一種基于Boosting的集成學(xué)習(xí)算法在銀行個人信用評級中的應(yīng)用
2017-06-06 07:37:06陳力黃艷瑩游德創(chuàng)
價值工程 2017年18期
關(guān)鍵詞:信用評級
陳力+黃艷瑩+游德創(chuàng)
摘要: 本文針對銀行個人信用數(shù)據(jù)的分類預(yù)測問題,從數(shù)據(jù)集的特征選擇和集成學(xué)習(xí)兩個角度出發(fā),提出了PCA-Adaboost-Logistic集成學(xué)習(xí)算法。在采用Accuracy和AUC作為分類模型評價指標的前提下,本文選取了源于澳大利亞某銀行的個人信貸數(shù)據(jù)集進行測試。測試結(jié)果表明本算法在有效提取關(guān)鍵特征后提高了Adaboost的穩(wěn)定性,并且在分類準確度上相比單純使用Logistic分類器有不同程度的提高。
Abstract: This paper focused on classification prediction problem of the bank personal credit data, proposed a PCA-Adaboost-Logistic ensemble learning algorithm based on feature selection and ensemble learning. Accuracy and AUC were used as the classification model evaluation metric under the premise, this paper used the credit data sets from Australian banks to test the proposed algorithm. The results show that the proposed algorithm improves the stability of the Adaboost after extract the key features, and the classification accuracy is higher than the Logistic classifier.
關(guān)鍵詞: 信用評級;主成分分析;Adaboost;邏輯回歸
Key words: credit score;PCA;Adaboost;Logistic Regression
中圖分類號:F830.5 文獻標識碼:A 文章編號:1006-4311(2017)18-0170-03
0 引言
1936年,費舍爾[1]提出了統(tǒng)計判別分析的概念,這是信用評級領(lǐng)域的基礎(chǔ)。后來,大衛(wèi)·杜蘭德[2]在1941年運用了幾種算法來區(qū)分好的貸款和壞的貸款。1980年,銀行業(yè)專家鼓勵對信用卡使用信用評級,這也是首次將信用評級應(yīng)用到其他產(chǎn)品。托馬斯[3]定義信用評級為認識銀行客戶的過程,為了根據(jù)一系列預(yù)定的標準給他們發(fā)放貸款。現(xiàn)在,許多關(guān)于信用評級的研究集中到人工智能技術(shù)上,比如人工神經(jīng)網(wǎng)絡(luò)、遺傳算法和支持向量機,這些算法比統(tǒng)計優(yōu)化方法更能區(qū)分客戶的好壞。此外,基于集成學(xué)習(xí)算法的信用評分模型已經(jīng)被廣大的研究人員所使用,他們的研究成果已經(jīng)證實這種模型比單純的分類算法模型擁有更好的性能。
基于以上的研究背景,本文采取了融合特征選擇和集成算法的PCA-Adaboost-Logistic集成學(xué)習(xí)算法來評估銀行客戶信用等級。本算法首先利用PCA對數(shù)據(jù)集進行特征選擇,然后采用Adaboost集成學(xué)習(xí)框架,提出基于Logistic分類器的Adaboost算法,該算法有效提升了分類模型的學(xué)習(xí)能力,在預(yù)測銀行客戶信用等級方面具有良好的性能。
1 PCA-Adaboost-Logistic集成學(xué)習(xí)算法
1.1 PCA
PCA,即Principal Components Analysis,也就是主成分分析。PCA是一種常用的數(shù)據(jù)分析方法,它通過線性變換將原始數(shù)據(jù)變換為一組各維度線性無關(guān)的表示,可用于提取數(shù)據(jù)的主要特征分量,常用于高維數(shù)據(jù)的降維。
1.2 Adaboost-Logistic分類算法
1.2.1 Adaboost算法
Boosting,也稱為增強學(xué)習(xí)或提升法,是一種重要的集成學(xué)習(xí)技術(shù),能夠?qū)㈩A(yù)測精度僅比隨機猜測度略高的弱分類器增強為預(yù)測精度高的強分類器。Adaboost正是其中最成功的代表,其被評為數(shù)據(jù)挖掘十大算法之一[4]。該算法是一種迭代算法,是由Schapire和Freund在1995年共同提出的[5][6][7]。
Adaboost算法的基本思想是:開始時,每個樣本對應(yīng)的權(quán)重是相同的,即其中m為樣本個數(shù),那么每個訓(xùn)練樣本的初始權(quán)重都是1/m,在此樣本分布下訓(xùn)練出一弱分類器。基本規(guī)則是對訓(xùn)練失敗的樣本賦予較大的權(quán)重,這樣下次迭代時分類器將重點學(xué)習(xí)那些失敗的樣本,而對于分類正確的樣本,降低其權(quán)重,從而得到一個新的樣本分布。在新的樣本分布下,再次對樣本進行訓(xùn)練,得到弱分類器。依次類推,經(jīng)過T次循環(huán),得到T個弱分類器,把這T個弱分類器按一定的權(quán)重疊加起來,得到最終想要的強分類器。
1.2.2 Logistic 回歸
Logistic回歸,即Logistic Rregression。Logistic回歸是概率型非線性回歸模型,是研究二分類觀察結(jié)果y與一些影響因素(x1,x2,…,xn)之間關(guān)系的一種多變量分析方法。通常的問題是,研究某些因素條件下某個結(jié)果是否發(fā)生,比如本文中根據(jù)銀行客戶的數(shù)據(jù)信息來評價該客戶是“Good(好客戶)”或者“Bad(壞客戶)”。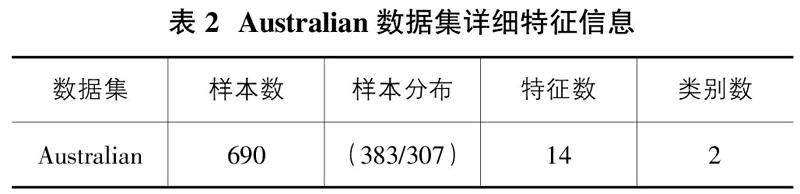
1.3 PCA-Adaboost-Logistic集成學(xué)習(xí)算法
PCA-Adaboost-Logistic集成學(xué)習(xí)算法首先采取PCA進行特征選擇,之后用經(jīng)特征選擇的數(shù)據(jù)來訓(xùn)練模型,然后通過模型對測試數(shù)據(jù)集進行分類,得到分類結(jié)果,并且計算出模型預(yù)測的精度和AUC值。PCA-Adaboost-Logistic集成學(xué)習(xí)算法的具體流程如表1所示。
2 數(shù)據(jù)準備和模型評估指標
2.1 數(shù)據(jù)集的描述
一些來源于現(xiàn)實世界的公共數(shù)據(jù)集已經(jīng)非常有名,而且在學(xué)者的文章中都有廣泛采用,這些數(shù)據(jù)集很容易地可以從UCI數(shù)據(jù)庫中獲得。本文所使用的個人信貸數(shù)據(jù)集Australian采集于UCI數(shù)據(jù)庫、源于澳大利亞某銀行。這個數(shù)據(jù)集的詳細特征信息如表2所述。
2.2 數(shù)據(jù)預(yù)處理
數(shù)據(jù)集Australian共有690條記錄,每一條記錄有15個字段組成。這其中前面14個字段是有關(guān)銀行客戶信貸信息的描述,最后一個字段是銀行對客戶信用級別的定義,該字段分為兩類,分別是:“Good(好客戶)”、“Bad(壞客戶)”。
以上部分對Australian數(shù)據(jù)集進行了簡單的總結(jié)分析,明顯發(fā)現(xiàn)每個數(shù)據(jù)集的特征屬性都比較多。然而,這些特征屬性對目標屬性的影響程度大不相同,因此使用PCA對數(shù)據(jù)集進行特征選擇從而達到降低數(shù)據(jù)維度的步驟不可或缺。另外,數(shù)據(jù)集中的屬性的類型各不相同,有數(shù)值型、字符型等,因此我們將字符型屬性對應(yīng)轉(zhuǎn)換成數(shù)值型屬性,這樣有利于后文實驗的開展。
2.3 模型評價指標
在傳統(tǒng)的分類方法中,常用準確度(Accuracy)作為評價指標。然而,很多情況下,僅僅依靠準確度不足以區(qū)分分類模型的優(yōu)劣。所以,為了讓所提出的模型的預(yù)測結(jié)論可靠,本文在模型準確度的基礎(chǔ)上,新增AUC(area under the curve)作為評估分類模型性能的指標。AUC就是ROC(receiver operating characteristic)曲線下方的面積,取值在0.5到1之間。ROC曲線是一種使用率很高的分類器評價指標,它是基于混淆矩陣得來的,表3就是一個分類問題的混淆矩陣。
根據(jù)上面的混淆矩陣,有以下概念:
3 實驗設(shè)計及結(jié)果分析
3.1 實驗設(shè)計
為了同時驗證本文提出的PCA-Adaboost-Logistic算法中Adaboost的性能和特征選擇的有效性,實驗分別測試了不經(jīng)過特征提取也不使用Adaboost的單純Logistic算法、不經(jīng)過特征提取使用Adaboost-Logistic算法、采用特征提取的PCA-Logistic算法、采用特征提取的PCA-Adaboost-Logistic算法四種算法所得出的Accuracy和AUC。在實驗中,我們采用十字交叉驗證(10-fold cross-validation)的測試方法。這種方法的基本思想是把原始數(shù)據(jù)分成十份,輪流將其中9份作為訓(xùn)練集,1份作為測試集。首先用訓(xùn)練集對分類器進行訓(xùn)練,然后利用測試集來測試訓(xùn)練得到的模型,最后評價模型的分類性能。在使用十字交叉驗證方法時,會得到10次模型評價結(jié)果,將這10次結(jié)果的平均值作為模型最終的評價指標。另外,試驗中集成學(xué)習(xí)算法Adaboost的迭代次數(shù)取值100。表4為以上四種算法的Accuracy和AUC對比情況。
3.2 結(jié)果分析
從表4可以看出,單純使用Logistic回歸的分類模型在Accuracy和AUC值上都比其他三種模型低,這說明單純的Logistic算法的預(yù)測精度和穩(wěn)定性都有很大的改善空間。在使用Logistic回歸的前提下,加入集成學(xué)習(xí)算法Adaboost使得模型的分類精度和穩(wěn)定性有了顯著的提升,同理,對數(shù)據(jù)集進行特征選擇后Logistic回歸算法預(yù)測的精度也有了極大的提升,同時也更加穩(wěn)定,這說明數(shù)據(jù)集的質(zhì)量對分類模型的影響十分大,從某種程度上決定了分類模型的性能。而且,可以很容易地看出,PCA-Adaboost-Logistic算法較前三種算法的性能更加優(yōu)秀,這種模型的預(yù)測精度和穩(wěn)定性都表現(xiàn)地很出色。因此基于數(shù)據(jù)處理的集成學(xué)習(xí)算法較單純的分類算法具有更好的性能。
4 結(jié)論
本文提出了PCA-Adaboost-Logistic集成學(xué)習(xí)算法,該算法首先利用PCA對數(shù)據(jù)進行特征選擇,選取最優(yōu)特征子集后采用Adaboost-Logistic分類算法進行分類。在使用相同組數(shù)據(jù)集的前提下,實驗使用Logistic、Adaboost-Logistic、PCA-Logistic和PCA-Adaboost-Logistic四種分類算法分別對銀行客戶進行信用評級,實驗結(jié)果證實PCA-Adaboost-Logistic集成學(xué)習(xí)算法較其他三種算法的性能更優(yōu)越。因此,集成學(xué)習(xí)算法較單純的分類器具有更優(yōu)良的分類性能。
參考文獻:
[1]Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of Human Genetics, 7(2), 179-188.
[2]Durand, D. (1941). Risk elements in consumer instalment financing. NY: National Bureau of Economic Research.
[3]Crook, J. N., Edelman, D. B., & Thomas, L. C. (2007). Recent developments in consumer credit risk assessment. European Journal of Operational Research, 183, 1447-1465.
[4]Zhou Z H, Yang Y, Wu X D, Kumar V. The Top Ten Algorithms in Data Mining. New York, USA: CRC Press, 2009,127-149.
[5]Freund Y, Schapire R E. A decision-theoretic generalization of on-line learning and an application to Boosting. Journal of Computer and System Sciences, 1997, 55(1): 119-139.
[6]Freund Y, Schapire R E. Experiments with a new Boosting algorithm. In: Proceedings of the 13th Conference on Machine Learning. San Francisco, USA: Morgan Kaufmann,1996. 148-156.
[7]Schapire R E, Singer Y. Improved Boosting algorithms using confidence-rated predictions. Machine Learning, 1999,37(3): 297-336.
猜你喜歡
山東工業(yè)技術(shù)(2016年24期)2017-01-12 22:02:45
現(xiàn)代商貿(mào)工業(yè)(2016年11期)2016-12-26 17:42:18
現(xiàn)代企業(yè)文化·理論版(2016年19期)2016-12-21 08:17:09
價值工程(2016年32期)2016-12-20 20:07:35
時代金融(2016年29期)2016-12-05 13:54:11
現(xiàn)代經(jīng)濟信息(2016年21期)2016-10-25 06:21:22
中國市場(2016年33期)2016-10-18 12:30:28
商(2016年17期)2016-06-06 08:10:49
商(2016年7期)2016-04-20 01:29:53
商(2016年8期)2016-04-08 10:31:04
