海量非結構化網絡招聘數據的挖掘分析
2017-10-23 10:35:11張學新賈園園
長春師范大學學報 2017年10期
張學新,賈園園,饒 希,蔡 黎
(湖北工程學院數學與統計學院,湖北孝感 432000)
海量非結構化網絡招聘數據的挖掘分析
張學新,賈園園,饒 希,蔡 黎
(湖北工程學院數學與統計學院,湖北孝感 432000)
網絡招聘憑借其獨特優勢,己成為招聘者發布信息和應聘者獲取信息的主要渠道,挖掘海量網絡招聘信息里隱含的社會和相關行業的需求特點與趨勢有著非常重要的意義。本文抓取拉勾網站發布的50多萬條招聘數據及58同城兩千多條應聘數據,先對其中的非結構化數據進行去重去空、中文分詞及停用詞過濾等數據預處理,再使用TF-IDF權重法提取候選特征詞,形成詞袋,構造詞匯-文本矩陣,利用基于潛在語義(LSA)分析的奇異值分解算法(SVD)對詞匯-文本矩陣進行空間語義降維,最后通過k-means聚類算法對職位的職業類型和專業領域進行劃分,找出熱門需求,分析大數據職位需求情況與行業分布情況、大數據職位技能要求及IT行業供求與發展;對相關結果進行可視化展示,并運用關聯規則挖掘信息間的內在聯系。
大數據;網絡招聘信息;TF-IDF;奇異值分解;Python語言
隨著互聯網技術的迅速發展,企業把人才招聘信息越來越多地發布到互聯網上,產生了大量的非結構化數據。這些數據包含用人單位對人才的需求及能力要求信息,在一定程度上代表了人才需求的未來走向。但是,對模糊而且非結構化的文本數據進行挖掘比較困難,涉及統計學、機器學習、數據庫技術以及專業軟件使用等技術。國內對這方面的挖掘研究很少。鐘曉旭[1-2]先后對2010年的3家招聘網站的78481條招聘信息及新安人才網上計算機類專業招聘信息進行聚類,統計各個職位的需求量,計算職位間的相關系數。王靜[3]選擇2011年的4家招聘網站、包括6種職業的2262個招聘網頁,采用偽二維隱馬爾可夫模型來分割,抽取其中的職位名、機構名等信息。總的來說,這些文本挖掘的研究深度有限,所用數據不是真正意義上的網絡招聘數據,不是大量非結構化的招聘數據;統計分析方法簡單,很少使用軟件編程。本文利用八爪魚采集器,結合Python語言爬取自2015年11月至2016年4月拉鉤網25萬多條企業招聘信息(http://www.lagou.com),58同城網上北京地區的人才招聘信息共2219條,深入挖掘并可視化海量非結構化網絡招聘數據的有關信息。
1 數據預處理
觀察抓取的數據,招聘信息.csv中的字段大多為文本格式,需要將其量化成數值形式才能對其進行分析。而職位描述.csv中有大量空行以及重復的情況,如果不做處理會對后續分析造成影響,并且招聘文本信息存在大量噪聲特征,如果把這些數據也引入進行分詞、詞頻統計乃至文本聚類等,則必然會對聚類結果的質量造成很大的影響,因此首先要對數據進行預處理。
1.1 屬性數值化
對于招聘信息.csv、Salary(月薪)、Work Year(工作經驗)、Position Advantage(職位優勢)、Finance Stage(公司階段)、Education(學歷要求)、Company Size(公司規模)等指標,需要將其數值化,例如:Salary出現3種字符類型:8k~12k、8k以下、12k以上,正則表達式轉換為數字型:10、8、12,單位:k;Finance Stage:初創型(未融資)、初創型(不需要融資)、初創型(天使輪)、成長型(不需要融資)、成長型(A輪)、成長型(B輪)、成熟型(不需要融資)、成熟型(C輪)、成熟型(D輪及以上)、上市公司。編碼轉換為:初創型—B1、成長型—B2、成熟型—B3、上市公司—B4。
1.2 去重、去空
對職位描述.csv,存在大量空行和崗位描述文本完全一致的樣本,去除后數據僅剩365890行。
1.3 中文分詞
由于中文文本的特點是詞與詞之間沒有明顯的界限,從文本中提取詞語時需要分詞,本文采用Python開發的一個中文分詞模塊——jieba分詞,對每一個崗位描述進行中文分詞,jieba分詞的原理是采用Trie樹進行詞圖掃描,得到一個有向無環圖(DAG),其中包括漢字所有可能的構詞。對句子中詞的切分采用最大概率(詞頻的最大)方法,對詞典中沒有的詞,采用Viterbi算法,使用HMM模型處理。該分詞系統具有分詞、詞性標注、未登錄詞識別,支持用戶自定義詞典、關鍵詞提取等功能。
部分分詞結果示例如圖1所示。

圖1 部分分詞結果
圖1的分詞結果是沒有停用詞過濾的結果,可以看到,其中含有大量標點及表達無意義的字詞,對后續分析會造成很大影響,因此接下來需要進行停用詞過濾。
1.4 停用詞過濾
把文本里某些無實義的介詞、連詞、分號等字符,以及某些無助于分類的專用名詞過濾掉,以減少存儲空間,提高搜索效率。停用詞有兩個特征:一是極其普遍、出現頻率高;二是包含信息量低,對文本標識無意義。

2 文本向量化
2.1 文檔頻數(DF)
文檔頻數(DF)即訓練集合中包含某單詞的文本數。當一個詞在大量文檔中出現時,這個詞通常被認為是噪聲詞。本文選用DF方法篩選出如下停用詞:我、有、的、了、是,等。將篩選出的停用詞加入停用詞表,再利用停用詞表過濾停用詞,將分詞結果與停用詞表中的詞語進行匹配,若匹配成功,則進行刪除處理。去除停用詞后的部分結果示例如圖2所示。
2.2 文本特征抽取
經過上述文本預處理后,雖然已經去掉部分停用詞,但還是包含大量詞語,給文本向量化過程帶來困難,所以特征抽取的主要目的是在不改變文本原有核心信息的情況下盡量減少要處理的詞數,以此來降低向量空間維數,從而簡化計算,提高文本處理的速度和效率。

圖2 停用詞過濾后分詞結果
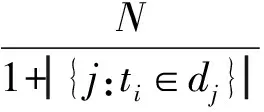
在Shannon的信息論的解釋中,如果特征項在所有文本中出現的頻率越高,它所包含的信息嫡越小;如果特征項集中在少數文本中,即在少數文本中出現頻率較高,則它所具有的信息嫡也較高。這樣詞的權重可以定義為wij=tfij×idfi,將權重按照從大到小的順序排列,抽取權重最大的前50000個特征詞作為候選特征詞。
2.3 文本的空間向量模型[5]
用向量空間的一個向量表示每一個文本,并以每一個不同的特征項(詞條)對應為向量空間中的一個維度,而每一個維度的值就是對應的特征項在文本中的權重,這里的權重可以由TF-IDF等算法得到。向量空間模型就是將文本表示成為一個特征向量V(d)=(wi)n×1,其中,ti為文檔d中的特征項,wi為該特征項的權值,可由TF-IDF算法得出。
2.4 文本的向量化表示
上述文本特征抽取將全部特征項篩選為50000個候選特征項,這時需要構建一個詞袋,根據招聘文本的特征項對應詞袋中的位置,組成一個同維數的向量,最后得到一個詞匯-文本矩陣(wij)m×n,其每一行表示一個特征項在各個文檔中的權重,每一列表示一個文檔向量。表1和表2是部分結果顯示。

表1 詞匯-文本詞頻矩陣
2.5 語義空間降維
理論上,當得出文本向量后就可以直接比較兩向量夾角的余弦值進行相似度的計算。但可以發現,現在構造的詞匯-文本矩陣是一個50000×365890的巨大矩陣,計算起來比較困難。另外,招聘信息文本信息中存在同義詞和近義詞等詞語,即使通過特征抽取轉化得到的文本向量也可能達不到自然語言屬性本質的要求。
因此,這里需要借用潛在語義分析(LSA)理論,將招聘信息的文本向量空間中非完全正交的多維特征投影到維數較少的潛在語義空間上。而LSA對特征空間進行處理時用的關鍵技術就是奇異值分解(SVD),在統計學上,它是針對矩陣中的特征向量進行分解和壓縮的技術。
2.6 奇異值分解的基本原理
奇異值分解可以將網頁文本通過向量轉換后的非完全正交的多維特征投影到較少的一個潛在語義空間中,同時保持原空間的語義特征,從而可以實現對特征空間的降噪和降維處理。
對于任意的矩陣A=Am×n,這里是由招聘文本信息組成的詞匯-文本矩陣。它的奇異值分解表達式為A=U∑VT,其中,Um×m是酉矩陣,∑m×n是對角矩陣,Vn×n是酉矩陣。∑對角線上的元素是A的奇異值,∑=diag(σ1,σ2,…,σr,0,…,0),其中σ1≥σ2≥…≥σr>0。
奇異值分解定理[6]設A∈Rm×n,且r=rank(A)≤min(m,n),則存在正交矩陣U∈Rm×n和V∈Rm×n,對角矩陣∑∈Rm×n,∑=diag(σ1,σ2,…,σr,0,…,0),其中σ1≥σ2≥…≥σr>0,使得
A=U∑VT.
(1)
2.7 詞匯-文本矩陣的奇異值分解
對于矩陣詞匯-文檔矩陣Am×n的奇異值分解可表示為Am×n=Um×m∑m×nVn×nT,其中,Um×m稱為詞匯矩陣,每一行可以理解為意思相關的一類詞,行中的元素就是某個詞與該行其它詞的相關性大小的度量,而Vn×nT視為文檔矩陣,它的每一列都表示招聘信息中同一主題一類的文本,其中的每個元素代表這類文本中每篇文本的相關性,∑m×n矩陣表示的是某類詞與招聘文本之間的相關性。在生成的這個“語義空間”中,大的奇異值對應的維度更具詞的共性,而小的奇異值所對應的維度更具有詞的個性。
對Um×m及Vn×n進行行分塊,得到

(2)

Am×n≈Um×k∑k×kVk×nT?Ak.
(3)

3 數據挖掘
3.1 文本聚類
相似度是用來衡量文本間相似程度的一個標準。本文采用基于距離度量的歐幾里得距離測度招聘文本間差異。文本聚類對無類別標記的文本信息,根據不同的特征,將有著各自特征的文本進行分類,使用相似度計算將具有相同屬性或者相似屬性的文本聚類在一起。通過對不同職位進行分類,求職者可以結合自身狀況更加快捷地獲取相關信息資源。
聚類結果顯示,目前所需人才分為產品類、技術類、運營類、金融類、設計類、市場與銷售類、職能類等類型;人才需求中分為移動互聯網、電子商務、分類信息、廣告營銷、教育、金融、旅游、企業服務、社交網絡、生活服務、數據服務、文化娛樂、信息安全、醫療健康、硬件、游戲、招聘等專業領域。
3.2 分析熱門需求
首先,要定義何為熱門需求,本文認為熱門需求具備以下幾個特征:普遍供不應求、企業需求量大、平均工資高、未來需求量大、發展前景好。本文用企業發布招聘信息數量、平均薪水、發展階段與公司規模描述人才需求情況。所抓取的文檔涉及300個大中小地域,利用python 2.7求得各個地域發布的招聘信息量,首先篩選出發布信息量在前33名的地域占總招聘信息數的98.89%,因此其余267個城市可以忽略不計,進而構造上述指標,運用主成分分析法構建綜合排名算法對其進行綜合排名。熱門行業排行前五的分別是:移動互聯網、金融、電子商務·金融、移動互聯網·金融、電子商務。經統計,所抓取文檔中共有124類職位,首先篩選出發布信息量在前37名的行業占總招聘信息數的99.83%,因此其余87個行業可以忽略不計,同樣對其進行綜合排名。熱門職位排行前五的分別是:后端開發、運營、銷售、視覺設計、編輯。
3.3 未來人才需求走向
對于熱門地域前五名,即北京、上海、深圳、杭州、廣州,分析其對學歷的需求,大多以本科、專科為主;分析其對工作經驗的需求,要求大多在1~3年。分析各月發布的招聘信息中,熱門地域所占比例均大于80%,占較大比重,且趨勢較均衡,可以看出近期熱門地域對人才的需求仍然很大。
3.4 大數據職位需求情況
首先需要將大數據相關職位篩選出來進行分析,本文通過對大數據相關職位的職位名稱特點進行分析,發現其職位名稱大多包含“數據”二字,但是某些職位如“數據庫開發師”“數據倉庫工程師”等并不屬于大數據相關職位,因此,本文在篩選數據時,只在職位名稱文檔中選出包含“數據”字段且不包含“數據庫”與“數據倉庫”字段的數據,共得到10958條招聘信息。
3.5 關聯規則挖掘[7]
進行關聯規則挖掘時,首先對數據進行編碼,將文本型數據轉換為分類數據,編碼結果是,城市C1~C4,對應一線城市~四線城市;公司規模B1~B4,對應員工50人以下~500人以上;應聘者教育水平E1~E4,對應大專及學歷不限~博士;公司金融狀況F1~F4,對應初創型~上市公司;工作年限要求W1~W4,對應1年以下(應屆,不限)~5年以上;月薪資水平S1~S7,對應5千以下~3萬以上。對編碼后的數據對,分析各個指標之間的關聯規則(圖3)。

圖3 關聯規則網絡
關聯分析的部分結果如表3所示,在所有大數據相關職位中,存在的關聯規則如下:如果一個企業提供的平均薪酬在2萬~2.5萬范圍內,且要求學歷是本科,那么這家企業92.83%的概率在一線城市。如果一家企業要求的工作經驗是3~5年,公司規模是500人以上,位于一線城市,那么它有86.99%的概率需要本科以上學歷。

表3 關聯分析部分結果
4 大數據職位的行業分布情況
4.1 地區分布情況
從大數據職位的區域分布來看,“北上深杭廣”等特大一線城市合計占據89.2%的職位份額,僅北京地區占比就超過五成。因此,對于大數據的職業發展來說,“堅守一線城市”才是明智的選擇。
4.2 大數據職位技能要求
本文篩選出所有的大數據職位與其對應編號,按照編號將抓取保存的數據集中相應的大數據職位的崗位描述和任職要求提取出來,利用武漢大學開發的ROST文本挖掘系統對這些文本進行分詞,由于文本中有大量的專業術語如“數據分析”“數據挖掘”“云計算”等,需要添加自定義的用戶詞典,將這些專業術語添加進去,然后再進行分詞,詞頻統計,畫出詞云圖[8]如圖4所示。

圖4 詞云圖
根據圖4可以看出,“數據”“數據分析”“數據挖掘”“開發”“技術”“算法”“模型”“系統”“互聯網”等詞語出現頻數較大,這說明大數據相關職位要求應聘者具有良好的數據處理與分析能力,其次,“運營”“項目”“市場”“客戶”“用戶行為”“營銷”等詞出現頻率也比較高,這說明要求應聘者具有對數據的業務理解能力;另外,“學歷”“統計學”“數學”“計算機”等詞語,說明大數據相關職位對與學歷和專業都有一定的要求。
越來越多的企業將“大數據”視為未來發展的“能源”,期待數據能給企業的運營、產品策略、市場研究、品牌管理等方面帶來價值。企業對數據分析師等數據相關人才的需求不斷上升。2016年,據獵聘網人才大數據研究中心估計,中高級數據分析師的人才處于極度緊缺狀態,人才緊缺指數在4.5以上。
4.3 IT行業供求與發展
IT行業包括計算機硬件業、通信設備業、軟件業、計算機及通信服務業。原始數據沒有給出IT人才市場的供應量,需要爬取外部網絡招聘數據,構造TSI人才緊缺指數來分析IT人才市場的供求現狀和發展趨勢。
4.4 數據來源

4.5 不同職位供求現狀
不同學歷TSI指數見圖5和圖6。由于職業種類很多,本文只對發布招聘信息數前8位的職位進行供求分析。根據圖5可以看出,目前IT行業中網頁設計/制作以及軟件工程師的人才緊缺指數較大,呈現供不應求的現狀;而硬件工程師、網絡管理員、電子電器工程師和技術支持維護人員的緊缺指數較低,呈現供過于求的狀態。根據圖6可以看出,目前大專學歷和碩士人才緊缺指數較大,呈現供不應求的現狀;而本科生的人才緊缺指數較低,呈現供過于求的狀態,可能是由于大學擴招導致本科畢業生數量急劇上升,就業形勢險峻。
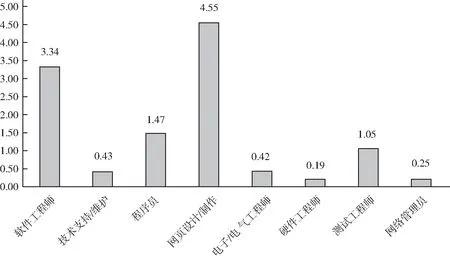
圖5 不同職位TSI指數

圖6 不同學歷TSI指數
5 結語
本文基于TF-IDF權重法提取特征詞,構造詞匯-文本矩陣,進一步運用基于潛在語義(LSA)分析的奇異值分解算法(SVD)對詞匯-文本矩陣進行空間語義降維,通過k-means聚類算法對職位的職業類型和專業領域進行了聚類;分析了熱門行業、職位、地域;對大數據相關新興職位,深入挖掘其關聯規則,分析其需求增長趨勢、行業分布情況、地域分布情況、行業職位特征、行業薪酬情況以及技能要求。
得到的聚類結果準確度與抓取文檔的結果在一定程度上有出入,主要是采用歐式距離測度相似性有局限性,k均值算法本身也需要改進。在中文文本挖掘過程中如何使用較復雜的數學統計模型值得進行深入研究。
[1]鐘曉旭.基于Web招聘信息的文本挖掘系統研究[D].合肥:合肥工業大學,2010.
[2]鐘曉旭,胡學鋼.基于數據挖掘的Web招聘信息相關性分析[J].安徽建筑工業學院學報:自然科學版,2010,18(4):23-45.
[3]王靜.Web對象的信息抽取的關鍵技術研究[D].西安:西安電子科技大學,2011.
[4]朱明.數據挖掘[M].2版.合肥:中國科學技術大學出版社,2008.
[5]鄔啟為.基于向量空間的文本聚類方法與實現[D].北京:北京交通大學,2014.
[6]鄭慧嬈,陳紹林,莫忠息,等.數值計算方法[M].2版.武漢:武漢大學出版社,2012.
[7]Pang-Ning Tan,Michael Steinbach,Vipin Kumar.數據挖掘導論[M].北京:人民郵電出版社,2006.
[8]Helic D,Trattner C,Strohmaier M,et al.Are tag clouds useful for navigation? A network-theoretic analysis[J].Journal of Social Computing and Cyber-Physical Systems,2011,1(1):33-55.
[9]周健,傅昭南,田茂再.基于TSI指數的中國運輸服務指數構建[J].系統工程理論與實踐,2015,35(4):965-972.
DataMiningAnalysisofMassiveUnstructuredNetworkRecruitmentInformation
ZHANG Xue-xin, JIA Yuan-yuan, RAO Xi, CAI Li
(Mathematics and Statistics School,Hubei Engineering University,Xiaogan Hubei 432000,China)
With its unique advantages, network recruitment has become the main channel for recruiters and candidates to release information, thus, it is of great significance to excavate the features and trends of the social & related industries demand hidden in the vast network of recruitment information. This paper crawl out about 500 thousand recruitment texts from Lagou net and more than 2 thousand application job data from 58 tong city. First of all, the unstructured data are reprocessed by discard empty, Chinese word segmenting and stop word filtering and other data preprocessing. Secondly, extracting of candidate feature words using TF-IDF weighting method, formation words bag, structuring term-document matrix, to reduce the dimensionality of the semantic space for term-document matrix based on the singular value decomposition algorithm for latent semantic analysis are carry out. Finally, post types of occupations and areas of specialization are divided through the K-means clustering algorithm, and the hot demand is find out, the demand for big data jobs and big data industry distribution, big data job skill requirements and the development of IT industry are analyzed, also, visualization of the relevant results, and the inherent link between information by association rules mining are implemented.
big data; network recruitment information; TF-IDF; SVD; Python language
TP391.4
A
2095-7602(2017)10-0028-09
2017-05-06
湖北工程學院教研項目“與大數據公司聯合開展(應用)統計學專業實訓教學的探索與思考”(2016A20)。
張學新(1966- ),男,副教授,博士,從事概率論與數理統計方法應用研究。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
