基于協同過濾的圖書館個性化推薦系統研究
2017-03-24 11:49:56陳新張楠王洪信
卷宗 2016年11期
關鍵詞:分類
陳新+張楠+王洪信
摘 要:分析了基于用戶的協同過濾系統的原理和優缺點,針對圖書館系統的特殊性,采取對圖書進行分類和對讀者進行分類想結合的方法,尋找用戶的相似最近鄰居,可有效克服協同過濾系統的稀疏性、可擴展性問題。
關鍵詞:協同過濾;個性化推薦;稀疏性;分類
Abstract:This paper analyzes the principle and advantages and disadvantages of user-based collaborative filtering system. According to the particularity of the library system, the method of classifying the books and classifying the readers to find the similar neighbors of the users can effectively overcome the collaborative filtering system Sparsity and scalability issues.
Key words:Collaborative filtering; Personalized recommendations; Sparseness; classification
1 引言
在社會科技發展變化的驅動下,為了適應時代發展,圖書館從最初的紙質圖書收藏地,不斷地發展進化。過去,圖書館是人們獲取知識、資源的的最主要途徑,而如今網絡技術迅猛發展,信息呈爆炸式增長,人們正在傾向從網絡獲取知識,圖書館的作用正在不斷弱化。
面對大數據時代的挑戰,圖書館領域需要變革,改變傳統圖書館的被動式服務方式,采取更加積極的主動式服務方式[1],以提高圖書館利用率,強化圖書館的作用和職能。其中對讀者進行個性化推薦就是主動服務的一種。
個性化推薦技術,是對用戶的個人信息和瀏覽歷史進行分析,從而找到用戶的興趣偏好,對用戶進行針對性的個性化推薦服務。
目前主流的推算算法主要有:協同過濾推薦算法、基于內容的推薦算法、基于知識的推薦算法、混合推薦算法等[2]。其中協同過濾推薦算法是應用最廣泛的一種算法。
2 基于用戶的協同過濾推薦系統
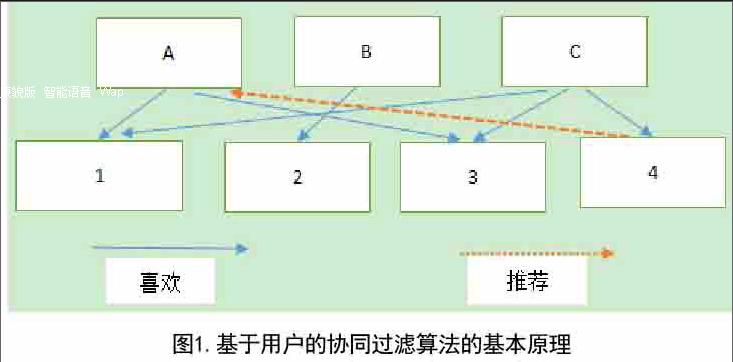
2.1 基于用戶的協同過濾系統基本原理
基于用戶的協同過濾推薦系統的基本原理是,根據所有用戶對物品或者信息的偏好,找出與當前用戶有相似興趣或偏好的“鄰居”用戶群,記為“K鄰居”,然后基于這K個鄰居用戶的興趣偏好信息,對當前用戶進行推薦[4]。
圖1為基于用戶的協同推薦系統的基本原理,用戶A喜歡物品1和物品3,用戶B喜歡物品2,用戶C喜歡物品1、物品3和物品4,可以看出用戶A和用戶C共同喜歡物品1和物品3,可判斷用戶A與用戶C有相似的興趣,那么用戶C喜歡物品4,用戶A可能也會對物品4感興趣,于是把物品4推薦用戶A。
如果把A看做當前用戶,那么C便是A的相似K鄰居用戶。基于用戶的協同過濾的基礎是評價數據庫[3],
2.2 計算過程。
基于用戶的協同過濾的關鍵問題,是如何找到與當前用戶相似度高的“K-鄰居”用戶。余弦距離相似性是應用廣泛的方法[5]。
公式(1)通過計算向量、夾角的余弦作用衡量用戶a與用戶b的相似度。如果兩個向量方向一致,夾角接近零,那么這兩個向量就相近。
例如:經過計算,用戶A與用戶B的夾角余弦接近1時,則可以認為用戶A與用戶B是相似的。
2.3 協同過濾算法的缺點
協同過濾算法能夠過濾難以進行機器自動基于內容分析的信息,能夠對于一些復雜的、難以表述的概念進行過濾,但是也存在一些缺點和不足[6]。
1)稀疏性問題。當系統中數據量大的情況下,用戶對商品的評價非常稀疏,通過評分矩陣,難以找出用戶之間的相似性。
2)冷啟動問題。當資源進入系統中時,資源的評分為空,系統就無法進行推薦。
3)可擴展性問題。當數據庫中資源不斷增長,用戶不斷增多,評分矩陣會變得十分復雜,計算效率下降。
3 基于分類的協同過濾圖書館個性化推薦系統
3.1 以圖書分類號為基礎進行分類。
對于圖書館系統來說,讀者的興趣相對固定,尤其是高校圖書館,學生除了對一些比較熱門的社會學書籍感興趣外,就只對自己本專業的書籍資料有興趣,跨專業借閱圖書的現象極少出現。而圖書館系統中的圖書都有明確的分類,以中文圖書為例,依據中圖分類法,圖書可分為5大部類,22個大類,大量的小類。對于圖書推薦系統的協同過濾,在相同的圖書分類內查找有相同興趣的用戶,成功幾率會有較大的提升。
3.2 以讀者特征進行分類
對于讀者也可以進行分類,高校圖書館讀者信息完善,有明確的院系分類,在同學院、同專業中尋找最近鄰,成功幾率可以提升很多。此方法可以有效解決算法的稀疏性問題和可擴展性問題。對于公共圖書館,可以采用平均值聚類算法對讀者進行聚類劃分。
3.3 算法流程
以圖書分類號為基礎進行分類為例,流程如下:
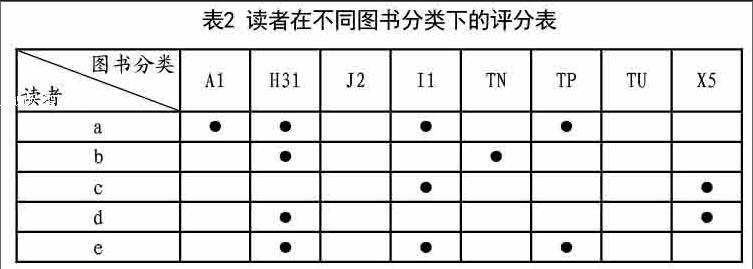
1)通過讀者的歷史評分記錄,建立讀者在不同圖書分類下的評分矩陣,表2是一個評分矩陣的例子。
2)對讀者進行分類,降低矩陣維度。
表2 中讀者d對H31、X5兩個分類的圖書進行了評分,表明d對這兩個分類的圖書感興趣,從表2中可以看出,只有讀者b、c、e同d存在交集,這樣就可以把縮小矩陣的維度,提高計算效率。
可以看出b、e與d的交集是H31,而H31是英語類,屬于工具學科,在高校中,是絕大多數學生都會學習的,有廣泛通用性,在推薦系統中,可以看做是一個干擾項,去掉H31這個干擾項,就只有c與d有交集,從而將矩陣維度進一步降低。
3)計算推薦結果
使用公式(1)的余弦距離相似性算法,找到最近鄰,得出推薦結果。
4 結語
協同過濾推薦系統在電子商務領域應用廣泛,在圖書館領域,需要根據圖書館的特點,設計更加優秀的算法,克服稀疏性、可擴展性的問題,使圖書館個性化推薦系統達到更好的推薦效果,更好地為讀者服務。
參考文獻
[1]黃紅梅.數字圖書館主動服務模式優化研究[J].圖書館學刊,2009,26(9):61-63.
[2]陳潔敏.個性化推薦算法研究[J].華南師范大學學報(自然科學版),2014,46(5):8-15.
[3]黃創光.不確定近鄰的協同過濾推薦算法[J].計算機學報,2010,33(8):1369-1377.
[4]馬宏偉.協同過濾推薦算法綜述[J].小型微型計算機系統,2009,30(7):1282-1288.
[5]基于用戶相似度的協同過濾推薦算法[J].通信學報,2014,35(2):16-24.
[6]基于用戶興趣分類的協同過濾推薦算法[J].計算機系統應用,2011,20(5):55-59.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
