基于語義樹與VSM的主題爬取策略研究
2017-11-20 11:11:53倪曉軍
計算機技術與發展 2017年11期
張 金,倪曉軍
(南京郵電大學 計算機學院,江蘇 南京 210003)
基于語義樹與VSM的主題爬取策略研究
張 金,倪曉軍
(南京郵電大學 計算機學院,江蘇 南京 210003)
主題爬蟲主要用于解決用戶的定制化搜索需求,即在日益增長的網絡數據中快速、有效、準確地選取用戶關注的主題內容進行爬取。提高爬取特定信息的準確性,需要對網頁的內容相關度進行主題相關判斷,而主題爬蟲關注的核心問題就是相關度計算,但現有的改進算法大多采用人工智能和機器學習等技術,不僅引起算法復雜度的提高,而且提升效果有限。為此,提出了一種基于語義樹與VSM的主題爬取策略,將語義相似度的計算加入到內容相關度計算與鏈接排序中,并通過對策略中算法細節的改進優化相關度的主題判別。實驗結果表明,使用基于語義樹與VSM爬取策略的主題爬蟲可將爬行路線一直保持在相關度較高的網頁鏈接中,對網頁鏈接進行了相關與不相關的有效分類,顯著地提高了爬取的準確率。
主題爬蟲;語義樹;向量空間模型;內容相關度;鏈接排序
1 概 述
主題爬取是指遵循一定的規則對相應主題進行爬取操作,有別于傳統的爬取策略(爬取所有的頁面以供用戶后期的檢索,信息范圍廣泛),而主題爬取盡可能多地爬取只與主題相關的網頁,避免其他無關頁面,信息領域特定,結果專業,提高了爬蟲爬取的效率。在互聯網的飛速發展下,網絡上的信息資源呈指數級增長,爬取的信息量也隨之增長,如何在海量數據中為用戶提供個性化需求的信息成為當下爬取研究的重點。
主題爬取基于主題爬蟲,主題爬蟲[1]在1999年被Chakrabarti等提出,主要用于解決爬取特定主題、個性化需求的網頁時查準率不高的問題。主題爬蟲在爬取過程中對網頁判斷主題是否相關,相關則抓取,通過這樣的判斷減少了無關頁面的抓取,從而降低了帶寬、時間以及存儲空間的需求,既提高了抓取的準確率,又提高了系統的抓取效率。與通用爬蟲相比,主題爬蟲的網頁相關度判斷需要解決鏈接的主題相關性、鏈接優先級等問題,這就需要實現基于主題搜索場景設計的爬蟲。目前傳統的主題爬蟲對于主題相關性算法主要從兩方面進行分析:內容與鏈接。在內容分析方面,主要通過計算主題與頁面的相似度來確定抓取隊列,主要代表有Fish-Search[2]算法和Shark-Search[3]算法。而鏈接分析主要通過鏈接間的相互引用決定鏈接的重要性排序,代表算法有PageRank[4]與HITS[5]。這兩類算法都得到了研究人員的大量關注,并對此進行了許多改進,但這些算法大都只是對算法的適用度進行增強,因此如何在對用戶主題的特定需求下,既準確又高效地進行網頁抓取成為研究重點。
在一般主題爬蟲的基礎上,提出一種改進的語義樹[6]與VSM[7]相結合的主題爬取策略,優化主題相關度計算與鏈接排序,提高抓取的準確率。在向量空間模型計算頁面相似度的基礎上,發揮語義樹在計算內容語義相似度的關鍵性作用,判斷頁面相關度,使用多次鏈接的相似度計算對鏈接進行候選優先級排序,實現了在個性化場景下爬取的準確與高效。
在信息采集領域,相關度理論的研究一直是焦點,尤其是主題爬蟲中的網頁相關度算法的研究與改進。傳統的相關度算法主要分為基于鏈接的重要度分析和基于內容的相似度計算分析兩大類。基于鏈接分析主要是通過PageRank等算法來建立主題相關度計算模塊,PageRank算法通過鏈接到頁面的鏈接重要性遞歸計算來計算頁面的等級,鏈接的頁面越多,計算得到的等級也越高。但在PageRank算法中,由于出度鏈接的不確定性、用戶點擊概率的非均等性等問題,抓取時會出現“主題漂移”,導致無效抓取,浪費資源。基于內容分析是依據向量空間模型,首先依據主題特征詞生成主題特征向量,再將頁面關鍵詞權重用TF*IDF表示,然后對頁面向量與主題詞特征向量進行相似度計算,通過設定相應的閾值對網頁進行相關匹配,解決無關頁面的資源占用,但是如果頁面對關鍵詞進行虛假設置,就會導致相關度計算結果的不準確,從而導致誤判現象,同時也忽略了網絡結構的作用。文獻[8]考慮了關鍵詞出現位置的差異性,根據關鍵詞出現的不同位置賦予不同權重系數,這樣能更加精確地描述頁面間相關度,抓取更為準確。但是并沒有考慮特征詞之間的語義差別,而語義上的差別肯定會干擾頁面相關度的判斷,進而影響相關頁面的確定與抓取。
主題爬蟲在之前發展的基礎上,加入了更多技術手段來優化相關度的計算,比如遺傳算法、蟻群算法、神經網絡等。文獻[9]通過關鍵詞來定義頁面信息,使用在線增量學習的方式進行鏈接爬行,對錨文本、URL串、父子頁面間的關系進行頁面綜合價值的計算并排序。這類算法使得抓取的精度更高,不容易產生主題漂移現象,但同時加大了算法復雜度,降低了抓取效率。文獻[10]通過對URL中的關鍵字出現次數與父頁面相關性進行總相關性計算來確定鏈接的相關得分。在此基礎上,文獻[11]通過樸素貝葉斯分類算法模型計算鏈接的相關度,但是無法對關鍵詞不同的頁面進行有效處理,不管頁面的主題是否相似。文獻[12]將語義計算與主題爬蟲結合起來,提高了相關度計算的準確度以及抓取的準確性,有效地過濾無關頁面,但其時間與空間復雜度相較于其他有了明顯提高。文獻[13]使用語義來對頁面的語義關系進行評估,并對相關度的頁面賦予高優先級進行抓取。在語義關系的比較中,最常用的是語義樹,文獻[14]在對基于語義樹的語義計算方法進行大量研究的基礎上,提出了計算各個特征詞向量之間的相似度來判斷詞的相似性,但是針對詞的相似判斷基礎是特征詞所在的上下文也是相同的,這顯然會出現比較明顯的錯誤。
文獻[15]通過大量實驗研究對比了不同主題算法的效果后發現,無論是基于分類增加型學習的算法,還是基于遺傳和神經網絡的算法,實際上抓取效果提升平平,并沒有對抓取進行實際明顯的優化。
為了進一步提升主題抓取的準確率和效率,對語義樹在計算相似度方面的算法進行深度的分析與挖掘,將基于語義樹的語義判斷加入算法中,同時仍采用VSM計算頁面間基本的相似度,將兩者結合以提高相似度計算的準確性。通過對父子URL鏈接的多次相關度計算與語義距離綜合計算頁面得分并對候選URL進行排序,從而達到準確率提高的效果。
2 主題爬取策略
2.1內容相關度計算
內容相關度計算就是對即將爬取的頁面主題相關程度進行計算,對相關度高的頁面進行抓取,以盡可能避免發生“主題漂移”現象,主要涉及如何對主題與網頁特征的相似比較。首先需要確定的是爬取主題,其次需要將主題信息轉化為可計算的模式,通過主題特征詞的轉化建立主題特征向量:
T={t1,t2,…,tn}
(1)
其中,n為主題特征值的個數,tn為特征值的權重。
主題特征向量可以通過兩種方式進行設定,一種是通過人工設定主題的特征值與特征權重來形成向量,這里的特征值指的就是主題特征詞;另外一種就是通過對抓取的初始頁面進行分析得到主題特征向量。
采用基于語義相似度與VSM的頁面特征相似度算法進行相關度計算,首先需要提取頁面文本信息,即對網頁特征值進行提取并映射成設定的網頁特征向量:
W={w1,w2,…,wn}
(2)
考慮到出現在不同位置的關鍵詞,對網頁所起的重要性也不同,對用于特征提取的TF計算公式進行改進:
(3)
其中,wtf表示詞頻;vi表示不同位置的特征向量;wvi表示對應位置的權重向量;tvi表示關鍵詞出現的次數向量。
通過對不同位置的關鍵詞加權,比如錨文本、標題等,從而更加精確地描述了頁面的主題,生成合理的特征向量。在得到網頁特征向量之后,計算向量余弦距離:
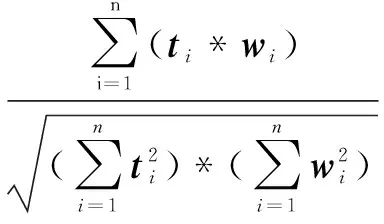
(4)
其中,T表示主題特征向量;W表示網頁的特征向量。
但是單純地將特征向量的余弦距離作為頁面內容相關度得分是不可靠的,因為這里的關鍵詞受到頁面噪聲的干擾較大,同時也存在人為設置關鍵詞的問題,容易引發誤判。因此需要進一步研究語義樹在計算相似度方面的作用,考慮語義的影響因素,以此解決VSM的局限性,提高內容相關度計算的精確性。將語義樹應用到語義相似度計算中,語義樹中的每一個節點都是語義相關的,不同的是語義樹節點間的父子關系不同,所計算的節點距離不同。這里通過各個特征詞在語義樹上的節點距離來計算語義相似度,首先計算各個特征詞的語義相似度:
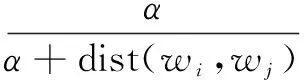
(5)
其中,α取節點相似度為一半的距離;dist(wi,wj)計算節點間的距離以對相似度進行校正。首先設定節點X,Y,P,其中節點P為節點X與Y的距離兩個最近的共同祖先節點,有:
dist(wi,wj)=
(6)
dep(X,Y)=|dep(X)-dep(Y)|
(7)
在此基礎上,對特征向量的n個特征值相似度求和,計算網頁特征向量的語義相似度:
SemanticSim(Wi,Wj)=
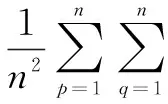
(8)
最終綜合特征向量的余弦距離與語義相似度,得出網頁特征向量的相似度,作為內容相關度的得分:
Sim(T,W)=
(9)
2.2鏈接隊列排序
確定鏈接隊列順序,對于優先爬取相關度高的頁面來說尤為重要,同時也是主題爬蟲研究的關鍵問題之一。優先級隊列的確定可以保證主題抓取始終保持在高相關度的頁面中。傳統的鏈接重要分析使用在PageRank算法基礎上進行改進的策略,PageRank算法建立在用戶的點擊操作不僅是隨機的,而且對每一個鏈接來說點擊的概率是均等的基礎上,這種情況在實際當中并不普遍存在,而且依此分析出來的頁面也并非都是主題相關的。因此,提出依據頁面子鏈接的分析為基礎的鏈接排序算法。根據大量的研究表明,子鏈接通常與頁面內容也有一定關系,因此可以考慮子鏈接的相關度對當前的鏈接相關度進行加權,但是頁面中的子鏈接并不都是有用的,有些頁面含有大量的廣告鏈接、導航鏈接等,這些無效的鏈接需要剔除掉,以減少對當前鏈接的影響,因此最終選擇的鏈接的優先級得分計算公式為:
Scoreurl=
(10)
其中,T為主題特征向量;V為當前鏈接特征向量;vi為子鏈接;m為有效鏈接數;n為總鏈接數;δ為權重因子;使用式(9)計算相似度。
對于上文提出的問題,分三種情況進行計算。當子鏈接大部分相關度高時,拋棄相關度低的鏈接后再計算鏈接的得分;當大部分子鏈接都不相關時,忽略子鏈接對當前鏈接的加權;其他情況則正常計算鏈接的得分值。
通過加權計算所得的得分進行鏈接隊列的排序與更新,保證了抓取時的爬行路線可以保持在較高相關度的鏈接中,確保抓取的都是主題相關高的頁面,從而提高了爬取的準確性,避免了無效抓取。同時由于加權使鏈接延伸,有利于爬蟲進行隧道穿越。
2.3算法流程實現
主題爬蟲的特點就是使得爬蟲永遠在主題相關的頁面上爬行,拋棄不相關的頁面。基于語義樹與VSM的內容相關度計算成了主題爬蟲的重點,采用當前鏈接與子鏈接的相關度計算對鏈接進行排序,從而優化爬行路線。提出的爬取策略主要在兩個部分進行改進,一個是內容相關度計算,一個是鏈接隊列排序,依據該算法的爬取結構如圖1所示。
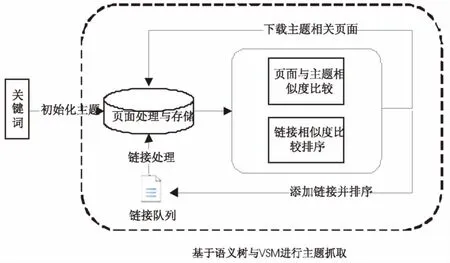
圖1 爬取結構圖
首先確定搜索主題,生成可用于相關計算的主題特征向量,根據鏈接隊列爬取頁面并抽取特征詞生成頁面的特征向量,同時加入語義判斷計算判斷頁面是否相關,并將主題相關的頁面進行存儲,同時提取頁面中的子鏈接,根據鏈接的相關度得分進行優先級排列并更新鏈接隊列,然后重復此抓取過程直到達到設定的停止條件。
算法流程如下:
(1)初始化主題特征向量,人工指定或使用訓練集訓練;
(2)從鏈接隊列按序取得網頁鏈接抓取頁面;
(3)對各個頁面進行特征向量提取,通過式(9)計算相似度并進行比較,取得相關性高的頁面并抓取存儲,更新頁面庫;
(4)對頁面中的種子鏈接通過式(10)遍歷計算與主題的相似度得分,并更新排序鏈接隊列;
(5)重復步驟(2)~(4),直到達到系統指定的結束條件,抓取的總頁面數或者抓取深度。
3 實驗與分析
通過查全率與查準率對主題爬取策略進行衡量。查全率是指網絡中所有相關網頁中被主題爬取的網頁所占的比例,要計算查全率,就需要知道整個網絡中的網頁資源,而這個在實際實驗中基本上是不能的,雖然可以通過公式模擬計算查全率,但意義不大。查準率是指在所有已爬取的相關頁面中真正主題相關的頁面所占的比例。計算公式為:
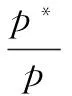
(11)
其中,p為已爬取的所有頁面數;p*為其中主題相關的頁面數。
除查準率之外,算法提升對時間效率上的影響也是評價一個主題爬取策略優越性的重要指標。
綜上所訴,在比較不同策略查準率的同時,也考慮對同一時間內不同策略抓取的相關頁面的數量進行比較,綜合比較策略的準確性與效率。在確定好評價標準的基礎上,將基于傳統VSM策略的爬蟲與提出的策略進行比較,以驗證該策略的有效性。
實驗以教授、專家、學者、報告、講座、匯報為關鍵詞集,通過搜索引擎獲取部分鏈接與人工設定鏈接作為初始鏈接,同時設定爬取深度為3,設定權重因子δ為0.8。保證在兩種策略的主題、初始鏈接、停止條件相同的情況下進行比較實驗,結果如圖2和圖3所示。
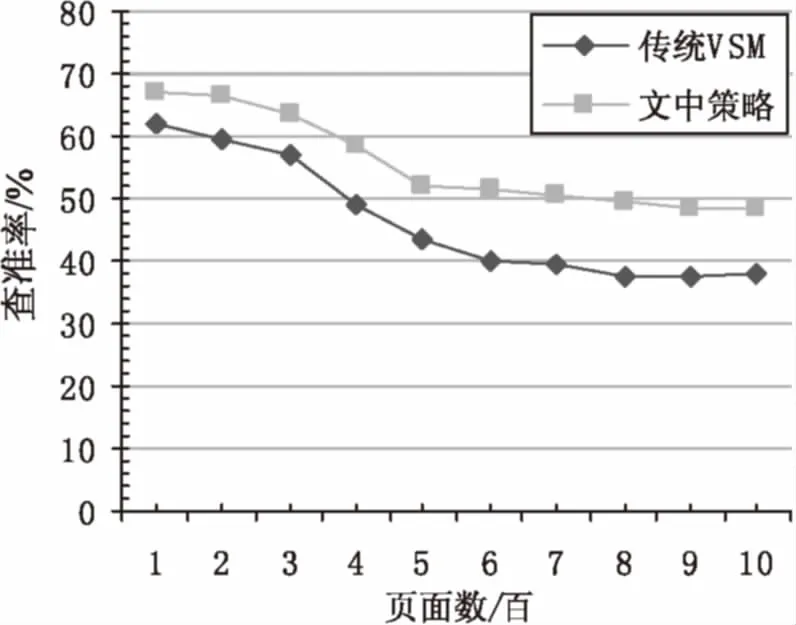
圖2 查準率對比

圖3 時間對比
從圖2中可以看出,改進策略在爬取相同頁面數時,爬取準確率普遍提升。傳統策略平均查準率為46.37%,改進策略平均查準率為55.55%,提高了9.18個百分點。同時還可以發現,隨著頁面數的增加,查準率隨之下降,而傳統策略下降得更快,這是因為提出策略加入了語義相似度的計算,保證了爬蟲可以在相關度更高的頁面中爬行。
從圖3中可以看出,改進策略在獲取相同相關頁面數的情況下,一開始所耗時間高于傳統策略,而后逐漸縮小差距,這是因為該策略改進了相關度算法、鏈接排序算法,提高了算法復雜度,繼而增加了開銷,使得在查準率高的情況下,總數會相對減少,但是隨著頁面數的增加,優勢也逐漸凸顯。
4 結束語
為了進一步提高主題爬蟲的抓取準確率,提出了一種基于語義樹與VSM的主題爬取策略,以優化爬蟲的爬行路線,盡可能多地避開無關頁面。通過將語義樹應用于內容相關度計算,解決了使用傳統向量余弦距離計算頁面相似度沒有考慮語義的問題。另一方面,分析子鏈接的相關度對當前鏈接相關度得分的影響,通過對鏈接進一步的分析,使得鏈接排序更加合理,有利于爬蟲穿越隧道。實驗結果及其分析均表明,該策略進一步提高了抓取的準確性,減少了無關的爬取存儲操作。但語義相似度的計算需要依賴于語義樹的構建,且該策略本身也沒有涉及對爬取效率的提升。由于爬取效率與準確率一樣,對主題爬取至關重要,因此提升主題爬取準確率將成為下一步工作中的研究重點。
[1] Chakrabarti S,van den Berg M,Dom B.Focused crawling:a new approach to topic-specific web resource discovery[J].Computer Networks,1999,31(11-16):1623-1640.
[2] de Bra P M E,Post R D J.Information retrieval in the world-wide web:making client-based searching feasible[J].Computer Networks and ISDN Systems,1994,27(2):183-192.
[3] Hersovici M,Jacovi M,Maarek Y S,et al.The shark-search algorithm.An application:tailored Web site mapping[J].Computer Networks and ISDN Systems,1998,30(1-7):317-326.
[4] Page L.The PageRank citation ranking:bringing order to the web[D].California:Stanford University,1998.
[5] Kleinberg J M.Authoritative sources in a hyperlinked environment[J].Journal of the ACM,1999,46(5):604-632.
[6] 張 亮,尹存燕,陳家駿.基于語義樹的中文詞語相似度計算與分析[J].中文信息學報,2010,24(6):23-30.
[7] 劉冬明,楊爾弘.話題內相關文本的內容計算[J].中文信息學報,2015,29(5):98-103.
[8] Pal A,Tomar D S,Shrivastava S C.Effective focused crawling based on content and link structure analysis[J].International Journal of Computer Science and Information Security,2009,2(1):1-5.
[9] Aggarwal C C,A1·Garawi F,Yu P S.On the design of a learning crawler for topical resource discovery[J].ACM Transactions on Information Systems,2001,19(3):286-309.
[10] Hati D,Kumar A.An approach for identifying URLs based on division score and link score in focused crawler[J].International Journal of Computer Applications,2010,2(3):48-53.
[11] Hati D,Kumar A,Mishra L.Unvisited URL relevancy calculation in focused crawling based on Native Bayesian classification[J].International Journal of Computer Applications,2010,3(9):23-30.
[12] Ehrig M,Maedche A.Ontology-focused crawling of web documents[C]//Proceedings of the 2003 ACM symposium on applied computing.[s.l.]:ACM,2003:1174-1178.
[13] Ganesh S,Jayaraj M,Kalyan V,et al.Ontology-based web crawler[C]//International conference on information technology:coding and computing.[s.l.]:IEEE,2004:337-341.
[14] 于甜甜.基于語義樹的語句相似度和相關度在問答系統中的研究[D].濟南:山東財經大學,2014.
[15] Mencaer F,Pant G,Srinivasan P.Topical web crawlers: evaluating adaptive algorithms[J].ACM Transactions on Internet Technology,2004,4(4):378-419.
ResearchonTopicCrawlingStrategyBasedonSemanticTreeandVSM
ZHANG Jin,NI Xiao-jun
(College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
Topic crawler is mainly adopted to solve the customized search needs of users,that is to select the concerning topics of users for crawling quickly,effectively and accurately in the growing network data.In order to improve the accuracy of crawling specific information,the relevance of the content of the page needs to be subject-related judgments while the main concern of the topic crawler is the correlation calculation.But the most of the existing improved algorithms adopt techniques like artificial intelligence and machine learning,which not only improve their complexity,but also own limitations in effect enhancement.Therefore,a topic crawling strategy based on semantic tree and VSM is proposed and the semantic similarity calculation is added to the content relevance calculation and link ranking to optimize the subject discrimination of relevance through the improvement of detail of the algorithm in the strategy.Experimental results show that it can always keep the crawl course in the link of the web page with high relevance,which has effectively classified the web links relevant or not and significantly improved accuracy of crawling.
topic crawler;semantic tree;VSM;content relevance;link ranking
2016-11-12
2017-02-23 < class="emphasis_bold">網絡出版時間
時間:2017-07-19
教育部專項研究項目(2013116)
張 金(1992-),男,碩士研究生,研究方向為大數據、網絡爬蟲技術;倪曉軍,教授,研究方向為嵌入式。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170719.1110.044.html
TP301
A
1673-629X(2017)11-0066-05
10.3969/j.issn.1673-629X.2017.11.014
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
開放教育研究(2020年2期)2020-03-31 01:54:14
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
時代英語·高三(2014年5期)2014-08-26 02:49:51
電腦愛好者(2011年11期)2011-06-22 08:20:18
