基于教育數據挖掘的在線學習者學業成績預測建模研究
2017-05-30 05:19:59陳子健朱曉亮
中國電化教育 2017年12期
關鍵詞:機器學習
陳子健 朱曉亮

摘要:該文采用數據挖掘和機器學習的方法,研究從教育數據中挖掘影響在線學習者學業成績的因素并構建分類預測模型。首先,通過計算所有單個數據屬性和學業成績類別之間的相關系數和計算所有屬性的信息增益率兩種方法共同確定學業成績的影響因素。然后,提出采用集成學習的方法構建集成式學業成績分類預測模型,并比較多種算法構建的單一分類模型和集成分類模型的性能。最后,進一步采用嵌套集成學習的方法構建在線學習者學業成績分類預測模型,并對模型的性能進行評估。研究成果可以為在線學習者學業成績影響因素研究和預測建模研究提供借鑒,也有助于推進在線學習學業預警、學業成績預測和評價的實踐。
關鍵詞:教育數據挖掘;機器學習;預測建模;學業成績;在線學習
一、引言
在線教育已經逐漸被人們認可和接受,特別是在K12教育、語言類教育和職業技能培訓領域發展迅速。截至2016年12月,中國在線教育用戶規模達1.38億,較2015年底增加2750萬人,年增長率為25.0%。不同于面對面的課堂教學情境,在線學習中師生處于分離狀態,且學習者數量龐大。如何對在線學習者的學業成績進行預測,依據預測結果實施學業預警,并為教學決策提供依據,是在線教育需要解決的一個問題。利用教育數據挖掘技術,通過數據驅動的方式構建在線學習者學業成績預測模型,即從數據中自動學習預測模型是目前研究的熱點。然而,采用決策樹、人工神經網絡等算法訓練的單一預測模型性能不穩定,對數據變化比較敏感。針對上述問題,本文基于“集體決策優于個體決策”的假設,嘗試采用集成學習(EnsembleLearning)方法構建集式模型。在實驗驗證的基礎上,進一步采用嵌套集成學習方法構建在線學習者學業成績分類預測模型,并對模型的性能進行評估分析。
二、概念界定及相關研究
(一)概念界定與分析
教育數據挖掘(Edueational Data Mining,EDM)是數據挖掘技術在教育領域的應用。根據國際教育數據挖掘工作組網站的定義,教育數據挖掘是指運用不斷發展的方法和技術,探索特定教育環境中的各類數據,挖掘出有價值的信息,以幫助教師更好地理解學生,并改善他們所學習的環境,為教育者、學習者、管理者等教育工作者提供服務。EDM與學習分析(Learning Analytics,LA)交叉,但是兩者又存在差異:(1)EDM強調自動發現,側重建立模型和發現模式,多采用機器學習和數據挖掘技術;LA盡管也強調自動發現,但同時還需要人為干預,多采用統計分析技術。(2)EDM起源于智能輔導領域,強調預測學習者的學業成績和關注預測建模;LA也包括這些要素,但它更強調系統干預,注重個性化和自適應。(3)LA側重于描述已發生的事件或其結果,而EDM側重于發現新知識與新模型。
預測建模(Predictive Modeling)是指根據現有數據先建立一個模型,利用模型可以對未來的數據進行預測。本研究中的學業成績預測建模主要是利用已知學生學業成績類別的訓練數據訓練得到一個分類函數或分類模型(即分類器),并評估模型的性能。學業成績預測的目的是將學習者在學習過程中的相關數據輸入預測模型,預測學習者在學習結束時可能的成績類別,為是否進行學業預警和調整教學策略提供依據。
(二)相關研究
教育數據量的急劇增長、數據類型的多樣性、數據的可獲取性以及數據挖掘技術的發展等多種因素共同推動了教育數據研究的發展。學習者模型、學業成績預測、行為模式發現、學習反饋與評價等是當前教育數據研究的主要熱點,已有的學業成績預測相關研究,根據其研究的側重點大致可以分為三類。
1.學業成績預測與評價的理論模型研究
美國佛羅里達農工大學的Ohia博士在Nichol的五步模型的基礎上,提出了采集學業成績相關數據并進行評價的六步模型一FAMOUS,模型名稱由六個關鍵步聚的首字母組成。蔚瑩等對QFD(質量功能展開)模型進行適當的調整,提出基于QFD的學生學習能力評估理論模型。張濤等參考Kirkpatrick評估模型建立了翻轉課堂環境下的學習績效評價理論模型。武法提等基于學習行為分析模型和學習結果分類理論設計了學業成績預測框架,包括學習內容分析、學習行為分析和學習預測分析三個模塊。金義富等在討論學業預警系統設計框架的基礎上,提出了課程、課堂、課外“三位一體”預警信息發現與生成模型LAOMA。
2.學業成績影響因素研究
Carmel McNaught等關注香港高校中e-Learning學習過程和學業成績預測,探索學習設計,特別是學習設計中的策略設計與學習環境設計,與學業成績之間的關系。Galbraith,Craig S調查116門課程的學生評教與學生學業成績的相關數據,研究學生評教與學業成績和教學效能之間有無相關性。Gary Pike等使用美國“全國大學生學習參與度調查”(NSSE)數據,并引入學生特征和院系特征,調查教育支出、學習參與度和學生自我報告學業成績之間的聯系。J.Fredericks Volkwein等通過40個機構的203個工程項目的數據,研究評價標準與學生經歷和學業成績的關系。趙艷等運用相關分析、多元回歸分析方法得出了影響中小學教師遠程培訓效果的主要因素。趙慧瓊等利用多元回歸分析法分析學習者在線學習行為數據,判定影響學業成績的預警因素。劉銘、馬小強等采用質性研究方法,通過訪談、現場觀察和實物收集等手段,從學習者的視角挖掘了學習者參與云教室學習并取得績效的影響因素。傅鋼善等以陜西師范大學“現代教育技術”網絡課程為例,探討學習者的行為特征與學業成績的關系。吳青等選擇遠程教學平臺的學習行為數據,采用關聯規則算法挖掘學習風格、學習行為和學習成就之間的內在規律。
3.學業成績預測和評價的數學建模
LC Duque等采用問卷收集數據,利用象限分析、ANOVA測試和結構方程模型組成的多重方法研究學業成績和滿意度的建模。Arsad等使用人工神經網絡方法建模,預測馬來西亞瑪拉工業大學工程學專業學生的學業成績。模型以學習者的基礎課程的學分積點作為輸入,以學分積點的平均值作為輸出。陸柳生等提出基于離群點檢測的學生學習狀態分析方法,對學生考試成績數據進行挖掘,判定學生學習狀態是否異常。施儉等在分析教育數據挖掘技術及應用的基礎上,建立以關聯規則挖掘和聚類分析為核心的網絡學習過程監管的數據挖掘模型,可以從學習數據中判定學生網絡學習效果。舒忠梅等利用神經網絡算法建立17個輸入節點,7個隱藏節點,1個輸出節點的三層神經網絡模型對學生的學業成績進行預測。
通過文獻分析,發現國內外學術界在學業成績預測和評價方面已經做了不少研究工作。但是現有研究,特別是國內研究,主要集中在:(1)從理論視角研究學業成績預測和評估的框架模型,實證研究稍顯不足,缺乏對理論框架的詳細驗證;(2)基于理論演繹推導和經驗,建立某些因素與學業成績之間存在相關性的假設,再采用問卷和訪談等方法收集數據,分析驗證假設;這種方式只能證明選定因素與學業成績之間存在相關性,但難以確定選定因素與學業成績之間數量關系;(3)部分研究者采用決策樹、神經網絡等算法建立學業成績預測模型,但是建立的模型往往是單一的分類器,由于算法本身特性的原因,單個分類器的性能容易受數據變化的影響。
本研究嘗試使用數據驅動的建模方法,從數據中挖掘影響在線學習者學業成績的因素,通過機器學習從數據中自動學習分類預測模型。針對單一分類預測模型容易受數據變化影響而表現出分類性能不穩定的問題,采用集成學習的方法構建集成式預測模型。在比較多種算法構建的單一分類器和集成分類器的分類性能的基礎上,進一步提出采用嵌套集成學習的方法構建在線學習者學業成績分類預測模型,并對模型的性能進行評估,以期為在線學習者的學業成績預測建模提供借鑒。
三、數據來源及學業成績影響因素的選擇確定
(一)數據來源
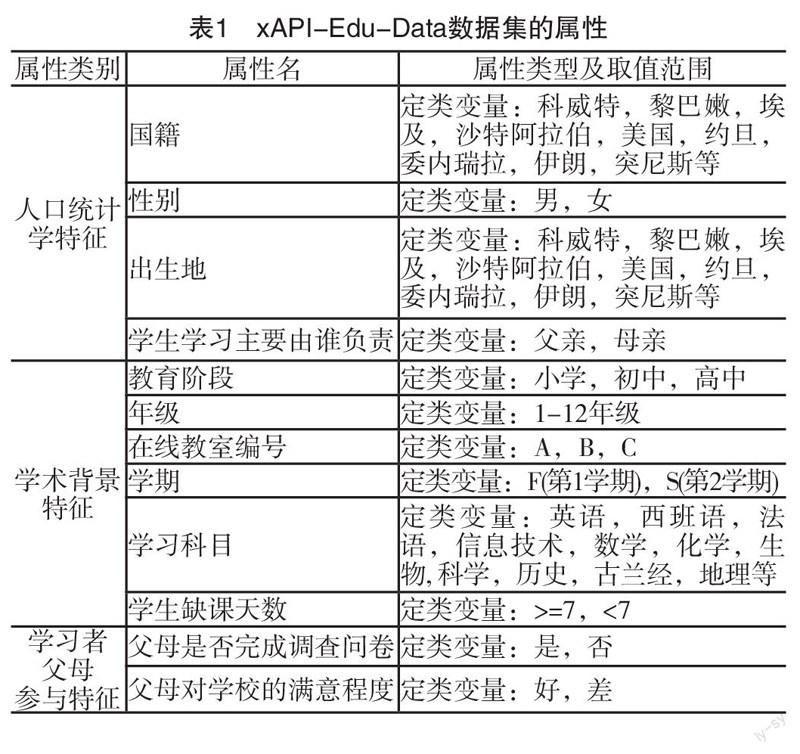
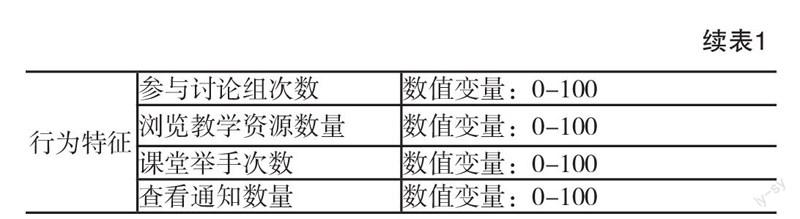
本研究使用約旦大學e-Learning學業成績數據集(xAPI-Edu-Data)。數據來自Kalboard 360學習管理系統,并在學習管理系統內嵌入學習者活動跟蹤工具ExperienceAPI(xAPI)采集學習者行為相關數據。采集到的原始數據共500條記錄,其中20條記錄中存在缺失值,剔除含缺失值的數據,最后保留480條有效記錄。學習者中男生305名,女生175名,主要來自科威特、約旦等中東國家,也有少量來自突尼斯、美國、墨西哥、委內瑞拉等歐洲和美洲國家。每條數據記錄包括16個屬性(如表1所示),除了與學習者自身相關的人口統計學特征,學習背景特征和學習行為特征之外,數據集中還包括與學習者父母相關的數據,如學習者的學習主要由父親還是母親負責,學習者父母是否完成問卷調查以及學習者父母對教學的滿意度。數據采集的時間跨度為兩個學期,其中245名學習者的記錄是第一個學期采集的,235名學者的數據是第二個學期采集的。依據學習者最終的成績將學習者的學業成績劃分為三個層次,其中,70分以下為低水平(Low),70~89分為中等水平(Middle),90分以上為高水平(High)。
數據集中同時包含定類屬性和數值屬性,為避免數值屬性取值范圍的差異對分類預測的干擾,首先對數值屬性進行歸一化處理,使所有的數值屬性的取值范圍處于[0,1]區間內。
(二)學業成績影響因素的選擇確定
學業成績影響因素的選擇確定在數據挖掘中表現為數據屬性子集的選擇確定。原始數據集中通常包含一些不相關或冗余的屬性,例如學生的學號與學生的學業成績顯然不存在相關性。去除冗余和不相關的特征可以提升分類的準確率,并且在屬性子集上學習到的預測模型也更好理解。屬性子集選擇的目標是找出最小屬性集,并使得數據子集的概率分布盡可能地接近原始數據的分布。屬性子集選擇的理想方法是:將所有可能的屬性子集作為數據挖掘算法的輸入,然后選取產生最好結果的子集。然而,由于涉及n個屬性的子集多達2n個,這種方法一般行不通,需要其它策略。
本研究采用對原始數據中所有的單個屬性進行評估并排序,然后依據排序結果來選擇屬性子集的方法。具體實現是借助Weka,采用兩種方法對數據集的屬性進行評估和排序。第一種方法是計算所有單個屬性和學業成績類別之間的皮爾森相關系數,并依據皮爾森系數的大小進行排序,系數值越大表示該屬性與學業成績類別之間的相關性越強。第二種方法是計算所有屬性的信息增益率,并根據信息增益率的大小對屬性進行排序,屬性的信息增益率越大表示該屬性對學業成績進行分類的能力越強。兩種屬性評估方法的排序結果如下頁表2所示。第1列是屬性的相關系數或信息增益比率,第2列是屬性的序號,第3列則是屬性的名稱。從下頁表2可以發現,雖然兩種屬性評估方法的排序結果有差異,但兩種方法的排序結果的前9項組成的屬性子集具有一致性。從相關系數和信息增益率的數值大小可以判斷這9項也是影響學業成績的主要影響因素,因此將其作為預測建模的自變量。
四、預測算法與實驗設計
(一)預測算法
分類和回歸是兩類主要的預測問題,分類是預測離散的值,回歸是預測連續的值。本研究主要是預測在線學習者在學習結束時學業成績的類別,類別∈{Low,Middle,High}。分類一般分為兩個步驟,首先利用已知類別標簽的數據集訓練分類模型,并評估模型,該步聚也稱作有監督的學習;然后利用模型將未知類別的數據對象映射到某個給定的類別。目前,常用的分類算法有貝葉斯網絡(BN)、決策樹(DT)、人工神經網絡(ANN)和支持向量機(SVM)等。
傳統分類建模方法是將原數據分為訓練集、驗證集和測試集,其中訓練集用于學習模型,驗證集用于模型調參,測試集來檢驗模型的性能。這樣學習到的往往是一個單一分類器。基于“集體決策優于個體決策”的假設,本研究采用集成學習方法對原始數據進行二次抽樣以得到多個訓練集,使用特定算法在每個訓練集建立一個分類器(基分類器),每個基分類器分別預測未知樣本的類別,最后對基分類器的分類結果進行某種組合來決定最終的類別。集成學習的邏輯視圖如圖1所示。常見的集成學習方法有裝袋(Bagging)和提升(Boosting),另外隨機森林算法也是一種集成學習方法。
1.裝袋(Bagging)
通過對原數據集進行有放回的抽樣構建出大小和原數據集D一樣大小的新數據集D1,D2,D3……,然后用這些新的數據集訓練多個基分類器C1,C2,C3……。因為是有放回的抽樣,所以在同一個訓練集中同一個樣本可能會出現多次,也可能有的樣本不會出現。裝袋算法對所有基分類器的預測值進行多數表決,將得票最高的類別指派給測試樣本。
2.提升(Boosting)
提升為每一個訓練樣本賦一個權重,在每一輪提升過程結束時自動調整權重。開始時所有樣本的權重都等于是1/N,抽到的概率都一樣,抽樣得到的訓練集經過訓練得到一個分類器。利用分類器對原始數據集中所有樣本進行分類,然后增加錯誤分類樣本的權重(對錯分數據進行懲罰),減少正確分類樣本的權重,使分類器在后續迭代中關注那些難以分類的樣本。
3.隨機森林(Random Forest)
隨機森林是一種專門為決策樹基分類器設計的集成學習方法。它集成多棵決策樹的預測,其中每棵樹都是基于隨機向量的一個獨立集合的值產生。隨機森林得到基分類器Ci的算法主要分為兩步:(1)對原始訓練集采用有放回的自助抽樣,得到和原始訓練集大小一致的訓練集,與裝袋方法一致;(2)隨機選取分裂屬性集。在每個內部節點,從M個屬性中隨機選取F(F(二)實驗設計
采用十折交叉驗證方法將原始數據分為訓練集和驗證集,分別使用BN、DT、ANN和SVM四種算法在訓練集上訓練單一分類器,然后分別以四種算法訓練基分類器,采用三種集成學習方法構建集成分類器。比對單一分類器和集成分類器的性能,檢驗集成分類器能否提升分類性能,是否對所有基分類器有效。在上一步實驗的基礎上,嘗試采用嵌套集成學習方法構建學業成績分類預測模型,優化模型參數,評估模型對學業成績分類預測的效果。實驗在安裝Weka 3.8的PC(Intel(R)Core(TM)i5-6600cpu@3.30GHz,8G RAM)上完成。完整的實驗流程如下頁圖2所示,其中數據預處理和屬性選擇在“學業成績影響因素的選擇確定”階段已經完成。
五、實驗結果與分析
(一)單一分類器與集成分類器性能比較
實驗采用BN、DT、ANN和SVM四種算法訓練得到4個單一分類器;將4個單一分類器作為基分類器,分別采用裝袋和提升方法訓練得到8個集成分類器;以DT分類器為基分類器,采用隨機森林算法訓練得到1個集成分類器,共計13個分類器。各個分類器的性能指標如表3所示。表中所有指標是分類器對Low、Middle、High三個學業成績類別進行預測的平均值。
結果顯示,對于貝葉斯網絡(BN)、決策樹(DT)和人工神經網絡(ANN)三種算法,通過構建集成分類器都能不同程度地提升分類性能,真正率、精度和召回率都有所提升,假正率都有所降低。以ANN算法為例,單一分類器的精度是0.722,而裝袋方法訓練得到的集成分類器的精度是0.769,提升方法訓練得到的集成分類器的精度是0.767。雖然精度提升幅度不明顯,但是如果測試樣本數量較大,能夠正確分類的實例數還是會有較大差異。相比而言,在幾種不同類型的基分類器中,集成學習對于ANN類型的基分類器性能提升最為顯著f提升6.5%),通過隨機森林方法得到的DT類型的集成分類器性能最好。實驗結果同時顯示,對于SVM算法,構建集成分類器并不能提高分類性能,反而相對于單一分類器,性能有輕微的降低。
(二)學業成績分類預測模型構建與分析
依據前面實驗結果,選擇分類性能最好的隨機森林集成分類器作為基分類器,采用裝袋方法訓練集成分類器,即進行集成學習的嵌套,并對訓練過程中的參數進行調整,構建學業成績分類預測模型。
學業成績分類預測模型(嵌套集成分類器)的性能摘要如表4所示。
分類器能對480個實例中的380個實例進行正確分類,分類的準確率為79.1667%,分類的準確性有了進一步提高。kappa系數為0.6785,一般認為kappa系數處于[0.6,0.8]就可以判定為分類性能較好。分類器的真正率(TP Rate)、召回率(Recall)、精度(Precision)、受試者操作特征曲線面積(ROC Area)等各項指標如表5所示。各項指標顯示分類器對學業成績類別集合{Low,Middle,High}中的Low預測更為準確,其精度為0.857,表示分類器預測為學業成績差的學習者中有85.7%學習者在學習結束時的學業成績是較差的。ROC Area=0.968(如下頁圖3所示),隨機分類時ROC Area=0.5,ROC Area值介于0.5和1之間,ROC Area越接近1越好。ROC Area=0.968表示分類器性能很好。總體來說,分類器對Class=Low的分類性能最好,對Class=High的分類性能次之,對Class=Middle的分類性能最差。
分類預測模型對學業成績類別Class=Low的分類預測更為準確也符合實際應用,因為分類預測的主要目的之一就是為了及早發現學業成績可能較差的學習者,及時進行干預。如下頁表6所示的分類器混淆矩陣的行代表真實的類別,列代表分類器的預測結果。混淆矩陣顯示,127個真實類別為Low的實例中,108個預測正確,19個錯誤預測為Middle,沒有實例錯誤預測為High;211個真實類別為Middle的實例中163個預測正確,18個實例錯誤預測為Low,30個實例錯誤預測為High;142個真實類別為High的實例中,109個預測正確,33個錯誤預測為Middle,沒有實例錯誤預測為Low。
六、結論與討論
學習者學業成績的預測和評價是全世界教育研究者共同關注的話題,而在線教育的快速發展又賦予它新的使命,即如何對在線學習者的學業成績進行預測,以便及時提供預警和其它干預措施。在大數據時代,學習者在線學習過程中會積累海量結構性和非結構性的數據,可以通過數據挖掘技術探尋在線學習者學業成績的影響因素,也可以通過機器學習的方法從數據中自動學習到學業成績預測模型。
針對本研究所使用的數據集,在學業成績影響因素的挖掘過程中發現學習者行為對學業成績影響最大,父母的參與度與態度對學業成績的影響次之,學習者人口統計學方面的特征對學業成績的影響最小。該發現對在線教育平臺的設計和在線教育的數據采集具有借鑒意義。要實現真正個性化在線教育,實現對學業成績的精準預測和提供及時干預,首先需要通過在線教育平臺的功能設計實現對學習者相關數據的自動采集;其次,數據的采集類別除了現在普遍關注的人口統計學方面的特征數據,還需特別注重對學習者行為特征數據的采集。隨著情感計算技術在教育中的應用,學習者情感特征數據也需要進行采集;另外,對于不同類型的在線學習者,影響其學業成績的因素不同,需要采集的數據類別也存差異;例如,本研究中的K12階段的中小學生不同于大學生等成人學習者,中小學生父母的行為和態度也是預測學習者學業成績時需要考慮的一個重要方面。
對于通過機器學習從數據中自動學習分類預測模型的問題,本研究假設相比于單一分類模型,學習多個基分類器,然后對基分類器的結果進行組合的集成學習方法可以提升預測模型的性能。研究發現,對于貝葉斯網絡(BN)、決策樹(DT)、人工神經網絡(ANN)三種算法,通過集成學習構建集成分類模型確實都能不同程度地提升分類預測的性能;但是對于支持向量機(SVM)算法,學習到的集成分類模型并沒有提升分類預測的性能,反而相比于單一分類模型,分類性能有所降低。理論上講,集成學習可以或多或少地提升分類性能,但提升的幅度與基分類器的穩定性有關,對于不穩定的基分類的性能提升更加明顯。對于SVM算法,集成學習降低模型的分類性能的原因在于:SVM算法得到基分類器本身比較穩定,集成學習算法對分類性能的提升并不明顯;同時,由于集成學習算法在訓練基分類器時,因為算法本身的特性會使得訓練子集可能存在重復樣本,導致基分類器性能降低,從而使得整個模型的分類性能輕微下降。
在確認集成學習方法可以提升學業成績分類預測模型性能的前提下,本研究進一步采用嵌套集成學習的方法從數據中自動學習分類預測模型。用隨機森林算法訓練基分類器,采用裝袋算法對基分器的預測值進行多數表決,并對模型的性能進行分析。研究發現:通過嵌套集成方法學習到的模型的分類精度得到了進一步提高。需要說明的是模型分類精度的高低除了受算法本身優劣性的影響之外,還受分類的類別數量的影響。分類的類別越多,準確分類的難度越大,例如本研究中將學業成績的預測結果劃分為三個類別,平均精度是79.2%;但如果只將預測結果劃分二個類別,分類的精度將得到較大幅度的提升。假設是對學業成績預測結果為“差”的學習者進行預警,則只需將預測結果劃分為“差”和“不差”兩個類別,分類的準確度得到大幅提升,如下頁圖4所示。在下頁圖4的混淆矩陣中,列代表預測類別,行代表真實類別,預測類別和真實類別一致代表預測正確。a代表學業成績預測結果為差(class=Low),b代表預測結果不為差(Class≠Low,即Class=High'Class=Middle)。預測結果為差的樣本中,109個樣本預測正確,18個預測錯誤;預測結果不為差的樣本中,335個樣本預測正確,18個樣本預測錯誤;預測準確度為92.5%((109+335)/(109+18+335+18)=0.925)。
最后,對于數據驅動的在線學習者學業成績預測建模問題,模型分類預測的準確性除了受到上面分析中提到的算法優劣性、分類類別數量的影響之外,還和原始數據集有較大關系。因為數據驅動的預測建模首先需要在原始數據的屬性集中篩選出影響學業成績的主要屬性,然后再以選定的屬性作為自變量,以學業成績為因變量建立數學模型。那么原始數據的屬性集能否涵蓋影響學業成績的全部主要因素,對構建的預測模型的精確性有影響。數據集中的噪聲也會影響模型分類準確度的提升。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
