弱監督任意姿態人體檢測*
2017-04-17 01:39:11蔡雅薇譚曉陽
計算機與生活 2017年4期
蔡雅薇,譚曉陽
南京航空航天大學 計算機科學與技術學院,南京 210016
弱監督任意姿態人體檢測*
蔡雅薇+,譚曉陽
南京航空航天大學 計算機科學與技術學院,南京 210016
弱監督;人體檢測;任意姿態;多示例學習
1 引言
多姿態人體檢測在日常生活中有很多重要的應用[1]。例如在人類行為估計中[2],人們首先需要檢測人體的位置,為頭、手、腳等其他部分提供參考定位。對于智能機器人,它的活動必須避免碰撞人類,但房間里的人不會總是直立的,他們可以是趴著、坐著、躺著,或者是其他姿態。圖1說明了一些不同姿態的人體,其中的圖片來自LSP數據集[3]。因此檢測任意姿態的人體變得十分必要[4]。

Fig.1 Illustration of human body under different poses圖1 不同姿態的人體說明
但是這個課題并未受到足夠的關注。與之相關的課題中,被研究最多的是行人檢測問題[5],它有著廣泛的應用,尤其在城市智能交通系統。目前其性能已經達到了很高的水平[6],這為多姿態人體檢測在很多方面(例如特征提取、模型選擇、評估方法)提供了寶貴的經驗。但是行人檢測本身主要關注直立姿態的人體。
任意姿態的人體檢測面臨著多個挑戰,除了大量的外形變化,多種姿態使人工標注工作變得困難和費力,因此通常只能得到弱標記的樣本。多示例學習(multiple instance learning,MIL)是克服這些挑戰的一個很好的工具,因為它放松了對精確標記的要求。在多示例學習中,人們甚至不需要注釋真實數據(ground truth),只需要標注圖片中是否存在感興趣的對象即可。最近,Cinbis等人[7]將多示例學習用于一般的對象檢測并在Pascal VOC 2007數據集上得到了較好的結果,體現了這個方法的潛力。但是他們沒有重點關注多姿態人體檢測問題以及一些多示例學習的實現細節,例如樣本選擇、參數設置等。
本文主要提出了一種新的選擇性弱監督檢測算法(selective weakly supervised detection,SWSD),并給出了這個課題的深度評估,關注了以下重要但很少被研究的問題:首先,通過比較監督學習和多示例學習的性能,探究了在弱監督環境下多示例學習的能力;第二,研究了對于多示例模型訓練,什么樣的訓練樣本最有幫助,證明了SWSD算法的合理性;第三,測試了不同示例概率融合策略的效果;最后,驗證了SWSD算法的優越性。
本文在被認可的Pascal VOC 2007[8]的person數據集上進行了發廣泛的評估,并且得到了幾個有趣的實驗結論,希望能為后面的研究者提供幫助。
本文組織結構如下:第2章介紹弱監督檢測的相關工作;第3章給出多示例學習算法以及SWSD算法;第4章闡述評估路線;第5章呈現綜合性弱監督多姿態人體檢測的實驗評估;第6章總結了主要的實驗結論。
2 相關工作
2014年,Girshick等人為對象檢測提出了R-CNN(regions with CNN features)框架[9],他們采用Selective Search算法生成檢測提議。之后,很多人在此基礎上進一步提高了檢測準確度。目前Pascal VOC 2007上最好的人類檢測平均精確度(average precision,AP)已經達到70.1%[10],相信很快就會有新的突破。但是這些監督學習都建立在大量的精確注釋和時間代價的基礎上,因為在卷積神經網絡(convolutional neural network,CNN)中存在太多的模型參數需要訓練調整。
人們希望以最少的監督信息定位對象,因此弱監督對象檢測在提出之后得到了不斷的發展。2011年,Pandey和Lazebnik[11]結合了DPM(deformable parts model)和隱SVM(support vector machine)模型,證明了DPM也可以勝任弱監督對象的定位任務。Siva和Xiang[12]提出了弱監督學習框架,使用一種新的初始化注釋模型來啟動檢測器的迭代學習。2012年,Russakovsky等人[13]根據已知對象位置能對圖像分類有幫助的直覺,提出了對象中心空間池方法。
2014年,Song等人[14]結合有識別力的子模塊和平滑隱SVM模型,可以自動觀察正對象窗口。同年,他們也提出了自動識別具有區別力的視覺模式的方法[15]。Bilen等人[16]提出了基于從CNN提取的特征和隱SVM模型的方法,可以找出圖片中的多對象示例。Wang等人[17]提出了潛在類別學習,首先使用典型的概率潛在語義分析學習潛在類別,然后決策哪個類別包含目標對象,并且還提出了用于評估每個類別區別力的類別選擇方法。
2015年,Cinbis等人[7]對正訓練圖片進行迭代訓練并指出對象位置。他們的主要貢獻在于多重多示例學習過程,避免了提前鎖定到錯誤的對象位置。他們也通過從CNN中提取特征提高了多示例檢測的性能。目前弱監督人體檢測最好的AP為20.3%,顯然還有很大的提升空間。
3 多示例檢測
以下簡單描述如何將多示例學習用于對象檢測,介紹兩種多示例學習算法,并重點關注選擇性弱監督檢測算法。
3.1 多示例學習
在多示例學習中[18],數據集由N個包組成,用表示。其中代表第i個包,它是多示例訓練中的單元,如同監督學習中的一個樣本,M為包中的示例數量,xij為包中的一個示例;ti為包的標記,但示例沒有標記。包的標記主要取決于包中是否包含正示例。那意味著,只有包中沒有任何正示例,這個包即被稱為負包(ti=0),否則這就是一個正包(ti=1)。在這個定義下,不能確定正包中哪個示例為正示例,這一點加大了多示例算法的挑戰。為了實現好的性能,模型必須能夠足夠魯棒地對抗正包中的噪聲數據。
在對象檢測環境下,一個候選窗口被視為一個示例,多個候選窗口組成一個包。這樣就可以訓練多示例對象檢測模型,但在測試的時候,每個候選窗口(示例)必須被指定一個標記,這似乎直接違背了多示例學習的定義,因為示例沒有明確的標記。可以通過示例層次的模型預測來避免這個問題,或者將單一的測試示例視為只有一個示例的包,然后使用包層次的模型預測。
正式地,用 pij表示示例xij為正的概率。為了估計包層次的條件概率pi,可以使用不同的策略融合示例層次的概率。兩個最常見的方法為最大匯合(Max Pooling)和噪聲或模型(Noisy-or)。

Max Pooling策略的目標是找出包中最可能為正的示例,并不關心包中其他示例的標記。相對地,Noisy-or模型考慮了所有示例,但假設它們之間相互獨立。
不同的多示例學習算法的差異體現在很多方面,例如示例模型(pij)、損失函數、優化方法等。文獻[18]給出了最近的綜述。本文實驗中主要感興趣于兩種多示例學習算法,多示例邏輯回歸(MIL_LR)[19]和多示例AdaBoost算法(MIL_AdaBoost)[20]。下面將簡單介紹這兩種算法。
3.2 多示例邏輯回歸
多示例邏輯回歸是一種線性分類器,在這個意義上,對于每個示例xij,它的輸出標記yij可以被線性模型化為yij=wTxij+b,w和b為待學習的參數。使用sigmoid函數模型化示例為正的概率為。本文使用負的似然函數作為損失函數來訓練模型:
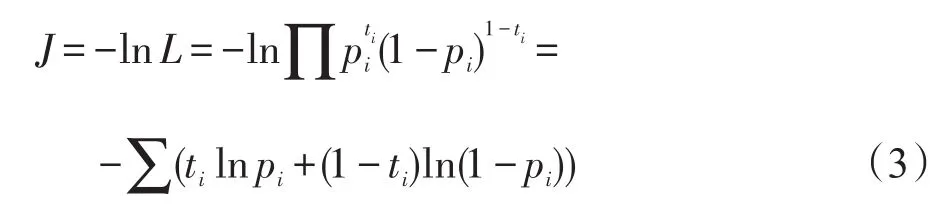
通過梯度下降法優化參數:

MIL_LR和一般的LR算法的區別在于,在學習參數時,MIL_LR還需要考慮每個包的似然對包中示例的影響,即,而一般的LR算法則不需要。有趣的是,這個比例與示例融合策略有關。特別是在Max Pooling下,它僅僅依賴于獲勝的示例xij*,而且,其中。如果線性模型合理,這個性質使得Max Pooling對不準確的注釋非常魯棒。但在Noisy-or模型下,每個示例對計算這個比例都起作用,有時這意味著包中的一些困難示例可能有機會潛在地誤導學習。
3.3 多示例AdaBoost
在AdaBoost算法的多示例版本中[20],示例層次的預測模型C(xij)由多個弱分類器的輸出線性組合構成,即C(xij)=∑λtct(xij)。換言之,不同于MIL_LR模型,輸出標記yij對于相應的xij是非線性的。多示例AdaBoost的目標是在多示例框架下學習一組弱分類器ct(xij),以及組合系數λt。
特別地,為了學習下一個弱分類器ct,首先要固定目前已經學到的分類器,然后用它對每個xij估計yij。然后用sigmoid函數將yij過渡到pij,接著用Max Pooling或者Noisy-or模型融合到 pi。最后,MIL_ AdaBoost的學習問題歸結為最大化下面的似然函數:
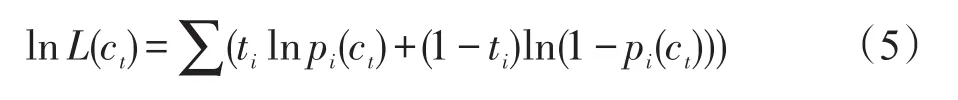
這個問題可以在ct所屬函數空間上,通過梯度上升搜索來解決。之后,執行簡單的線性搜索就能估計λt的值。
3.4 選擇性弱監督檢測
在多示例學習框架的基礎上,希望進一步提高弱監督檢測的性能。本文提出一種新的選擇性弱監督檢測算法SWSD。它利用了少量監督樣本的優勢,雖然無法獲取大量的監督樣本,但是可以手工標注少量的ground truth。這些ground truth所需的代價很小,但可以發揮重大作用。之所以設計這個算法是因為與ground truth重合越大的示例對多示例訓練越有幫助,需要通過算法找出這些高質量的示例。本文將通過實驗證明該觀點。SWSD算法使用很少的ground truth來迭代選擇高質量示例,模型訓練過程如下。
算法1選擇性弱監督檢測算法SWSD
(1)初始化訓練集S:包括由M個ground truth和M個正包中的負示例組成的監督樣本,以及N個空的訓練正包。
(2)For iterationt=1toT
①通過監督學習和多示例學習,用S訓練一個檢測器;
②用這個檢測器測試所有正訓練圖片中剩下的檢測提議;
③在每張圖片中選擇n個得分最高的提議作為示例加入到相應的訓練正包中,更新S。
(3)輸出最終的檢測器。
另外,對于迭代次數T,可以采用交叉驗證的方法來尋找最優解。圖2給出了SWSD算法的簡要過程。其中虛線框內的部分是本文方法的創新之處。在多示例學習框架中,從未關注過訓練正包中的示例組成,而SWSD算法通過選擇提議來提高正包中正示例的比例,從而提升算法的準確度。

Fig.2 Procedure of SWSD圖2SWSD算法過程
4 評估路線
下面將介紹弱監督人體檢測的評估路線,主要包括4部分,即檢測提議的生成、特征表示、多示例學習和檢測、后期處理過程。圖3給出了評估過程及方法。

Fig.3 Procedure and methods of evaluation圖3評估過程及方法
4.1 檢測提議生成
雖然滑動窗口[21-23]是最常用的檢測提議(候選窗口)生成方法之一,但在本文的工作中,采用選擇性搜索(Selective Search)算法[24-26],它能產生很多的稀疏提議,并且不會損失圖片中的主要信息。Selective Search算法的主要思想基于感興趣的對象具有相似的視覺特征的假設,而且能夠通過這些特征將它們從背景中分離,這大大減少了對象提議的數量。在文獻中還提到了很多其他的方法,例如MCG(multiscale combinatorial grouping)[27]、Objectness[28]、隨機種子[29],它們都可以用于這個目的。
4.2 特征表示
如何獲取最具區別力的特征一直是模式識別領域的重要問題之一。已經有很多不錯的特征表示方法供人們選擇,例如HOG(histogram of oriented gradient)特征[30]、SIFT特征(scale-invariant feature transform)[31]、HSV(hue,saturation,value)特征[32]等。深度卷積神經網絡[33]由于在實際中的卓越性能,成為一種受歡迎的特征表示方法。
在本文的工作中,選擇VGG網絡[34],這是一個38層的深度網絡,最初是在ImageNet[35]數據集上訓練得到。本文使用第37層的輸出作為最終的特征表示,也就意味著,每個提議都會映射成一個1 000維的向量,作為多示例學習模塊的輸入。注意到本文并沒有在原有VGG網絡的基礎上進一步微調,因為從Image-Net數據集上學到的特征空間足夠描述人體圖片。
4.3 多示例學習和檢測
如何合適地定義正包是多示例學習中一個棘手的問題。在弱監督環境下,人們無法獲得圖片中每個對象的ground truth邊界框,只能將一張正例圖片的所有提議組成一個正包。在其他情況下,當已知ground truth,就可以縮小正包的尺寸,因為只需要考慮和ground truth的IOU(intersection over union)大于0.5的示例,通常將它們視為正示例,否則即為負示例。圖4給出了ground truth邊界框、正示例和負示例的說明。

Fig.4 Illustration of ground truth bounding box,positive instances and negative instances圖4 ground truth邊界框、正示例和負示例的說明
由于MIL_LR和MIL_AdaBoost算法在本質上具有不同的復雜性,集成它們是有利的。對于示例xij,用和分別表示它在兩種算法下的得分輸出,那么xij的最終得分定義為:

4.4 后期處理
人們提出了很多方法用于提高最終預測窗口的準確率,例如邊界調整法[7]和邊界框回歸法[9]。本文使用一種基于聚類思想的簡單但有效的方法。特別地,在每個測試包中,只考慮得分的示例作為候選輸出。在這些候選中,選擇得分最高的作為一個聚類中心,如果其他示例和這個中心有超過30%的重疊,就認為這個示例屬于這個類,否則將它作為一個新的聚類中心。對所有剩下的示例進行此操作,直到所有的候選都被分配到某個類別中。最后,取每個類別的平均值統計量給出位置和邊界框的預測。
5 實驗
有很多因素影響著SWSD算法,尤其是對其中的多示例學習部分。以下討論正示例比例、融合策略和示例質量的影響,同時說明SWSD算法的合理性及優越性。
5.1 實驗數據及設置
這一部分將描述實驗設置,包括訓練數據和測試數據的構成以及評估協議。對于多示例訓練,構造了一個由4 916張圖片組成的訓練集,其中2 000張是從LSP數據集[3]上選取的正例,每張圖片中包含一個人體。另外2 916張是從Pascal VOC 2007[8]的人類訓練集上選取的負例,不包含任何人體對象。對于測試,直接使用Pascal VOC 2007的人類測試集,包括4 952張圖片,其中2 007個正例共包含了4 528個人體對象。
圖1和圖5分別展示了LSP數據集和Pascal VOC 2007中的人體圖片。可以發現Pascal VOC 2007中的一些圖片非常具有挑戰性,有的太小,有的被部分遮擋,見圖5最下面一行。但是這些特征可幫助測試檢測器的魯棒性。另一方面,LSP數據集上的目標更加明顯,包含了更多的有效信息,將有利于多示例模型的訓練。
本文使用平均準確率AP評估人體檢測的性能。AP基于精確度,即正確檢測與所有預測之比,也是以回歸率為橫軸,精確度為縱軸的曲線下的面積。
5.2 基準線
本文使用了兩個不同的基準線,一個是相同圖片樣本下監督學習的性能,另一個是只使用100個正例樣本的DPM的性能。由于想要證明多示例學習在某些情況下優于監督學習(supervised learning,SL),還想提高只有少量監督樣本情況下的檢測性能,因此需要兩個基準線。
對于監督學習,使用在LSP數據集上標注的2 000個ground truth和2 916張Pascal VOC 2007上的負例圖片作為訓練樣本。分別測試了SL_Ada-Boost、SL_LR和SL_LR+SL_AdaBoost的性能。對于DPM,直接使用Pascal VOC 2007的person訓練集,其中包括2 095個正例和2 916個負例。在實驗中,從2 000到100逐漸減少正例的數量,相應地,負例數量與正例數量相等。這兩個實驗均為監督學習實驗。

Fig.5 Illustration of human body images in Pascal VOC 2007圖5 Pascal VOC 2007中人體圖片說明
表1列出了3種監督方法的AP,可以看出SL_ AdaBoost+SL_LR算法的性能最好。本文的監督學習性能低于R-CNN框架是必然的,因為只使用了2 000個正例樣本,并且也沒有采用復雜的檢測算法。它僅僅用于對比多示例學習。圖6說明,當正例數量為2 000時,AP為35.96%,但降為100時,AP只有24.62%。根據這條曲線,發現DPM的性能隨著正例樣本數量的減少而降低,因此當監督信息很少時,DPM難以發揮作用。

Table 1 AP of supervised learning表1 監督學習的AP
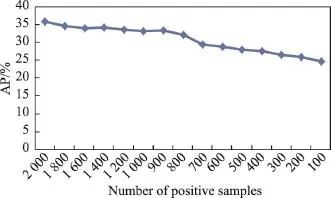
Fig.6 AP of DPM with different numbers of positive samples圖6 在不同正例樣本數量下DPM的AP
5.3 正示例比例的影響
為了得到更好的性能,應該選擇合適的樣本用于訓練。包中正示例比例(ratio of positive,ROP)對檢測性能的影響將指導人們如何構造訓練集。
在這組實驗中,變量為ROP,在第1次實驗中,向每個訓練正包中只添加正示例,在第2至20次實驗中,逐漸加入負示例。因此,ROP將從100%不斷下降至5%。所有的訓練正包中均不包含ground truth。本文使用Max Pooling估算包概率。
圖7展示了MIL_AdaBoost、MIL_LR和MIL_ AdaBoost+MIL_LR算法的結果。可以發現三者的AP都隨著ROP的下降而減少。其中,性能最好的MIL_AdaBoost+MIL_LR的AP從39.98%降低至14.56%。這證明了ROP是影響多示例性能的關鍵因素,從而SWSD算法中的迭代選擇過程是合理的。
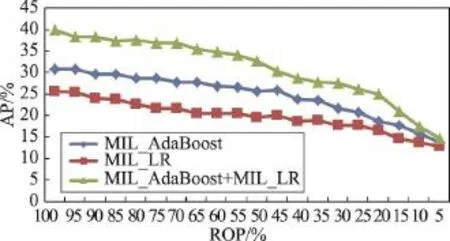
Fig.7 AP of 3 algorithms with reduction of ROP圖7 隨著ROP的減小3種算法的AP
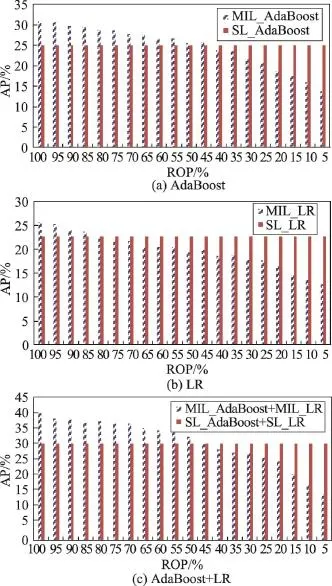
Fig.8 Comparison between MIL and SL圖8MIL與SL的比較
根據圖8可以看出,MIL_AdaBoost算法的AP在 ROP大于45%時優于SL_AdaBoost,MIL_LR算法的AP在ROP大于85%時才優于SL_LR算法,MIL_Ada-Boost+MIL_LR的性能也只在ROP大于45%時優于監督學習。因此只有ROP是個較大值時,多示例學習才會比監督學習更好。
可以觀察到不論在監督學習,還是在多示例學習中,AdaBoost和LR的集成方法性能都是最好的,因此在下面的實驗中,只采用此方法。
5.4 融合策略的比較
上面的實驗中,選擇的估算包概率的融合策略為Max Pooling(MIL-max),如式(1)所示,它只關注包中最可能為正的示例,忽略了其他示例。式(2)中的Noisy-or模型(MIL-nor)則綜合了所有示例的情況,但是當包中示例數量較大時,假設為1 000,即使包中每個示例為正的概率為0.1,包為負的概率為(1-0.1)1000≈1.7×10-46。因此本文考慮只使用3個最可能為正的示例用于計算。此外,也嘗試使用更多的示例,但是實驗效果更差。
這組實驗和上一組的實驗形成對比,因此訓練正包中也不包含ground truth。每次實驗中包中的示例也是相同的,唯一不同的是,模型訓練時,所選的融合策略為Noisy-or模型。
Noisy-or模型和Max Pooling的AP比較如圖9所示。Noisy-or模型的性能遠遠低于Max Pooling的性能。MIL-max最高AP為39.98%,而MIL-nor最高只有23.95%。而且,MIL-nor的曲線一直在監督學習(SL)基準線的下方,這說明使用Noisy-or模型的多示例學習不如監督學習。

Fig.9 Comparison among MIL-max,MIL-nor and SL圖9 MIL-max、MIL-nor與SL之間的比較
5.5 提議質量
在上面的兩組實驗中,每個訓練正包中都不包含ground truth。本文定位正示例為與ground truth的 IOU大于0.5的示例,但是采用剛剛大于0.5的提議作為示例來訓練顯然是不夠的,需要高質量的示例來訓練更好的模型。本文通過實驗評估提議的質量。
在這組實驗中,所有設置均與上一個實驗相同,每次實驗包中示例也相同,除了在每個訓練正包中額外加入了ground truth。依舊分別使用Max Pooling和Noisy-or模型估算包為正的概率。
圖10展示了訓練正包中是否包含ground truth對檢測性能的影響。發現包含與不包含的情況之間只有極小的差距。前者最好的AP為40.02%,而后者最好也達到39.98%。所有20次實驗中,兩者之間的差距都在1%左右,這說明在LSP數據集上Selective Search可以提供類似ground truth的提議,并且它們可以在多示例訓練中起到ground truth的作用。還觀察到,即使添加了額外的ground truth,MIL-nor的性能依然很差。因此認為Noisy-or模型并不適用于多示例檢測。在本文下面的實驗中,只采用Max Pooling策略。

Fig.10 Comparison between whether containing ground truth圖10 是否包含ground truth之間的比較
5.6SWSD算法性能
通過上面的實驗已經知道,正示例比例越大檢測性能就會越好。但如果將所有的提議都作為示例,正示例的比例只有大約30%,因此需要采用SWSD算法選擇好的提議,提高包中正示例比例。
有兩種方法用于構造訓練正包:一種是隨機法(random),即初始化訓練正包為空,然后每次實驗隨機向包中添加示例,直到所有提議都作為示例加入包中。那么每個包中示例數量與提議總數之比IOP(instances over proposals)就從5%增加至100%。另一種就是SWSD算法中所采用的選擇法(selective),本文使用100個ground truth和100個正包中的負示例來訓練原始檢測器,然后每次選擇5%的提議加入到相應的正訓練包中,執行此迭代操作20次。
圖11說明了選擇法的性能優于隨機法。隨機法最高的AP為33.75%,而選擇法最高可達到44.34%。根據圖12,顯然隨機法的方差較大,SWSD算法更加穩定。當使用全部的提議時,SWSD算法的AP為30.79%,優于隨機法的27.03%,因為SWSD算法多使用了100個ground truth作為全監督樣本。當IOP為5%時,SWSD算法的AP為30.59%,高于只使用100個正例樣本時DPM的AP,因為添加了更多的弱監督信息。當IOP逐漸增加到30%,SWSD算法的AP不斷增大,因為選出了更多的正示例。當IOP介于25%到65%之間時,AP高于40%。但當IOP繼續增大,可選擇的正示例數量減小,只能將負示例加入包中,因此AP下降了。
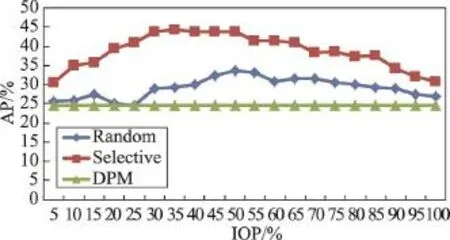
Fig.11 Comparison among random, selective and DPM methods圖11 隨機法,選擇法與DPM之間的比較

Fig.12 Variance comparison between random and selective methods圖12 隨機法與選擇法的方差比較
圖13展示了某張圖片第1~15個被選擇的提議,可以看出大部分均為正,說明了SWSD算法的有效性。雖然本文使用了100個手工標注的ground truth,但這只需要很小的代價。實驗說明只要選擇合適數量的提議,就可以提高弱監督檢測的性能。

Fig.13 1~15 selected proposals of one image圖13 某張圖片第1~15個被選擇的提議
表2列出了近兩年在Pascal VOC 2007的人類測試集上多個弱監督檢測的AP。可以看出,經過對訓練樣本和模型參數的分析,SWSD算法大幅度提高了性能。之所以本文方法更好,主要是因為加入了少量的監督信息,同時控制了更多的實驗細節,發現了最好的訓練方法。最關鍵的是,盡可能保證了包中正示例比例是個較大的值。圖14給出了實驗過程。

Table 2 AP of multiple instance detection in person test set of Pascal VOC 2007表2 Pascal VOC 2007的人類測試集上多示例檢測的AP

Fig.14 Experimental process圖14 實驗過程
6 結束語
經過本文綜合性的評估實驗,根據實驗結果和相關分析,主要得出以下結論:
(1)當正示例比例是一個相對較大的值時,多示例學習的性能優于監督學習,體現了多示例學習的巨大潛力。
(2)可以手工標注少量的樣本,然后用這些樣本迭代選擇示例。本文提出的SWSD算法用較小的代價確保了大的正示例比例,并提高了弱監督人體檢測的性能。
(3)在多示例檢測中,使用Max Pooling融合策略估算包為正的概率比Noisy-or模型更合適。
(4)在LSP數據集上,Selective Search算法可以提供類似ground truth的提議。
(5)在本文工作中,最好的多示例檢測模型為MIL_AdaBoost與MIL_LR的集成算法。
[1]Dalal N,Triggs B.Histograms of oriented gradients for human detection[C]//Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition,San Diego,USA,Jun 20-26,2005.Washington:IEEE Computer Society,2005,1:886-893.
[2]Toshev A,Szegedy C.Deeppose:human pose estimation via deep neural networks[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition,Columbus,USA,Jun 23-28,2014.Washington:IEEE Computer Society,2014:1653-1660.
[3]Yang Y,Ramanan D.Articulated human detection with flexible mixtures of parts[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(12):2878-2890.
[4]Buys K,Cagniart C,Baksheev A,et al.An adaptable system for RGB-D based human body detection and pose estimation[J].Journal of Visual Communication and Image Representation,2014,25(1):39-52.
[5]Oren M,Papageorgiou C,Sinha P,et al.Pedestrian detection using wavelet templates[C]//Proceedings of the 1997 IEEE Conference on Computer Vision and Pattern Recognition, San Juan,Puerto Rico,Jun 17-19,1997.Washington:IEEE Computer Society,1997:193-199.
[6]Ouyang Wanli,Zeng Xingyu,Wang Xiaogang.Learning mutual visibility relationship for pedestrian detection with a deep model[J].International Journal of Computer Vision, 2016,120(1):14-27.
[7]Cinbis R G,Verbeek J,Schmid C.Weakly supervised object localization with multi-fold multiple instance learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(1):189-203.
[8]Everingham M,Van Gool L,Williams C K,et al.The Pascal visual object classes(VOC)challenge[J].International Journal of Computer Vision,2010,88(2):303-338.
[9]Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition,Columbus,USA,Jun 23-28,2014.Washington:IEEE Computer Society,2014: 580-587.
[10]Zhang Yuting,Kihyuk S,Ruben V,et al.Improving object detection with deep convolutional networks via Bayesian optimization and structured prediction[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition,Boston,USA,Jun 7-12,2015.Washington:IEEE Computer Society,2015:249-258.
[11]Pandey M,Lazebnik S.Scene recognition and weakly supervised object localization with deformable part-based models[C]//Proceedings of the 2011 International Conference onComputer Vision,Barcelona,Spain,Nov 6-13,2011.Washington:IEEE Computer Society,2011:1307-1314.
[12]Siva P,Xiang Tao.Weakly supervised object detector learning with model drift detection[C]//Proceedings of the 2011 International Conference on Computer Vision,Barcelona,Spain, Nov 6-13,2011.Washington:IEEE Computer Society,2011: 343-350.
[13]Russakovsky O,Lin Yuanqing,Yu Kai,et al.Object-centric spatial pooling for image classification[C]//Proceedings of the 12th European Conference on Computer Vision,Florence, Italy,Oct 7-13,2012.Berlin,Heidelberg:Springer,2012:1-15.
[14]Song H O,Girshick R,Jegelka S,et al.On learning to localize objects with minimal supervision[J].arXiv:1403.1024,2014.
[15]Song H O,Lee Y J,Jegelka S,et al.Weakly-supervised discovery of visual pattern configurations[C]//Proceedings of the Annual Conference on Neural Information Processing Systems,Montreal,Canada,Dec 8-13,2014:1637-1645.
[16]Bilen H,Pedersoli M,Tuytelaars T.Weakly supervised object detection with posterior regularization[C]//Proceedings of the British Machine Vision Conference,Nottingham,UK, Sep 1-5,2014:1997-2005.
[17]Wang Chong,Ren Weiqiang,Huang Kaiqi,et al.Weakly supervised object localization with latent category learning [C]//LNCS 8694:Proceedings of the 13th European Conference on Computer Vision,Zurich,Switzerland,Sep 6-12,2014. Berlin,Heidelberg:Springer,2014:431-445.
[18]Ray S,Craven M.Supervised versus multiple instance learning:an empirical comparison[C]//Proceedings of the 22nd International Conference on Machine Learning,Bonn, Germany,Aug 7-11,2005.New York:ACM,2005:697-704.
[19]Xu Xin,Frank E.Logistic regression and boosting for labeled bags of instances[C]//LNCS 3056:Proceedings of the 8th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining,Sydney,Australia,May 26-28, 2004.Berlin,Heidelberg:Springer,2004:272-281.
[20]Viola P,Platt J C,Zhang Cha.Multiple instance boosting for object detection[C]//Proceedings of the Annual Conference on Neural Information Processing Systems,Vancouver, Canada,Dec 5-8,2005:1417-1424.
[21]Papageorgiou C,Poggio T.A trainable system for object detection[J].International Journal of Computer Vision,2000, 38(1):15-33.
[22]Viola P,Jones M.robust real-time face detection[J].International Journal of Computer Vision,2004,57(2):137-154.
[23]Felzenszwalb P F,Girshick R B,McAllester D.Cascade object detection with deformable part models[C]//Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition,San Francisco,USA,Jun 13-18,2010.Washington:IEEE Computer Society,2010:2241-2248.
[24]Van de Sande K E A,Uijlings J R R,Gevers T,et al.Segmentation as selective search for object recognition[C]//Proceedings of the 2011 International Conference on Computer Vision,Barcelona,Spain,Nov 6-13,2011.Washington:IEEE Computer Society,2011:1879-1886.
[25]Uijlings J R R,van de Sande K E A,Gevers T,et al.Selective search for object recognition[J].International Journal of Computer Vision,2013,104(2):154-171.
[26]Hosang J,Benenson R,Dollár P,et al.What makes for effective detection proposals?[J].IEEE Transactions of Pattern Analysis and Machine Learning,2016,38(4):814-830.
[27]Arbelaez P,Pont-Tuset J,Barron J,et al.Multiscale combinatorial grouping[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition,Columbus,USA,Jun 23-28,2014.Washington:IEEE Computer Society,2014:328-335.
[28]Alexe B,Deselaers T,Ferrari V.Measuring the objectness of image windows[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(11):2189-2202.
[29]Van den Bergh M,Roig G,Boix X,et al.Online video SEEDS for temporal window objectness[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision,Sydney,Australia,Dec 1-8,2013.Piscataway,USA: IEEE,2013:377-384.
[30]Zhu Qiang,Yeh M C,Cheng K T,et al.Fast human detection using a cascade of histograms of oriented gradients[C]//Proceedings of the 2006 IEEE Conference on Computer Vision and Pattern Recognition,New York,Jun 17-22,2006.Washington:IEEE Computer Society,2006,2:1491-1498.
[31]Ke Yan,Sukthankar R.PCA-SIFT:a more distinctive representation for local image descriptors[C]//Proceedings of the 2004 IEEE Conference on Computer Vision and Pattern Recognition,Washington,Jun 27-Jul 2,2004.Washington:IEEE Computer Society,2004:506-513.
[32]Howarth P,Rüger S.Evaluation of texture features for con-tent-based image retrieval[C]//LNCS 3115:Proceedings of the 3rd International Conference on Image and Video Retrieval,Dublin,Ireland,Jul 21-23,2004.Berlin,Heidelberg:Springer,2004:326-334.
[33]Schmidhuber J.Deep learning in neural networks:an overview[J].Neural Networks,2015,61:85-117.
[34]Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[J].arXiv:1409.1556, 2014.
[35]Deng Jia,Dong Wei,Socher R,et al.ImageNet:a largescale hierarchical image database[C]//Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition,Miami,USA,Jun 20-25,2009.Washington: IEEE Computer Society,2009:248-255.

CAI Yawei was born in 1992.She is an M.S.candidate at College of Computer Science and Technology,Nanjing University ofAeronautics andAstronautics.Her research interests include pattern recognition and machine learning.蔡雅薇(1992—),女,安徽黃山人,南京航空航天大學計算機科學與技術學院碩士研究生,主要研究模式識別,機器學習。

TAN Xiaoyang was born in 1971.He received the Ph.D.degree from Department of Computer Science and Technology,Nanjing University in 2005.Now he is a professor and Ph.D.supervisor at Nanjing University of Aeronautics and Astronautics,and the member of CCF.His research interests include computer vision,pattern recognition and machine learning.
譚曉陽(1971—),男,江蘇淮安人,2005年于南京大學計算機科學與技術系獲得博士學位,現為南京航空航天大學計算機科學與技術學院教授、博士生導師,CCF會員,主要研究領域為計算機視覺,模式識別,機器學習。主持多項科研課題,在一流國際期刊和頂級國際會議上發表論文40余篇。
Weakly Supervised Human Body Detection underArbitrary Poses*
CAI Yawei+,TAN Xiaoyang
College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China
+Corresponding author:E-mail:caiyawei@nuaa.edu.cn
The problem of weakly supervised human body detection under difficult poses(e.g.,multi-view and/or arbitrary poses)is studied.Most current methods on human body detection focuse only on a few common human body poses with human body in upright positions,while in the real world human bodies may exhibit very rich pose variations(e.g.,when people are bending,sleeping or sitting).This not only imposes great challenges on the task of human detection,but also makes the job of manual annotation even more difficult,and usually only weak annotations are available in practice.The multiple instance learning method relaxes the requirements of accurate labeling and hence is commonly used to address the task.However,it is sensitive to the quality of positive instances and the settings of some model parameters such as the strategy to fuse the instance-level conditional probability into a baglevel one.This paper presents a comprehensive and in-depth empirical method of these important but less studied issues on the person dataset of Pascal VOC 2007,and proposes a new selective weakly supervised detection algorithm(SWSD).Experiments demonstrate that with only a few fully supervised samples,the performance of weakly supervised human body detection can be significantly improved under the multiple instance learning framework.
weakly supervision;human body detection;arbitrary poses;multiple instance learning
10.3778/j.issn.1673-9418.1603044
A
TP391
*The National Natural Science Foundation of China under Grant No.61373060(國家自然科學基金).
Received 2016-03,Accepted 2016-05.
CNKI網絡優先出版:2016-05-13,http://www.cnki.net/kcms/detail/11.5602.TP.20160513.1434.004.html
CAI Yawei,TAN Xiaoyang.Weakly supervised human body detection under arbitrary poses.Journal of Frontiers of Computer Science and Technology,2017,11(4):587-598.
摘 要:困難姿態(多視角或者任意姿態)下的弱監督人體檢測問題被關注研究。現在大部分人體檢測僅僅關注普通的直立姿態,但現實中的人體卻呈現非常豐富的姿態(如彎曲的、躺著的、坐著的),這不僅加大了人體檢測的難度,而且令標注工作更加困難,實際中通常只能獲得弱標注樣本。多示例學習方法放松了精準標注的要求,因此常常被用來解決此類問題。但是多示例學習對正示例的質量以及一些模型參數設置相當敏感,例如將示例層次條件概率融合到包層次的策略。在Pascal VOC 2007的人類數據集上對這些重要但很少被關注的問題進行了綜合性深度研究,并提出了一種新的選擇性弱監督檢測算法(selective weakly supervised detection,SWSD)。實驗證明,只要添加少量的監督樣本,在多示例學習框架下,可以大幅度提高弱監督人體檢測性能。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
人大建設(2020年4期)2020-09-21 03:39:12
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
