政府統計數據質量優化方法研究
2018-01-13 01:57:46蔣清泉
統計與決策 2017年24期
蔣清泉
0 引言
隨著大數據的爆炸發展,數據逐漸成為人們獲取信息的載體,通過數據可以了解當前社會經濟的發展狀態、生態環境的發展水平、消費者的需求以及金融資本的流向等,以前筆紙化的文本獲取方式逐漸被虛擬化的網絡記載所替代,以前信息的不對稱因為大數據的網絡傳播逐漸被改善。因此,數據化的建設顯得尤為重要和亟待解決。政府統計數據作為數據的重要組成部分,它的質量尤為重要。所以,研究和分析政府統計數據質量的相關影響因素是我國進行信息化建設、數據化發展不可忽視的重要課題。
為了更好地研究數據包含的信息,提高數據的質量,很多政府組織和學者從不同角度、不同層面對不同類型的數據進行了研究和分析。國際貨幣基金組織(IMF)為了研究數據問題,評估數據的質量,通過測量設計了三層測評指標對數據進行測量,后來的許多研究都會參考這些指標和測量架構進行相關研究。宋敏等學者[1]在對我國政府數據進行研究之前,首先分析國外政府數據的相關管理方法,通過匯總分析指出我國政府數據存在的一些不足和改進方向。孫海英[2]認為目前我國的政府數據存在著很多問題,主要在于管理不當,數據搜集前期的量表設計、數據搜集過程中的統計方法、數據處理后期的管理策略等都影響著數據的質量。程開明[3]提出在數量的輸出結果方面,應該根據目標群體使用的數據不同的情況而采用不同的方法衡量數據的質量,在評價數據質量時要結合實際情況針對不同數據的使用者指定測量量表,合理科學地管理數據。王建高等[4]認為人為干擾等非技術性因素、環境限制等客觀因素、技術性因素是影響基礎統計數據質量的主要因素。張衛華[5]分析了影響數據質量的因素,分析結果顯示統計制度、統計手段等方面是影響數據的主要方面,應該把握數據形成過程中的每一個環節,進行重點監控。馬元三[6]為了更好地研究數據質量問題,首先分析了數據形成的主要流程,然后針對不同階段提出管理建議和策略,提出要形成統一的管理制度和方法,保證數據搜集、加工、處理等工作的順利完成。曾曉峰[7]對統計數據形成的流程進行了分析,提出各個環節處理數據的方法,并強調數據形成的流程對于保障數據質量的有效性和準確性非常重要。賈靜等[8]另辟蹊徑,希望以統計方法、統計相關法律法規等人為因素,通過設計模型用統計方法進行分析,最后對數據的質量進行整體評價和研究。初蓓[9]通過分析發現,要重視數據形成過程中的人為因素,強調數據搜集環境的重要性。曾五一[10]從數據質量研究的目的出發,分析了數據質量研究的一些基本問題并對數據質量相關問題進行了探索。向蓉美[11]對國家統計數據質量的管理方法進行了探討和分析,并針對現有的管理方法進行概述,為以后的研究者提供參考和借鑒。李先鋒[12]以某一城市的政府數據為研究對象進行案例研究,分別從統計數據的管理機構、統計人員以及統計制度等進行分析,通過對不同相關因素進行分析找到各因素與數據質量之間的相關關系。綜上所述,可以看到部分學者從數據形成的流程和環節為研究切入點,針對流程和重要環境進行分析;部分學者從數據的統計方法和評價方法方面進行分析,希望找到影響數據質量的因素,提出改進方法和措施。
通過上述分析可以發現統計數據質量影響路徑優化方面研究較少,而偏最小二乘法在研究多變量關系以及優化檢驗方面具有許多優點,已有學者[13]通過運用偏最小二乘法解決影響路徑和優化問題。因此,本文以統計相關主體為切入點,從統計數據獲取路徑、發布路徑、監管路徑三個方面分析其對統計數據質量的影響,為了研究數據質量的影響因素構建優化模型并在已有研究的基礎上提出假設,探討各因素與數據質量間的相關關系。通過偏最小二乘法對數據進行分析,對模型假設進行檢驗,得到數據質量影響路徑的影響程度,并針對性地提出提升政府統計數據質量的優化方法。
1 偏最小二乘法
偏最小二乘法(PLS)是伍德和阿巴諾等人為了解決多元統計問題而提出的一種分析方法,偏最小二乘回歸開辟了一種新的技術途徑,該方法首先根據變量包含的信息對變量進行分解,然后根據條件和準則進行篩選,通過不斷地計算和處理得到一個因子,該因子包含的信息能夠最大化地解釋被解釋變量。偏最小二乘法可以實現包括典型相關分析、主成分分析、多元線性回歸分析等多種統計分析方法的功能,比較容易理解和分析。本文研究的數據質量優化問題中,樣本量較少,變量之間的相關性較大,使用偏最小二乘法,不僅可以充分提取樣本信息,還可以解決各因素間的相關性引起的共線性問題。對于統計數據影響路徑優化問題,因為研究樣本數量有限,偏最小二乘法更適合調查數據的客觀條件。
因此,運用偏最小二乘法解決這類問題可以概括為以下幾點原因:首先,因為使用統計數據的群體相對來說有限,想要調查對統計數據相關問題了解的人群又很少,調查數據獲取有限,將獲取的數據作為樣本大多數情況下僅僅為小樣本。其次在研究的統計數據質量相關維度中,不可能全部的數據類型都滿足測量型數據處理的要求。大多數的統計方法在進行分析前要檢驗數據是否滿足正態分布等條件,但是很多時候在進行數據和模型分析時會發現數據的樣本量很難獲取或者本來就是小樣本,并且很難滿足約束條件。而相對其他分析方法,偏最小二乘法不受樣本量和正態分布要求的限制,用該方法分析此類問題更有效,更便捷。
假設本文研究的樣本量為n,測量量表中分別包含a個被解釋變量{y1,…,ya}和b個解釋變量{x1,…,xb} 。分別用X和Y表示上述兩個變量的標準化數據,它們分別為:

首先,需要對變量進行降維處理,分別提取主成分{s1,…,sc} 和{t1, …,tc} ,其中 c=min{a,b} ,每個主成分包含被提取變量中最多的信息。為了保證s對t最大的解釋能力,sc和tc之間的相關度保持最大。因此,可以得到X組和Y組的第一個主成分分別為s1和t1,并且它們滿足以下關系式:
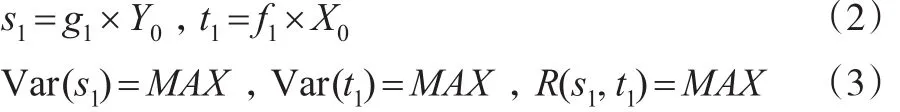
上式中g1和 f1表示第一主成分的系數向量。
然后,再分別建立Y1對t1和X1被t1的回歸方程:
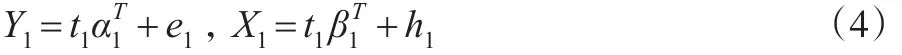
根據最小二乘估計原理得:
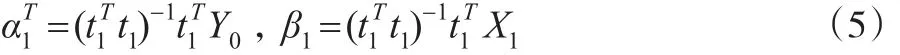
α1和β1為模型效應載荷量。
上述過程為變量信息提取過程,從上述過程可以發現在提取第一主成分時,只提取了大部分的信息,一些信息沒有提取出來。因此,需要對殘差矩陣e1、e2進行再提取,具體過程如下:
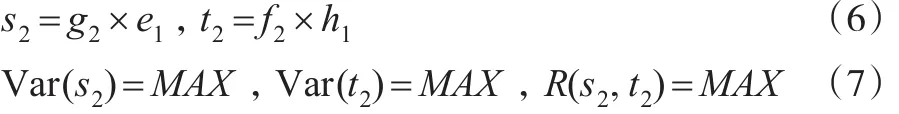
可以得到:
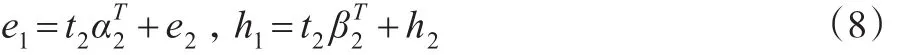
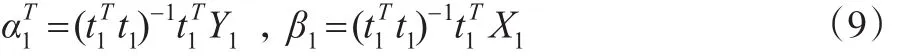
然后,通過變形轉換得到:
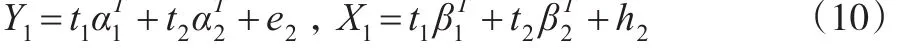
令n×b數據觀測矩陣的秩為Rank=min(n,b)=k,則存在k個成分t1,…,tk使得:
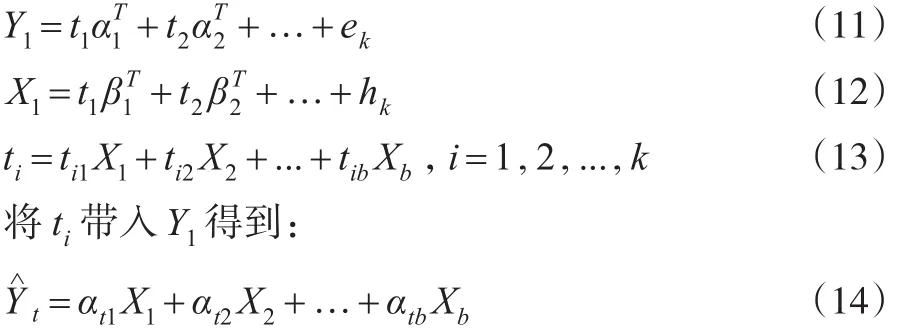
最后,通過類比推廣得到在非標準化情況下的模型為:
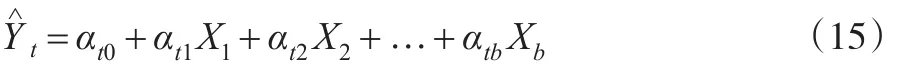
2 模型構建
為了探索優化數據質量的方法和措施,本文通過分析數據形成的直接相關者找到提升路徑,主要有數據來源者、數據處理者、數據監管者三個主體,數據形成的流程主要包括獲取、發布、監管等重要部分。因此,本文從數據來源者、數據處理者、數據監管者、數據獲取、發布、監管這六個方面進行研究,探索不同主體或流程對數據質量的影響,分析模型中各個變量間的關系,最終得到改善數據質量的路徑和優化方法。
數據獲取主要衡量被調查者的文化水平、配合度以及對其信息保密度方面對數據質量的影響,數據處理過程包括數據的整理錄入、匯總處理、加工發布等部分。在這些流程中,每一步都非常重要,一旦出現操作失誤或不當就會直接影響數據質量,因此統計工作對數據工作人員的統計方法和專業技能要求很高,要保障統計工作的硬件設施和信息化發展水平,以及統計工作的環境問題。數據監管可以包括兩個方面:一是組織內部的自我監管,工作人員不僅要自我監督進行復查和審核,員工之間還要相互監督,相互審核驗證。同時組織機構外部要形成監督力量,上級組織可以成立評估監察小組負責整個流程的監察,同時外部媒體、大眾等也可以根據實際情況進行有效的監督。在統計數據質量方面,本文參考王華等學者[14]提出的數據質量維度劃分標準,準確性、適用性是數據基本特征,方法健全性、制度合理性是數據質量生產方面的特征,及時性、可得性是數據發布方面的特征。通過對數據獲取、處理、發布等環節進行分析,通過分析研究,在參考國內外相關研究的基礎上,本文構建數據質量影響路徑分析模型如圖1所示。本文選取六個維度16個指標,通過設計測量量表進行調查,獲取樣本數據測量數據質量優化模型中指標間的結構關系。
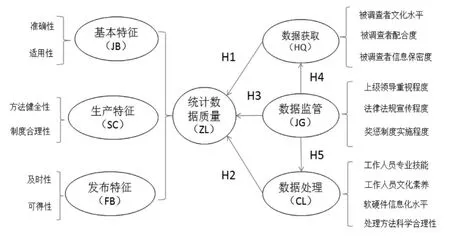
圖1 統計數據質量影響路徑模型
根據部分學者的研究以及實際中的認識,本文認為數據獲取方面、數據處理方面和數據監督方面對數據質量的影響為正向的。一線工作人員在數據搜集和調查中,在不影響搜集質量的情況下盡可能地提高工作效率。同時也可以通過數據改善統計分析和處理方法、提高硬件設施水平、刪減不必要的工作流程等保證數據質量的準確性和方法的健全性。而加強數據監管不僅可以對工作人員獲取進行監督和審查,保證數據的搜集、整理。并且還對數據的處理產生一定的影響,加強數據監管可以防止數據虛報、漏報、錯報,防止統計工作人員的人為操作,降低數據質量。根據上述分析,本文作出以下假設:
H1:數據質量與數據獲取路徑有正向的關系
H2:數據質量與數據處理路徑有正向的關系
H3:數據質量與數據監管路徑有正向的關系
H4:數據監管路徑對數據獲取路徑有正向影響
H5:數據監管路徑對數據處理路徑有正向影響
3 實證分析
為了研究改善數據質量的路徑和方法,本文通過搜索大量國內外參考文獻進行匯總整理和分析,構建了數據質量測量量表。為了保證調查對象的隨機性和有效性,本文更傾向于對經常使用數據的群體進行調查,以使被調查的信息更具有說服力。最終,回收有效樣本340份,滿足使用偏最小二乘法的要求。為了了解調查對象的基本情況本文通過描述統計分析,分析結果如表1所示。
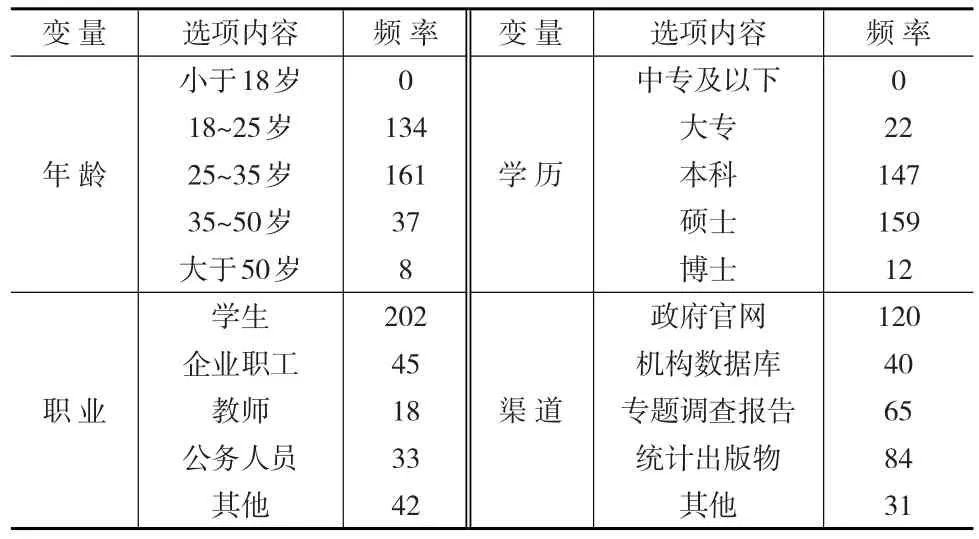
表1 調查對象基本信息
首先,進行信效度檢驗,信度表示用同一方法多次處理結果的一致性程度,效度表示研究數據反映研究問題的有效程度。按照業界的標準文章將對測量量表的區分效度和收斂效度進行檢驗,檢驗測量量表的有效性。國際上公認的區分效度合格標準是AVE(Average Variance Extracted)值大于0.6同時CR值要大于0.7(Composite Reliability),這時認為該量表具有一定的收斂效度。而當上述條件滿足時,如果變量間的相關系數小于對應AVE的平方根,這時可以認為該測量量表滿足區分效度檢驗。
為了檢驗本文所用測量量表的信效度,本文運用Smart PLS軟件對模型進行分析,通過模型分析得到結果如表2所示。分析結果顯示:潛變量數據質量的AVE值為0.6424大于0.6,Composite Reliability值為0.9151大于0.7;潛變量數據獲取的AVE值為0.7728大于0.6,Composite Reliability值為0.9107大于0.7;潛變量數據處理的AVE值為0.6756大于0.6,Composite Reliability值為0.8925大于0.7;潛變量數據監管的AVE值為0.7879大于0.6,Composite Reliability值為0.9175大于0.7;上述變量的AVE值都大于0.6,并且Composite Reliability值都大于0.7,這表明該測量量表具有收斂效度。同時,可以發現各個潛變量之間的對角線的數據都大于每一列的數值,這表示變量間的相關系數的平方小于AVE值,通過了區分效度檢驗,說明該測量量表具有一定的區分效度。綜上可知,本文所用量表具有有效性。
表2 信效度檢驗結果
運用軟件分析得到各個潛變量的載荷值,從表3中數據可以看到,各個潛變量的載荷值都大于0.7,超過業界公認的一般水平值,因此可以認為潛變量提取的信息可以有效的解釋變量之間的關系。分析結果也說明發布特征、數據獲取、數據監管以及數據質量的基本特征、生產特征、數據處理等變量所對應的觀測變量對結構變量的解釋度比較好,根據測量量表得到的數據可以分析得到模型中各變量間的結構關系。
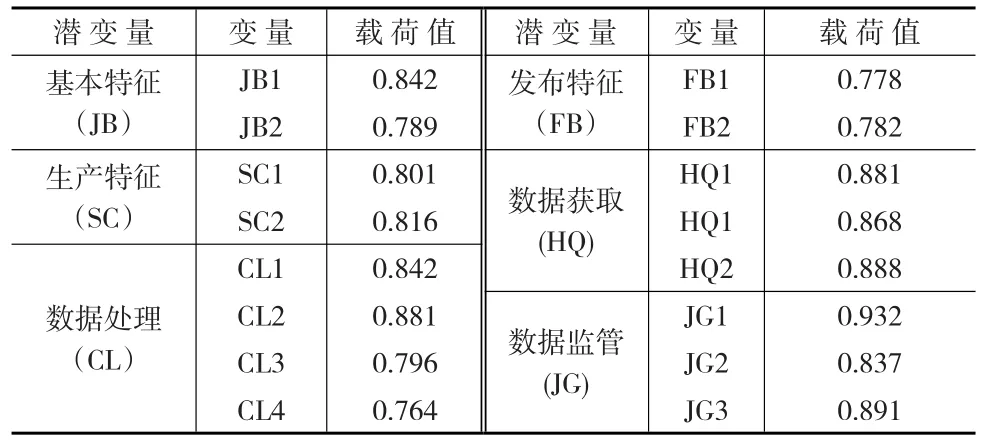
表3 各觀測變量載荷值
為了分析模型中各變量之間的相關關系,本文運用Smart PLS軟件對變量間的結構關系進行分析。數據結果顯示:模型的R平方值為0.697,這表示模型的擬合優度較好。為了更加直觀地了解模型處理結果,本文對數據結果進行匯總整理得到表4。
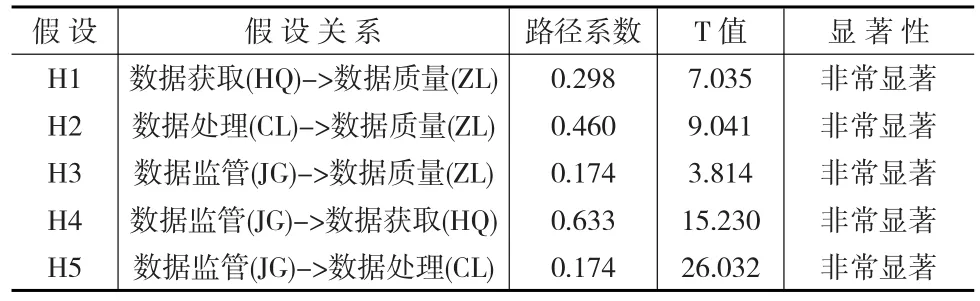
表4 假設檢驗結果
表4的分析結果顯示:數據獲取(HQ)與數據質量(ZL)間的路徑系數為0.298,大于零有正向的作用關系,同時T值為7.035大于1.96,表明線性關系非常顯著,假設一成立。根據假設一可以改善數據獲取流程,比如加強工作人員的技能培訓,更新硬件系統優化量表設計方案等,通過這些方式提升數據質量。數據處理(CL)與數據質量(ZL)間的路徑系數為0.460大于零,同時T值為9.041大于1.96,T檢驗非常顯著,表明假設二成立,數據處理的提高可以增加數據質量。數據監管(JG)與數據質量(ZL)間的作用為正相關,路徑系數為0.174,T值檢驗為3.814,大于1.96,非常顯著,說明假設三成立。數據監管(JG)與數據獲取(HQ)間的路徑系數為0.633,大于零有正向的作用關系,同時T值檢驗為15.230大于1.96,T檢驗非常顯著,假設四成立,這表明數據監管可以正向的影響數據獲取的效果,比如加強獎懲力度,加大監管法規建設等。數據監管(JG)與數據處理(CL)間的作用為正,路徑系數為0.174,T值為26.032,T檢驗非常顯著,假設五成立。加強監管不僅可以提高數據搜集的效率,保證數據快速有效的統計,并且可以加強數據的加工和處理,督促數據和信息的完成和發布。數據獲取、處理、監管這三個流程中,數據處理方面對數據質量的影響作用最大,其次為數據獲取和數據監管方面,并且數據監管對數據獲取和處理有正向的促進作用。
4 總結
為了探索數據質量的優化路徑和方法,本文以數據相關主體為切入點,分別從數據來源、處理、監管等流程探索數據獲取路徑、發布路徑、監管路徑對數據質量的影響。本文構建模型并提出假設,運用偏最小二乘法和相關軟件進行分析,通過假設檢驗和分析研究,最終得到如下結論:(1)數據處理方面對數據質量的作用最大,其中工作人員的專業技能和文化素養對數據處理作用明顯。因此,可以通過提高統計數據工作人員的文化程度和學習培訓,加強統計工作人員的專業技能,提升統計工作人員的基本素養,以此促進統計數據質量的提升。(2)統計數據監管方面對數據質量的影響相對較小,主要是因為監管手段和措施生硬,沒有創新。此外上級領導對統計工作的重視程度對監管效果的作用顯著,在統計工作中上級領導的重視程度直接影響著工作人員的積極性。(3)在數據獲取方面,數據獲取的質量直接與工作人員有關,因此對工作人員的專業素養和技能顯得非常重要,同時統計量表的設計、數據獲取的時間和形式也影響著數據的價值。此外,被調查者的配合度以及被調查者信息的保密度可以在短時間內得到提高,通過法規宣傳增加他們對統計工作的認識,保證他們的個人隱私不受侵害,獲得他們的支持和信任,提高獲取統計數據的質量。(4)數據監督路徑的提高可以對數據獲取和數據處理產生積極的作用,法律法規的宣傳實施、獎懲制度的實施可以在很大程度上提升數據獲取和處理的質量。
[1]宋敏,覃正.國外數據質量管理研究綜述[J].情報雜志,2007,(2).
[2]孫海英.當前政府統計體制對統計數據質量的影響分析[J].統計與管理,2015,(12).
[3]程開明.基于利益相關者視角的統計數據質量管理體系研究[J].商業經濟與管理,2013,(3).
[4]王建高,曹德.影響基礎統計數據質量的因素分析及其對策[J].青海統計,2012,(9).
[5]張衛華.淺談統計數據質量的應先因素及其控制[J].內蒙古科技與經濟,2011,(9).
[6]馬元三.基于全面質量管理的統計數據質量研究[J].宏觀經濟研究,2010,(11).
[7]曾曉峰,從統計流程談統計數據質量控制[J].中國統計,2008,(2).
[8]賈靜,樊相宇.基于結構方程模型的統計數據質量影響因素分析[J].西安郵電學院學報,2011,16(4).
[9]初蓓.影響統計數據信息質量的原因及對策[J].科技情報開發與經濟,2005,15(3).
[10]曾五一.國家統計數據質量研究的基本問題[J].商業經濟與管理,2010,(12).
[11]向蓉美.國家統計數據質量管理研究述評[C].政府統計數據質量研討會論文集,2010.
[12]李先鋒.DZ市政府統計數據質量影響因素研究[D].西安:西安科技大學學位論文,2013.
[13]程慧平,萬莉,張熠.基于偏最小二乘結構方程的我國區域圖書館發展水平研究[J].圖書情報工作,2015,59(12).
[14]王華,金勇進.統計數據質量與用戶滿意度:測評量表設計與實證研究[J].統計研究,2010,27(7).
猜你喜歡
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:08
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
全球化(2018年6期)2018-09-10 21:29:09
中國經貿導刊(2018年12期)2018-05-29 10:42:32
山東工業技術(2016年15期)2016-12-01 05:31:22
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
世界熱帶農業信息(2014年8期)2014-09-23 18:27:22
