一種基于OCC模型的文本情感挖掘方法
2017-12-05 11:22:22皇甫璐雯毛文吉
智能系統學報 2017年5期
皇甫璐雯,毛文吉
(中國科學院自動化研究所 復雜系統管理與控制國家重點實驗室,北京 100190)
一種基于OCC模型的文本情感挖掘方法
皇甫璐雯,毛文吉
(中國科學院自動化研究所 復雜系統管理與控制國家重點實驗室,北京 100190)
觀點挖掘(或情感分析)作為面向網絡社會媒體分析挖掘領域的一個核心研究課題,具有重要的研究意義和應用價值。針對傳統觀點挖掘方法存在的不足和局限性,本文設計并實現了一種基于OCC情感模型的觀點挖掘方法。該方法首先采用統計方法,利用WordNet詞典、句法依存關系及少量標注數據,自動構建情感維度詞典;其次,對所構建的情感維度詞典進行求精,通過語義、情感傾向的不一致性處理和非情感詞的過濾,得到高質量的情感維度詞典;最后,基于所得到的情感維度詞典,結合OCC模型中情感維度值與情感類型的對應關系,生成6種主要的情感類型。實驗方法表明,此方法在使用靈活性、可解釋性和有效性上具有明顯的優勢。
觀點挖掘;OCC情感模型;情感維度;情感類型;情感詞典;認知心理學;情感挖掘;共現
近年來,社會媒體迅猛發展并快速滲透到了社會、經濟、政治、文化等各方面,互聯網用戶產生的內容中包含大量關于用戶意見、態度、情緒等有價值的信息,而且其數量隨時間累積呈指數級增長。這些信息主要是用戶的主觀性觀點,與客觀的事實有很大的不同。這些包含用戶觀點的海量數據蘊含著巨大的實際應用價值,亟需自動化的計算分析與處理技術,這種現象促進了觀點挖掘與情感分析這一新興研究領域的蓬勃發展。目前,觀點挖掘(或情感分析)[1-2]已成為社會媒體分析挖掘領域的一個核心研究課題,其研究成果已應用于用戶觀點發現、產品評論分析及社會輿情監控等領域,并在推動社會和諧發展、改善人們生活方面發揮重要作用[3]。
互聯網中的文本數據大致可以分為兩類:一類用來陳述客觀性的事實,另一類用來表達主觀性的觀點。相對于客觀性的事實數據,主觀性的觀點數據由于其內在的復雜性,在研究方法和技術上與前者區別較大。目前觀點挖掘分為兩類工作:識別觀點的正負極性和文本中的情感類型。文本中的情感類型比正負極性包含更為豐富的信息,因而挖掘文本中的情感類型更具有挑戰性,但往往需要大量的手工標注數據,并且所獲得的情感類型常常缺乏可解釋性。
挖掘觀點正負極性的方法主要有文檔級觀點挖掘[3-4]、語句級觀點挖掘[5-8]、基于情感對象特征的觀點挖掘[9-10]等。Turney[4]提出了一種利用非監督學習方法計算詞之間的互信息(PMI)來判斷整個文檔的正負極性。Pang等[3]提出采用多種機器學習方法分類每篇電影評論的正負極性。Wiebe等[8]通過大量數據集學習線索和特征,區分主觀觀點和客觀事實,并在語句級判斷觀點的正負極性。Zhang等[11]提出利用詞之間的依賴關系分析中文語句的正負傾向性。Hu等[9]利用頻繁挖掘算法獲得情感對象特征,再利用語義詞典確定情感詞的正負極性,從而輸出針對每個情感對象特征的相關正負評論。
挖掘文本中情感類型的方法主要包括基于統計的方法[12]、機器學習方法[13-16]、基于情感結構/模型的方法[16-17]等。基于機器學習的情感類型挖掘工作主要采用分類學習算法[13-14,16,18-19]。Mostafa[17]提出了一種基于情感模型的方法,該方法利用大量的手工標注數據,并基于主要的情感變量計算語句中幾乎所有詞的情感變量值,進而計算得到整個語句的情感類型。但是,這種方法不但需要大量人力,費時費力,而且不加區分地計算句子中出現的詞,導致該方法的效率和性能較低。
綜上,觀點傾向性的傳統挖掘方法主要關注觀點的正負極性而忽略了其豐富的情感類型;已有的情感類型挖掘盡管能夠輸出豐富的情感類型,但是需要大量的標注數據支持。此外,以往工作幾乎都未考慮情感認知理論模型在觀點挖掘和情感分析中的重要作用。因此,為了更好地實現從網上文本數據中挖掘出豐富的情感類型,文中提出一種基于OCC情感模型的觀點挖掘方法。
1 情感的認知結構模型OCC
認知評估理論[20-23]是認知心理學研究中最為成熟和影響最廣的情感理論。認知評估理論認為評估過程是個體評價其與所處環境間的關系,包括目前的條件、導致當前狀態的事件和對未來的預期。評估理論認為評估本身盡管不是一個慎思的過程,但其確實由認知的過程提供信息,尤其是那些參與理解和與環境交互的過程。評估將這些異類過程的特征映射到一個共同的中介術語集(即維度變量)。這些維度變量作為個體與環境之間關系的中介描述,在刺激源和反應之間進行協調。維度變量刻畫了對個體而言事件的重要特征。
認知評估理論中的不同情感模型采用了不同的情感維度變量,但它們所使用的情感維度變量間有很大的相似性,其中文獻[23]工作中的分類最全,包括相關性(relevance)、合意性(desirability)、行動性(actionability)、責備/褒獎(praise/blame-worthiness)、可能性(likelihood)、意外性(unexpectedness)、自我投入(ego-involvement)、可控性(controllability)、權力(power)、適應性(adaptability)。
不同的情感維度變量及其取值產生不同的情感類型。比如,在一個具體的經濟環境下,“賠錢”是個不合人意的事件,并導致負性情感評估。在此情形下,其他變量的不同取值可引發不同的情感評估。諸如,如果可能性是不確定的,引發“恐懼”(fear)情感,否則引發“悲傷”(distress)情感。自我的行動帶來應受到責備的行為后果引發“羞恥”(shame),如果事件是不合己意的,則帶來“悔恨”(remorse)。如果不合己意的事件帶來的后果是他人應受到責備的行為引發的,則導致“生氣”(anger)情感。
OCC情感模型[21]是認知心理學中經典的情感認知結構模型,也是在計算領域近年來采用最多的心理學情感模型,在情感的計算建模中有著非常廣泛的應用。
OCC情感模型的整個層次結構主要包括3個部分:與事件結果相關的情感,與智能體行為相關的情感和與對象屬性相關的情感。這3個部分也可以結合起來組合成更為復雜的情感類型。該模型共描述了22種不同情感類型的認知結構。OCC模型中每個情感類型的出現都由一定的條件觸發,這些條件通過不同的情感維度值表達。其中,“合意性(desirability)” “褒貶性(praise-/blame-worthiness)”和“可能性(likelihood)”是該模型中3個最為重要的情感維度變量。“合意性”與主體的目標相關聯,“褒貶性”與行為是否符合社會道德標準相關聯,而“可能性”則表示對事件發生的期望。
在情感認知結構理論中,每個情感維度變量有不同的取值。“合意性(desirability)”維度的取值包括“合意的(desirable)”和“不合意的(undesirable)”。當某些事件的發生有利于最終目標的實現時,這種情況對于主體而言是合意的;反之則是不合意的。類似地,“褒貶性(praise-/blame-worthiness)”維度的取值有“值得稱贊的(praiseworthy)”和“應受責備的(blameworthy)”。“可能性(likelihood)”維度有“可能的(likely)”和“確定的(certain)”這兩個取值。情感維度變量的不同取值及其組合可以生成不同的情感類型。例如,如果“合意的”事件的可能性是“確定的”,引發“高興(joy)”情感;否則引發“希望(hope)”。如果個體“值得表揚的(praiseworthy)”行為帶來合乎自己心意的行為后果,則導致“驕傲(pride)”情感的產生。表1給出了3個情感維度變量與情感類型之間的對應關系。
表13個情感維度變量及其對應的情感類型
Table1Threeemotionaldimensionvariablesandtheircorrespondingemotiontypes

合意性褒貶性可能性情感類型合意的—確定的高興不合意的—確定的悲傷合意的—可能的希望不合意的—可能的恐懼合意的值得稱贊的確定的驕傲不合意的應受責備的確定的羞恥
表1左邊3列是情感維度取值列表,右邊一列是在特定的情感維度取值下所產生的情感類型。本文的研究思路基于經典的OCC情感模型,選取其最主要的3個情感維度,以挖掘文中包含的這3類維度變量的情感。
詞為重點,通過建立相應的情感維度詞典,自動推演出6種主要的情感類型:高興(joy)、悲傷(distress)、希望(hope)、恐懼(fear)、驕傲(pride)和羞恥(shame)。
2 基于OCC模型的情感挖掘方法
結合前面介紹的OCC情感認知結構模型,建立自動識別文本中情感類型的方法。基于OCC模型的情感類型挖掘問題可以分解成兩個子問題:1)自動構建高質量的情感維度詞典,即建立包括具體的詞和抽象的情感維度值之間的映射關系;2)基于OCC模型,以規則的形式建立情感維度值與情感類型間的對應關系。構建情感維度詞典則是建立文本情感類型識別系統的關鍵。情感維度詞典涵蓋了比通常僅包含正負極性的情感詞庫更豐富的信息,所以在構建情感維度詞典時,綜合考慮了依存句法關系、語義關系和統計信息。由于構建后的情感維度詞典存在語義、情感傾向的不一致性等問題,因此還需要對情感維度詞典進一步求精,過濾掉低質量的候選詞。
圖1是基于OCC情感模型的觀點挖掘方法的數據流圖,主要由情感維度詞典的構建、求精和情感類型的生成3個模塊組成。該方法基于海量開源文本輸入,以句子為單位輸出情感類型及其關聯的情感對象。其中,情感維度詞典的構建模塊利用通用語義詞典和句法依存關系建立關于各情感維度值的詞典,情感維度詞典的求精模塊包括語義、正負情感傾向的不一致性處理和非情感詞的過濾。針對前2個模塊,文中還提出了融合Bootstrapping的構建與求精同步的改進算法。情感類型的生成模塊基于前2個模塊得到情感維度詞典,利用經典的OCC情感模型,獲得情感類型。最后,得到情感類型與情感對象相結合的輸出結果,以滿足用戶需求。
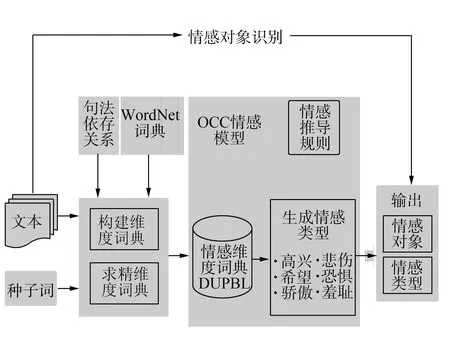
圖1 基于OCC模型的本文情感挖掘方法Fig.1 OCC model-based emotion mining method from texts
2.1 情感維度詞典的構建與求精
情感維度詞典是基于WordNet詞典和句法依存關系,采用統計的方法自動構建的。WordNet詞典可以提供詞的語義解釋和詞之間的關系,有同義詞、反義詞、還原詞、派生詞等。句法依存關系是指,通過句法分析樹中得到的詞之間存在的聯系,可以提示詞之間潛在的關系。
為自動構建情感維度詞典,首先手工挑選少量高質量的情感維度值種子詞(不超過10個)和4個依存關系模板。其中,關于每個情感維度值的種子詞包含詞的原型和詞性信息。加入詞性信息是因為相同的詞在詞性不同的時候含義大不相同,例如:sentence做動詞時,意思為“判刑”,維度是Blameworthy;但是做名詞時,意思為“句子”,可以認為不是情感詞。4個依存關系包括conj_and、conj_or、prep_in和parataxis。其含義分別是詞之間的并列and關系、詞之間的并列or關系、詞之間的介詞in關系和2個詞在分句中所處的并列關系。然而,僅僅依靠依存關系可能會有一些問題。比如,簡單的并列關系“wonderful and exciting”中wonderful和exciting是同義詞關系;而在另一個短語“young and old”中,young和old有著強烈的反義詞關系而不是同義詞關系。由此可見,盡管模板conj_and可以提示詞之間存在語義關系,但是這種語義關系到底是一致還是恰好相反需要借助詞典來進一步判斷。因此,基于詞典的方法不但用來尋找候選的情感維度詞,而且用來判斷候選情感維度詞的情感維度值的合理性。
在第一輪循環開始,對于每種情感維度值挑選少量高質量的種子詞,作為初始的情感維度詞典輸入。情感維度詞典包括DICD(合意的)、DICU(不合意的)、DICP(值得稱贊的)、DICB(應受責備的)。挑選情感維度種子詞有多種策略,可以通過手工查看數據集憑經驗進行挑選或者通過計算詞出現的頻率挑選出頻率高并且包含情感維度值的詞作為種子詞。
2.1.1 構建過程
在每一輪循環中,用WordNet和手工挑選的模板不斷地抽取不同維度值下的情感詞。在每一輪循環后,利用一個基于共現思想的評分函數來評估抽取的情感維度詞。情感維度詞典的構建過程如下。
1)針對情感維度詞典中每個新加入的情感維度詞,基于WordNet詞典,找出其同義詞和反義詞,并將其同義詞和反義詞分別放入相應的情感維度詞典候選集中。
2)利用前面提到的4個句法依存關系從輸入的海量文本中找出與所述相應的情感維度詞典中已有的情感維度詞具有依存關系的新情感維度詞,放入相應的情感維度詞典候選集中。
3)利用(1)式所示的評分函數對相應的情感維度詞典候選集進行評價與過濾,選取其中評分大于閾值的候選集中的情感詞,放入相應的情感維度詞典中:
4)不斷重復步驟2)~3),直到不再有新的情感維度詞加入;
5)利用WordNet中的派生以及還原關系擴充情感維度詞典。
構建情感維度詞典過程中的輸入是海量的文本和關于某個情感維度值的種子詞,輸出是針對這個情感維度值建立起來的情感維度詞典。這里涉及3個維度,6個維度值,情感維度值可以是“合意的” “不合意的” “值得稱贊的” “應受責備的” “可能的”和“確定的”,分別簡寫為“D” “U” “P” “B” “L” “C”。其中L、C情感維度詞典的構建僅僅依賴WordNet中詞之間的語義關系,并且Likelihood維度的默認值為C。
循環初始時挑選的高質量情感維度種子詞為1)和2)提供一個良好的基礎。1)和2)的目的是分別基于詞典和基于依存關系獲得候選的情感維度詞。3)通過計算一個評分函數保證進入情感維度詞典的詞的質量。最后,在情感維度詞典中的詞基于WordNet中的同義、反義、還原和派生關系進行擴充。比如,如果“harm”是在情感維度詞典中維度值為“blameworthy”的詞,擴充它的派生詞“harmful”到情感維度詞典中,同時它的情感維度值也為“blameworthy”。
評分函數f(v∈DICk)主要是基于共現的思想,如果待評價的情感詞與某一已知情感維度值的情感詞共同出現的次數越多,則該情感詞的維度值就更有可能成為該情感維度值。在每一輪循環中,評分函數利用WordNet詞典和句法依存關系得到候選集,通過設定共現次數的閾值θ1,過濾掉低質量的候選情感維度詞。這里v是當前待評價的候選情感詞,u是已知情感維度值為k的情感維度詞典中的詞,k的取值可以是“D” “U” “P” “B”。DICk是當前生成的維度值為k的情感維度詞典,|DICk|表示情感維度詞典元素個數。DIC是當前所有情感維度詞典的并集,其元素個數為|DIC|。函數c(v,u) 表示詞v和詞u在同一語句中共現的次數。評分函數中詞v是否屬于某類情感維度詞典的計算既考慮了v與該類情感維度詞共現的次數(作為后驗),也考慮到該類情感維度詞典在當前所有情感維度詞典中所占的詞的比例(作為先驗)。
2.1.2 求精過程
構建完成后的情感維度詞典往往存在不一致性或者噪聲,包括語義不一致性、情感傾向不一致性,以及非情感詞等。因此利用情感維度詞的同義詞集合和反義詞集合檢查情感維度詞的正負傾向,從而過濾掉質量低的情感維度詞,完成情感維度詞典的求精過程。
語義不一致性是指同一個詞在同一情感維度上具有相互矛盾的取值,比如在“褒貶性”維度上同時具有“P”和“B”這兩個維度值或者在“合意性”維度上同時具有“D”和“U”這兩個維度值;情感傾向不一致性是指一個詞同時具有正負情感傾向相互沖突的情感維度值。情感詞的極性可以是正向或負向。根據含義可知,“P”和“D”表示對情感對象的正面態度或評價,故極性為正;“B”和“U”表示對情感對象的負面態度或評價,故極性為負。若檢測到語義或情感傾向不一致的詞,對該情感詞的求精方法根據通用語義詞典中的同義和反義關系共同確定其情感傾向。當前待求精的情感維度詞的計算公式如式(2):
式中:nSyn、nAnt分別是當前待求精的情感詞的同義詞和反義詞的總數,nSyn+、nSyn-分別是該詞的極性為正和為負的同義詞個數,nSyn-、nAnt-分別是該詞的極性為正和為負的反義詞個數。同時,為了保證同義詞和反義詞集合的均衡性,將其歸一化后相加。如果計算得到的score值小于某一閾值θ2,則過濾掉該情感詞。由于以往相關工作中已建立了多個關于情感詞的正負極性詞典,這里nSyn、nAnt的正負極性可通過參照這些情感極性詞典來確定。
非情感詞包括無實際意義的詞,如具體數字、代詞等,也包括中性的名詞和動詞。過濾的方法包括直接列出這些明顯的不應該加入的詞加以過濾,或者計算情感傾向,將某一閾值范圍內的詞剔除。
除了以本身建造的情感維度詞典作為極性詞典,還采用一個公開的極性詞表[9]。選擇這兩個極性詞典的原因是它們的優勢可以互補。構建的情感維度詞典能夠覆蓋到較大集合的情感維度詞,詞性詞表盡管質量高,但是包含詞的數量非常有限,并且只有詞的極性信息。所以,兩者結合后彼此揚長避短。同時可以通過(3)式進一步提高詞的質量。
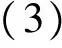
(0≤α≤1)
式中scorepolarity1和scorepolarity2雖然基于相同的(2)式,但是分別利用了上面提到的不同的極性詞典計算而得的。通過設定score的閾值,以避免加入質量過低的詞。
2.2 情感類型的生成
完成構建和求精情感維度詞典后,便可以利用OCC情感模型生成情感類型。情感類型的生成基于情感認知結構模型,根據該模型中每種情感類型與情感維度及其取值的對應關系,自動生成6種主要的情感類型。具體地說,“合意性”維度值為“合意的”并且“可能性”維度值為“確定的”時對應的情感類型為“高興”;“合意性”維度值為“不合意的”且“可能性”維度值為“確定的”對應的情感類型為“悲傷”;“合意性”維度值為“合意的”且“可能性”維度值為“可能的”對應的情感類型為“希望”;“合意性”維度值為“不合意的”且“可能性”維度值為“可能的”對應的情感類型為“恐懼”;“合意性”維度值為“合意的”,“褒貶性”維度值為 “值得稱贊的”且“可能性”維度值為“確定的”對應的情感類型為“驕傲”;“合意性”維度值為“不合意的”, “褒貶性”維度值為“應受責備的” 且“可能性”維度值為“確定的”對應的情感類型為“羞恥”。工作實現的6種情感類型生成規則如下。
規則1 如果“合意性”維度值=“合意的”并且 “可能性”維度值=“確定的”對應的情感類型=“高興”。
規則2 如果“合意性”維度值=“不合意的” 并且“可能性”維度值=“確定的”對應的情感類型=“悲傷”。
規則3 如果“合意性”維度值=“不合意”并且“可能性”維度值=“可能的” 對應的情感類型=“希望”。
規則4 如果 “合意性”維度值=“不合意的”并且“可能性”維度值=“可能的”對應的情感類型=“恐懼”。
規則5 如果“合意性”維度值=“合意的”并且“褒貶性”維度值=“值得稱贊的” 對應的情感類型=“驕傲”。
規則6 如果“合意性”維度值=“不合意的”并且“褒貶性”維度值=“應受責備的” 對應的情感類型=“羞恥”。
根據前述的情感類型的生成過程,下面給出一個具體示例。
圖2是對句子“US’s providing aid is a step in the right direction.”的情感類型挖掘過程。查看情感維度詞典,可得到這句話中包含2個情感維度詞,分別是“is”和“right”。其中,“is”的情感維度“可能性”取值為“確定的”,“right”的情感維度 “合意性”取值為“合意的”,情感維度“褒貶性”的取值為“值得稱贊的”。再根據情感類型生成規則1和規則5得到兩種情感,分別為“Joy(高興)”和“Pride(驕傲)”。
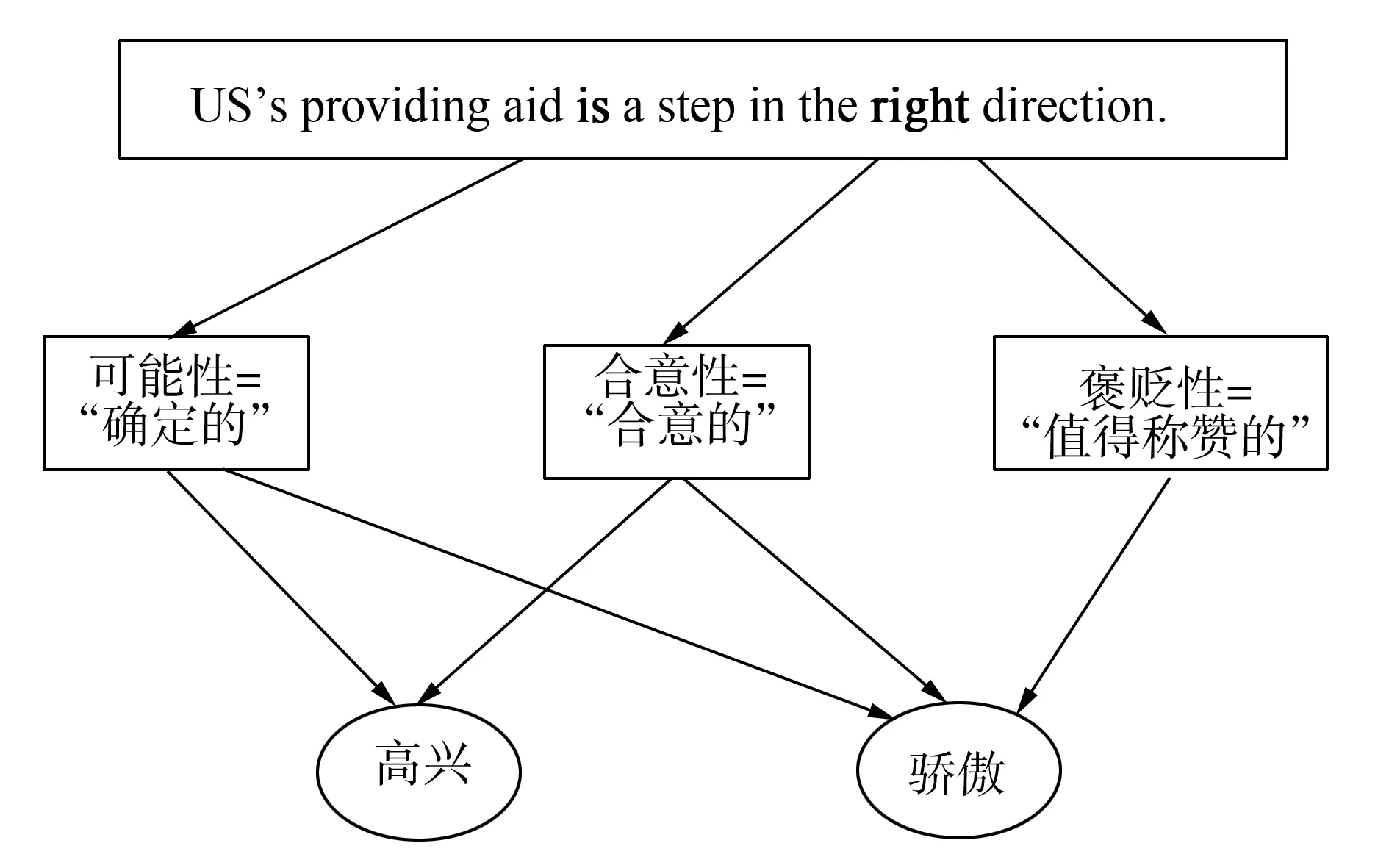
圖2 情感類型生成示例圖Fig.2 Generation of emotion types example
由此可見,通過求精后的情感維度詞典和OCC模型,最后生成多種情感類型是切實可行的。與這些情感類型相關聯的情感對象則通過由文獻[9]提出的頻繁情感對象識別算法進行挖掘。下面是一些輸出結果的示例:
North Korea is in a bad situation.
=gt;(North Korea ,{Distress});
It was very wise for us to compromise and to promise food aid.
=gt;(food aid,{Joy, Hope, Pride}).
Consequently, this deal is brilliant.
=gt;( deal,{Joy, Pride}).
2.3 實驗結果與分析
為實際驗證提出的基于OCC情感模型的挖掘方法,文中基于網上新聞評論數據,設計實驗方法,對所建立的情感維度詞典進行有效性驗證。
2.3.1 數據獲取
從紐約時報抓取了2002年1月1日~2012年1月1日這10年間的16 398個新聞評論數據作為實驗數據,然后利用斯坦福的句法分析器將句子的成分都提取出來,并且手工定義高質量的情感維度種子詞,覆蓋情感維度值包括“D” “U” “P” “B” “L”。全部種子詞如表2(括號外為情感維度詞,括號內為情感維度詞的詞性)所示。

表2 情感維度種子詞
基于情感維度種子詞,利用WordNet詞典和句法依存關系得到情感維度詞的候選集合,并基于共現思想進行過濾,進而獲得高質量的情感維度詞,建立相應的情感維度詞典。對情感維度詞典的求精過程完成語義、情感傾向的不一致處理和非情感詞的過濾。由于維度L主要通過同義詞和反義詞獲得,文中僅驗證情感維度詞典DUPB的性能。詞典DUPB在求精前和求精后所包含詞的數目如表3所示。
表3求精前后情感維度詞典
Table3Emotion-dimensiondictionariesbeforeandafterrefinement

階段DUPB求精前(含重復)203316219109034108求精后(α=0.3,β=0.65)13071467794895
2.3.2 實驗設計
為了保證標注數據的客觀性,請兩個標注者分別獨立標注了237個測試數據。若標注者認為一句話中某個單詞包含某種情感維度值,就將其連同維度值一起標注出來。為了檢查兩個標注者的一致程度,采用式(4)計算其Kappa值:
其中,Pr(a)表示實際標注時的一致程度,Pr(e)表示隨機情況下期望的一致程度。實驗中兩個標注者的Kappa值為0.613(Kappa值大于0.6表明一致程度較好)。
基于標注數據,利用精度、召回率和F值這3個指標對情感維度詞典DUPB進行定量評價。F值的計算公式為
式中:F-value表示F值,precision表示精度,recall表示召回率。
2.3.3 實驗結果
平均精度、召回率和F值的實驗結果如表4所示。
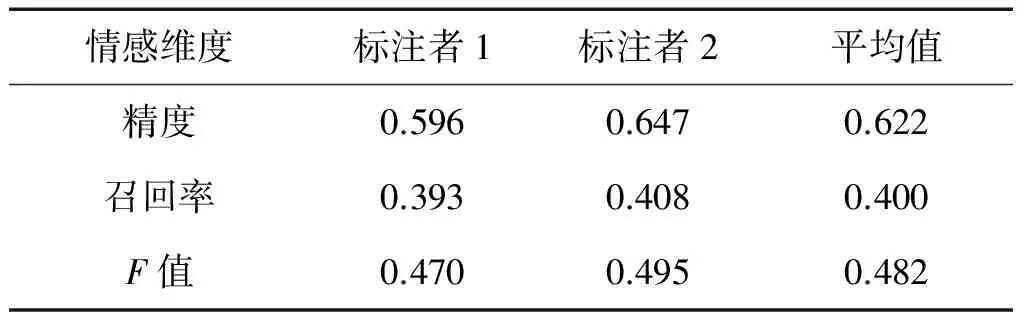
表4 實驗結果
由表4可知,平均精度、召回率和F值分別為0.622、0.400和0.482。可以看到,情感維度詞典DUPB的平均精度較好但召回率還比較低,導致召回率較低的一個原因是情感維度詞典中的情感維度詞的數量有限,對于驗證集中的情感維度詞覆蓋程度不足,因此召回率不高。
2.3.4 結果分析及改進
上面介紹的基于OCC模型的情感挖掘方法仍存在一些可改進之處,如:將情感維度詞典的構建和求精分開進行,使用預先定義的固定模板,以及不加區分地對待詞之間的共現情形等。特別是,考慮到情感維度詞和模板之間的相互關聯,可以通過兩者之間的互學習促進情感挖掘的性能。
針對以上不足,文中考慮了融合Bootstrapping的改進方法。該方法將情感維度詞典的構建和求精在同一個循環中完成。算法的主要思想是利用情感維度詞與模板進行互學習,并且對兩者分別進行評分。基于情感維度詞在模板前后的維度值,對模板進行評分,將一致性/不一致性用模板的可區分性指標進行刻畫。這里的可區分情況有兩種:一種是模板前后的詞維度恰好一致,另一種是模板前后的詞維度恰好相反。如果一個模板在這兩種情況中的一種占大多數,則該模板的質量較好。基于模板,對情感維度詞進行評分,將情感維度詞屬于某個情感維度值的概率用可靠性進行刻畫。此外,用相關性刻畫某一模板與情感維度詞共現的程度,用傾向性刻畫某一情感詞的極性值。
3 結束語
本文提出了一種基于認知心理學領域發展成熟的情感認知結構模型OCC,設計并實現了一種基于OCC情感模型的觀點挖掘方法,并采用網上新聞評論數據,采用實驗方法初步驗證了文中方法的有效性。與相關工作比較,該方法所需要的人力少,且在使用靈活性和有效性上具有明顯的優勢。同時,本文基于經典的情感認知結構模型,不但給文本情感分析這一研究問題賦予了更深層次的認知結構關聯,而且為情感類型的輸出維度提供了一個建立在認知心理學模型基礎上的更加精細的解釋。
[1]CHEN, Hsinchun. AI and opinion mining, part 2[J]. IEEE intelligentsystems, 2010, 25(4): 72-79.
[2]CHEN, Hsinchun, DAVID Z. AI and opinion mining[J]. IEEE intelligentsystems, 2010, 25(3): 74-80.
[3]PANG B, LEE L, VAITHYANATHAN S. Thumbs up?: sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10. Stroudsburg,USA, 2002: 79-86.
[4]TURNEY P D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, USA, 2002: 417-424.
[5]WIEBE J, WILSON T, BRUCE R, et al. Learning subjective language[J]. Computational linguistics, 2004, 30(3): 277-308.
[6]ATTARDI G, SIMI M. Blog Mining through opinionated words[C]//Fifteenth Text Retrieval Conference, Trec 2006.Gaithersburg, USA, 2006.
[7]HATZIVASSILOGLOU V, WIEBE J M. Effects of adjective orientation and gradability on sentence subjectivity[C]//Proceedings of the 18th Conference on Computational Linguistics-Volume 1. Stroudsburg, USA, 2000: 299-305.
[8]RILOFF E, WIEBE J, WILSON T. Learning subjective nouns using extraction pattern bootstrapping[C]//Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003-Volume 4. Stroudsburg,USA,2003: 25-32.
[9]HU M, LIU B. Mining and summarizing customer reviews[C]//Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2004: 168-177.
[10]HU M, LIU B. Mining opinion features in customer reviews[C]//AAAI. 2004, 4(4): 755-760.
[11]ZHANG C, ZENG D, LI J, et al. Sentiment analysis of Chinese documents: from sentence to document level[J]. Journal of the American society for information science and technology, 2009, 60(12): 2474-2487.
[12]READ J. Recognising affect in text using pointwise-mutual information[D]. Brighton:University of Sussex,2004:1-29.
[13]MISHNE G. Experiments with mood classification in blog posts[C]//Proceedings of ACM SIGIR 2005 Workshop on Stylistic Analysis of Text for Information Access. Stroudsburg,USA, 2005: 19.
[14]ALM C O, ROTH D, SPROAT R. Emotions from text: machine learning for text-based emotion prediction[C]//Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing. Association for Computational Linguistics,2005: 579-586.
[15]FENG S, WANG D, YU G, et al. Extracting common emotions from blogs based on fine-grained sentiment clustering[J]. Knowledge and information systems, 2011, 27(2): 281-302.
[16]KESHTKAR F, INKPEN D. Using sentiment orientation features for mood classification in blogs[C]//Proceedings of the IEEE International Conference on Natural Language Processing and Knowledge Engineering (IEEE NLP-KE 2009).Dalian, China, 2009.
[17]SHAIKH M A M. An analytical approach for affect sensing from text[D]. Toyko: University of Tokyo,2008: 1-111.
[18]YANG C, LIN K H Y, CHEN H H. Building emotion lexicon from weblog corpora[C]//Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions. Stroudsburg, USA, 2007: 133-136.
[19]MAO Y, LEBANON G. Sequential models for sentiment prediction[C]//ICML Workshop on Learning in Structured Output Spaces. Pittsburgh, USA, 2006.
[20]FRIJDA N H. The emotions[M]. New York: Cambridge University Press, 1986.
[21]ORTONY A. The cognitive structure of emotions[M]. New York: Cambridge University Press, 1990.
[22]LAZARUS R S. Emotion and adaptation[M]. New York: Oxford University Press, 1991.
[23]SCHERER K R, SCHORR A E, JOHNSTONE T E. Appraisal processes in emotion: theory, methods, research[M]. New York: Oxford University Press, 2001.

皇甫璐雯,女,1988年生,碩士研究生,主要研究方向為社會媒體信息分析與處理、情感分析與觀點挖掘。

毛文吉,女,1968年生,研究員,博士生導師,主要研究方向為智能信息處理、人工智能、社會計算。
OCC-model-basedtext-emotionminingmethod
HUANGFU Luwen, MAO Wenji
(State Key Laboratory of Management and Control for Complex Systems, Institute of Automation, Chinese Academy of Science, Beijing 100190, China)
Opinion mining, also called sentiment analysis, as one of the core research areas in the network-oriented social media analysis and mining domain, has important practical and research significance. Due to the weaknesses and limitations of traditional opinion mining methods, in this study, we designe and implemente an OCC emotion model-based opinion mining method for extracting emotion types from text. First, we adopte a statistical method to construct an emotion dictionary, based on candidate sets collected by the WordNet dictionary, as well as several syntactic dependent relationships and a small amount of annotated data. Next, we refine the constructed emotion-dimension dictionary to improve its quality by filtering out non-emotional words as well as emotional words that have conflicting syntactic or orientation. Lastly, we generate six main emotion types based on the obtained emotion-dimension dictionary combined with the corresponding relations between emotional dimensions and the different emotion types identified by the OCC model. Experimental results show that the proposed method has obvious advantages with respect to flexibility of usage, interpretability, and effectiveness.
opinion mining; OCC emotion model; emotional dimension; emotion types; emotion dictionary; cognitive psychology; emotion mining; co-occurrence
10.11992/tis.201312032
http://kns.cnki.net/kcms/detail/23.1538.TP.20171021.1342.002.html
TP391
A
1673-4785(2017)05-0645-08
中文引用格式:皇甫璐雯,毛文吉.一種基于OCC模型的文本情感挖掘方法J.智能系統學報, 2017, 12(5): 645-652.
英文引用格式:HUANGFULuwen,MAOWenji.OCC-model-basedtext-emotionminingmethodJ.CAAItransactionsonintelligentsystems, 2017, 12(5): 645-652.
2013-12-17. < class="emphasis_bold">網絡出版日期
日期:2017-10-21.
國家自然科學基金項目(61175040, 71025001).
毛文吉. E-mail:wenji.mao@ia.ac.cn.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
