融合詞向量的多特征句子相似度計算方法研究*
2017-04-17 01:39:17侯加英曾榮仁
計算機與生活 2017年4期
李 峰,侯加英,曾榮仁,凌 晨
1.中國人民解放軍后勤科學研究所,北京 100166
2.北京航空航天大學 計算機學院,北京 100191
3.昆明理工大學 信息工程與自動化學院,昆明 650504
融合詞向量的多特征句子相似度計算方法研究*
李 峰1,2+,侯加英3,曾榮仁1,凌 晨1
1.中國人民解放軍后勤科學研究所,北京 100166
2.北京航空航天大學 計算機學院,北京 100191
3.昆明理工大學 信息工程與自動化學院,昆明 650504
在歸納常見的句子相似度計算方法后,基于《人民日報》3.4萬余份文本訓練了用于語義相似度計算的詞向量模型,并設計了一種融合詞向量的多特征句子相似度計算方法。該方法在詞方面,考慮了句子中重疊的詞數和詞的連續性,并運用詞向量模型測量了非重疊詞間的相似性;在結構方面,考慮了句子中重疊詞的語序和兩個句子的長度一致性。實驗部分設計實現了4種句子相似度計算方法,并開發了相應的實驗系統。結果表明:提出的算法能夠取得相對較好的實驗結果,對句子中詞的語義特征和句子結構特征進行組合處理和優化,能夠提升句子相似度計算的準確性。
詞向量;句子相似度;Word2vec;算法設計
1 引言
句子相似度計算是自然語言處理領域中十分重要而又較為基礎的研究工作。例如:在機器翻譯研究中,用于查找最為相似的例句[1-2];在問答系統中,用于查找可能的答案[3];在噪音信息過濾中,用于剔除可能的垃圾信息[4];在文本自動摘要研究中,用于計算摘要句的權重分配[5];在分類或聚類中,用來判定句子或文檔的類別[6],等。目前常見的句子相似度計算方法大體上可分為以下3類:
(1)基于表層信息的相似度計算。該方法通常計算句子中詞形相似度、詞序相似度和句長相似度等信息[7],分別如式(1)~(3)所示。
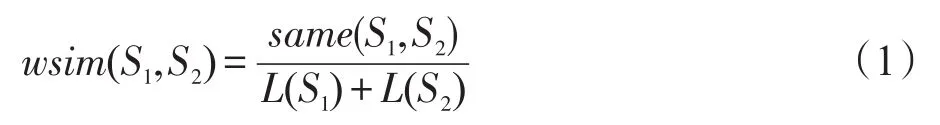
式(1)中,S1和S2代表兩個句子;same(S1,S2)表示兩個句子中重疊詞的個數;L(S1)和L(S2)分別代表兩個句子的詞數。

式(2)中,v1n和v2n分別代表由句子S1和S2的N-Gram表示的向量;當n值為1時,取詞的tf-idf值;當n值大于1時,若句子包含重疊詞,則向量值取1,否則取0。
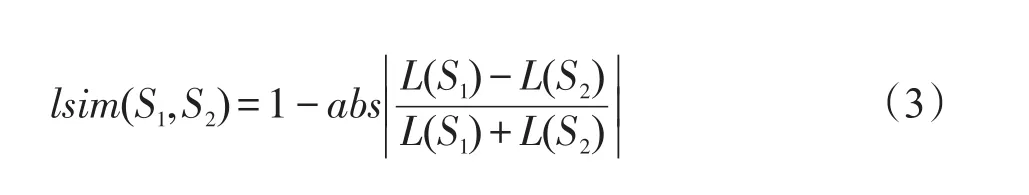
式(3)中,L(S1)和L(S2)分別代表兩個句子中詞的個數。
(2)基于句子結構的相似度計算。這種方法主要考查兩個句子在結構上的相似性,如基于詞類串結構、本體結構、詞性及詞性依存結構等進行句子的相似度計算。這里引用文獻[8]提出的基于詞性及詞性依存的句子結構相似度計算方法來進行介紹。該方法認為句子主要由主成分和修飾成分組成,主成分由句子中的核心動詞擔任并作為句子的支配者,修飾成分則作為支配者。同一主成分可以被不同的修飾成分修飾,達到不同的效果。其中,句子的成分信息可由詞性來反映,詞性依存關系中各成分之間的修飾關系能夠體現句子的整體性。因此,可以通過計算詞性及詞性依存信息來把握句子間的相似性。該方法首先通過計算得到句子S1和S2詞性相似度矩陣,如式(4)所示:

其中,sij表示句子S1中第i個詞性和句子S2中第 j個詞性的相似度,若兩詞性相等,則 sij=1;否則sij=0。然后使用式(5)計算兩個句子的結構相似度:
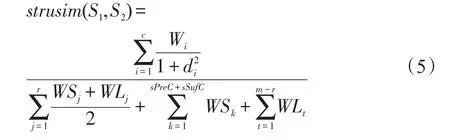
其中,c為句子S1和S2中相同詞性的個數;d為相鄰對應詞間距;r為句子中詞性對應總數;表示兩句中能夠對應上的詞性權值均值線性和;為能夠對應上的詞性前余及后余詞性權值均值線性和;表示兩句中無法對應上的詞性權值均值線性和。
最后,在式(4)、(5)計算的基礎上,通過雙向最佳路徑匹配搜索算法得到結構相似度的最大值作為句子S1和S2的結構相似度。
(3)基于語義資源的相似度計算。該方法主要通過已建成的語義資源來考察詞間的語義關系,從而計算句子的相似度,具有代表性的主要有基于Word-Net、HowNet或同義詞林等的句子相似度計算方法。主要思路為:首先利用語義資源獲取句子S1和S2中詞語間的相似度s(wk,wn),詞義相似度計算方法請見相應的參考文獻[9-11],這里不再贅述。
其次,利用式(6)計算求得句子S1中詞語和句子S2中詞語的平均最大相似度Q1和Q2:
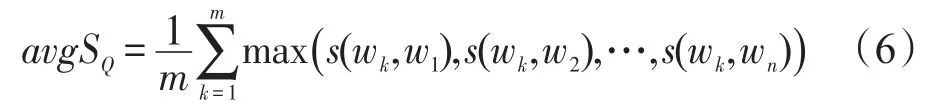
其中,m、n分別為兩個句子中詞的個數;s(wk,wn)表示當前句子中第k個詞與另一個句子中第n個詞的語義相似度值。
最后利用式(7)得到雙向平均最大相似度的算術平均值作為句子S1和句子S2的相似度值:

上述3種方式能夠從不同的角度計算出兩個句子之間的相似度信息,并得到了較為廣泛的應用。也有學者嘗試將幾種方法融合起來應用于句子的相似度計算,也取得了較好的效果[12]。
本文則在前人研究的基礎上,提出了一種融合詞向量的多特征句子相似度計算方法。該方法綜合考察兩個句子中詞的語義信息和句子的結構信息來測量句子的相似度。其中,在詞義計算過程中,除了考慮兩個句子中重疊詞的個數、連續性,還通過引入詞向量特征來刻畫非重疊詞之間的語義相似性;在句子結構相似度計算過程中,則分別計算了重疊詞在句子中出現的詞序和兩個句子的句長相似性兩個因素。本文第2章將基于Word2vec工具使用大規模《人民日報》語料訓練詞向量模型,同時測試不同字面詞之間的相關性;第3章將詳細描述本文提出的融合詞向量的多特征句子相似度計算方法;第4章將開發并實現相應的實驗系統,對多種句子相似度算法進行實驗和分析,并給出實驗結論;第5章對全文進行總結。
2 詞向量與語義相似度計算
2.1 詞向量和相關語言模型
語言模型的建立與訓練是自然語言處理領域十分重要的組成部分,常見的有經典的N-Gram模型[13]以及最近得到廣泛討論的深度學習模型(deep learning)[14-15]等。詞向量作為深度學習模型中一種詞的分布式表達(distributed representation),能夠較好地解決數據稀疏對統計建模的影響,克服維數災難,取得了較好的應用效果[16],得到了研究者們廣泛的關注。采用詞的分布式表達來表示詞向量最早由Hinton[17]提出,也稱之為Word Representation或Word Embedding。該方法采用一組低維度的實數向量來刻畫詞的特征,常見形式為[-0.047 339 3,-0.125 004 8, 0.223 884 4,0.051 308 5,…],其優點主要表現在兩個方面:一是可以通過計算詞向量之間的距離來測試詞之間的相關或相似性,例如“西安”、“鄭州”和“中醫”3個詞中前兩個詞較為相關,則對應的詞向量距離就較小,反之亦然;另外通過使用較低維度的特征來刻畫詞,可以大幅降低計算的復雜度,從而提高方法的實際應用價值。
詞向量的數值一般是從大量未經標注的文本數據中,通過無監督的語言模型訓練同步得到。鑒于下文使用的Word2vec工具主要包括CBOW(continuous bag of word)模型和Skip-gram模型[18-19],這里重點介紹這兩個模型。兩個模型均由Mikolov[18]提出,架構示意如圖1所示,模型的主要目標在于以較小的計算量獲取較好的詞向量表示。
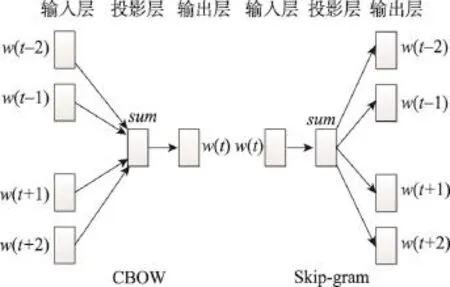
Fig.1 CBOW model and Skip-gram model圖1CBOW模型與Skip-gram模型示意圖

Skip-gram模型通過“跳過一定字符”的方式來訓練當前詞的上下文詞向量,用于刻畫上下文信息,可以簡單地理解為根據上下文對當前詞進行分類。該模型訓練的目標是尋找參數集合θ來最大化式(9)中Τ的值。其中,w和c均表示一個詞;D為所有單詞w和它的語境中單詞構成的組合的集合。

CBOW模型通過計算當前詞的上下文來得到當前詞出現的概率,認為上下文中所有詞對當前詞出現的影響程度是相同的,而不考慮這些詞出現的順序,因此被稱為連續空間中的詞袋模型。該模型包括輸入、投影和輸出3層,輸入與輸出層表示詞向量,維數通常在50至100之間。設投影層維數為D,輸入層上下文窗口長度為N,訓練語料詞典大小為|| V,CBOW模型的訓練復雜度Q為:
采用同樣的表達方式,若上下文窗口長度為N,Skip-gram模型的訓練復雜度Q為:

通過式(8)、(10)可以看出,相同條件下Skipgram模型與CBOW模型相比計算復雜度要高。研究表明[20-21],兩個模型的差異在于:CBOW模型能夠在訓練中獲取更好的語法信息,得到較高的語法測試準確性,而Skip-gram模型對詞的特征刻畫相對更加準確,具備更好的語義區分性,能夠得到相對較高的語義計算精度。
CBOW模型和Skip-gram模型的共同優點在于能夠從數億級的海量未經標注的數據中得到高質量的詞向量訓練結果,能更好地刻畫詞之間的相關或相似性,能夠描述詞和短語之間的相關性,對長距離跨度的詞間關系能夠進行有效的表達。同時訓練的結果模型可以作為自然語言處理應用中詞、句子或篇章主題相似或相關性計算的基礎資源。
2.2 Word2vec與語義相似度計算
Word2vec是谷歌2013年發布的詞向量訓練與生成工具,能夠從大規模未經標注的語料中高效地生成詞的向量形式,并提供了CBOW模型和Skip-gram模型的實現(https://code.google.com/p/word2vec)。因其簡單易用,獲取詞向量的結果較好,而受到了廣泛的關注。目前,Word2vec工具已有多個編程語言實現包,如C、Java、Python等,較為方便研究者學習和調用,也因此成為可利用的基于詞的語義相似度計算工具之一。盡管學界已經推出了Sentence2vec[22-23]、Topic2vec[24]、Doc2vec[25]等句向量、話題向量或篇章向量計算方法,但由于詞一直是自然語言處理研究的基礎之一,加之以詞為統計元素,語料相對更為豐富,計算復雜度也易為大眾接受,相比較而言Word2vec近幾年應用則更為普遍[26-28]。
本文采用ansj編寫的Java版本的Word2vec作為詞向量的訓練工具(https://github.com/ansjsun/Word-2vec_java)。為方便測試,采用《人民日報》2014年6月30日至2015年9月6日共434天的報紙文本作為訓練語料,在訓練之前剔出圖片類、廣告類新聞、正文句子數少于兩句的新聞,使用NLPIR2015(http:// ictclas.nlpir.org/downloads)進行分詞處理并剔除詞性信息,最后共34 033篇語料參與訓練,詞總數為202 119。由于Word2vec最初開發時主要針對英文語言的應用,而眾所周知,英文和中文之間存在著一定的差異,如中文重語義,更傾向于通過上下文來確定詞的具體使用含義,英文則可通過詞法等結構信息來體現時態和使用含義。文獻[19]通過研究和大規模語料實驗表明,Word2vec工具可以較好地適用于中文處理,且采用Skip-gram模型要優于采用CBOW模型。同時當詞向量維度保持在170至250維之間時,能夠取得相對穩定和準確的效果。在多次訓練后,本文設置上下文窗口長度為5,維度為200,并采用Skip-gram模型進行訓練。訓練結束后,抽樣了幾種不同類型的詞的前5個相近詞,按向量距離倒序排列,結果如表1所示。
不難看出,對于名詞、動詞及形容詞這些內容詞而言,使用Word2vec工具能夠取得較好的結果。在句子相似度計算中,無論以何種方式通常都撇不開詞之間關系的計算,而詞間關系的計算往往更側重于實詞。基于前人的研究和上述實驗結果(http:// www.kaxiba.com/data2015.zip),可以認為:在句子相似度計算過程中,融入詞向量特征強化非重疊實詞間的相似性度量,能夠提升句子相似度計算的準確性。下文基于該假設設計了一種融合詞向量的多特征句子相似度計算方法,并進行了實驗分析。
3 融合詞向量的多特征句子相似度計算方法
兩個句子之間的相似程度取決于多個因素,如句子中的詞數、詞義、詞序、句子結構、上下文語境等。限于句子結構及上下文語境等計算資源的獲取或計算實現難度太大,一般傾向于通過句子中詞義間的相關性和句子的表層信息來計算句子的相似性。本文提出的融合詞向量的多特征句子相似度計算方法主要考察句子中重疊詞的詞數、重疊詞的連續性、重疊詞在句子中的順序以及非重疊詞的語義相似性等因素。
算法主要框架流程如圖2所示,主要包含以下幾個步驟。
步驟1求取句子間的公共詞塊列表。對于輸入句子S1和S2,如果兩個句子值不為空且長度大于0,分別進行分詞處理和詞性標注,提取動、名、形3類詞作為內容詞后,運用動態規劃算法求取兩個句子的公共詞塊列表C。該列表中不僅包含詞,而且包含詞塊,但不包含單個字。
例如,對于兩個句子“習近平同哈薩克斯坦總統納扎爾巴耶夫會談”和“本報北京8月31日電(記者李偉紅)國家主席習近平31日在人民大會堂同哈薩克斯坦總統納扎爾巴耶夫舉行會談”,經分詞處理及計算后得到的公共詞塊列表C中元素依次為“習近平”、“哈薩克斯坦總統納扎爾巴耶夫”、“會談”。

Fig.2 Process flowchart of algorithm圖2 算法處理流程圖

Table 1 Sampling based on the results of Word2vec training model表1 基于Word2vec訓練結果的抽樣
步驟2以公共詞列表為基礎計算兩個句子的相似度。以公共詞列表C為基礎,從句子S1和S2重疊詞個數、重疊詞在兩個句子中的連續性和詞序一致性三方面來計算兩句的相似度。其中重疊詞個數和詞在句子中的連續性使用式(11)計算:

其中,m為C中元素的個數;L(ci)表示C中第i個元素中包含詞的個數;k為連續詞加權系數。當ci為獨立單詞時,L(ci)為1,公式起不到加權的作用,當L(ci)大于1時,即由連續詞構成了詞塊,系數k起到加權的作用。
對于句子S1和S2重疊詞在兩個句子中詞序的相似性,計算步驟為:
(1)以單個詞為單位獲取兩個句子重疊詞列表W。
(2)順序遍歷S1,標記同時屬于S1和W的詞wi在S1中的索引I1,同一詞在句子S1中多次出現時,僅記錄首次索引,最終得到的索引形如I1=[1,2,3,4,5]。
(3)順序遍歷S2,標記同時屬于S2和W的詞wj在S1中的索引I2,同一詞在句子S2中多次出現時,僅記錄首次索引,最終得到的索引形如I2=[4,3,1,2,5]。
(4)計算I2中索引的次序,對不是正常順序的索引進行懲罰,計算公式如式(12):

其中,當I2中第n個索引比第n-1個索引值小時,對詞序相似度進行懲罰,其中Q表示索引差值,δ表示懲罰因子,取值范圍為0至1;當I2中第n個索引比第n-1個索引值大時,表示該詞在S2中出現的順序與S1中保持一致,記語序相似度值為1。計算完成后,使用式(13)得到句子中詞序相似度的總體值:
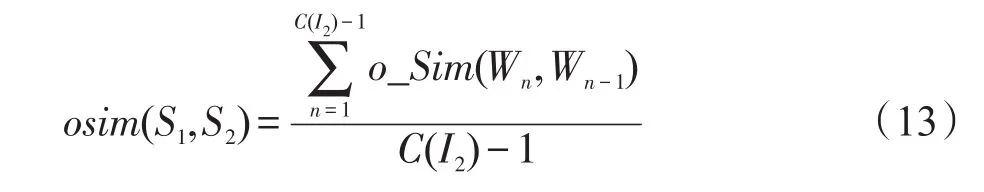
式(13)中C(I2)表示索引列表I2中元素的個數。
步驟3使用詞向量模型計算非重疊詞相似度。對于句子S1和S2中非重疊詞部分相似度的計算,采用本文第2章訓練的詞向量模型進行。
(1)使用兩個句子重疊詞列表W對句子S1和S2進行過濾,得到非重疊詞列表A和B。
(2)循環遍歷列表A和B中的詞,兩兩計算詞間的相似度wij,計算時采用Word2vec模型中詞間的向量距離來度量,如式(14):

其中,n表示Word2vec模型訓練時向量的維數;m為向量vi和vj下標值。例如可通過式(14)計算得到“總統”和“國家”、“主席”間的相似度值分別為0.297 951 4和0.522 891 6。在計算完成后,得到詞間的相似度矩陣,如式(15)所示:

(3)通過動態規劃算法求解句子S1和S2非重疊部分最大相似度值之和dsim并返回。
步驟4融合多特征計算句子整體相似度。在得到句子S1和S2中詞的相似度值、詞序的相似度值之后,本文通過式(3)計算兩個句子的句長相似度lsim,最后采用參數化線性疊加的方式得到兩個句子的整體相似度值,計算公式如式(16)所示:

其中,α、β、γ分別為詞義、句長、詞序相似度調節因子,三者之和為1;k為連續詞塊加權系數;minL(S1,S2)表示兩個句子中最短句包含的實詞個數。由于式(12)中計算詞序的得分是在句子S1和S2具有公共詞塊基礎上進行的,這里對兩者得分相乘。
4 實驗與分析
4.1 實驗方法與數據
在實際應用中,句子相似度計算主要用于從一個句子集中找到與目標句子最為相似的句子,或者計算句子集中兩兩句子的相似度并排序,如自動問答與文本自動摘要等應用,但本質依然需要計算兩個句子間的相似度。對于新聞文本而言,一般都有標題和正文兩個部分,而標題作為新聞話題的標識,其意義在正文中一般都會通過一個句子或多個句子再次體現。據此,本文以新聞標題為目標句,要求算法從正文中計算與標題最為相似的句子并返回。最后統計算法計算結果與人工選擇結果的差異,來考察算法的準確性。
為保證實驗的科學可靠,避免新聞文本正文中出現雷同句,本文采用《人民日報》2015年9月1日至9月3日的新聞作為實驗源數據,在刪除圖片類、廣告類以及一句話新聞之后,剔除了標題類似“記住那歷史瞬間”以及“報告”、“宣言”類主題意義不明顯的新聞之后,隨機抽取100篇新聞參與實驗。在實驗進行之前,使用正則表達式結合標點符號進行斷句處理,使用NLPIR2015進行分詞和詞性標注。在詞向量計算部分,采用本文第2章《人民日報》語料訓練的Word-2vec模型作為詞向量計算基礎資源。邀請一名漢語語言文學專業碩士研究生手動標記這100篇新聞正文中與標題最為相似的句子作為參考答案。
實驗過程中,加上本文提出的句子相似度算法,共有4種算法參與對比分析,分別為:(1)基于字面特征的句子相似度算法;(2)基于多特征融合的句子相似度算法;(3)融合詞向量與字面特征的句子相似度算法;(4)融合詞向量的多特征句子相似度算法。
為保證實驗的順利進行,方便驗證各個算法的實際應用效果,本文對參與實驗的算法進行了全部的編碼實現,并開發了相應的句子相似度計算與實驗系統,主界面如圖3所示。
該實驗系統能夠加載不同的詞向量模型,能夠基于上述4種算法,通過設置不同的參數,分別從新聞文本中找出與標題最為相似的句子,并輸出統計結果。為提高系統的應用價值,該系統采用了開放式設計,不僅能夠支持中文,而且可以支持其他語種;不僅能夠支持新聞類文本,也可以支持其他類似格式文本,以期為后續學者提供一個便捷的句子相似度研究與實驗平臺1))實驗數據、實驗結果、算法源代碼、實驗系統程序及源代碼下載地址為http://www.kaxiba.com/sim2015.zip。。
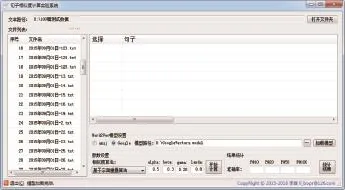
Fig.3 Main interface of sentence similarity computing experiment system圖3 句子相似度計算實驗系統主界面
4.2 實驗結果分析
在實驗過程中,本文以10篇、20篇、50篇、100篇分段統計各種算法的準確率P@10、P@20、P@50和P@100,并統計平均準確率P@avg,α、β、γ、δ的取值分別為0.5、0.3、0.2、0.8,加權系數k為1.5。為方便表示,上述4種算法分別對應簡稱為LM、MFM、LM_W2V和MFM_W2V算法。在分析過程中,主要考察多特征的引入對句子相似度計算準確率的影響,詞向量的引入對句子相似度的影響,以及4種不同的句子相似度計算方法的計算效果。
(1)多個特征的引入對句子相似度計算的影響。基于字面特征的算法和基于多特征融合的算法在本實驗中取得的準確率值對比如圖4所示。可以看出,對于僅基于字面重疊的算法而言,當引入詞的連續性特征和句子中重疊詞塊的順序特征后,準確率得到了改善。在實驗數據較少時,統計特征不夠明顯,多特征的改善作用不突出,當超過20篇實驗語料后,基于多特征融合的句子相似度計算方法能夠取得約10%準確率的提升。可以認為,這兩項特征的融入提高了句子相似度計算的準確性。

Fig.4 Accuracy of LM and MFM algorithms圖4LM和MFM兩種算法的準確率
(2)詞向量的引入對句子相似度計算的影響。隨后,本文在前述兩種算法的基礎上融入詞向量特征,考察詞向量特征引入能否提高句子相似度計算的準確率。引入詞向量特征后的對比結果如圖5和圖6所示。
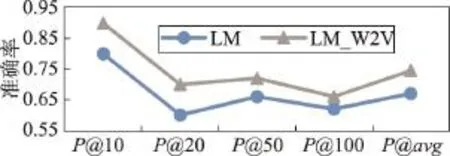
Fig.5 Accuracy of LM and LM_W2V algorithms圖5LM和LM_W2V兩種算法的準確率
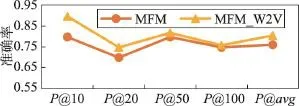
Fig.6 Accuracy of MFM and MFM_W2V algorithms圖6MFM和MFM_W2V兩種算法的準確率
從圖5中可以看出,基于字面的句子相似度計算方法在融入詞向量特征后,取不同比率的實驗語料,均能夠得到較為明顯的準確率提升,平均準確率提升約9%。同時,兩種算法的準確率變化趨勢較為一致,可以認為,詞向量的引入對于提升基于字面的句子相似度計算方法的準確率起到了積極的作用。
圖6顯示了當在多個特征的基礎上再融入詞向量特征后句子相似度計算的準確率情況。不難發現,融合詞向量特征后,當取不同比率的實驗數據時依然能夠提升句子相似度計算的準確性,平均提升準確率約5個百分點。同時,從整體上看,融入詞向量的多特征句子相似度計算方法準確率趨勢仍然和僅基于多特征計算的方法保持大體一致。
綜合圖5與圖6可以得出,融合詞向量特征能夠提升句子相似度計算的準確率,當特征較少時作用更為明顯。
(3)各種相似度算法總體結果對比。為從總體上觀察實驗中各種方法取得的準確率,圖7給出了實驗中4種句子相似度計算方法在不同比率實驗數據條件下取得的平均準確率情況。
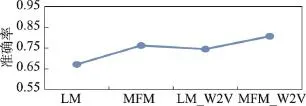
Fig.7 Accuracy of 4 sentence similarity calculation methods圖7 4種句子相似度計算方法準確率
從圖7中可以觀察到,特征的選取以及選取特征的數量對句子相似度計算有著明顯的影響。在相同的條件下,詞向量的融入能夠明顯提升句子相似度計算的準確性。同時本文設計的融合詞向量的多特征句子相似度計算方法能夠取得相對更好的準確率。
4.3 相關結論
在句子相似度計算中,字面重疊和詞向量特征屬于句子中詞義層面的計算,可以視為句子中詞義層面的特征;重疊詞的連續性、在句子中的語序以及兩句的句長特征則傾向于歸類為句子結構層面的特征。通過上文實驗不難得出如下結論:
(1)在句子相似度計算時,通過詞的語義層面或句子結構層面的優化,均有利于提升句子相似度計算的準確性。
(2)單個層面的優化結果往往不如多個層面融合的結果更能提升句子相似度計算的準確性。如圖7所示,融合詞向量與字面特征的句子相似度算法并沒有優于沒有融入詞向量的多特征融合的句子相似度算法。
(3)詞向量的融入能夠提升句子中所包含詞語義層面計算的準確性,同時結合句子結構層面的特征,能夠取得相對最好的句子相似度計算準確率。
5 結束語
句子相似度計算在自然語言處理領域中是一項基礎性研究工作,伴隨著自然語言處理的發展,相關方法不斷演進。本文對前人的研究進行了歸類,總結了前人的研究成果,并給出了具有代表性方法的計算公式。基于詞向量的語義表示近年來在自然語言處理研究中得到了廣泛的關注。首先詳細分析了詞向量與語義相似度計算的關系,基于《人民日報》語料運用Word2vec工具訓練了相關的語義相似度計算模型;隨后詳細描述了融合詞向量的多特征句子相似度計算方法,包括方法的整體框架流程、實現步驟及相關的計算公式。基于前人的研究與本文提出的方法,設計實現了4種句子相似度計算方法,開發了相應的句子相似度實驗系統,并基于《人民日報》語料進行了較為詳盡的實驗。最后從多個特征的引入對句子相似度計算的影響、詞向量對句子相似度計算的影響和4種句子相似度計算方法的總體準確率3個層面分析討論了實驗結果,表明了本文方法的有效性及可行性,并基于前文的算法與實驗分析,給出了相關結論。
未來的研究將在本文的基礎上,一方面嘗試采用不同的方法在不同體裁的文本上進行測試,比如在微博、短信息等短文本上的測試情況;另一方面擬擴大語種范圍,測試本文方法在英文、俄文等語言上的模型、參數選擇和實際應用效果等。
[1]Cranias L,Papageorgiou H,Piperidis S.A matching technique in example-based machine translation[C]//Proceedings of the 15th Conference on Computational Linguistics,Kyoto,Japan,Aug 5-9,1994.Stroudsburg,USA:ACL,1994: 100-104.
[2]Lin C Y,Och F J.Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics[C]//Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics,Barcelona, Spain,Jul 21-26,2004.Stroudsburg,USA:ACL,2004:605.
[3]Pradhan N,Gyanchandani M,Wadhvani R.A review on text similarity technique used in IR and its application[J]. International Journal of Computer Applications,2015,120 (9):29-34.
[4]Adafre S F,Rijke D M.Finding similar sentences across multiple languages in Wikipedia[C]//Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics,Trento,Italy,Apr 3-7,2006. Stroudsburg,USA:ACL,2006:62-69.
[5]Sarkar K,Saraf K,Ghosh A.Improving graph based multidocument text summarization using an enhanced sentence similarity measure[C]//Proceedings of the 2nd IEEE International Conference on Recent Trends in Information Systems,Kolkata,India,Jul 9-11,2015.Piscataway,USA:IEEE, 2015:359-365.
[6]Lin Y S,Jiang J Y,Lee S J.A similarity measure for text classification and clustering[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(7):1575-1590.
[7]Zhang Lin,Hu Jie.Sentence similarity computing for FAQ question answering system[J].Journal of Zhengzhou University:Natural Science Edition,2010,42(1):57-61.
[8]Lan Yanling,Chen Jianchao.Chinese sentence structures similarity computation based on POS and POS dependency [J].Computer Engineering,2011,37(10):47-49.
[9]Chen Lisha.The research and implementation on WordNetbased sentence similarity of automatic question answering system[D].Guangzhou:South China University of Technology,2014.
[10]Xia Tian.Study on Chinese words semantic similarity computation[J].Computer Engineering,2007,33(6):191-194.
[11]Tian Jiule,Zhao Wei.Words similarity algorithm based on Tongyici cilin in semantic Web adaptive learning system[J]. Journal of Jilin University:Information Science Edition, 2010,28(6):602-608.
[12]Zhang Peiying.Model for sentence similarity computing based on multi-features combination[J].Computer Engineering andApplications,2010,46(26):136-137.
[13]Brown P F,Desouza P V,Mercer R L,et al.Class-based ngram models of natural language[J].Computational Linguistics,1992,18(4):467-479.
[14]Mikolov T,Kombrink S,Burget L,et al.Extensions of recurrent neural network language model[C]//Proceedings of the 2011 IEEE International Conference on Acoustics,Speech and Signal Processing,Prague,Czech,May 22-27,2011. Piscataway,USA:IEEE,2011:5528-5531.
[15]Devlin J,Zbib R,Huang Z,et al.Fast and robust neural network joint models for statistical machine translation[C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics,Baltimore,USA,Jun 23-25, 2014.Stroudsburg,USA:ACL,2014:1370-1380.
[16]Zhang Jian,Qu Dan,Li Zhen.Recurrent neural network language model based on word vector features[J].Pattern Recognition andArtificial Intelligence,2015,28(4):299-305.
[17]Bengio Y.Deep learning of representations:looking forward [C]//LNCS 7978:Proceedings of the 1st International Conference on Statistical Language and Speech Processing,Tarragona,Spain,Jul 29-31,2013.Berlin,Heidelberg:Springer, 2013:1-37.
[18]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[EB/OL].[2015-10-15]. http://arxiv.org/pdf/1301.3781v3.pdf.
[19]Yu Mo,Dredze M.Improving lexical embeddings with semantic knowledge[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore,USA,Jun 23-25,2014.Stroudsburg,USA:ACL, 2014:545-550.
[20]Xiong Fulin,Deng Yihao,Tang Xiaosheng.The architecture of Word2vec and its application[J].Journal of Nanjing Normal University:Engineering and Technology Edition,2015, 15(1):43-48.
[21]Zhang Dongwen,Xu Hua,Su Zengcai,et al.Chinese comments sentiment classification based on Word2vec and SVM [J].Expert Systems withApplications,2015,42(4):1857-1863.
[22]Iyyer M,Boyd-Graber J,Daumé III H.Generating sentences from semantic vector space representations[C]//Proceedings of the 2014 Conference on Neural Information Processing Systems Workshop on Learning Semantics,Montréal,Canada,Dec 8-13,2014.
[23]Singh P.Decompositional semantics for document embedding[D].Indian Institute of Technology Kanpur,2015.
[24]Niu Liqiang,Dai Xinyu.Topic2Vec:learning distributed representations of topics[EB/OL].[2015-10-15].http://arxiv. org/pdf/1506.08422.pdf.
[25]Matt K,Yu Sun,Nicholas K,et al.From word embeddings to document distances[C]//Proceedings of the 32nd International Conference on Machine Learning,Lille,France,Jul 6-11,2015:957-966.
[26]Wolf L,Hanani Y,Bar K,et al.Joint Word2vec networks for bilingual semantic representations[J].International Journal of Computational Linguistics and Applications,2014,5 (1):27-44.
[27]Goldberg Y,Levy O.Word2vec explained:deriving Mikolov et al.'s negative-sampling word-embedding method[EB/OL]. [2015-10-15].http://arxiv.org/pdf/1402.3722.pdf.
[28]Su Zengcai,Xu Hua,Zhang Dongwen,et al.Chinese sentiment classification using a neural network tool—Word2vec [C]//Proceedings of the 2014 International Conference on Multisensor Fusion and Information Integration for Intelligent Systems,Beijing,Sep 28-29,2014.Piscataway,USA: IEEE,2014:1-6.
附中文參考文獻:
[7]張琳,胡杰.FAQ問答系統句子相似度計算[J].鄭州大學學報:理學版,2010,42(1):57-61.
[8]藍雁玲,陳建超.基于詞性及詞性依存的句子結構相似度計算[J].計算機工程,2011,37(10):47-49.
[9]陳麗莎.自動問答系統中基于WordNet的句子相似度計算研究與實現[D].廣州:華南理工大學,2014.
[10]夏天.漢語詞語語義相似度計算研究[J].計算機工程, 2007,33(6):191-194.
[11]田久樂,趙蔚.基于同義詞詞林的詞語相似度計算方法[J].吉林大學學報:信息科學版,2010,28(6):602-608.
[12]張培穎.多特征融合的語句相似度計算模型[J].計算機工程與應用,2010,46(26):136-137.
[16]張劍,屈丹,李真.基于詞向量特征的循環神經網絡語言模型[J].模式識別與人工智能,2015,28(4):299-305.
[20]熊富林,鄧怡豪,唐曉晟.Word2vec的核心架構及其應用[J].南京師范大學學報:工程技術版,2015,15(1):43-48.

LI Feng was born in 1982.He received the Ph.D.degree in computational linguistics from PLA University of Foreign Languages in 2012.His research interests include natural language processing,big data analytics and corpus linguistics,etc.
李峰(1982—),男,河南固始人,2012年于解放軍外國語學院計算語言學專業獲得博士學位,主要研究領域為自然語言處理,大數據分析,語料庫語言學等。

HOU Jiaying was born in 1993.She is an M.S.candidate at Kunming University of Science and Technology.Her research interests include nature language processing and information retrieval,etc.
侯加英(1993—),女,山東泰安人,昆明理工大學碩士研究生,主要研究領域為自然語言處理,信息檢索等。

ZENG Rongren was born in 1973.He received the M.S.degree in computer science and technology from National University of Defense Technology in 1997.His research interests include information system design,artificial intelligence and radio frequency identification,etc.
曾榮仁(1973—),男,福建莆田人,1997年于國防科技大學計算機科學與技術專業獲得碩士學位,主要研究領域為信息系統設計,人工智能,射頻識別等。

LING Chen was born in 1980.He graduated from PLA University of Science and Technology in 2001.His research interests include big data analysis,information system design and artificial intelligence,etc.
凌晨(1980—),男,山東淄博人,2001年畢業于解放軍理工大學,主要研究領域為大數據分析,信息系統設計,人工智能等。
Research on Multi-Feature Sentence Similarity Computing Method with Word Embedding*
LI Feng1,2+,HOU Jiaying3,ZENG Rongren1,LING Chen1
1.Logistics Science Research Institute of PLA,Beijing 100166,China
2.School of Computer Science and Engineering,Beihang University,Beijing 100191,China
3.School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650504,China
+Corresponding author:E-mail:li_bopr@126.com
Based on the summarization of sentence similarity computing methods,this paper applies 34 000 pieces of texts of People's Daily to train word vector space model for semantic similarity computing.Then,based on the trained word vector model,this paper designs a multi-feature sentence similarity computing method,which takes both word and sentence structure features into consideration.Firstly,the method takes note of possible effects of the number of overlapping words and word continuity,and then applies word vector model to calculate the semantic similarity of non-overlapping words.Regarding the aspect of sentence structure,the method takes both overlapping word order and sentence length conformity into consideration.Finally,this paper designs and implements four different sentence similarity calculating methods,and further develops an experimental system.The experimental results show that the method proposed in this paper can get satisfactory results and the combination and optimization upon the features of words and sentence structures can improve the accuracy of sentence similarity calculating.
word embedding;sentence similarity;Word2vec;algorithm design
10.3778/j.issn.1673-9418.1604029
A
TP391
*The National Natural Science Foundation of China under Grant No.61370126(國家自然科學基金);the National High Technology Research and Development Program of China under Grant No.2015AA016004(國家高技術研究發展計劃(863計劃));the National Social Science Foundation of China under Grant No.15GJ003-154(國家社會科學基金);the Fund of the State Key Laboratory of Software Development Environment under Grant No.SKLSDE-2015ZX-16(軟件開發環境國家重點實驗室探索性自主研究課題基金).
Received 2016-04,Accepted 2016-06.
CNKI網絡優先出版:2016-06-23,http://www.cnki.net/kcms/detail/11.5602.TP.20160623.1401.020.html
LI Feng,HOU Jiaying,ZENG Rongren,et al.Research on multi-feature sentence similarity computing method with word embedding.Journal of Frontiers of Computer Science and Technology,2017,11(4):608-618.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
