數據,使用urllib.request.URLretrieve()下載圖片和各種網絡請求。
2.1 爬蟲準備
開發圖片爬蟲程序使用Python3.6版本,主要用到了urllib的requests模塊、BeautifulSoup模塊和random模塊,模塊是包含變量、函數或類的定義程序文件,使用模塊前通過import導入這些模塊。定義了兩個全局變量null和true并初始化,以避免當訪問網址url中出現null和true字樣時,Python會將null和true當成變量未初始化而報錯。
import urllib.request
from bs4 import BeautifulSoup
import random
global null#設置了兩個全局變量null和true并初始化
null="
global true
true-
2.2 定義圖片抓取函數
定義圖片抓取函數get_images(),使用BeautifulSoup解析獲取網頁,找到所有圖片標簽,從每個圖片標簽中下載圖片并重命名到本地保存,其代碼如下所示。
def get_images(info):#定義圖片抓取函數
soup=BeautifulSoup(info,'html.parser')#創建beautifulsoup對象soup
all_img=soup.find_all('img',class_='BDE Image')#找到所有圖片標簽
for img in all_img:#從每一個圖片標簽中下載圖片并重命名
image_name='%s.jpg'%img['src']
image_name=image_name.replace('jpg';a')
image_name=image_name+'.jpg'
image_name=image_name[-22:]
urllib.request.urlretrieve(img['src'],image_name)#下載圖片保存到本地文件image_name
print('成功抓取到圖片',img['src'])
print('抓取完成!')
2.3 模擬瀏覽器訪問網站
爬蟲程序模擬瀏覽器發送HTTP/HTTPS請求并從互聯網獲取數據。用戶代理UserAgent是Http協議的一部分,是請求頭信息的一部分。random是Python標準庫的模塊,用戶可以直接調用random的方法random.randint(a,b)生成一個指定范圍內的整數,其中參數a是下限,參數b是上限,下限必須小于上限。可用該函數生成隨機整數用于選取模擬的瀏覽器。訪問網站時通過用戶代理向服務器提供用戶使用的瀏覽器版本及類型,通過改寫User-Agent將Python爬蟲模擬成瀏覽器。如下代碼模擬不同瀏覽器型號并進入百度帖吧首頁。
Agent=['Mozilla/5.0(Macintosh;U;IntelMac OS X 10_6_8;en-us)AppleWebKit/534.50(KHTML,like Gecko)Version/5.1',
'Mozilla/4.0(compatible;MSIE 8.0;Windows NT6.0;Trident/4.0)',
'Mozilla/4.0(compatible;MSIE 7.0;Windows NT5.1;Maxthon 2.0)',
'Mozilla/4.0(compatible;MSIE 7.0;Windows NT5.1;The World)',
'Mozilla/5.0(Windows NT6.1;rv:2.0.1)Gecko/20100101 Firefox/4.0.1']
yemian=input('輸入要抓取的貼吧地址:')
req=urllib.request.Request(yemian)#用Request構建添加headers信息的完整URL請求
req.add_header('Host','tieba.baidu.com')#添加請求頭信息Host、Referer、User-Agent
req.add_header('Referer','http://tieba.baidu.com/')
req.add_header('User-Agent',Agent[random.randint(0,4)])#用random生成隨機數選取模擬的瀏覽器
2.4 進入帖子爬取圖片核心代碼
爬蟲主體程序核心代碼如下,通過urllib的requests和URLopen()方法模擬瀏覽器訪問網站獲取網頁數據,用BeautifulSoup的findall()解析獲取的網頁數據,進入帖子內抓取帶有圖片標簽的圖片文件并下載保存在本地磁盤。運行圖片爬蟲程序后爬取下載的帖吧圖片存儲如圖1所示。
html=urllib.request.URLopen(req)#打開一個URL請求返回一個文件對象hunt
string=html.read()
soup=BeautifulSoup(string;'html.parser')#用Python標準庫解析請求網頁返回的數據
all_img=soup.find_all('li',class_='j_thread_list')#返回文檔中符合條件的所有標簽tag
for img in all img:#從圖片連接中下載圖片
a=eval(img['data-field'])
b=a['id']
URL2='http://tieba.baidu.com/p/%s'%b
req2=urllib.request.Request(URL2)
req2.add_header('Host','tieba.baidu.con')
req2.add header('Referer','http://tieba.baidu.com/')
req2.add_header('User-Agent',Agent[random.randint(0,4)])
html2=urllib.request.urlopen(req2)
info=html2.readQ
get_images(info)
print('全部抓取完成.')
input()#程序運行結束后等待用戶輸入回車鍵再退出
3 結束語
本文研究了網絡爬蟲的工作原理和Python構建爬蟲的相關技術模塊,討論了Python構建爬蟲的模塊urllib、BeautifulSoup和random的功能用法。以百度貼吧圖片爬蟲構建為例,從爬蟲準備、模擬瀏覽器登陸網站、定義圖片爬取函數、進入貼吧解析網頁、爬取圖片存儲等方面詳細闡述了采用Python的Requests-BeautifulSoup技術構建圖片爬蟲程序抓取百度貼吧美圖吧圖片的過程。實驗結果證明基于Python的Requests-BeautifulSoup技術可快速有效地構建圖片爬蟲程序實現對網頁圖片數據的自動解析和爬取。
參考文獻
[1]郭麗蓉.基于Python的網絡爬蟲程序設計[J].電子技術與軟件工程,2017(23):248-249.
[2]賈棋然.基于Python專用型網絡爬蟲的設計及實現[J].電腦知識與技術,2017(12):47-49.
[3]劉艷平,俞海英,戎沁.Python模擬登錄網站并抓取網頁的方法[J].微型電腦應用,2015,31(01):58-60.
[4]涂輝,王峰,商慶偉.Python3編程實現網絡爬蟲[J].電腦編程技巧與維護,2017(23):21-22.
[5]周中華,張惠然,謝江.基于Python的新浪微博數據爬蟲[J].計算機應用,2014,34(11):3131-3134.
猜你喜歡
電腦愛好者(2020年6期)2020-05-26 09:27:33
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
信息安全與通信保密(2016年3期)2016-08-23 01:23:56
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:34
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:25
中國衛生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
