Xen的I/O虛擬化性能分析與優化①
2017-07-19 12:27:20章建雄閻燕山
計算機系統應用 2017年7期
關鍵詞:設備
劉 佩, 章建雄, 馬 鵬, 閻燕山
1(華東計算技術研究所, 上海 200000)
2(中國航空無線電電子研究所615所, 上海 200241)
Xen的I/O虛擬化性能分析與優化①
劉 佩1, 章建雄1, 馬 鵬1, 閻燕山2
1(華東計算技術研究所, 上海 200000)
2(中國航空無線電電子研究所615所, 上海 200241)
在Credit算法應用中, 由I/O事務喚醒的VCPU處于最高優先級BOOST狀態, 優先搶占PCPU資源, 使I/O操作的響應速度提高, 但多個虛擬機同時進行I/O操作時, 會引起較長延時和公平性原則被破壞問題. 針對這個問題, 研究分析SEDF算法、Credit算法、Credit2算法, 提出L-Credit調度算法解決多個虛擬機同時進行I/O操作引起響應延遲的問題. 通過監測I/O設備環共享頁面中響應和請求的個數的方法, 對處于BOOST狀態下I/O操作進一步細化排序, 使稀疏型I/O操作較密集型I/O操作先調用執行. 通過對L-Credit算法與Credit算法在同一應用場景下反復對比實驗, 得出L-Credit算法可以提高I/O響應性能, 并且繼承了Credit算法負載均衡和按比例公平共享的特點.
I/O虛擬化; Credit; SEDF; Credit2; L-Credit
虛擬化技術是云計算中最關鍵、最核心的技術原動力[1]. 云計算的提出推動了系統虛擬化技術的發展,而虛擬化的層次將決定虛擬機性能[2]. 虛擬化技術的研究方向主要分為: CPU虛擬化、內存虛擬化和I/O虛擬化[3], 其中CPU虛擬化的核心問題是如何保證VCPU(virtual CPU)的正確執行; 內存虛擬化的核心問題是如何利用分塊共享的思想來虛擬計算機的物理內存;I/O虛擬化的核心問題是如何協調多個虛擬機對同一套硬件硬件設備的應用同時保證I/O操作的實時性、正確性. Intel和AMD先后分別推出了Intel VT(Virtualization Technology)和AMD VT產品[5], 很大程度上解決了CPU虛擬化和內存虛擬化問題. 而I/O設備虛擬化由于I/O設備具有異構性強、內部狀態不易控制的特點, 成為虛擬化的技術難點之一. 虛擬機是系統級虛擬技術的應用平臺, 其中Xen虛擬機管理器VMM是一個完全開源項目, 具有較好的兼容性和運行效率, 在學術界和業界受到廣泛重視[2]Xen. 在過去十幾年時間中, 對VCPU調度算法不斷的優化改進, 按照時間排序: BVT算法、SEDF算法、Credit算法、Credit2算法, 目前最新版的Xen虛擬機的默認算法為Credit算法, Credit2算法目前還在實驗階段[4].
本文以Xen虛擬機管理器為基礎, 通過對VCPU調度算法: SEDF、Credit、Credit2調度算法研究分析, 提出一種新的調度算法L-Credit算法, 用于解決多臺虛擬機同時進行I/O操作時, 存在的I/O操作延時長和公平性原則被破壞等問題.
1 Xen虛擬機結構分析
在Xen系統中, 存在一個輕量級的軟件層虛擬機管理器(VMM或Xen Hypervisor), 向運行在它之上的虛擬機提供虛擬硬件資源, 同時分配和管理這些資源, 并保證虛擬機之間的相互隔離[3]. 虛擬機則稱之為域(Dom).虛擬機管理器VMM存在于操作系統與硬件之間, 主要作用是為運行的操作系統內核提供硬件環境. Xen采用混合模式, 設置一個Dom為特權域Dom0, 其它域稱之為DomU. Dom0用于輔助Xen管理其他域DomU, 提供相應的虛擬資源服務, 特別是DomU的I/O操作.
根據VMM向虛擬機提供硬件資源的方式, Xen虛擬化方式分為FV(Full Virtualization)、PV(Para-Virtualization)、HAV(Hardware Assisted Virtualization).因為結構特點, FV技術雖然可以向虛擬機虛擬出和真實硬件完全相同的硬件環境, 以及給虛擬機提供完整的硬件支持服務, 但對于I/O設備而言, 仍然是基于PV環境開發的前后端驅動模式, 因此, 最初的Xen完全虛擬化需要使用Qemu來仿真計算機硬件, 其I/O設備的性能比PV技術要低. 而HAV技術需要CPU支持Intel-VT技術或者AMD-V技術. 對比而言, PV技術實現的I/O虛擬化性能更優良和方便.
以PV為例對Xen的I/O虛擬化過程進行說明. 如圖1所示, 在Xen系統中, I/O操作采用的是前后端(Frontend-Backend)I/O技術, 其中前端設備驅動(Frontend Device Driver)位于DomU中將I/O請求發送給位于Dom0的后端設備驅動(Back-end Device Driver), 在由后端設備驅動接收I/O請求, 權限檢查, 通過之后交由原生設備驅動. Dom與VMM之間的數據傳輸采用的是基于循環隊列結構的生產者消費者模型. 接收操作系統指令的傳遞, 是由Xen為每個Domain建立的VCPU完成. VCPU的調度算法對于I/O虛擬化的性能有著決定性的影響. 在Xen中, 關于VCPU的調度算法主要有SEDF調度算法、Credit調度算法、Credit2調度算法.
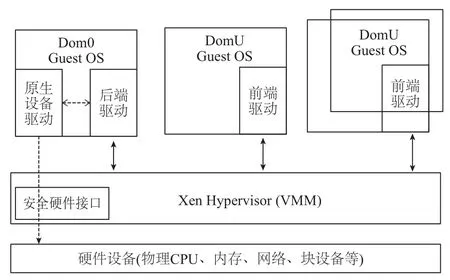
圖1 Xen半虛擬化結構圖
2 算法分析
I/O虛擬化技術的性能主要體現在實時性、負載均衡等特性上. SEDF算法可以在單核應用場景中保證I/O操作的實時性; Credit算法可以在多核應用場景中很好實現I/O虛擬化的負載均衡特性; Credit2算法結合Credit算法在多核應用場景中保證負載平衡的基礎上,解決了I/O虛擬化操作的延時性等問題, 但是帶來了緩存壓力過大的問題.
2.1 SEDF算法
SEDF算法是一種動態優先調度算法, 最初為每個VCPU進行初始化時設置一個截止期限. 截止期限最早的VCPU在VCPU調度時具有較高的優先級會優先調用. SEDF算法通過設置參數(s, p, x)控制VCPU的運行,其中s指代時間片, p指代周期時間, x是布爾值. 在時間p內, 設置的VCPU至少可以獲取s單位的CPU運行時間.x值代表額外的CPU運行時間(p-s)是否可以繼續持有.調度器中維護一個可運行隊列和一個等待隊列, 可運行隊列中按照截止期限順序保存當前周期仍有運行時間的隊列, 等待隊列中保存當前周期運行時間已消耗完VCPU, 并結合x參數以及截止時間依次排列. 每次調度時, 處理器獲取運行隊列中的頭元素進行調度. 假設系統中存在兩個VCPU, 初始化時設vcpu1(2, 7, 1)、vcpu2(1, 9, 0), 如圖2, vcpu1的截止時間是第5個時刻,vcpu2的截止時間是第8個時刻, 按照算法的優先原則,vcpu1先被調度執行, 執行2個時間單位, 接著調度執行vcpu2, 執行1個時間單位. 那么在時刻3處, vcpu1和vcpu2調度完成, 那么剩余的時間CPU處的狀態由x決定, x都為0時, 代表周期剩余的時間是不能被VCPU使用, CPU處于idle狀態. 若x為1, 代表剩余周期的時間,被某VCPU使用. 由于vcpu1中x=1, 代表剩余周期vcpu1將占用CPU, 直到有新的VCPU被釋放.
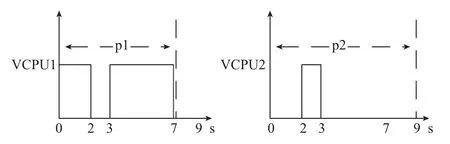
圖2 SEDF算法示例
SEDF算法在負載較輕時, 處理器利用率很高, 但是當多個負載超過50%時, 會導致有些進程錯過截止時間, 忽略執行, 對性能有很大影響. 而且算法只能對單個CPU進行SEDF調度, 不能夠進行多個CPU之間的負載平衡操作.
2.2 Credit算法
Credit調度算法是以VCPU調度為單位, 在調度過程中, 每個VCPU都包含兩個配置參數: weight(VCPU的權重)和cap(VCPU能運行的時間的上限). 由weight決定參數Credit(VCPU能夠運行的時間)的值, 當VCPU被調度過程中credit值會減少. Xen4.1虛擬機之后, 每個VCPU包含了3種運行狀態: BOOST、UNDER、OVER.UNDER狀態: 當VCPU處于正常等待運行并且credit值不為負時, VCPU處于UNDER狀態. OVER狀態: 只要當credit值為負時, VCPU切換為OVER狀態, 不再被調用執行. BOOST狀態: 當被事件喚醒的虛擬機具有較高的優先級時, VCPU進入BOOST狀態, 如果當前運行的VCPU為UNDER狀態, 就搶占執行, 如圖3所示. 若當前運行狀態為BOOST時, 按照隊列先到先得的規則執行.
Credit調度算法在執行調度時, 只關心VCPU所處狀態, 按照被調度的優先級由高到低排序, 依次是BOOST狀態、UNDER狀態、OVER狀態. Credit算法為每個物理CPU維護一個運行隊列, 按照先后順序依次是BOOST、UNDER、OVER 3個區域. 每個區域內的VCPU按照先后順序排列, 按照隊列的特性, 每10 ms(一個時間片)響應一次中斷, 執行選擇隊列第一個VCPU運行并且消耗credit值. 如果被調用VCPU的credit值為負處于OVER狀態, 那么它將不再被繼續執行, 重新計算credit值, 重新調度隊列VCPU. 若進行了3個時間片, 一直執行VCPU的credit值仍為非負值, 中止調度運行, 重新計算credit值, 重新調度隊列VCPU.系統每隔10 ms會中斷一次, 當前正在運行的VCPU會被消耗100個credit值, 當所有的credit值得總和為負, 按照比例加速最初設置的weight值. 如果某個VCPU的credit值累積到一定值域, 將其減半, 然后處于睡眠狀態.
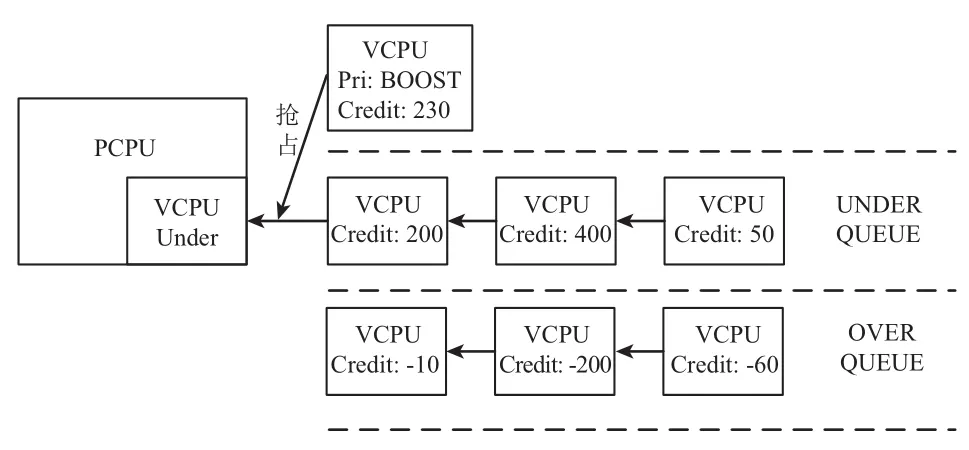
圖3 Credit算法運行狀態
加入了BOOST狀態的Credit算法大大降低了響應延遲平均值, 提高了虛擬I/O操作性能. 但是當多臺虛擬機同時運行I/O操作時, 它們按照虛擬機的優先權限都被設置為BOOST狀態, 而按照同一狀態模式下, 執行順序按照先到先得服務機制, 會造成很長延遲和公平性原則的破壞.
2.3 Credit2算法
Credit2算法任然沿用Credit算法參數weight和credit. 此時weight含義是credit值消耗速度, weight值越高消耗速度越慢. Credit2調度算法任然采用隊列去組織所有VCPU, 但是沒有按照優先級狀態處理VCPU.在Credit算法各個狀態的隊列排序不會關心credit值大小, 但是Credit2算法中會按照credit值由大到小進行隊列排序. 當有新的VCPU加入時, 會隊列進行從頭到尾的遍歷, 按照credit值大小插入合適的位置, 然后選擇CPU選擇隊頭元素進行運行, 如圖4所示. 當處于隊列中的下一個vcpu值是小于或者等于零時, credit命令是reset, 意味著, 此時每個vcpu的credit值減去最小值, 然后加上固定的credit值.
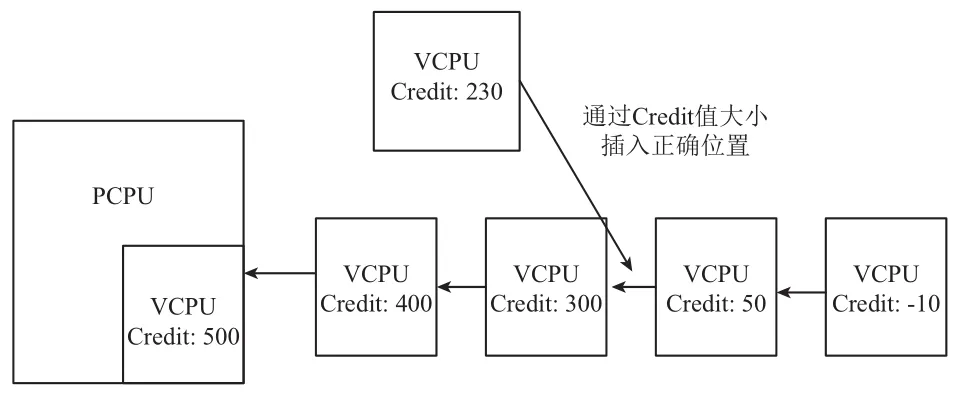
圖4 Credit2算法運行狀態
對于I/O虛擬化來說, I/O操作相比于其它任務占用的CPU資源較少, 會優先運行, 而且在同樣是I/O請求的情景下, 對于稀疏型I/O任務會優先運行, 解決了Credit算法產生的多個I/O操作同時進行時, 延遲和公平性原則得破壞的問題, 但是由于頻繁的切換, 同時大大的增加了緩存的壓力, 目前Credit2算法仍處于改進與測試中, 還沒有被設定為Xen默認的調度器.
3 算法優化
3.1 算法優化的基本思想
通過對SEDF算法、Credit算法、Credit2算法分析比較, 針對解決虛擬機I/O操作延時問題, 在Credit算法的基礎上可以根據喚醒VCPU的事件類型, 密集型I/O操作或者稀疏型I/O操作, 進一步細分排序BOOST狀態下VCPU. 根據Xen結構的I/O操作結構特點,Xen采用設備分離的策略如圖5, 原生的設備驅動存在于特權域Dom0中同時還包含后端設備驅動, 在DomU中存在的是前端設備驅動. 前端驅動通過環形隊列緩沖區、授權表以及事件通道與后端驅動進行交互.當虛擬機的某個操作系統要發起I/O操作時, 首先前端驅動建立通信鏈接, 分配一個空閑頁面作為I/O設備環、分配授權表引用并在Xenstore中存放、分配允許后端驅動連接的未被綁定的事件通道, 然后后端通信建立鏈接, 從Xenstore中讀取前端提供的授權表引用、映射到I/O設備環的共享頁面、獲取前端綁定的事件通道. 整個過程在分離設備驅動的共享內存中實現, 交換請求和響應, 然后通過事件通道進行異步通知, 每個域都有各自的I/O設備環. 而且操作系統允許將一系列類似I/O請求形成請求隊列, 然后發送一個Hypercall, 使Xen以批量的方式來接受和響應請求[3]. 在I/O設備環的代碼實現過程中, 定義了三種結構體, 共享環頁面結構體、前端私有變量結構體、后端私有變量結構體如,表1和表2所示. 通過獲取結構體元素nr_ents知道共享頁面中響應和請求的個數, 這個將作為條件加入到新算法L-Credit算法中.
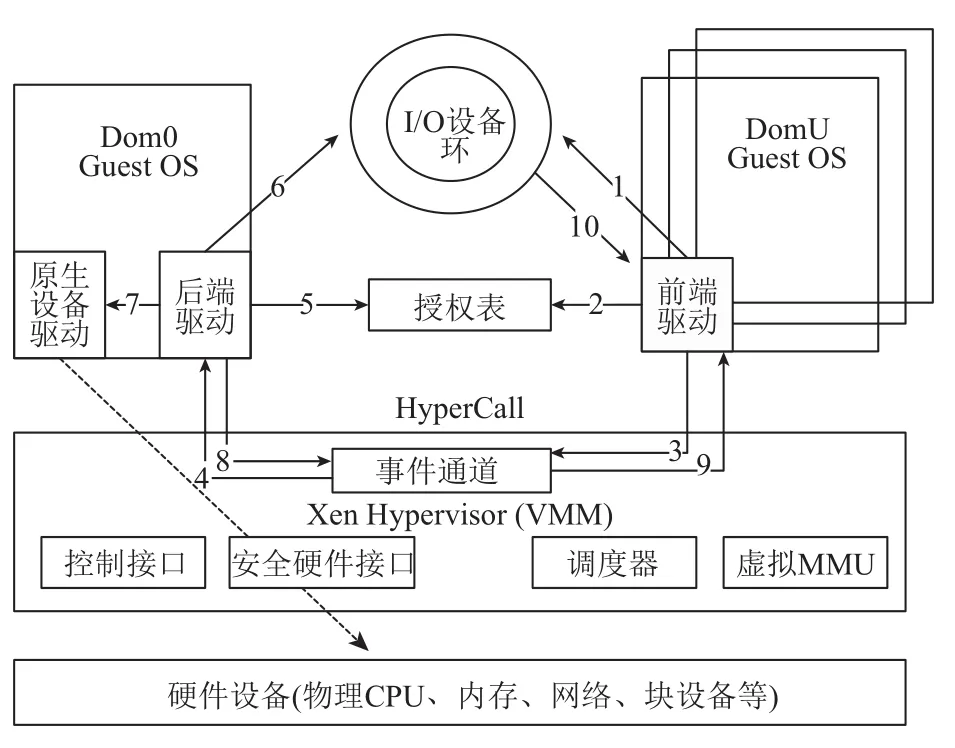
圖5 I/O設備環

表1 前端私有變量結構體

表2 后端私有變量結構體
3.2 優化算法L-Credit
Credit算法的特點在于VCPU可以有三個運行狀態BOOST、UNDER、OVER, 其中處于BOOST狀態的VCPU優先被CPU調度執行. 而Credit算法中I/O操作的VCPU處于最高優先級BOOST, 確實降低了響應延遲平均值, 提高了虛擬I/O性能, 但是當面臨多個I/O操作同時進行時, 它們按照虛擬機的優先權限都被設置為BOOST狀態, 而按照同一狀態模式下, 執行順序按照先到先得服務機制, 會造成很長延遲和公平性原則得破壞. 為了解決這個問題L-Credit算法可以加入一個新的運行順序標準: 當VCPU被新的事務喚醒時, 在Credit算法對于事務優先等級的劃分進行隊列排序基礎上, 在優先等級同樣為BOOST狀態時, 通過判斷當前域中, 對應的共享頁面中響應和請求的個數對VCPU進行排序,使處于BOOST狀態的VCPU調度順序進行進一步細分,數目少的先調度執行, 數目相同時任選一個調度執行,從而達到區分發起的I/O事務是屬于稀疏型還是密集型操作的目的, 保證稀疏型I/O操作先于密集型I/O操作先被調度執行, 如圖6所示, 部分代碼如下文所示.
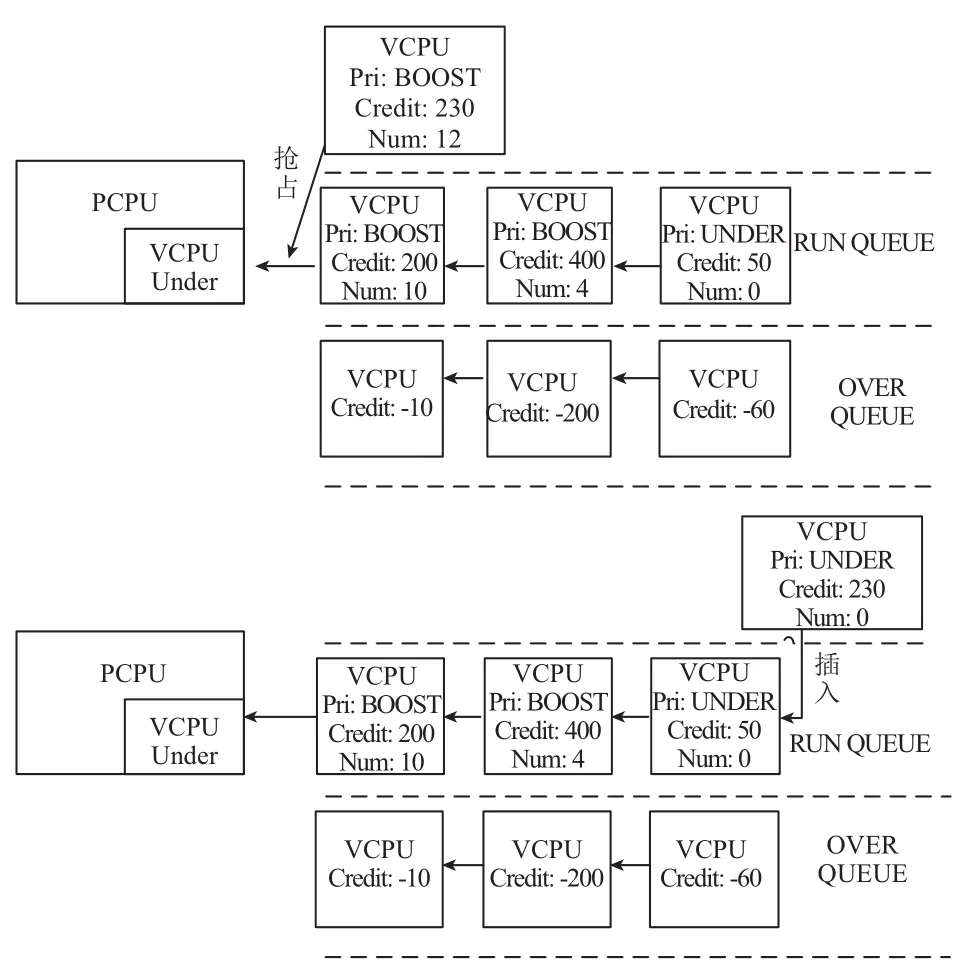
圖6 L-Credit算法運行圖

L-credit算法的實現主要分為四個部分: Sburn_credit、runq_insert、runq_elem、Csched_load_balance,如圖7所示. 在runq_insert加入compare監控函數, 用于獲取VCPU之間共享頁面中響應和請求的數值, 根據返回整數值作為同一優先級BOOST狀態的操作排序依據. Compare監控函數偽代碼如下:

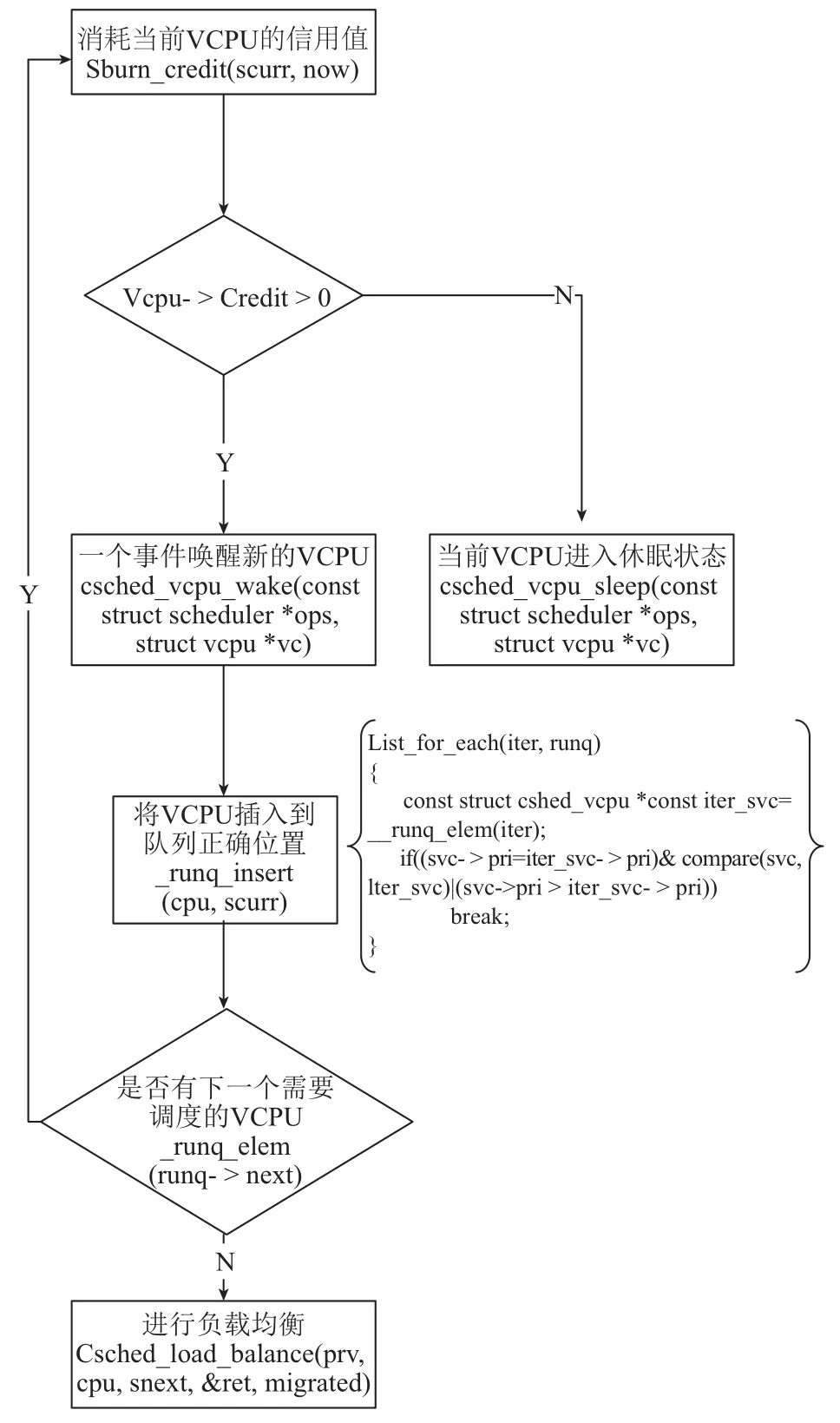
圖7 L-Credit算法結構


Sburn_credit消耗信用值, 設Cs(P)為每個PCPU更新時全部可分配的credit值, Ws(P)為PCPU對應所有VCPU全部weight值之和, 且每個域的VCPU數相同, 若第k個域對應的weight值為Wk(P), 那么第k個域第i個VCPU每次更新時可分配的credit值為ΔCki(P), 滿足:
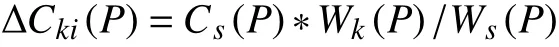
4 L-Credit實驗結果分析
為驗證L-Credit算法性能, 搭建測試環境如下:
硬件平臺: thinkpad服務器, 處理器Inter Core i3 CPU, 內存 4GB, CPU工作頻率: 2.4GHZ
軟件平臺: 安裝Xen4.4.2版本開源Xen虛擬機管理器, 特權域Dom0為系統Ubuntu 14.04, 其它3個域DoumU系統Ubuntu 13.1, 使用iozone命令模擬I/O操作,iostate命令用于實時監控每個I/O請求處理的平均時間及其它信息.
實驗場景: 分別就經典算法Credit和L-Credit算法進行比較, 在Dom0中進行稀疏型I/O操作, DomU進行I/O密集型操作, 運行iozone命令產生對應的I/O操作,iostate命令用于實時監控每個I/O請求處理的平均時間.
操作:
(1)開源Xen虛擬機管理器VCPU調度算法選擇:Credit調度算法和L-Credit調度算法二選一, 進行實驗比較.
static const struct scheduler *schedulers[] = {
&sched sedf_def,
&sched credit_def,
&sched credit2_def,
&sched l-credit_def,
};
/*選擇Credit調度算法作為VCPU調度算法*/
static char __initdata opt_sched[10] = “credit”;
/*選擇L-Credit調度算法作為VCPU調度算法*/
static char __initdata opt_sched[10] = “l-credit”;
string_param(“sched”, opt_sched);
(2) 進行I/O讀寫測試, 測試文件大小是128 M, 記錄塊從2 K到8 M, 并將測試數據輸出到Excel文件中
命令行: /opt/iozone/bin/iozone -a -s 128 m -i 0 -i 1 -f /tmp/testfile -y 2k -q 8m -Rb output.xls
(3) 進行I/O操作的實時監控
命令行: iostat -d -x -k 1 10
其中, await(ms): 每一個I/O請求的處理的平均時間; svctm(ms): 表示平均每次設備I/O操作的服務時間;%util: 在統計時間內所有處理I/O時間, 除以總共統計時間. 如果svctm的值與await很接近, 表示幾乎沒有I/O等待, 如果await的值遠高于svctm的值, 則表示I/O隊列等待太長.
(4) 多次重復測試, 實驗結果統計如圖8、圖9和圖10所示.
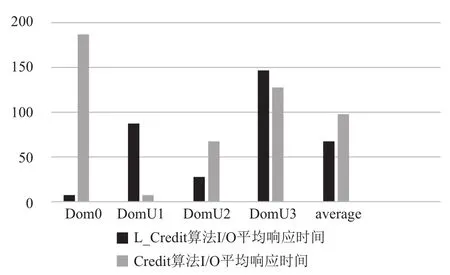
圖8 Credit算法出現最壞情況下I/O平均響應
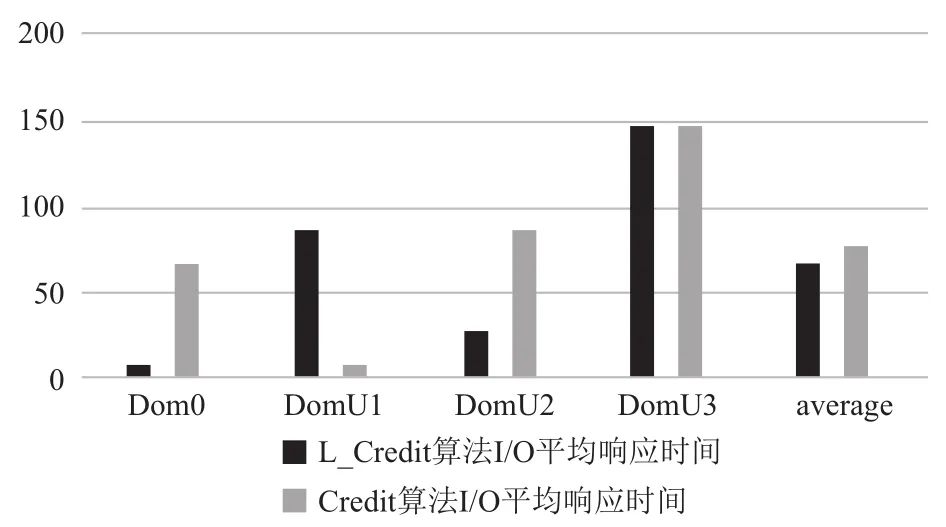
圖9 Credit算法與L-Credit算法平均響應
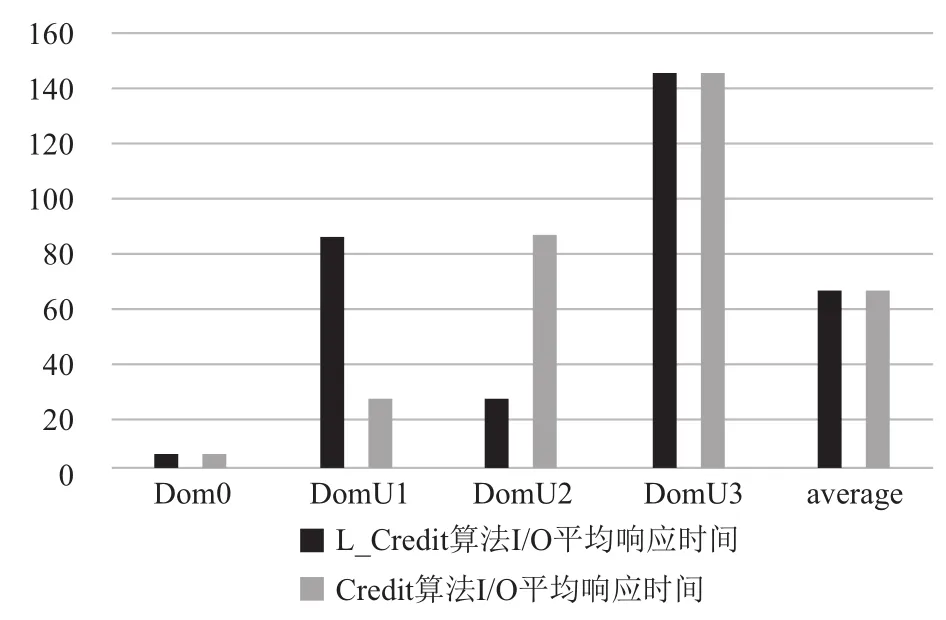
圖10 Credit算法出現最好情況下I/O平均響應
設Tdl為延時響應時間長度, Tslice為時間片長度,Tprd為VCPU被搶占前使用CPU的時間長度. 而在Credit算法下, 喚醒VCPU的I/O事件到達后, 若同一時間沒有其他的I/O操作產生既VCPU處于非阻塞狀態,那么I/O事件的響應將等待PCPU對其的調度, 由Tdl值由Tslice和隊列中的VCPU數目決定. 對于I/O事務類型,稀疏型I/O操作所耗費時間一定要小于I/O密集型操作所耗費時間既value_min=Tslice. 根據Credit算法的特點,當同時出現多個I/O操作時, 會發生阻塞, 最壞的情況是I/O稀疏型操作在所有密集型I/O操作完成之后才被PCUP調度執行, 在本次實驗場景中, Credit算法可能出現最壞情況如圖11所示, 按照執行先后順序Tdl=Tprd1+Tslice1+Tslice2+Tslice3, 實驗結果如圖8所示. Credit算法可能出現最好的情況是稀疏型I/O操作最先被執行如圖12所示,按照執行先后順序Tdl=Tprd0+Tslice.+Tslice1+Tslice2, 實驗結果如圖10所示. 改進之后的L-Credit算法, 在同時發生多個I/O操作事件時, 可以自主的讓I/O稀疏型任務先執行如圖12所示, 實驗結果如圖8、9和10所示, 能夠確保減少平均響應時間.
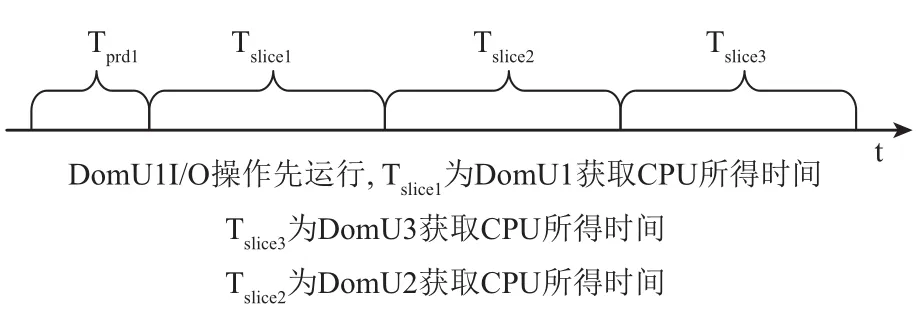
圖11 最壞情況下時間延遲
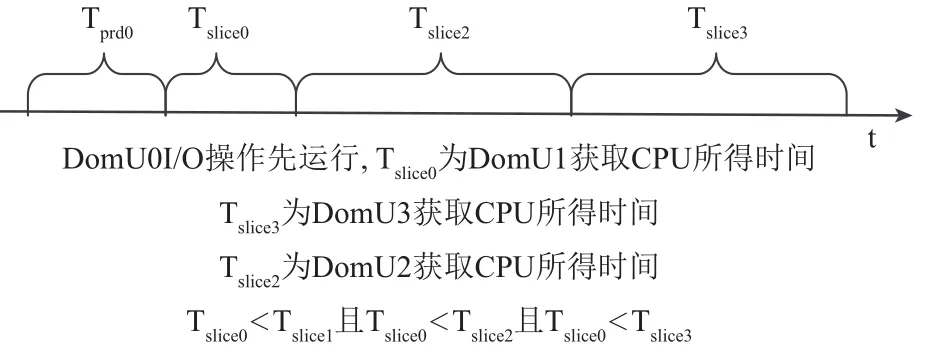
圖12 最好情況下時間延遲
5 結束語
本文主要對Xen虛擬機相關的VCPU調度算法(Credit、Credit2、SEDF調度算法)進行了研究分析, 新提出的L-Credit調度算法相比于Credit調度算法, 增加了compare(struct csched_vcpu *vcpu1, struct csched_vcpu*vcpu2), 用于對處于同一BOOST狀態的VCPU隊列進一步細分排序, 解決多個I/O操作同時進行時, 延遲和公平性原則得破壞的問題. 在未來的工作中, 對Credit算法與L-Credit算法在多核處理器應用場景下, 對同時發起I/O操作的虛擬機數目依次進行增加,進行重復試驗, 對L-Credit算法進一步驗證.
1惠新忠. Xen虛擬I/O優化策略[碩士學位論文]. 大連: 大連理工大學, 2010.
2丁曉波, 馬中, 戴新發. 面向響應延遲的虛擬機動態時間片調度算法. 計算機工程, 2015, 41(7): 11–16, 24.
3石磊, 鄒德清, 金海. Xen虛擬化技術. 武漢: 華中科學技術大學出版社, 2009.
4Hnarakis R. In Perfect Xen, A Performance Study of the Emerging Xen Schedule. Califormia: Califormia Polytechnic State University, 2013.
5胥平勇. 基于緩存關聯的Xen虛擬機調度優化[碩士學位論文]. 南京: 南京大學, 2012.
6廣小明. 虛擬化技術原理與實現. 北京: 電子工業出版社,2012.
7張天宇, 關楠, 鄧慶緒. Xen虛擬機Credit調度算法的實時性能分析. 計算機科學, 2015, 42(12): 115–119.
8Hess K, Newman A. 虛擬化技術實戰. 徐炯, 譯. 北京: 人民郵電出版社, 2012.
9鄭興杰. 基于SMP架構的半虛擬化CPU調度算法研究[碩士學位論文]. 哈爾濱: 哈爾濱工程大學, 2009.
10黃漾. 多核平臺下XEN虛擬機動態調度算法研究. 計算技術與自動化, 2014, 33(3): 84–87.
11宋聿, 蔣烈輝, 董衛宇, 等. 一種獨立式I/O虛擬化方法研究.計算機工程, 2014, 40(10): 81–85. [doi: 10.3969/j.issn.1000-3428.2014.10.016]
12李瑩瑩, 喬平安. 云環境下網絡I/O虛擬化的研究與改進.計算機與數字工程, 2015, 43(4): 684–688.
13王凱, 候紫峰. Xen虛擬機的虛擬CPU松弛協同調度方法.計算機研究與發展, 2012, 49(1): 118–127.
14張燦群. Xen虛擬CPU調度算法的研究與改進[碩士學位論文]. 武漢: 華中科技大學, 2012.
15顧振宇, 張申生, 李曉勇. Xen中Credit調度算法的優化. 微型電腦應用, 2009, 25(2): 1–3.
16葉漢民, 宋子航. 數據包聚合算法提高云計算環境下的網絡I/O虛擬化. 計算機應用與軟件, 2016, 33(1): 127–130,133.
17郭御風, 郭誦忻, 鄧宇. 眾核處理器中硬件支持的I/O虛擬化優化技術研究. 計算機科學, 2012, 39(1): 299–304.
18李超. SR-IOV虛擬化技術的研究與優化[碩士學位論文].長沙: 國防科學技術大學, 2010.
19王彤. Xen虛擬機調度算法的實時性能研究[碩士學位論文]. 沈陽: 東北大學, 2014.
20張文濤. 基于I/O性能的虛擬機資源調度算法研究[碩士學位論文]. 武漢: 華中科技大學, 2013.
21陳慧星. 多核環境下虛擬機調度算法研究[碩士學位論文].長沙: 湖南大學, 2013.
Performance Analysis and Optimization on I/O Virtualization of Xen
LIU Pei1, ZHANG Jian-Xiong1, MA Peng1, YAN Yan-Shan2
1(East China Institute of Computer Technology, Shanghai 200000, China)
2(China Aeronautical Radio Electronics Research Institute, Shanghai 200241, China)
In the application of Credit algorithms, the VCPU awakened by the I/O transaction is in the highest priority BOOST state, which gives it priority to gain access to the PCPU resources and improves the response speed of the I/O operation, but that will cause long time delay and destroy fairness principle, when multiple virtual machines are doing the operation of I/O at the same time. To solve this problem, SEDF algorithm, Credit algorithm, Credit2 algorithm are analyzed and L-Credit scheduling algorithm is proposed to reduce the response delay caused by multiple virtual machines’concurrent I/O operation. By monitoring I/O device ring sharing page to get the number of requests, which can further refine the sort in the I/O state BOOST operation, so that sparse type I/O operation can the implementation before the I/O intensive operations. According to the comparison report of the L-Credit algorithm and Credit algorithm in the same application scenario experiment, L-Credit algorithm can improve the performance of the I/O response, and inherits the Credit algorithm load balance and the characteristics of proportional fair sharing.
I/O virtualization; Credit; SEDF; Credit2; L-Credit
劉佩,章建雄,馬鵬,閻燕山.Xen的I/O虛擬化性能分析與優化.計算機系統應用,2017,26(7):10–16. http://www.c-s-a.org.cn/1003-3254/5857.html
2016-11-08; 收到修改稿時間: 2016-12-12
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
當代工人(2020年13期)2020-09-27 23:04:20
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年11期)2018-08-04 03:26:08
電子制作(2018年10期)2018-08-04 03:24:48
家庭影院技術(2017年11期)2017-12-20 08:10:57
工業設計(2016年12期)2016-04-16 02:52:00
IT時代周刊(2015年8期)2015-11-11 05:50:37
汽車維修與保養(2015年1期)2015-04-17 03:25:28
設備管理與維修(2015年12期)2015-04-09 06:57:00
