基于認知計算的就業咨詢智慧服務系統
2017-11-20 11:07:23唐新晨
計算機技術與發展 2017年11期
唐新晨
(南京郵電大學 通信與信息工程學院,江蘇 南京 210000)
基于認知計算的就業咨詢智慧服務系統
唐新晨
(南京郵電大學 通信與信息工程學院,江蘇 南京 210000)
隨著智慧服務系統的發展和大數據時代的到來,如何實現類似人腦的認知與判決為應屆生求職方向做出正確的決策,顯得尤為重要。智慧服務系統由四部分組成,數據采集單元使用Scrapy爬蟲框架獲取信息,能夠實時從各大招聘網站采集招聘信息;數據計算平臺使用隨機森林、SVM和樸素貝葉斯等基于認知計算的相關算法進行文本識別、特征提取以及文本分類等工作,能夠正確實現特征采樣和數據分類;數據存儲單元搭建MongoDB數據庫集群完成數據存儲工作,具備海量數據儲量能力和高容錯性;用戶服務平臺由Web應用框架構建,具備多用戶業務服務能力。因此其能夠有效采集和分類招聘信息,準確定位學生能力,從而高效地為院校學生的就業崗位選擇提供咨詢與幫助。
認知計算;Scrapy爬蟲;機器學習;Web應用;服務系統
0 引 言
IBM在2013年宣布成立“認知計算研究聯合會”。國內于2013年10月11日在北京舉辦了以“從大數據到認知計算”為主題的認知計算研討會,達成“我們已經進入了認知計算的新時代”的共識。經過長期調研發現應屆生就業面臨如下問題:就業信息挖掘不足、應屆生對自身實力定位不當而造成就業困難等。因此應當構建基于認知計算的就業咨詢智慧服務系統,有效為院校學生就業崗位的選擇提供咨詢與幫助。該系統能夠實現招聘信息的采集和分類、學生實力的準確定位、信息的定向推送等功能。其主要由數據采集單元、數據計算平臺、用戶服務平臺和數據存儲單元四個部分組成。下面將從系統設計、技術選擇、系統實現以及結果展示這四個角度重點闡述其工作原理[1]。
1 系統設計
該項目的技術方案設計包括四部分:
(1)設計并搭建數據采集單元。
通過問卷調查、聯合社團與院校合作等方式選取近年來南京郵電大學高質量的研究生簡歷以及最終就業單位、崗位信息。通過Scrapy爬蟲框架,爬取各大就業信息網(南京郵電大學招生就業創業網、南大小百合BBS等)的就業信息,并進行數據預處理。
(2)設計并搭建數據計算平臺。
使用多類別支持向量機、樸素貝葉斯算法,構造“就業崗位智慧分類模型”,對提取的就業信息進行數據分類;采用隨機森林算法對用戶簡歷信息進行數據分析,構造“就業智慧決策樹模型”,洞察簡歷信息與就業崗位的內在聯系,完成用戶崗位信息的預測判決。
(3)設計并搭建用戶服務平臺。
使用SSH框架完成人機交互服務與業務邏輯設計、數據展示等。
(4)搭建數據存儲單元。
采用MongoDB數據庫完成數據存儲,并配置用戶登陸、副本集等功能,保障數據安全和冗余備份。
具體業務流程如圖1所示。

圖1 系統框架及業務流程
2 Scrapy框架結構
Scrapy是一個快速,高層次的屏幕抓取和Web抓取框架,用于抓取Web站點并從頁面中提取結構化的數據。Scrapy可用于數據挖掘、監測和自動化測試,并且是開源框架最新版本,提供了Web2.0爬蟲的支持。
Scrapy框架的主要構件是引擎,調度器,下載器,蜘蛛,管道項目,下載器中間件,蜘蛛中間件以及調度中間件[2]。
3 數據計算平臺算法設計
3.1樸素貝葉斯算法的應用
樸素貝葉斯是貝葉斯分類器的一個擴展,是用于文檔分類的常用算法。它在數據較少的情況下仍然有效,并且可以處理多類別問題[3]。
根據貝葉斯定理,對于一個分類問題給定樣本特征X,樣本屬于類別Y的概率為:
P(y|x)=P(x|y)P(y)/P(x)
(1)
其中,x為一個特征向量。假設x的維度為M。因為樸素的假設,即特征條件獨立,根據全概率公式展開,式(1)可以表達為:
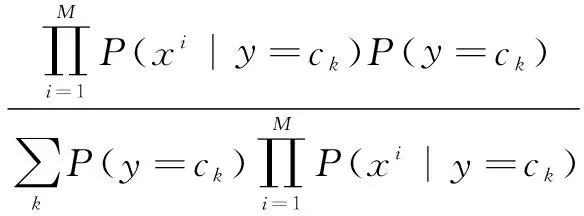
(2)
這里只要分別估計出特征xi在每一類的條件概率即可。類別y的先驗概率可以通過訓練集計算出,同樣通過訓練集上的統計,可以得出對應每一類上條件獨立的特征對應的條件概率向量[4]。
從獲得的數據中,通過學習得到樸素貝葉斯分類模型。具體做法如下:


(3)
其中,I(x)為指示函數,若括號內成立,則計1,否則計0。
接下來計算分子中的條件概率。設M維特征的第j維有L個取值,則某維特征的某個取值ajl,在給定某分類Ck下的條件概率為:
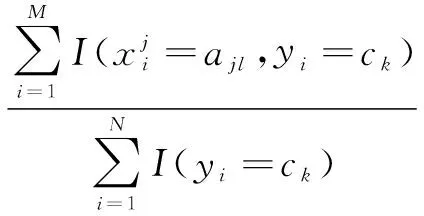
(4)
經過上述步驟,就得到了模型的基本概率,也就完成模型構建的任務。
之后當給定未分類新實例x時,就可通過上述概率進行計算,得到該實例屬于各類的后驗概率P(y=ck|x)。因為對所有的類別來說,式(2)中分母的值都相同,所以只計算分子部分即可,具體步驟如下:
計算該實例屬于y=ck類的概率:
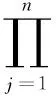
(5)
得到該實例所屬的分類y:
(6)
3.2支持向量機算法的應用
支持向量機(Support Vector Machine,SVM)是一種通過尋求結構化風險最小來提高學習機泛化能力的分類算法,實現經驗風險和置信范圍的最小化,從而達到在統計樣本量較少的情況下,亦能獲得良好統計規律的目的[5]。

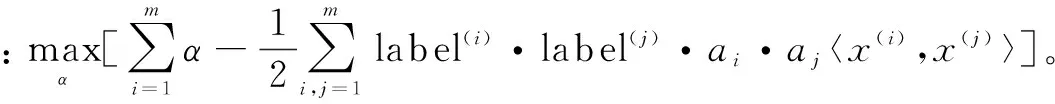

求解SVM就是求解該表達式的最優解問題。
3.3隨機森林算法的應用
隨機森林算法在機器學習、計算機視覺等領域內應用極為廣泛,可以用來做分類和回歸。隨機森林由多個決策樹構成,相比于單個決策樹算法,分類、預測的效果更好,不容易出現過度擬合的情況[7]。
隨機森林是由多個決策樹構成的森林,算法分類結果由這些決策樹投票得到。當基于某些屬性對一個新的對象進行分類判別時,隨機森林中的每一棵樹都會給出自己的分類選擇,并由此進行“投票”,森林整體的輸出結果將會是票數最多的分類選項;而在回歸問題中,隨機森林的輸出將會是所有決策樹輸出的平均值。決策樹在生成過程中分別在行方向和列方向上添加隨機過程。行方向上構建決策樹時采用放回抽樣得到訓練數據,列方向上采用無放回隨機抽樣得到特征子集,并據此得到其最優切分點。
3.4特征向量提取
特征向量提取的最終目標是使得選出的特征向量在多個類別之間具有一定的類別區分度。由于分詞后得到大量的詞語,通過選擇降維技術能很好地減少計算量,并維持分類的精度。這里介紹卡方統計量和TD-IDF兩種特征向量提取算法。
計算卡方統計的公式如下:
χ2(t,c)=
(7)
其中,N為訓練數據集文檔總數;A為在一個類別中包含某個詞的文檔數量;B為在一個類別中排除該類別后,其他類別包含某個詞的文檔數量;C為在一個類別中不包含某個詞的文檔數量;D為在一個類別中不包含某個詞,也不在該類別中的文檔數量
TF-IDF(Term Frequency-Inverse Document Frequency)是一種用于資訊檢索與資訊探勘的常用加權技術。主要思想是:如果某個詞或短語在一篇文章中出現的頻率(TF)高并且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。計算TD-IDF的公式如下:
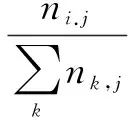
(8)
4 系統結構設計
Struts2和SpringMVC是目前比較流行的MVC Web后臺框架,都規范封裝了Servlet的開發,大大提升了Web后臺的開發效率[8]。Hibernate是一個開放源代碼的對象關系映射框架,對JDBC進行了輕量級的封裝,使得Java程序員可以隨心所欲地使用對象編程的思維來操縱數據庫,并且它提供了對常用數據庫的基本操作[9]。Spring是一個輕量級Java開發框架,是輕量級的IoC和AOP的容器框架。主要功能是提供了對象之間的解耦,簡化開發,以及AOP編程,聲明式事務的支持等功能[10]。
MongDB是一種非關系型數據庫,與關系型數據庫相比,具有弱一致性、基于內存存儲方式、支持大容量存儲、更快速獲取數據、內置Sharding提供數據分段存儲等特點[11]。
5 系統關鍵模塊設計與結果展示
5.1數據采集單元
采用Scrapy完成招聘數據的大量采集,采集的目標網站為南京郵電大學就業創業網等四家高校的招生就業信息專欄。圖2展示了Scrapy爬蟲獲取的信息經過處理后得到的文本文件截圖,可見數據采集單元具備就業數據采集能力。

圖2 經過Scrapy采集得到的文本文件截圖
5.2數據計算平臺
數據平臺的設計使用樸素貝葉斯算法、多類別SVM算法、隨機森林算法。使用樸素貝葉斯算法完成崗位信息的技術與非技術分類;使用多類別SVM算法完成與技術相關的開發、測試、技術支持和其他的分類;使用隨機森林算法完成職位預測功能。具體介紹多類別SVM的實現。工作大致分為以下幾個步驟:
(1)選擇文本訓練數據集和測試數據集:訓練集和測試集都是類標簽已知的,都是由Scrapy從網上爬取的各大招生就業信息,經過樸素貝葉斯分類后形成的所有技術相關的就業信息。
(2)訓練集文本預處理:包括分詞、去停用詞、建立詞袋模型(倒排表)。系統使用了MMAnalyzer完成分詞的操作,使用停用詞字典完成停用詞去除,并將字典保存于vocab變量中。
(3)選擇文本分類使用的特征向量(詞向量):使用卡方統計量和TD-IDF提取特征向量。卡方統計具體代碼如下:
common.FeatureMap.java完成整個過程的調度;
其中public Map
int N=item.get(label).size()+Left_Label(label).size();
;
intA=docCountContainingWordInLabel;
intB=docCountContainingWordNotInLabel;
intC=docCountNotContainingWordInLabel;
IntD=docCountNotContainingWordNotInLabel;
Int temp=(A*D-B*C);
double chi=(double)N*temp*temp/((A+C)*(A+B)*(B+D)*(C+D));
word_frequency.put(word,chi);
PublicMap
函數將Map的值按照CHI進行排序;
public Map
利用TD-IDF進行進一步提取,代碼如下:
DifferentSchoolAnalyzer中會調用component.DocumentTFIDFComputation.java文件的compute完成TF-IDF的計算
private double multiple(int word_in_one_document,int word_showtimes_in_one_document
intword_showtimes_in_one_document,intword_showtimes_in_alldocuments,int all_documents_num){
double tf=(double)word_showtimes_in_one_docu
ment/(double)word_in_one_document;
double idf=Math.log10((double)all_documents_n
um/word_showtimes_in_alldocuments);
return tf*idf;}
最終產生的特征向量編號如圖3所示。

圖3 選取出的特征向量
各個特征向量對應的TF-IDF如圖4所示。

圖4 各特征向量對應的TF-IDF值
(4)輸出LIBSVM支持的量化的訓練樣本集文件,并基于類別和特征向量來量化文本訓練集,使其能夠滿足使用LIBSVM訓練所需要的數據格式。
調用LIBSVM的接口函數如下所示:
public class ClassPrediction {
//對原始樣本進行歸一化
public void svmscale(int lower, int upper,String save_filename, String restore_filename)
//訓練數據集生成模型文件
public voidsvmtrain(String[]
options,String training_set_file, String model_file);
//根據模型,對測試數據進行預測
public voidsvmpredict (String[] options ,String test_file, String model_file,String output_file);
(5)測試數據集預處理:同樣包括分詞(需要和訓練過程中使用的分詞器一致)、去停用詞、建立詞袋模型(倒排表),但是這時需要加載訓練過程中生成的特征向量,用特征向量排除多余的不在特征向量中的詞。
(6)輸出LIBSVM支持的量化的測試樣本集文件:格式和訓練數據集的預處理階段的輸出相同。
(7)使用LIBSVM訓練文本分類器:使用訓練集預處理階段輸出的量化的數據集文件,最終輸出分類模型文件。
(8)使用LIBSVM驗證分類模型的精度:使用測試集預處理階段輸出的量化的數據集文件和分類模型文件來驗證分類精度。
在主要參數設置上,采用C_SVC類型、RBF核函數、多項式核中degree值為3,懲罰系數為1,損失函數中e為0.1,交叉驗證次數為10。
5.3用戶服務平臺
用戶服務平臺采用SSH框架[12],調用數據采集單元和數據計算平臺接口,完成自動化數據采集和分類過程[13-14]。分類結果如圖5所示。
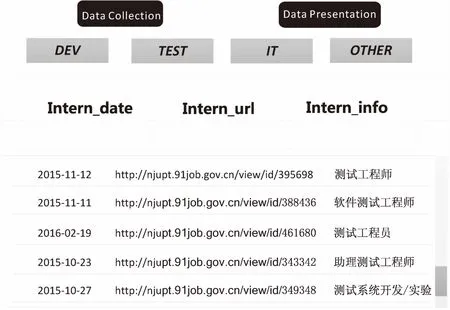
圖5 數據分類結果展示
當點擊“Data Collection”和“Date Presentation”按鍵之后,招聘信息會經過采集、存儲、分類等操作,在前端頁面進行展示。圖中所示為點擊“TEST”按鍵后的結果展示,都是與測試工程師相關的工作崗位[14],可見其能夠完成數據的特征采集和招聘信息分類的功能。
5.4數據存儲單元
數據存儲單元搭建MongoDB副本集并實現了讀寫分離功能。對副本集的集群設計如圖6所示。
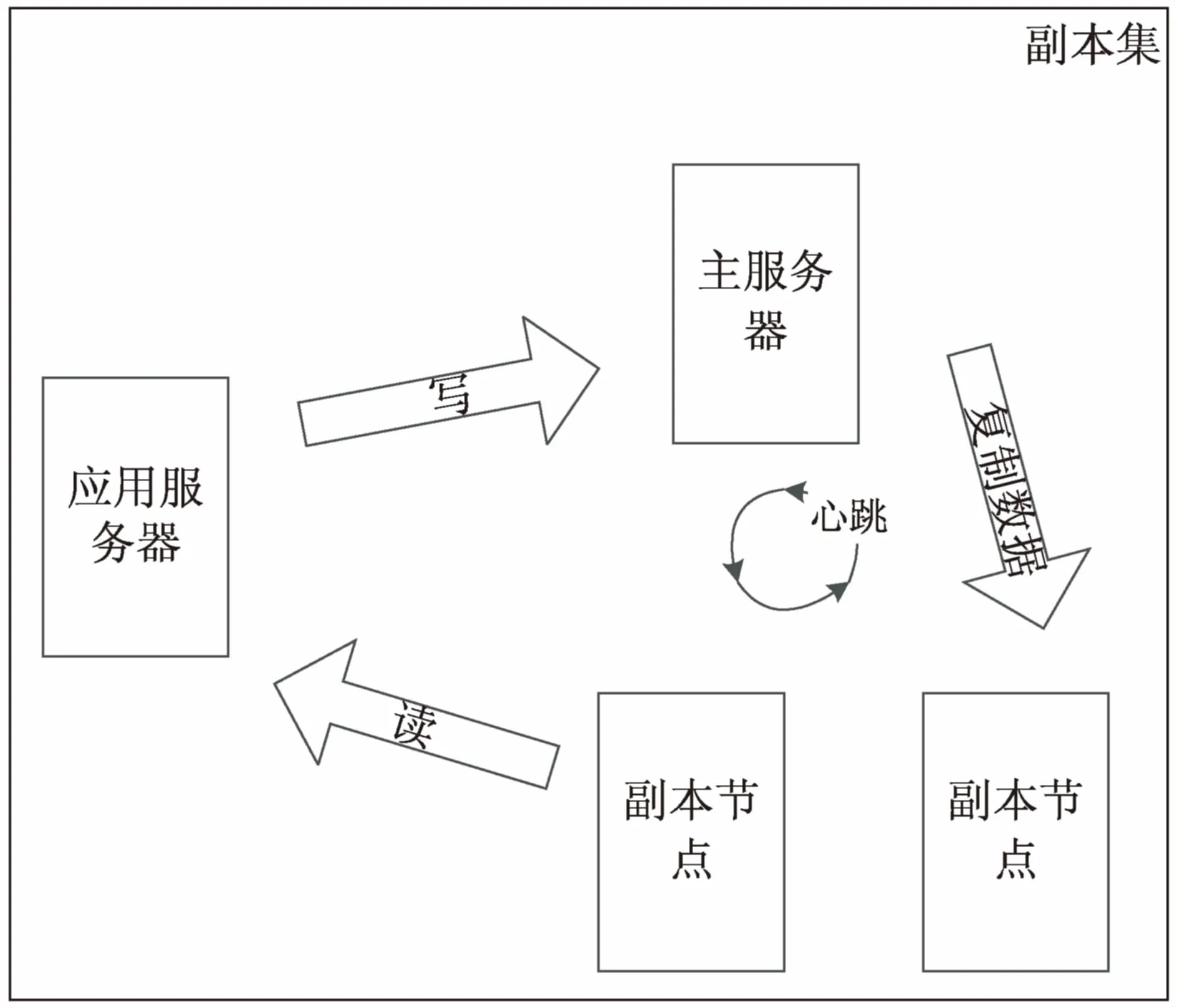
圖6 MongoDB副本集設計
實驗環境中主服務器選用一臺性能卓越的機架式服務器,id=1。從服務器為兩臺PC,id值分別為2和3。
因為在主服務器上進行寫操作,為防止數據因為誤刪等人工原因造成數據丟失,配置id為3的從服務器(slaveDelay:0)實時同步于主服務器,id為2的從服務器(slaveDelay:3 600)每隔3 600 s同步于主服務器。
為了保證數據的安全性,設計id為3的從服務器(hidden:true),從而不能被外界程序訪問,并且設置(prority:0)表示當主服務器宕機后,該從服務器將不參與新的主服務器的選舉。
當服務器發生宕機等突發事件時,數據訪問端會依次按照優先級順序切換到備份服務器上,從而使得數據訪問具備高容錯性和實時性。
6 結束語
在如今的大數據時代,就業咨詢智慧服務系統旨在通過分析海量數據為應屆生求職方向提供正確的決策建議。Scrapy框架完成數據采集,認知計算相關算法完成數據分類,MongoDB集群用于海量數據存儲。系統具備海量數據計算能力,能夠有效進行特征采集和招聘信息分類的工作,能對學生能力進行準確定位,可有效為院校學生求職崗位的選擇提供智能化的輔助咨詢服務。
[1] 馬 旭.探究Tomcat虛擬路徑功能應用[J].中國新通信,2016(2):67.
[2] Kouzis-Loukas D.Learning scrapy[M].Birmingham,UK:Packt Publishing Ltd,2016.
[3] 阿培丁.機器學習導論[M].北京:機械工業出版社,2009.
[4] Liu Chaoping,Li Feng.The design and implementation of exquisite course website[C]//International symposium on information technology in medicine & education.[s.l.]:[s.n.],2012:341-344.
[5] 鄧珍榮,唐興興,黃文明,等.一種Web服務器集群負載均衡調度算法[J].計算機應用與軟件,2013,30(10):53-56.
[6] Harrington P.Machine learning in action[M].Greenwich,CT:Manning,2012.
[7] Zrelli S,Ishida A,Okabe N,et al.ENM:a service oriented architecture for ontology-driven network management in heterogeneous network infrastructures[C]//Network operations and management symposium.[s.l.]:IEEE,2012:1096-1103.
[8] 劉石忠.云計算在智能化城市體系中的應用[J].無線互聯科技,2012(11):32.
[9] Sebastiani F.Machine learning in automated text categorization[J].Journal of ACM Computing Surveys,2002,34(1):1-47.
[10] 霍福華,尹宇孚.基于J2EE架構的五層Web開發模型研究[J].通訊世界,2017(1):225-226.
[11] 霍多羅夫,迪洛爾夫.MongoDB權威指南[M].程顯峰,譯.北京:人民郵電出版社,2013.
[12] Kim H,Howland P,Park H,et al.Dimension reduction in text classification with support vector machines[J].Journal of Machine Learning Research,2005,6(1):37-53.
[13] 聞劍峰,石屹嶸.以分布式計算實現電信數據分析業務加速的研究[J].電信科學,2012,28(2):22-26.
[14] Zhao Wei,Li Ming,Liu Jinhua,et al.Design and implementation of national meteorological computing resource management system based on grid[C]//International conference on information science and engineering.[s.l.]:[s.n.],2012:182-185.
EmploymentConsultationIntelligentServiceSystemBasedonCognitiveComputation
TANG Xin-chen
(School of Telecommunications and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210000,China)
Currently,with the development of the intelligence service system and the arrival of the big data era,how to use the computer to help graduates make right decisions of job hunting like human is particularly important.Employment consultation intelligent service system with cognitive computation consists of four parts.Data collection unit uses the Scrapy framework for massive employee information from the various employee network in real-time.Data computing platform carries out the text recognition,feature extraction and text classification by several algorithms based on cognitive computing like random forest,SVM and Naive Bayes,which can correctly realize the feature sampling and data classification.Data storage unit builds the MongoDB cluster to complete the data storage with large memory capacity and high fault tolerance.User service platform integrates the Web framework and has multiple user services.Therefore,it can collect and classify effectively the employee information and evaluate students’ ability accurately,which can provide students for effective help on choosing the right and good job.
cognitive computing;Scrapy;machine learning;Web application;service system
2016-05-19
2016-08-17 < class="emphasis_bold">網絡出版時間
時間:2017-08-01
全國3S杯大學生物聯網技術與應用“三創大賽”組委會項目支持(16B049)
唐新晨(1992-),男,碩士研究生,研究方向為網絡技術應用。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170801.1548.002.html
TP302
A
1673-629X(2017)11-0166-05
10.3969/j.issn.1673-629X.2017.11.036
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
