人臉識別背后的數(shù)據(jù)清理問題研究
2017-12-05 11:22:19夏洋洋龔勛洪西進(jìn)
智能系統(tǒng)學(xué)報 2017年5期
夏洋洋,龔勛,洪西進(jìn),2
(1.西南交通大學(xué) 信息科學(xué)與技術(shù)學(xué)院,四川 成都 611756; 2. 臺灣科技大學(xué) 資訊工程系,臺灣 臺北 10607)
人臉識別背后的數(shù)據(jù)清理問題研究
夏洋洋1,龔勛1,洪西進(jìn)1,2
(1.西南交通大學(xué) 信息科學(xué)與技術(shù)學(xué)院,四川 成都 611756; 2. 臺灣科技大學(xué) 資訊工程系,臺灣 臺北 10607)
人臉識別技術(shù)在深度卷積神經(jīng)網(wǎng)絡(luò)(deep convolution neural networks, DCNN)的快速發(fā)展下取得了顯著的成就。這些成果主要體現(xiàn)在更深層次的DCNN架構(gòu)和更大的訓(xùn)練數(shù)據(jù)庫。然而,由大多數(shù)私人公司持有的大型數(shù)據(jù)庫(百萬級)并不對外公開,即使當(dāng)前部分開放的大型數(shù)據(jù)庫,因為標(biāo)注信息過少,無法保證精度,會影響DCNN的訓(xùn)練。本文提出了一種易于使用的多角度清理圖像方法來提高數(shù)據(jù)的準(zhǔn)確性:通過人臉檢測算法清除掉無法檢測到人臉的圖像;在清理后的數(shù)據(jù)集上利用已有模型提取圖像特征,并計算相似度,進(jìn)而統(tǒng)計出一類人臉圖像中每一張圖像與其他圖像不相似的數(shù)目,根據(jù)改進(jìn)參數(shù)清理數(shù)據(jù)。實驗表明,清理后的數(shù)據(jù)庫訓(xùn)練模型在LFW和Youtube Face數(shù)據(jù)集上測試的精度得到了提升,使用較小規(guī)模數(shù)據(jù)集情況下,在LFW數(shù)據(jù)集上取得了99.17%的準(zhǔn)確率,在Youtube Face數(shù)據(jù)集也達(dá)到了93.53%的準(zhǔn)確率。
深度卷積神經(jīng)網(wǎng)絡(luò);DCNN;清理圖像;人臉識別;大型數(shù)據(jù)庫
構(gòu)建一個完整的人臉識別系統(tǒng)主要包括圖像采集、人臉檢測、人臉對齊、特征表示與分類識別等步驟。人臉識別技術(shù)的核心在于特征提取和分類識別,而特征提取則是人臉識別的重點關(guān)注點[1-3]。深度學(xué)習(xí)與傳統(tǒng)人臉識別技術(shù)的主要區(qū)別在于:深度學(xué)習(xí)是通過從海量數(shù)據(jù)中有監(jiān)督的訓(xùn)練學(xué)習(xí)來獲取能夠有效表示人臉信息的特征,不再需要大量的人臉識別先驗知識來設(shè)計特征,這種人臉面部特征學(xué)習(xí)更具魯棒性[4-6]。深度卷積神經(jīng)網(wǎng)絡(luò)(DCNN)作為一種深度學(xué)習(xí)架構(gòu),已成功應(yīng)用于人臉識別和其他計算機(jī)視覺任務(wù),并逐漸成為一種通用算法[1,4-5,7-10]。雖然DCNN是通過從大量數(shù)據(jù)中自動學(xué)習(xí)更具區(qū)分力的特征,人臉識別的主要目的也是通過從海量數(shù)據(jù)中學(xué)習(xí)具有泛化能力的人臉特征,但最大的挑戰(zhàn)是如何訓(xùn)練更好的DCNN算法。目前可以通過以下兩種方式進(jìn)行提升:設(shè)計更強(qiáng)表達(dá)能力的網(wǎng)絡(luò)結(jié)構(gòu);使用規(guī)模更大的數(shù)據(jù)集,對訓(xùn)練集進(jìn)行更精確的預(yù)處理。
1 人臉識別技術(shù)與數(shù)據(jù)庫現(xiàn)狀
2009年發(fā)布的LFW數(shù)據(jù)庫的樣本圖片來自于互聯(lián)網(wǎng)名人圖像,其中有5 700余人13 000多張圖像,采用十折平均精度作為人臉識別性能指標(biāo),是在真實條件下最具權(quán)威的人臉識別數(shù)據(jù)庫之一[11]。有許多DCNN的開源實現(xiàn)已經(jīng)公布,2014年Facebook[9]和香港中文大學(xué)[12]使用DCNN技術(shù)在人臉識別中取得重大突破,分別在LFW上獲得了97.35%和97.45%的平均分類精度。隨后,在LFW數(shù)據(jù)集上平均分類精度分別由VGGface、CaffeFace和Google FaceNet刷新到97.27%、99.28%和99.63%,百度公司甚至得到99.77%的準(zhǔn)確率[13]。
DCNN算法之所以需要大量的數(shù)據(jù),主要原因在于越大規(guī)模的數(shù)據(jù)越能夠?qū)W習(xí)到更加抽象、更加魯棒的特征。表1中的數(shù)據(jù)充分體現(xiàn)了這一趨勢:DeepID系列從20萬~45萬,Caffeface使用70萬,百度使用120萬,DeepFace為4億,VGGFace有260萬,谷歌達(dá)到2億,F(xiàn)acebook使用超過10萬人的50億圖像數(shù)據(jù)庫[14]。
表1幾種經(jīng)典的DCNN模型在LFW數(shù)據(jù)集上的測試結(jié)果
Table1ThetestresultsofseveralclassicDCNNmodelsontheLFWdataset
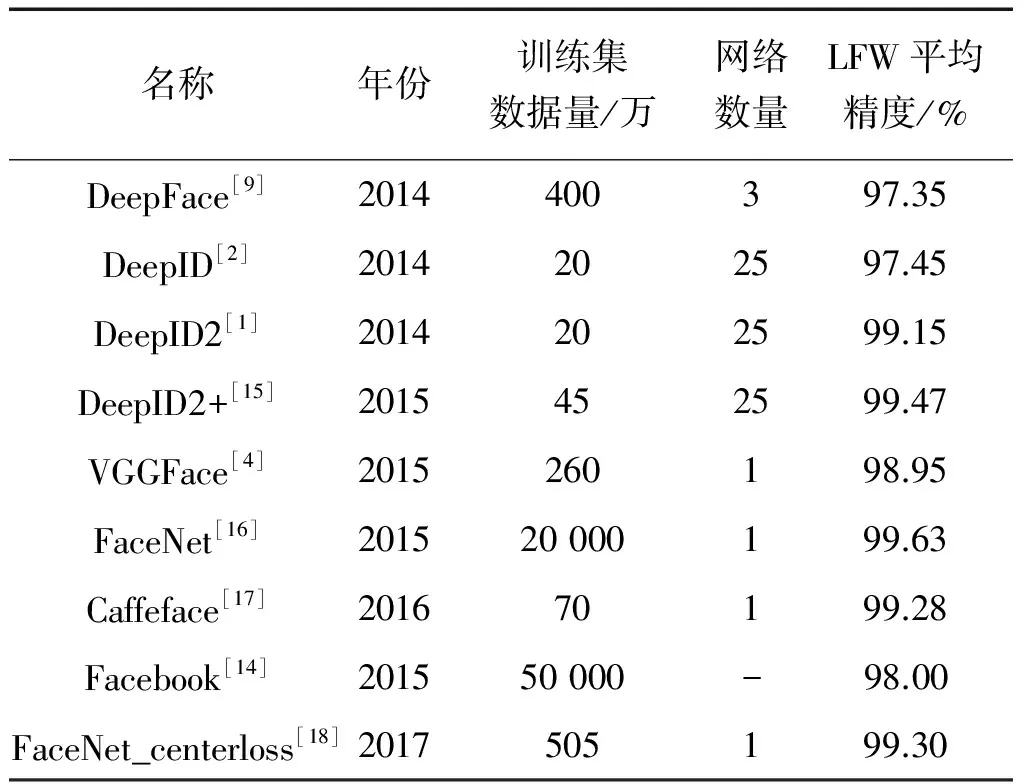
名稱年份訓(xùn)練集數(shù)據(jù)量/萬網(wǎng)絡(luò)數(shù)量LFW平均精度/%DeepFace[9]2014400397.35DeepID[2]2014202597.45DeepID2[1]2014202599.15DeepID2+[15]2015452599.47VGGFace[4]2015260198.95FaceNet[16]201520000199.63Caffeface[17]201670199.28Facebook[14]201550000-98.00FaceNet_centerloss[18]2017505199.30
可以看出,DCNN需要大量數(shù)據(jù)進(jìn)行訓(xùn)練,雖然很多數(shù)據(jù)可以從網(wǎng)絡(luò)上抓取,但是沒有組織,需要手動標(biāo)注信息。可用性強(qiáng)并且標(biāo)注信息豐富的大規(guī)模數(shù)據(jù)庫往往由Google、Facebook和百度這樣的大型公司持有,但因為版權(quán)和隱私的問題,它們并沒有公開發(fā)布。由于在獲取大規(guī)模標(biāo)注信息豐富、準(zhǔn)確度高的數(shù)據(jù)庫方面遇到了較大的障礙,人臉識別技術(shù)在學(xué)術(shù)領(lǐng)域處于被動狀態(tài),甚至落后于工業(yè)界。為了克服這個問題,越來越多的研究機(jī)構(gòu)也相繼發(fā)布了一些大型的、多樣化的數(shù)據(jù)集。目前,表2是公開的一些大型人臉數(shù)據(jù)集及其標(biāo)注信息,香港中文大學(xué)團(tuán)隊發(fā)布了CelebFaces+數(shù)據(jù)集,包含了大約10 000個身份的20萬張圖像,標(biāo)注信息豐富,身份信息未劃分,主要可以用來研究特征點定位和人臉屬性學(xué)習(xí)。2014年中科院自動化研究所發(fā)布并建立了一個大規(guī)模的CASIA-webface人臉識別數(shù)據(jù)集,包含了大約10 500個身份的49萬張圖像,并表示這個數(shù)據(jù)集是作為大規(guī)模訓(xùn)練集來使用。在文獻(xiàn)[4]中,作者也公布了2 622個身份的260萬張圖像。MegaFace[20]數(shù)量大于CASIA,但是被設(shè)計為測試集,每個人提供的圖像很少,因此它從未用于訓(xùn)練DCNN系統(tǒng)。目前,這些數(shù)據(jù)集仍有很多噪聲,身份標(biāo)簽錯誤,單張圖像含有多個人臉等(圖1)問題,這導(dǎo)致數(shù)據(jù)庫的準(zhǔn)確性很難得到保證。

圖1 數(shù)據(jù)庫存的問題示例Fig.1 Examples of problems that exist with the database
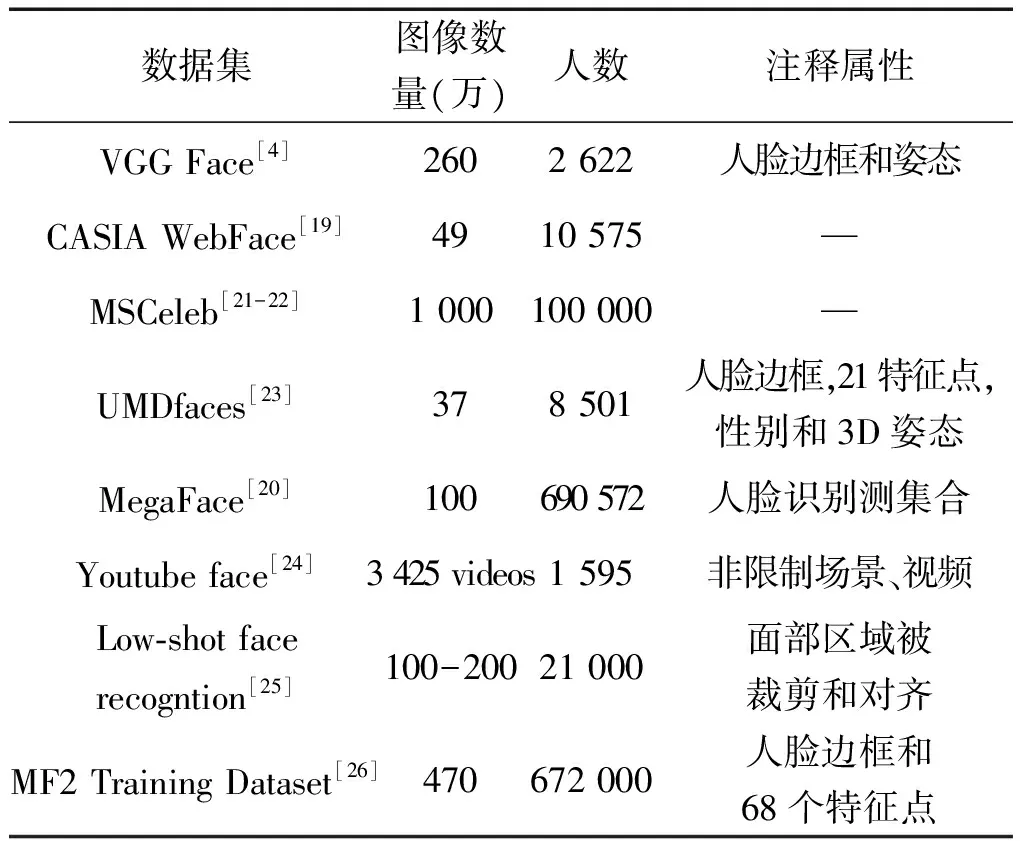
數(shù)據(jù)集圖像數(shù)量(萬)人數(shù)注釋屬性VGGFace[4]2602622人臉邊框和姿態(tài)CASIAWebFace[19]4910575—MSCeleb[21-22]1000100000—UMDfaces[23]378501人臉邊框,21特征點,性別和3D姿態(tài)MegaFace[20]100690572人臉識別測集合Youtubeface[24]3425videos1595非限制場景、視頻Low?shotfacerecogntion[25]100-20021000面部區(qū)域被裁剪和對齊MF2TrainingDataset[26]470672000人臉邊框和68個特征點
DCNN的訓(xùn)練集通常需要進(jìn)行大量的預(yù)處理工作,包括圖像反轉(zhuǎn)、隨機(jī)裁剪、多尺度、彩色渲染、標(biāo)準(zhǔn)化數(shù)據(jù)等。通過不同方式的預(yù)處理產(chǎn)生的結(jié)果也是有很大偏差的,主要表現(xiàn)為人臉檢測錯誤、特征點定位錯誤、身份歸類錯誤等,這些偏差會對訓(xùn)練結(jié)果造成較大的影響。為了研究數(shù)據(jù)庫準(zhǔn)確性對DCNN訓(xùn)練的影響,本文提出了一種多角度評估數(shù)據(jù)清理方法,主要貢獻(xiàn)總結(jié)包括:1)從人臉檢測、特征點定位和人臉相似性等方面對數(shù)據(jù)庫進(jìn)行了清理;2)驗證清理圖像數(shù)據(jù)庫的有效性,以提高訓(xùn)練準(zhǔn)確性。
2 多角度評價清理圖像
首先,采用當(dāng)前主流的人臉檢測和特征點定位算法對數(shù)據(jù)集進(jìn)行清理。其次,利用公開的網(wǎng)絡(luò)模型提取特征計算相似度,并使用相似度統(tǒng)計算法進(jìn)行圖像清理。如圖2是數(shù)據(jù)清理的具體流程。
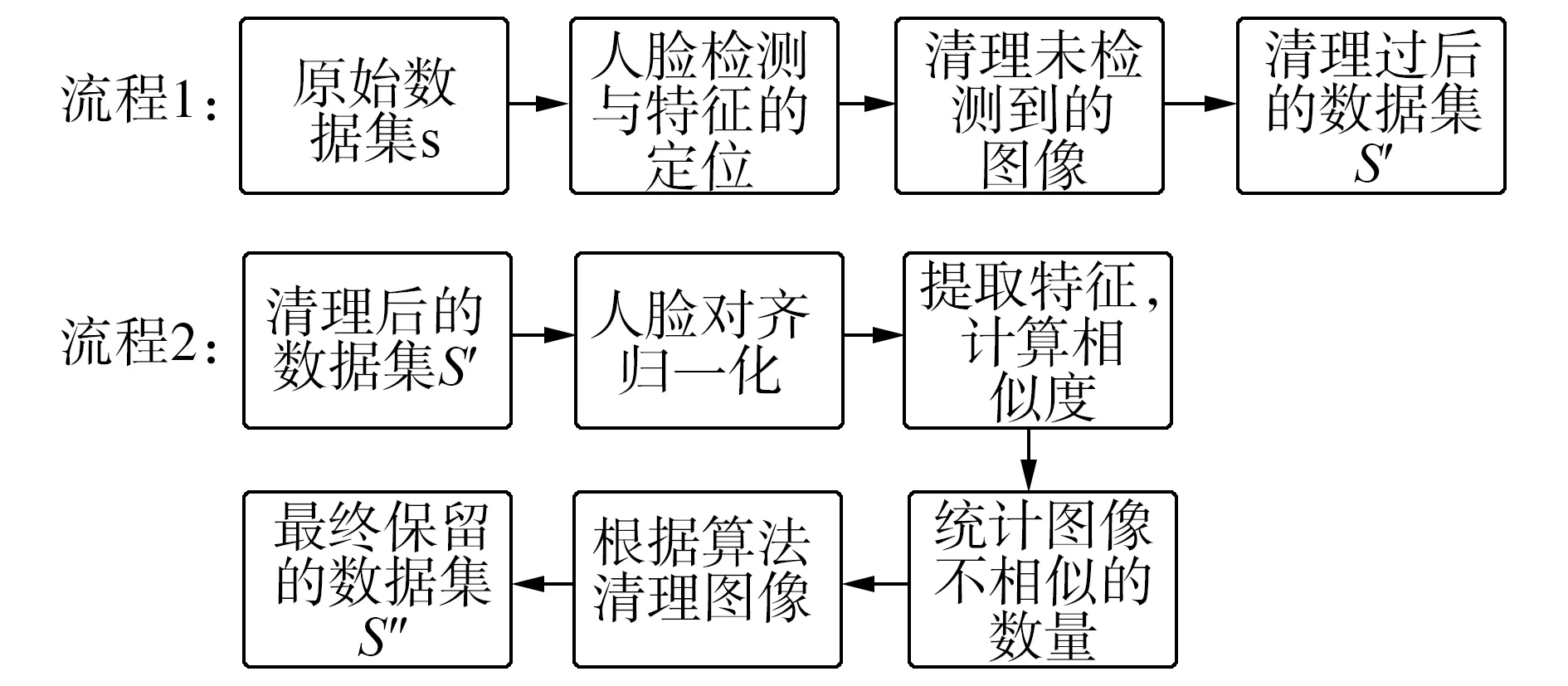
圖2 數(shù)據(jù)清理流程Fig.2 Data cleansing process
2.1 臉檢測與特征點定位
人臉檢測和人臉對齊已經(jīng)成為獨立的研究方向,人臉特征提取的前提就需要對這些算法進(jìn)行研究,其中必不可少的就是人臉檢測。人臉對齊(校準(zhǔn))或面部特征點定位主要是通過瞳孔、眉毛、嘴巴等人臉上的面部特征點對人臉進(jìn)行校準(zhǔn),以促進(jìn)正面特征提取,特別是對于局部關(guān)鍵特征提取。
本節(jié)主要對香港中文大學(xué)DCNN Seetaface、中國科學(xué)院的面部檢測算法和深圳先進(jìn)學(xué)校MTCNN算法[27]通過比較分析實際面部檢測表現(xiàn),并針對接下來的大規(guī)模臉數(shù)據(jù)集選擇適當(dāng)?shù)娜四槞z測和關(guān)鍵點檢測算法,從不同角度對DCNN、Seetaface、MTCNN這3種算法進(jìn)行測試和分析,驗證3種算法的性能。
表3是3種算法在3個不同測試數(shù)據(jù)集上5個關(guān)鍵點的平均差、標(biāo)準(zhǔn)差和效率。從表3中可以看出,DCNN算法的標(biāo)準(zhǔn)差均小于Seetaface算法和MTCNN算法,MTCNN算法略好于Seetaface算法,在這3個小數(shù)據(jù)集的測試中DCNN算法的穩(wěn)定性最好,其次是MTCNN;從平均誤差來說,表現(xiàn)最好的是Seetaface算法,表明Seetaface算法可以適應(yīng)更廣泛的場景。
通過比較人臉檢測和特征點定位的時間效率可以看出,MTCNN檢測的時間最短,DCNN算法檢測的時間最長。

表3 5個關(guān)鍵點的測試平均差、標(biāo)準(zhǔn)差和效率
在本文中訓(xùn)練深度卷積神經(jīng)網(wǎng)絡(luò)需要大規(guī)模數(shù)據(jù)集預(yù)處理工作,因此需要考慮面部檢測算法的綜合性能,主要包括效果和效率。表4進(jìn)一步進(jìn)行了兩次大規(guī)模數(shù)據(jù)集的測試,從表4可以看出,MTCNN算法對大數(shù)據(jù)的穩(wěn)定性較好,CelebA共計20多萬圖像,測試CelebA時MTCNN算法實際檢測的面部圖像為182 387張,Seetaface算法實際檢測的臉部圖像為180 032張 , MTCNN算法在大規(guī)模數(shù)據(jù)集中具有較好的效果。
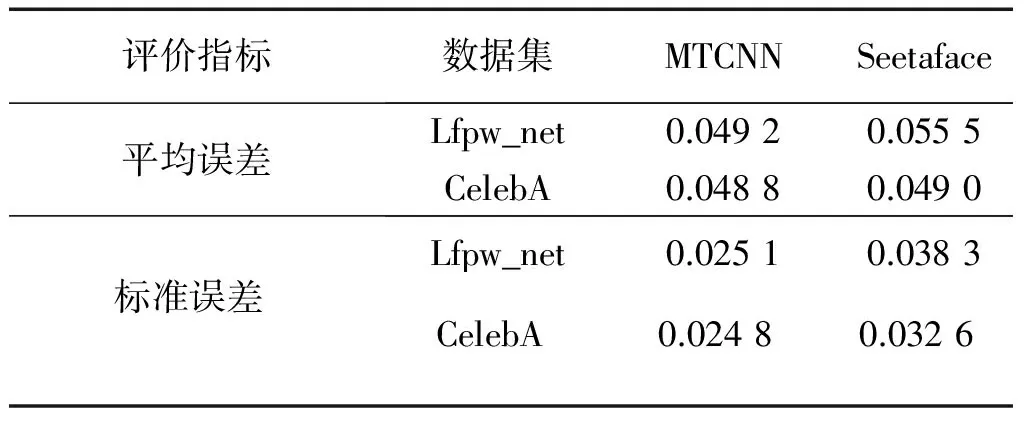
表4 大規(guī)模數(shù)據(jù)集上5個特征點的比較
根據(jù)上述實際測試的數(shù)據(jù),本文選擇MTCNN算法作為所有數(shù)據(jù)庫的面部檢測算法。
2.2 基于相似度統(tǒng)計的圖像清理
基于相似度統(tǒng)計的圖像清理算法的3個主要步驟如下。
1)人臉對齊
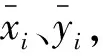
(1)
在求出標(biāo)準(zhǔn)模板之后,根據(jù)式(2)求出原圖到目標(biāo)圖像的仿射變換矩陣:

式中:Opt是原圖像的5個特征點,Cpt是標(biāo)準(zhǔn)模板的5個點,T是求得的變換矩陣,cp2tform是MATLAB的標(biāo)準(zhǔn)函數(shù)。
根據(jù)式(3)得出對齊之后的人臉圖像:
crop=imtransform(I,T,′XData′,[1,imgsize(2)],
式中:I是原圖像,imgsize是要對齊的圖像尺寸,crop是對齊之后的人臉圖像,imtransform是MATLAB的標(biāo)準(zhǔn)函數(shù)。
2)人臉特征提取與相似度計算
本文使用的網(wǎng)絡(luò)結(jié)構(gòu)來自于文獻(xiàn)[17]在github上提供的開源文件,如圖3所示。
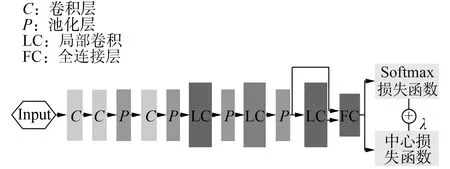
圖3 本文中人臉識別任務(wù)中使用的DCNN架構(gòu)Fig.3 The DCNN architecture used in face recognition tasks in this article
Softmax損失函數(shù)和中心損失函數(shù)的聯(lián)合監(jiān)視,可以訓(xùn)練足夠強(qiáng)大的DCNN,并且能夠得到兩個關(guān)鍵學(xué)習(xí)目標(biāo)的深層特征以及盡可能高的類間分散性和類內(nèi)緊密性。這些特性對人臉識別來說至關(guān)重要。提取特征的模型也采用了文獻(xiàn)[17]公布的網(wǎng)絡(luò)模型,部分超參數(shù)設(shè)置由實際數(shù)據(jù)庫來確定。
對于特征提取,按照慣例在進(jìn)入網(wǎng)絡(luò)模型之前,RGB圖像像素值將減去127.5,并將每個像素值除以128。 深度特征來自第一FC層的輸出,提取每個圖像的特征和翻轉(zhuǎn)圖像的特征,并將其作為特征向量進(jìn)行連接。 在提取所有圖像的特征之后,對從兩個不同圖像提取的特征向量進(jìn)行相似性計算。所使用的度量是余弦距離,(4)式是兩個特征向量A和B的角度,直接計算余弦距離作為相似度S,即
使用等誤差率(EER)作為判斷是否為同一個人的閾值。 當(dāng)相似度超過該閾值T時,認(rèn)定為同一個人,小于閾值T時不為同一個人。 對于每種圖像,進(jìn)行相似度計算,1表示兩個圖像是同一個人,0表示兩個圖像不是一個人。
式(5)表明如何判斷兩個圖像是否為同一個人。
式中:Pi、Pj表示一類圖像中的第i和j張圖像的特征向量,Lij表示第i和j張圖像是否為同一個人。
3)根據(jù)不相似的圖像的比例確定是否清理
根據(jù)式(6)統(tǒng)計同一個人的人臉圖像C中每一張圖像與其他圖像不相似的數(shù)目。
式中:Ni表示第i張圖像與其他圖像不相似的數(shù)目,i=1,2,…,n。
最后,根據(jù)式(7)判斷是否清理該圖像。
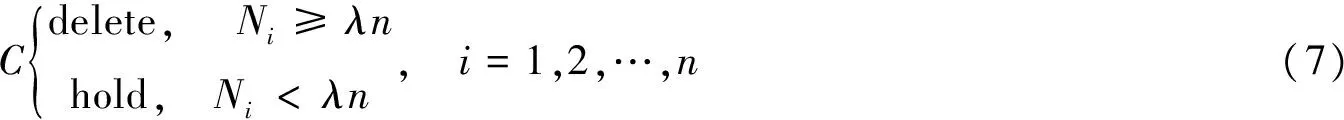
式中:n表示一類人臉?biāo)袌D像數(shù)目;參數(shù)λ的值需要根據(jù)不同的數(shù)據(jù)庫來確定,具體λ值將在下一章實驗部分具體分析。
3 實驗與分析
本節(jié)選取了CASIA-webface數(shù)據(jù)集、UMDface數(shù)據(jù)集和MSceleb數(shù)據(jù)集作為實驗數(shù)據(jù)庫,并選取公共權(quán)威人臉識別測試數(shù)據(jù)集LFW和Youtube face作為測試數(shù)據(jù)集。
LFW收集的數(shù)據(jù)集包含5 749個不同的人,有姿態(tài)、表情和光照的變化,總共13 233個圖像,旨在研究人臉圖像數(shù)據(jù)庫中的困難的人臉識別問題。 根據(jù)LFW提供的測試方案——unrestricted with labeled outside data[28],我們測試了6 000個人臉對,人臉如圖4所示。

圖4 LFW測試協(xié)議人臉對Fig.4 The LFW test protocol face pair
Youtube臉(YTF)數(shù)據(jù)集包含3 495個不同人的視頻,平均每人2.15個視頻。剪輯持續(xù)48~6 070幀,平均長度為181.3幀。它旨在研究視頻下人臉識別的問題。根據(jù)YTF提供的測試協(xié)議——unrestricted with labeled outside data,測試5 000個視頻對,如圖5所示。

圖5 YTF測試協(xié)議人臉視頻對Fig.5 The YTF test protocol face video pair
3.1 訓(xùn)練細(xì)節(jié)
1)預(yù)處理
CASIA-webface和MSceleb使用2.1節(jié)提出的人臉檢測方法進(jìn)行初步篩選,刪除未檢測到的人臉圖像,并使用2.2節(jié)步驟1提出的人臉對齊將所有的人臉圖像對齊成112×96的 RGB圖像。UMDface數(shù)據(jù)集是經(jīng)過包括人工判斷在內(nèi)的深度清理過的人臉圖像數(shù)據(jù)集,清理過程在文獻(xiàn)[23]中具體描述,提供了21個關(guān)鍵點的標(biāo)注信息,我們選取了與MTCNN算法檢測相同的5個點作為UMDface原始圖像的特征點,并使用2.2節(jié)步驟1提出的方法進(jìn)行人臉對齊。
2)數(shù)據(jù)集設(shè)置
本文使用經(jīng)過2.1節(jié)方式清理過的CASIA-webface作為第1個數(shù)據(jù)集A,共有10 575個人,491 582張圖像。使用UMDface數(shù)據(jù)集作為第2個數(shù)據(jù)集B,共有8 501個人,367 919張圖像。第3個數(shù)據(jù)集C來自于2.2節(jié)得出最終清理的數(shù)據(jù)集。經(jīng)過2.1節(jié)方式清理過的MSceleb數(shù)據(jù)集作為第4個數(shù)據(jù)集D,共有近90 000個人,8 500 000余張圖像。所有數(shù)據(jù)集按照11∶1的比例分為訓(xùn)練集和驗證集,至少使用一個圖像作為驗證集。
3)網(wǎng)絡(luò)設(shè)置和參數(shù)
本文使用的是windows環(huán)境下配置的caffe平臺[29]來訓(xùn)練模型,本節(jié)中的所有CNN模型都是相同的架構(gòu),詳細(xì)信息如圖3所示。學(xué)習(xí)率從0.1開始,學(xué)習(xí)策略(learning policy)多步衰減,迭代次數(shù)到15 000、24 000、32 000次時學(xué)習(xí)率分別除10,權(quán)重腐蝕(weight decay)為0.000 5,記憶因子(momentum)為0.9。
3.2 不同準(zhǔn)確度數(shù)據(jù)庫訓(xùn)練實驗
本實驗是研究不同精度數(shù)據(jù)庫對訓(xùn)練的影響,使用UMDface數(shù)據(jù)庫和Webface數(shù)據(jù)庫,這兩個數(shù)據(jù)庫在保證數(shù)據(jù)準(zhǔn)確性的程度上表現(xiàn)出很大的區(qū)別,UMDface的數(shù)據(jù)庫精度由大量人工信息標(biāo)注,并且類別精確,Webface數(shù)據(jù)庫則沒有任何人臉標(biāo)注信息,很難保證數(shù)據(jù)的準(zhǔn)確性。MSceleb的準(zhǔn)確性由于規(guī)模龐大,更加難以保證數(shù)據(jù)準(zhǔn)確性,3個數(shù)據(jù)庫的詳細(xì)數(shù)據(jù)對比如表5所示。
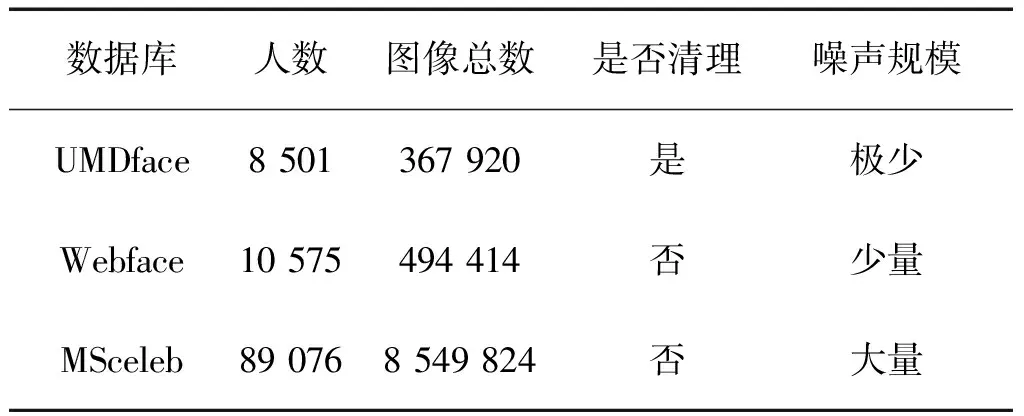
表5 3個數(shù)據(jù)庫的屬性比較
在表6中,EER是等錯誤率的準(zhǔn)確率,這種精度是面部識別性能的重要指標(biāo)。當(dāng)FPR較小時,較大的TPR可以進(jìn)一步解釋模型的影響,應(yīng)用場景不同對FPR的要求也不一樣。 因此,從表6可以看出,UMDface以最小的規(guī)模實現(xiàn)了最高的精度,而MSceleb數(shù)據(jù)庫規(guī)模最大,準(zhǔn)確率也是最低的,數(shù)據(jù)的準(zhǔn)確性對訓(xùn)練的影響是非常大的,即使數(shù)據(jù)規(guī)模再大,無法保證較高的數(shù)據(jù)精度,也無法獲得較高的準(zhǔn)確率,說明進(jìn)行數(shù)據(jù)庫清理是非常有必要的。
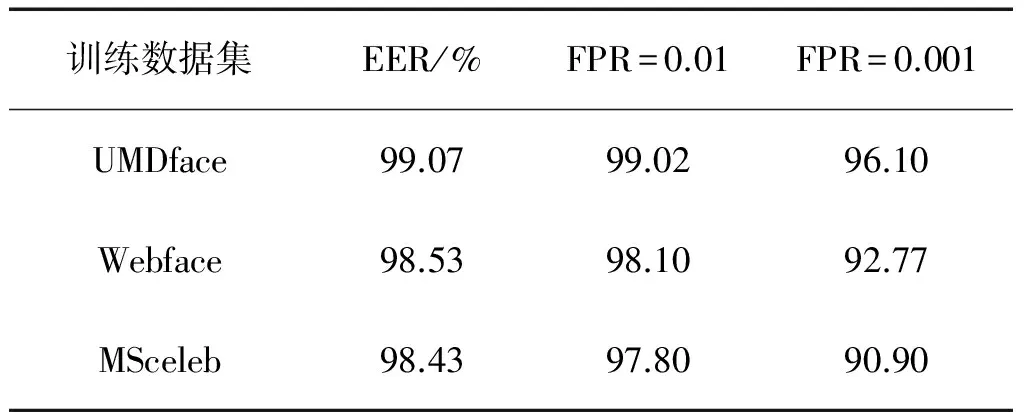
表6 不同模型在LFW上的準(zhǔn)確率
3.3 參數(shù)λ和一類圖像的最小靈敏度
參數(shù)λ在清理圖像數(shù)量方面起著重要作用,這可能會影響訓(xùn)練結(jié)果,某類圖像的最小數(shù)量也可能會影響訓(xùn)練。
在第1個實驗中,λ從0.1~1來完成數(shù)據(jù)集A的深度清理工作,并使用清理后的數(shù)據(jù)集來訓(xùn)練模型,這些模型在LFW數(shù)據(jù)集上的準(zhǔn)確率如圖6(a)所示。顯然,不做任何清理λ=1)準(zhǔn)確率最差;正確選擇λ的值可以提高DCNN特征的準(zhǔn)確率;進(jìn)行不同程度的清理(λ不同)在一定范圍內(nèi)準(zhǔn)確率保持穩(wěn)定,清理過度會導(dǎo)準(zhǔn)確率下降。本文建議將λ的值設(shè)定在0.3~0.6,然后使用不同程度的清理數(shù)據(jù)集進(jìn)行訓(xùn)練,并選取最佳λ值。
在第2個實驗中,將λ值設(shè)為0.4,再繼續(xù)清理掉某些類圖像數(shù)目少于一定值(從10到20)的類,然后使用清理后的數(shù)據(jù)集來訓(xùn)練模型,這些模型在LFW數(shù)據(jù)集上的準(zhǔn)確率如圖6(b)所示。同樣,這種模式的準(zhǔn)確性在一定范圍內(nèi)可以穩(wěn)定,最好的結(jié)果是每個類別中不少于15個人,參數(shù)λ=0.4,清理后的CASIA-webface數(shù)據(jù)集有9 240個人,一共400 000張圖像作為數(shù)據(jù)集C。
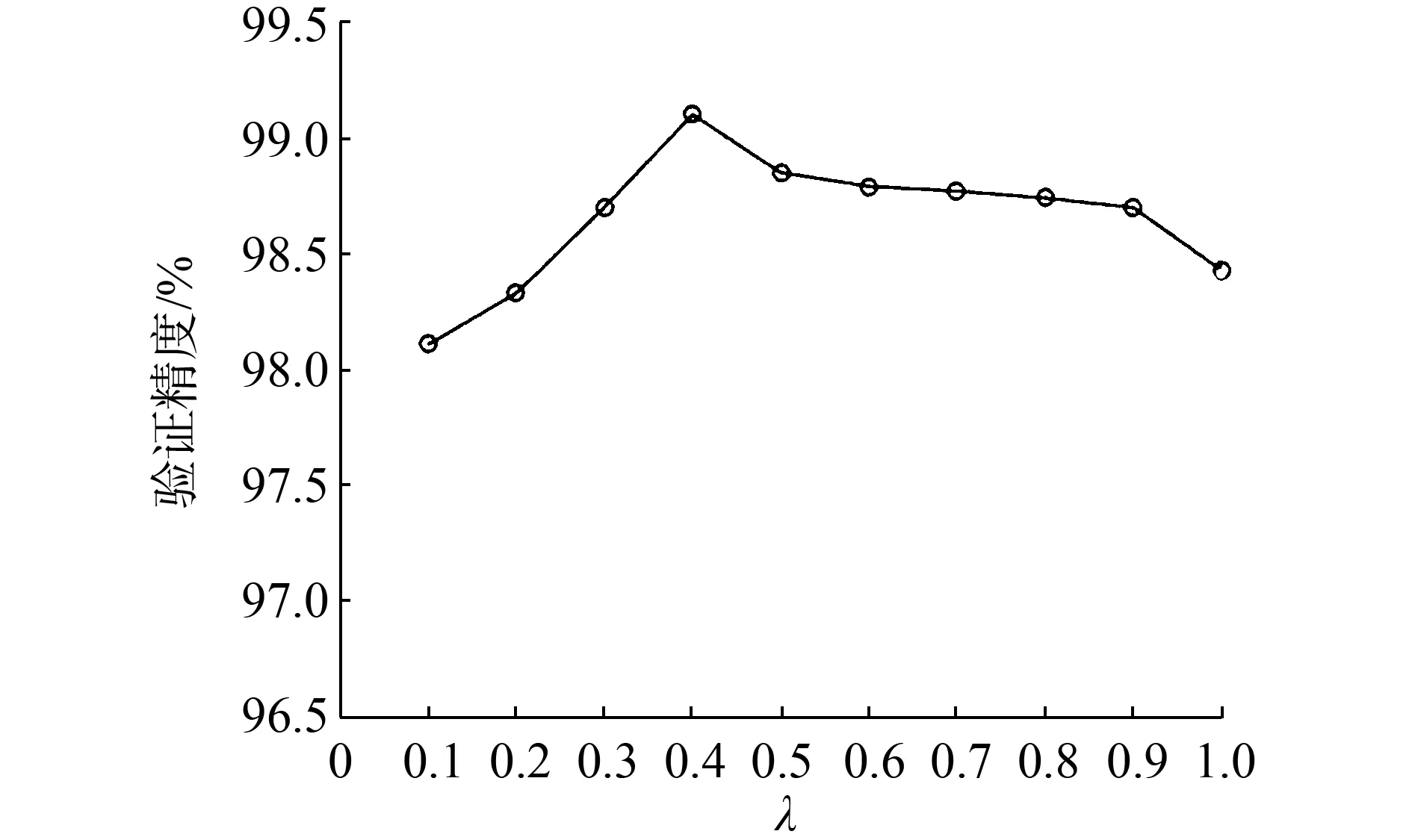
(a)不同的λ模型
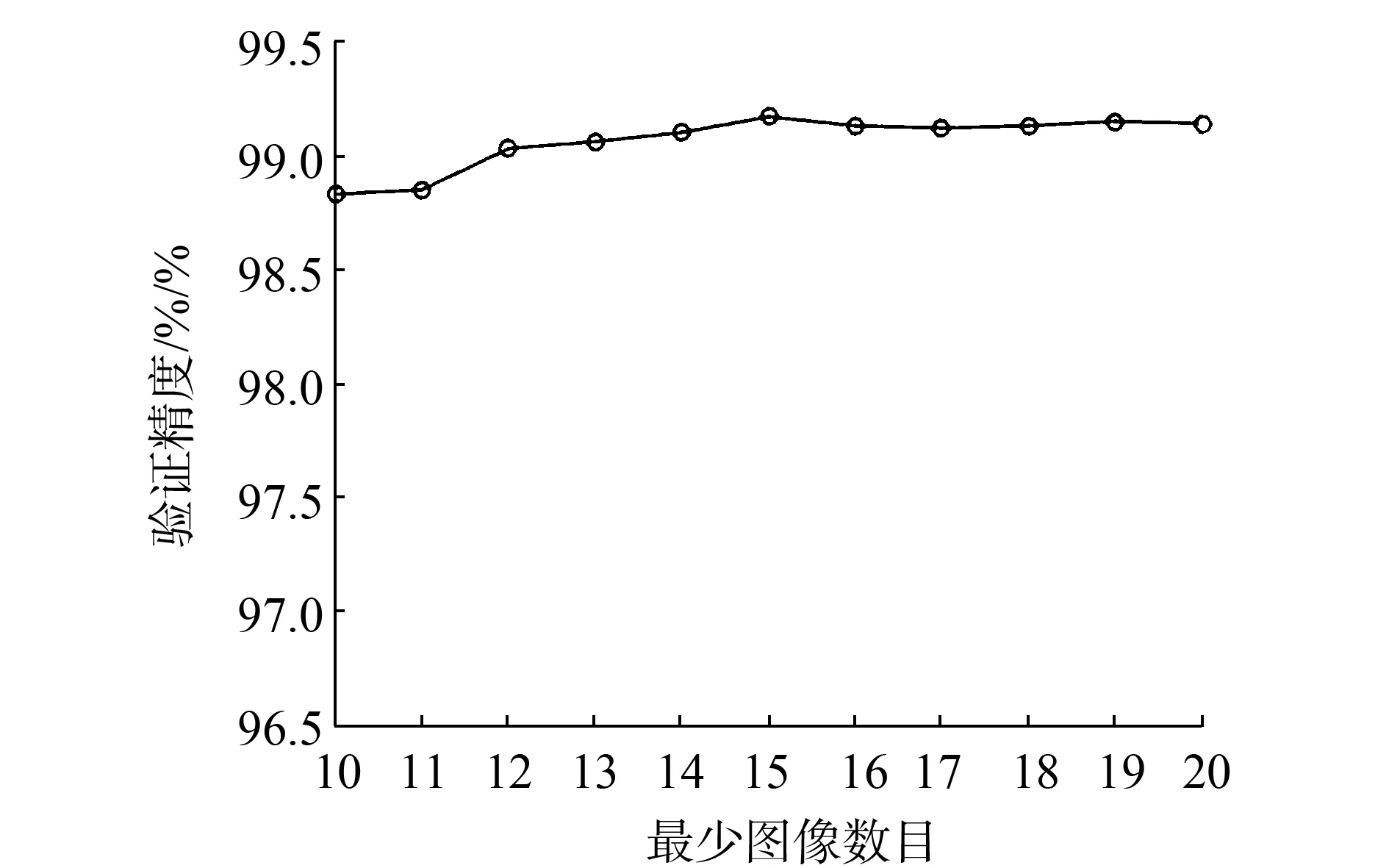
(b)λ=0.4不同的最少圖像數(shù)目模型圖6 LFW數(shù)據(jù)集上驗證準(zhǔn)確率Fig.6 Verification accuracy on LFW datasets
3.4 在LFW和Youtube face上的測試結(jié)果
表7是在LFW上的測試結(jié)果和其他算法結(jié)果的對比,模型A是由數(shù)據(jù)集A作為訓(xùn)練集訓(xùn)練出來的模型,模型B是由數(shù)據(jù)集B作為訓(xùn)練集訓(xùn)練出來的模型,模型C是由數(shù)據(jù)集C作為訓(xùn)練集訓(xùn)練出來的模型。
圖7顯示了不同方法的ROC曲線,我們可以從表7和圖7的測試結(jié)果中得出以下結(jié)論:首先,模型C在3個實驗?zāi)P椭羞_(dá)到了最高的精度,模型B精度高于模型A,表明數(shù)據(jù)清理明顯提高了人臉識別訓(xùn)練模型的準(zhǔn)確性;其次,原來的Caffeface訓(xùn)練所使用的數(shù)據(jù)集包含其他數(shù)據(jù)集,數(shù)據(jù)量更大,類別也是本文的2倍,而在測試時,Caffeface的結(jié)果是經(jīng)過特征提取后的PCA處理, 本文的結(jié)果未被PCA處理,也與原來的結(jié)果非常接近,進(jìn)一步證明了數(shù)據(jù)清理的有效性。
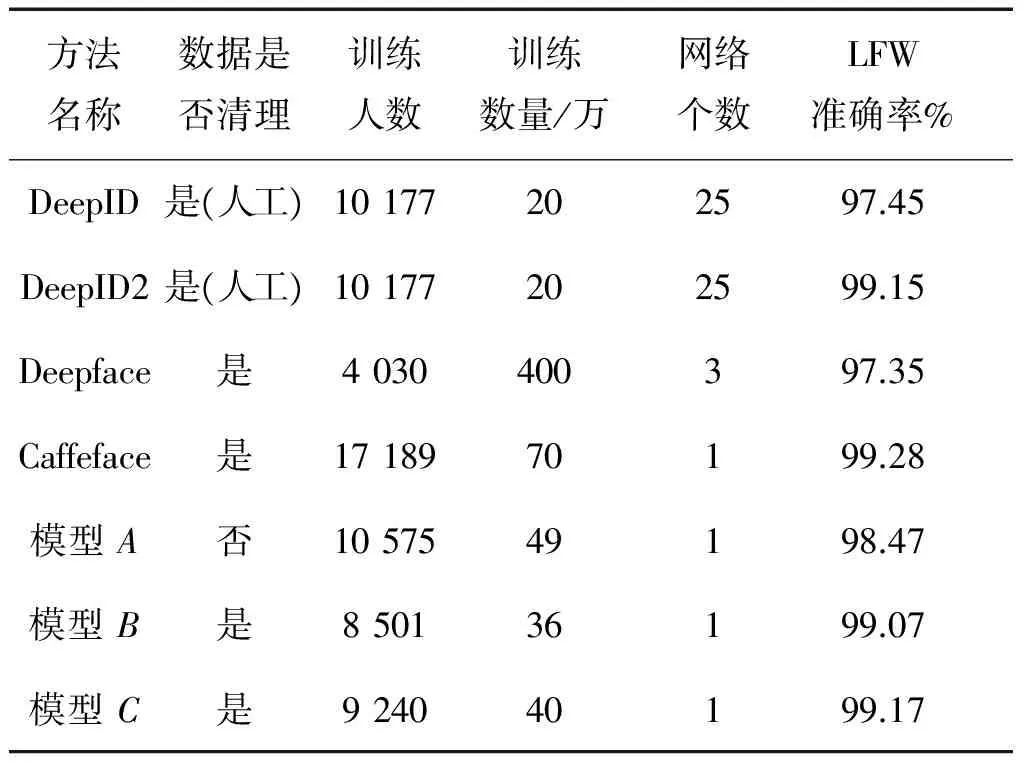
表7 LFW上的人臉驗證結(jié)果
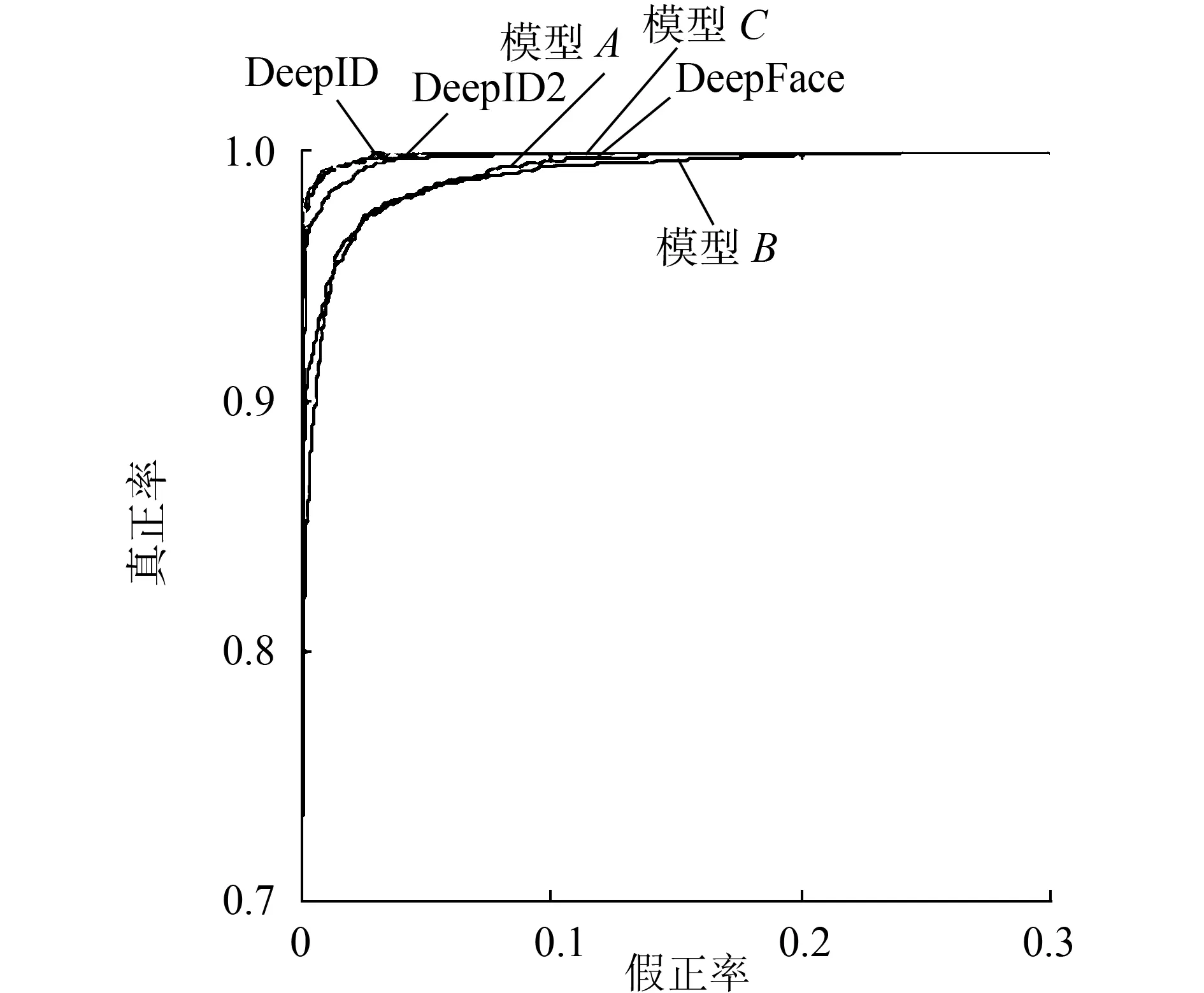
(a)假正率0~0.3的ROC曲線
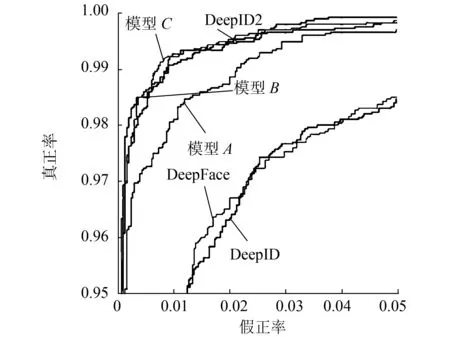
(b)假正率0~0.05的ROC曲線圖7 LFW 上不同方法的ROC曲線Fig.7 ROC curves of different methods on LFW
表8是在Youtube face數(shù)據(jù)集上本文得出的測試結(jié)果和其他算法結(jié)果的對比,測試協(xié)議按照3.1節(jié)對Youtube face數(shù)據(jù)庫的描述進(jìn)行。
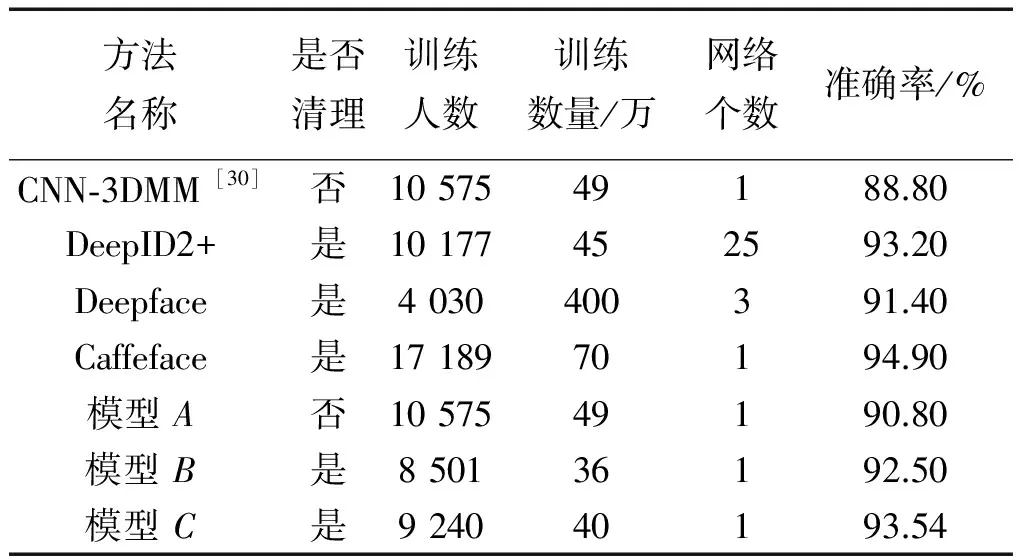
表8 Youtube face上的人臉驗證結(jié)果
圖8顯示了不同方法的ROC曲線,我們還可以從表8和圖8的測試結(jié)果中得出以下結(jié)論:模型C在3個模型中已經(jīng)達(dá)到了最高的準(zhǔn)確度,遠(yuǎn)遠(yuǎn)超過其他兩個模型的ROC曲線,在非限制條件下的視頻場景中,數(shù)據(jù)清理仍然會提高人臉識別精度。在目前的主流人臉識別算法中,模型C也顯示出顯著的成果,比3DMM算法、DeepID2 +算法、Deepface算法,以及Caffeface算法訓(xùn)練的效果好。 圖像清理后,對數(shù)據(jù)集進(jìn)行訓(xùn)練,干擾因子較小,對于基于深卷積神經(jīng)網(wǎng)絡(luò)的人臉識別非常有用。
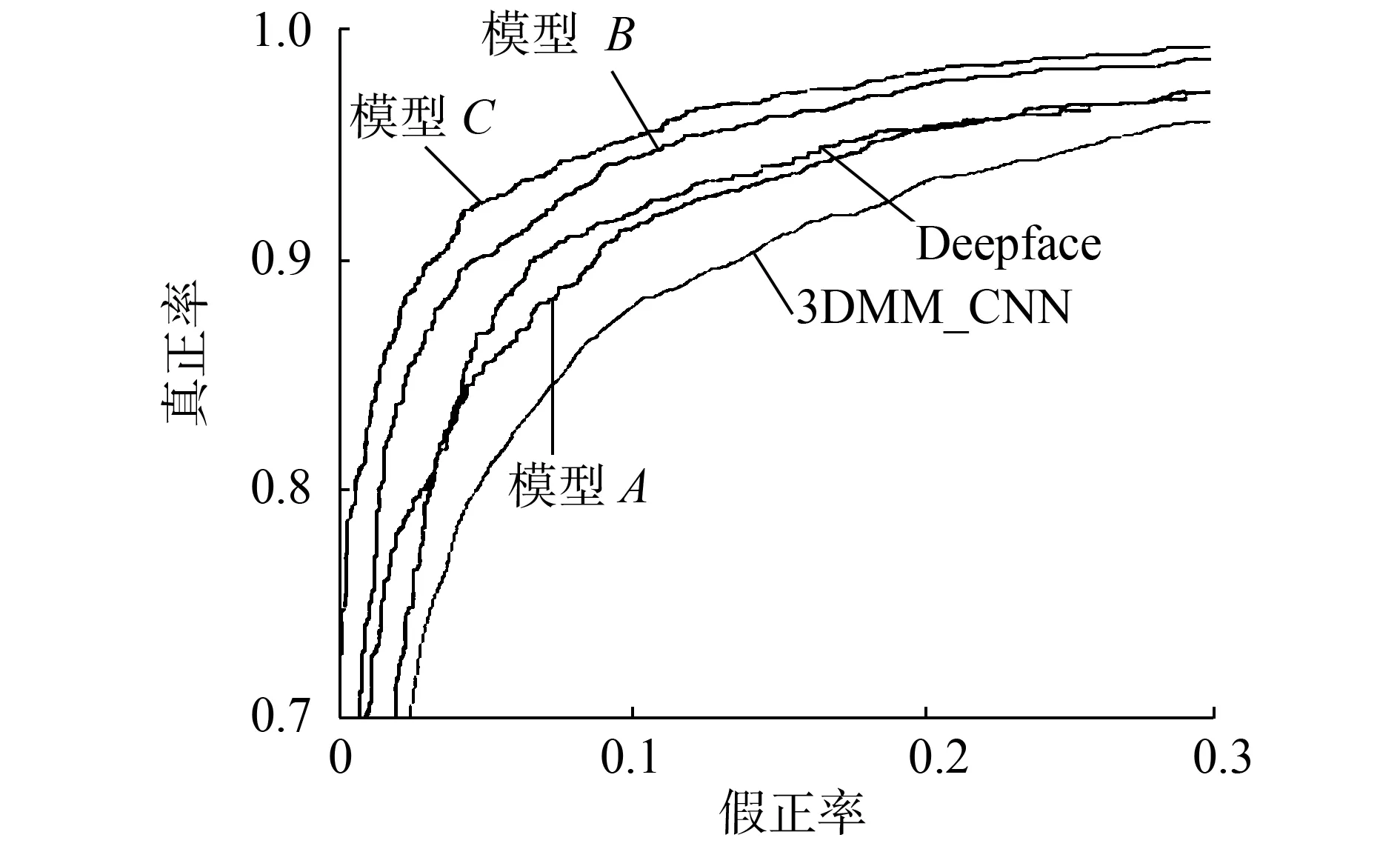
(a)假正率0~0.3的ROC曲線
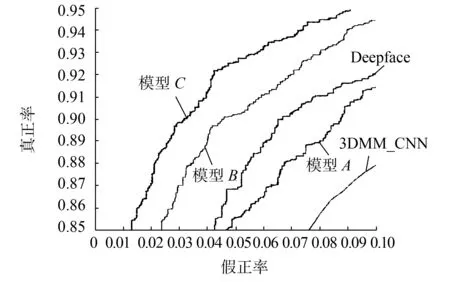
(b)假正率0~0.1的ROC曲線圖8 Youtube face上不同方法的ROC 曲線Fig.8 ROC curves of different methods on Youtube face
4 結(jié)束語
深度卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展得益于大數(shù)據(jù),因為數(shù)據(jù)量夠大,計算機(jī)夠強(qiáng)大,機(jī)器本身才能學(xué)習(xí)出各種復(fù)雜的特征。而數(shù)據(jù)的準(zhǔn)確性,也就是數(shù)據(jù)標(biāo)簽、標(biāo)注信息、類別等的準(zhǔn)確性,也會對訓(xùn)練的模型結(jié)果造成一定的影響,因此本文對數(shù)據(jù)庫清理方面做了研究。本文提出將數(shù)據(jù)庫進(jìn)行多角度清理后再訓(xùn)練的方法,通過與未清理和其他方法的比較發(fā)現(xiàn),清理后的數(shù)據(jù)庫在訓(xùn)練上結(jié)果更精確。實驗證明,清理后的數(shù)據(jù)集能夠提高網(wǎng)絡(luò)識別率。
目前,大多數(shù)公開的數(shù)據(jù)集仍含有很多噪聲,大規(guī)模數(shù)據(jù)去除噪聲仍是一個值得重視的問題。本文數(shù)據(jù)清理方法是否對所有數(shù)據(jù)庫具有普適性,是否已經(jīng)存在更高效更準(zhǔn)確的數(shù)據(jù)清理方法需要進(jìn)一步探究。下一步的工作可以考慮將多個清理后的數(shù)據(jù)集進(jìn)行合并來擴(kuò)大數(shù)據(jù)量。
[1]SUN Y, WANG X, TANG X. Deep learning face representation by joint identification-verification[J]. Advances in neural information processing systems, 2014, 27: 1988-1996.
[2]SUN Y, WANG X, TANG X. Deep learning face representation from predicting 10,000 classes[C]// IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA, 2014: 1891-1898.
[3]王曉剛,孫袆,湯曉鷗. 從統(tǒng)一子空間分析到聯(lián)合深度學(xué)習(xí): 人臉識別的十年歷程[J]. 中國計算機(jī)學(xué)會通訊, 2015, 11(4): 8-15 .
WANG Xiaogang, SUN Hui, TANG Xiaoou. From unified subspace analysis to joint depth learning: ten years of face recognition[J]. China computer society newsletter, 2015, 11(4): 8-15.
[4]PARKHI O M, VEDALDI A, ZISSERMAN A. Deep face recognition[C]//British Machine Vision. London,Britain, 2015: 411-4112.
[5]SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: A unified embedding for face recognition and clustering[C]// IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA, 2015: 815-823.
[6]DING C, TAO D. A comprehensive survey on pose-invariant face recognition[J]. Acm transactions on intelligent systems and technology, 2015, 7(3): 37.
[7]SUN Y, LIANG D, WANG X, et al. DeepID3: face recognition with very deep neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA, 2015: 963-971.
[8]SUN Y, WANG X, TANG X. Hybrid deep learning for face verification[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 38(10): 1997-2009.
[9]TAIGMAN Y, YANG M, RANZATO M, et al. Deepface: closing the gap to human-level performance in face verification[C]//IEEE Conference on Computer Vision and Pattern Recognition. Columbia,American,2014: 1701-1708.
[10]WEN Y, ZHANG K, LI Z, et al. A discriminative feature learning approach for deep face recognition[C]//ECCV Conference on Computer Vision.Amsterdam,Holand, 2016: 499-515.
[11]HUANG G B,MATTAR M, BERG T, et al. Labeled faces in the wild: a database for studying face recognition in unconstrained environments[J].Month, 2007.
[12]SUN Y, WANG X, TANG X. Deep learning face representation from predicting 10,000 classes[C]//IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA, 2014: 1891-1898.
[13]LIU J, DENG Y, BAI T, et al. Targeting ultimate accuracy: face recognition via deep embedding[C]//European Conference on Computer Vision.Amsterdam,Netherlands, 2016: 499-515.
[14]TAIGMAN Y, YANG M, RANZATO M, et al. Web-scale training for face identification[C]//Computer Vision and Pattern Recognition.Columbus, USA, 2014: 2746-2754.
[15]SUN Y, WANG X, TANG X. Deeply learned face representations are sparse, selective, and robust[C]// Computer Vision and Pattern Recognition. Boston, USA, 2015: 2892-2900.
[16]SCHROFF F, KALENICHENKO D, PHILBIN J. Facenet: a unified embedding for face recognition and clustering[C]// IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA, 2015: 815-823.
[17]WEN Y, ZHANG K, LI Z, et al. A discriminative feature learning approach for deep face recognition[C]//European Conference on Computer Vision. Amsterdam, Netherlands,2016: 499-515.
[18]SEITZ S M, MILLER D, et al.The megaface benchmark: 1 million faces for recognition at scale[C]//Computer Vision and Pattern Recognition. Las Vegas,USA,2016:4873-4882.
[19]BORJI A, IZADI S, ITTI L. iLab-20M: a large-scale controlled object dataset to investigate deep learning[C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA, 2016: 2221-2230.
[20]KEMELMACHERSHLIZERMAN I, SEITZ S M, MILLER D, et al. The megaface benchmark: 1 million faces for recognition at scale[C]// Computer Vision and Pattern Recognition. Las Vegas, USA, 2016:4873-4882.
[21]GUO Y, ZHANG L, HU Y, et al. MS-Celeb-1M: challenge of recognizing one million celebrities in the real world[C]//Electronic imaging. San Francisco,USA,2016: 1-6.
[22]GUO Y, ZHANG L, HU Y, et al. MS-celeb-1M: a dataset and benchmark for large-scale face recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA, 2016: 113-124.
[23]BANSAL A, NANDURI A, CASTILLO C, et al. UMDFaces: an annotated face dataset for training deep networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA, 2016: 976-984.
[24]WOLF L, HASSENER T, MAOZ I. Face recognition in unconstrained videos with matched background similarity[C]// Computer Vision and Pattern Recognition. Colorado Springs, USA, 2011:529-534.
[25]GUO Y, ZHANG L. One-shot face recognition by promoting underrepresented classes[J]. Computer vision and pattern recognition, arxiv:1707.05574,2017.
[26]NECH A, Kemelmachershlizerman I. Level playing field for million scale face recognition[J]. Computer vision and pattern recognition, arxiv:1705.00393,2017.
[27]ZHANG K, ZHANG Z, LI Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE signal processing letters, 2016, 23(10):1499-1503.
[28]HUANG G.B, LEARNED-MILLER E. Labeled faces in the wild: updates and new reporting procedures[R]. Technical report UM-CS-2014-003.
[29]JIA Y, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding[J]. Eprint arxiv, 2014:675-678.
[30]LIU F, ZENG D, ZHAO Q, et al. Joint face alignment and 3D face reconstruction[C]//European Conference on Computer Vision. Amsterdam,Netherlands, 2016: 545-560.

夏洋洋,男,1990年生,碩士研究生,主要研究方向為深度學(xué)習(xí)、圖像處理、人臉識別。

龔勛,男,1980年生,副教授,博士,主要研究方向為圖像處理及模式識別、三維人臉建模、人臉圖像分析及識別。獲國家發(fā)明專利2項,發(fā)表學(xué)術(shù)論文30余篇,出版專著 1部。

洪西進(jìn),男,1957年生,特聘教授,博士,主要研究方向為信息安全、生物辨識、云計算與大數(shù)據(jù)、智能圖像處理。發(fā)明專利13項,發(fā)表SCI期刊學(xué)術(shù)論文80余篇,國際學(xué)術(shù)會議論文110余篇。
Researchonthedatacleansingproblemforfacerecognitiontechnology
XIA Yangyang1, GONG Xun1, HONG Xijin1,2
(1.School of Information Science and Technology, Southwest Jiaotong University,Chengdu 611756, China; 2. Department of Computer Science and Information Engineering, National Taiwan University of Science and Technology, Taipei 10607, China)
Face recognition technology has made a significant progress in the rapid development of deep convolution neural networks (DCNN). These developments are mainly focused toward a denser DCNN architecture and larger training database. However, DCNN training is affected because the large-scale database held by most private companies are not publically accessible. Moreover, current large-scale open databases are not accessible because of the slight availability of the labeled information and hard-to-guarantee accuracy. This study presents an easy-to-use image cleansing method to improve the accuracy of data from the following perspectives: First, deleting the face image that cannot be detected by face detection; second, using the existing model to extract the features of an image on the cleaned dataset and calculate the similarity; and finally, counting the number of images that are unlike the other images. The data were cleansed according to the improved parameters extracted from the abovementioned perspectives. The experimental results reveal that the cleansed database training model has improved the accuracy of face recognition in LFW(labeled faces in the wild) and YouTube face database. In the case of using a small-scale dataset, an accuracy of 99.17% and 93.53% was achieved on the LFW and YouTube face datasets, respectively.
deep convolution neural network; DCNN; cleansing image; face recognition; large database
10.11992/tis.201706025
http://kns.cnki.net/kcms/detail/23.1538.TP.20171021.1350.012.html
TP391.4
A
1673-4785(2017)05-0616-08
中文引用格式:夏洋洋,龔勛,洪西進(jìn).人臉識別背后的數(shù)據(jù)清理問題研究J.智能系統(tǒng)學(xué)報, 2017, 12(5): 616-623.
英文引用格式:XIAYangyang,GONGXun,HONGXijin.ResearchonthedatacleansingproblemforfacerecognitiontechnologyJ.CAAItransactionsonintelligentsystems, 2017, 12(5): 616-623.
2017-06-08. < class="emphasis_bold">網(wǎng)絡(luò)出版日期
日期:2017-10-21.
國家自然科學(xué)基金項目(61202191);計算智能重慶市重點實驗室開放基金項目(CQ-LCI-2013-06);國家重點研發(fā)計劃項目(2016YFC0802209).
龔勛.E-mail:xgong@swjtu.edu.cn.
猜你喜歡
作文中學(xué)版(2022年1期)2022-04-14 08:00:34
學(xué)生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
計算機(jī)工程(2015年8期)2015-07-03 12:19:07
