一種支持變形基24 FFT的4路并行訪存方法
2017-02-22 01:03:06陳海燕
計算機研究與發展 2017年1期
關鍵詞:變形
楊 超 陳海燕 劉 勝
(國防科學技術大學計算機學院 長沙 410073)(yc.nudt@gmail.com)
一種支持變形基24FFT的4路并行訪存方法
楊 超 陳海燕 劉 勝
(國防科學技術大學計算機學院 長沙 410073)(yc.nudt@gmail.com)
IEEE 802.15.3c是高速無線個人局域網(high-rate wireless personal area networks, WPANs)的國際統一標準,該標準要求采樣頻率為2.592 GHz的情況下在222.2 ns內完成512點FFT運算,這對FFT處理器提出了極高的標準.為了滿足這一要求,部分FFT處理器采用了變形的基24FFT算法以及多運算單元(processing element, PE)并行的方法.在多PE并行的情況下,只有支持其無沖突并行訪問操作數以及并行按序輸入輸出數據的存儲系統設計,才能完全發揮出多個PE單元并行的優勢.根據4路并行變形的基24FFT運算單元訪問操作數的規律,設計了一種支持4路PE并行訪問操作數的地址轉換方法;并且該方法支持并行按序輸入輸出數據,這解決了由于數據輸入或者輸出需要進行位反序操作給并行按序輸入輸出帶來的困難.最后基于同一綜合約束條件進行邏輯綜合,結果表明:該方法比之前的方法節約面積46%,功耗節約了28%,并且該方法支持連續數據流(continuous-flow)操作以及即位運算(in-place).
IEEE 802.15.3c標準;基24;FFT算法;地址轉換;并行;即位運算;連續數據流
快速傅里葉變換(fast Fourier transform, FFT)算法在數字信號處理中得到了越來越廣泛的應用,比如圖像處理、媒體信號處理、光譜分析、電力系統、醫學分析中等.近些年來,正交頻譜分解技術 (orth-ogonal frequency-division multiplexing, OFDM)在無線通信領域中得到了越來越廣泛的應用,而OFDM技術的基礎是FFT算法;因此,隨著無線通信系統需求的發展,FFT處理器的硬件加速性能變得越來越重要.
為滿足無線通信應用需求的發展,IEEE訂立了多種標準[1],比如IEEE 802.11agn,IEEE 802.16e(OFDMA),IEEE 802.16e(OFDM)標準等.FFT算法作為這些標準的核心和基礎算法,其運算的實時性和處理速度要求越來越高.而802.15.3c標準,就是針對高速無線個人局域網(high-rate wireless personal area networks, WPANs)設計的標準,該標準針對采樣頻率為2.592 GHz的512點數據進行FFT運算,FFT處理器完成512點數據的處理時間小于222.2 ns,這對處理器的設計實現帶來了極大的困難.
目前,各種各樣的FFT處理器已經被設計出來,但是總體歸納起來主要分為2類:基于流水結構的FFT處理器[2-5]和基于存儲結構的FFT處理器[6-7].基于流水線的處理器吞吐率和實時性比較高,但是這類處理器需要占用更多的面積和功耗;由于基于存儲的FFT處理器具有占用面積和功耗小的優點,目前在嵌入式應用領域引起了越來越多的重視.
為了滿足應用需求的不斷增長,文獻[8-9]中提出了針對特定領域更高效的FFT算法,文獻[10]中的數字信號處理器為FFT算法設計了專用的指令集和體系結構,文獻[4,9]中采用了多個運算單元(processing element, PE)并行的結構以提高運算性能.
在采用多個PE單元并行運算的結構下,存儲接口是連接存儲器與輸入和輸出(IO)設備以及運算單元之間的橋梁,只有存儲系統支持多個操作數并行訪問,避免訪存沖突引起FFT處理數據停頓,才能發揮出FFT處理器并行運算單元最大的數據運算能力.并且在高速的FFT處理器中IO單元和并行運算單元的數據帶寬應當匹配,這就要求數據IO單元能實現并行存取.然而由于在FFT運算的開始或者結束需要進行位反序操作,這就給輸入或者輸出的并行帶來了困難.因此,一個支持運算過程中操作數并行訪問,以及支持數據并行按序輸入或輸出的存儲系統至關重要,這直接影響著處理器性能的發揮.然而文獻[1,11-14]采用的按位相加、個別地址位異或等地址轉換方法僅僅針對基24或者固定基r有效,并不支持多路變形的基24FFT PE單元并行訪問操作數以及數據并行按序輸入或者輸出.
1 算法原理
1.1 傳統基24算法
N個樣本點的DFT為
(1)
k=0,1,…,N-1,
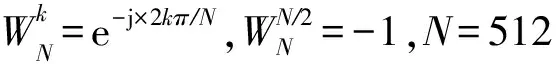
(2)
n1,k1=[0:15];n2,k2=[0:31].
將式(2)帶入式(1)中:
X(16k2+k1)=
(3)
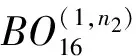
接下來可以繼續對式(3)進行1級基24FFT運算,之后進行1級基2運算,即可完成運算.
通過式(3)我們可以發現,采用傳統的基24FFT運算,一共需要24個存儲體、1個基24與基2 FFT運算單元,然而基24運算單元復雜度比較高,并且采用這種傳統的算法必須進行3級FFT運算.
指除職業暴露外其他個人行為發生的HIV暴露。暴露評估及處理原則尤其是阻斷用藥與職業暴露相似。尤其注意評估后阻斷用藥是自愿的原則及規范隨訪,以盡早發現感染者。
1.2 變形的基24算法
文獻[9]提出了一種變形的基24FFT算法,可以將16個操作數繼續分割成4個1組,采用4次基4 FFT算法以及簡單的乘加單元即可完成.
n1=4m1+m2,
(4)
m1,m2,t1,t2=[0:3],
(5)
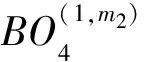
2 無沖突設計
2.1 需求分析
針對IEEE 802.15.3c設計標準,采樣時鐘頻率是2.592 GHz,假設FFT處理器的時鐘頻率是采樣頻率的18,即2.592 GHz×18=0.324 GHz.在IEEE 802.15.3c標準里,在連續數據流的情況下,整個運算的時間只有222.2 ns,則在處理器運算和IO并行的情況下,處理器運算時間和IO時間只有72個時鐘周期.為了達到這一要求,表1列出了采用各種不同的基所需要的運算級數、蝶形操作數總個數以及最大基的PE的并行度.

Table1 The Demand of FFT Processor of IEEE 802.15.3c
可以從表1中看出,基4 FFT算法為主的情況下一共需要4級基4和1級基2 FFT運算,最低需要16個基4 PE并行;基8 FFT算法為主下一共需要3級基8 FFT運算,最低需要4個基8 PE并行;基16 FFT算法為主的情況下,一共需要2級基16 和1級基2 FFT運算,基16 PE并行數最低為2.采用這些傳統的FFT算法,在滿足時間要求的前提下,由于并行度過高,需要消耗大量的面積.而采用上述變形的基24FFT算法,并且結合存儲無沖突設計以及IO全并行的方法可以解決該問題.
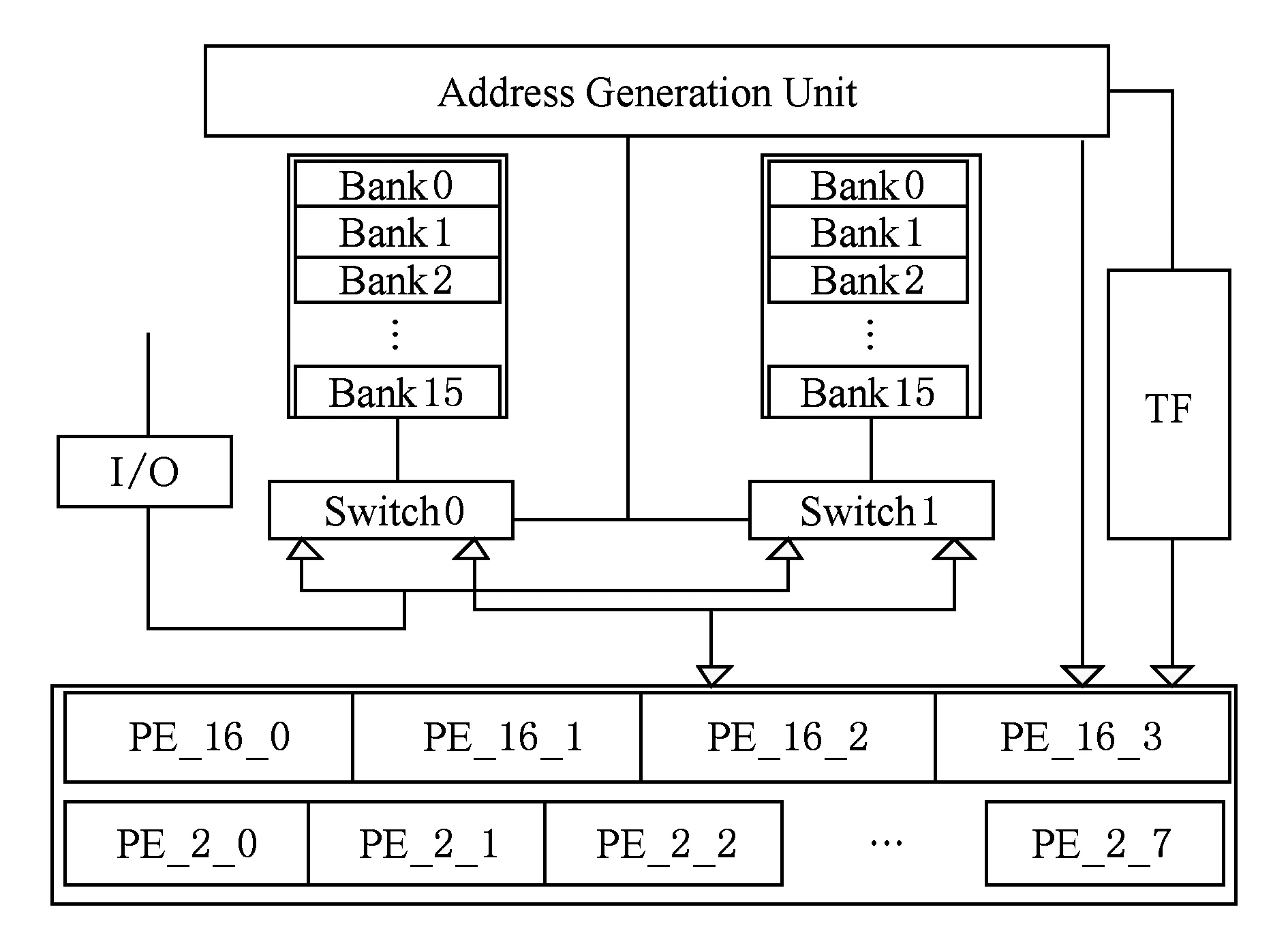
Fig. 1 The architecture of FFT processor圖1 FFT處理器結構圖
為了滿足上述應用需求,采用16個存儲體,并行進行4路變形的基24FFT算法,第1級操作順序不做要求,第2級要求相鄰的2路取數在運算完成后直接進行基2 FFT運算[9,15].雖然文獻[16]里的設計也可以在第2級基16 FFT運算完成后,結果不用存回存儲器而直接進行基2 FFT運算,但是文獻[16]所采用的變形基16 FFT算法流水線過長,PE單元占用面積比較大.為了完成上述設計,支持4路運算單元同時運算,并且支持在第2級運算完成后可以不用存回而直接進行基2 FFT運算,存儲器的并行訪問設計是關鍵.該處理器結構如圖1所示,圖1中2個存儲器均包含有16個雙端口的存儲體;該FFT處理器通過控制開關Switch0以及Switch1完成連續數據流操作;PE單元主要包括4個變形基16 PE和8個基2 PE.
2.2 操作數并行訪問設計
本文主要針對操作數的并行訪問進行優化,旋轉因子可以采用文獻[9,17]中提出的計算方法.在采用上述算法設計時,第1級變形的基24FFT算法4路運算單元同時取數的地址如表2所示:
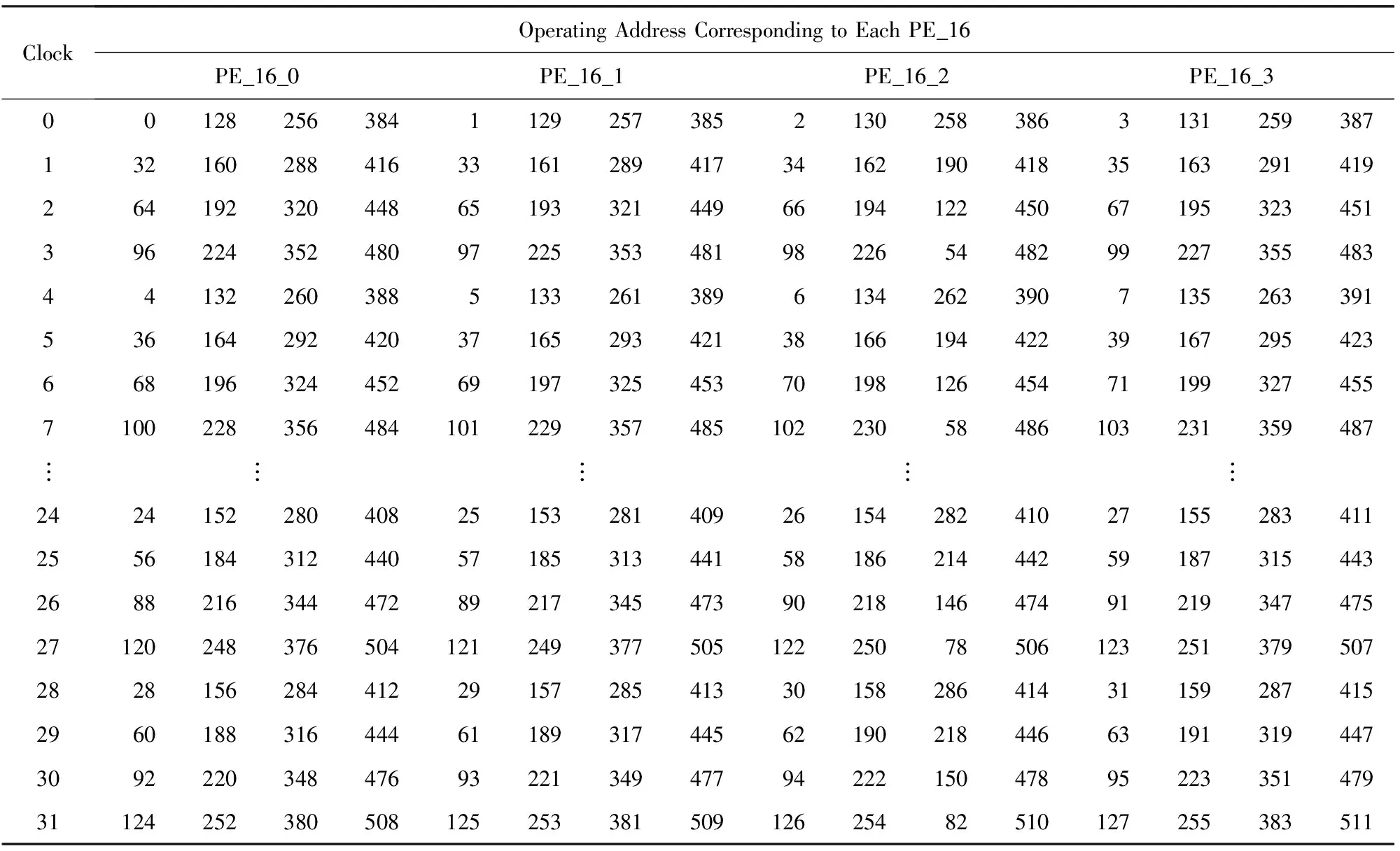
Table2 Operating Access Order in the First Stage
在FFT運算的第1級,同一個時鐘周期需要取出的操作數可以表示為:k,k+128,k+256,k+384,k+1,k+129,k+257,k+385,k+2,k+130,k+258,k+386,k+3,k+131,k+259,k+387; 在每次基24運算的子基4運算時,k值加32;在每次基24運算結束時,下一個基24運算的k值相對于上一次基24運算的初始k值加上4.
第2級4路并行基24FFT運算,必須在相鄰2路基24FFT運算完成后可以直接進行基2 FFT運算,數據的訪問如表3所示.
在FFT運算的第2級,同一個時鐘周期需要取出的操作數可以表示為:k,k+8,k+16,k+24,k+1,k+9,k+17,k+25,k+32,k+40,k+48,k+56,k+33,k+41,k+49,k+57.在每次基24運算的子基4運算時,k值加2;在每次基24運算完成時,下一個基24運算的初始k值相對于上一次基24運算的初始k值加64.
通過該運算訪問操作數的順序我們可以發現,在采用16體低位交叉的存儲方式時,第1,2級每次需要取出的16個操作數分別存在于2個存儲體里,需要8個節拍才能取出,而這8個節拍期間PE會處于閑置狀態,故一般的低位交叉存儲方式并不適合該種變形算法.只有4路基24FFT運算需要訪問的16個操作數可以無沖突并行取出,才可以充分發揮運算單元的并行性,才能在第2級基24FFT運算完成后直接進行基2 FFT運算,以達到節約時鐘周期的目的.
在上述2級運算中,每一個訪存節拍只有對存儲器準確高效地讀寫4路PE并行運算結構才能完全發揮出性能.而地址位b[8:7],b[2:0]可以區分出第1級的數據地址,地址位b[6:3],b[0]可以區分出第2級的數據地址.這里我們令addr表示地址所在的行,bank代表地址所在的存儲體,本文中,bank和addr分別表示如式(6)所示:
(6)
在采用式(6)中地址轉換方法轉換后,地址排列如表4所示.從表4可看出,在地址訪問的第1級和第2級,1次16個操作數可以并行無沖突取出,這就說明該地址轉換可以有效支持變形的基24FFT算法4路同時操作,在第2級運算完成后可以直接進行基2 運算,節省了時鐘數.

Table 3 Operating Order in the Second Stage

Table 4 Address Scheme After Transformation
2.3 結果并行順序輸出
為了在規定的時鐘周期內完成運算,數據的并行輸入和輸出至關重要.假設采用頻域分解DIF方法,數據的輸入可以并行順序輸入,然而結果輸出時,由于需要進行位反序(bit reversal)操作,這給結果的并行按序輸出帶來了難度.所以衡量一個地址轉換方法的好壞,除了是否支持操作數可以并行訪問,運算結果可以并行順序輸出也是關鍵.而本文中的地址轉換方法可以支持運算結果并行順序輸出.
在運算結果輸出時,運算結果是X(k),地址k=k[8:0].數據輸入為x(n),n可以表示為b[8:0].則k用n表示為k=k[8:0]={b[0],b[4:1],b[8:5]}.每個時鐘周期,并行輸出X(16m)~X(16m+15),m=[0:31].m初始值為0,每過一個時鐘周期,m值增加1,即運算結果地址位k[8:4]每次增加1,一直增加到m值為31,即完成一次完整的運算結果輸出.表5給出了運算結果順序輸出分別對應的bank地址和addr地址.

Table 5 Parallel and Normal Order Output of Result
從表5可以看出,在每一個時鐘周期并行輸出的16個連續的運算結果,均存放在不同的bank體內,也即本文中提出的地址轉換方法支持運算結果并行按序輸出.
3 實現與對比
在文獻[1,11-14]中提出的FFT處理器無沖突并行地址排列方法,要么不支持多路變形的基24PE并行訪問操作數,要么不支持數據并行按序輸入或者輸出.在文獻[9,15]中,為了支持4路變形的基24FFT運算單元并行訪問操作數且數據并行按序輸入或者輸出的地址轉換式為
(7)
對比式(6)(7),可以看出式(7)中采用的地址轉換方法,除了需要進行異或操作外,還要對2個2位二進制地址進行乘法操作以及對2進制地址進行1次模4和模16操作.而本文中的地址轉換方法,可以僅僅通過3個2輸入異或門和1個3輸入異或門進行實現,地址轉換電路實現非常簡單.將式(6)中的地址轉換方法,用電路進行實現,b[8:0]代表初始地址,a[8:0]代表轉換后的完整地址,如圖2所示:
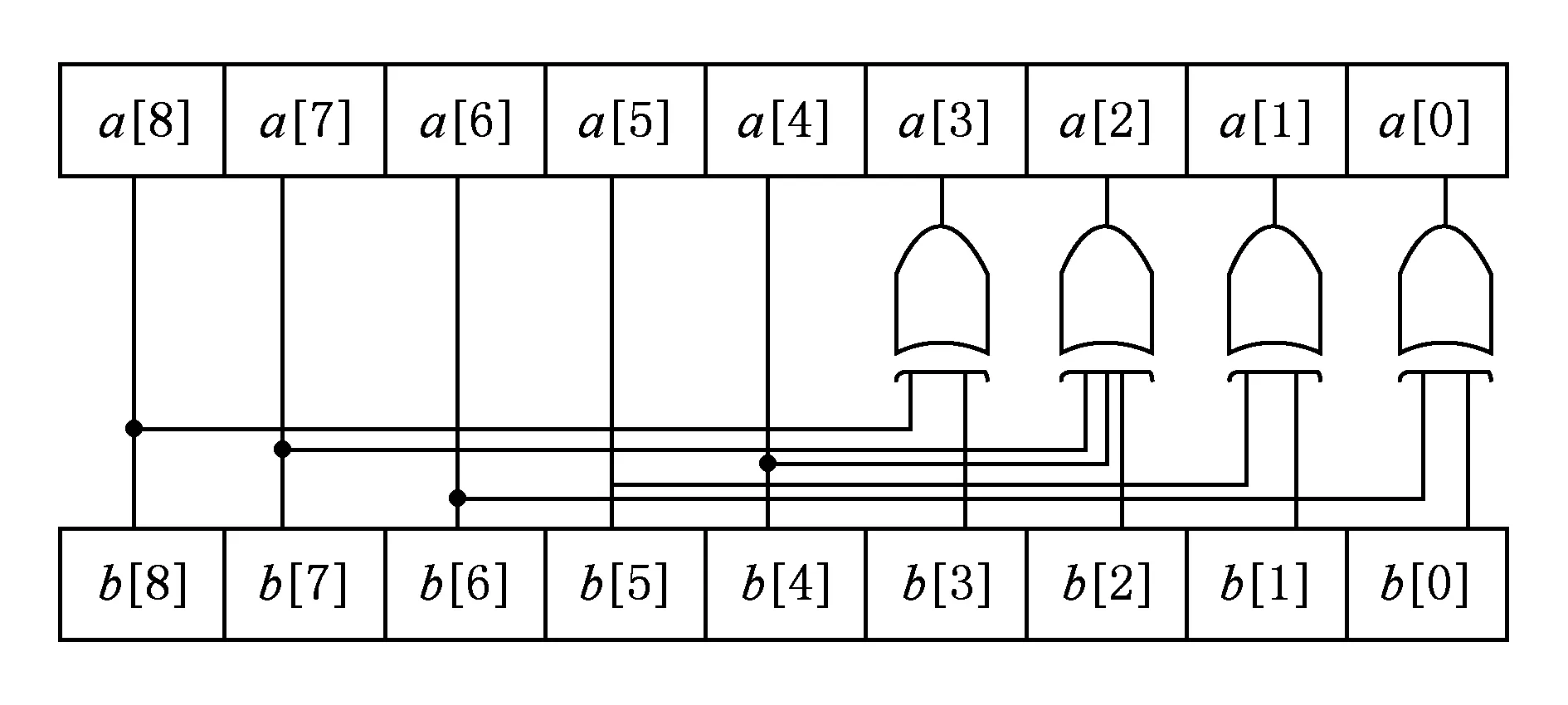
Fig. 2 Circuit of address transformation圖2 地址轉換電路
圖1中地址生成單元主要包括操作數地址生成單元[9]和輸出結果地址生成單元(DIF情況下,原始數據并行按序輸入很簡單,所以不做介紹),分別如圖3、圖4所示.圖3和圖4中的Address Trans-formation Unit就是地址轉換單元.圖3中,計數器從0開始,每個周期加1,一直到31即完成1級FFT運算,2級運算都完成后,整個512點FFT運算結束.圖4中,計數器從0每次加1到31,即可完成512點數據并行按序輸出,圖4中顯示地址為k值位反序后的n值,結果輸出順序和表5一樣.
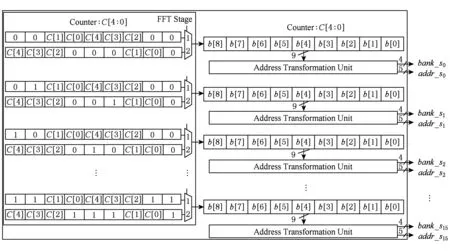
Fig. 3 Circuit of operating address generation圖3 操作數地址生成單元
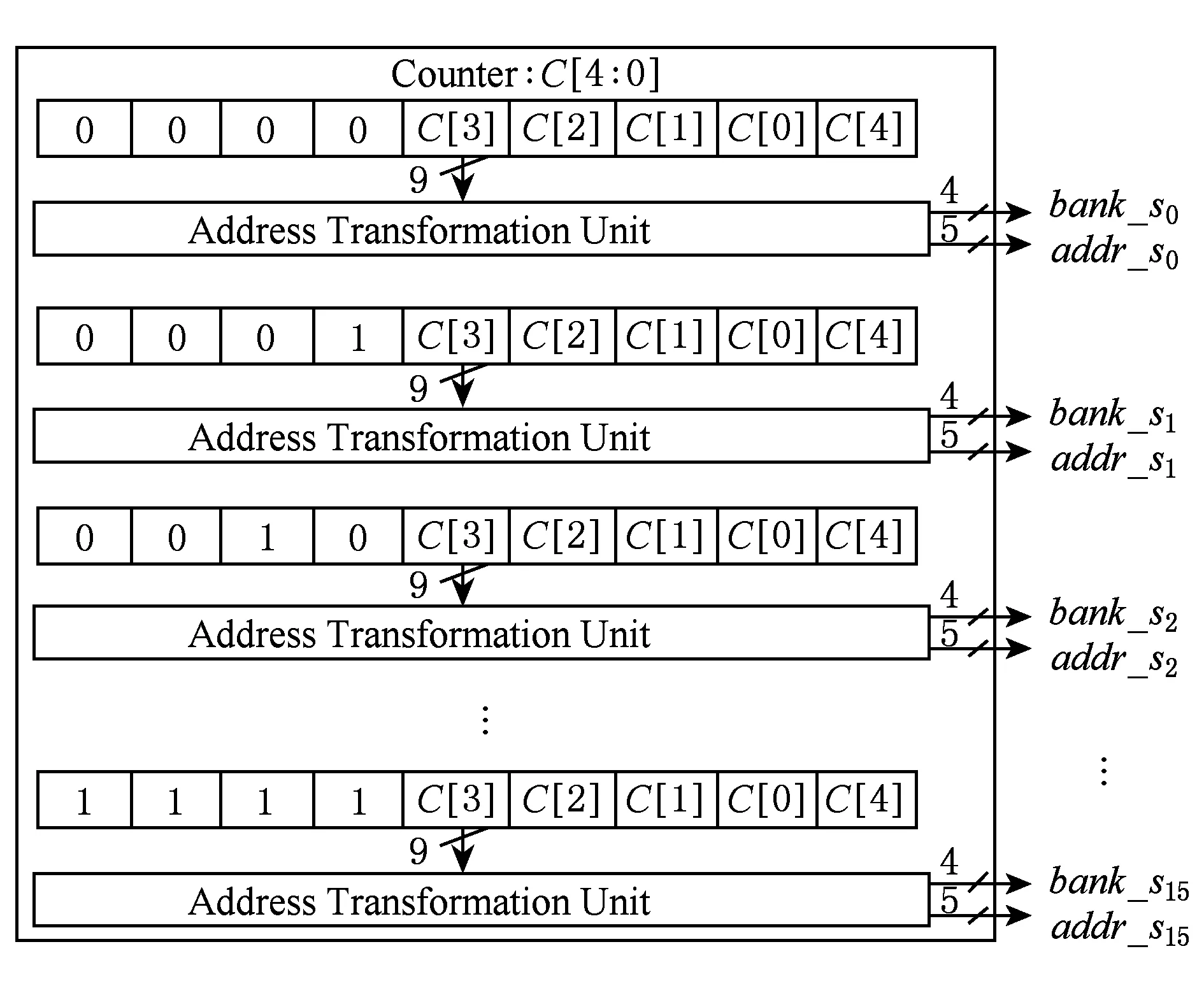
Fig. 4 Circuit of output result address generation圖4 輸出結果地址生成單元
將本文中提出的方法與文獻[9,15]中采用的方法也即式(7),在某廠家65 nm工藝下進行綜合,結果顯示式(7)綜合的面積為81 nm2,功耗為110μW;而本文中的面積約為44 nm2,功耗為79μW;而且在連續數據流的2組雙端口存儲器里,如圖3和圖4所示,數據輸入輸出以及運算取操作數和存中間運算結果共需要2組地址轉換單元,故一共需要16×2=32個地址轉換單元,故本文中的地址轉換方法相對文獻[9,15]中采用的方法一共節約面積(81-44)×32 nm2=1 184 nm2,功耗節約了(110-79)×32μW=992 μW.最后經過對比,本文中的方法比式(7)的方法節約面積46%,功耗節約了28%.
4 總 結
本文提出了一種極其簡單的支持4路變形基24FFT算法并行訪問操作數的地址轉換方法,它支持即位運算和連續數據流;更重要的是,這種簡單的地址轉換方法同時可以支持在位反序的情況下數據并行按序輸入或者輸出,這就可以減少后續其他部件等待FFT運算結果的時間.本文中的方法相對之前方法的實現更為簡單,最后的面積和功耗的綜合結果表明了本文中的地址轉換方法是最優的.
[1]Tsai P Y, Lin C Y. A generalized conflict-free memory addressing scheme for continuous-flow parallel-processing FFT processors with rescheduling[J]. IEEE Trans on Very Large Scale Integration Systems, 2012, 19(12): 2290-2302
[2]Chang Yunnan, Parhi K. An efficient pipelined FFT architecture[J]. IEEE Trans on Circuits and Systems II: Analog and Digital Signal Porcessing, 2003, 50(6): 322-325
[3]Lin Yuwei, Liu Hsuanyu, Lee Chenyi. A 1-GSs FFTIFFT processor for UWB applications[J]. IEEE Journal of Solid-State Circuits, 2005, 40(8): 1726-1735
[4]Shin M, Lee H. A high-speed four-parallel radix-24FFTIFFT processor for UWB applications[C]Proc of IEEE ISCSA’08. Piscataway, NJ: IEEE, 2008: 960-963
[5]Cho T, Lee H, Park J, et al. A high-speed low-complexity modified radix-25 FFT processor for gigabit WPAN applications[C]Proc of IEEE ISCAS’11. Piscataway, NJ: IEEE, 2011: 1259-1262
[6]Ma Y, Wanhammar L. A hardware efficient control of memory addressing for high-performance FFT processors[J]. IEEE Trans on Signal Processing, 2000, 48(3): 917-921
[7]Baas B M. A low-power, high-performance, 1024-point FFT processor[J]. IEEE Journal of Solid-State Circuits, 1999, 34(3): 380-387
[8]Fang Wei, Sun Guangzhong, Wu Chao, et al. A parallel algorithm of three-dimensional fast Fourier transform[J]. Journal of Computer Research and Development, 2011, 48(3): 440-446 (in Chinese)(方維, 孫廣中, 吳超, 等. 一種三維快速傅里葉變換并行算法[J]. 計算機研究與發展, 2011, 48(3): 440-446)
[9]Huang S J, Chen S G. A high-throughput radix-16 FFT processor with parallel and normal inputoutput ordering for IEEE 802.15.3c systems[J]. IEEE Trans on Circuits and Systems I: Regular Papers, 2012, 59(8): 1752-1765
[10]Chen Shuming, Li Zhentao, Wan Jianghua, et al. Research and development of high performance YHFT digital signal processor [J]. Journal of Computer Research and Development, 2006, 43(6): 993-1000 (in Chinese)(陳書明, 李振濤, 萬江華, 等. 銀河飛騰"高性能數字信號處理器研究進展[J]. 計算機研究與發展, 2006, 43(6): 993-1000)
[11]Sorokin H, Takala J. Conflict-free parallel access scheme for mixed-radix FFT supporting IO permutations[C]Proc of IEEE ICASSP’11. Piscataway, NJ: IEEE, 2011: 1709-1712
[12]Takala J H, Jarvinen T S, Sorokin H T. Conflict-free parallel memory access scheme for FFT processors[C]Proc of IEEE ISCAS’03. Piscataway, NJ: IEEE, 2003: IV-524-IV-527
[13]Reisis D, Vlassopoulos N. Conflict-free parallel memory accessing techniques for FFT architectures[J]. IEEE Trans on Circuits and Systems I: Regular Papers, 2008, 55(11): 3438-3447
[14]Richardson S, Markovic D, Danowitz A, et al. Building conflict-free FFT schedules[J]. IEEE Trans on Circuits and Systems I: Regular Papers, 2015, 62(4): 1146-1155
[15]Liu Weichang, Wei Tingchen, Huang Yashiue, et al. All-digital synchronization for SCOFDM mode of IEEE 802.15.3c and IEEE 802.11ad[J]. IEEE Trans on Circuits and Systems I: Regular Papers, 2015, 62(2): 545-553
[16]Huang Shenjui, Chen Saugee. A green FFT processor with 2.5-GSs for IEEE 802.15.3c (WPANs)[C]Proc of IEEE ICGCS’10. Piscataway, NJ: IEEE, 2010: 9-13
[17]Huang S J, Chen S G. A new memoryless and low-latency FFT rotator architecture[C]Proc of ISIC’14. Piscataway, NJ: IEEE, 2014: 180-183

Yang Chao, born in 1990. Received his MSc degree from the College of Computer, National University of Defense Technology (NUDT), China, in 2015. PhD candidate in the College of Computer, NUDT, China. His main research interests include FFT processor, memory system and SIMD.

Chen Haiyan, born in 1967. Received her BE and master degrees in computer science from NUDT, China. Currently a professor in the College of Computer, NUDT, China. Her main research interests include VLSI designs, microprocessor architecture and the memory system.

Liu Sheng, born in 1984. Currently an associate professor at the College of Computer, NUDT, China. Received his PhD degree in electronic science and technology from NUDT, China. His main research interests include memory systems and VLSI designs.
An Address Parallel Access Method Supporting Four Reformulated Radix-24FFT
Yang Chao, Chen Haiyan, and Liu Sheng
(CollegeofComputer,NationalUniversityofDefenseTechnology,Changsha410073)
IEEE 802.15.3c is international unified standard of high-rate wireless personal area networks (high-rate WPANs) to support high data rate applications such as high-definition streaming content downloads, home theater and etc, which needs to finish 512 FFT sizes operations in only 222.2 ns at the sampling rate of 2.592 GHz. To satisfy this demand, some FFT processors adopt parallel PEs and reformulated radix-24FFT algorithm which can reduce the required number of butterfly stages. When parallel PEs are employed, only memory system supporting these PEs parallel accessing operating data and normal order IO can express the full advantages of parallel PEs. According to the accessing law of four reformulated radix-24FFT PEs, this paper designs an address transformation method supporting four reformulated radix-24. And the method in this paper supports normal order IO, which solves the difficulty caused by bit reversal operation of initial or result data, to get a high-throughput design result. The implementation of the single address transformation unit is simple which requires only three two-input XOR gates and one three-input XOR gate. At the same synthesis condition, this method saves area 47% and power 24% compared with the method before. And this method supports continuous flow and in-place operation.
IEEE 802.15.3c; radix-24; FFT; address schedule; parallel; in-place; continuous-flow
2015-07-20;
2016-04-01
國家自然科學基金項目(61472432) This work was supported by the National Natural Science Foundation of China (61472432).
陳海燕(hychen@nudt.edu.cn)
TP332.1
猜你喜歡
智慧少年·故事叮當(2020年10期)2020-11-06 06:19:00
中華詩詞(2020年1期)2020-09-21 09:24:52
河北理科教學研究(2020年1期)2020-07-24 08:14:34
作文成功之路·小學版(2020年11期)2020-02-01 06:26:58
作文周刊·小學二年級版(2018年29期)2018-11-26 11:20:28
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
童話世界(2018年14期)2018-05-29 00:48:08
數學小靈通·3-4年級(2017年10期)2017-11-08 08:42:59
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
數學大王·中高年級(2016年12期)2016-12-26 21:37:36
