應用假設檢驗需特別注意的幾個問題
2017-03-21 05:10:10,,,,,
中華醫學圖書情報雜志 2017年5期
, , , , ,
假設檢驗是醫學科研中重要的推斷方法,用于判斷醫學研究中通過樣本觀察到的“差別”是由抽樣誤差引起的還是因總體本身不同造成的。如為比較某新藥與常規用藥治療嬰幼兒貧血的療效,將20名貧血患兒隨機等分兩組,分別接受兩種藥物治療,結果測得兩組血紅蛋白增加量(g/l)的平均值分別為23.6和20.9。研究人員需借助假設檢驗判斷觀察到的“差別”是由抽樣誤差(即患兒個體的差異)引起的還是因總體本身不同(即兩藥物療效不同)造成的。
假設檢驗是指對總體提出某種假設 ,然后利用從總體中抽樣所得的樣本信息檢驗所提假設是否正確的一種統計推斷方法,在科學研究中應用非常廣泛。但由于人們對假設檢驗的相關概念和方法理解不夠深入和透徹,常會做出不準確甚至是錯誤的推斷[1-2]。本文就參數假設檢驗選擇單側檢驗還是雙側檢驗、如何建立原假設和備擇假設、檢驗結果的誤判率有多大、如何提高檢驗效能等問題展開討論、辨析,能夠消除人們的疑惑,使假設檢驗發揮更好的作用。
1 兩類錯誤、檢驗效能及誤判率
對于任何一次假設檢驗,不論其結論是拒絕H0,還是接受H0,都有判斷錯誤的可能,即可能犯兩類錯誤。如在前面提到的比較兩種藥物治療嬰幼兒貧血的療效的問題中,H0設為兩種藥物療效無顯著性差別,并取檢驗水準α=0.05,則當統計分析結果認為兩藥物療效有顯著性差別時會犯第一類錯誤,但犯第一類錯誤的概率很小,小于規定的檢驗水準0.05,即犯錯的概率小于5%;當統計分析結果認為兩藥物療效無顯著性差別時會犯第二類錯誤,但犯第二類錯誤的概率未知。
第一類錯誤(也稱Ⅰ型錯誤)是指拒絕了實際上成立的H0,其概率大小用α表示;第二類錯誤(也稱Ⅱ型錯誤)是指接受了實際不成立的H0,其概率大小用β來表示。通常把1-β稱為檢驗效能(也稱把握度),其意義是當兩個總體確有差別時,按規定的檢驗水準α能夠發現該差別的能力[3]。如1-β=0.90,則意味著當H0不成立時,理論上在每100次抽樣檢驗中,按照α的檢驗水準平均有90次能夠得出差別有統計學意義的結論。
當樣本含量一定時,不可能同時降低兩類錯誤,減小α會導致β增大,而減小β又會導致α增大。要使α與β同時減小,則只有加大樣本含量。
在給定樣本含量的情況下,我們總是控制第一類錯誤的概率,使它不大于α,α通常取0.05、0.01等。這種只控制第一類錯誤的概率,而不考慮第二類錯誤的概率的檢驗稱為顯著性檢驗[4]。拒絕H0時認為差別顯著,有統計學意義,誤判率P<α;不拒絕H0時認為差別不顯著,沒有統計學意義,誤判率未知。
2 單、雙側檢驗的選擇
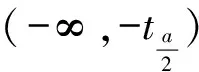
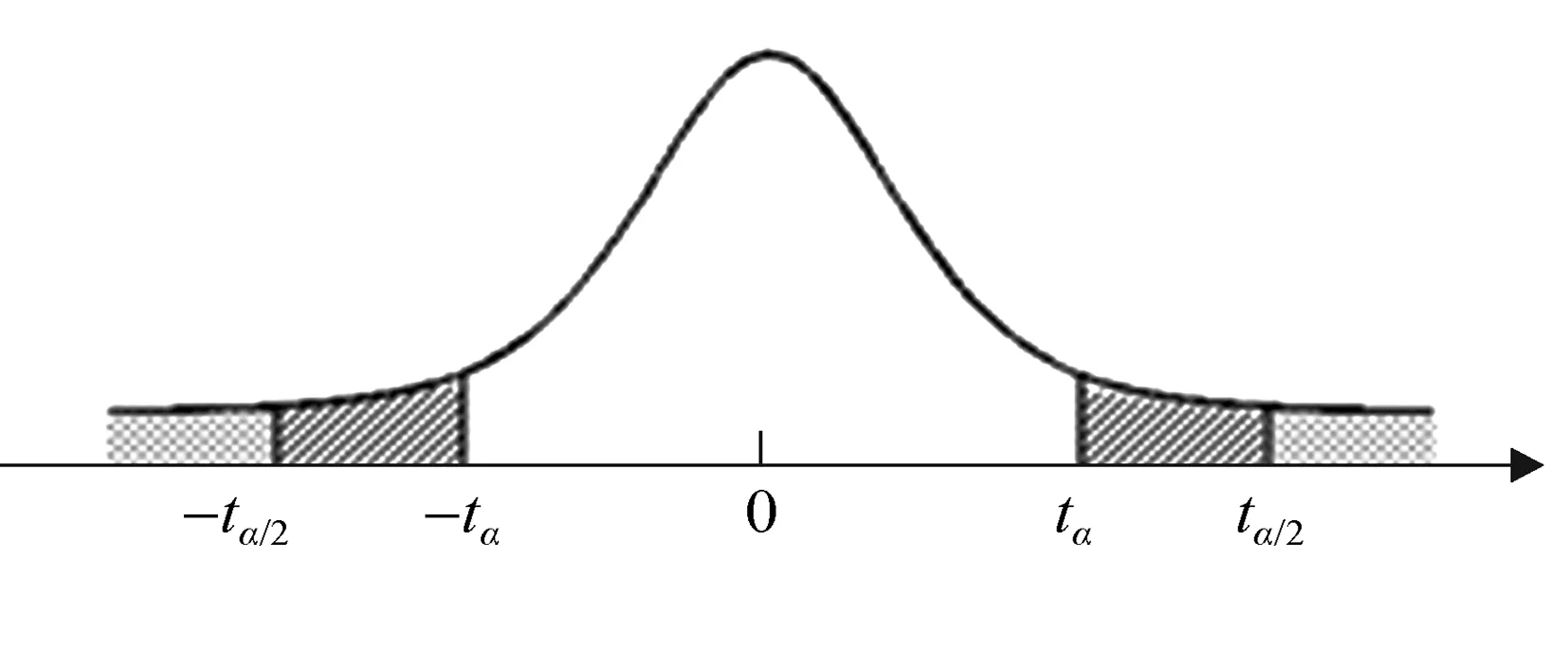
圖1 t檢驗拒絕域示意圖
3 原假設和備擇假設的建立
因為假設檢驗只能控制第一類錯誤的概率α(拒絕H0可能犯的錯誤),即只規定了拒絕H0時的誤判率要小于檢驗水準α(α通常取0.05或0.01),未控制第二類錯誤的概率β(接受H0可能犯的錯誤)。因此在實際應用時,為了通過假設檢驗對某一結論(如試驗中發生的結果)取得科學的、強有力的支持,通常把這種結論本身作為備擇假設H1,而將這一結論的逆命題作為原假設H0。這樣,當假設檢驗的結果為拒絕H0而接受H1時,犯錯誤的概率很小(小于顯著性水準α,即P<α)。因此有充分的理由接受H1,即對H1的結論給出了科學的、強有力的支持[5-6]。如生產線運行異常時需停產,會造成嚴重后果,需要有科學的、強有力的支持時才能停產,因此一般把生產線異常作為備擇假設。下面通過實際例子進一步說明。
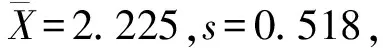
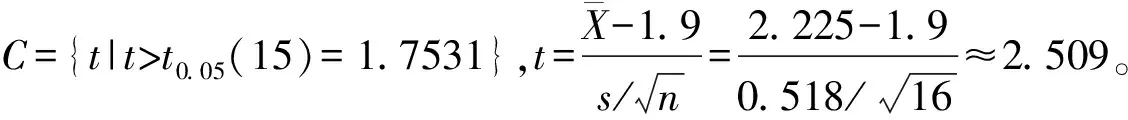
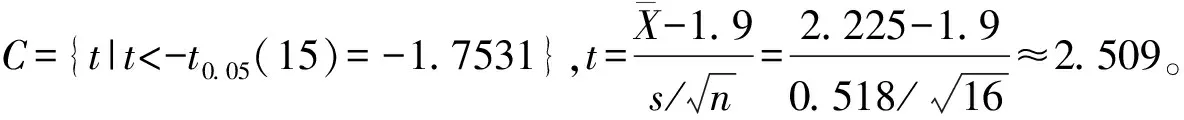
上面的例子說明,由于假設檢驗只能控制第一類錯誤的概率α,所以只有當檢驗結果拒絕H0而接受H1時,誤判率才是已知的(為P<α),結論才具有科學性。因此應當把想要證實的結論作為備擇假設H1,而將這一結論的逆命題作為原假設H0。
4 提高檢驗效能的途徑
當假設檢驗結果為“不拒絕”原假設H0時,僅僅意味著樣本數據與原假設不存在矛盾,并不意味著原假設應該被接受。這種情況很可能是由于樣本太小等原因使得檢驗效能1-β不足,發現不了真實存在的差別,研究者切忌因此而放棄原有的觀點,得出組間“無差別”的結論。“不拒絕”不等于“接受”,當相關專業知識或經驗支持“有差別”的猜測時,可通過加大樣本含量降低二類錯誤的概率β,提高檢驗效能1-β。當然,也可以適當增大一類錯誤的概率α,以減少二類錯誤的概率β,從而達到提高檢驗效能1-β的目的。
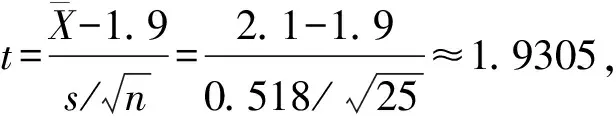
在“風險”決策中, 對“風險”的處理依賴于決策者的價值判斷。若要嚴格控制一類錯誤的概率α,就只能通過加大樣本含量來提高檢驗效能。實際上,如果總體確有差別,那么對于小樣本試驗,總體差別大假設檢驗結果也不一定有統計學意義;而對于大樣本試驗,總體差別小假設檢驗結果也可以有統計學意義。需要說明的是,差別有統計學意義不一定有實際意義。如某新藥比常規用藥的有效率僅提高了1%,沒有臨床意義,但只要樣本量足夠大,假設檢驗就一定能得出差別有統計學意義的結論[3]。
5 科研論文中假設檢驗應用常見的問題
5.1 未說明所用的假設檢驗方法的名稱
不少利用假設檢驗進行數據分析的科研論文中都未說明所用的假設檢驗方法的名稱,只簡單地給出了P值。例如文獻[7]和[8],讀者無法考察作者所選假設檢驗方法是否正確、統計計算結果是否正確等,因此也無法判斷作者給出的結論的科學性。一般而言,科研論文中若用到了假設檢驗方法就應該說明具體的方法的名稱,例如2檢驗,t檢驗,F檢驗等[9]。當一篇論文中用到一個以上的統計分析方法時,還應對每個統計結果所用的統計方法加以說明[10]。
5.2 樣本量小導致假設檢驗結論的科學性差
樣本量太小是導致假設檢驗效能較低、假設檢驗結論科學性差的重要因素之一,但這種情況在科研論文中并不少見。如文獻[7]抽取了科研教育組用戶67人、企業組用戶23人,并對兩組人員的生物醫藥信息來源及信息交流方式進行了統計分析,結果均為差異無統計學意義(P>0.05)。
由于是計數資料,比較的是相對數指標百分比,樣本太小時(尤其是企業組用戶僅抽取了23人)計算出的百分比不能正確地反應對應總體的真實情況,假設檢驗效能較低,假設檢驗結果的可信度較差,即差異無統計學意義(P>0.05)的結論的科學性較差。
6 結語
進行假設檢驗前,應該先分析樣本數據所提示的總體間的差異在專業上或實際中是否有意義。如果有意義,再進行檢驗;如果沒有意義,就不必再作檢驗了,因為不論檢驗結果如何,都是無價值的。
運用假設檢驗要正確設置原假設和備擇假設,應該把想要證實的結論作為備擇假設,因為假設檢驗能夠檢驗備擇假設的真實性而不能驗證原假設的真實性。假設檢驗結果的正確性是以概率為保證的,不論拒絕或不拒絕檢驗假設都可能發生錯誤,應結合專業知識下結論。當假設檢驗結果為差異無統計學意義時要慎重下組間無差異的結論,因為此時有可能是因為樣本太小,假設檢驗效能較低,無法測出存在的差別。必要時可通過加大樣本量降低兩類錯誤的概率,提高假設檢驗結果的科學性。
