分析式紋理合成技術及其在深度學習的應用
2017-11-20 11:07:09李宏林
計算機技術與發(fā)展 2017年11期
李宏林
(日本山梨大學 大學院 生命情報系統(tǒng)系,山梨 甲府 400-8510)
分析式紋理合成技術及其在深度學習的應用
李宏林
(日本山梨大學 大學院 生命情報系統(tǒng)系,山梨 甲府 400-8510)
當前國際主流的非參數(shù)和參數(shù)法分析式紋理生成技術,對于計算機視覺領域的圖像紋理合成具有一定的借鑒意義。在概括總結與比較分析式紋理生成技術原理、框架結構、應用發(fā)展趨勢及其優(yōu)缺點的基礎上,分析了基于graph cut模型的非參數(shù)法、基于P&S模型的參數(shù)法兩種典型的紋理生成技術以及廣泛應用于圖像處理領域的深度學習新技術—卷積神經網(wǎng)絡(CNN)的結構與原理,進一步討論了以基于CNN的Caffe網(wǎng)絡框架及在2014年ImagNet圖像分類和目標識別大賽上取得優(yōu)異成績的VGG模型為基礎的分析式紋理生成模型VGG-19的工作原理及其在人腦視覺分析研究方面的應用。分析結果表明:相對于普通參數(shù)法和基于CNN網(wǎng)絡模型的參數(shù)法,非參數(shù)法具有更快的處理速度,可生成更高視覺質量與更多種類的目標紋理圖;參數(shù)法適合作為紋理合成領域的分析研究工具;卷積神經網(wǎng)絡應用到參數(shù)法中,可大幅縮短特征量設計與參數(shù)調整周期并提高合成效果,進一步提升了參數(shù)法作為理論分析和應用實現(xiàn)工具的價值。
分析式紋理合成法;非參數(shù)法紋理生成;參數(shù)法紋理生成;深度學習;卷積神經網(wǎng)絡;VGG-19
1 概 述
紋理是圖像的重要特征之一,紋理圖是數(shù)字圖像中的一個重要類別,分規(guī)則紋理圖和非規(guī)則紋理圖兩類;前者整體圖像的各部分重復均勻分布,后者圖像各部分總體相似但在大小、方向、顏色等方面隨機分布。當前紋理生成技術主要有非參數(shù)和普通參數(shù)法兩大類。非參數(shù)法通過建立或改進一系列模型、方法和算法生成紋理圖像,主要有基于濾波器采樣的模型、基于像素拷貝的模型以及基于片拷貝的模型三大類。基于濾波器采樣的模型通過對樣本采樣紋理圖的一系列不同分辨率圖像的濾波結果進行采樣分析,生成目標紋理圖;基于像素拷貝的模型通過從樣本采樣紋理圖向輸出圖區(qū)域拷貝像素生成目標紋理圖;基于片拷貝的模型通過拷貝紋理片生成目標紋理圖。普通參數(shù)法通過在一個緊湊完備(參數(shù)數(shù)量適中并有效,不易發(fā)生過度訓練)的參數(shù)模型中建立、調整參數(shù)信息來描述紋理特征,并基于這些特征描述生成目標紋理圖;其參數(shù)類型主要包括基于像素法、基于距離測量以及基于分析法的統(tǒng)計量。基于像素法是通過建立具有與樣本紋理圖相同的N階統(tǒng)計量像素生成目標紋理圖;基于距離法通過最小化樣本紋理圖和生成紋理圖之間的距離差異特征量生成目標紋理圖;基于分析法利用漸進式分析方法分析采樣紋理和目標紋理,并通過最小化損失函數(shù)等方法逐漸縮小兩者間的差距,進而生成最終目標紋理圖。非參數(shù)和普通參數(shù)紋理生成法的主要區(qū)別在于:前者目標紋理圖的建立源于一系列模型、方法、算法;后者通過對前人研究成果的分析以及對樣本紋理圖特征的觀察和數(shù)學分析手動建立一系列參數(shù),形成參數(shù)紋理模型,并利用該模型生成目標紋理圖。非參數(shù)法的優(yōu)點在于擁有更快的處理速度并生成更高視覺質量與更多種類的目標紋理圖;缺點在于無法為紋理圖建立對應的特征表達,而且不適合作為一種分析研究工具。普通參數(shù)法的優(yōu)點在于可以為各類紋理圖建立相應的特征表達進行推廣與改進,同時可作為分析研究工具應用于多個領域;缺點在于建立的紋理種類相對有限,某些生成紋理效果并不理想,此外由于參數(shù)是人工分析建立的,設計或改進參數(shù)周期很長。
深度學習(Deep Learning)是近年來興起的新技術[1],廣泛應用于圖像處理及計算機視覺領域;卷積神經網(wǎng)絡(Convolution Neutral Network,CNN)是基于深度學習的一項重要應用,是一種基于大數(shù)據(jù)自動學習的端到端參數(shù)模型。利用CNN自動訓練生成的特征表達可以推廣應用到其他各種數(shù)據(jù)集,節(jié)省了人工設計特征的時間周期;同時,由于其在圖像分類和目標識別領域方面的準確率已經大幅超越傳統(tǒng)機器學習方法,因此基于CNN的參數(shù)模型紋理生成方法正逐漸取代普通參數(shù)法,其合成紋理質量也正逐步向非參數(shù)法逼近。
為此,在概括總結并對比分析基于graph cut模型的非參數(shù)法和基于P&S模型的參數(shù)法兩個典型的國際主流分析式紋理合成技術以及深度學習卷積神經網(wǎng)絡的原理、框架結構、應用發(fā)展趨勢和優(yōu)缺點的基礎上,進一步討論了結合基于CNN的Caffe網(wǎng)絡和VGG結構的VGG-19紋理合成模型,通過對其結構框架、特征量建立與優(yōu)化等過程原理的分析,可以發(fā)現(xiàn)深度學習CNN網(wǎng)絡的引入有助于參數(shù)法紋理合成模型的建立與優(yōu)化,能有效提高參數(shù)法紋理合成效果并縮短改進周期。
2 非參數(shù)紋理生成法Graph-cut
Graph-cut是一種著名的非參數(shù)紋理生成方法[2],基于該方法建立的紋理圖效果迄今依然優(yōu)于大量普通參數(shù)法甚至CNN參數(shù)法。該方法運用了片拷貝的紋理生成法,可實現(xiàn)紋理圖像生成、紋理圖像優(yōu)化、不同種類圖像合成以及視頻合成等多種應用;其運行過程主要包含兩大核心步驟:選擇片放置位置與獲取優(yōu)化塊。利用隨機法或匹配法在輸出紋理圖區(qū)域選擇放置采樣紋理片的位置范圍(等于或小于采樣紋理區(qū)域的矩形區(qū)域);利用Graph-cut算法確定采樣紋理片的優(yōu)化提取塊(一般為小于采樣區(qū)域的不規(guī)則形狀),拷貝該優(yōu)化塊到目標紋理圖的放置區(qū)域。
原理如圖1所示。
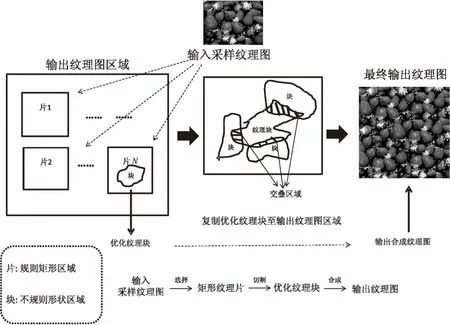
圖1 Graph-cut算法紋理合成基本原理
2.1選擇片放置位置
片放置方法主要有隨機放置和匹配放置。隨機放置指將整個輸入采樣紋理片每次隨機放置在輸出目標紋理圖區(qū)域的任意一個位置,這種方法耗時最短,主要適用于生成隨機紋理圖。匹配放置分兩種方式:第一種是整片匹配放置,該方法每次都放入整個輸入采樣紋理片的最優(yōu)塊(通過計算重疊區(qū)域的最小代價生成),適用于合成規(guī)則性紋理圖;第二種是子片匹配放置,該方法每次放入輸入采樣紋理一個局部區(qū)域片(遠小于采樣紋理片)的最優(yōu)塊,適合合成隨機紋理圖和紋理視頻。
其放置過程分初始化與優(yōu)化兩個階段。初始化階段主要將采樣紋理片的最優(yōu)塊逐步填充到空的輸出紋理圖區(qū)域中,分三個步驟:將第一個采樣紋理片放置在輸入紋理區(qū)的隨機位置;選擇第二次片放置位置(與上一次放入的部分或全部交疊),運行Graph-cut算法獲取放入片的優(yōu)化塊后放入該交疊位置;重復上一步直至填滿整個輸出圖區(qū)域。優(yōu)化階段是對已填充完畢的輸出紋理圖再次填充采樣輸入紋理信息,達到修正改進的目的,分兩步:利用代價函數(shù)計算出已填滿的輸出紋理圖的最大誤差塊,在該范圍內放入輸入紋理片的優(yōu)化塊區(qū)域;重復上一步,直至對最終結果滿意,從而結束迭代,獲得最終優(yōu)化輸出紋理填充圖。
2.2獲取優(yōu)化塊
獲取優(yōu)化塊的核心方法是運用Graph-cut算法,該算法是基于圖的最小代價路徑切取方法,是在Dynamic program算法[3]上的進一步改進。Dynamic program算法用于選擇兩個片的邊界交疊區(qū)域的優(yōu)化塊,原理是利用該區(qū)域的相鄰配對像素點分屬新舊片區(qū)的色差值之和來計算最小代價位置,步驟為:對交疊區(qū)域逐行掃描相鄰像素對,計算像素對屬于新舊區(qū)域時的色差值的和,記為代價值;記錄每一行的最小代價值點位置,繼續(xù)掃描下一行;重復上一步直至掃描整塊交疊區(qū)域結束,連接每行的最小代價值位置點,生成最優(yōu)塊的邊界線。
Graph-cut算法在Dynamic program算法的基礎上從處理兩個邊界域交疊區(qū)進一步擴展到處理多個邊界域或包圍域交疊區(qū),通過在舊優(yōu)化塊切割線(邊界線)的相鄰像素節(jié)點間插入塊節(jié)點,建立新的連接弧并重新計算生成最小代價切割線(優(yōu)化塊邊界線)。該算法的主要步驟是:在舊優(yōu)化塊邊界線的左右相鄰兩像素節(jié)點間插入新的塊節(jié)點;在每個塊節(jié)點和新片之間建立一條新的連接弧,計算該塊節(jié)點與相鄰兩像素節(jié)點及新片之間三條連接弧的代價值;存在三種新的切割方式,分別是從塊節(jié)點與新片區(qū)的連結弧切入、從三條連接弧以外的區(qū)域切入、從塊節(jié)點與相鄰像素節(jié)點之間切入,分別對應保留、取代、移除舊塊切割線。
2.3改進與擴展應用
Graph-cut算法還引入了三種方法優(yōu)化合成效果:運用梯度計算法優(yōu)化代價函數(shù)以更好地檢測邊緣,運用羽化和多分辨率處理法隱藏或移除視覺假象,運用快速傅里葉法以加速基于平方差和的交疊區(qū)域代價計算算法。此外,該算法還實現(xiàn)了多種擴展應用:對輸入采樣紋理進行翻轉、鏡像、縮放變換處理以增加生成紋理的多樣性,與用戶交互式方法結合實現(xiàn)不同種類圖像的合并以及從二維紋理圖像生成擴展到三維紋理視頻合成。但是該算法往往難以很好地合成具有明顯邊界結構特征的紋理,尤其是對那些獨立性很強、排列緊密并具有明顯邊界的色彩模式單元[4]。為了更好地保持紋理的邊界結構特征,國內研究人員先后提出了基于邊界圖的紋理合成法[4]、基于不規(guī)則塊的紋理合成法[5]與基于Graph cut的快速紋理合成算法[6]對其加以改進,提高合成效果并縮短合成時間。
3 參數(shù)法P&S模型紋理生成法
基于樣本的紋理合成技術是一種重要的參數(shù)法紋理生成技術[7],它是一種基于給定的小區(qū)域紋理樣本并按照表面的幾何形狀拼合生成整個圖像紋理的方法,其生成紋理在視覺上是相似而連續(xù)的[8],代表性模型是P&S模型[9],該模型迄今仍是普通參數(shù)法紋理生成的重要基礎模型。P&S模型是一種基于分析合成的模型,通過觀察前人設計的參數(shù)并運用數(shù)學推理和實驗分析設計及改進參數(shù),利用最大熵方法采集樣本圖像像素密度值,運用實踐遍歷性方法(對圖像空間信息取平均值)估算樣本圖像的參數(shù)值,生成可推廣的參數(shù)紋理生成模型。該模型利用一系列小波特征量和它們的相互關系建立邊緣、系數(shù)相關性、系數(shù)大小、跨尺度相位四類統(tǒng)計量參數(shù),運用梯度投影法將這些參數(shù)先后施加在高斯白噪圖上漸進式合成紋理,并迭代這一過程直至收斂得到最終紋理圖。其原理如圖2所示。
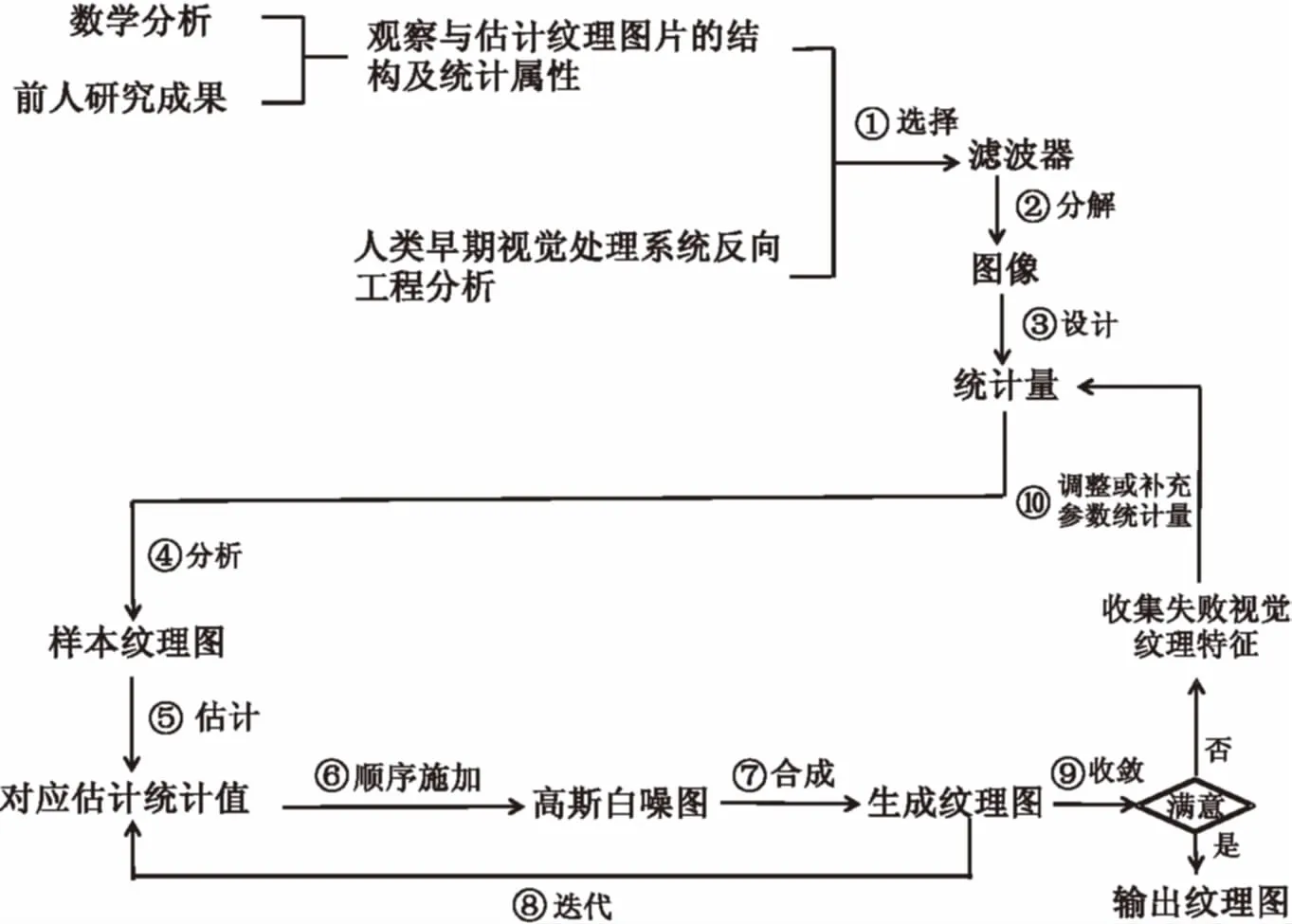
圖2 P&S模型系統(tǒng)原理
P&S模型參數(shù)對應的基礎函數(shù)特征與運用順序梯度投影算法合成紋理圖的方法決定了該模型利用可控金字塔濾波器[10]而非高斯濾波器分解圖像特征;可控金字塔濾波器方法具有良好的圖像重建特性、平移不變性和旋轉不變性,包含了方向波段和縮放比例(金字塔層次)兩套系數(shù)。P&S模型以小波多分辨率原理為基礎,運用可控金字塔濾波器將源樣本紋理圖分解成多個不同尺度的紋理圖像,進而設計了四類參數(shù)統(tǒng)計量:邊緣統(tǒng)計量包含偏差、峰度、尺寸、像素深度差異等信息;系數(shù)相關性統(tǒng)計量對應周期性、全局性的方向紋理結構;系數(shù)大小統(tǒng)計量體現(xiàn)了紋理邊角信息;跨尺度相位統(tǒng)計量反映了紋理立體陰影細節(jié)。
但是P&S參數(shù)模型方法具有如下缺點:對于紋理圖,無法區(qū)分直線和曲線輪廓,無法捕捉線條末端粗細度,無法形成封閉式輪廓,無法區(qū)分某些樣例中的線條與邊緣;對于非紋理圖,只能捕捉到局部結構信息而無法得到圖中不同目標的整體空間聯(lián)系;雖然該模型在處理對應樣本庫中的數(shù)百種紋理樣本時,迭代次數(shù)總能控制在50次左右,但理論上還無法確定參數(shù)模型何時收斂;由于參數(shù)是手動設計的,所以無法從理論上驗證是否還有更優(yōu)秀的參數(shù)集存在。
P&S參數(shù)模型方法主要適用于單種紋理樣本合成,國內研究者后續(xù)提出了基于相關性原理的多樣圖紋理合成方法以增加生成紋理種類滿足更多需求[11],以及結合圖像細節(jié)特征的全局優(yōu)化紋理合成方法用于更好地解決基于樣本的紋理合成中紋理圖像不連續(xù)、紋理結構或特征容易斷裂等情況[12]。
4 卷積神經網(wǎng)絡
模式識別、機器學習和深度學習技術長期以來廣泛應用于計算機視覺領域,在2012年基于ImageNet圖像數(shù)據(jù)庫的ILSVRC大賽中,以基于深度學習的CNN方法設計的AlexNet網(wǎng)在圖像分類比賽上獲得了第一名,其Top-5準確率(五次選擇有一次正確即納入正確分類)超出了第二名基于傳統(tǒng)機器學習的SVM方法達10%以上,此后2012年至2015年的圖像分類冠軍均為基于CNN方法的模型。CNN網(wǎng)絡主要包含卷積層、池化層和全連接層三種層次結構,使用損失函數(shù)評估系統(tǒng)性能,利用梯度下降法優(yōu)化卷積層和全連接層的連接權值;其所處理的輸入圖像一般具有寬度、高度和通道數(shù)三種屬性,比如ImageNet的224×224×3的標準輸入圖像即指像素寬度、高度均為224以及包含RGB共3個通道的輸入圖像。
與傳統(tǒng)神經網(wǎng)絡相比,CNN的不同點在于:主要用途是將輸入的傳感信息轉為有效的特征表達,這些表達目前在大尺度圖像識別領域已經超越了人工特征;用卷積層和池化層代替了大部分全連接層,應用局部連接、參數(shù)共享和特征圖方法,在大幅度降低參數(shù)數(shù)量的同時盡可能保有圖像特征;通過前向卷積與池化進程將輸入圖像分解為特征圖表達,再通過反向傳播進程調用梯度下降法優(yōu)化卷積層和全連接層的連接權值,迭代前向和反向進程直至收斂完成網(wǎng)絡訓練,生成最優(yōu)參數(shù)組合。
與傳統(tǒng)機器學習方法相比,CNN的不同點在于:SVM、KNN、Boosting等傳統(tǒng)機器學習方法都是淺層網(wǎng)絡結構,網(wǎng)絡深度遠低于CNN;傳統(tǒng)機器學習方法一般使用人工設計特征,比如用于目標檢測的SIFT特征、用于人臉識別的LBP特征與用于行人檢測的HOG特征,其設計周期長、效率低,CNN通過自動從大數(shù)據(jù)分析學習自動優(yōu)化調整特征參數(shù),大大縮短了特征設計周期;傳統(tǒng)機器學習方法的特征提取和分類階段是相互獨立先后進行,CNN是一種端到端系統(tǒng)(前向輸入卷積與反向輸出梯度下降優(yōu)化過程迭代進行至收斂到最優(yōu)),其特征提取和分類過程相互作用同步優(yōu)化,是全局性的統(tǒng)一過程,兩者不可分割。
4.1卷積層
CNN卷積層處理輸入圖像生成輸出特征圖,其3個重要特性分別是局部連接、參數(shù)共享與特征圖建立。局部連接原則借鑒了人眼視覺神經成像原理,即每個神經關注的只是圖像的某個局部位置而非全圖,最后再合成所有神經的局部觀察結果形成最終成像結果圖;參數(shù)共享原則令多個神經共享一套參數(shù),該原則適用于有一定規(guī)律的圖像(比如紋理圖),對非規(guī)則圖像應適當放寬條件;特征圖建立則是通過增加特征圖數(shù)量增強圖像表達能力(一張?zhí)卣鲌D對應源圖像的某一方面特征)以彌補前兩個特性造成的圖像信息損失。以神經通過3×3的濾波器去觀察6×6分辨率的輸入圖像為例:設濾波器卷積橫向縱向滑動步長值均為2,共需移動9次方能處理完整幅圖像(即用9個神經方能觀測整幅圖像):若采用全連接方式觀測,共需6×6×9個連接權值(每個像素對應一個連接權值);運用局部連接原則,設每個神經只觀測該圖像的3×3局部區(qū)域,則只需3×3×9個;運用參數(shù)共享原則,令9個神經均使用同一套參數(shù),則進一步縮減為只需3×3×1個;建立10張?zhí)卣鲌D表達圖像,則需3×3×10個;最終參數(shù)數(shù)量(連接權值數(shù)量)縮減為最初的27.8%,上述特性在處理大尺度分辨率圖像時,縮減參數(shù)幅度更為明顯。
每個卷積層包含的參數(shù)數(shù)量由輸入特征圖數(shù)量和輸出特征圖數(shù)量共同決定。假設某卷積層接收的輸入信息為64張?zhí)卣鲌D,輸出信息是128張?zhí)卣鲌D,使用的是3×3的濾波器(不考慮偏差值時,則每一套連接權值參數(shù)為3×3=9個);每個濾波器用64套不同參數(shù)對64張輸入特征圖進行卷積,每層需128個濾波器生成128張輸出特征圖,因此該卷積層所包含的連接權值參數(shù)個數(shù)一共是64×3×3×128=73 728個。
4.2池化層和全連接層
池化層采用了基于圖像多分辨率處理原理的金字塔式圖像處理方法,它利用向下采樣技術縮小輸入特征圖的大小,進而減少連接權值參數(shù)數(shù)量;一般采用2×2大小(3×3及其以上大小的池化層會造成信息損失過大)步長2(不重疊)的池化層,可以將輸入特征圖的寬度和高度分別縮小為原來的二分之一。池化層主要有平均值、最大值、隨機值池化層三類,目前以最大值池化層使用最為頻繁,2×2大小的最大值池化層就是取池化窗口所套入的鄰域空間的四個像素值的最大值作為該鄰域空間的輸出值。池化層除了具有縮小特征圖大小的特性以外,還保持了圖像的平移旋轉和縮放不變性,其多分辨率處理方式令整個CNN網(wǎng)絡能更好地識別圖像的不同區(qū)域。
最大連接層一般置于CNN網(wǎng)絡的尾部,用于將卷積層和池化層處理分解出的圖像各種特征表達合并輸出作為最終分類層的輸入信息;但由于CNN網(wǎng)絡的連接權值參數(shù)主要產生于全連接層,為了減少計算代價,全連接層正逐漸被移除或轉換成卷積層。
5 Caffe框架和VGG模型
5.1Caffe框架
Caffe是CNN的重要框架之一[13],包含了當前主流的深度學習算法和一系列參考模型(如Alexnet網(wǎng));該框架將模型表達和實際應用分離,支持C++和Python語言,廣泛應用于圖像分類、目標識別、語義特征學習等領域。Caffe采用名為Blobs的4維數(shù)組存儲數(shù)據(jù)(圖像坐標、權值和偏差),利用谷歌協(xié)議緩沖區(qū)存儲CNN網(wǎng)絡模型,調用CUDA核進行GPU卷積運算,包含了前向進程(接收輸入數(shù)據(jù)生成輸出數(shù)據(jù))和后向進程(利用隨機梯度下降算法優(yōu)化連接權值),并不斷迭代前向后向進程直至收斂得到最優(yōu)參數(shù)網(wǎng)絡。
5.2VGG模型
VGG模型[14]是建立在Caffe框架下的一個實用型CNN模型,在2014年ImageNet比賽中的圖像分類和目標識別方面分別取得了第二名和第一名。相對于2012年比賽冠軍(11×11濾波器,步長為4)和2013年冠軍(7×7濾波器,步長為2),VGG網(wǎng)的主要改進在于采用了更小的濾波器(3×3濾波器,步長為1)和更深的層數(shù)(19個權值層)。由于小型濾波器能夠表達更多輸入圖像特征進而使得決策函數(shù)更具區(qū)分性,同時還能減少參數(shù)數(shù)量,VGG模型使用3個堆疊的3×3濾波器卷積層取代1個7×7濾波器卷積層(其卷積輸出結果圖像大小相等,缺點是由于層數(shù)增加導致計算代價增大)。一共有6個模型(A-LRN/VGG-11/VGG-13/VGG-16/VGG-16*/VGG-19)參與了研究分析,前四個主要用于實驗測試對比以及參數(shù)初始化,后兩個分別用于目標識別和圖像分類。VGG-19模型一共包含16個卷積層、5個池化層和3個全連接層以及1個soft-max分類層,其中含連接權值的卷積層和全連接層一共19個(VGG-19名字源于此),其結構如圖3所示(圖中各層詳細示意圖標注于主框架圖下方)。
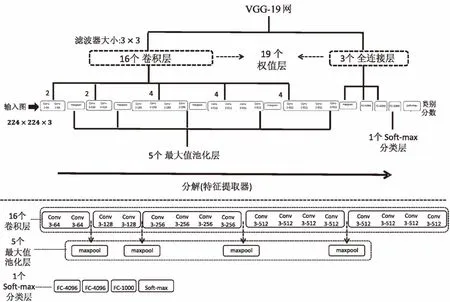
圖3 VGG-19網(wǎng)絡結構圖
由于深層網(wǎng)絡的梯度具有不穩(wěn)定性,一般先用隨機連接權值初始化淺層網(wǎng)絡,再將訓練后的淺層網(wǎng)絡的各層連接權值作為深層網(wǎng)絡對應層的初始化權值(該深層網(wǎng)絡的其余未賦值層連接權值使用隨機初始化值),最后使用梯度下降法自動迭代訓練優(yōu)化連接權值,得到最終應用模型。VGG-19模型的前4層卷積層和后3層全連接層的初始化權值來自訓練后的VGG-11模型的對應層,剩余12層則采用隨機初始化值。利用大數(shù)據(jù)集訓練完畢的VGG網(wǎng)絡除了可直接運用于圖像分類和目標識別外,還可推廣應用到其他小數(shù)據(jù)集建立特征表達,并結合傳統(tǒng)機器學習分類器實現(xiàn)對小數(shù)據(jù)集的圖像分類和目標識別。
6 基于VGG-19的紋理生成模型
VGG-19紋理生成模型[15]的結構是在VGG-19模型的基礎上移除最后3個全連接層以及將5個最大值池化層轉為平均值池化層,其工作原理源于P&S模型,是一個基于CNN的參數(shù)法紋理生成模型。VGG-19模型建立了一種新型特征表達(關系矩陣)來表示紋理,可用于合成紋理圖;此外,該模型在不同卷積層生成的階段性紋理還可用于探測分析人腦視覺成像的不同階段。
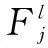
上述特征表達形成步驟原理如圖4所示。
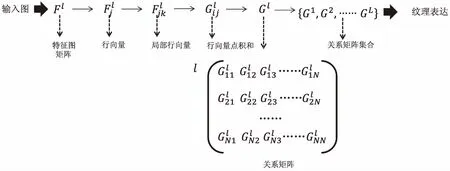
圖4 紋理特征表達形成步驟原理
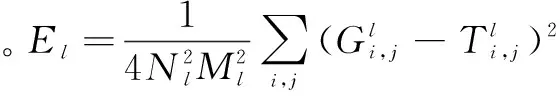
VGG-19紋理模型建立的紋理圖的效果比P&S模型及Caffe結果更好[15],但依然弱于Graph-cut方法。該模型工作原理類似于人腦視覺成像過程(由低級信息合成中級信息直至最終形成高級成像信息,逐層清晰化),在每個層次上合成的紋理圖可以用于探測視覺成像系統(tǒng),根據(jù)不同信號反饋分析模型和成像系統(tǒng)的層與層之間的聯(lián)系。此外,由于所采用的特征表達為關系矩陣集,該模型生成非紋理圖時,保留了圖像中的目標信息,但丟失了相關目標之間的全局聯(lián)系信息。
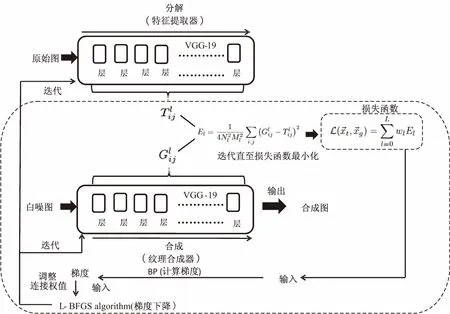
圖5 VGG-19紋理生成模型
7 結束語
紋理作為數(shù)字圖像的一個重要基礎特征廣泛應用于計算機視覺等圖像處理領域,分析式紋理合成方法是重要的紋理合成技術之一。以基于Graph-cut模型的非參數(shù)法、基于P&S模型的參數(shù)法和基于CNN的VGG-19網(wǎng)絡模型為研究對象,綜合回顧并對比分析三者的框架結構、過程原理和實現(xiàn)步驟,并討論了非參數(shù)法、參數(shù)法的應用發(fā)展趨勢和優(yōu)缺點。通過深入剖析VGG-19紋理合成模型原理,得出了引入深度學習卷積神經網(wǎng)絡新興技術的參數(shù)法能有效縮短參數(shù)設計改進周期并顯著提高合成效果的結論。此外,還進行了大量合成式紋理主流與新興技術的調研,對于計算機視覺領域的圖像紋理合成研究工作有一定借鑒意義。下一步將調研分析信息應用于相關研究課題項目上,并進一步論證其在相關領域方面的實際功效。
[1] Johnson J,Karpathy A.Convolutional neural networks for visual recognition[EB/OL].2015.http://cs231n.github.io/convolutional-networks.
[2] Kwatra V,Sch?dl A,Essa I,et al.Graphcut textures:image and video synthesis using graph cuts[J].ACM Transactions on Graphics,2003,22(3):277-286.
[3] Efros A A,Freeman W T.Image quilting for texture synthesis and transfer[C]//Proceedings of the 28th annual conference on computer graphics and interactive techniques.[s.l.]:IEEE,2001:341-346.
[4] 楊 剛,王文成,吳恩華.基于邊界圖的紋理合成方法[J].計算機研究與發(fā)展,2005,42(12):2118-2125.
[5] 熊昌鎮(zhèn),黃 靜,齊東旭.基于不規(guī)則塊的紋理合成方法[J].計算機研究與發(fā)展,2007,44(4):701-706.
[6] 鄒 昆,韓國強,李 聞,等.基于Graph Cut的快速紋理合成算法[J].計算機輔助設計與圖形學學報,2008,20(5):652-658.
[7] 朱文浩,魏寶剛.基于樣本的紋理合成技術綜述[J].中國圖象圖形學報,2008,13(11):2063-2069.
[8] 徐曉剛,鮑虎軍,馬利莊.紋理合成技術研究[J].計算機研究與發(fā)展,2002,39(11):1405-1411.
[9] Portilla J,Simoncelli E P.A parametric texture model based on joint statistics of complex wavelet coefficients[J].International Journal of Computer Vision,2000,40(1):49-70.
[10] Simoncelli E P,Freeman W T.The steerable pyramid:a flexible architecture for multi-scale derivative computation[C]//International conference on image processing.[s.l.]:[s.n.],1995:444-447.
[11] 徐曉剛,鮑虎軍,馬利莊.基于相關性原理的多樣圖紋理合成方法[J].自然科學進展,2002,12(6):665-668.
[12] 肖春霞,黃志勇,聶勇偉,等.結合圖像細節(jié)特征的全局優(yōu)化紋理合成[J].計算機學報,2009,32(6):1196-1205.
[13] Ia Y,Shelhamer E,Donahue J,et al.Caffe:convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM international conference on multimedia.[s.l.]:ACM,2014:675-678.
[14] Karen S,Andrew Z.Very deep convolutional networks for large-scale image recognition[EB/OL].2015-04-10.http://www.robots.ox.ac.uk/vgg/research/very_deep/.
[15] Gatys L A,Ecker A S,Bethge M.Texture synthesis using convolutional neural networks[C]//Proceedings of the 28th international conference on neural information processing systems.[s.l.]:[s.n.],2015.
[16] Zhu C,Byrd R H,Lu P,et al.Algorithm 778:L-BFGS-B:fortran subroutines for large-scale bound-constrained optimization[J].ACM Transactions on Mathematical Software,1997,23(4):550-560.
AnalyzedTexture-synthesisTechniquesandTheirApplicationsinDeepLearning
LI Hong-lin
(Life-Information System Course,Graduate-School of Yamanashi University,Kofu 400-8510,Japan)
The state-of-the-art analyzed texture synthesis techniques are divided into non-parametric and parametric methods,which contribute to the current corresponding research on computer vision.By summarizing and comparing their principles,structures,development trends,advantages and disadvantages,a non-parametric method based on graph-cut model and a parametric method based on P&S model are analyzed in detail.In addition,the structures and principles of Convolution Neural Network (CNN) based on deep-learning which are widely applied in image-process filed are also discussed.Finally,a new texture synthesis model VGG-19 is introduced,which is the combination of CNN-based Caffe network with VGG model that obtained high scores in the 2014 ImageNet classification and object detection competence.The VGG-19 model can be also used to analyze human visual process.The analyzed results show the facts as below.Non-parametric methods can synthesize high-quality textures of various kinds with high speed.Parametric methods are appropriate for being used as analysis tools.CNN applied in parametric methods can greatly reduce the time period of designing and adjusting feature representations and parameters and improve the synthesized results synchronously,which is proved to be valuable tools for analyzing theory and realizing applications on texture-synthesis work.
analyzed texture synthesis method;non-parametric texture generation;parametric texture generation;deep learning;convolutional neural network;VGG-19
2016-10-30
2017-02-10 < class="emphasis_bold">網(wǎng)絡出版時間
時間:2017-07-19
李宏林(1979-),男,講師,博士,研究方向為計算機視覺、圖像處理、數(shù)據(jù)挖掘等。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170719.1109.032.html
TP37
A
1673-629X(2017)11-0007-07
10.3969/j.issn.1673-629X.2017.11.002
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
