基于說話人辨識的自上而下聽覺顯著性注意模型①
2017-07-19 12:27:06葉于林莫建華
計算機系統(tǒng)應(yīng)用 2017年7期
葉于林, 楊 波, 莫建華, 劉 夏
1(中國人民解放軍78438部隊, 四川 成都 610066)
2(中國人民解放軍68108部隊, 甘肅 蘭州 730030)
基于說話人辨識的自上而下聽覺顯著性注意模型①
葉于林1, 楊 波2, 莫建華1, 劉 夏1
1(中國人民解放軍78438部隊, 四川 成都 610066)
2(中國人民解放軍68108部隊, 甘肅 蘭州 730030)
為體現(xiàn)聽覺注意神經(jīng)信息處理計算機制對聽覺場景內(nèi)容的自動分析與理解功能, 本文基于人耳對頻率變換的感知特性, 結(jié)合深度信念網(wǎng)絡(luò)的說話人辨識與聽覺顯著模型, 提出了一種自上而下的聽覺顯著性注意提取模型.仿真結(jié)果表明: 該模型具有可行性, 同時在利用深度信念網(wǎng)絡(luò)的說話人辨識技術(shù)中能夠有效地凸顯目標說話人的顯著度.
聽覺顯著性注意; 顯著性注意提取模型; 深度信念網(wǎng)絡(luò); 說話人辨識
耳朵是人體生理結(jié)構(gòu)不可缺少的一部分, 在復(fù)雜的聲源環(huán)境中, 人類首先通過它獲取大量的聽覺信息,然后再經(jīng)過大腦神經(jīng)系統(tǒng)分析處理, 最后智能提取出我們所需的信息, 這就是人類聽覺系統(tǒng)的選擇性注意特性的具體表現(xiàn). 聽覺選擇性注意是人類對外界聲音信息進行加工處理的一項心理調(diào)節(jié)機制, 它體現(xiàn)了處理過程中的效率, 即在大量的聲音信號中, 選擇提取有用信號并抑制大部分的干擾信號以確保有用信號的進一步加工. 通過模擬人類聽覺系統(tǒng)這種選擇性注意能力, 研究探索具有一定主動性、選擇性的聽覺選擇性注意計算模型算法, 使得計算機語音處理系統(tǒng)也像人類聽覺系統(tǒng)一樣具有一定的聽覺主動性和選擇性, 對豐富和發(fā)展計算機聽覺理論及其在語音處理、人工智能等多個研究領(lǐng)域中都具有重要的意義, 同時對人耳聽覺系統(tǒng)的研究也有著深遠的影響, 這也是近年來國內(nèi)外學(xué)者研究的熱點課題.
目前國內(nèi)外對于顯著性注意的研究主要集中在視覺上, 近年來各大院校都相繼有視覺關(guān)注度相關(guān)的文獻報道. 對于聽覺關(guān)注度的研究尚處于起步階段, 其主要以具有突發(fā)性的自下而上顯著性聲源[1]為研究對象,即自下而上聽覺顯著性注意模型研究, 但在研究過程中未深入考慮聽覺顯著性和視覺顯著性的差異. 所以,本文在人耳聽覺系統(tǒng)對語音信息的研究過程中, 將語音信號分別進行頻率通道和時間通道處理, 并結(jié)合頻率上的差異, 首先提出一種自下而上聽覺顯著性注意計算模型, 同時為了體現(xiàn)聽覺注意神經(jīng)信息處理計算機制對聽覺場景內(nèi)容有自動分析與理解功能, 在自下而上聽覺顯著性注意計算模型的基礎(chǔ)上加入語音流的說話人辨識技術(shù), 得到一種自上而下聽覺顯著性注意計算模型, 其目的是模擬人類聽覺系統(tǒng)在復(fù)雜的多聲源環(huán)境下智能提取感興趣或重要的聲音內(nèi)容, 即“雞尾酒會效應(yīng)”[2]. 仿真結(jié)果表明: 結(jié)合了說話人辨識技術(shù)的自下而上聽覺顯著性注意計算模型, 能夠在語音流中有效降低非目標說話人的聽覺顯著性, 從而提高目標說話人的聽覺顯著性.
1 聽覺顯著性注意模型
1.1 自下而上聽覺顯著性注意模型
自下而上顯著性模型最早出現(xiàn)在圖像研究中[3], 以Itti和Kouch提出的計算模型(即Itti模型)[4]最受肯定.Itti模型首先從原始圖像中提取出顏色、方向、亮度三種特征圖, 并利用中心周邊差異算子提取特征的對比度, 再將三種特征顯著性注意線性合并作為最終的顯著性注意. 聽覺顯著性注意模型這一概念最早由Kayser[5]等人提出, 模型流程如圖1所示, 該模型將聲音信號的語譜圖作為原始圖像輸入, 利用Itti模型的原理來提取語音信號的聽覺顯著性注意. 之后, Kalinli在Kasyer的基礎(chǔ)上, 在特征提取時增加了方向和基音特征, 并采用了不同的歸一化方法[6]. 隨后, Durk Talsma[7]等人開始研究視、聽覺關(guān)注機制與多種感知融合的交互影響, 試圖建立一個融合機制的統(tǒng)一框架.
根據(jù)以上的模型流程圖, 將語音信號的語譜圖完全作為視覺顯著性注意模型的輸入并提取相應(yīng)的特征,這樣做并未充分考慮到聽覺信號和視覺信號的差異,視覺顯著度突出的是二維區(qū)域的顯著度, 而聲音信號顯著度的重點則體現(xiàn)在時間和頻率維度的變化上. 為了有利于突出語音信號顯著度在時間和頻率維度上的變化, 本文將語譜圖的各個頻帶、各幀數(shù)據(jù)看作一個時間流, 來做相應(yīng)的處理, 具體處理算法如下.
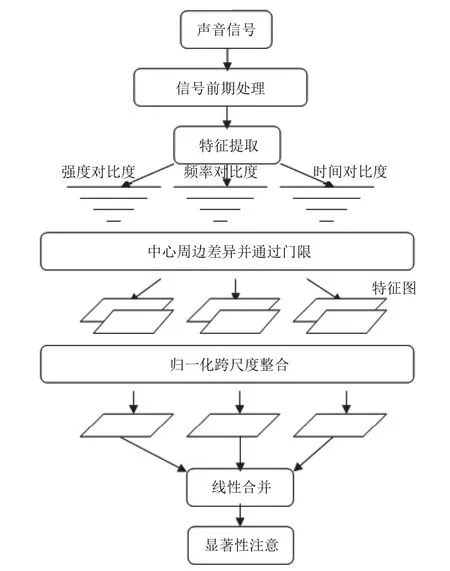
圖1 Kayser模型流程圖
首先將語音信號進行預(yù)處理、分幀、求得語譜圖Ptf, t表示幀數(shù). 再用24個不同帶寬的帶通濾波器將Ptf在頻率和時間上分別劃分為2 4個頻率通道和時間通道, 這24個帶通濾波器都為三角濾波器, 并且在梅爾頻率下是均勻分布的, 梅爾頻率與一般頻率f的關(guān)系為:
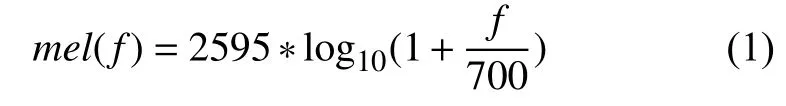
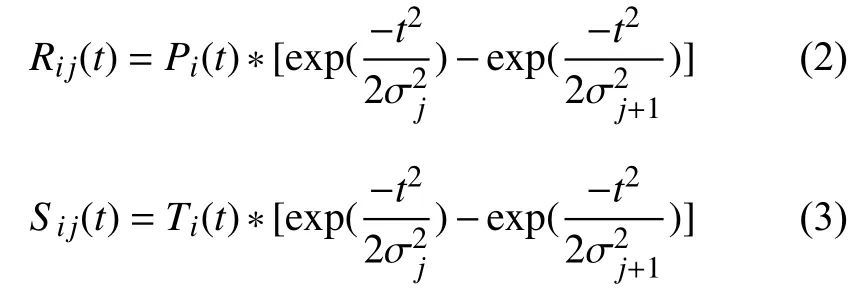
式中i=1, 2, 3, …, 24, σ1=2, σk+1=2×σk, k={1, 2, 3, 4, 5}.將每個頻率通道和時間通道不同層次的濾波結(jié)果分別線性合并得到按時間變化的聽覺顯著性注意模型RR和按頻率變化的聽覺顯著性注意模型SS.
其后合并RR和SS, 本文引用圖像方面的全局加強法. 全局加強法的優(yōu)點是加強突出注意目標貢獻大的特征而削弱貢獻小的特征. 具體策略是將各特征圖的特征值歸一化到同一個范圍內(nèi)后, 找出每一幅特征圖的全局極大M和除此全局極大之外的其他局部極大的平均值, 給每一幅特征圖乘以加強因子, 這就是每幅特征圖的權(quán). 這里的“全局”體現(xiàn)在將每幅特征圖的全局極大與其他活躍區(qū)的平均水平作比較, 差別越大, 權(quán)值就越大, 這種顯著性就更加被放大; 差別越小, 權(quán)值就越小, 該特征圖就越容易被忽略.
采用全局加強法合并RR和SS得到最終的自下而上聽覺顯著性注意模型REI為:
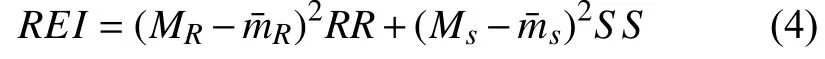
1.2 自上而下聽覺顯著性注意模型
本文的自上而下聽覺顯著性注意模型原理框圖如圖2所示.
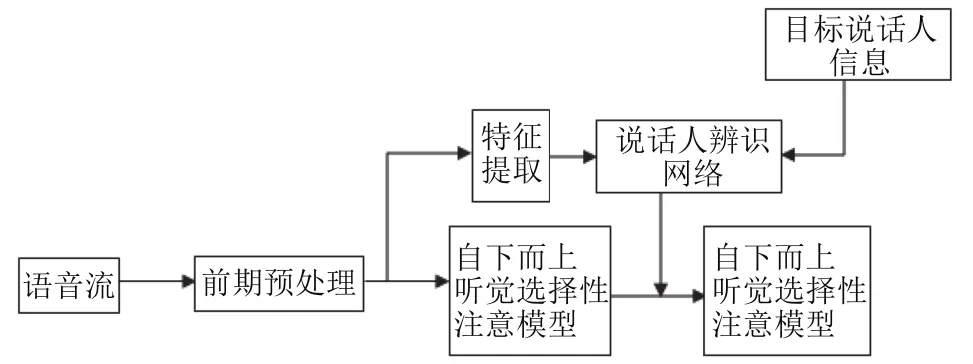
圖2 自上而下聽覺顯著性注意模型
該模型基于時間-頻率層面, 對語音流前期預(yù)處理之后, 首先采用本文提出的聽覺顯著性注意模型提取算法提取語音流的顯著性注意模型, 即得到自下而上聽覺顯著性注意模型, 然后將語音流前期處理之后提取的特征參數(shù)與目標說話人的信息一起輸入到說話人辨識網(wǎng)絡(luò)中進行說話人辨識, 通過識別結(jié)果即可知道哪些時間段是目標說話人的發(fā)音, 將辨識結(jié)果與語音流的自下而上顯著性注意模型線性合并, 即可得到自上而下的顯著性注意模型. 本文的語音特征提取采用普遍認為能夠體現(xiàn)人耳聽覺特性的梅爾倒譜系數(shù)(mfcc)作為特征參數(shù), 同時鑒于人體大腦結(jié)構(gòu)非常復(fù)雜以及人體耳朵特殊的生理結(jié)構(gòu), 在說話人辨識部分采用基于疊層自動編碼機作為基礎(chǔ)模塊的深度信念網(wǎng)絡(luò).
對上面的模型原理框圖進行分析, 該改進的模型對先驗信息有一定的依賴性, 本文先驗信息主要體現(xiàn)在聲源數(shù)量確定、噪聲為白噪聲、說話人語音信號沒有重疊等, 其優(yōu)點是可以顯著提高識別性能, 缺點是識別結(jié)果明顯偏向于模型中出現(xiàn)過的語音信號. 而現(xiàn)實聲源環(huán)境中是非常復(fù)雜的, 如聲源數(shù)量不確定、聲源信號方位信息也可能在實時發(fā)生變化、嘈雜的背景噪聲等多種可能性, 且這些先驗信息都是無法確定的, 因此, 在實際應(yīng)用中應(yīng)考慮大規(guī)模聲源信號的分離與識別, 同時多方面考慮影響語音信號特性的因素, 還要考慮識別過程中噪聲消除、語音增強、如何處理回音等多個方面的問題, 使得該模型在現(xiàn)實生活中得以應(yīng)用.
2 基于疊層自動編碼機的深度信念網(wǎng)絡(luò)說話人辨識
說話人辨識是說話人識別的一種, 即對目標說話人的識別過程, 識別技術(shù)目前主要有基于高斯混合模型(GMM)的說話人辨識系統(tǒng)[8]、利用因子分析的說話人辨識系統(tǒng)[9]、基于神經(jīng)網(wǎng)絡(luò)的說話人辨識系統(tǒng)[10]等.GMM、因子分析等方法并不能有效模擬人腦的識別過程, 對于神經(jīng)網(wǎng)絡(luò)的辨識系統(tǒng), 雖然能夠有效模擬人腦的神經(jīng)元, 但是由于人體大腦的結(jié)構(gòu)非常復(fù)雜, 所以普通神經(jīng)網(wǎng)絡(luò)一直得不到廣大研究者的滿足, 故深度多層的神經(jīng)網(wǎng)絡(luò)研究也就開始出現(xiàn)[11]. 隨著研究深入,Hinton等首先提出的深度信念網(wǎng)絡(luò)(Deep Belief Networks)[12], 采用多層結(jié)構(gòu)的DBN(由波爾茲曼模型(RBM)作為每層訓(xùn)練的基礎(chǔ)模塊)使得深度網(wǎng)絡(luò)在學(xué)習(xí)效率上有了突破性的進展. 之后不久, Bengio等發(fā)表文章把DBN的成功歸納為采用了逐層無監(jiān)督的預(yù)訓(xùn)練步驟(Layer-wise Unsupervised Pre-traning)[13]. 同時另外一種名叫自動編碼機(Autoencoders)的基礎(chǔ)模塊也被提出, 同樣取得了很好的學(xué)習(xí)效果. 通過理論比較分析DBN和自動編碼機的復(fù)雜程度和可實現(xiàn)性, 本文采用自動編碼機作為多層DBN的基礎(chǔ)模塊.
自動編碼機類似于一個含有單一隱含層的神經(jīng)網(wǎng)絡(luò), 共有3層, 其中隱藏層為數(shù)據(jù)的特征表達, 通過最小化輸入層與輸出層之間的誤差來校準網(wǎng)絡(luò)權(quán)值, 基本的結(jié)構(gòu)原理如圖3所示.
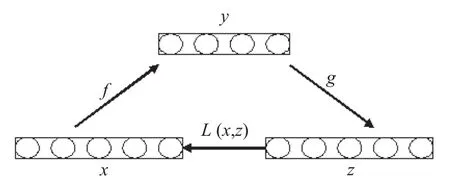
圖3 自動編碼機結(jié)構(gòu)原理圖
一般自動編碼機的算法: 自動編碼機的輸入向量為x, 該向量通過映射函數(shù)f映射到隱藏層, 表達式為y,即, 其中W為權(quán)值矩陣, b為偏置向量,. 之后, 中間層y通過映射函數(shù)g到輸出層, 表達式為z, 即, 其中W′可以通過限定使得, b′為偏置向量. 最后通過交叉熵函數(shù)來度量x與z的距離:
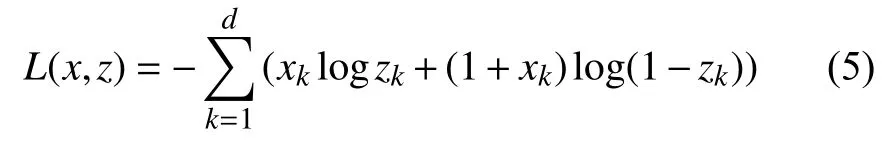
并通過反向傳播算法來更新網(wǎng)絡(luò)參數(shù).
由于自動編碼機只有一個隱藏層, 應(yīng)用到多層的神經(jīng)網(wǎng)絡(luò)的時候, 顯然是不合適的, 因此本文采用了疊層自動編碼機[14], 其結(jié)構(gòu)原理圖如圖4所示. 其基本思想就是每一層都用到自動編碼機的思想, 使其輸入經(jīng)過網(wǎng)絡(luò)后得到的輸出盡可能的逼近輸入. 與單層的自動編碼機相比, 一是疊層自動編碼機在自下而上的逐層訓(xùn)練過程中, 下層的特征可以作為上層的輸入繼續(xù)參加訓(xùn)練; 二是疊層自動編碼機能進行多層次的特征提取, 提高了網(wǎng)絡(luò)的整體表達能力. 總之, 通過疊層自動編碼機對網(wǎng)絡(luò)權(quán)值進行預(yù)訓(xùn)練, 能夠把網(wǎng)絡(luò)的權(quán)值限制在對后續(xù)訓(xùn)練有利的區(qū)域, 其后更有利于對網(wǎng)絡(luò)權(quán)值進行進一步的整體優(yōu)化調(diào)整.
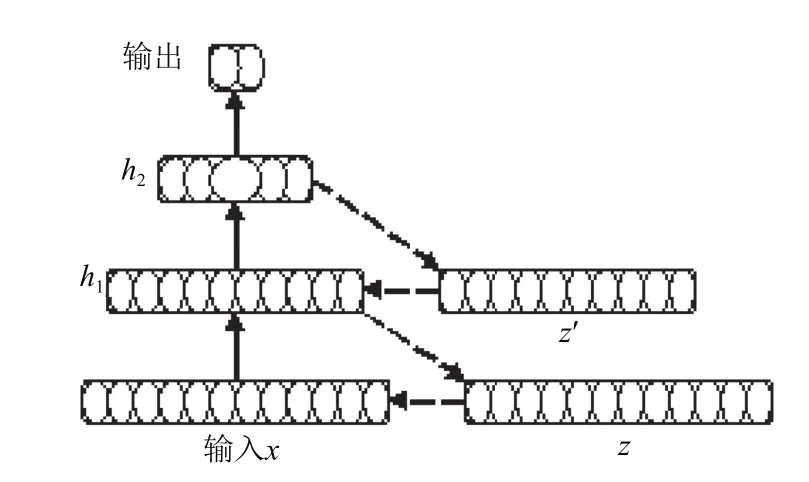
圖4 疊層自動編碼機結(jié)構(gòu)
以圖4的疊層自動編碼機的結(jié)構(gòu)原理圖為例, x為輸入數(shù)據(jù), 輸入端有12個神經(jīng)單元, 由于本文實驗部分的語音流是兩個說話人的交替發(fā)音, 所以輸出端使用了2個神經(jīng)單元, h1和h2分別為第一個和第二個隱藏層,神經(jīng)元個數(shù)分別為10和5. 本文在自上而下的逐層預(yù)訓(xùn)練中, 隱藏層h1對輸入數(shù)據(jù)通過自動編碼機訓(xùn)練, 得到的輸出結(jié)果作為隱藏層h2的輸入繼續(xù)訓(xùn)練, 完成預(yù)訓(xùn)練后, 網(wǎng)絡(luò)權(quán)值對所有實例抽取隱藏層的特征, 把這些特征作為上層自動編碼機的輸入繼續(xù)訓(xùn)練, 這樣逐層迭代, 就構(gòu)成一個深度信念網(wǎng)絡(luò). 在具體的訓(xùn)練過程中,層與層之間的權(quán)值更新都是局部的, 也就是說隱藏層h1和h2之間權(quán)值的更新相互并不產(chǎn)生任何影響, 這樣通過一層一層的訓(xùn)練, 使得每層的權(quán)值有一個初始值, 之后再根據(jù)具體需要采用方向傳播算法對權(quán)值進行整體調(diào)優(yōu), 即可實現(xiàn)具體的功能, 這樣做好處就是有效的防范了只采用方向傳播算法所造成的局部最優(yōu)問題.
3 實驗仿真
為了說明本文提出的自下而上聽覺顯著性注意模型方法具有可行性. 實驗一: 將頻率分別為1500 Hz和2000 Hz的正弦信號, 頻率從2500 Hz到7500 Hz以速率為800 hz/s變化的線性調(diào)頻信號和頻率從7500 Hz到2500 Hz以速率為-800 hz/s變化的線性調(diào)頻信號組合成一個測試信號, 采用本文提出的聽覺顯著性注意模型算法得到的信號顯著性注意和語譜圖如圖5所示.

圖5 測試信號語譜圖和聽覺顯著性注意
從圖5中可以看出, 調(diào)頻信號因為頻率在變化, 它的顯著性注意大致符合其語譜圖的走勢; 而正弦信號由于頻率恒定, 其顯著性注意在開始和結(jié)束的時候比較明顯, 而在中間部分比較弱, 這符合人耳的聽覺特性,故說明了本文提出的聽覺顯著性注意提取方法具有可行性.
實驗二: 我們從語料庫NIST中選取了兩個說話人(一男一女), 每人10句發(fā)音, 平均每句4 s長, 各自選取其中3句, 通過女-男-女的發(fā)音順序合成一個對話. 通過本文的聽覺顯著性注意模型方法, 得到其自下而上聽覺顯著性注意與頻譜圖的對比如圖6所示.
實驗三: 用每人另外的7句發(fā)音作為訓(xùn)練語音, 用來訓(xùn)練深度信念網(wǎng)絡(luò), 以男性作為目標說話人, 女性作為干擾說話人. 本文采用包含兩個隱含層的網(wǎng)絡(luò), 其中第一個隱藏層的節(jié)點數(shù)為10, 第二個隱藏層的節(jié)點數(shù)為5; 輸出層采用的兩個節(jié)點, 如果發(fā)音為男性的, 則理想輸出為[1, 0], 如果發(fā)音為女性的, 則理想輸出為[0,1]. 將待識別的語音流分幀, 幀長256, 提取特征參數(shù)送入訓(xùn)練好的網(wǎng)絡(luò)識別, 得到一個識別結(jié)果REC, 其中REC分布在是0到1之間的兩維矩陣, 因為此處男性作為目標說話人, 所以取REC的第一維參數(shù), 為其長度為幀數(shù). 考慮到實際的語音環(huán)境中, 耳朵不可能完全屏蔽掉非關(guān)注的語音流, 所以本文設(shè)定一個閥值0.6, 對于REC, 小于0.6的結(jié)果默認為0.01, 大于0.6的結(jié)果默認為1. 考慮到說話人辨識系統(tǒng)識別不可能100%成功, 且語音流中有靜音段, 即說話人說話中途的停頓, 以及說話人在發(fā)音時發(fā)音不會太短等問題, 將REC進行平滑處理. 平滑處理準則為: 一是如果為1的幀相連前后4幀都為0.01, 則這一幀也為0.01; 如果為0.01的幀相連前后4幀都為1, 則這幀為1; 二是如果多個連續(xù)1的長度小于20幀(由于目前聽覺注意顯著性模型結(jié)合說話人識別這方面的文獻較少, 對這個數(shù)值還有待研究, 所以本文通過觀察REC, 取為20幀), 則將其全部置0.01. 此時得到的REC已經(jīng)去除了語音流中的靜音段, 但是為了更好的刻畫某個說話人的發(fā)音段, 再將說話人發(fā)音中途的靜音段平滑, 最后結(jié)果如圖7所示.

圖6 語音流的自下而上聽覺顯著性注意與語譜圖
圖7中長黑線包含的部分為理想的目標說話人的發(fā)音段. 結(jié)合圖6中語音流的聽覺顯著性注意和圖7對目標說話人的識別結(jié)果可以得到目標說話人自上而下聽覺顯著性注意與語音流聽覺顯著性注意對比如圖8所示.
圖8說明通過深度信念網(wǎng)絡(luò)的說話人辨識技術(shù), 可以有效屏蔽語音流的聽覺顯著性注意中非目標說話人的部分, 凸顯目標說話人.
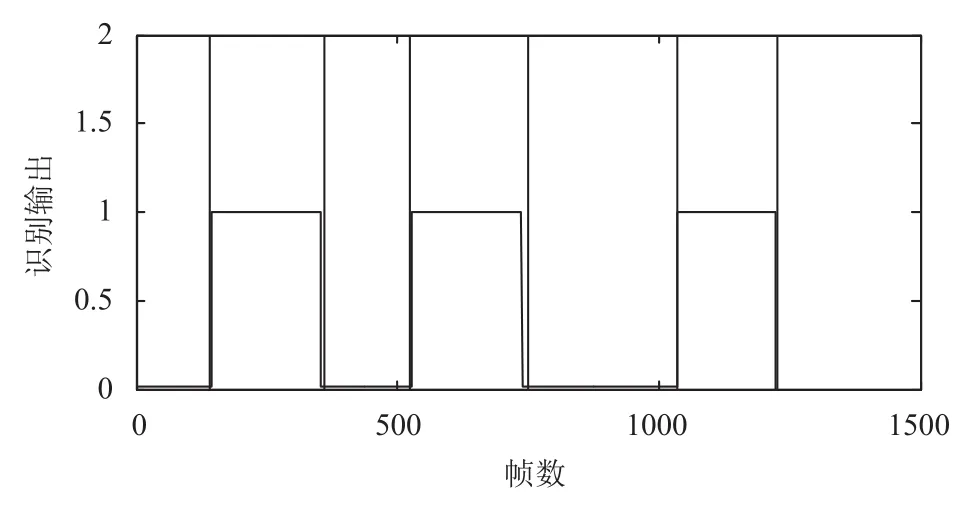
圖7 語音流的識別結(jié)果
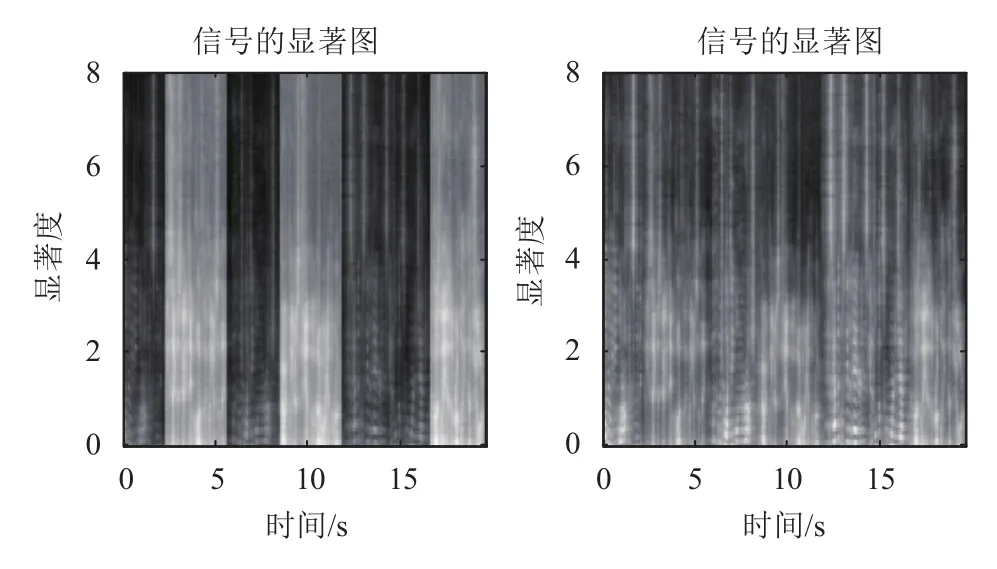
圖8 語音流的自上而下聽覺顯著性注意
4 結(jié)語
本文首先根據(jù)聽覺與視覺顯著性的差異性, 提出了一種基于時間變化的自下而上聽覺顯著性注意模型,該模型模擬人耳的聽覺特性, 對聲音按時間分頻率通道進行處理, 凸顯了聲音隨時間變化的差異. 其后與說話人辨識技術(shù)相結(jié)合設(shè)計出了自上而下聽覺顯著性注意模型, 該模型可以有效的屏蔽顯著性注意中非目標說話人部分. 仿真實驗表明: 本文提出的自下而上聽覺顯著性模型, 能夠很好的模擬人耳的聽覺特性, 在頻率恒定時, 關(guān)注度低; 而在頻率變化時, 關(guān)注度會隨頻率變化. 通過結(jié)合基于自動編碼機的深度信念網(wǎng)絡(luò), 能夠有效凸顯目標說話人的顯著度, 進一步體現(xiàn)聽覺注意神經(jīng)信息處理計算機制對聽覺場景內(nèi)容的自動分析與理解功能. 在以后的研究中, 我們希望在不知道整個語音流的時候, 可以實時的根據(jù)語音的進展提取出顯著性注意并辨識出目標說話人, 屏蔽其他非目標說話人,進而實時凸顯目標說話人的顯著性注意.
1Navalpakkam V, Itti L. Modeling the influence of task on attention. Vision Research, 2005, 45(2): 205–231. [doi:10.1016/j.visres.2004.07.042]
2Ainhoren Y, Engelberg S, Friedman S. The cocktail party problem [instrumentation notes]. IEEE Instrumentation &Measurement Magazine, 2008, 11(3): 44–48.
3王彤, 滕奇志, 唐棠. EBCOT圖像壓縮算法中若干問題的研究. 四川大學(xué)學(xué)報(自然科學(xué)版), 2009, 46(2): 395–400.
4Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. on Pattern Analysis and Machine Intelligence, 1998, 20(11):1254–1259. [doi: 10.1109/34.730558]
5Kayser C, Petkov CI, Lippert M, et al. Mechanisms for allocating auditory attention: An auditory saliency map.Current Biology, 2005, 15(21): 1943–1947. [doi: 10.1016/j.cub.2005.09.040]
6Kalinli O, Narayanan S. A saliency-based auditory attention model with applications to unsupervised prominent syllable detection in speech. 8th Annual Conference of the International Speech Communication Association. Antwerp,Belgium. 2007.
7Talsma D, Senkowski D, Soto-Faraco S, et al. The multifaceted interplay between attention and multisensory integration. Trends in Cognitive Sciences, 2010, 14(9):400–410. [doi: 10.1016/j.tics.2010.06.008]
8Kenny P, Boulianne G, Ouellet P, et al. Speaker and session variability in GMM-based speaker verification. IEEE Trans.on Audio, Speech and Language Processing, 2007, 15(4):1448–1460. [doi: 10.1109/TASL.2007.894527]
9李軼杰, 郭武, 戴禮榮. 話者識別的信道補償. 小型微型計算機系統(tǒng), 2008, 29(12): 2344–2347.
10Bengio Y. Learning deep architectures for AI. Foundations and Trends?in Machine Learning, 2009, 2(1): 1–127. [doi:10.1561/2200000006]
11Bengio Y, LeCun Y. Scaling learning algorithms towards AI.Bottou L, Chapelle O, DeCoste D, et al. Large-Scale Kernel Machines. Cambridge, London. 2007. 321–359.
12Hinton GE, Osindero S, Teh YW. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527–1554. [doi: 10.1162/neco.2006.18.7.1527]
13Le Roux N, Bengio Y. Representational power of restricted boltzmann machines and deep belief networks. Neural Computation, 2008, 20(6): 1631–1649. [doi: 10.1162/neco.2008.04-07-510]
14Bengio Y, Lamblin P, Popovici D, et al. Greedy layer-wise training of deep networks. Advances in Neural Information Processing Systems, 2007, (19): 153–160.
Top-Down Auditory Saliency Attention Model Based on Speaker Identification
YE Yu-Lin1, YANG Bo2, MO Jian-Hua1, LIU Xia1
1(78438 Troops of the Chinese People’s Liberation Army, Chengdu 610066, China)
2(68108 Troops of the Chinese People’s Liberation Army, Lanzhou 730030, China)
In order to reflect the automatic analysis and understanding of the auditory scene content by the auditory attention neural information processing computational mechanism , this paper presents a top-down extraction model of the auditory saliency attention, based on the perceptual characteristics of human ear to frequency transformation, and combined with the speaker identification using the depth belief network and the auditory significant model. The simulation results show that the proposed model is feasible, and it can effectively highlight the significant degree of the target speaker in the speaker identification technology using the depth belief network.
auditory saliency attention; extraction model of saliency attention; depth belief network; speaker identification
葉于林,楊波,莫建華,劉夏.基于說話人辨識的自上而下聽覺顯著性注意模型.計算機系統(tǒng)應(yīng)用,2017,26(7):252–257. http://www.c-sa.org.cn/1003-3254/5814.html
2016-10-11; 收到修改稿時間: 2016-11-14
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學(xué)學(xué)報(2015年3期)2015-11-11 17:20:00
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
