基于本體的電子病歷后結構化模型關鍵技術
2017-03-22 04:02:14,
中華醫學圖書情報雜志 2017年8期
,
我國幅員遼闊,地區間經濟發展不平衡,區域間醫療資源的差距明顯,優質醫療資源始終處于緊張狀態,“看病難”“看病貴”成為一種常態現象[1]。人類社會正飛速進入信息大數據時代,充分利用醫療信息資源,進行數據處理和分析,可以實現計算機輔助決策,推動分級診療、精準治療,從而進一步合理配置醫療資源,促進基本醫療衛生服務實現均等化。
1 研究背景
1.1 電子病歷及電子病歷挖掘現狀及發展趨勢
醫療信息資源有非結構化文本、圖像、圖形、聲音、視頻等多種形式[2],文本信息占比高達95%以上,文本信息又以電子病歷(Electronic Medical Record,EMR)為重要代表。電子病歷出現的初衷是解決越來越多需要存儲的醫療文本問題[3],發展到今天,電子病歷要求包含患者的就診信息,支持記錄診斷和治療情況,并可以實現信息的累加、共享、分析和利用,促進醫療服務,提高醫療質量和效率。國內目前很多大型醫院的電子病歷系統,對患者臨床信息的描述性數據是以自由文本形式存在的[4],非結構化的輸入形式帶來了數據的多維性,不確定性,受控醫學詞匯表以及支持臨床決策的臨床數據倉庫,使大量臨床數據分散在不同的系統中,很難實現高效方便地獲取病人完整和準確的診療信息[5]。經過標準化處理的文本信息,通過查詢,分析,才能真正輔助臨床決策,實現精準醫療。目前國內外對電子病歷的應用都在朝集成方向、專家智能方向發展[6],希望通過建標準、區域共享化實現醫療信息的可擴展、可互操作等深層次應用。在互聯網技術的蓬勃發展的前景下,利用“互聯網+”跨學科思維,把電子病歷從語義的角度解讀,并描述醫學事實的內涵及外延,利用本體、知識庫模型,能更有效挖掘電子病歷資源。
1.2 本體研究在電子病歷中的應用
隨著醫學信息電子化處理的飛速發展,愈來愈多的應用受制于術語問題(terminology problem)[7],即同一醫學概念在不同領域和不同人群中表達方式不同,造成信息查詢和利用的障礙。醫院信息系統的開發供應商希望有一種統一的編碼系統來滿足臨床電子病歷發展的需要。
醫學本體描述客觀的醫學事實[8],是客觀事實的抽象模型,用精準的數學描述反映概念之間的關系,能進行共享利用。通過本體,知識庫模型打造一體化醫學語言系統[9],可以規范統一的概念表達,提供信息查詢的統一入口,從而解決獲取信息的語言屏障。例如美國國立醫學圖書館開發的醫學語言系統(Unified Medical Language System,簡稱UMLS),中國中醫研究院開發的傳統醫學一體化醫學語言系統[10],中國醫學科學院開發的中文一體化醫學語言系統等[11]。其方式都是系統整合各種醫學資源的檢索術語,使許多不同源術語集中的相同語義擁有標準格式,用以完成醫學信息的存儲、提取與分析。隨著信息技術的發展,醫療信息資源本體、知識庫可以實現制定統一的知識規則,通過跨學科融合,促進電子病歷信息的標準化,增加可互操作、可重復利用。
本文將以川崎病電子病歷大數據為對象,將文本處理簡化為空間的三維向量(本體模型)進行實例展示,通過計算、比較表達文本在語義上的相似度,幫助找尋出川崎病電子病歷海量數據中的關聯規則,歸納出川崎病患者的診斷標準、醫生的診療習慣、診療模式、用藥習慣等診療行為。相對于傳統的文本檢索方式,能更準確、更有效、更快速地分析電子病歷信息,進行臨床輔助診療。
2 基于本體的電子病歷后結構化模型構建
本體(Ontology)是知識庫構建的基礎[12]。本文從某三甲專科兒童醫院病案室收集了以川崎病為最終診斷結果的電子病歷2 294份,采用形式概念分析,對電子病歷進行了數據清洗,建立本體,本文以一條病程記錄為實例演示如何建立川崎病概念本體(圖1)。
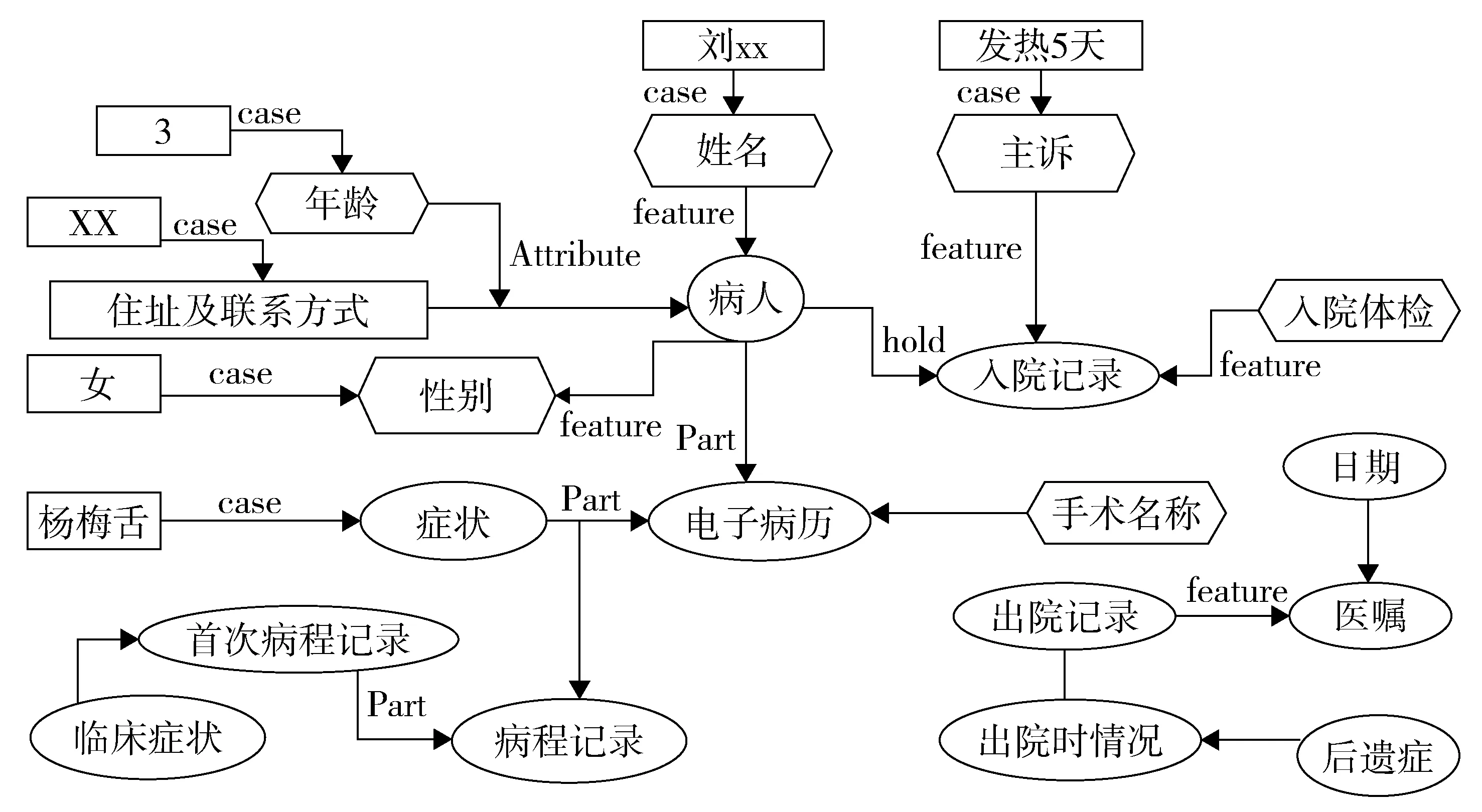
圖1 川崎病概念本體的鑒定
圖1顯示,從病歷中可以提取關于川崎病的表述概念,表述概念與本體最大的區別在于,表述概念屬于本體的擴展,具有可擴展性和不確定性,而本體是表述概念的內涵。因此建立概念本體在信息檢索上更具有優勢。
定義1(表示概念 ):假設一個三元組Y=(L,M,N),其中L是所有對象的集合,M是屬性集合,N (LXM),也就是說N是LXM的子集。
定義2:設{O1,D1},{O2,D2}是形式背景{O,D}兩個形式概念,{O2,D2}是{O1,D1}的超概念。
定義3:概念相似度計算為:


圖2本體產生的概念圖
由以上定義及概念圖,本體產生具體步驟如下:
第一,結構化電子病歷,針對vMR中的數據,參考HL7 CDA的結構及其對應的文檔模板,用可擴展標記語言XML構建標準化的川崎病電子健康文檔,其步驟為:定義解析文檔、生成XML解析數據文件,形成規范樣式表。最終生成川崎病結構化電子健康文檔。
第二,形成領域詞典,每個病人的所有記錄,形成一條結構化的病歷,這里面包括了患者從到醫院后的所有信息。從每一條信息中取出相關詞語并實現再分詞,形成詞典。
第三,計算相似度,運用上述定義1、2、3公式計算其相似度。
第四,形成川崎病本體,去掉相似度相近詞語,形成本體。
3 基于向量空間模型知識庫的構建
知識庫與本體是多對一的映射關系[13],知識庫是本體的外延,本體是知識庫的內涵[14]。前面已經形成川崎病的本體,為進一步打造知識庫打下堅實基礎。由此基于向量空間模型算法做如下定義:
根據上述定義構建知識庫的方法如下:
第一,建立患者語義庫、電子病歷醫生語義庫、專家語義庫。
第二,從以上各種語義庫中分別取詞。
第三,利用定義1、2、3計算Tf、Idf、W。
第四,分別計算相似度。通過計算相似度建立起川崎病本體與各種語義庫的一對多映射關系,形成患者知識庫、醫生知識庫、專家知識庫。
4 驗證
本驗證限于篇幅不能全部驗證,僅以一條病人電子病歷為說明,其中數據庫清洗,XML結構化電子病歷限于技術的相對成熟就不在這里描述,直接給出一條簡單的電子病歷,且以醫生某一項檢查本體和知識庫為樣本。
4.1 本體形成
表1為4條病人需要檢查記錄,分別記錄為D1、D2、D2、D4。

表1 4條病人需要檢查的記錄
以上每條記錄去掉無關詞后形成文檔詞序列見表2。

表2 4條病人檢查記錄文檔詞序列
根據以上表格及形式背景定義得出屬性集合G:彩超 多普勒 ,屬性M分別是:心臟、 彩超、 多普勒、 腹部 、胃腸。那么其子集I為{彩超, 多普勒,心臟},{ 彩超 ,多普勒,彩超},{彩超 ,多普勒,多普勒},{彩超 ,多普勒,腹部},{彩超, 多普勒,胃腸}。由此根據定義3運算得出結論本體為:彩超 多普勒 。
4.2 知識的形成
根據本體建立表3。
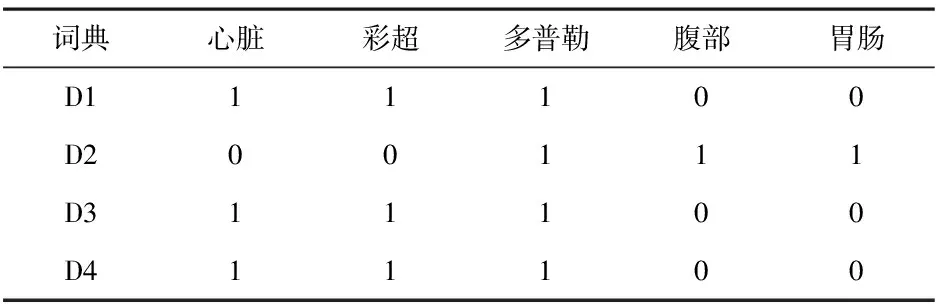
表3 屬性M本體構建
分別計算Tf、Tdf、W,結果見表4。

表4 屬性M權值分布
根據以上結果得出結論,檢查部分的要點為:多普勒 心臟 彩超 腹部 胃腸。經問卷調查臨床醫生,有川崎病的孩子檢查都要進行多普勒心臟彩超確診,但有少部分需要做腹部或胃腸彩輔助檢查,可見此法構建本體,知識庫真實有效。
川崎病大部分的患兒經臨床治療后能康復情況較好,但部分川崎病患兒會因癥狀體征不典型性而容易與其他特異或者非特異炎癥疾病發生混淆,還有極少數會因并發癥發展成為重癥,三甲兒童專科醫院的醫生臨床經驗豐富,基于臨床癥狀判斷,檢查、佐證,能較及時判斷患兒病情。但是更多的二級醫院醫生相關臨床經驗可能不足,如果借助川崎病的知識庫,可以更好的進行臨床的診斷和治療,從而實現對疾病的早期干預和治療。
5 結論
本文采用的構建模型方法簡單、實用、效率高,軟件的實現相對簡單,開發成本低。項目成果亦可用于其他病種,構建模型方法擺脫了傳統一病一法的粗糙聚類方法。為推動電子病歷數據挖掘,疾病的分類管理、分級診療、計算機輔助決策、精準醫療的全面實施提供有力知識保證。
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
中華手工(2017年2期)2017-06-06 23:00:31
山東青年(2016年1期)2016-02-28 14:25:25
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
海外英語(2006年11期)2006-11-30 05:16:56
