404 Not Found
404 Not Found
基于自然語言處理的中文產科電子病歷研究
張坤麗, 馬鴻超, 趙悅淑, 昝紅英, 莊 雷
(1.鄭州大學 信息工程學院 河南 鄭州 450001; 2.鄭州大學 第三附屬醫院 河南 鄭州 450052)
DOI: 10.13705/j.issn.1671-6841.2017005
基于自然語言處理的中文產科電子病歷研究
張坤麗1, 馬鴻超1, 趙悅淑2, 昝紅英1, 莊 雷1
(1.鄭州大學 信息工程學院 河南 鄭州 450001; 2.鄭州大學 第三附屬醫院 河南 鄭州 450052)
電子病歷中蘊含著大量的醫療知識和患者的健康信息,而產科電子病歷的結構化及信息抽取對臨床決策支持及提高人口的生育健康水平具有重要意義.首先對中文產科電子病歷的結構特點及內容進行了分析,并采用基于規則的方法對電子病歷數據進行了清洗和結構化;其次采用最大熵(ME)模型及基于規則方法按治療類型對電子病歷進行分類,分類的F值達到88.16%;最后,為了進一步利用電子病歷進行信息抽取和知識挖掘,以短句為單位,相似度為衡量標準,采用支持向量機(SVM)模型對首次病程記錄進行去重處理及自動差異化分析,從分析的結果中篩選出68.6%的重復及相似短句.
產科電子病歷; 數據清洗; 分類; 差異化; 相似度
DOI: 10.13705/j.issn.1671-6841.2017005
0 引言
醫療信息化離不開電子病歷的支撐.電子病歷是指醫務人員在醫療活動過程中,使用醫療機構信息系統生成的文字、符號、圖表、圖形、數據、影像等數字化信息,并能實現存儲、管理、傳輸和重現的醫療記錄,是病歷的一種記錄形式[1].美國麻省總醫院門診電子病歷系統于1960年開發完成并投入使用,是早期最著名的電子病歷系統[2].我國的電子病歷的廣泛實施起步較晚,自2010年國家衛生計生委醫政醫管局出臺《電子病歷基本規范(試行)》[1]之后,電子病歷在各級醫療機構廣泛實施.海量的電子病歷數據是醫療領域的大數據,蘊含著大量的醫療知識和患者的健康信息,亟待得到有效應用.
電子病歷包括一些自由文本(半結構或無結構)數據,采用自然語言處理技術(natural language processing,NLP)對電子病歷進行結構化和信息抽取,是充分利用電子病歷所蘊藏知識的重要一步.本文在分析中文產科電子病歷自由文本結構及內容的基礎上,對數據進行了清洗,去除病歷中存在的噪音數據,按照治療類型采用最大熵(maximum entropy,ME)模型對電子病歷進行了分類,并采用支持向量機(support vector machine,SVM)對電子病歷中的相似或相同句子進行了去重處理及差異化分析,為后續利用產科電子病歷大數據進行信息抽取及臨床決策支持奠定了基礎.
1 相關工作
國外對于電子病歷的研究起步較早,有針對電子病歷系統的研究[3],也有NLP技術在臨床決策支持中的研究[4].文獻[5]用SVM構建分類器對電子病歷中的命名實體進行識別,并且采用ME模型對電子病歷實體關系進行抽取.文獻[6]采用統計模型(條件隨機和ME)與規則相結合的方法識別電子病歷中的命名實體.文獻[7]用半監督的方法,用SVM作為分類器對電子病歷實體關系進行抽取.文獻[8]開發了一個臨床決策支持系統,用于提高診斷準確性,實現精準醫療.文獻[9]用神經網絡的方法對雙胞胎胎兒體重進行估計[9].此外,醫療領域還有其獨有的語言資源,如一體化醫學語言系統(unified medical language system,UMLS)[10],國際疾病分類標準(international classification of diseases,ICD)[11]和醫學系統命名法-臨床術語(systematized nomenclature of medicine-clinical terms,SNOMED CT)[12]等資源,這些資源為英文電子病歷的研究提供了術語規范及知識層級結構.
針對中文的電子病歷的研究則起步較晚,文獻[13]和[14]從不同的角度針對電子病歷的結構化進行了研究.文獻[15]對出院小結中存在的問題進行了歸納.此外,從自然語言處理的角度,文獻[16]采用分詞和詞性聯合模型——管道模型對中文電子病歷的詞性標注進行研究.文獻[17]采用條件隨機和深度學習的方法對實體和關系抽取進行了研究.在語言資源建設方面,文獻[18]借鑒I2B2的標注規范初步構建了電子病歷命名實體和實體關系標注語料庫.文獻[19]構建了中文醫學一體化醫學語言系統(Chinese unified medical language system,CUMLS).文獻[20]構建了中藥一體化醫學語言系統(traditional Chinese medical language system,TCMLS).針對中文產科電子病歷,文獻[21]對產科電子病歷中的手術知情同意書進行了研究.文獻[22]運用統計學的方法探討了產科病歷的質量問題,分析其缺陷并制定出相應的改進措施.到目前為止,還鮮有公開的中文電子病歷的數據集,并且缺乏公開的中文生物醫學領域語言資源的支撐,這也為開展中文電子病歷研究帶來了一定的困難.
2 產科電子病歷的結構及特點
2.1基本結構和內容
中國的電子病歷書寫以《電子病歷基本規范(試行)》[1]為基本指導.圖表和自由文本是電子病歷數據的主要表現形式[23],而自由文本這種非結構化數據是信息抽取研究的最主要對象.本文著重介紹病程記錄和出院小結兩部分的結構和內容.病程記錄包括首次病程記錄(每份病歷中一個)、日常病程記錄(也稱查房記錄,每份病歷中有一個或多個)、上級醫師查房記錄和出院小結(每份病歷一個)等.本文以15家醫院隨機抽取的產科3 034份電子病歷為研究對象,對電子病歷結構及內容進行了分析.所使用的數據均已作隱私化處理.病程記錄及出院小結結構及所包含的內容如表1所示.

表1 產科電子病歷結構與內容
2.2產科電子病歷現存問題及數據清洗
醫院信息管理系統在設計時為了減少輸入工作量,通常采用直接套用模板,或在原有病歷上修改的方式錄入.這種方式會導致一些問題,如電子病歷中重復內容較多,信息不一致,時間先后順序錯誤等.本文主要針對電子病歷中存在的信息的冗余與缺失以及信息的錯誤這兩類問題進行分析.
2.2.1信息冗余與缺失 根據電子病歷章節特征,采用基于規則的方法對電子病歷進行結構化時發現,電子病歷中存在首次病程記錄和出院小結缺失的情況.由于已經隱私化處理,無法建立兩個病歷之間的關聯,根據信息抽取的需求,對缺失這兩部分的電子病歷直接從數據集中移除.移除的病歷一共279份.
對冗余信息的處理,采用自動比對的方式進行篩選,當檢測到同一個病歷中有多個首次病程記錄或出院小結時,根據信息的完整性以及記錄時間,甄選出正確的首次病程記錄或出院小結.
2.2.2電子病歷數據錯誤及識別 通過分析,本文所采集的電子病歷中,第一類較為集中的錯誤是時序錯誤.按診療順序及診療時間,病歷中出現時間超前,甚至為未來時間的情況.如本文抽樣采集的數據為2015年電子病歷,個別病歷中出現記錄時間為 “2016.12.23”的情況.針對時序錯誤問題,根據產科治療的時序邏輯,首次病程記錄中出現的時間一般不會早于末次月經時間,且不會晚于預產期的時間.根據診療活動的邏輯順序,設計出了時序檢測方案,具體算法如圖1所示.經時序錯誤檢測,共發現有10份病歷出現時序錯誤.

圖1 時序錯誤檢測算法Fig.1 The detection algorithm of time series error
第二類錯誤是電子病歷中的邏輯錯誤.針對產科住院者的情況,在電子病歷的入院診斷和出院診斷中,會出現“孕X產Y”這樣明確的診斷.根據在產科所進行的如順產、剖宮產、引產、流產、保胎治療等醫療活動中,在入院診斷中為“孕X產Y”,出院診斷則應為“孕X產Y”或“孕X產Y+1”.如入院診斷是“孕2產0”,當所進行的治療為保胎治療,出院診斷是“孕2產0”,此出院診斷與入院診斷邏輯一致.但是某一份病歷中入院診斷和出院診斷中都是“孕4產2”,但在出院診斷中有“剖娩了一個男嬰和一個女嬰”,據此可判斷此病歷出現了邏輯錯誤.基于以上分析,發現如果進行生產,則首次病程記錄中的入院診斷中的“孕X產Y”, 出院小結中的出院診斷應為“孕X產Y+1”,而其余醫療活動,入院診斷和出院診斷中的“孕X產Y”應保持一致.根據這一規律,用規則分別提取到這兩部分內容進行比對,經過處理發現共有52份出現此類邏輯錯誤的病歷.
2.3信息過濾及結構整理
電子病歷是對病人診療活動的完整記錄,其中有些數據是常規的告知性信息,并非患者的個性信息,如手術前的風險告知等內容,對所有的患者都是相同的.這部分內容會成為數據分析與挖掘時的噪音,因此從病歷中剔除這類無特定病人信息的告知性文本.此外,電子病歷的原始文本是所有內容混排在一起,為了進行數據分析,需要把首次病程記錄、查房記錄和出院小結按章節進行整理,對首次病程記錄按表1所示的內容,如主訴、入院查體、產科檢查、輔助檢查、入院診斷、診斷依據、鑒別診斷和診療計劃等進行結構化.為了便于進一步的研究,先把病程記錄和出院小結提取出來,然后對首次病程記錄的格式進行整理.
3 產科電子病歷的自動分類
患者在產科的診療按其是否分娩可分為保胎治療、分娩和其他,按分娩方式可分為順產、剖宮產、引產和流產.本文把產科電子病歷分為:順產、剖宮產、引產、流產、保胎治療和其他6類.諸如產后并發癥等入住產科的病歷,則歸入其他類別.相同的診療活動,電子病歷的內容及結構較為相似,因此把產科電子病歷按診療活動分為不同種類,便于對同一種類電子病歷的信息進行抽取處理.本文采用最大熵模型和基于規則的方法對電子病歷進行自動分類.
3.1最大熵原理
最大熵模型的基本原理是在已知部分信息的前提下,關于未知分布最合理的推斷是符合已知信息最不確定或最大隨機的推斷.對于任意一個隨機變量X,隨機變量的不確定性越大,熵也就越大.
(1)
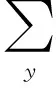
(2)
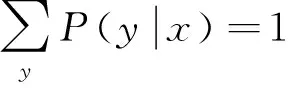
3.2實驗
實驗數據是人工標注了1 500份經過數據清洗的電子病歷,包含順產(29.4%)、剖宮產(30.47%)、保胎治療(30.13%)、引產(5.73%)、流產(2.47%)和其他(1.8%)6類,其中1 000份作為訓練語料,500份作為測試語料.本實驗選用最大熵工具包(https://github.com/lzhang10/maxent),分詞工具是ICTCLAS(https://codeload.github.com/NLPIR-team/NLPIR-ICTCLAS/zip/master),詞表是在互聯網和《婦產科學》[24]上收集的婦產科醫療術語和藥物名稱等一共1 751個.實驗采用P、R和F-1值作為評價指標.
基于規則的方法是在觀察語料過程中,根據電子病歷特點,將其分類特征形式化,形成了兩個規則集Ruleset1和Ruleset2,其中|Ruleset1|lt;|Ruleset2|.Ruleset1規則集中主要是顯式特征,包括“入院診斷”和“出院診斷”中“孕X產Y”形式及含有某個類別特定的關鍵字,通過對“孕X產Y”比對及關鍵字匹配確定相應的類別.采用Ruleset1的分類效果較差,P為82.47%,保胎類別的準確率P_bt為94.01%.
進一步總結了非明顯特征,加入到規則集Ruleset1中,形成Ruleset2.Ruleset2中增加了諸如流產和引產在月份上的區別,2.2.2節所提到的入院診斷和出院診斷中“孕X產Y”判斷分類等規則.采用規則集Ruleset2進行分類時,P為88.53%,保胎類別的準確率P_bt為97.51%.雖然基于規則的方法也有比較好的分類結果,但總結規則的工作比較煩瑣,費時費力,人工成本較高,且沒有學習能力,因此無法有效推廣.通過表2中的F-1值可以看出,最大熵模型能夠對病歷很好的分類,F-1達到了最高的88.16%,并且能夠很好地推廣利用.

表2 分類結果
4 首次病程記錄的文本去重
根據目前現有電子病歷的特點,每個類別的電子病歷有大量的重復和相似性信息.如果能去除這部分重復的信息,保留個性,則能提高后期的信息抽取等工作的效率.例如在主訴中出現的“發育正常,營養中等”都是正常的指標,且多份電子病歷中的首次病程記錄中均相同,并非診斷的決定性因素,因此本文考慮通過計算句子相似度,去同存異,僅留存個性信息.但若句子中有數值信息,如末次月經時間,雙頂徑等,是診斷所依據的關鍵信息,因此在進行文本去重時,首先將這類句子篩選出來,不參與相似度計算.
4.1句子相似度計算
本文采用基于語義的方法計算句子的相似度(https://my.oschina.net/twosnail/blog/370744#comment-list),具體公式為
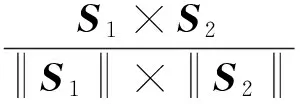
(3)
其中S1、S2是兩個句子的語義向量表示.S1和S2的計算方式如下:
1) 給定句子Ti,分詞后,得到的所有詞W構成的向量為句子Ti的向量表示,即Ti={w1,w2,…,wn}.
2) 給定兩個句子Ti、Tj的向量表示,將Ti、Tj中的所有詞wi進行合并,重復的詞只保留一個,得到兩個向量之和,稱為Ti、Tj的并集,表示T=TiUTj.
3) 給定句子Ti的向量表示Ti={w1,w2,…,wn}和一個詞wi,依次計算wi和Ti中每一個詞的相似度(值為0到1之間),所有結果中的最大值稱為wi在Ti中的語義分數,表示為Ci.
4) 給定兩個句子Ti、Tj的向量表示,Ti和Tj的集合T={w1,w2,…,wn},對T中的每一個詞wi,計算wi在Ti中的語義分數Ci=score(如果wi在Ti中出現,則score=1;如果wi在Ti中沒有出現,本文設score=0.2),T中每個分詞的語義分數組成的一個向量,稱為Ti基于T的語義向量,表示為Si={C1,C2,…,Cn}.
4.2實驗數據準備
基于相同類型診療活動電子病歷更為相似的原則,采用第3節所訓練最大熵模型對未標注的1 255份電子病歷進行分類,并對分類結果進行人工校對,加上第3節所用1 500份電子病歷,抽取所包含的824份剖宮產類別的首次病程記錄進行文本去重.在進行相似度計算之前,先對數據做如下處理.
1) 用標點符號“;”(中文分號)、“.”(中文句號)、“、”(中文頓號)、“,”(中文逗號)、“:”(中文冒號)、“;” (英文分號)、“:” (英文冒號)和正則表達式“[1-9]{1}\.”把首次病程記錄切分成一條條的短句,共130 910條短句.
2) 含有數字的短句可能包含關鍵信息,去除含有數字的短句,剩余10 023條短句.
3) 進行分詞處理.
4.3實驗結果
通過對相似度計算結果的分析,將相似度的閾值設置為0.9,這個閾值能將相似度較高的句子剔除,保留個性化信息.實驗數據中的10 023短句,經過相似度計算,刪除相似度高于0.9之后,剩余3 146條短句.可以看出,經過相似度處理之后,短句減少了68.6%.例如句子“患者自覺胎動明顯增多或者減少”和句子“患者胎動無明顯異常”有一定差別,相似度為0.694 9,因此不能刪除.句子“唐氏篩查及四維彩超正常”和句子“四維彩超及唐氏篩查均無異常”相似度較高為0.900 7,則進行刪除.通過這樣的差異化分析,保留了更有價值的信息,并且減小了數據規模,為進一步的輔助診斷及高效的信息抽取奠定了基礎.
5 總結與展望
本文完成的主要工作有:分析產科電子病歷的基本結構及內容,對電子病歷中存在的問題及數據清洗進行了介紹.采用基于規則及最大熵模型按診療活動類型對電子病歷的自動分類進行了研究;依據分類結果,采用語義相似度的計算方法剔除電子病歷中相似度較高的句子,為差異化分析及信息抽取奠定基礎.本文所完成的工作對產科的電子病歷進行了初步的分類及處理,今后將在此基礎上以醫學專業敘詞表為基礎,構建知識圖譜,對電子病歷中所包含的實體、關系以及所蘊含的知識進行識別和抽取,針對不同類型的生產方式進行研究分析,為臨床專家提供醫療輔助決策.
[1] 李曉雅.衛生部出臺《電子病歷基本規范(試行)》[J]. 中國社區醫師(醫學專業),2010,11(3):21.
[2] 楊孝光,李運明,張虎軍,等.發達國家及地區電子病歷發展現狀與啟示[J].西南軍醫,2013,15(3):345-346.
[3] KOHANE I S, GREENSPUN P, FACKLER J, et al. Building national electronic medical record systems via the world wide web[J]. American journal of ophthalmology, 1996, 122(3):191-207.
[4] DEMNERFUSHMAN D, CHAPMAN W W, MCDONALD C J. What can natural language processing do for clinical decision support?[J]. Journal of biomedical informatics, 2009, 42(5):760-772.
[5] BRUIJN B, CHERRY C, KIRITCHENKO S, et al. Machine-learned solutions for three stages of clinical information extraction: the state of the art at i2b2 2010[J]. Journal of the American medical informatics association, 2011, 18(5): 557-562.
[6] CLARK C, ABERDEEN J, COARR M, et al. MITRE system for clinical assertion status classification[J]. Journal of the American medical informatics association, 2010, 18(5): 563-567.
[7] RYAN R J. Groundtruth budgeting: a novel approach to semi-supervised relation extraction of medical language[D]. Cambridge: Massachusetts institute of technology, 2011: 2-66.
[8] CASTANEDA C, NALLEY K, MANNION C, et al. Clinical decision support systems for improving diagnostic accuracy and achieving precision medicine[J]. Journal of clinical bioinformatics, 2015, 5(1):1-16.
[9] MOHAMMADI H, NEMATI M, ALLAHMORADI Z, et al. Ultrasound estimation of fetal weight in twins by artificial neural network[J]. Journal of biomedical science and engineering, 2011, 4(1):46-50.
[10] BODENREIDER O. The unified medical language system (UMLS): integrating biomedical terminology[J]. Nucleic acids research, 2004, 32: 267-270.
[11] UZUNER ?, LUO Y, SZOLOVITS P. Evaluating the state-of-the-art in automatic de-identification[J]. Journal of the American medical informatics association, 2007, 14(5): 550-563.
[12] UZUNER ?, SOLTI I, CADAG E. Extracting medication information from clinical text[J]. Journal of the American medical informatics association, 2010, 17(5): 514-518.
[13] 于一,廖睿,葉大田. 電子病歷結構化方法概述[J]. 北京生物醫學工程,2007,26(1):103-106.
[14] 李偉. 非結構化病歷文檔結構化轉換方法研究[D]. 天津:河北工業大學,2013.
[15] 趙津京,滕國洲,冷建文,等. 出院小結存在的問題及對策[J]. 解放軍醫院管理雜志,2009,16(1):34-35.
[16] 趙芳芳. 面向中文電子病歷的詞性標注技術研究[D]. 哈爾濱:哈爾濱工業大學, 2014.
[17] 葉楓,陳鶯鶯,周根貴,等. 電子病歷中命名實體的智能識別[J]. 中國生物醫學工程學報,2011,30(2):256-262.
[18] 楊錦鋒, 關毅, 何彬,等. 中文電子病歷命名實體和實體關系語料庫構建[J]. 軟件學報, 2016, 27(11): 2725-2746.
[19] 李丹亞,胡鐵軍,李軍蓮,等.中文一體化醫學語言系統的構建與應用[J].情報雜志,2011,30(2):147-151.
[20] 曾召,王小平.UMLS與中醫藥一體化語言系統的建立[J].中華醫學圖書情報雜志,2006,15(3):1-3.
[21] 李廉. 電子病歷婦產科手術知情同意書缺陷分析與改進措施[J].中國病案,2015,16(2):56-59.
[22] 江林,童亞非,李興海,等. 婦產科住院病歷書寫質控與持續改進[J].現代醫學,2011,39(3):353-355.
[23] 楊錦鋒,于秋濱,關毅,等. 電子病歷命名實體識別和實體關系抽取研究綜述[J]. 自動化學報,2014,40(8):1537-1562.
[24] 謝幸, 茍文麗. 婦產科學[M]. 第8版.北京:人民衛生出版社, 2013.
(責任編輯:方惠敏)
TheStudyofChineseObstetricElectronicMedicalRecordsBasedonNaturalLanguageProcessing
ZHANG Kunli1, MA Hongchao1, ZHAO Yueshu2, ZAN Hongying1, ZHUANG Lei1
(1.SchoolofInformationEngineering,ZhengzhouUniversity,Zhengzhou450001,China; 2.TheThirdAffiliatedHospital,ZhengzhouUniversity,Zhengzhou450052,China)
Electronic medical record contains a lot of medical knowledge and patient′s health information. The structuralization and information extraction of obstetric electronic medical records is of great significance on clinical decision and the bearing health. The structural characteristics and content of Chinese obstetric electronic medical records were analyzed. The EMR data was cleaned and structuralized by using the rule-base method. Then the electronic medical records of different treatment types were automatically classified by using the maximum entropy model and rule-based methods. And theFvalue reached 88.16%. At last, in order to further use electronic medical records for information extraction and knowledge mining, the support vector machine model, in which a phrase was taken as a unit and similarity as benchmark, was used to remove the repetition in first course of disease records. And the result was that 68.6% of the reduplicate and similar phrases were deleted from the records. It was expected that this study could contribute to the further research on the information extraction from obstetrics electronic medical records.
obstetric electronic medical record; data cleaning; categorization; differentiation; similarity degree
2017-01-08
973課題(2014CB340504);國家自然科學基金項目(61402419,60970083);國家社會科學基金項目(14BYY096);河南省科技廳基礎研究項目(142300410231,142300410308).
張坤麗(1977—),女,河南鞏義人,講師,主要從事自然語言處理、語言資源構建研究,E-mail:ieklzhang@zzu.edu.cn;通信作者:馬鴻超(1990—),男,河南開封人,主要從事自然語言處理研究,E-mail:ma-hc@foxmail.com.
TP391
A
1671-6841(2017)04-0040-06
