基于Hadoop的固網寬帶終端識別技術研究和實現
2017-11-20 11:07:25范孟可
計算機技術與發展 2017年11期
范孟可,王 攀
(南京郵電大學 物聯網學院,江蘇 南京 210003)
基于Hadoop的固網寬帶終端識別技術研究和實現
范孟可,王 攀
(南京郵電大學 物聯網學院,江蘇 南京 210003)
隨著大數據時代的來臨,大數據在各個行業應用越來越廣泛。大數據在運營商行業的應用也很普遍,但同時也遇到了很多技術問題,其中家庭畫像的塑造是運營商大數據的一個核心問題。如何提取和識別固網寬帶下的終端類型是一個有待解決的問題。不像移動網,固網寬帶由于沒有信令通道,所以不攜帶任何準確的終端信息,因而對固網下的終端類型識別比較困難。傳統方法都是采用解析和匹配HTTP GET報文中的UA字段進行識別。但這種方法由于UA的非標準化,以及終端數量和種類眾多的緣故而導致終端類型的識別準確率低下。文中采用Hadoop框架,利用Hive中UDF的方法,結合分布式爬蟲獲取終端庫,可以更加快速準確地識別出用戶上網終端信息。實驗結果表明,終端識別準確率可以達到92%以上,相比傳統方法有了大幅提升。
終端識別;Hadoop;User Defined Function (UDF);分布式爬蟲;固網寬帶;大數據運營
0 引 言
當今,隨著計算機技術的發展,大數據被應用到生活中的各行各業。大數據已經是行業的趨勢,當今時代也是“大數據”[1]時代。
傳統的電信運營商還只是把數據簡單地保存起來,沒有發揮數據的價值。而隨著信息技術的快速發展,運營商開始意識到數據對企業日常的管理和營銷的支撐具有重大意義。因此,運營商建立了一些企業信息化系統為公司的經營決策[2]和資源配置提供幫助。這些系統包括企業的管理系統、運營支撐系統、市場營銷支撐系統等。相對于互聯網商,電信運營商的最大優勢是它擁有用戶的全流量數據,是用戶數據[3]的第一接口。電信運營商擁有用戶身份信息、網絡狀態、終端、業務識別、位置、社交關系、消費信用等信息,而且這些信息具有很大的商業價值。另外手機、PAD等移動終端是移動互聯網時代必不可少的物品。電信運營商需要對用戶使用的移動終端做深入研究,以此來提升用戶體驗,提高自己的用戶量。因此進行終端型號識別以及終端功能配置識別具有很大的意義。
(1)不僅能夠減輕無線網絡中數據業務負擔,而且能提高服務質量。固網寬帶自建家庭WiFi是一個很好的解決方案。統計有多少移動終端支持WiFi功能對于運營商來說是需要解決的問題。
(2)對于傳統市場營銷,往往通過區域劃分來反映相應的用戶商業價值。但隨著互聯網的發展,區域劃分并不能準確代表用戶的商業價值[4]。現在提出通過用戶終端、用戶上網行為和用戶訂閱的業務來分析用戶潛在的商業價值。
因此,為了滿足以上類似的要求,研究互聯網中用戶的移動終端類型成為重要課題。然而,在這個大數據時代,人們的生活中出現了很多新型移動互聯網業務,比如微信等即時通信、支付寶等手機支付、百度地圖等導航服務和直播平臺等。而且當今移動互聯網用戶量巨大,在網絡方面4G的普及,電信百兆寬帶的提倡,大大提高了網絡速率。在智能終端[5]方面,硬件處理性能和軟件功能都有大幅提高。這些因素導致網絡流量數據[6]空前巨大,這些海量的用戶數據,對于數據處理能力也提出了更高的要求,傳統的計算方式已經不能滿足當前數據量的要求。然而云計算模型Hadoop框架使對海量的數據處理[7]和挖掘成為可能。Hadoop的出現為人們提供了一個可靠的共享存儲和處理分析系統,使人們在存儲和分析大數據時更加高效,其分布式文件系統HDFS可以實現數據的分布式存儲。
基于此,文中采用Hadoop框架,對用戶終端進行識別。提出了自己的識別方法并通過實驗進行驗證。
1 用戶終端識別的方法
對于移動用戶終端,最早是根據HTTP報文的User-Agent(UA)報文頭獲取終端性能[8]信息。
早期,互聯網是基于文本的,用戶是通過敲命令的方式訪問互聯網。后來開發出了瀏覽互聯的工具,這些工具稱為用戶代理,即User-Agent。通過對User-Agent[9]進行解析,可以獲得用戶終端的瀏覽器、操作系統、字符集和終端型號等。各種各樣的HTTP請求報文[10]格式和字符集在不斷變換,網絡開發者無法應對,因此,標準化組織提出了兩個規范:
(1)萬維網協會提出了復合配置/偏好設置(CC/PP)標準化,即移動終端需要采用統一標準的格式向網絡服務上傳移動終端配置信息。
(2)開放移動聯盟提出了一個CC/PP詳細字典,即User Agent Profile (UAProff)。UAProff可以用來表示移動終端信息,而且在不好的無線網絡中,網絡服務根據終端性能,可以高效地在終端顯示內容。一個移動終端如果遵循了UAProff標準,當它向服務端發送HTTP請求時,請求報文中會包含終端信息的XML文件URL。服務端獲取URL后,讀取XML文件,得到終端信息。
雖然發布了以上兩個標準,但是市場的移動終端類型很多,很多都沒有遵循以上標準,致使終端識別沒有得到好的解決。這時開源項目WURFL(Wireless Universal Resource File)提出了另一種解決方案。UA字段中含有很多用戶移動終端的信息,WURFL就是基于UA自身內容進行終端識別。WURFL首先將UA的內容與包含終端信息的配置文件進行文本匹配,這樣Web服務器就可以識別終端的型號和品牌。這種方式突破了UA格式的限制,然而仍有缺陷,因為它識別的終端信息需要依賴自身的資料庫。當今的用戶終端市場上,移動終端日益更新,但是WURFL資料庫中終端型號及終端信息的更新速度遠遠趕不上用戶終端的腳步,因此這種終端識別的準確率不是很高。
另外,傳統上對User-Agent獲取終端信息時,采用基于字符串匹配的方法。這種方法就是對User-Agent獲取能夠代表終端類的字符串,然后與一個內容很大的機器詞典中的詞條進行逐一匹配或者按照某種算法進行匹配,如果配到了,則獲取到終端類型。該種方法實現簡單,但是對于海量的用戶數據來說具有很大的缺點。首先大容量的機器詞典一般存于文件或者數據庫中,占用很大的資源,而且匹配時對于機器詞典具有很大的依賴性,不同詞典會導致不同的結果。其次,當數據量很大時,終端匹配的效率非常低。當數據量超過千萬級別時,數據庫的性能會直線下降。上述方法幾乎不能完成海量數據的用戶終端型號識別。
文中是對User-Agent進行分析,獲取相應用戶終端信息。對User-Agent進行分詞[11],采用正則表達式[12],首先過濾掉不代表用戶終端信息的字符串,然后特定位置的字符串通過正則表達式獲取。因為各種移動終端較多,比如手機、平板、PC等,因此通過統計不同終端類型,寫出不同的正則表達式進行匹配,得到一個正則表達式的配置文件。然后利用分布式爬蟲獲取電商上各種終端型號的相關信息作終端庫信息。利用Hadoop/hive分布式快速處理大數據[13]量的特點進行終端匹配。為了使開發方便快捷,使用hive中的UDF功能,對用戶終端類型進行識別。
2 相關技術
2.1Hadoop簡介
Hadoop[14]是Apache組織管理的一個開源項目,是對于Google云計算理論Big Table、MapReduce、GFS的軟件實現。Hadoop可以讓用戶在不了解底層細節的情況下開發MapReduce程序,并可以運算和存儲在硬件配置較低的商用集群上。Hadoop主要包含兩個核心組件,即分布式文件系統HDFS和分布式計算模型MapReduce。HDFS[15]是Hadoop的分布式文件系統,包含兩種節點:namenode(管理者)和datanode(工作者)。namenode負責管理整個文件系統的命名空間,維護文件系統的樹及樹內的所有文件目錄,并將這些元數據保存在namenode的本地磁盤上。namenode也同時記錄每個塊及各個塊的數據節點信息。HDFS文件系統實際存儲是由datanode負責,根據需要存儲和檢索的數據塊,定期向namenode發送它們所存儲塊的列表,從而與namenode進行交互。MapReduce是一個編程框架模型,可以進行穩定、高效、超大數據量的分布式分析計算。MapReduce的執行主要包含Map和Reduce兩個過程,當Map過程結束后還會進行Shuffle/Sort過程,負責對Map產生的輸出進行排序和把Map輸出傳遞給Reduce。
2.2Hive/UDF
Hive[16-17]是構建在Hadoop上的數據倉庫平臺,其目的是讓Hadoop上的數據操作與傳統的SQL相結合,讓開發更簡單。Hive可以在HDFS上構建數據倉庫來存儲結構化的數據,這些數據來源于HDFS的原始數據。Hive擁有類似SQL的HiveQL查詢語言,可以進行存儲、查詢、變換數據、分析數據等操作。通過解析HiveQL[18]語句,在底層被轉換成MapReduce操作。更方便的是,Hive提供自定義函數,即UDF(User Defined Function)。雖然Hive中內置許多函數,但通常并不能滿足用戶的需求,因此Hive提供了自定義函數的開發。用戶根據自己的需求編寫相應的函數,從而更方便地對數據進行處理。在使用時,可以將自定義的函數打成jar包,在Hive會話中添加自定義jar文件,然后創建函數,繼而使用。另外,也可以將自定義函數寫到Hive的內置函數中,使之成為默認函數,這樣就不需要在使用時重新創建。通過上述內容不難發現,使用Hive中的HiveQL語句比編寫MapReduce代碼更簡單,而且提供UDF功能,更減少了開發的代碼。
2.3網絡爬蟲-WebMagic爬蟲框架
網絡通常類比成一個蜘蛛網,每個節點就是一個網站,蜘蛛絲就是網站的鏈接,聯系著各個網站。網絡爬蟲的基本原理就是通過網頁中的鏈接地址來找到下一個網頁,通常從網站主頁面開始,讀取網頁HTML內容,通過解析HTML內容獲取到想要的內容和其中的鏈接地址,然后從這個鏈接地址跳轉到下一個網頁,再進行解析。就這樣一直不斷地重復下去,直到把這個網站上的所有網頁都分析完為止。
WebMagic是一個開源的Java垂直爬蟲框架,目標是簡化爬蟲的開發流程,讓開發者注重邏輯功能開發。其主要功能包括:頁面下載、鏈接提取、URL管理和內容分析與持久化。WebMagic中的各組件如下:
(1)Downloader組件:采用Apache HttpClient對頁面進行下載,獲取頁面的HTML以便后續處理。
(2)PageProcessor組件:采用基于XPath和CSS的選擇器,對網頁的HTML內容進行解析,得到想要的信息。另外還可以從中獲取新的頁面鏈接。
(3)Schedule組件:主要負責對獲取的URL進行管理并去掉重復的URL。開發人員不僅可以使用基于JDK的內存隊列來管理URL,也可以通過Redis對URL進行分布式管理。
(4)Pipeline組件:對爬取結果進行自定義,獲取想要的數據格式,并且可以將結果保存到文件中或數據庫中,以實現數據的永久保存。
3 技術方案
基于Hadoop的電信運營商海量數據處理需要做到:
(1)不僅能夠海量讀取、存儲多種結構的用戶數據,還能對已有的數據倉庫進行監控和管理。
(2)能夠對大規模的數據進行高效處理運算,具有高數據吞吐量的功能。
(3)為了提高市場評估和網絡運營能力,需要具有高拓展性,支持低成本數據挖掘,同時兼容多種應用。
(4)實時性的數據分析要求不高。
基于以上的數據特性和目標,根據Hadoop和Hive的特性,對電信寬帶下的用戶終端信息進行挖掘,可以更快地處理海量數據,以及更方便地對用戶終端信息進行挖掘。同時編寫UDF將源數據進行預處理,從而得到人們期望處理的數據格式。Hive可以方便地插入用戶編寫的處理代碼并在查詢中調用它們。由此可以看出,利用hive執行任務的效率低于直接用MapReduce程序執行任務的效率,但是Hive給廣大用戶提供了最寶貴的SQL接口,并且避免了編寫繁瑣的MapReduce程序。為此,做出以下技術方案,如圖1所示。
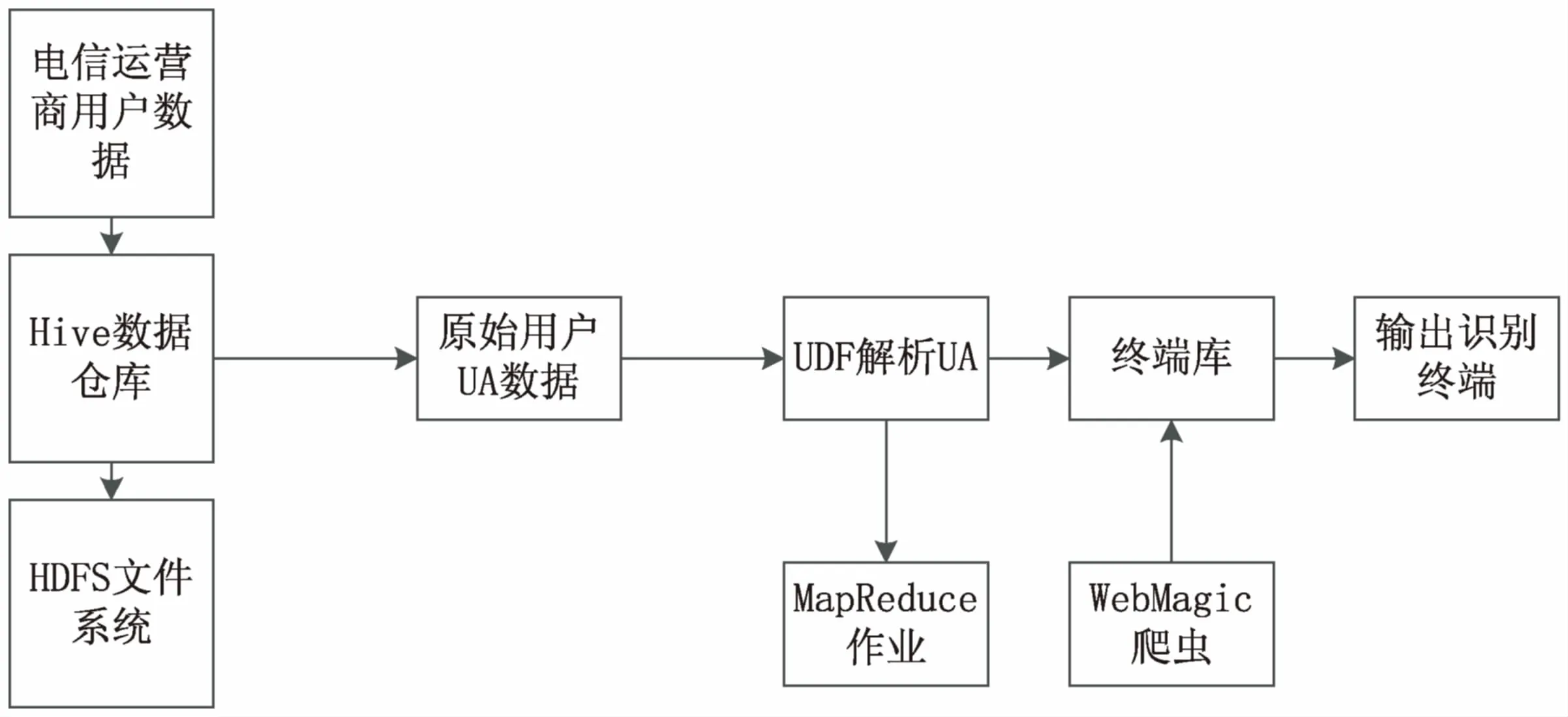
圖1 技術方案
因為用戶數據中包含用戶終端信息的字段,不是規則的,無法直接通過HQL語句特定的函數進行處理,所以采用UDF對用戶終端的字段進行處理。通過對用戶數據中含有UA的字段進行分析,寫出能獲取到用戶終端類型的正則表達式,寫成配置文件,作為正則匹配。UDF函數邏輯如圖2所示。
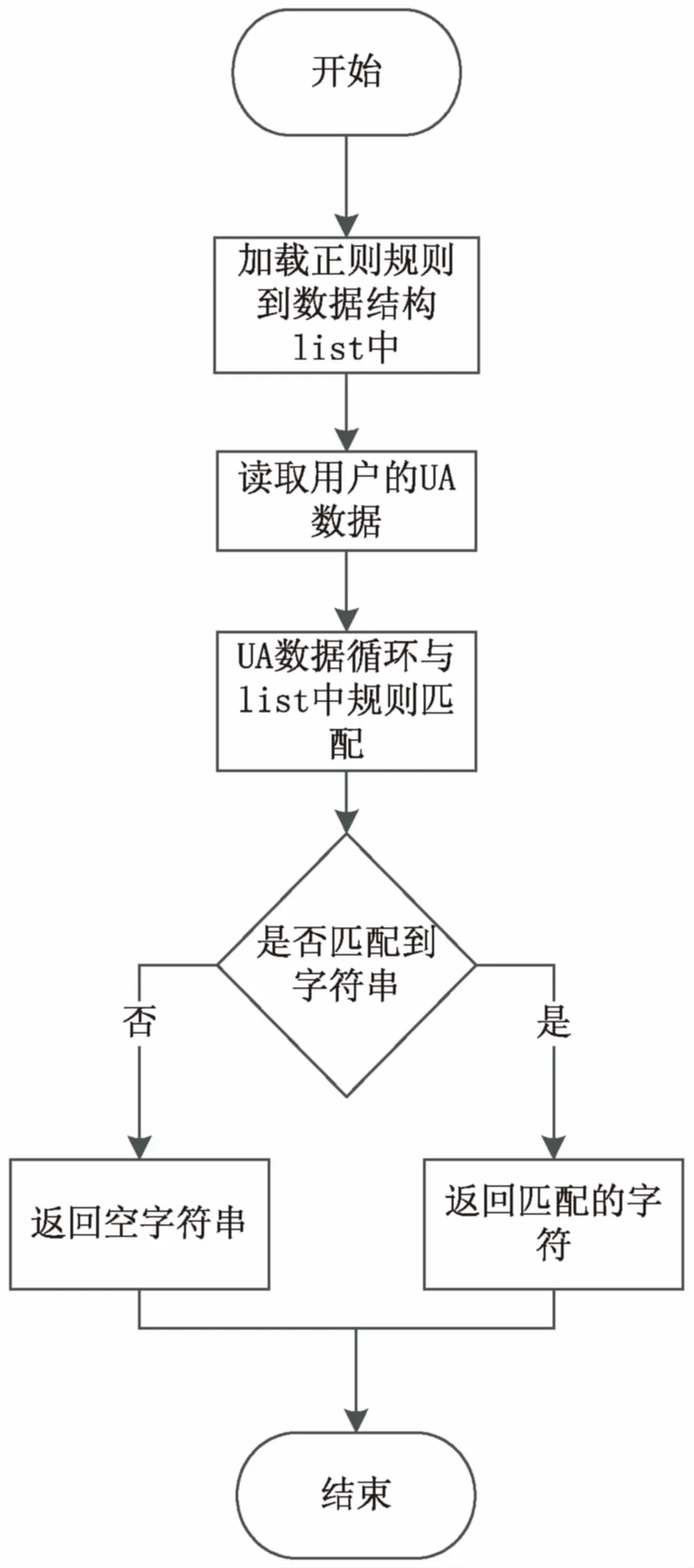
圖2 UDF函數邏輯
4 實 驗
4.1實驗環境
CDH的Hadoop集群,一個namenode節點,五個datanode節點。
namenode配置:CPU的型號為Intel 2650,內存為16 G。
datanode配置:CPU為Intel 2650,內存32 G。
4.2實驗數據
(1)用戶上網源數據。
為了驗證該技術方案,搭建了實驗測試環境,包括100臺終端(PC/PAD/PHONE/盒子),采集了12個月的數據,共計1 000萬條。數據記錄包含字段有用戶寬帶賬號、用戶終端信息、用戶訪問的URL。解析用戶的UA就是在包含用戶終端信息的字段中。這個字段的部分數據如圖3所示。
(2)識別用戶終端UA的正則表達式文件。
這個文件中的正則表達式觀察用戶上網的源數據中包含用戶終端信息的字段,寫出能匹配出用戶UA的正則表達式。
4.3實驗步驟
(1)創建用戶終端表。
create tablet_user_terminal_info (
username string,
ua string
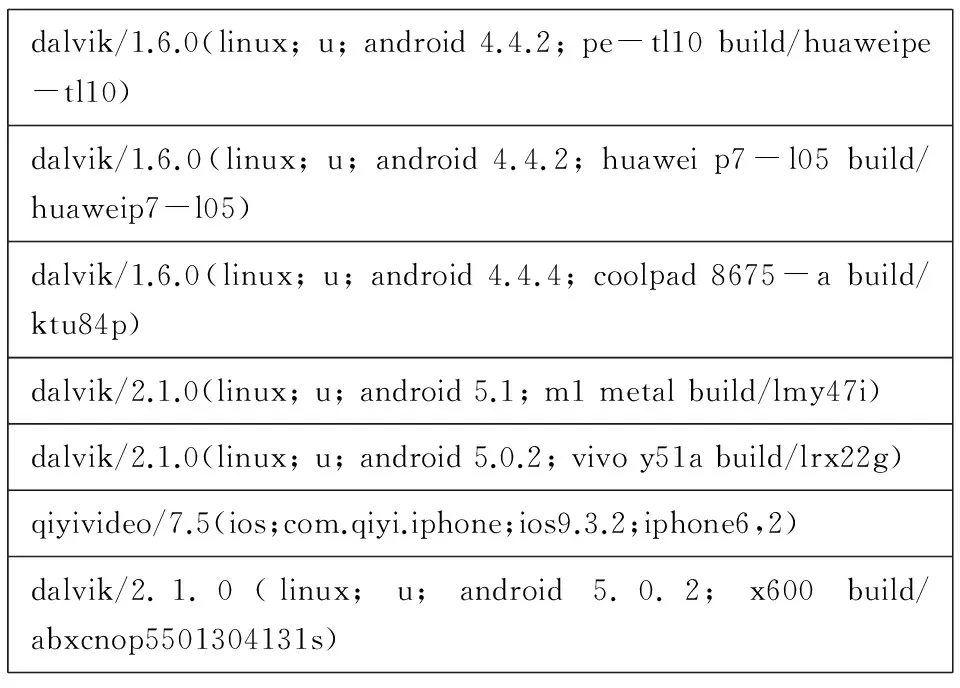
dalvik/1.6.0(linux;u;android4.4.2;pe-tl10build/huaweipe-tl10)dalvik/1.6.0(linux;u;android4.4.2;huaweip7-l05build/huaweip7-l05)dalvik/1.6.0(linux;u;android4.4.4;coolpad8675-abuild/ktu84p)dalvik/2.1.0(linux;u;android5.1;m1metalbuild/lmy47i)dalvik/2.1.0(linux;u;android5.0.2;vivoy51abuild/lrx22g)qiyivideo/7.5(ios;com.qiyi.iphone;ios9.3.2;iphone6,2)dalvik/2.1.0(linux;u;android5.0.2;x600build/abxcnop5501304131s)
圖3 源數據的UA字段
)
row format delimited
fields terminated by ' ';
(2)將編寫解析UA的udf程序打成的jar包導到Hive的環境變量中。
addjar /home/shkd/20160418/udf/datamining-1.0-SNAPSHOT-jar-with-dependencies.jar;
(3)創造臨時函數uaparse,解析源數據中包含用戶終端UA的信息的字段。
create temporary functionuaparse as 'cn.com.runtrend.datamining.udf.UAParserUDF'
(4)在Hive腳本調用創建的臨時函數,經解析結構存入t_user_terminal_info。
insert intot_user_terminal_info select username,uaparse (ua) from t_etlr_userinfo;
其中,t_etlr_userinfo為用戶上網源數據表。
(5)將解析UA中能代表用戶終端類型的字段與終端庫進行匹配,獲取最終的終端類型。
4.4實驗結果
t_user_terminal_info的部分內容見表1。
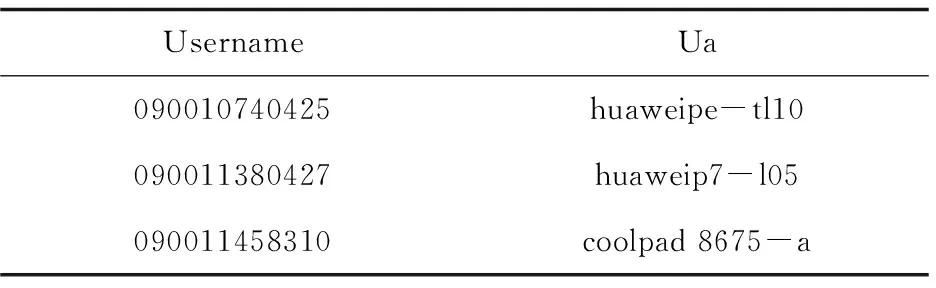
表1 t_user_terminal_info的部分內容
將解析的UA與終端庫進行匹配,最后對類型進行匯總,得到識別的不同終端類型數量,如圖4所示。
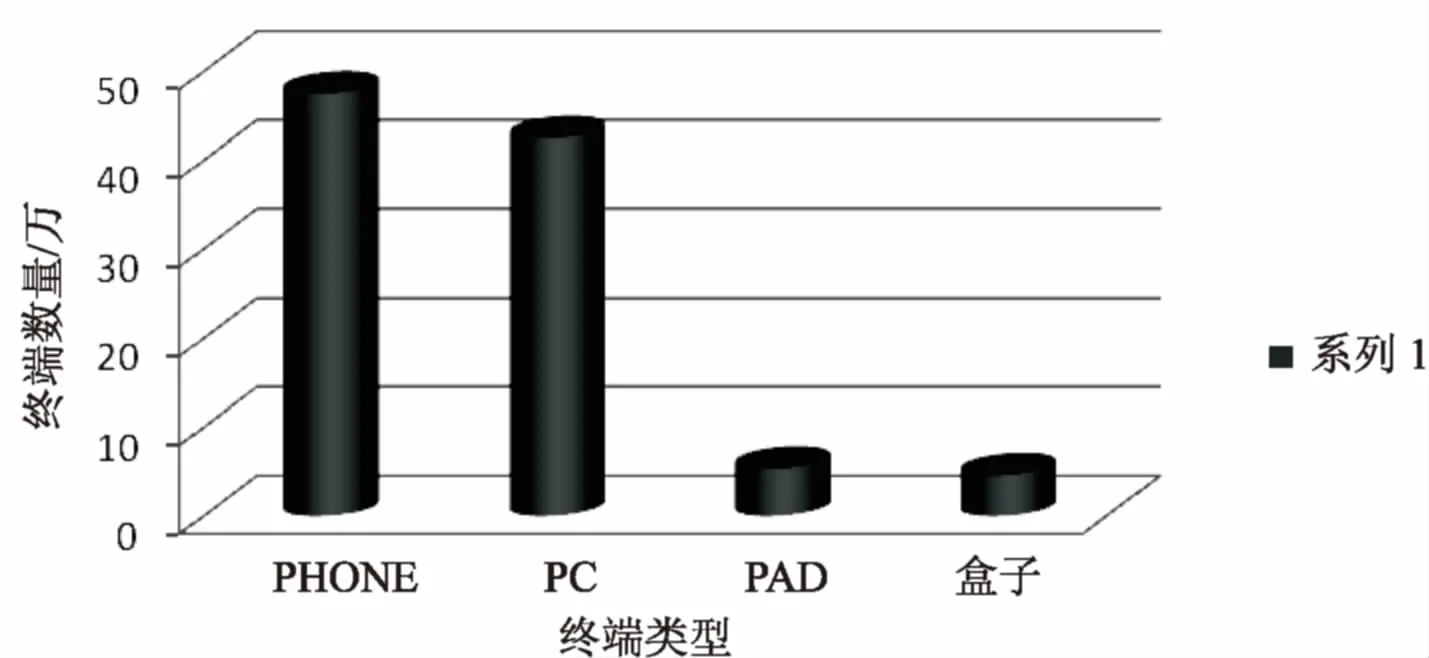
圖4 識別的終端類型數量
4.5實驗評估
對于其他用戶終端,采用準確率進行評估。記各種終端的總樣本數為n,準確識別的數量為m,識別終端的準確率為c=m/n*100%。對于上面實驗得到的識別準確率如圖5所示。
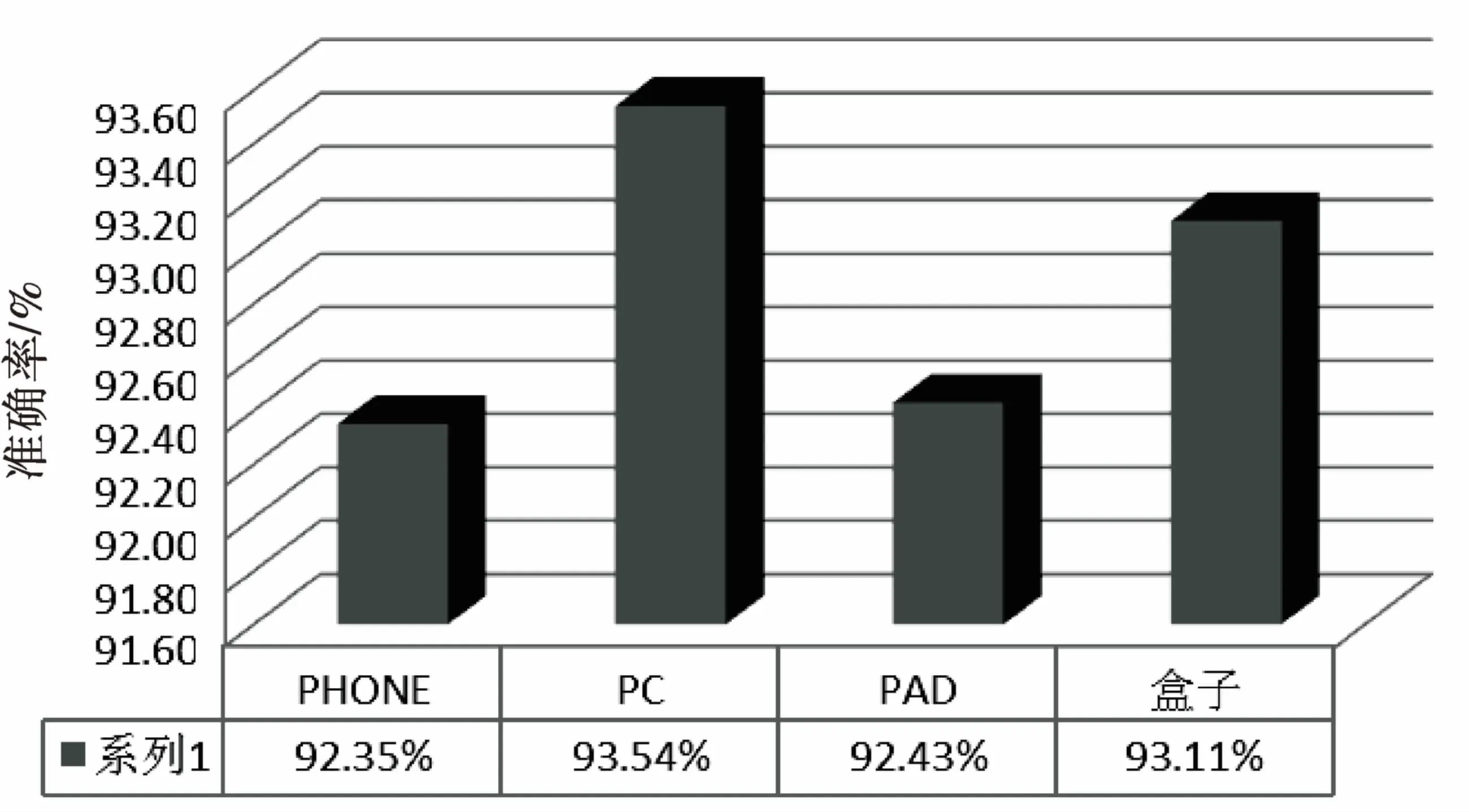
圖5 識別的終端準確率
最終識別的準確率并不是非常高,這其中存在一些主要原因:
(1)爬蟲獲取的終端庫可能并不完整,導致有些識別的終端不能被匹配到;
(2)正則匹配的配置文件中,正則匹配表達式并不完善,從而導致識別的終端出錯。
因此,正則表達式的配置文件和爬蟲的終端標準庫需要不斷更新,才能提高識別的準確率。
5 結束語
通過實驗發現,基于Hadoop/Hive集群可以實現對家庭固網寬帶下用戶終端信息的識別。Hadoop集群具有高可靠性、高拓展性、高容錯性。為分析固網寬帶用戶提供了一種非常好的技術手段。利用Hadoop平臺更高效,對電信寬帶用戶能精準挖掘有用信息,實現流量變現。另外,Hive提供SQL接口,利用SQL可以更方便地使用Hadoop,而且Hive還提供自定義函數,避免了復雜的MapReduce程序的編寫,讓開發更簡單。
[1] 張 引,陳 敏,廖小飛.大數據應用的現狀與展望[J].計算機研究與發展,2013,50:216-233.
[2] 馮明麗,陳志彬.基于電信運營商的大數據解決方案分析[J].通信與信息技術,2013(5):36-40.
[3] Baghel S K,Keshav K,Manepalli V R.An investigation into traffic analysis for diverse data applications on smartphones[C]//National conference on communications.[s.l.]:IEEE,2012:1-5.
[4] 陳 勇.大數據及其商業價值[J].通信與信息技術,2013(1):59-60.
[5] 王研昊,馬媛媛,楊 明,等.基于隱性標識符的零權限Android智能終端識別[J].東南大學學報:自然科學版,2015,45(6):1046-1050.
[6] Sagiroglu S,Sinanc D.Big data:a review[C]//International conference on collaboration technologies and systems.[s.l.]:IEEE,2013:42-47.
[7] 程 瑩,張云勇,徐 雷,等.基于Hadoop及關系型數據庫的海量數據分析研究[J].電信科學,2010,26(11):47-50.
[8] 梁其峰.WLAN終端識別技術研究[J].科技傳播,2013(18):186-188.
[9] Wu T,Xu Z,Ni L,et al.Towards a media fragment URI aware user agent[C]//Web information system and application conference.[s.l.]:IEEE,2014:37-42.
[10] La V H,Fuentes R,Cavalli A R.Network monitoring using MMT:an application based on the user-agent field in HTTP headers[C]//International conference on advanced information networking and applications.[s.l.]:[s.n.],2016:147-154.
[11] 何 莘,王琬蕪.自然語言檢索中的中文分詞技術研究進展及應用[J].情報科學,2008,26(5):787-791.
[12] 徐 乾,鄂躍鵬,葛敬國,等.深度包檢測中一種高效的正則表達式壓縮算法[J].軟件學報,2009,20(8):2214-2226.
[13] Pal A,Agrawal S.An experimental approach towards big data for analyzing memory utilization on a hadoop cluster using HDFS and MapReduce[C]//International conference on networks & soft computing.[s.l.]:[s.n.],2014:442-447.
[14] White T.Hadoop權威指南[M].北京:清華大學出版社,2015.
[15] 劉 鵬,黃宜華,陳衛衛.實戰Hadoop開啟通向云計算的捷徑[M].北京:電子工業出版社,2011.
[16] 謝 恒,王 梅,樂嘉錦,等.基于hive的計算結果特征提取與重用策略[J].計算機研究與發展,2015,52(9):2014-2024.
[17] Ganesh S,Binu A.Statistical analysis to determine the performance of multiple beneficiaries of educational sector using Hadoop-Hive[C]//International conference on data science & engineering.[s.l.]:IEEE,2014:32-37.
[18] Bhardwaj A,Vanraj,Kumar A,et al.Big data emerging technologies:a casestudy with analyzing twitter data using apache hive[C]//International conference on recent advances in engineering & computational sciences.[s.l.]:IEEE,2015:1-6.
ResearchandImplementationofTerminalIdentificationTechnologyofFixed-lineBroadbandBasedonHadoop
FAN Meng-ke,WANG Pan
(School of Internet of Things,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
With the coming of the era of big data,big data is more and more widely applied in various industries,which is also done in operators industry,but many technical problems are found simultaneously,of which family portraits of shaping is a core for operators of large data.How to extract and identify the terminal type of fixed-line broadband is a problem needed to be solved.Unlike mobile network,fixed-line broadband don’t take any accurate terminal information due to lack of signaling channel,so it is hard to conduct terminal type identification in fixed-line.The traditional method adopts UA fields of HTTP GET message parsing and matching for identification,but it is low in identification accuracy because of UA non-standardized and the large amounts of terminal number and varieties.Based on the Hadoop framework,the UDF of Hive is used,and combined with the distributed crawler for obtainment of terminal library,the user terminal information online is identified more quickly and accurately.According to the experiment,the accuracy of terminal identification can reach above 92%,a substantial increase compared with the traditional method.
terminal identification;Hadoop;User Defined Function (UDF);distributed crawler;fixed-line broadband;big data operations
2016-11-27
2017-03-29 < class="emphasis_bold">網絡出版時間
時間:2017-08-01
2015江蘇省產學研前瞻性聯合研究項目(BY2015011-02)
范孟可(1990-),男,碩士研究生,研究方向為大數據分析技術。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170801.1552.048.html
TP31
A
1673-629X(2017)11-0171-05
10.3969/j.issn.1673-629X.2017.11.037
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
