引入結(jié)構(gòu)信息的模糊支持向量機(jī)
2017-04-26 05:26:15李凱顧麗鳳張雷
河北大學(xué)學(xué)報(自然科學(xué)版) 2017年2期
李凱,顧麗鳳,張雷
(1.河北大學(xué) 計算機(jī)科學(xué)與技術(shù)學(xué)院,河北 保定 071002;2.中國聯(lián)合網(wǎng)絡(luò)通信有限公司保定市分公司 網(wǎng)絡(luò)與信息安全部,河北 保定 071051)
?
引入結(jié)構(gòu)信息的模糊支持向量機(jī)
李凱1,顧麗鳳1,張雷2
(1.河北大學(xué) 計算機(jī)科學(xué)與技術(shù)學(xué)院,河北 保定 071002;2.中國聯(lián)合網(wǎng)絡(luò)通信有限公司保定市分公司 網(wǎng)絡(luò)與信息安全部,河北 保定 071051)
模糊支持向量機(jī)是在支持向量機(jī)的基礎(chǔ)上,通過考慮不同樣本對支持向量機(jī)的作用而提出的一種分類方法,然而,該方法卻忽視了給定樣本集的結(jié)構(gòu)信息.為此,將樣本集中的結(jié)構(gòu)信息引入到模糊支持向量機(jī)中,給出了一種結(jié)構(gòu)型模糊支持向量機(jī)模型,利用拉格朗日求解方法,將其轉(zhuǎn)換為一個具有約束條件的優(yōu)化問題,通過求解該對偶問題,獲得了結(jié)構(gòu)型模糊支持向量機(jī)分類器.實驗中選取標(biāo)準(zhǔn)數(shù)據(jù)集,驗證了提出方法的有效性.
支持向量機(jī);模糊支持向量機(jī);結(jié)構(gòu)信息;類內(nèi)離散度
支持向量機(jī)SVM (support vector machine)是由Vapnik等[1]提出的一種機(jī)器學(xué)習(xí)方法,其理論基礎(chǔ)是統(tǒng)計學(xué)習(xí)理論的VC (vapnik chervonenkis)維和結(jié)構(gòu)風(fēng)險最小化原理.SVM的基本思想是尋找具有最大間隔且將2類樣本正確分開的超平面,為此,研究人員對其進(jìn)行了深入的研究,并提出了很多不同的支持向量機(jī),例如υ-SVM(υ-support vector machines)[2]和LS-SVM(least squares support vector machine)[3].由于支持向量機(jī)對噪聲或異常點具有較強(qiáng)的敏感性,使得它的訓(xùn)練易產(chǎn)生過擬合現(xiàn)象,從而導(dǎo)致支持向量機(jī)的泛化性能降低.為了解決該問題,研究人員提出了模糊支持向量機(jī)FSVM (fuzzy support vector machine)[4],該方法主要將模糊理論引入到支持向量機(jī)中,通過考慮不同樣本對支持向量機(jī)的作用,較好地解決了噪聲或異常點對支持向量機(jī)的影響.然而,如何確定不同樣本的作用,即合理設(shè)置樣本的模糊隸屬度是模糊支持向量機(jī)的主要問題.之后,研究人員依據(jù)訓(xùn)練樣本的分布獲得了模糊隸屬度的確定方法[5-7]. 另外,一些研究人員通過研究模糊隸屬度的確定方法也獲得了不同類型的模糊支持向量機(jī)[8-10]. 可以看到,對于以上介紹的支持向量機(jī)或模糊支持向量機(jī),主要利用了數(shù)據(jù)集的類間的可分性,但忽視了數(shù)據(jù)集中類內(nèi)的結(jié)構(gòu)信息,為此,人們提出了結(jié)構(gòu)支持向量機(jī)[11-16],進(jìn)一步提高了支持向量機(jī)的泛化性能.目前,關(guān)于結(jié)構(gòu)支持向量機(jī),人們主要在傳統(tǒng)支持向量機(jī)的基礎(chǔ)上并結(jié)合結(jié)構(gòu)信息進(jìn)行了研究.鑒于模糊支持向量機(jī)的影響之深,本文對基于結(jié)構(gòu)信息的模糊支持向量機(jī)進(jìn)行了研究,給出了結(jié)構(gòu)型模糊支持向量機(jī)模型,利用拉格朗日方法獲得了結(jié)構(gòu)型模糊支持向量機(jī)分類器,實驗驗證了提出方法的有效性.
1 模糊支持向量機(jī)
模糊支持向量機(jī)是由Lin等[4]提出的一種分類方法,它主要針對數(shù)據(jù)樣本點的重要性不同,將每個數(shù)據(jù)樣本點xi賦予一個合適的模糊隸屬值si(0≤si≤1),以此克服噪聲或異常點對支持向量機(jī)的影響.為此,在模糊支持向量機(jī)中,給定的數(shù)據(jù)樣本集是具有模糊隸屬度的一個數(shù)據(jù)集合.假設(shè)X={(x1,y1,s1),(x2,y2,s2),…,(xl,yl,sl)},其中xi∈Rn,yi∈{+1,-1},i=1,2,…,l,si是樣本xi屬于類yi的模糊隸屬度.
模糊支持向量機(jī)的優(yōu)化問題如下:
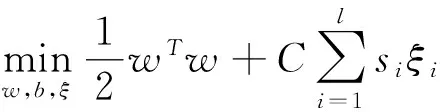
s.t yi(wTxi+b)+ξi≥1,i=1,2,…,l,
(1)
ξi≥0,i=1,2,…,l,
其中ξi是松弛變量,ξ=(ξ1,ξ2,…,ξl)是由松弛變量構(gòu)成的向量,C是懲罰因子,siξi度量不同變量的重要性.原優(yōu)化問題(1)的對偶問題為
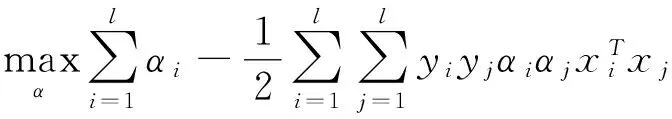
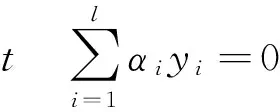
(2)
0≤αi≤Csi,i=1,2,…,l.
2 結(jié)構(gòu)型模糊支持向量機(jī)
2.1 結(jié)構(gòu)型模糊支持向量機(jī)模型
在結(jié)構(gòu)型模糊支持向量機(jī)SFSVM (structural fuzzy support vector machine)中,不僅尋找具有最大間隔的超平面,而且使得每類具有較小的離散度,為此,將數(shù)據(jù)集中的結(jié)構(gòu)信息引入到模糊支持向量機(jī)中,從而得到結(jié)構(gòu)型模糊支持向量機(jī)模型,其優(yōu)化問題如下:
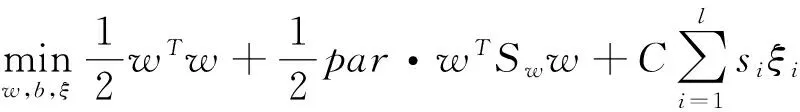
s.t yi(xi·w+b)+ξi≥1,i=1,2,…,l,
(3)
ξi≥0,i=1,2,…,l.
其中par≥0為參數(shù),Sw為給定數(shù)據(jù)的總類內(nèi)離散度矩陣.
令I(lǐng)為單位矩陣,∑=par·Sw+I,則(3)進(jìn)一步變?yōu)槿缦碌膬?yōu)化問題:
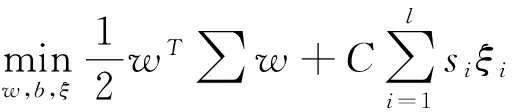
s.t yi(xi·w+b)+ξi≥1,i=1,2,…,l,
(4)
ξi≥0,i=1,2,…,l.
使用拉格朗日方法求解(4),為此構(gòu)造如下拉格朗日函數(shù):
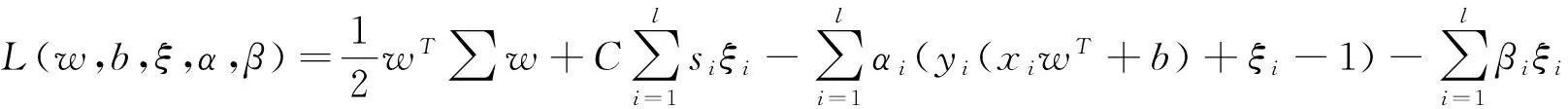
(5)
其中α≥0和β≥0為拉格朗日乘子向量,即α=(α1,α2,…,αl) ,β=(β1,β2,…,βl),函數(shù)L的極值應(yīng)滿足如下條件:
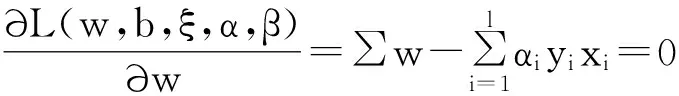
(6)
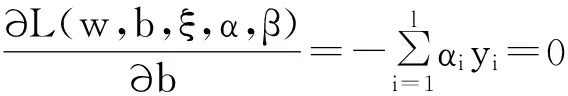
(7)
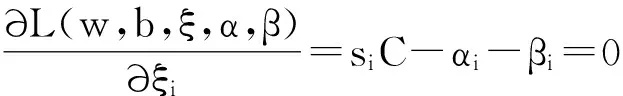
(8)
將式(6)、(7)和(8)帶入(5),由此得到如下優(yōu)化問題:
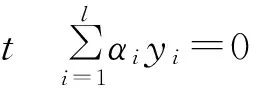
0≤αi≤Csi,i=1,2,…,l.
(9)
可以看到,式(9)為二次規(guī)劃問題,可以對其直接求解,設(shè)獲得的解為α*=(α*1,α*2,…,α*l),將其帶入(6),從而得到最優(yōu)超平面的法線方向w=∑-1·∑li=1α*iyixi,由此進(jìn)一步得到如下的決策函數(shù):
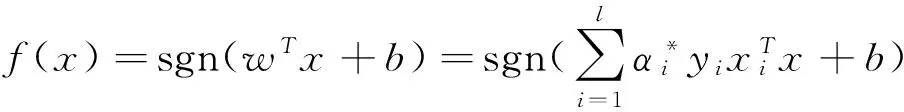
其中b可由K-T條件獲得.
2.2 結(jié)構(gòu)信息的獲取
假設(shè)樣本集X中的2類樣本構(gòu)成的集合分別為X+和X-,即X=X+∪X-,m1和m2分別為X+和X-的均值向量,則樣本集X的結(jié)構(gòu)信息,即樣本集X的類內(nèi)離散度為

對于樣本集X的結(jié)構(gòu)信息,除了使用類內(nèi)離散度方法獲取外,也可利用聚類方法得到. 假設(shè)對每類樣本聚類的簇數(shù)為k個,其聚類結(jié)果分別為X+和X-,即
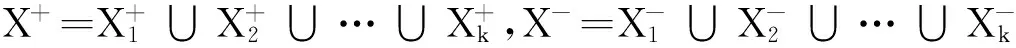
其中X+i和X-i(i=1,2,…,k)分別為對正類樣本和負(fù)類樣本聚類后得到的第i個簇;然后對每個簇X+i和X-i(i=1,2,…,k),分別計算類內(nèi)離散度S+i和S-i,從而獲得每類的類內(nèi)離散度S+和S-,即S+=∑ki=1S+i,S-=∑ki=1S-i,則樣本集X的結(jié)構(gòu)信息為Sw=S++S-.
可以看到,對于結(jié)構(gòu)信息的獲取,給出的2種方法可以統(tǒng)一為使用聚類方法獲取樣本集的結(jié)構(gòu)信息,也就是說,當(dāng)聚類方法中的簇數(shù)k=1時,則聚類方法獲取的結(jié)構(gòu)信息變?yōu)橹苯邮褂妹款惖念悆?nèi)離散度方法.
2.3 模糊隸屬度的確定方法
對于給定的數(shù)據(jù)集,如何確定每個樣本的隸屬度呢?關(guān)于該問題,研究人員提出了一些方法.在本文中,使用了Lin等[4]提出的樣本隸屬度的確定方法,即通過計算每個樣本到其類中心的距離來獲取樣本隸屬度,從而減少異常點或噪聲對支持向量機(jī)的影響.下面給出計算樣本模糊隸屬度的具體步驟:
1)分別計算正類和負(fù)類樣本的類中心,設(shè)為x+和x-.
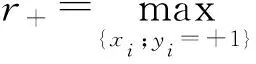
3)根據(jù)樣本類均值和類半徑獲得每個樣本的模糊隸屬度
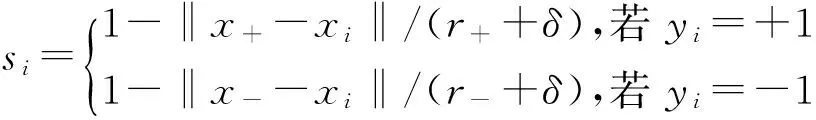
其中,δ>0主要用來避免si=0.
3 實驗研究
為了驗證提出方法的有效性,實驗中選取了11個數(shù)據(jù)集,分別來自于UCI和Statlog數(shù)據(jù)庫,所有數(shù)據(jù)集均為2類,具體特性如表1所示.值得說明的是Wine數(shù)據(jù)集為3類,但在實驗中將其轉(zhuǎn)換為2類數(shù)據(jù)集.在下面的實驗中,對于每個數(shù)據(jù)集,使用隨機(jī)方法分別抽取90%和70%比例的數(shù)據(jù)作為訓(xùn)練集,剩余的10%和30%數(shù)據(jù)作為測試集,實驗結(jié)果為執(zhí)行10次實驗后得到的平均值,結(jié)構(gòu)信息的獲取主要研究了直接計算每類的類內(nèi)離散度方法,同時與使用聚類方法獲取結(jié)構(gòu)信息進(jìn)行了比較.
為了表明結(jié)構(gòu)信息對支持向量機(jī)的影響,實驗中選取參數(shù)par=9.5進(jìn)行了研究,隨機(jī)選取的訓(xùn)練集比例為90%,實驗結(jié)果如圖1所示,其中縱坐標(biāo)表示10次實驗結(jié)果的均值和標(biāo)準(zhǔn)差.另外,與模糊支持向量機(jī)FSVM的實驗結(jié)果進(jìn)行了比較,如圖2所示.
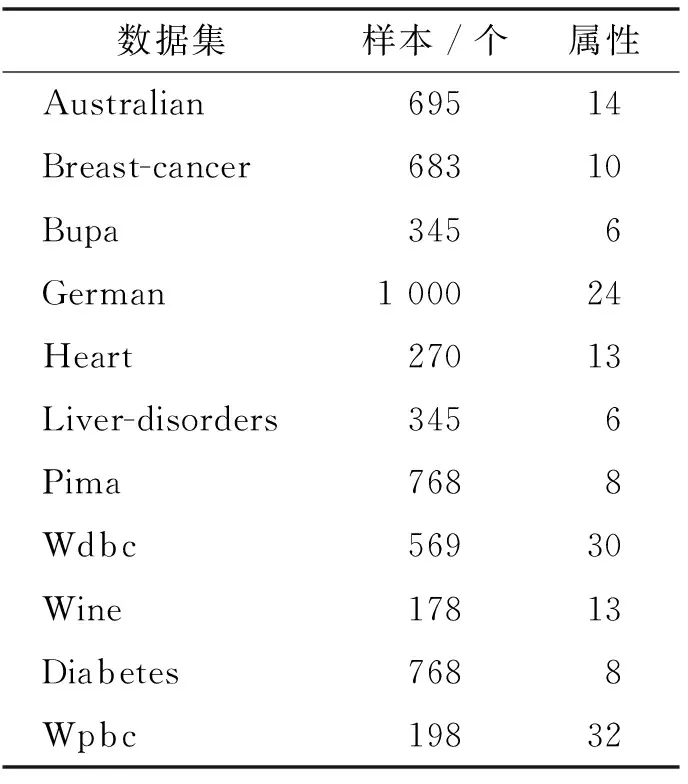
表1 數(shù)據(jù)集的特性
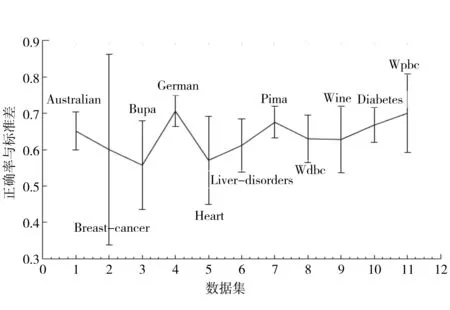
圖1 不同數(shù)據(jù)集的平均正確率與標(biāo)準(zhǔn)差Fig.1 Average accuracy and standard deviation on each data set
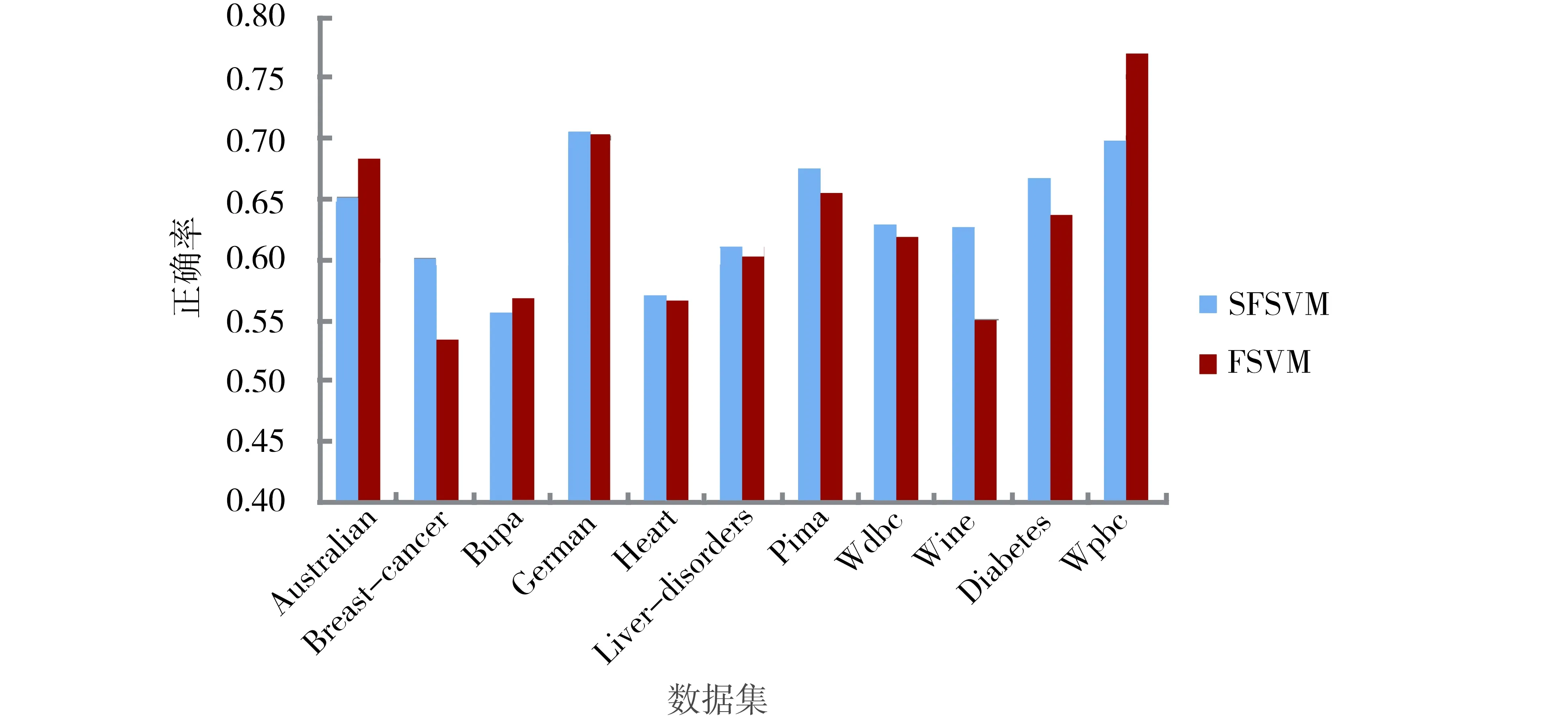
圖2 固定參數(shù)后的2種不同方法的平均正確率的比較 Fig.2 Comparison of average accuracy for SFSVM and FSVM on each data set with par=9.5
由圖2可以看到,在選取的11個數(shù)據(jù)集中,當(dāng)選取參數(shù)par=9.5時,在8個數(shù)據(jù)集中,提出的方法SFSVM的性能優(yōu)于模糊支持向量機(jī)FSVM,在另外的3個數(shù)據(jù)集Australian、Bupa和Wpbc的性能劣于模糊支持向量機(jī)FSVM.但是,可以通過合理設(shè)置參數(shù)par的值,使得提出的方法SFSVM在大部分?jǐn)?shù)據(jù)集上優(yōu)于模糊支持向量機(jī)FSVM,為了表明此種情況,對參數(shù)par的不同取值進(jìn)行了實驗研究,其取值范圍為[3,10],實驗結(jié)果如圖3與圖4所示,其中圖3標(biāo)出了取得較好結(jié)果的參數(shù)值,圖4給出了對應(yīng)參數(shù)的10次運行結(jié)果的平均值及FSVM的平均值.可以看到,除了Bupa數(shù)據(jù)集稍有下降外,在其他數(shù)據(jù)集都獲得了較好的性能.
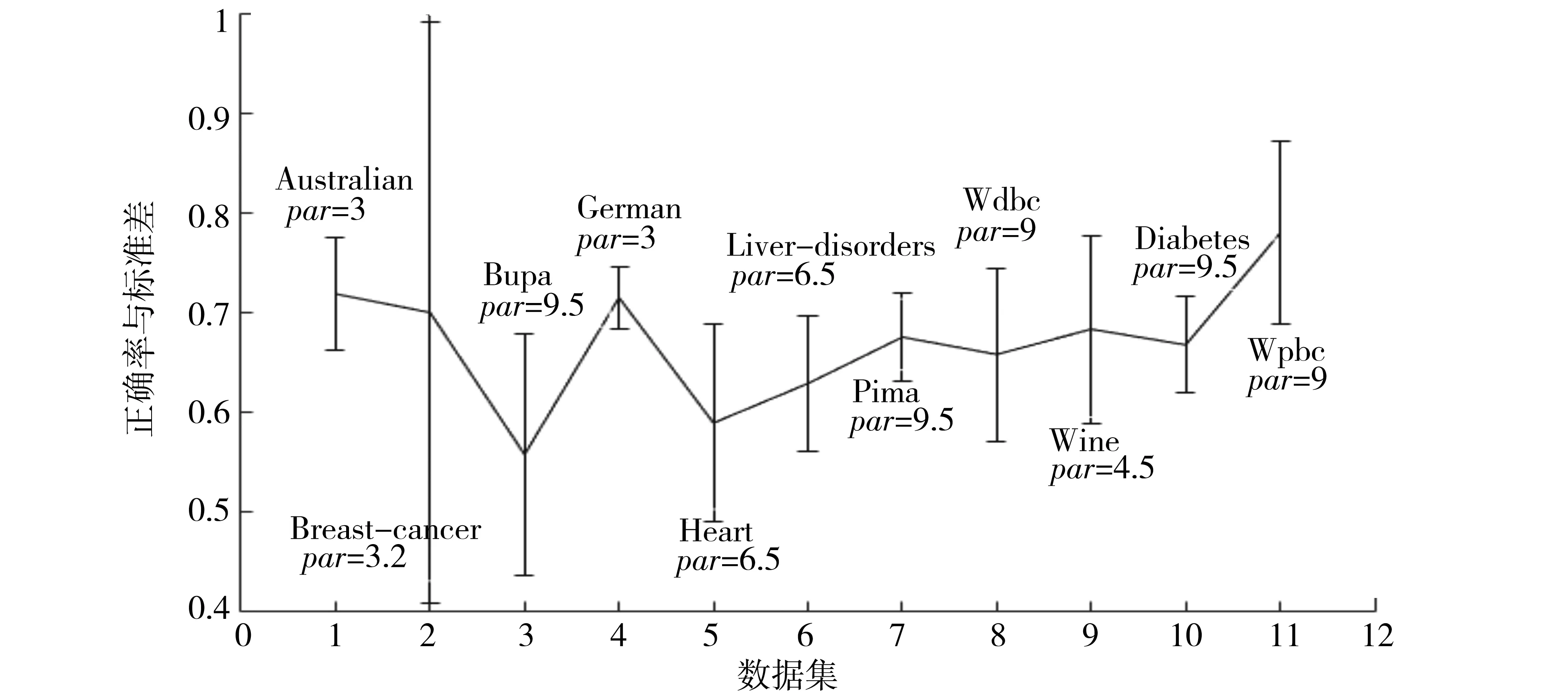
圖3 選取較好參數(shù)的每個數(shù)據(jù)集的平均正確率與標(biāo)準(zhǔn)差Fig.3 Average accuracy and standard deviation on each data set with better parameter value
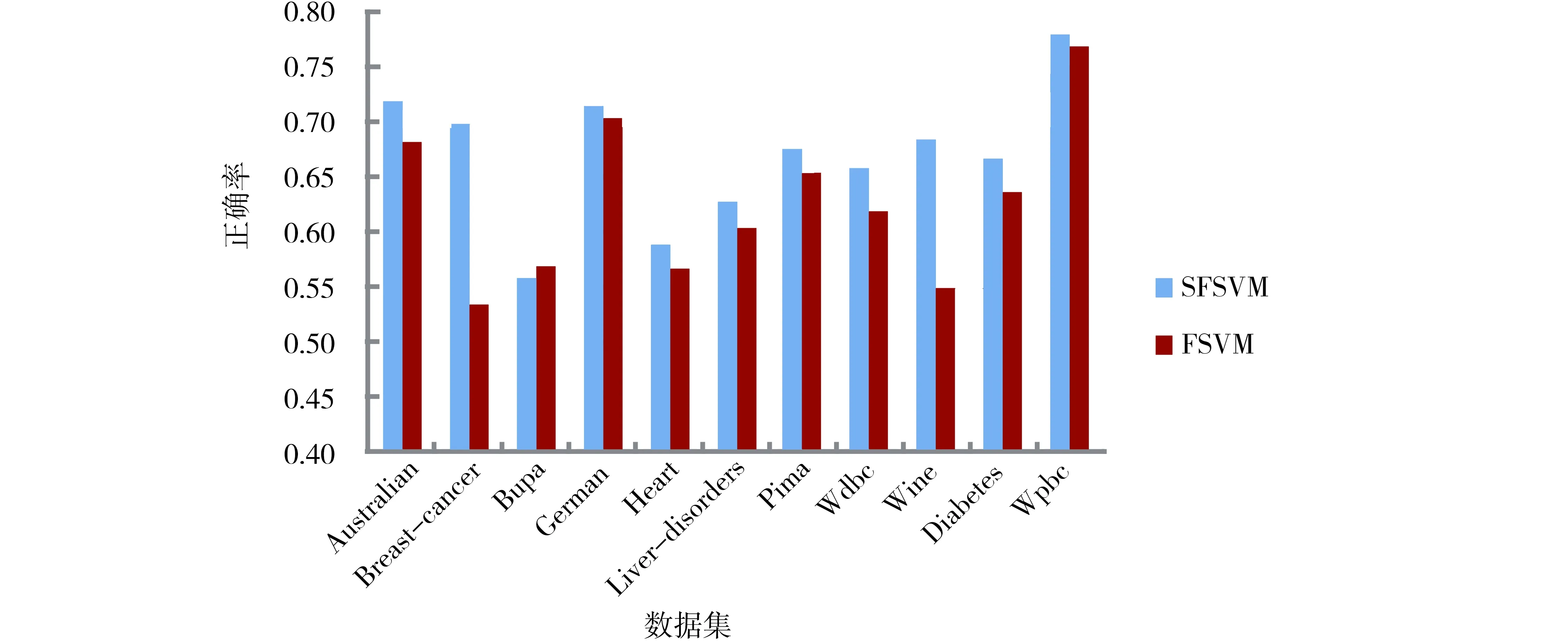
圖4 選取較好參數(shù)的2種不同方法的平均正確率的比較Fig.4 Comparison of average accuracy for SFSVM and FSVM on each data set with better parameter value
為了表明不同比例的訓(xùn)練數(shù)據(jù)對分類的影響,針對選取的70%的訓(xùn)練數(shù)據(jù)進(jìn)行了實驗,參數(shù)par的取值分別為4,4.5,5,5.5和6,實驗結(jié)果如圖5和圖6所示.由實驗結(jié)果可以看到,在9個數(shù)據(jù)集中,提出的方法SFSVM的性能優(yōu)于模糊支持向量機(jī),而在Bupa和Wine數(shù)據(jù)集上劣于FSVM,然而對于Wine數(shù)據(jù)集的性能,2種方法的正確率基本上保持一致.
另外,通過選取90%的數(shù)據(jù)作為訓(xùn)練集,聚類數(shù)目k=3且C=10,利用聚類技術(shù)獲取數(shù)據(jù)集的結(jié)構(gòu)信息也進(jìn)行了實驗,同時與FSVM及SFSVM 2種方法進(jìn)行了比較,為了區(qū)分2種不同獲取結(jié)構(gòu)信息的方法,用SFSVM-1和SFSVM-2分別表示直接使用類內(nèi)離散度和聚類技術(shù)獲取結(jié)構(gòu)信息的SFSVM,實驗結(jié)果如圖7所示. 可以看到,使用結(jié)構(gòu)信息的SFSVM的分類正確率在大部分?jǐn)?shù)據(jù)集上優(yōu)于FSVM,而使用2種方法獲取結(jié)構(gòu)信息的分類正確率在不同的數(shù)據(jù)集上各有千秋,實際上,可以針對不同的數(shù)據(jù)集,通過設(shè)置合理的參數(shù)獲得較好的分類性能.
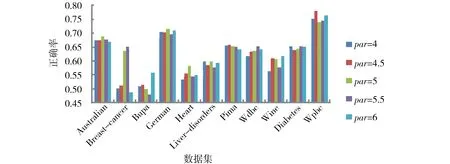
圖5 SFSVM在不同參數(shù)下的平均正確率Fig.5 Average accuracy for SFSVM on each data set with different parameter value
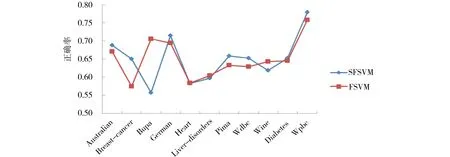
圖6 選取較好參數(shù)下SFSVM與FSVM的平均正確率比較Fig.6 Comparison of average accuracy for SFSVM and FSVM on each data set with better parameter value
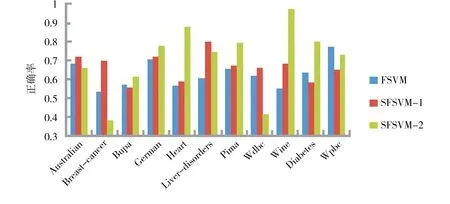
圖7 3種不同方法的平均正確率比較Fig.7 Comparison of average accuracy with three different methods
綜上所述,在模糊支持向量機(jī)中通過引入結(jié)構(gòu)信息,在一定程度上提高了支持向量機(jī)的泛化性能,然而,在一些數(shù)據(jù)集,例如Bupa等,引入結(jié)構(gòu)信息后反而使得支持向量機(jī)的性能有所下降,這主要是由于實驗中par的參數(shù)取值確定為[3,10],該問題的解決可以通過進(jìn)一步調(diào)整參數(shù)值獲得較好的性能.
4 結(jié)論
模糊支持向量機(jī)是在支持向量機(jī)的基礎(chǔ)上,通過考慮不同樣本的作用而提出的一種機(jī)器學(xué)習(xí)方法,然而,該方法只關(guān)注了類間的可分性,并未考慮樣本集中的結(jié)構(gòu)信息.在本文中,將樣本中的結(jié)構(gòu)信息引入到模糊支持向量機(jī)中,獲得了結(jié)構(gòu)型模糊支持向量機(jī)模型,利用拉格朗日方法,將其轉(zhuǎn)換為一個具有約束條件的優(yōu)化問題,通過求解該對偶問題,從而獲得結(jié)構(gòu)型模糊支持向量機(jī)分類器.通過選取標(biāo)準(zhǔn)數(shù)據(jù)集,實驗驗證了提出方法的有效性,在以后的工作中,進(jìn)一步研究使用聚類技術(shù)方法獲取結(jié)構(gòu)信息的模糊支持向量機(jī).
[1] VAPNIK V N. The nature of statistical learning theory [M]. New York:Springer, 1995.
[2] SCHOLKOPF B, SMOLA A J, WILLIAMSON R C, et al. New support vector algorithms [J]. Neural Computation, 2000, 12(5):1207-1245. DOI:10.1162/089976600300015565.
[3] SUYKENS J, VANDEWALLE J. Least squares support vector machine classifiers [J]. Neural Processing Letters, 1999, 9(3):293-300. DOI:10.1023/ A:1018628609742.
[4] LIN C F, WANG S D. Fuzzy support vector machines [J]. IEEE Transaction on Neural Networks, 2002, 13(2):464-471. DOI:10.1109/72.991432.
[5] LIN C F, WANG S D. Fuzzy support vector machines with automatic membership setting [J]. Studies in Fuzziness and Soft Computing, 2005, 177:233-254. DOI:10.1007/10984697_11.
[6] JIANG X F, YI Z, LV J C. Fuzzy SVM with a new fuzzy membership function [J]. Neural Computing and Application, 2006, 15(3-4):268-276. DOI:10.1007/s00521-006-0028-z.
[7] 楊志民.模糊支持向量機(jī)及其應(yīng)用研究[D].北京:中國農(nóng)業(yè)大學(xué), 2005. DOI:10.7666/d.y773695. YANG Z M. Fuzzy support vector machine and its application [D]. Beijing:China Agricultural University, 2005. DOI:10.7666/d.y773695.
[8] SHILTON A, LAI D T H. Iterative fuzzy support vector machine classification[Z]. IEEE International Conference on Fuzzy Systems, London, UK, 2007. DOI:10.1109/FUZZY.2007.4295570.
[9] HONG D H, HWANG C H. Support vector fuzzy regression machines [J]. Fuzzy Sets and System, 2003, 138(2):271-281. DOI:10.1016/S0165-0114(02)00514-6.
[10] YANG X W, ZHANG G Q, LU J. A kernel fuzzy C-means clustering-based fuzzy support vector machine algorithm for classfication problems with outliers or noises [J]. IEEE Transactions on Fuzzy Systems, 2011, 19(1):105-115. DOI:10.1109/TFUZZ.2010.2087382.
[11] YEUNG D, WANG D, NG W, et al. Structured large margin machines:sensitive to data distributions [J]. Machine Learning, 2007, 68(2):171-200. DOI:10.1007/s10994-007-5015-9.
[12] XUE H, CHEN S C, YANG Q. Structural regularized support vector machine:a framework for structural large margin classifier [J]. IEEE Transactions on Neural Networks, 2011, 22(4):573-587. DOI:10.1109/TNN.2011.2108315.
[13] XIONG T, CHERKASSKY V. A combined SVM and LDA approach for classification[Z]. International Joint Conference on Neural Networks, Montreal, Canada, 2005. DOI:10.1109/IJCNN.2005.1556089.
[14] ZHANG L, ZHOU W D. Fisher-regularized support vector machine [J]. Information Sciences, 2016,343-344:79-93. DOI:10.1016/j.ins.2016.01.053.
[15] HOUTHOOFT R, TURCK F D. Integrated inference and learning of neural factors in structural support vector machines[J]. Pattern Recognition, 2016, 59:292-301. DOI:10.1016/j.patcog.2016.03.014.
[16] HOU Q L, ZHEN L, DENG N Y, et al. Novel grouping method-based support vector machine plus for structured data[J]. Neurocomputing, 2016, 211:191-201. DOI:10.1016/j.neucom.2016.03.086.
(責(zé)任編輯:孟素蘭)
Fuzzy support vector machine based on structural information
LI Kai1, GU Lifeng1,ZHANG Lei2
(1.College of Computer Science and Technology, Hebei University, Baoding 071002, China;2.Department of Network and Information Security,Baoding City Branch of China United Network Communication Corporation Limited,Baoding 071051,China)
By considering the role of different samples on support vector machine, fuzzy support vector machine is presented based on support vector machine. However, it ignores the structural information of the given sample set. To this end, structural information of the given sample set is introduced into fuzzy support vector machine and obtained a structural fuzzy support vector machine model. It is converted to dual problem with quadratic programming using Lagrange method. Through solving this dual problem,the fuzzy support vector machine classifier is obtained. Experimental results in selected standard data sets demonstrate the effectiveness of the proposed method.
support vector machines;fuzzy support vector machine;structure information;within class scatter
10.3969/j.issn.1000-1565.2017.02.013
2016-08-04
國家自然科學(xué)基金資助項目(61375075)
李凱 (1963—),男,河北滿城人,河北大學(xué)教授,博士,主要從事機(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘和模式識別研究.E-mail:likai@hbu.edu.cn
TP 319
A
1000-1565(2017)02-0187-07
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
哲學(xué)評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
中外會展(2014年4期)2014-11-27 07:46:46
