基于深度學習特征的異常行為檢測
2017-11-20 08:37:46王軍夏利民
湖南大學學報·自然科學版 2017年10期
關鍵詞:特征提取
王軍+夏利民


摘 要:已有的異常行為檢測大多采用人工特征,然而人工特征計算復雜度高且在復雜場景下很難選擇和設計一種有效的行為特征.為了解決這一問題,結合堆積去噪編碼器和改進的稠密軌跡,提出了一種基于深度學習特征的異常行為檢測方法.為了有效地描述行為,利用堆積去噪編碼器分別提取行為的外觀特征和運動特征,同時為了減少計算復雜度,將特征提取約束在稠密軌跡的空時體積中;采用詞包法將特征轉化為行為視覺詞表示,并利用加權相關性方法進行特征融合以提高特征的分類能力.最后,采用稀疏重建誤差判斷行為的異常.在公共數據庫CAVIAR和BOSS上對該方法進行了驗證,并與其它方法進行了對比試驗,結果表明了該方法的有效性.
關鍵詞:異常行為;深度學習特征;堆積去噪編碼器;特征提取;稠密軌跡
中圖分類號:TP391 文獻標志碼:A
Abnormal Behavior Detection Based on Deep-Learned Features
WANG Jun,XIA Limin
(College of Information Science and Engineering,Central South University ,Changsha 410075,China )
Abstract:Most existing methods of abnormal behavior detection merely use hand-crafted features to represent behavior,which may be costly. Moreover,choice and design of hand-crafted features can be difficult in the complex scene without prior knowledge. In order to solve this problem,combining the stacked denoising autoencoders (SDAE) and improved dense trajectories,a new approach for abnormal behavior detection was proposed by using deep-learned features. To effectively represent the object behavior,two SDAE were utilized to automatically learn appearance feature and motion feature,respectively,which were constrained in the space-time volume of dense trajectories to reduce the computational complexity. The vision words were also exploited to describe the behavior using the method of bag of words. In order to enhance the discriminating power of these features,a novel method was adopted for feature fusing by using weighted correlation similarity measurement. The sparse representation was applied to detect abnormal behaviors via sparse reconstruction costs. Experiments results show the effectiveness of the proposed method in comparison with other state-of-the-art methods on the public databases CAVIAR and BOSS for abnormal behavior detection.
Key words:abnormal behavior; deep-learned features; SDAE; feature extraction; dense trajectories
異常行為檢測是智能監控系統的核心,近年來,已引起了學術界和工業界的廣泛關注,并成為計算機視覺的重要研究課題.然而,場景的復雜性和異常行為的多樣性,使得異常行為檢測仍然是一項具有挑戰性的工作.
根據所用特征,異常行為檢測方法可分為兩大類:基于視覺特征的異常檢測和基于軌跡的異常檢測.在基于物體軌跡的異常檢測方面,Junejo等[1]以軌跡的位置、速度、空時曲率等作為特征,提出了基于DBN的異常行為檢測.Yang等[2]提出了基于軌跡和多示例學習的局部異常檢測方法.Li等[3]用三次樣條曲線表示目標軌跡,提出了基于稀疏表示的異常檢測方法.Mo等[4]提出了基于軌跡聯合稀疏表示的異常行為檢測方法.Kang等[5]用HMM表示軌跡的運動模式,提出了基于HMM的異常檢測方法.然而,在目標遮擋情況下,跟蹤性能明顯下降,導致異常檢測率低.
為了解決上述問題,采用視覺特征進行異常行為檢測,如方向梯度直方圖HOG,3D空時梯度,光流直方圖HOF等.Saligrama等[6]利用局部空-時特征和最優決策規則進行異常檢測.Nallaivarothayan[7]以光流加速度、光流梯度直方圖作為特征,提出了基于MRF的異常事件檢測.Wang等[8]引入加速度信息,構建混合光流方向直方圖,采用稀疏編碼進行異常檢測.Zhang等[9]結合運動信息和外觀信息進行異常檢測.Mehran等[10] 利用光流特征構建社會力模型SFM來表示人群行為和異常行為識別.Wang和Schmid[11]提出了基于稠密軌跡行為識別,沿著稠密軌跡提取HOG,HOF以及運動邊界描述符MBH來表示行為,利用SVM進行行為識別.然而,這些視覺特征是人為設計的,很難有效地反映行為特性,并且計算復雜.endprint
目前,基于深度學習特征表示已成功地用于異常行為檢測.Xu等[12]采用堆積去噪編碼器提取外觀特征和運動特征,利用多類SVM進行異常行為檢測.Erfani等[13]利用深度置信網絡提取行為特征,利用SVM進行異常行為檢測.Zhou等[14]采用空時卷積神經網絡提取行為特征,進行人群異常行為檢測和定位.Fang等[15]以圖像的顯著性信息和多尺度光流直方圖作為低層特征,然后采用深度學習網絡PCANet從這些低層特征中提取更有效的特征用于異常事件檢測.Hu等[16]構建了一個深度增強慢特征分析網絡,并用于行為特征提取和異常檢測.基于深度學習的異常行為檢測是借助于深度結構,通過多層非線性變換從原始圖像中學習和挖掘復雜的非線性行為特征表示,相比基于人工特征的異常檢測,由于深度學習得到的特征往往具有一定的語義特征和更強的區分能力,能更有效地表示行為特性,因此基于深度學習的異常行為檢測準確率更高.同時基于深度學習的異常行為檢測降低了計算復雜性.然而,基于深度學習的異常行為檢測的性能遠沒有達到人們的期望,主要原因是:1)深度學習方法需要大量的樣本用于訓練,而一般的行為數據庫樣本相對比較少;2)為了平衡計算代價,基于深度學習的行為表示通常采用下采樣策略,導致信息丟失[17].
為了解決該問題,受文獻[11-12]的啟發,我們結合堆積去噪編碼器和改進的稠密軌跡,提出了一種基于深度學習特征的異常行為檢測方法,利用深度學習提取行為特征,采用稀疏重建進行異常行為檢測.該方法基本思想是利用堆積去噪編碼器的學習能力和稠密軌跡方法的優良采樣性能和特征提取策略來提取有效的行為特征.首先利用堆積去噪編碼器,沿行為興趣點軌跡提取深度外觀特征和運動特征;由于不同行為視頻中目標個數不同,從而興趣點個數及其對應的軌跡數不同,導致整個特征長度不同,為了解決該問題,采用詞包法將特征轉化為行為視覺詞表示;在此基礎上,為了提高特征的分類能力,利用加權相關性法對這二種特征進行融合;最后,采用稀疏重建進行異常行為檢測.在公共數據庫CAVIAR和BOSS上利用文中方法和其它幾種方法進行了對比實驗.
1 改進的稠密軌跡提取
首先介紹稠密軌跡的提取[11].把圖像劃分成大小為W×W的網格,并在每個網格上進行采樣.在采樣過程中,以網格的中心作為采樣點,對每個采樣點進行三值插值處理得到興趣點.為了得到足夠多的興趣點,按1/2比例增加空間尺度,由于視頻分辨率的限制,可選擇8個空間尺度.通過實驗發現,當W=5,在所有數據庫上都可以得到很好的實驗結果.
由于在沒有結構的均勻區域內跟蹤不到任何點,因此,將這些區域內的點去掉,這些點對應的自相關矩陣的特征值很小,為此設置一個閾值,舍棄自相關矩陣的特征值小于閾值的興趣點.閾值設置為:
T=0.001×maxi∈Imin(λ1i,λ2i)(1)
式中:(λ1i,λ2i)是圖像I中點i自相關矩陣的特征值.
得到興趣點后,利用光流法在每個空間尺度上對興趣點進行跟蹤,得到其運動軌跡.設第t幀圖像It的稠密光流為wt =(ut, vt),這里ut和vt分別為光流的水平分量和豎直分量,則It中某一點zt =(xt, yt)在下一幀It+1中的位置可通過對wt進行中值濾波平滑得到:
zt+1=(xt+1,yt+1)=(xt,yt)+(M*wt)|(xt,yt)(2)
式中:M為中值濾波的核,其大小為3×3.采用中值濾波可以很好地保留跟蹤過程中邊界上的點.
把各幀對應的興趣點連接起來就得到該興趣點的軌跡:(zt,zt+1,…,zt+L-1).在跟蹤過程中可能會出現軌跡漂移,為了避免這種現象,我們限制采樣幀的長度L=15,另外,由于一條持續5幀圖像的軌跡才是“可靠的”,短于5幀的軌跡自動被刪除.為了得到稠密的軌跡,在每一幀圖像中,如果在一個W×W的鄰域內沒有任何跟蹤點,那么選擇新的點作為采樣點,并對新采樣點進行跟蹤.在后處理階段,我們刪掉靜態軌跡和突然漂移比較大的軌跡,因為前者不包含運動信息,后者很有可能是跟蹤誤差所致.
2 行為深度特征
稠密軌跡附近包含豐富的行為信息,我們利用稠密軌跡和堆積去噪編碼器SDAE提取行為深度外觀特征和運動特征.首先介紹堆積去噪編碼器,然后描述基于稠密軌跡和堆積去噪編碼器的行為深度學習特征提取方法.
2.1 堆積去噪編碼器
去噪編碼器DAE[18]是一種三層神經網絡,用于從噪聲數據i重建原數據xi,DEA包含二個部分:編碼器和解碼器.DEA學習就是學習兩個映射函數fe(W;b)和fd(W′;b′),其中W,b表示編碼器部分的權值矩陣和偏差向量,W′,b′對應于解碼器的參數.對于噪聲數據i,編碼器的隱層輸出為y:
y=fe(i)=s(Wi+b)=11+e-(Wi+b)(3)
解碼器目的是從噪聲數據i重建原數據xi:
zi=fd(y)=s(W′y+b′)(4)
給定一組訓練樣本X={xi}Ni=1,通過求解下列優化問題來學習DEA的參數(W,W′,b,b′):
minW,W′,b,b′∑Ni=1‖xi-zi‖22+λ(‖W‖2F+
‖W′‖2F)+β∑Kj=1KL(μ‖)(5)
式中:第一項表示重建誤差,第二項為權值懲罰項,第三項為稀疏性約束,λ,β為平衡參數,μ是稀疏性參數,它表示隱節點的系數水平,K是隱含層的節點個數,j是隱含層第j 個節點對所有訓練樣本的平均閾值化激活值,如果平均激活值大于0.5時,j=1,否則j=0.第三項稀疏性約束為:
KL(μ‖j)=-μlogj+(1-μ)log(1-j)(6)
利用梯度下降法對式(5)進行求解,可確定DAE參數.endprint
將多個DAE逐層堆疊形成SDAE,其中低層DAE的輸出作為上一層DAE的輸入.SDAE的訓練,采用從低層向高層逐層訓練的方式對各層中的DAE進行訓練.訓練好的SDAE可用于從輸入數據中學習到有效的特征表示.
2.2 行為深度特征提取
我們分別利用兩個SDAE在以軌跡為中心的3D體積中提取行為的外觀特征和運動特征.3D體積的大小為N×N×L,L=15為軌跡的長度,N取32.為了嵌入結構信息,首先,將該立方體劃分為nσ×nσ×nτ的時-空網格,本文取nσ=2,nτ=3;然后在這些網格(大小為16×16×5)中用SDAE提取深度特征;最后將所有網格的特征結合得到與該軌跡對應的深度特征.
圖1表示提取行為深度特征的SDAE的結構,它包括兩個SDAE,其中一個用于學習外觀特征,稱為外觀堆積去噪編碼器(ASDAE),另一個用于學習運動特征,稱為運動堆積去噪編碼器(MSDAE).每個SDAE 包括兩個部分:編碼器和解碼器.編碼器的輸入層節點數等于輸入數據的維數,然后,每層節點數逐層減少一半,直到“瓶頸”隱層,解碼器的結構與編碼器對稱,“瓶頸”隱層的輸出就是深度特征,實驗結果表明,當隱層數為5時系統檢測率最高.
2.2.1 外觀深度特征
在灰度視頻圖像中,以軌跡為中心的3D體積中各個網格區域的圖像(16×16×5)作為ASDAE的輸入,其“瓶頸”隱層的輸出作為外觀深度特征,然后,將體積中各個網格區域的外觀深度特征連接起來得到該軌跡(該興趣點)的外觀深度特征.由于網格區域大小為16×16×5,所以ASDAE的輸入層節點個數為1 280,各隱層節點個數分別為:640,320,160,80,40;一條軌跡對應的外觀特征維數為480(2×2×3×40).
2.2.2 運動深度特征
根據光流場提取運動深度特征.以軌跡為中心的3D體積中各個網格區域的光流場(16×16×2×5)作為MSDAE的輸入,其“瓶頸”隱層的輸出作為運動深度特征,然后,將體積中各個網格區域的運動深度特征連接起來得到該軌跡(該興趣點)的運動深度特征.這里ASDAE的輸入層節點個數為2 560,各隱層節點個數分別為:1 280,640,320,160,80;一條軌跡對應的外觀特征維數為960(2×2×3×80).
將兩類特征合在一起,則每一條軌跡可用1 440維的向量表示.相比一般深度特征而言,我們的深度學習特征具有以下優點:
1)不需要大量的行為樣本,適合于樣本少的行為數據庫識別.因為我們用深度網絡不是直接提取整個行為特征,而是提取行為區域中的采樣點(興趣點)的特征,而采樣點的個數足以訓練深度網絡.
2)盡可能保留了行為信息.這是因為我們采用的是稠密軌跡采樣,這是一種濃密的采樣,信息丟失較少,同時保留了結構信息.
3)計算復雜度不高.因為我們只是在稠密軌跡附近提取特征,而包含少量運動信息的區域并未計算.
3 基于加權相關性的特征融合
3.1 行為特征的詞包表示
由上可知,對于一條軌跡可以得到一個1 440維的特征向量.由于不同視頻中目標個數不同,導致興趣點的個數以及對應的軌跡條數不同,行為特征維數不同,因此,利用詞包法將行為特征用視覺詞表示,以統一行為的維數.分別根據外觀深度特征和運動深度特征利用詞包法建立外觀視覺字典和運動視覺字典,然后分別由外觀視覺詞和運動視覺詞表示外觀深度特征和運動深度特征.
具體方法是:首先,提取軌跡的外觀深度特征/運動深度;然后對所有軌跡外觀深度特征/運動深度進行聚類,得到Nv個類中心,每個類對應一個視覺詞.對于測試行為樣本,根據最近鄰原則,把它的每條軌跡分類到每一類,于是可得到各個視覺詞在樣本中出現的頻率,這些頻率就構成樣本的視覺詞表示.
經過多次實驗得到外觀視覺詞和運動視覺詞的個數分別為230和470.因此,外觀深度特征和運動深度特征分別用230維和470維的視覺詞向量表示.
3.2 基于加權相關性的特征融合
為了提高特征的分類能力,采用基于加權相關性的特征融合方法將外觀深度特征和運動深度特征結合在一起形成700維的特征向量.
為了表示方便,將外觀深度特征和運動深度特征分別用y1,y2表示,則融合后的特征y為:
y=(ω1y1,ω2y2)(7)
這里ωi是加權系數,且(ω1)2+ (ω2)2=1.我們根據類內一致性和類間可分性來確定該加權系數.
類內一致性:一般希望同類中的樣本在特征空間盡可能接近.但是通常在同一類中樣本特征會出現較大的方差,因此,沒有必要要求同類中的所有樣本都相互接近.一種權衡的方法是保證同類中同一近鄰內的樣本盡可能接近.設yi=(ω1 yi1,ω2 yi2),yj=(ω1 yj1,ω2 yj2)表示第i,第j個樣本,則類內一致性定義為:
Sc=∑Ni=1∑j∈N+k(Fi)〈yi,yj〉‖yi‖‖yj‖=
∑Ni=1∑j∈N+k(Fi)∑2k=1ω2kykiykj∑2k=1ω2k(yki)2∑2k=1ω2k(ykj)2(8)
式中:N+k(Fi)表示樣本Fi的、且與Fi屬于同一類的k個最近鄰樣本的索引集.
類間可分性:要求特征具有好的區分性,即不同類的兩個樣本在特征空間盡可能遠離.但這樣的樣本對很多,為了減少計算量,只考慮特征空間分界面附近的樣本對.于是定義類間可分性為:
Sc=∑Ni=1∑j∈N-k(Fi)〈yi,yj〉‖yi‖‖yj‖
=∑Ni=1∑j∈N-k(Fi)∑2k=1ω2kykiykj∑2k=1ω2k(yki)2∑2k=1ω2k(ykj)2(9)endprint
式中:N-k(Fi)表示樣本Fi的、且與Fi不同類的k個最近鄰樣本的索引集.
融合后的特征應具有良好的類內一致性和類間可分性,因此通過求解下列優化問題確定加權系數:
maxω{(Sc-Sb)+λs‖ω‖}
s.t. ωk>0,‖ω‖=1(10)
式中,λs是控制參數.
采用梯度下降法求解式(10),即:
ωk(t+1)=ωk(t)+ηLωk|ωk=ωk(t)(11)
式中:t為迭代次數,η為迭代步長,L=(Sc-Sb)+λs‖ω‖為目標函數.
Lωk=
∑Ni=1∑j∈N+k(xi)hij(ω)ωk-∑j∈N-k(xi)hij(ω)ωk+2λsωk(12)
這里:
hij=∑2k=1ω2kykiykj∑2k=1ω2k(yki)2∑2k=1ω2k(ykj)2(13)
hij(ω)ωk=
2fkijb1/2iib1/2jj+bij(b1/2jjf1/2ii/b1/2ii+b1/2iif1/2jj/b1/2jj)∑2k=1ω2k(fik)2∑2k=1ω2k(fjk)2(14)
fkij=ykiykj(15)
bij=∑2k=1ω2kykiykj(16)
4 基于稀疏重建的異常行為檢測
得到行為的特征后,采用稀疏重建來進行異常行為檢測,其基本思想是任何行為可以用一組正常訓練樣本的稀疏線性組合表示.對于正常行為,稀疏重建誤差小,而異常行為稀疏重建誤差比較大.因此,我們可根據重建誤差[19]來進行異常檢測.
設有C類正常行為,每個行為用上述特征向量表示,D=[D1,D2,…,DC]表示稀疏字典,其中Di是由K個第i類行為構成的子字典,對于測試樣本y可表示為:
y=Dα(17)
這里,α=[α1,α2,…,αc]T為稀疏編碼向量.稀疏重建的關鍵是字典學習和求解稀疏編碼.
4.1 字典學習
給定訓練樣本集Y={y1, y2,…, yN}∈Rm×N,yi∈ Rm表示第i個正常樣本的特征向量,目的是學習字典D和稀疏編碼向量α,使Y可以通過字典的加權和來重建,即:Y=Dα,也就是求解下列優化問題:
minD,α‖Y-Dα‖F+λ‖α‖2,1(18)
這里λ控制參數,第一項是重建誤差,第二項是稀疏性約束.這是一個非凸的優化問題.但是如果D和α中的一個固定,則問題就變為線性的.因此,通過依次固定D和α,可以導出D和α,具體算法[20]如下:
1)輸入訓練樣本集Y,初始字典D0∈Rm×K,i=0;
2)令i=i+1;
3)固定D利用式(22)求αi;
4)固定α利用式(21)求Di;
5)重復2),3),4)步,直到收斂;
6)輸出字典Di.
算法中每一步確定Di和αi就是求解:
Di=argminD‖Y-Dα‖F(19)
αi=argminα‖Y-Dα‖F+λ‖α‖2,1(20)
式(19)采用K-SVD算法來求解.由于‖α‖2,1是非平滑的,所以,式(20)對應的優化問題是凸的、非平滑的優化問題,用一般優化算法求解會導致收斂速度很慢,在此,利用Nesterov提出的方法[21]來求解.考慮目標函數f0(x) + g(x),其中,f0(x) 是凸的且平滑,而g(x)是凸的、非平滑,Nesterov采用
PZ,L(x)=f0(Z)+〈f0(Z),x-Z〉+
L‖x-Z‖2F+g(x)(21)
來近似表示Z處的f0(x) + g(x).這里L是Lipschitz常數.這樣每次迭代,只需求解minx PZ,L(x).
定義f0(α)=‖Y-Dα‖F,g(α)=λ‖α‖1,則有:
PZ,L(α)=f0(Z)+〈f0(Z),α-Z〉+
L‖α-Z‖2F+λ‖α‖2,1(22)
類似文獻[21],可得到式(20)的解:
argminαPZ,L(α)=Hλ/L(Z-1Lf(Z))(23)
式中,Hτ:M∈Rk×k → N ∈Rk×k
Ni=0,‖Mi‖≤τ;
(1-τ/‖Mi‖)Mi,otherwise(24)
這里,τ=λ/L,M=Z-(1/L)f(Z),Mi是原數據的第i行,Ni是計算得到的矩陣的第i行.
4.2 異常行為檢測
給定一個字典D,對于測試樣本y可用式(17)表示,其中,稀疏編碼α可通過求解式(25)獲得:
α*=minα‖y-Dα‖2+λ‖α‖1(25)
一旦得到最優的稀疏編碼α*,可以計算稀疏重建代價(SRC) [19]:
S(y,α*,D)=‖y-Dα‖2+λ‖α*‖1(26)
對于正常行為,稀疏重建代價較小,而異常行為稀疏重建代價較大.因此如果
S(y,α*,D)>ε(27)
則y為異常行為.式中,ε是預先設置的閾值.
5 實驗與結果
為了驗證所提方法的有效性,我們在公共數據庫CAVIAR和BOSS上進行了實驗,并與以下4種方法進行對比:1) Mo等[4]提出的基于軌跡聯合稀疏表示的異常行為檢測方法;2)Wang等[11]提出的基于稠密軌跡方法;3)Xu等[12]提出的基于外觀深度網絡和運動深度網絡的異常檢測方法;4)Zhou等[14]提出的基于空時卷積神經網絡的異常檢測方法.endprint
我們以ROC曲線評估異常行為檢測效果,ROC曲線以FPR為橫坐標,TPR為縱坐標.其中:
TPR=TPTP+FN,FPR=FPFP+TN(28)
這里,TP (True positive)是真異常行為,FN(False negative)假正常行為,FP (False positive)是假異常行為,TN(True negative)真正常行為. 我們選擇不同的閾值ε,分別計算FPR和TPR,然后,作ROC曲線.ROC曲線越靠近上方,曲線下面積AUC越大,則檢測的準確率越高,否則檢測準確率越低.
5.1 CAVIAR 數據庫
在實驗中,我們利用CAVIAR數據庫的第一部分數據進行實驗.這些數據是利用廣角鏡頭拍攝的,包括行走、閑逛,休息、跌倒或暈倒等單人行為,以及會談、兩人走近和分開、兩人打架等交互行為.每個場景包括3至5片段,每個片段持續40至60 s,分辨率為384×288,共采用了26個片段.該數據庫可用于單人異常行為和兩人的交互異常行為.
由于每片段包含幾種行為,因此采用人工方法將每片段分成多個鏡頭,使每個鏡頭只包含一個行為.結果數據庫分成1 200個行為鏡頭,其中,200個異常行為和1 000正常行為.其中打架、追趕、閑逛、丟包和暈倒等異常行為個數分別為44,39,42,37和38.圖2是該數據庫的一些異常行為的視頻幀.其中,圖2(a)為一個人穿過大廳時暈倒;圖2(b)是一個人丟包;圖2(c)是兩個人打架.實驗中,我們首先提取稠密軌跡;其次隨機選擇500萬條軌跡訓練SDA,并采用K-均值聚類法得到230個外觀視覺詞和470個運動視覺詞(視覺詞的個數分別從100到1 000變化時,發現當外觀視覺詞為230個、運動視覺詞為470個可取得最好性能);然后隨機選擇800個正常行為學習特征融合參數,得到:ω1=0.3,ω2=0.7;最后,用800個正常行為學習稀疏字典.以全部異常行為樣本和余下的200個正常樣本作為測試樣本,測試結果為AUC=0.996,表明文中方法的檢測率很高.圖3給出了幾種檢測方法的ROC曲線.表1是幾種檢測方法ROC曲線下的面積AUC.結果表明,對于單人異常行為和兩人的交互異常行為,文中方法比其它3種方法具有更好的檢測準確率.
5.2 BOSS數據庫
BOSS數據庫是在列車上通過9個攝像頭拍攝的,包括14個視頻序列,每段視頻持續1到5 min.分辨率為720×576,幀率25 fps.14個視頻包括3個正常行為視頻,11個異常行為視頻.異常行為包括:搶手機、打架、搶報紙、騷擾、暈倒、恐慌.該數據庫可用于單人、多人的異常行為檢測.
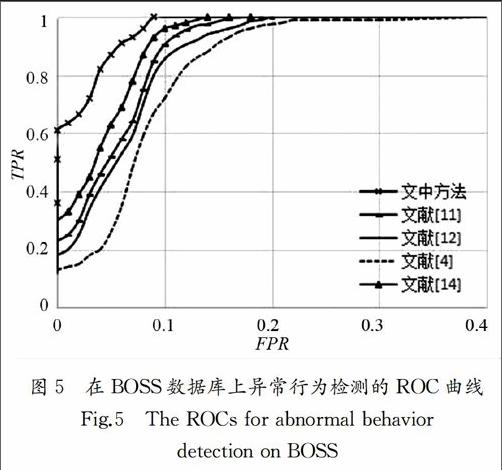
同樣采用人工方法將每視頻分成多個鏡頭,每個鏡頭只包含一個行為.結果這個數據庫分成1 600個行為鏡頭,其中,400個異常行為和1 200正常行為,搶手機、打架、搶報紙、騷擾、暈倒、恐慌等異常行為數分別為52,70,65,58,65,90. 圖4是該數據庫的一些異常行為的視頻幀.其中圖 4(a)為打架;圖4(b) 是暈倒;圖4(c) 為搶手機.實驗過程和CAVIAR數據庫上的實驗一樣,隨機選擇500萬條軌跡訓練SDA、確定外觀視覺詞和運動視覺詞;選擇1 000個正常行為學習特征融合參數(ω1=0.35,ω2=0.65)和稀疏字典.用全部異常行為樣本和余下的200個正常樣本作為測試樣本,測試結果為AUC=0.982,即我們的方法有很高的檢測率.圖5是幾種檢測方法的ROC曲線.
以上結果表明,無論是單人的異常行為檢測還是多人異常行為檢測,與其它方法相比,我們的方法都具有更高的檢測準確率.文獻[4]采用基于目標軌跡的異常行為檢測,由于視頻中有多人交互情況,不可避免存在遮擋問題,使得跟蹤性能明顯下降,導致異常檢測率比其它方法低.文獻[11]采用稠密軌跡特征(HOG,HOF 和MBH),這些特征是目前最好的人工特征[17],因此檢測準確率明顯提高.文獻[12]和[14]分別采用堆積自動編碼器和空時卷積神經網絡提取行為特征,這些特征能較好地描述人體行為,因此其檢測率超過93%.但這兩個方法檢測率并不比基于稠密軌跡方法高,這是因為:1)這些方法需要大量的樣本用于訓練深度學習網絡,而行為數據庫樣本相對比較少;2)為了平衡計算代價,提取行為表示通常下采樣策略,采用導致信息丟失.而我們的方法是沿行為興趣點的稠密軌跡提取行為的外觀特征和運動特征.一方面,由于在稠密軌跡附近有豐富的運動信息,利用堆積去噪編碼器強大的學習能力可提取有效的行為特征;另一方面,用深度網絡不是直接提取整個行為特征,只是提取行為區域中的采樣點的特征,而這些采樣點的個數足以訓練深度網絡,因此不需要大量的樣本訓練深度網絡,解決了訓練樣本不足對深度學習的影響,所以異常行為檢測率比其他幾種方法更高.
5.3 計算復雜性
我們對所提方法的計算復雜度進行了測試,所有實驗都在工作站 (2.8 GHz CPU,32GB RAM)上進行.表3為幾種方法分別在CAVIAR,BOSS中每幀平均計算時間.從表中可看出,基于目標軌跡的異常行為檢測計算時間最少,而基于稠密軌跡的異常行為檢測計算時間最長,我們的方法與其它二個基于深度學習的異常行為檢測計算時間適中,表明我們的方法是非常有效的.這是因為這幾種方法在異常識別階段的時間都差不多,并占總時間的很小部分,主要計算時間花費在特征提取上.基于目標軌跡的異常行為檢測用B樣條函數近似目標軌跡,取B樣條函數50個控制點的坐標作為行為特征,顯然這些特征的提取需要時間最少.而基于稠密軌跡的異常行為檢測所用時間主要在光流場計算、稠密軌跡提取和HOG,HOF 和MBH的計算,其中特征HOG,HOF 和MBH的計算需要很長時間;文獻[12]和[14]分別采用深度網絡提取特征,因此計算速度快;相比文獻[12]和[14],我們的方法多了一步稠密軌跡提取,該過程約占總計算的10%,但由于我們只是提取稠密軌跡附近的特征,那些包含少量運動信息的圖像區域并未計算,所以總的計算時間并未顯著提高.endprint
6 結 論
結合堆積去噪編碼器和改進的稠密軌跡,提出了一種基于深度學習特征的異常行為檢測方法.首先,利用堆積去噪編碼器沿著稠密軌跡提取深度外觀特征和深度運動特征;然后,為了提高特征的分類能力,利用加權相關性方法對這二種特征進行融合;最后,采用稀疏重建進行異常行為檢測.為了驗證文中方法的有效性,在公共數據庫CAVIAR和BOSS上對文中方法進行了測試,并與其它幾種方法進行了對比,結果表明,文中方法具有更高的檢測率和較低的計算復雜度.
參考文獻
[1] JUNEJO I N.Using dynamic Bayesian network for scene modeling and anomaly detection[J].Signal Image and Video Processing,2010,4(1):1-10.
[2] YANG W Q,GAO Y ,CAO L B. TRASMIL:A local anomaly detection framework based on trajectory segmentation and multi-instance learning[J]. Computer Vision and Image Understanding,2013,117(10):1273-1286.
[3] LI C,HAN Z,YE Q M,et al. Visual abnormal behavior detection based on trajectory sparse reconstruction analysis[J]. Neurocomputing,2013,119(6):94-100.
[4] MO X,MONGAV,BALA R,et al. Adaptive sparse representations for video anomaly detection[J]. IEEE Transactions on Circuits and Systems for Video Technology,2014,24(4):631-645.
[5] KANG K,LIU W B ,XONG W W. Motion pattern study and analysis from video monitoring trajectory [J]. IEICE Transactions on Information and Systems,2014,97( 6):1574-1578.
[6] SALIGRAMA V,CHEN Z. Video anomaly detection based on local statistical aggregates[C]// IEEE Computer Vision and Pattern Recognition. Providence:IEEE,2012:2112-2119.
[7] NALLAIVAROTHAYAN H,FOOKES C,DENMAN S. An MRF based abnormal event detection approach using motion and appearance features[C]// IEEE International Conference on Advanced Video and Signal based Surveillance. Seoul:IEEE,2014:343-348.
[8] WANG Q, MA Q ,LUO C H,et al. Hybrid histogram of oriented optical flow for abnormal behavior detection in crowd scenes[J]. International Journal of Pattern Recognition and Artificial Intelligence,2016,30(2):1-14
[9] ZHANG Y ,LU H C,ZHANG L H,et al. Combining motion and appearance cues for anomaly detection[J].Pattern Recognition,2016,51(C):443-452.
[10]MEHRAN R,OYAMA A,SHAH M. Abnormal crowd behavior detection using social force model[C]//IEEE Conference on Computer Vision & Pattern Recognition. Miami Beach:IEEE Comp Soc,2009:935-942.
[11]WANG H,SCHMID C. Action recognition with improved trajectories[C]//IEEE International Conference on Computer Vision.Sydney,Australia:IEEE Comp Soc,2013:3551-3558.
[12]XU D,RICCI E. Learning deep representations of appearance and motion for anomalous event detection[C]//British Machine Vision Conference. Swansea:Spring,2015:1-12.
[13]ERFANI S M,RAJASEGARAR S,KARUNASEKERA S,et al . High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning[J]. Pattern Recognition,2016,58(C):121-134.endprint
[14]ZHOU S F,SHEN W,ZENG D,et al. Spatial- temporal convolutional neural networks for anomaly detection and localization in crowded scenes[J]. Signal Processing -Image Communication,2016,47:358- 368.
[15]FANG Z,FEI F,FANG Y. Abnormal event detection in crowded scenes based on deep learning [J]. Multimedia Tools and Applications,2016,75(22):14617-14639.
[16]HU X,HU S Q,HUANG Y P,et al. Video anomaly detection using deep incremental slow feature analysis network[J]. IET Computer Vision,2016,10(4):258-267.
[17]ZHU F,SHAO L,XIE J,et al. From handcrafted to learned representtations for human action recognition:A survey[J]. Image and Vision Computing,2016,55(1):42-52.
[18]VINCENT P,LAROCHELLE H,LAJPIE I,et al. Stacked denoising autoencoders:Learning useful representations in a deep network with a local denoising criterion[J]. Journal of Machine Learning Research,2010,11(12):3371-3408.
[19]CONG Y,YUAN,LIU J.Sparse reconstruction cost for abnormal event detection[C]// IEEE Computer Vision and Pattern Recognition. Colorado Springs:IEEE,2011,3449-3456.
[20]陳炳權,劉宏立. 基于稀疏分解的分塊圖像壓縮編碼算法[J]. 湖南大學學報:自然科學版,2014,41(2):95-101.
CHEN Bingquan,LIU Hongli. Block compressed image coding based on sparse decomposition[J]. Journal of Hunan University:Natural Sciences,2014,41(2):95-101.(In Chinese)
[21]NESTEROV Y. Gradient methods for minimizing composite objective function[J].Mathematical Programming,2013,140(1):125-161.endprint
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
