上市公司金融風險測度研究
2017-05-30 15:29:33潘莉曾鈴智潘遠翊
大東方 2017年11期
潘莉 曾鈴智 潘遠翊
摘要:本文運用Logi stic回歸模型構建了我國上市公司信用風險預測模型。該模型對我國上市公司出現信用風險概率的預測具有83.5%的準確性,可以為我國上市公司的投資者及監管者提供較為準確的上市公司信用風險狀況信息。
關鍵詞:金融風險測度;信用風險;Logi stic模型
金融風險監管是指對金融風險進行識別、測度和控制。金融風險管理的核心與基礎是金融風險測度,只有精準的測度風險發生的概率和規模大小,才能做出有效的管理。金融風險測度的研究需要與時代接軌,不斷改善,才能保障其對金融風險預測的準確性。因此,研究科學合理、符合當下金融環境的統計測度模型,對預防、規避金融風險顯得十分重要。
本文在上述背景下,積極探索研究符合當今金融環境下的金融風險統計測度模型,為我國金融市場的投資者和監管者提供理論支持,及時防范金融風險,促進我國金融與經濟的健康平穩發展。
一、模型構建
Logistic回歸模型是對二分類因變量進行回歸分析時最普通常見的多元統計方法,它根據樣本數據所采用的財務數據,使用最大似然估計法估計出參數值,可求得自變量取某個值的概率。
本文研究的上市公司分為存在信用風險或不存在信用風險兩個狀況,屬于二分類變量。當其取值為0時,代表上市公司存在信用風險;當其值取為1時,代表上市公司不存在信用風險。本文的單因素Logistic回歸模型的表達式如下所示:
在上述表達式中,P表示企業存在信用風險的概率,a為常數項,b為系數,x表示財務指標的取值。P的取值區間為(O,1),本文選取0.5作為分割點,即預測概率P大于0.5,表示企業存在信用風險,取值小于0.5,表示企業不存在信用風險。
二、數據來源及篩選
本文選取我國滬深兩市A股中在2015年至2016年期間被sT上市公司及其對應的非ST上市公司作為樣本數據進行建模,其中包括被ST公司98家,非Sr公司98家。選取我國滬深兩市A股中在2017年1月1日至2017~[z5月10日期間被sT上市公司及非sT]z市公司作為檢測樣本對模型進行檢測,其中包括被sT公司51家,非sT公司51家。
關于信用風險測度,本文選擇以下14個財務指標:凈資產收益率、銷售凈利率、總資產報酬率、應收賬款周轉率、總資產周轉率、流動資產周轉率、存貨周轉率、銷售現金比率、流動比率、速動比率、總資產負債率、總資產增長率、
凈利潤增長率、凈資產增長率。
根據我國國情,上市公司發出t-1年的年報與其在t年被sT這兩個事件幾乎是同時發生的。同時,前人的研究表明,運用t-1年的財務數據對t年該公司是否存在信用風險進行預測會高估模型的預測能力。因此,本文采取上市公司t-2年的財務數據來預測公司在t年是否會產生信用風險。
三、實證結論與模型檢驗
構建Logistic回歸模型的目的是對企業存在信用風險的概率進行預測,即將x帶入回歸方程,求出P值,得出企業是否存在信用風險的概率。
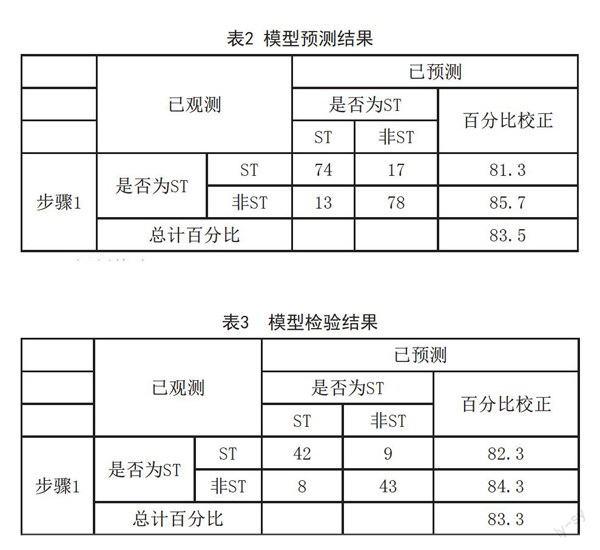
其預測結果如表2所示:
a.切割值為.500
將樣本數據帶入該模型中,對其出現信用風險的概率進行預測,從預測結果可以看出,該模型的預測準確率為83.5%。
將我國2017年上市上司中的51家被sT公司及對應51家非ST公司在2015年的財務數據帶入上述模型進行預測檢驗,檢驗結果如表3所示:
a.切割值為.500
從預測結果可以看出,用2017年上司公司作為該模型的檢驗樣本,預測準確度為83.3%,表明這是一個比較理想的信用風險預警模型。
四、研究不足
信用風險測度的研究是一項復雜的系統工程,上述模型也有以下幾個不足之處有待進一步研究:該模型僅適用于我國的上市公司,對于非上市公司,該模型有待進一步研究確認;企業出現信用風險是一個過程,本文僅使用了公司被sT的前t一2年的靜態數據進行研究,無法體現企業的財務數據變化;沒有考慮到其他非財務指標對企業出現信用風險的影響。
注:本文受國家統計局統計信息技術與數據挖掘重點開放實驗室課題項目(SDL201612)資助
作者簡介:
潘莉,成都信息工程大學統計學院講師,碩士;研究方向:金融數量分析。
曾鈴智,成都信息工程大學統計學院學生
潘遠翊,成都弘達偉業文化傳播有限責任公司研究員,博士;研究方向:數據挖掘
