垃圾債券新聞自動過濾
2017-07-16 21:25:47陳欽明劉丁屹呂威
中國新通信 2017年11期
陳欽明+劉丁屹+呂威
【摘要】 本文首先介紹了文本分類的應用背景,從傳統的人工分類到后面的基于機器學習的文本分類,而垃圾債券新聞自動過濾實際上可以看作文本分類的一個特例二分類問題,因此便可以基于文本分類的相關知識與理論對垃圾債券新聞進行自動過濾。接下來本文從數據預處理,文本分類算法設計與實現及分類算法評估等方面詳細地描述了垃圾債券新聞自動過濾的處理過程。
【關鍵字】 垃圾債券 文本二分類 數據預處理 SVM 分類指標 交叉驗證
一、應用背景
隨著網絡技術的迅猛發展以及電腦的普遍使用,電子化的文檔得到了“爆炸性”的增長,各種各樣的文檔層出不窮,充斥著網頁各個角落。一方面提高了人們獲取信息的便利性與快捷,豐富了人們的閱讀世界,另一方面也存在各種各樣的垃圾文檔包括垃圾新聞、垃圾郵件[1]等等,魚目混珠,良莠不齊。給人們的閱讀帶來了迷惑與不良的效果。本文主要基于它說平臺的債券新聞模塊嘗試了垃圾新聞的自動分類以達到自動過濾垃圾新聞的效果。
文本分類(Text categorization)[2]是指在給定分類體系下,根據文本內容自動確定文本類別的過程.20世紀90年代以前,占主導地位的文本分類方法一直是基于知識工程的分類方法,即由專業人員手工進行分類.人工分類非常費時,效率非常低.90年代以來,眾多的統計方法和機器學習方法應用于自動文本分類,文本分類技術的研究引起了研究人員的極大興趣并對其進行研究,在信息檢索、Web文檔自動分類、數字圖書館等多個領域得到了初步的應用。而本文所提到的垃圾債券新聞自動過濾實際上可以看做文本分類的一個特例,文本二分類的問題,即垃圾新聞與非垃圾新聞的分類問題,從而為垃圾債券新聞的自動過濾奠定了理論及實踐基礎。下面將從數據預處理,分類算法設計與實現及算法評估幾方面具體說說垃圾債券主體新聞自動過濾的處理過程。
二、數據預處理
數據預處理屬于文本分類的一個非常重要階段,它主要包括數據的過濾,轉化,清洗等過程,數據預處理的好壞一定程度上影響到后續算法分類效果的好壞。本文采用的數據來源為通過武大爬蟲,萬德數據庫以及鵬元爬蟲獲取到的新聞,本文抽取8306條新聞數據作為樣本集并對數據做了處理:記錄?txt文檔、非UTF-8編碼?UTF-8編碼;去掉html標記、換行符、多余空格,然后針對該樣本集進行垃圾新聞與非垃圾新聞的人工標記,最終非垃圾新聞數量為5807條,垃圾新聞數量為2499條。垃圾新聞樣例如下表1所示: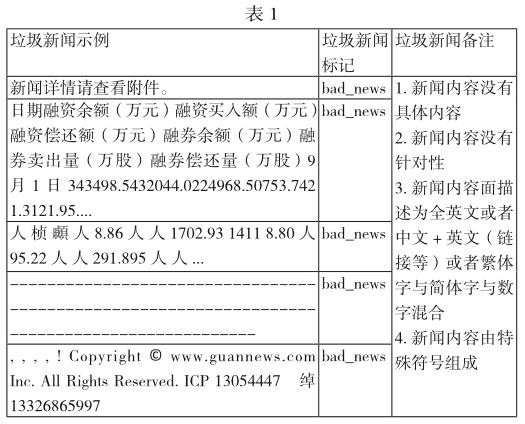
三、算法實現
常見的機器學習分類算法包括決策樹,神經網絡,貝葉斯,KNN,SVM等。本文主要采用貝葉斯,KNN以及SVM分類算法對垃圾債券新聞自動過濾進行算法實現。各種算法的主要思想如下文所示:
(1) 貝葉斯——對于給定的待分類項,求解在此項出現的條件下各個類別出現的概率,哪個最大,就把此待分類項歸屬于哪個類別.貝葉斯公式如下1-1所示: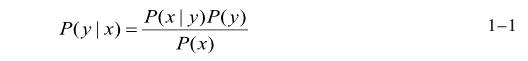
(2)KNN——KNN算法又稱為k最近鄰分類(k-nearest neighbor classification)[3]算法。該算法從訓練集中找到和新數據最接近的k條記錄,然后根據他們的主要分類來決定新數據的類別。該算法涉及3個主要因素:訓練集、距離或相似的衡量、k的大小。
(3)SVM——SVM為support vector machine(支持向量機)[4]的縮寫,它的主要思想是建立一個超平面作為決策平面,使得正例與反例之間的間隔最大化,這兩類的樣本中離決策平面最近的訓練樣本就叫做支持向量。
本文使用經數據預處理后的8306條新聞作為最終的樣本集,并對樣本集進行中文分詞[5]處理,構造樣本集文本對象,構建樣本集TF_IDF詞向量空間,然后使用相關分類算法進行預測分類結果。具體的算法流程圖如下圖1所示:
四、算法評價
常見的評價一個分類系統的好壞的分類指標大體可以分為兩大類。線上的指標還有離線的指標。線上的指標包括用戶滿意度等,需要通過調查問卷等方式進行采集。離線的指標包括平均絕對誤差(mean absolute error,MAE),ROC(Receiver Operating Characteristic)曲線,精度,召回率,F1-score,覆蓋率等。本文使用精度、召回率,錯分率以及 F1-score,混淆矩陣作為主要的評價指標。下面簡單介紹一下精度、召回率,錯分率以及F1-score,混淆矩陣:
1、精度(Precision,也稱為準確率):是檢索出的相關文檔數與檢索出的文檔總數的比率,衡量的是檢索系統的查準率。
精度(Precision)= 系統檢索到的相關文件 / 系統所有檢索到的文件總數
2、召回率(Recall Rate,也叫查全率):是檢索出的相關文檔數和文檔庫中所有相關文檔數的比率,衡量的是檢索系統的查全率。
3、錯分率為另外一個角度對召回率的刻畫,滿足錯分率+召回率=1
4、F1-score綜合考慮了精度以及召回率,是兩者的協調評價指標。
5、混淆矩陣(confusion matrix),是由false positives,false negatives,true positives和true negatives組成的兩行兩列的表格。它允許我們做出更多的分析,而不僅僅是局限在正確率。
本文按照10%測試集、90%訓練集的數據集隨機切分方式對分類結果進行了交叉驗證(cross_validation),最終的分類結果如下表2所示:
五、結論
由上表可知:SVM算法在垃圾債券新聞的自動過濾上能取得最好的過濾效果,貝葉斯算法也能取得相當不錯的效果,這一定程度上說明了垃圾債券新聞與非垃圾債券新聞兩者的區分度很高,兩種算法在垃圾債券新聞自動過濾上基本達到了可以相媲美的高度。而KNN算法則在區分度上不高。
參 考 文 獻
[1]郭泓.電子郵件過濾技術淺析.信息網絡安全,2002(10):4244.
[2]李榮陸.文本分類及其相關技術研究[D].上海:復旦大學計算機與信息技術系,2005,4-5
[3]亞南.KNN文本分類中基于遺傳算法的特征提取技術研究[D].中國石油大學,2011.
[4]毛雪岷,丁友明.基于語義引導與支持向量機的中文文本分類[J].情報雜志,2007,26(1 1):56-58
[5]李淑英.中文分詞技術[J].科技信息,2007, 36:65-66
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
