電力圖形系統應用中SVG文件壓縮算法
2017-04-25 23:44:52盧軍雄鐘俊
數字技術與應用 2017年1期
盧軍雄+鐘俊

摘要:針對可縮放矢量圖形(SVG)作為矢量圖形格式優勢明顯,但存儲時占用內存較大和SVG文件數據大量冗余的特點,提出分別使用Huffman算法和LZSS算法對電力系統圖形數據載體SVG文件進行壓縮,在滿足壓縮時間的前提下,LZSS算法相對于Huffman算法壓縮率更高。LZSS算法性能能滿足電力系統應用SVG文件壓縮要求。
關鍵詞:電力圖形系統;SVG文件;Huffman;LZSS
中圖分類號:TN919.8 文獻標識碼:A 文章編號:1007-9416(2017)01-0115-04
隨著電力系統規模的擴大和系統結構越發復雜,利用計算機技術開發出界面友好圖形化軟件對于提高電力系統自動化具有重要的意義。SVG作為W3C推出的一種基于XML文本性矢量描述語言,被IEC61970推薦為圖形文件的基本格式,逐步成為行業標準[1]。SVG文件的優點為。
(1)表達能力強,刪除和添加方便;
(2)支持圖形無失真縮放;
(3)支持動畫和互動。
SVG文件是純粹的XML,擁有XML的所有特性,SVG作為電力圖形系統數據載體已逐步成為一種趨勢[2]。SVG文件以樹的形式管理SVG元素,SVG元素都是基本圖元與其屬性構成的文本,基本圖元有直線、圓、橢圓、文本、圓弧等,每一種圖元都有相應的屬性,如顏色、線寬、填充等。例如一個圓的SVG元素定義為
信息論之父Claude Shannon認為信息都存在冗余,SVG文件存在很多相同的屬性文本,信息冗余量很大,有必要對SVG文件進行壓縮。本文分別從統計編碼Huffman編碼和字典編碼LZSS兩種編碼方案對SVG文件進行壓縮,實驗表明LZSS壓縮算法的壓縮比更高。
1 Huffman編碼和LZSS編碼原理
1.1 Huffman編碼
Huffman編碼是一種基于統計的變長編碼,在編碼前統計各模式的頻率,根據不同模式的頻率采用不同長度碼字對其編碼(對于出現頻率高的模式,其編碼的長度最短)。Huffman采用前綴碼的方法表示每一個字符,前綴碼有時也稱前綴樹[3],其特點是任何一個字符的編碼都不能作為另外一個字符編碼的前綴,這樣可以大大簡化解碼過程,解碼器只需要識別一個完整的前綴碼就能解碼當前字符,而不需要進一步讀取后面的編碼。Huffman編碼的平均長度,在類似的編碼方案中,Huffman編碼獲得的編碼效果最好[4]。
Huffman編碼過程是通過Huffman樹的構建過程完成的。首先將字符的統計結果按照字符出現頻率的降序排列,記待編碼的數據為個數為n的字符集,集合;字符出現頻率為,,集合為Huffman編碼的二進制輸出,為字符對應的二進制編碼。編碼帶權路徑長度,為編碼輸出的二進制長度。構造一個Huffman樹的簡單過程如圖1。
表1展示了8個字符A∶K出現頻率和經過Huffman編碼后對應的二進制輸出。
編碼輸出的帶權路徑長度為=2.58,而采用二進制編碼需要的帶權路徑長度為3。根據表中字符出現的頻率選擇出現頻率最小的兩個字符A,B構造樹,其左孩子為A,出現頻率為0.01,右孩子為B,出現頻率0.05,根節點為左右孩子出現頻率之和0.06;并將字符A,B從字符集中刪除。同時將作為新的字符加入字符集中,此時頻率最小的兩個節點是和字符F,同樣按照構造樹方式構造出整個Huffman樹如圖1。
1.2 LZSS編碼原理
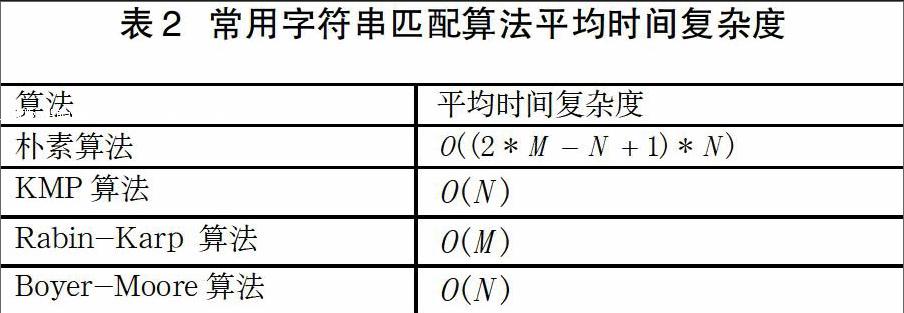
LZSS編碼原理不同于基于統計方式的Huffman編碼,它是基于字典壓縮算法LZ77算法的改進,不再需要統計字符出現頻率[5]。LZ77使用已出現的字符串的相關信息來表示當前需要被編碼的字符串,在此過程中使用滑動窗口完成字符流的輸入和字符串的匹配。在編碼過程中,字符緩沖區的大小設定為N,已壓縮好字符串的長度為M(M 壓縮開始前,緩沖區設為空,字符串以字符流的方式從右至左進入超前查看緩沖區,找出超前查看緩沖區和正文窗口的匹配的最長字符串,假設找到最長匹配字符串,其起始位置為s,長度為L(長度可以為0),出現第一個不匹配的字符位置為e,這樣從當前編碼位置開始到第一個不匹配的字符可以編碼為,且滿足。如果編碼信息占用空間比個字節小,便實現了字符串的壓縮。具體算法流程如圖3。 LZ77壓縮算法存在時間和空間的性能約束: 在壓縮時間上存在性能瓶頸:超前查看緩沖區字符與正文字典匹配采用的是線性的匹配方式,超前查看窗口的大小為,正文窗口大小為M,表2給出了常用字符串匹配算法的平均時間復雜度[7]。 表2給出的算法時間復雜度最好的情況還是線性的,LZ77算法正文窗口一般設置為幾千,超前查看緩沖區設置位十幾,在進行字符串匹配時嚴重影響算法的時間性能[8]。而且都是相關窗口大小成正比。算法在壓縮空間也存在缺陷:當未找到匹配字符串時,輸出三元組占用的空間比需要進行編碼的字符串占用的空間更大,出現負壓縮的情況。 LZSS算法針對LZ77算法的這兩點缺點作出了改進。LZSS采用二叉查找樹技術替換了滑動窗口的線性查找,超前查看緩沖區字符串進入正文窗口時需要按照二叉查找樹的特征加入到二叉樹中,采用二叉查找樹技術字符串的匹配時間極大優化,在壓縮時間上極大地提高了壓縮性能[5];LZSS在編碼輸出采用位標志方式區別輸出,輸出時編碼輸出與設定最小字符串長度的大小,只有在編碼輸出字節數較小采用編碼輸出,反之輸出真正的字符。
2 Huffman編碼與LZSS算法實現
2.1 Huffman編碼的實現
SVG文件字符采用單字節編碼,統計每個字符出現次數使用huffman_node *huffmanArray[0xff]數組便可以將SVG文本字符統計完整。Huffman樹節點的數據結構為:
typedef struct huffman_node
{
unsigned char value;
unsigned int count;
bool isDealt;
struct huffman_node *left, *right, *parent;
} huffman_node;
Huffman_node中value表示該節點代表的字符,isDealt表示該字符是否已被處理,在查找字符出現頻率最小的兩個中經常使用此標記。根據huffmanArray統計結果查找出現頻率最小的兩個字符,分別作為新建二叉樹的左右孩子,二叉樹父節點統計頻率為左右孩子出現頻率之和,并將已加入二叉樹的字符標記為已處理。二叉樹仍然可以按照單個字符處理,直到所有的字符都被加入Huffman樹中。在給編碼數組編碼時首先訪問Huffman樹最左邊的葉子節點,設定其編碼為‘0,然后通過parent指針訪問右節點設定編碼為‘1,再次通過parent回到父節點,避免使用遞歸方式遍歷樹結構帶來的時間開銷。通過已經編碼過的編碼數組為SVG文件每一個字符編碼,直到文件結束。Huffman編碼模塊劃分如圖4。
由于SVG文件所使用的字符都是8位編碼字符,編碼數組的長度為0xff。編碼數組的數據結構為
typedef struct code_list
{
byte_t codeLen;
unsigned int *code;
} code_list;
2.2 LZSS編碼的實現
根據前述的LZ77算法,改進后的LZSS算法在編碼輸出和字符串匹配上實現了優化。其算法的如流程圖5。
實現算法的相關數據結構:
超前查看緩沖區和正文緩沖區,根據文件內容上下文依賴關系正文緩沖區大小不盡相同,定義宏WINDOW_SIZE大小為4K,用12bits來表示,所以需要4bits來表示字符串的長度。超前查看緩沖區一般設置為18bits。定義最長不可編碼長度為MAX_UNCODED,當匹配字符串與MAX_UNCODED比較時,可以使用ENCODE與UNCODE來標識輸出。最大可編碼長度為超前查看緩沖區大小設置為MAX_CODE,由匹配字符串長度和最長不可編碼長度決定。
字符串編碼使用封裝長度和位置的數據結構:
typedef struct encoded_string
{
unsigned int offset;
unsigned int length;
} encoded_string;
offset和length可以分別得到字符串編碼信息:位置和長度。
二分查找樹是二叉樹的一種變形,二分查找樹根節點存儲的關鍵字總是大于其左子樹的關鍵字,小于右子樹的關鍵字。在建立二分查找樹時要按照二叉樹關鍵字的性質建立,對于N個節點的二分查找樹查找關鍵字時,最好的情況下時間復雜度為,大大加速了查找時間。該算法使用的二叉樹結構為:
typedef struct tree_node
{
unsigned int left;
unsigned int right;
unsigned int parent;
} tree_node;
該結構體中的left,right,parent都是指向正文緩沖區字符的索引;使用tree_node tree[WINDOW_SIZE]對應每一個正文緩沖區的字符。
在算法進入主循環前需要對正文緩沖區,超前查看緩沖區和二分查找樹初始化,InitializeSearchTree()完成樹的初始化工作,二分查找樹根節點ROOT_INDEX為依照正文緩沖區建立字符串的最后一個窗口為WINDOW_SIZE - MAX_CODED-1,為方便查找和插入操作空節點NULL_INDEX為ROOT_INDEX+1。初始化樹根節點的父節點為ROOT_INDEX;剩余所有節點左右孩子和父節點全部清空。
只有超前查看緩沖區不為空,壓縮算法將持續進行,主要是對位于超前查看緩沖區的字符串進行編碼,二分查找樹的字符串刪除和添加;MatchString()算法利用二分查找樹返回匹配字符串位置和長度,從根節點開始查找匹配字符,如匹配即利用左右節點關鍵字關系進行下一個字符匹配,直到搜索到葉子節點。將以編碼過的字符串加入二叉查找樹由AddString()完成,在向二分查找樹添加字符串的同時需要將樹中舊的字符串刪除DeleteString()。
3 壓縮算法性能與實驗
衡量壓縮算法的性能主要有壓縮率和壓縮耗時,但是這兩個指標之間存在矛盾,只能在合適的應用場景折中選擇。定義壓縮率=壓縮文件大小/源文件大小*100%,壓縮率越小表明壓縮效果越好;壓縮耗時是指壓縮完文件所需時間。
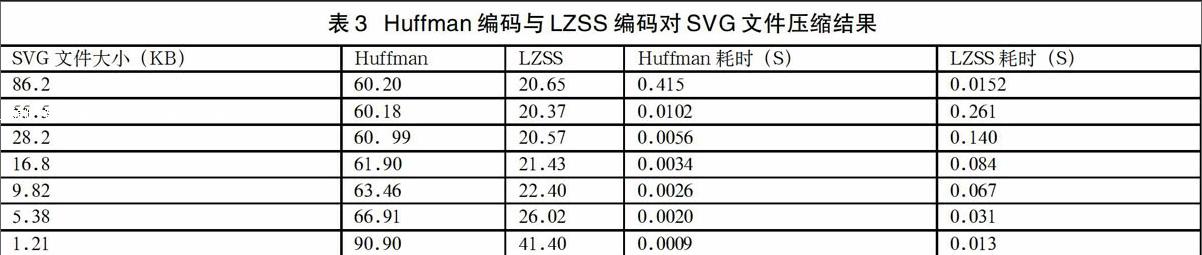
實驗設備采用采用Ubuntu 15.10操作系統,CPU型號為Intel(R) Core(TM) i5@2.53GHz,內存大小為4G,Huffman算法和LZSS算法運行環境相同。壓縮數據源為電力系統圖形界面SVG文件。實驗結果如表3。
從表3可以看出對Huffman壓縮算法在壓縮時間上比LZSS算法好,但LZSS壓縮算法在壓縮比性能上比Huffman壓縮效果好,在存儲空間較小的應用場合有一定的應用場景。對于特定的壓縮算法,文件在較大時其壓縮效果比小文件更好,在電力圖形化系統中SVG文件越大,其信息冗余越多,可以壓縮的空間越大,壓縮率也相對高一些。
參考文獻
[1]紀陵,蔣衍君,施廣德.基于SVG的電力系統圖形互操作研究[J].電力自動化設備,2011,31(7):105-114.
[2]李為,潘秀霞,等.基于SVG標準的電力系統圖形編輯器的設計與實現[J].中國電力教育,2008年研究綜述與技術論壇專刊.
[3]Utpal Nandi, Jyotsna Kumar Mandal. Windowed Huffman coding with limited distinct symbols[J]. Procedia Technology, 2012, 4:589-594.
[4]Yi Zhang, Zhili Pei, Jinhui Yang, Yanchun Liang. Canonical Huffman code based full-text index[J]. Progress in Natural Science, 2008, 18(3):325-330.
[5]王平著.LZSS文本壓縮算法實現與研究[J].計算機工程.2001年8月.第27卷(第 8期).
[6]閭松林.基于字典編解碼算法的應用與研究[D].湖南長沙,中南大學,2011:9-11.
[7]王堅.基于后綴數組的滑動窗口匹配壓縮改進算法研究[D].湖北武漢,華中科技大學,2012:7-10.
[8]蔡成攀.無損數據壓縮技術在嵌入式系統中的應用[D].陜西西安,西安電子科技大學,2007,14-18.
