基于字典學習的模糊車牌中文字符識別
2017-11-20 11:07:13干宗良麥媛玲
計算機技術與發展 2017年11期
關鍵詞:模型
呂 顥,劉 峰,干宗良,麥媛玲
(1.南京郵電大學 圖像處理與圖像通信江蘇省重點實驗室,江蘇 南京 210003;2.視頻圖像智能分析與應用公安部重點實驗室,廣東 廣州 510000)
基于字典學習的模糊車牌中文字符識別
呂 顥1,劉 峰1,干宗良1,麥媛玲2
(1.南京郵電大學 圖像處理與圖像通信江蘇省重點實驗室,江蘇 南京 210003;2.視頻圖像智能分析與應用公安部重點實驗室,廣東 廣州 510000)
車牌識別技術已經是一項非常成熟的技術。而車牌當中的中文字符由于筆畫比較復雜且位置較偏導致拍攝條件受限,得到的車牌中文字符圖像質量不佳,往往較難辨認,從而給車牌識別工作尤其是車牌中文字符識別帶來了極大困難。文中采用基于費希爾判別準則的字典學習方法來提取中文字符的特征,為了從不同的角度對中文字符提取特征,用不同的訓練樣本訓練三個字典學習模型,將車牌中文字符樣本分別通過訓練好的三個字典學習模型,從而形成三種殘差信息,用Softmax對三種殘差信息進行整合,最終得到識別結果。通過實際測試表明,由于文中采用了更加具有區分能力的基于費希爾判別準則的字典模型,且采用三種不同的字典學習模型同時對同一個中文字符進行特征提取,與傳統的中文識別方法相比,該方法對模糊車牌中文字符具有較好的識別效果。
中文字符識別;字典學習;主成分分析;Softmax回歸
0 引 言
隨著智慧城市的快速建設和機動車輛數量的增加,車牌識別技術變得愈來愈重要。由于受獲取圖像實際環境和條件的限制,車牌圖像可能會十分模糊。此外,中文字符結構具有多樣性和復雜性等特性,使得識別這種模糊場景中的車牌中文字符變得十分困難。
中文車牌識別技術在國內外研究廣泛,有許多方法可以處理此類問題。如最簡單的模板匹配[1-2],它不需要提取特征,輸入圖像直接與一系列的模板字符進行匹配,最終選擇出與原圖像最接近的模板并將其作為最終的字符識別結果。ANN(人工神經網絡)也常被用來識別中文字符[2-4]。當然目前CNN(卷積神經網絡)在中文字符的識別[6-7]上運用得更加廣泛,它是通過許多樣本來訓練一個能夠識別中文字符的卷積神經網絡,通過卷積層和采樣層來提取圖像特征。SVM(支持向量機)也常用在識別系統中[8-11]。近年來,字典學習也逐漸被使用[12-14]。還有用經典的字典學習方式SRC(稀疏表示識別方法)完成車牌識別任務。但是由于原始車牌中的噪聲干擾,導致字典不能有效地表示目標車牌。總的來說,上述方法都能識別出清晰的中文字符,但對于模糊車牌的識別仍然非常困難。
因此,文中提出一種基于費希爾判別準則的字典學習方法來表示車牌中的中文字符。通過費希爾判別準則得到的字典能夠比一般的字典學習方法生成的字典更好地表示模糊中文字符。采用三個字典學習模型同時對一個模糊車牌樣本進行處理,進而分別得到三個不同的殘差,將其通過Softmax回歸進行整合得到最終識別結果。
1 車牌中文識別算法
算法流程如圖1所示。
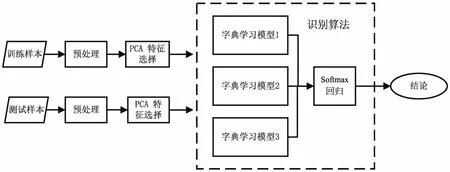
圖1 算法流程
先從現實的車牌圖像中截取車牌中文字符。經過一系列的預處理操作,用PCA(Principal Components Analysis)對車牌中文字符的特征進行提取,不僅可以降低數據的維度,加快算法的速度,同時也可以濾除噪聲。根據不同的訓練樣本分別生成三個字典學習模型。用基于費希爾判別準則的字典學習模型來建立字典更加利于模糊車牌中文字符的重建。最后,將經過字典學習所得到的殘差作為輸入,采用Softmax回歸的方式進行整合并得到最終的識別結果。識別模型數量的增加使得識別結果更加穩定。如果一旦一個識別器識別錯了,最終結果會被其他兩個識別器糾正過來。實驗結果表明,該方法更加有利于中文車牌字符的識別。
1.1預處理
一般從監控視頻中獲取的是包含車輛以及更多背景圖片的圖像,識別系統無法直接處理。因此,這些圖像必須經過一系列預處理,包括車牌截取、仿射變換、字符分割、灰度化、去均值和歸一化等步驟。經過預處理,中文字符圖像變得更加利于后續操作。
1.2特征提取
PCA是一種數據處理技術,可以方便有效地找出對象的主成分和圖像結構,消除冗余信息量的同時降低數據維度。該方法非常簡單且沒有參數限制,已經廣泛應用于字符識別中[15-16]。經過PCA操作,可以提取出模糊車牌中文字符的特征,加快整個算法的速度,在一定程度上降低圖像噪聲。
1.3識別算法
目前字典學習在許多圖像處理和計算機視覺領域當中應用廣泛[14-15]。與一般字典學習方法不同的是,文中算法生成的字典不僅具有區分性,而且對應的稀疏系數同樣具有稀疏性。
該方法先構造一組與類別標簽相關的結構字典D=[D1,D2,…,DC],其中Di為與第i個省份中文車牌信息相關的字典部分;C值為31,因為總共需要識別31個省份的車牌。訓練車牌樣本表示為X=[X1,X2,…,XC],X通過結構字典線性表示:X≈DA。其中A表示編碼稀疏矩陣,A=[A1,A2,…,AC],Ai代表屬于第i省份的所有訓練樣本Xi通過字典D表示所對應的編碼系數。除了需要字典D對訓練樣本X具有強大的重建區分能力,也希望A具有區別樣本的能力。因此引入費希爾判別準則,使得稀疏編碼系數A的類間散度變大同時類內散度變小。最終,損失函數如下:

λ2f(A)}
(1)
其中,r(A,D,X)為區別項;‖A‖1為稀疏項;f(A)為區別常數項;λ1和λ2為系數參數。
接下來詳細討論費希爾判決標準中的r(A,D,X)和f(x)。
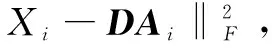
區別系數項f(A)是為了使編碼系數A同樣具有區分能力。基于費希爾判決準則,最小化類內間隔SW(A)同時最大化類間間隔SB(A)。其中SW(A)和SB(A)分別定義為:
(2)
(3)
其中,mi和m分別是Ai和A的平均向量。
因此f(A)被定義為:
(4)
殘差生成:對于測試樣本y,首先通過字典D編碼,從而能獲得它的稀疏系數編碼:
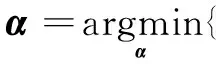
(5)
其中,α為子字典Di的系數。
定義殘差為:

(6)
其中,第一項代表第i個省的重建錯誤;第二項為系數向量α與所學習到的第i個省車牌的像素值均值的距離;ω為平衡這兩項的權重
識別整合:Softmax回歸是一個用于多分類識別的可監督學習模型。將得到的殘差還有所對應的省份標簽作為訓練樣本,將訓練樣本放入Softmax回歸模型進行訓練。因此,一旦能夠獲得這三類不同字典學習模型所獲得的殘差信息,就可以通過Softmax回歸模型去確定這輛車來自于哪個省份。
2 實驗結果與分析
在相同的軟件和硬件環境中測試并對比提出的識別算法與其他中文識別算法。如表1所示,SVM[8]占用了最少的時間,而ANN[2]和CNN[6]則花費了較多的時間,神經網絡需要花費大量時間在反向梯度傳導時計算偏導數,而一般神經網絡都有2到3層甚至更多。文中算法并沒有多層處理。因此,相對于多層網絡算法,時間損耗將少得多。即使重建模糊車牌需要花費一定的時間,但是由于基于費希爾判決的字典學習所產生的字典數量比其他字典學習要少,因此相對于其他字典學習方法花費了更少的時間。
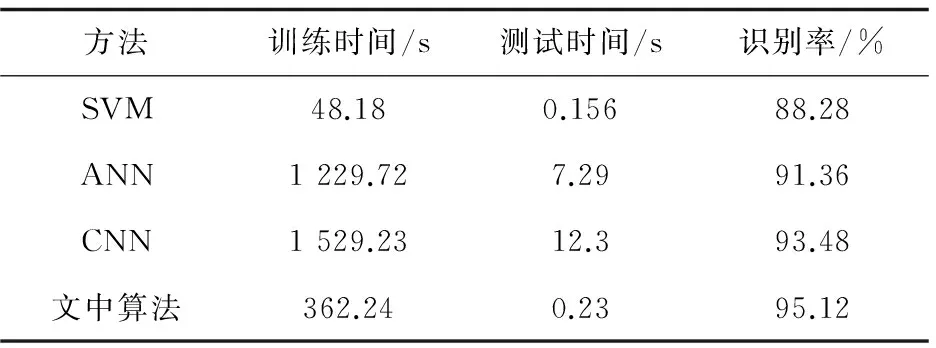
表1 不同算法的實驗對比
從表1同樣可以看出,文中算法比其他算法有更高的識別率。原因在于所用的字典具有較強的區分能力,能夠較好地重建出要識別的模糊車牌。此外,同時使用三個不同的字典學習模型去識別同一個模糊車牌中文字符,一旦一個識別器給出了錯誤信息,其他兩個識別器有很大的可能去糾正這個錯誤。鑒于以上兩條優勢,文中算法獲得了比較可觀的識別率。

表2 不同省份車牌的實驗結果統計
如表2所示,文中方法不光對于模糊中文車牌有更高的識別率,還有著很高的識別穩定性,對結構相近的省份字符同樣能夠區分出來,比如“甘”和“吉”、“云”和“甘”等等。在所有31個省份車牌中,有4個省的車牌達到100%的識別率,20個省的車牌達到大于97%的識別率。這與算法獨特的結構設計以及字典學習方式是分不開的。由于通過字典所形成的殘差和稀疏編碼系數同時都具有區分性,故文中算法的字典能很好地重建出模糊車牌中文字符,使得中文車牌字符不易于與其他中文結構相近的省份車牌字符所混淆。
3 結束語
文中提出了一種模糊車牌識別的新方法。該方法采用基于費希爾判決準則的字典學習模型和Softmax回歸來分別表示和識別模糊車牌中文字符。相比一般的字典學習算法,基于費希爾判決準則的字典學習對于模糊車牌中文字符有著更強的重建能力。此外,整合三個字典模型進行識別的方法比只憑一個識別器識別的方法具有更高的識別率和更好的穩定性。因此,可以廣泛應用于車牌系統識別中。
[1] Lan C,Li F,Jin Y,et al.Research on the license plate recognition based on image processing[C]//Fifth international conference on instrumentation and measurement,computer,communication and control.Qinhuangdao:IEEE,2015:731-734.
[2] 鄒明明,盧 迪.基于改進模板匹配的車牌字符識別算法實現[J].國外電子測量技術,2010,29(1):59-61.
[3] 咼潤華,蘇婷婷,馬曉偉.BP神經網絡聯合模板匹配的車牌識別系統[J].清華大學學報:自然科學版,2013(9):1221-1226.
[4] 吳 聰,殷 浩,黃中勇,等.基于人工神經網絡的車牌識別[J].計算機技術與發展,2016,26(12):160-163.
[5] Vishwanath N,Somasundaram S,Nishad A,et al.Indian license plate character recognition using Kohonen neural network[C]//International conference on computational intelligence & computing research.[s.l.]:IEEE,2012:1-4.
[6] Liu P,Li G,Tu D.Low-quality license plate character recognition based on CNN[C]//2015 8th international symposium on computational intelligence and design.Hangzhou:IEEE,2015:53-58.
[7] Zhong Z,Jin L,Feng Z.Multi-font printed Chinese character recognition using multi-pooling convolutional neural network[C]//13th international conference on document analysis and recognition.Tunis:IEEE,2015:96-100.
[8] Bautista R M J S,Navata V J L,Ng A H,et al.Recognition of handwritten alphanumeric characters using projection histogram and support vector machine[C]//International conference on humanoid,nanotechnology,information technology,communication and control,environment and management.[s.l.]:[s.n.],2015:1-6.
[9] Angeline L,Wei Y K,Wei L K,et al.Research of license plate character features extraction and recognition[C]//2nd international conference on computer science and network technology.[s.l.]:[s.n.],2012:2154-2157.
[10] Ghahnavieh A E,Amirkhani-Shahraki A,Raie A A.Enhancing the license plates character recognition methods by means of SVM[C]//22nd Iranian conference on electrical engineering.[s.l.]:[s.n.],2014:220-225.
[11] 周 鵬.基于支持向量機的車牌字符識別方法[J].數字技術與應用,2016(9):91.
[12] 陳思寶,趙 令,羅 斌.基于核Fisher判別字典學習的稀疏表示分類[J].光電子·激光,2014,25(10):2000-2008.
[13] 練秋生,石保順,陳書貞.字典學習模型、算法及其應用研究進展[J].自動化學報,2015,41(2):240-260.
[14] 朱 杰,楊萬扣,唐振民.基于字典學習的核稀疏表示人臉識別方法[J].模式識別與人工智能,2012,25(5):859-864.
[15] 劉冰冰.基于PCA車牌漢字識別算法的研究與實現[D].長春:長春理工大學,2011.
[16] 閆雪梅,王曉華,夏興高.基于PCA和BP神經網絡算法的車牌字符識別[J].激光與紅外,2007,37(5):481-484.
ChineseCharacterRecognitioninFuzzyVehiclePlateBasedonDictionaryLearning
LYU Hao1,LIU Feng1,GAN Zong-liang1,MAI Yuan-ling2
(1.Key Laboratory on Image Processing & Image Communications of Jiangsu Province,Nanjing University of Posts and Telecommunications,Nanjing 210003,China;2.Key Laboratory on Video Image Intelligent Analysis and Application of Ministry of Public Security,Guangzhou 510000,China)
Vehicle license plate recognition has already been a mature technology.However,due to the complicated strokes in Chinese character and bad shoot environment by the remote location,the image quality of Chinese character is too bad to recognize,which is difficult for the vehicle license plate recognition,especially for Chinese character recognition.The dictionary learning method based on Fisher discriminative criterion is proposed to extract the Chinese character features.In order to extracting features of Chinese character from different aspects,three dictionary learning models are trained by different training samples and through them,three different residual information are obtained which are integrated by Softmax for final recognition results.The practical tests show that compared with the traditional Chinese recognition methods,it can own better recognition effect in Chinese character of fuzzy vehicle plate since the use of dictionary model based on Fisher discriminative criterion with more strong distinguishing and adopting three dictionary learning models to extract features for same Chinese character at the same time.
Chinese character recognition;dictionary learning;principal component analysis;Softmax regression
2016-11-23
2017-03-09 < class="emphasis_bold">網絡出版時間
時間:2017-07-19
國家自然科學基金項目資助項目(61471201);江蘇省高校重大基礎研究項目(13KJA510004);江蘇省六大人才高峰資助計劃(RLD201402);南京郵電大學“1311”人才資助計劃;廣州市軟件和信息服務產業專項資金所屬重點專項(2060404)
呂 顥(1992-),男,碩士生,研究方向為圖像處理與多媒體通信;劉 峰,博士,教授,博士生導師,通訊作者,研究方向為圖像處理與多媒體通信、高速DSP與嵌入式系統。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170719.1113.084.html
TP301
A
1673-629X(2017)11-0075-04
10.3969/j.issn.1673-629X.2017.11.016
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
