界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式挖掘算法研究
2017-02-22 01:02:53聞?dòng)⒂?/span>王少鵬
計(jì)算機(jī)研究與發(fā)展 2017年1期
關(guān)鍵詞:規(guī)范
聞?dòng)⒂?王少鵬 趙 宏
1(東北大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院 沈陽 110819)2(內(nèi)蒙古大學(xué)計(jì)算機(jī)學(xué)院 呼和浩特 010021)3 (醫(yī)學(xué)影像計(jì)算教育部重點(diǎn)實(shí)驗(yàn)室(東北大學(xué)) 沈陽 110819)(wangshaopeng1984@163.com)
界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式挖掘算法研究
聞?dòng)⒂?,3王少鵬1,2趙 宏1,3
1(東北大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院 沈陽 110819)2(內(nèi)蒙古大學(xué)計(jì)算機(jī)學(xué)院 呼和浩特 010021)3(醫(yī)學(xué)影像計(jì)算教育部重點(diǎn)實(shí)驗(yàn)室(東北大學(xué)) 沈陽 110819)(wangshaopeng1984@163.com)
首次對(duì)界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式挖掘問題進(jìn)行了研究.為了克服na?ve算法在處理該問題時(shí)不具有增量計(jì)算的缺點(diǎn),提出了一種基于邊界界標(biāo)窗口技術(shù)的數(shù)據(jù)流最大規(guī)范模式挖掘(data stream maximal regular patterns mining based on boundary landmark window, DSMRM-BLW)算法.該算法將數(shù)據(jù)流上的第1個(gè)待處理窗口定義為邊界界標(biāo)窗口,使用na?ve算法對(duì)其進(jìn)行處理;之后每個(gè)窗口上的最大規(guī)范模式都可以基于前一個(gè)窗口上的最大規(guī)范模式集合增量獲得,可以克服na?ve算法的缺點(diǎn).實(shí)驗(yàn)結(jié)果表明:DSMRM-BLW算法是處理界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式挖掘的有效方法,與na?ve算法相比,具有相同的執(zhí)行結(jié)果,但時(shí)間與空間效率得到了很大的提高.
數(shù)據(jù)流;界標(biāo)窗口;最大規(guī)范模式;增量計(jì)算;邊界界標(biāo)窗口技術(shù)
隨著數(shù)據(jù)流應(yīng)用的不斷增多,挖掘數(shù)據(jù)流中用戶感興趣的模式已然成為數(shù)據(jù)流挖掘領(lǐng)域中一類非常重要的問題[1].現(xiàn)有相關(guān)研究關(guān)注較多的是頻繁模式的挖掘[1-5],但這些研究存在一個(gè)共同問題就是所挖掘模式的判別標(biāo)準(zhǔn)是它們?cè)跀?shù)據(jù)流區(qū)間中的出現(xiàn)次數(shù),而并不是模式本身的出現(xiàn)行為(如模式是否周期性、規(guī)律性地出現(xiàn)),所以對(duì)于很多更注重模式出現(xiàn)行為的實(shí)際應(yīng)用來說,這些研究無法有效解決它們當(dāng)中所涉及到的問題.比如在超市等銷售行業(yè)中,管理人員要獲得一年中常態(tài)情況下貨物的銷售情況,這種常態(tài)通常是指貨物的銷售具有規(guī)律性、周期性且銷售的周期不長.如果我們使用挖掘頻繁模式的方法來處理這個(gè)問題,對(duì)于像夏天的電扇和蚊香、冬天的電熱寶、雨季的雨具等在一年中某些特定時(shí)段內(nèi)銷售頻繁的貨物,也會(huì)因?yàn)檫_(dá)到頻繁標(biāo)準(zhǔn)而被選擇出來,但顯然它們并不是一年中滿足常態(tài)銷售這樣條件的貨物,所以并不是此時(shí)我們關(guān)注的對(duì)象.像實(shí)例中這樣要求出現(xiàn)具有規(guī)律性、周期性的模式通常被稱為規(guī)范模式(regular pattern)[6-12].而類似應(yīng)用場景的存在也使挖掘規(guī)范模式的研究顯得非常必要.
根據(jù)模式規(guī)范度的度量標(biāo)準(zhǔn)不同,現(xiàn)有規(guī)范模式可分為2類:1)以模式發(fā)生周期序列中的最大值作為規(guī)范度的規(guī)范模式;2)以模式發(fā)生周期序列的方差作為規(guī)范度的規(guī)范模式.比較起來前者更有時(shí)間優(yōu)勢(shì),而后者精確度更高.Tanbeer等人在文獻(xiàn)[1]中對(duì)數(shù)據(jù)流環(huán)境下第1類規(guī)范模式的挖掘問題進(jìn)行了研究,給出了基于RPS-tree的處理算法;接著Tanbeer等人又在文獻(xiàn)[6]中對(duì)規(guī)范模式的增量挖掘處理機(jī)制進(jìn)行了研究,提出了一種基于IncRT樹的規(guī)范模式挖掘算法,只需單遍掃描所關(guān)注的數(shù)據(jù)內(nèi)容就可以構(gòu)建IncRT樹,接著基于該樹以模式增長的方法獲得規(guī)范模式;Kumar等人在文獻(xiàn)[7]中對(duì)于數(shù)據(jù)流環(huán)境下基于窗口的第1類規(guī)范模式挖掘算法進(jìn)行了研究,提出了VDSRP算法,該算法采用垂直數(shù)據(jù)格式組織窗口中的數(shù)據(jù),通過類Aprior方法搜索可能的結(jié)果模式,在這個(gè)過程中通過比較這些模式規(guī)范度與用戶給定的規(guī)范閾值來確定該模式是否是規(guī)范模式,能夠有效地處理滑動(dòng)窗口下數(shù)據(jù)流的規(guī)范模式挖掘問題;Verma等人在文獻(xiàn)[8]中對(duì)VDSRP算法進(jìn)行了改進(jìn),主要改進(jìn)點(diǎn)在于進(jìn)一步使用了bit-sequence來組織窗口中的數(shù)據(jù),基于窗口中項(xiàng)的bit-sequence執(zhí)行位操作來獲得相關(guān)模式規(guī)范度,提高了算法執(zhí)行效率.很多研究還把這類規(guī)范模式與頻繁模式二者結(jié)合起來.如Kumar等人在文獻(xiàn)[9]中給出了滑動(dòng)窗口下基于該規(guī)范度的數(shù)據(jù)流規(guī)范頻繁模式挖掘方法RFPDS算法,該算法采用垂直數(shù)據(jù)格式組織窗口中的數(shù)據(jù),只計(jì)算頻繁模式的規(guī)范度,通過與用戶給定的規(guī)范閾值進(jìn)行比較來確定該模式是否是規(guī)范頻繁模式,能夠有效地處理滑動(dòng)窗口下數(shù)據(jù)流的規(guī)范頻繁模式挖掘問題.Sreedevi等人在文獻(xiàn)[10]中首次提出了用于處理滑動(dòng)窗口下基于該規(guī)范度的數(shù)據(jù)流規(guī)范閉模式挖掘算法,該算法將整個(gè)規(guī)范頻繁閉模式的求解過程分為2個(gè)階段:第1個(gè)階段求解規(guī)范模式集合;第2個(gè)階段在此基礎(chǔ)上得到規(guī)范頻繁閉模式,可以有效處理這類問題.當(dāng)前有關(guān)第2類規(guī)范模式的研究是將規(guī)范模式與頻繁模式結(jié)合起來展開.如Rashid等人在文獻(xiàn)[11]中對(duì)靜態(tài)數(shù)據(jù)庫下基于這種規(guī)范度的規(guī)范頻繁模式挖掘問題進(jìn)行了研究,并給出了相應(yīng)的處理方法,該方法中使用基于成員出現(xiàn)頻率遞減順序的RF-tree來存放數(shù)據(jù)庫中成員信息,另外使用類FP-growth算法的方式挖掘樹中的規(guī)范頻繁模式;Rashid等人在文獻(xiàn)[12]中設(shè)計(jì)了用于尋找傳感網(wǎng)絡(luò)中規(guī)范頻繁傳感器模式的RSP-tree數(shù)據(jù)結(jié)構(gòu),使用模式出現(xiàn)周期序列的方差作為模式的規(guī)范度,并給出了相應(yīng)的挖掘算法,能夠有效地應(yīng)用于該領(lǐng)域規(guī)范頻繁傳感模式的挖掘.
由文獻(xiàn)[1,13]可知,規(guī)范模式具有向下閉包的特點(diǎn),即如果一個(gè)模式是規(guī)范的,那么它所有的非空子模式也都是規(guī)范的,所以在挖掘數(shù)據(jù)集中的規(guī)范模式時(shí),如果我們只定性地關(guān)注哪些模式是規(guī)范的而不在意它們的具體規(guī)范度,那么完全可以通過挖掘其中所有長度最大的規(guī)范模式來提高挖掘效率.這些長度最大的規(guī)范模式間彼此并不包含,但能保證數(shù)據(jù)集中任何一個(gè)規(guī)范模式都是這些長度最大規(guī)范模式集合中某個(gè)成員的子集,我們把這類長度最大的規(guī)范模式稱為最大規(guī)范模式.由規(guī)范模式的閉包性可知一個(gè)數(shù)據(jù)集上所有的最大規(guī)范模式隱含了這個(gè)數(shù)據(jù)集上所有的規(guī)范模式,但數(shù)量卻比全部規(guī)范模式要少,這點(diǎn)與頻繁模式和最大頻繁模式間的關(guān)系類似.但由前面分析可知,當(dāng)前還沒有這個(gè)方向的研究.
本文基于這點(diǎn),首次對(duì)以模式周期最大值作為規(guī)范度的界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式挖掘問題進(jìn)行了研究.為了能增量地處理這個(gè)問題,本文分析了相鄰窗口上最大規(guī)范模式間的關(guān)系,提出了邊界界標(biāo)窗口技術(shù),接著在此技術(shù)基礎(chǔ)之上給出了該問題的增量處理方法DSMRM-BLW(data stream maximal regular patterns mining based on border landmark window)算法,一系列公用數(shù)據(jù)集上的實(shí)驗(yàn)證明了該算法的有效性.
1 相關(guān)知識(shí)
1.1 IncRT算法
IncRT算法是由Tanbeer等人在文獻(xiàn)[1]中提出的一種目前唯一用于增量挖掘數(shù)據(jù)庫中規(guī)范項(xiàng)集(或規(guī)范模式)的方法.該方法可以在當(dāng)前數(shù)據(jù)庫成員規(guī)范項(xiàng)集集合的基礎(chǔ)上增量獲得新數(shù)據(jù)成員到來后的數(shù)據(jù)庫中規(guī)范項(xiàng)集集合.整個(gè)算法通過1個(gè)IncRT樹來維護(hù)數(shù)據(jù)庫中的成員信息,該樹以字典順序存放每一條數(shù)據(jù)記錄.樹中每條記錄的尾結(jié)點(diǎn)存放著該記錄在數(shù)據(jù)庫中的索引號(hào),以此標(biāo)識(shí)該記錄在數(shù)據(jù)庫中的發(fā)生情況.樹中還維護(hù)著1個(gè)增量規(guī)范表IncR-table,每個(gè)表項(xiàng)分為5個(gè)域,i域用于存放樹中項(xiàng)的名稱,IncR-table中該域中成員的排列順序與樹中項(xiàng)的排列順序相同;r域是該項(xiàng)在樹中的規(guī)范度;tl域是該項(xiàng)最近發(fā)生的記錄索引;m域是該項(xiàng)的修改標(biāo)識(shí)域;p域是1個(gè)指針域,用于指向樹中具有相同項(xiàng)名的結(jié)點(diǎn),樹中所有具有相同項(xiàng)名的結(jié)點(diǎn)間也有指針彼此連接.在IncRT的構(gòu)造過程中,頭表中除了項(xiàng)的r域外,其他域值都可以設(shè)定.當(dāng)樹構(gòu)造完成后,借助為每個(gè)項(xiàng)分配的臨時(shí)數(shù)組結(jié)構(gòu),按照由下而上的順序完成對(duì)樹的1次掃描后得到每個(gè)項(xiàng)的r域值.當(dāng)樹的構(gòu)造完成后,按照FP-growth模式增長挖掘技術(shù)來獲得所有規(guī)范項(xiàng)集,保留所有規(guī)范項(xiàng)集成員.之后重置頭表成員的m域值.接著把新到來的數(shù)據(jù)成員插入到IncRT中,這個(gè)過程中重新設(shè)定頭表中成員的m域值;對(duì)于新的IncRT,只對(duì)IncR-table中m域發(fā)生變化的項(xiàng)使用FP-growth算法進(jìn)行挖掘,假設(shè)得到的規(guī)范項(xiàng)集集合為A.對(duì)于前一個(gè)窗口上的規(guī)范項(xiàng)集集合,找到其中不包含IncR-table中m域發(fā)生變化項(xiàng)的項(xiàng)集,如果在更新它們規(guī)范度后得到的規(guī)范項(xiàng)集集合為B,則A∪B即為當(dāng)前數(shù)據(jù)庫上的規(guī)范項(xiàng)集集合.有關(guān)該算法更詳細(xì)的說明可參見文獻(xiàn)[6].
1.2 PA算法
PA算法是由Verma等人在文獻(xiàn)[8]中提出的一種對(duì)數(shù)據(jù)流滑動(dòng)窗口下以項(xiàng)集周期最大值作為規(guī)范度的規(guī)范項(xiàng)集(或規(guī)范模式)進(jìn)行挖掘的算法.該算法使用垂直格式組織窗口中的數(shù)據(jù)流成員,不僅如此,該算法還基于當(dāng)前窗口中每個(gè)項(xiàng)在窗口數(shù)據(jù)流成員中的出現(xiàn)狀況,定義了這些項(xiàng)在當(dāng)前窗口中的bit-sequence.基于這些bit-sequence,PA算法采用Aprior算法思想可以求得當(dāng)前窗口中所有項(xiàng)集的bit-sequence.因?yàn)榛赽it-sequence中非0成員的位置情況,可以得到對(duì)應(yīng)項(xiàng)集在當(dāng)前窗口中的規(guī)范度,所以該算法可以求得當(dāng)前窗口中所有項(xiàng)集的規(guī)范度,進(jìn)而得到所有規(guī)范項(xiàng)集.關(guān)于該算法更詳細(xì)的情況,可參考文獻(xiàn)[8].
2 基本概念和問題說明
2.1 基本概念
設(shè)SI={I1,I2,…,Im}是m個(gè)項(xiàng)的集合,Ii是第i個(gè)項(xiàng),I中的所有成員按全序(字典序)排列.任給集合P,如果P?SI且l=|P|(即P中含有l(wèi)個(gè)SI的成員),則稱P為l模式,P的長度為l.ST={T1,T2,…,Tn}是事務(wù)集,其中Ti?SI,也即Ti為SI的子集.
定義1. 模式發(fā)生周期[1].任給模式P,令Ti,Tj是事務(wù)集ST中2個(gè)包含P的事務(wù),且在Ti與Tj間沒有任何包含P的其他事務(wù)存在,則i與j的差值被稱為P的一個(gè)發(fā)生周期.
定義2. 模式發(fā)生周期集合[1].令SP是ST中所有包含模式P的事務(wù)集合,|SP|是SP中的事務(wù)總數(shù),這里規(guī)定null事務(wù)(該事務(wù)為ST中第0個(gè)事務(wù),索引值為ST中第1個(gè)事務(wù)的索引值-1)和ST中最后一個(gè)事務(wù)分別是SP中的第1個(gè)和最后1個(gè)事務(wù),它們和ST中其他所有包含P的事務(wù)一起構(gòu)成了SP,SP中所有事務(wù)按它們?cè)赟T中的索引遞增排列.如果設(shè)Trank與Trank+1分別是SP中任意2個(gè)相鄰事務(wù),它們?cè)赟T中的索引分別為Trank.index與Trank+1.index,則CP={Trank+1.index-Trank.index|1≤k≤|SP|-1,k∈+}是P在ST中的發(fā)生周期集合.
定義3. 規(guī)范模式[1].模式P在ST中的規(guī)范度被定義為CP中成員的最大值,表示為RP,即有RP=max(CP).對(duì)于用戶給定的最大規(guī)范閾值λ(1≤λ≤|ST|),如果RP≤λ,則P是ST中一個(gè)規(guī)范模式;如果P的長度為1,則P又被稱為ST中的一個(gè)規(guī)范項(xiàng).
定義4. 最大規(guī)范模式.對(duì)于模式P,如果滿足條件Rp≤λ,同時(shí)對(duì)于任意滿足條件Y?SI且P?Y的模式Y(jié),均有RY>λ成立,則稱P為ST上的最大規(guī)范模式.
定義5. 數(shù)據(jù)流DS[1].數(shù)據(jù)流DS是一個(gè)由連續(xù)到來的事務(wù)組成的事務(wù)序列,表示為DS={T1,T2,…,Ti,…}.Ti為第i個(gè)到來的事務(wù).
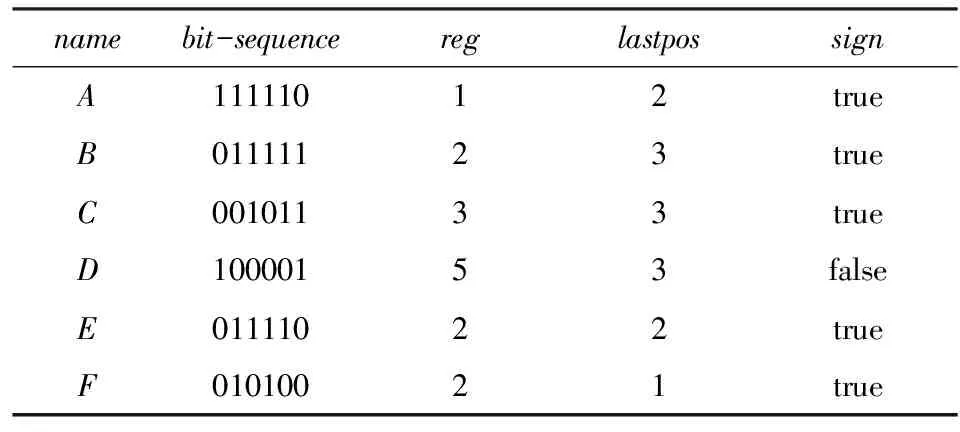
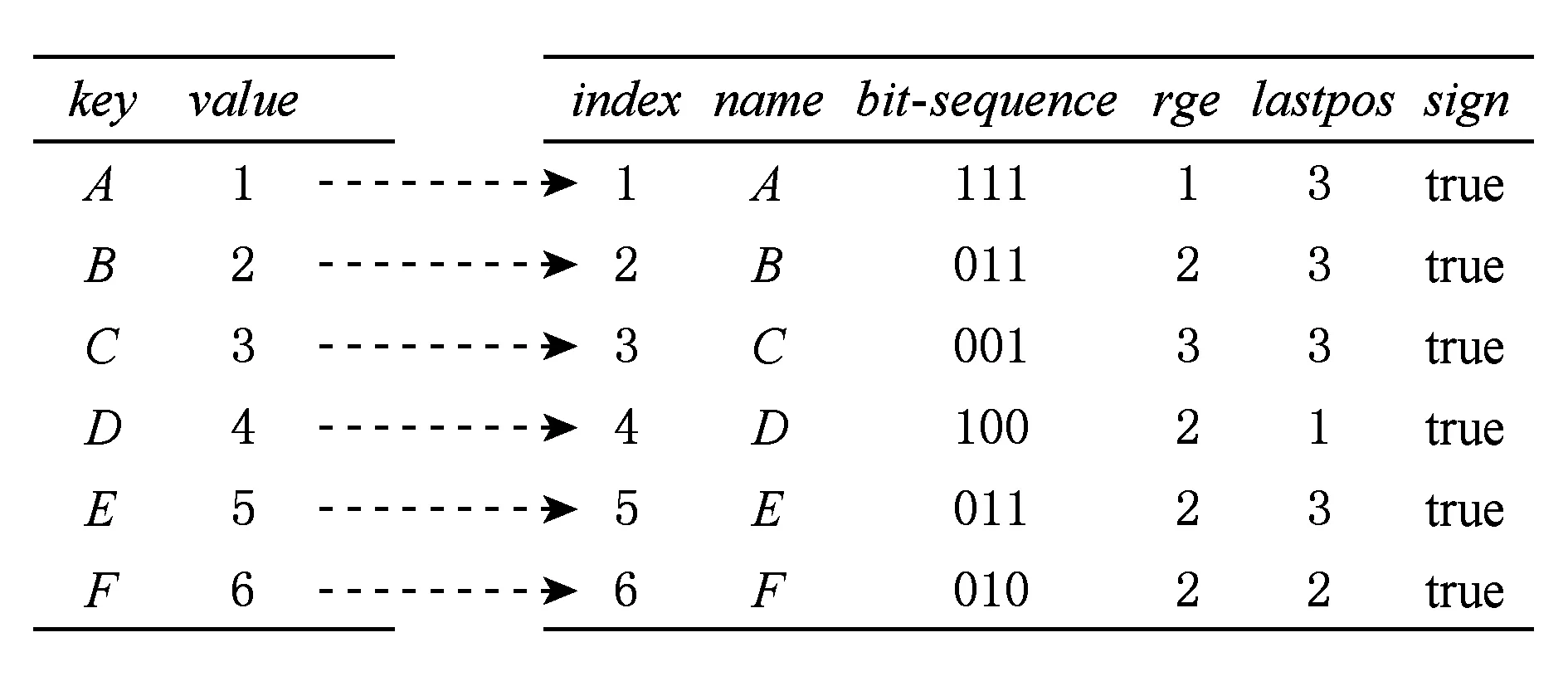
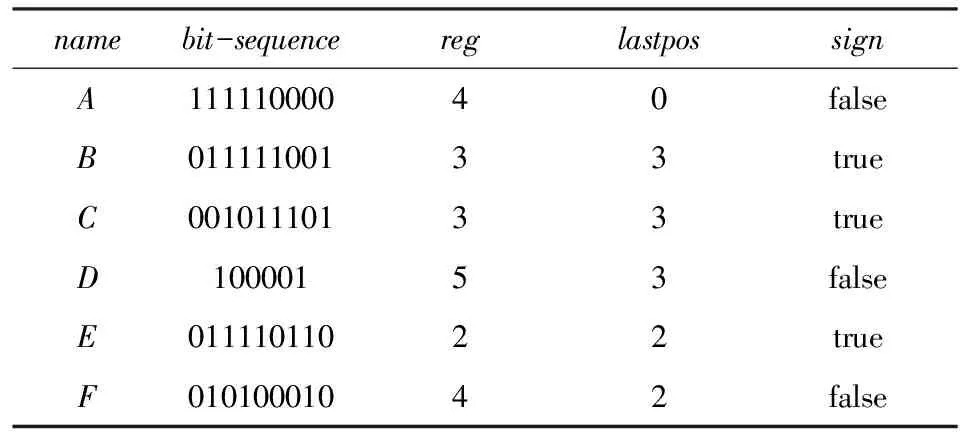
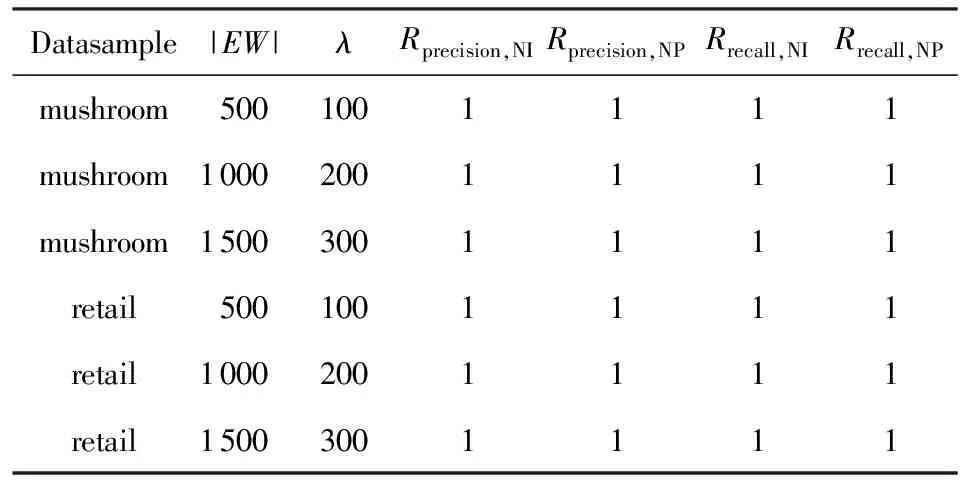
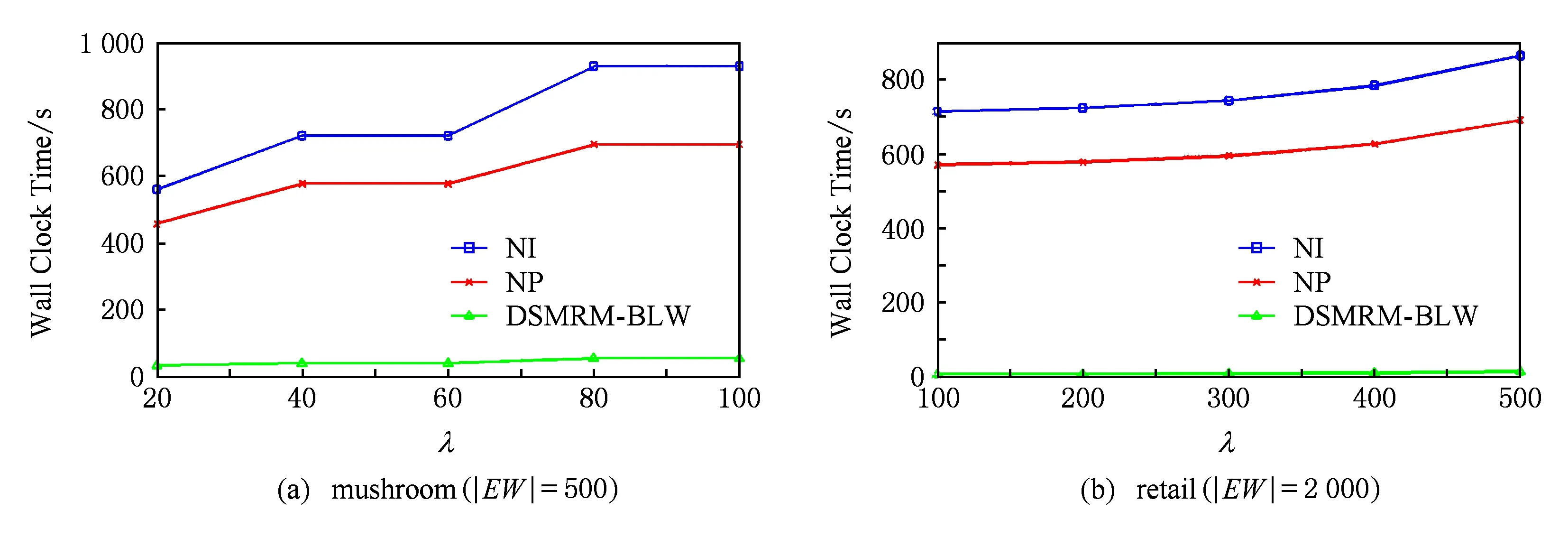
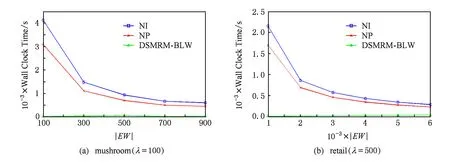
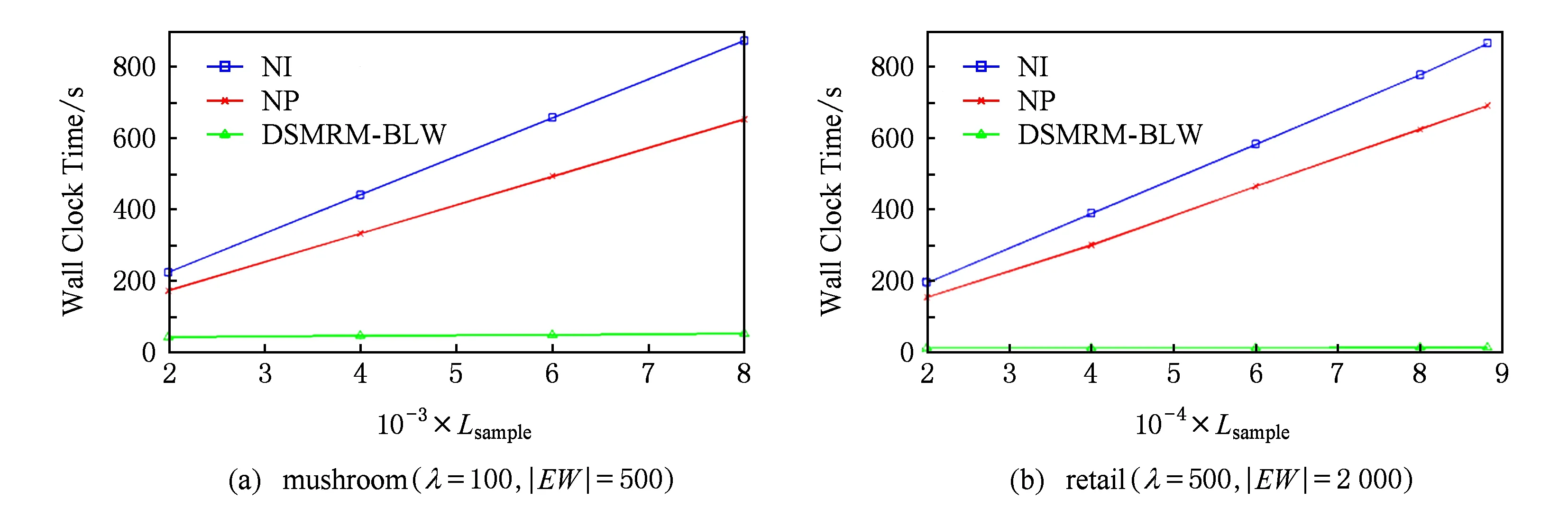
定義6. 基本窗口(element window,EW)與界標(biāo)窗口(landmark window,LW).EW是一個(gè)確定時(shí)間內(nèi)連續(xù)到達(dá)的數(shù)據(jù)流成員,即EW={Ti,Ti+1,…,Tj}(0 2.2 問題說明 參照文獻(xiàn)[6]中關(guān)于增量挖掘規(guī)范模式的說明,我們可以給出本文要處理問題的說明,即給定數(shù)據(jù)流DS、基本窗口大小|EW|、最大規(guī)范閾值λ(1≤λ≤|EW|)、界標(biāo)窗口起始位置sp,本文要解決的問題就是獲得起始位置為sp的每個(gè)界標(biāo)窗口上所有的最大規(guī)范模式. 當(dāng)前并沒有針對(duì)以模式周期最大值為規(guī)范度的界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式挖掘的專門研究,所以最直接的處理方式就是從定義出發(fā)來解決這個(gè)問題.文獻(xiàn)[6]中的IncRT算法是目前唯一可用于解決以模式周期最大值為規(guī)范度的界標(biāo)窗口下數(shù)據(jù)流規(guī)范模式增量挖掘的算法,基于該算法與最大規(guī)范模式的定義可以得到解決界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式挖掘的算法.文獻(xiàn)[8]中的PA算法使用了另外一種不同方法來挖掘滑動(dòng)窗口中數(shù)據(jù)流的規(guī)范模式.該算法使用垂直格式來組織當(dāng)前窗口上的數(shù)據(jù)流成員,并為窗口中的每個(gè)項(xiàng)定義bit-sequence,然后采用類Aprior方法來得到當(dāng)前窗口上的所有規(guī)范模式.如果在PA算法的滑動(dòng)窗口成員更新步驟中只執(zhí)行加入新數(shù)據(jù)成員的操作,之后對(duì)新窗口中成員再使用PA算法進(jìn)行處理,那么基于這個(gè)改動(dòng)的算法和最大規(guī)范模式的定義,可以得到另外一種挖掘界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式的算法. 以上2種算法在挖掘界標(biāo)窗口上數(shù)據(jù)流最大規(guī)范模式的過程中,都會(huì)執(zhí)行2個(gè)基本操作:1)得到每個(gè)界標(biāo)窗口上數(shù)據(jù)流的規(guī)范模式集合;2)消除集合中成員間存在的超集關(guān)系.我們把這2種算法都?xì)w類于na?ve算法,其中基于IncRT算法的方法被稱為NI(na?ve based on IncRT)算法,而基于PA算法的方法被稱為NP(na?ve based on PA)算法.但這2種算法存在明顯問題,就是每個(gè)界標(biāo)窗口上(以下簡稱窗口)最大規(guī)范模式集合都需要重新挖掘,而且必須是在得到了所有規(guī)范模式之后,才能得到最大規(guī)范模式集合,所以時(shí)間開銷會(huì)很大.如果我們能得到相鄰2個(gè)窗口上最大規(guī)范模式間的關(guān)系,每次窗口上最大規(guī)范模式的求解都是基于前一個(gè)窗口上的結(jié)果來執(zhí)行,那么一方面我們無需在求得數(shù)量龐大的所有規(guī)范模式后再得到最大規(guī)范模式集合;另一方面也可以省去對(duì)于相鄰窗口上相同最大規(guī)范模式的重復(fù)挖掘,能夠減小時(shí)間開銷.基于這個(gè)思想,在這部分我們首先分析了相鄰窗口上規(guī)范模式間的關(guān)系;接著在此基礎(chǔ)上得到了相鄰窗口上最大規(guī)范模式間的關(guān)系(我們稱其為邊界界標(biāo)窗口技術(shù));隨后又給出了便于該技術(shù)實(shí)現(xiàn)的數(shù)據(jù)結(jié)構(gòu);最后在該數(shù)據(jù)結(jié)構(gòu)的基礎(chǔ)上得到了能夠增量挖掘界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式的DSMRM-BLW算法. 3.1 相鄰窗口上規(guī)范模式間的關(guān)系 設(shè)LWi是第i個(gè)界標(biāo)窗口,RSi與USi分別是LWi上的規(guī)范模式與非規(guī)范模式集合,|RSi|與|USi|分別是這2個(gè)集合中的成員個(gè)數(shù),ri,j與ui,j分別是RSi與USi中第j個(gè)成員. 性質(zhì)1. 設(shè)Tnew,k是LWi后的第k(k>0)個(gè)新到事務(wù),則有USi中任意成員ui,j(1≤j≤|USi|)一定也是LWi∪Tnew,1∪Tnew,2∪…∪Tnew,k上非規(guī)范模式集合中的成員. 證畢. 性質(zhì)2. 設(shè)Tnew,k是LWi后第k(k≥1)個(gè)新到事務(wù),Tnew,k.index是Tnew,k在數(shù)據(jù)流中的索引,LWi.sp是界標(biāo)窗口起始位置的索引.當(dāng)Tnew,k.index-(LWi.sp-1)>λ時(shí),LWi∪Tnew,1∪Tnew,2∪…∪Tnew,k上的規(guī)范模式集合相對(duì)于LWi∪Tnew,1∪Tnew,2∪…∪Tnew,k-1上的規(guī)范模式集合,沒有新模式加入. 證明. 基于規(guī)范模式定義可以這樣理解LWi上規(guī)范模式的挖掘過程.首先針對(duì)LWi中每個(gè)事務(wù)求得該事務(wù)包含的所有子模式(即由構(gòu)成該事務(wù)的項(xiàng)形成的所有子集),每個(gè)子模式的索引都為該事務(wù)的索引,這樣由產(chǎn)生于每個(gè)事務(wù)的所有子模式構(gòu)成了候選規(guī)范模式集合CSi;接著求CSi中每個(gè)模式的規(guī)范度;最后通過規(guī)范度與最大規(guī)范閾值λ的比較判斷該模式是否為規(guī)范模式.當(dāng)k=1時(shí),令由Tnew,1產(chǎn)生的所有子模式所構(gòu)成的集合為Subsetnew,1.則Subsetnew,1與LWi上的候選規(guī)范模式集合CSi構(gòu)成了LWi∪Tnew,1上的候選規(guī)范模式集合.假設(shè)在Tnew,1到來后有新規(guī)范模式r1產(chǎn)生,則該r1一定位于Subsetnew,1中,而并不位于CSi中.這是因?yàn)槿绻鹯1也存在于CSi中,由題設(shè)可知,r1在CSi中并不是規(guī)范模式,也即r1在LWi上的規(guī)范度大于λ;當(dāng)Tnew,1到來后,因?yàn)閞1變成了規(guī)范模式,所以r1在LWi∪Tnew,1上的規(guī)范度小于等于λ.但因?yàn)長Wi?(LWi∪Tnew,1),再結(jié)合定義3可知,r1在LWi∪Tnew,1上的規(guī)范度一定大于等于其在LWi上的規(guī)范度,也即大于λ,這與r1是LWi∪Tnew,1上的規(guī)范模式相矛盾,所以r1不存在于CSi中.這樣r1的索引一定為Tnew,1.index.當(dāng)Tnew,1.index-(LWi.sp-1)>λ時(shí),由規(guī)范度定義可知,此時(shí)有Rr1>λ,故r1并非規(guī)范模式,這也與假設(shè)矛盾,即在Tnew,1到來后沒有新規(guī)范模式產(chǎn)生.與k=1的證明相類似,容易推得當(dāng)k≥2時(shí),結(jié)論也成立. 證畢. 下面我們通過實(shí)例說明性質(zhì)1~2的內(nèi)容.圖1給出了1個(gè)數(shù)據(jù)流圖示,其中|EW|=3. Fig. 1 Illustration of the property 1 and property 2圖1 性質(zhì)1和2的說明 圖1中ID為4的Transaction(圖1中加重且有下劃線的事務(wù),記為T4)是界標(biāo)窗口LW1后的第1個(gè)事務(wù),由定義2~3可知,E在LW1中的規(guī)范度RE=2.當(dāng)λ=1時(shí),E是LW1上的非規(guī)范模式,這時(shí)考慮E在LW1∪T4上的規(guī)范性,由性質(zhì)1可知,E一定是LW1∪T4上的非規(guī)范模式;當(dāng)λ=3時(shí),考慮LW1∪T4上的規(guī)范模式,因?yàn)榇藭r(shí)有T4.index-(LW1.sp-1)=4-(1-1)=4>λ,所以由性質(zhì)2可知,LW1∪T4上的規(guī)范模式集合與LW1上的規(guī)范模式集合相比,沒有新模式加入.同樣由性質(zhì)2可知,LW1∪T4∪T5∪T6…上的規(guī)范模式集合與LW1上的規(guī)范模式集合相比,沒有新模式加入. 3.2 邊界界標(biāo)窗口技術(shù) 定義7. 邊界基本窗口(border element window, BEW)與邊界界標(biāo)窗口(border landmark window, BLW).令界標(biāo)窗口LW的起始位置為LW.sp,Tran是起始位置后的1個(gè)事務(wù),Tran.index是該事務(wù)在數(shù)據(jù)流中的索引.如果Tran滿足條件Tran.index-(LWi.sp-1)=λ,我們就把Tran所在的基本窗口定義為邊界基本窗口BEW,而以BEW為最后一個(gè)基本窗口的界標(biāo)窗口定義為邊界界標(biāo)窗口BLW. 性質(zhì)3. BLW后的任意一個(gè)界標(biāo)窗口,其上的規(guī)范模式集合與相鄰前一個(gè)界標(biāo)窗口上的規(guī)范模式集合相比,沒有新模式加入. 證明. 由性質(zhì)2容易推得該性質(zhì)成立. 證畢. 性質(zhì)4. 假設(shè)ms是BLW上的最大規(guī)范模式.考慮BLW后第1個(gè)界標(biāo)窗口NLW1,有3個(gè)結(jié)論成立: 1) 如果ms是該窗口上的規(guī)范模式,則ms一定也是該窗口上的最大規(guī)范模式. 2) 如果ms不是該窗口上的規(guī)范模式,且其中每個(gè)成員都是規(guī)范項(xiàng),設(shè)ms長度為len,將ms所有l(wèi)en-1模式中滿足規(guī)范條件的成員放入結(jié)果集合;然后針對(duì)每個(gè)不滿足規(guī)范條件的len-1模式,求它們的len-2模式,將所有l(wèi)en-2模式中滿足規(guī)范條件的成員放入結(jié)果集合,這個(gè)過程一直到產(chǎn)生的每個(gè)模式都滿足規(guī)范條件或者是執(zhí)行到所有1模式為止,如果對(duì)此時(shí)結(jié)果集合執(zhí)行超集檢測后得到的集合為NS,則NS是當(dāng)前窗口上ms所有子模式的最大規(guī)范模式集合. 3) 如果ms不是該窗口上的規(guī)范模式,且其中存在非規(guī)范項(xiàng).這時(shí)令執(zhí)行了非規(guī)范項(xiàng)刪除操作后的ms為ms1,當(dāng)ms1是規(guī)范模式時(shí),該模式也是當(dāng)前窗口中ms子模式的最大規(guī)范模式;否則按結(jié)論2對(duì)其進(jìn)行處理,能得到當(dāng)前窗口上ms所有子模式的最大規(guī)范模式集合. 證明. 1) 設(shè)BLW與NLW1上的規(guī)范模式集合分別是RS1與RS2.因?yàn)閙s是BLW上的最大規(guī)范模式,所以由定義4可知我們無法在RS1中找到1個(gè)成員rs滿足條件ms?rs.考慮NLW1上情況,如果ms同時(shí)也是NLW1上的規(guī)范模式,也即ms滿足條件ms∈RS2,這時(shí)因?yàn)闊o法在RS1中找到1個(gè)成員rs滿足條件ms?rs,而且由性質(zhì)3可知RS2?RS1,所以也無法在RS2中找到成員rs1滿足條件ms?rs1,也即ms是NLW1上的最大規(guī)范模式. 2) 因?yàn)閙s是BLW上的最大規(guī)范模式,由規(guī)范模式閉包性可知,ms所有子模式也都是規(guī)范模式,而且ms能覆蓋(覆蓋是指子模式中的所有項(xiàng)都在ms中)這些子模式.另外由性質(zhì)3可知RS2?RS1,所以ms也能覆蓋存在于RS2中ms的所有子模式.但因?yàn)閙s?RS2,所以ms并不是存在于RS2中ms子模式的最大規(guī)范模式.設(shè)ms長度為len,由Aprior算法可知,ms可由ms的len-1模式執(zhí)行連接操作來得到,而且ms可以覆蓋它的所有l(wèi)en-1模式.依次類推,可得ms的所有l(wèi)en-1模式覆蓋了除ms外所有的ms子模式.所以當(dāng)ms不是NLW1上的規(guī)范模式時(shí),這時(shí)判斷ms上的len-1模式,如果它們都是規(guī)范模式,也即它們都是RS2中的成員,那么因?yàn)榇藭r(shí)ms?RS2,所以由這些規(guī)范模式構(gòu)成了能夠覆蓋存在于RS2中ms子模式的最大規(guī)范模式集合.如果其中存在某個(gè)len-1模式不滿足規(guī)范條件,則使用相同方法判斷該模式的len-2模式,一直到關(guān)注的每個(gè)模式都滿足規(guī)范條件,則由所有獲得的規(guī)范模式構(gòu)成了結(jié)果集合.由定義4可知,在消除了集合中成員間存在的超集關(guān)系后,該集合即為能夠覆蓋存在于RS2中ms子模式的最大規(guī)范模式集合. 3) 假設(shè)F是ms在NLW1中任意非規(guī)范項(xiàng),由規(guī)范模式閉包性可知,F(xiàn)在ms中的任何超集都不可能是NLW1上的規(guī)范模式,所以ms上含有F的子模式都不可能是NLW1中的規(guī)范模式,即RS2中不存在ms上含有F的子模式.假設(shè)subsetms是ms的子模式集合,則ms能覆蓋subsetms中每個(gè)成員;考慮存在于RS2中的ms子模式集合subset1ms,由前面分析可知subset1ms?subsetms成立,所以ms同樣可以覆蓋subset1ms中的每個(gè)成員;從subsetms中刪除所有含有ms在NLW1中非規(guī)范項(xiàng)的子模式,我們把新得到的集合記為subset2ms,則有subset1ms?subset2ms.另外假設(shè)ms在執(zhí)行了刪除所有NLW1中非規(guī)范項(xiàng)的操作后變?yōu)閙s1,則ms1能夠覆蓋subset2ms中的所有成員,進(jìn)一步可以覆蓋subset1ms中的所有成員.當(dāng)ms1為NLW1上的規(guī)范模式時(shí),結(jié)合定義4可知,ms1是subset1ms中的最大規(guī)范模式;當(dāng)ms1是NLW1上的非規(guī)范模式時(shí),與證明2情況類似,易得結(jié)論成立. 證畢. 性質(zhì)5. 假設(shè)BLW上最大規(guī)范模式集合mset={ms1,ms2,…,msn},NLW1上最大規(guī)范模式集合為mset1.對(duì)于mset與mset1有2個(gè)結(jié)論成立: 1) 如果mset中每個(gè)成員仍是NLW1上的規(guī)范模式,則mset=mset1. 2) 如果mset中有些成員不是NLW1上的規(guī)范模式,此時(shí)mset中的成員可分為3類:①在NLW1上仍然是規(guī)范模式的成員;②在NLW1上不是規(guī)范模式,但模式的構(gòu)成項(xiàng)中都是規(guī)范項(xiàng)的成員;③在NLW1上不是規(guī)范模式,但模式構(gòu)成項(xiàng)中存在非規(guī)范項(xiàng)的成員.分別使用性質(zhì)4的結(jié)論1~3來處理上述3類成員,假設(shè)由這3類成員的處理結(jié)果構(gòu)成的集合為RS,則執(zhí)行了超集檢驗(yàn)后的RS即為當(dāng)前窗口上的最大規(guī)范模式集合. 證明. 1) 設(shè)RS1與RS2分別是BLW與NLW1上的規(guī)范模式集合.因?yàn)閙set是BLW上的最大規(guī)范模式集合,所以可知:①mset中的成員覆蓋了RS1中的所有規(guī)范模式;②mset中任意2個(gè)成員msk與msl都有如下關(guān)系msk∩msl≠msk,且msk∩msl≠msl成立;③對(duì)于mset中任意成員mst,我們?cè)赗S1中無法找到1個(gè)成員rs,使得條件mst?rs成立.如果mset中每個(gè)成員仍是NLW1上的規(guī)范模式,由性質(zhì)4的結(jié)論1可知,這些成員也是NLW1上的最大規(guī)范模式,即mset也是NLW1上最大規(guī)范模式的集合.又由性質(zhì)3可知RS2?RS1,而且再由前面①可推得mset中的成員也覆蓋了RS2中的所有規(guī)范模式,另外前面的②和③顯然在NLW1上也依然成立,即mset也是NLW1上的最大規(guī)范模式集合. 2) 由證明1可知,如果mset中每個(gè)成員仍是NLW1上的規(guī)范模式,則mset=mset1,結(jié)合定義4可知,對(duì)于NLW1上任意1個(gè)規(guī)范模式,在mset(此時(shí)也即mset1)中至少有1個(gè)成員會(huì)完成對(duì)該模式的覆蓋.假設(shè)此時(shí)mset中有M個(gè)成員,我們可以根據(jù)RS2中成員(即NLW1中規(guī)范模式)被這M個(gè)成員所覆蓋情況,將其中成員分為M類,當(dāng)然這M類成員彼此間可能會(huì)有重合.每一類中成員都被對(duì)應(yīng)mset中的成員所覆蓋.當(dāng)mset中某些成員并不是NLW1上的規(guī)范模式時(shí),NLW1上本來應(yīng)該由這些成員覆蓋的所有規(guī)范模式,此時(shí)可能就沒有最大規(guī)范模式覆蓋了,所以需要求這部分規(guī)范模式的最大規(guī)范模式.假設(shè)將mset中不是NLW1上規(guī)范模式的成員組合成集合nset,對(duì)于nset中任意成員nseti,如果nseti的構(gòu)成項(xiàng)都是規(guī)范項(xiàng),由性質(zhì)4的結(jié)論2可知,使用該結(jié)論處理nseti后可以得到集合NSi,該集合是NLW1上nseti所有子模式的最大規(guī)范模式集合,覆蓋了存在于RS2中nseti的所有子模式;如果nseti的構(gòu)成項(xiàng)中存在非規(guī)范項(xiàng),由性質(zhì)4的結(jié)論3可知,在使用該結(jié)論處理nseti后,也可以得到該成員在NLW1上所有子模式的最大規(guī)范模式集合,覆蓋了存在于RS2中nseti的所有子模式;設(shè)從mset中除去nset中的成員后得到的集合為mset|nset,由前面分析及由性質(zhì)4的結(jié)論1可知,這些成員也是NLW1上的最大規(guī)范模式,可以覆蓋存在于RS2中每個(gè)mset|nset中成員的所有子模式,所以由這3部分構(gòu)成的RS覆蓋了RS2中所有規(guī)范模式,由定義4可知,RS集合在執(zhí)行超集檢測后,即成為NLW1上的最大規(guī)范模式集合. 證畢. 我們?nèi)砸詧D1為例說明這些性質(zhì)內(nèi)容.設(shè)LW1上λ=3時(shí)的規(guī)范模式集合為RS,由圖1可知RS={A,B,C,D,E,F,AC,AD,AB,AE,AF,BC,BE,BF,EF,CE,ABC,ABE,ABF,BCE,BEF,AEC,AEF,ABCE,ABEF};顯然最大規(guī)范模式集合MRS={ABCE,ABEF,AD};在求LW2上最大規(guī)范模式時(shí),如果ABCE,ABEF與AD仍是LW2上的規(guī)范模式,則LW2上的最大規(guī)范模式集合仍然為{ABCE,ABEF,AD}(性質(zhì)5的結(jié)論1).因?yàn)锳BCE與ABEF都是LW2上的規(guī)范模式,所以它們?nèi)匀皇荓W2上的最大規(guī)范模式(性質(zhì)4的結(jié)論1);又因?yàn)锳D不是LW2上的規(guī)范模式,而且這時(shí)D不是LW2上的規(guī)范模式,所以這時(shí)只考慮A.因?yàn)锳是規(guī)范模式,所以A是AD在LW2上所有子模式的最大規(guī)范模式(性質(zhì)4的結(jié)論3).令A(yù)與ABEF以及ABCE構(gòu)成集合Stem,由性質(zhì)5的結(jié)論2可知,在對(duì)該集合執(zhí)行超集檢測后,可得LW2上λ=3時(shí)的MRS={ABCE,ABEF}. 由性質(zhì)4~5不難推得BLW后任意2個(gè)相鄰界標(biāo)窗口上最大規(guī)范模式集合間都有相同結(jié)論成立.另外由2.2節(jié)可知,本文中λ的取值范圍為1≤λ≤|EW|,所以本文中BLW為最大規(guī)范模式挖掘過程中的第1個(gè)界標(biāo)窗口.由性質(zhì)5可知,從第2個(gè)界標(biāo)窗口開始,可以基于前一個(gè)窗口上最大規(guī)范模式集合來獲得當(dāng)前窗口上最大規(guī)范模式集合.具體方法為首先考慮前一個(gè)窗口上最大規(guī)范模式集合中每個(gè)成員模式的規(guī)范度,如果這些模式規(guī)范度都滿足規(guī)范條件,則它們構(gòu)成了新窗口上的最大規(guī)范模式集合,否則使用性質(zhì)5中的結(jié)論2對(duì)其進(jìn)行處理,則可以得到當(dāng)前窗口上的全部最大規(guī)范模式.這種從邊界界標(biāo)窗口的下一個(gè)窗口開始,基于前一個(gè)窗口最大規(guī)范模式集合求得當(dāng)前窗口最大規(guī)范模式集合的方法被稱為邊界界標(biāo)窗口技術(shù). 3.3 數(shù)據(jù)結(jié)構(gòu) 通過前面對(duì)邊界界標(biāo)窗口技術(shù)的分析可知,該技術(shù)執(zhí)行的1個(gè)重要前提就是需要一種便于計(jì)算前一個(gè)窗口上最大規(guī)范模式在當(dāng)前窗口上規(guī)范度的方法,而這種方法還需要便于計(jì)算當(dāng)前窗口上由規(guī)范項(xiàng)所構(gòu)成的任意模式的規(guī)范度.本部分主要給出了相關(guān)的數(shù)據(jù)結(jié)構(gòu),而這些數(shù)據(jù)結(jié)構(gòu)的使用可以滿足邊界界標(biāo)窗口技術(shù)使用的前提條件. 3.3.1BV(bit-vector) table 參照文獻(xiàn)[8]中的bit-sequence思想,我們對(duì)于邊界界標(biāo)窗口中每個(gè)項(xiàng)維護(hù)一個(gè)bit-vector結(jié)構(gòu).窗口中所有項(xiàng)的bit-vector構(gòu)成了bit-vectortable(簡稱BVtable).因?yàn)橥ㄟ^性質(zhì)3可以知道,BLW后的每個(gè)窗口上的規(guī)范模式都是BLW上規(guī)范模式的子集,進(jìn)一步可知,BLW后每個(gè)窗口上所有規(guī)范項(xiàng)的集合都是BLW上所有規(guī)范項(xiàng)集合的子集,所以我們只要維護(hù)好邊界界標(biāo)窗口上的BVtable在每個(gè)新窗口上的狀態(tài),無論計(jì)算前一個(gè)窗口上的最大規(guī)范模式在當(dāng)前窗口上的規(guī)范度,還是計(jì)算當(dāng)前窗口上由規(guī)范項(xiàng)所構(gòu)成模式的規(guī)范度,只需在當(dāng)前窗口的BVtable中找到模式中項(xiàng)對(duì)應(yīng)的bit-vector,然后基于它們執(zhí)行與操作,最后對(duì)得到的結(jié)果計(jì)算規(guī)范度即可. 1)BVtable結(jié)構(gòu) BVtable包含name,bit-sequence,reg,lastpos,sign這5個(gè)域,分別對(duì)應(yīng)項(xiàng)的名稱、項(xiàng)在當(dāng)前窗口中的bit序列、項(xiàng)的規(guī)范度reg、bit-sequence后|EW|個(gè)bit序列中最后一個(gè)非0位置以及該項(xiàng)在當(dāng)前窗口上的規(guī)范度是否不大于規(guī)范閾值λ的結(jié)果.其中bit-sequence是1個(gè)長度為|LW|×|EW|的位序列,每一位與界標(biāo)窗口中的每個(gè)數(shù)據(jù)流成員相對(duì)應(yīng).如果該項(xiàng)在這個(gè)數(shù)據(jù)流成員中出現(xiàn),則對(duì)應(yīng)的bit-sequence位設(shè)為1,否則設(shè)為0.BVtable中每條記錄與當(dāng)前窗口中的每個(gè)項(xiàng)對(duì)應(yīng),該記錄也是對(duì)應(yīng)項(xiàng)的bit-vector.BVtable中所有項(xiàng)按字典順序排列.表1給出了圖1中LW1上當(dāng)λ=3時(shí)的BVtable. Table 1 BV table over the LW1 2) 構(gòu)建BVtable 由定義7分析可知,本文中BLW是界標(biāo)窗口中第1個(gè)窗口,所以BVtable在第1個(gè)窗口中成員到來后開始構(gòu)建.①首先將BLW中的數(shù)據(jù)流成員按字典順序轉(zhuǎn)換成垂直格式,完成BVtable中每個(gè)項(xiàng)bit-sequence的構(gòu)造;②將bit-sequence中非0成員位置記錄下來形成1個(gè)序列,該序列在增加頭成員0和尾成員|EW|后形成1個(gè)新序列,求該序列中相鄰成員差值的最大值,以此作為該項(xiàng)的reg值,同時(shí)將bit-sequence中最后一個(gè)非0成員的位置作為該項(xiàng)的lastpos;③根據(jù)該項(xiàng)reg值與規(guī)范閾值λ間的關(guān)系,完成sign域的賦值.當(dāng)完成這些操作后,BLW上的BVtable構(gòu)造完成.具體如表1所示. 3) 更新BVtable 首先,結(jié)合規(guī)范模式的性質(zhì)與BVtable結(jié)構(gòu)特點(diǎn),可以得到性質(zhì)6: 性質(zhì)6. BLW上的BVtable中如果有項(xiàng)A的sign域值為false,則有2個(gè)性質(zhì)成立:①之后每個(gè)界標(biāo)窗口上的BVtable中,該項(xiàng)的sign域值都為false;②BLW上及其之后的每個(gè)窗口上的規(guī)范模式集合中,都不會(huì)有含有該項(xiàng)的模式出現(xiàn). ② 由規(guī)范模式向下閉包性的性質(zhì)可知,每個(gè)界標(biāo)窗口上都不會(huì)有含該項(xiàng)的規(guī)范模式出現(xiàn).性質(zhì)6中結(jié)論②成立. 證畢. 由性質(zhì)6可知,在我們得到邊界界標(biāo)窗口上的BVtable在每個(gè)新窗口上的狀態(tài)時(shí),我們只需對(duì)前一窗口上BVtable中sign域值為true的項(xiàng)執(zhí)行更新即可. 具體更新過程在新EW中所有成員到達(dá)后執(zhí)行,設(shè)前一個(gè)界標(biāo)窗口上的BVtable為PV.首先我們會(huì)針對(duì)PV中所有sign域?yàn)閠rue的項(xiàng),按照它們?cè)谛翬W的數(shù)據(jù)流成員中是否出現(xiàn)的情況,構(gòu)建這些項(xiàng)在新EW中的bit-sequence(記為item.bit-sequence).同時(shí)記下item.bit-sequence中第1個(gè)非0成員位置fp和最后一個(gè)非0成員位置lp.如果item.bit-sequence=0,我們令fp=|EW|,lp=0;接著按照定義1~3對(duì)item.bit-sequence進(jìn)行處理可以得到該項(xiàng)的reg值,記為item.reg.為便于說明,假設(shè)PV中sign域值為true的項(xiàng)I在新EW上的信息組成的臨時(shí)表為TemI,另設(shè)項(xiàng)I在PV中對(duì)應(yīng)的bit-vector為PVI,則可通過3個(gè)步驟更新PVI中信息:①PVI.bit-sequence=PVI.bit-sequence∪TemI.bit-sequence;②PVI.reg=max(|EW|-PVI.lastpos+TemI.fp,PVI.reg,TemI.reg);③PVI.lastpos=TemI.lp.表2給出了圖1中LW2上當(dāng)λ=3時(shí)的BVtable. Table 2 BV table over the LW2 4)BVtable的結(jié)構(gòu)分析 令item是BLW上任意規(guī)范項(xiàng).由界標(biāo)窗口特點(diǎn)可知,相鄰下一個(gè)界標(biāo)窗口是在當(dāng)前窗口上加1個(gè)基本窗口構(gòu)成的,也就是任何項(xiàng)在下一個(gè)界標(biāo)窗口上的bit-sequence是由該項(xiàng)在當(dāng)前窗口上的bit-sequence與其在下一個(gè)基本窗口上的bit-sequence構(gòu)成.設(shè)BScur是item在BLW上的bit-sequence,而BSnext是item在NLW1上的bit-sequence,則BScur與BSnext之間除了最后|EW|個(gè)位序列,其余完全相同.因?yàn)槲覀円骾tem在下一個(gè)窗口上的規(guī)范度,也即基于BSnext求item的規(guī)范度,而在處理BLW時(shí)我們基于BScur已經(jīng)得到了item在該窗口上的規(guī)范度,所以在基于BSnext求item的規(guī)范度時(shí),我們可以先求得BSnext中后|EW|個(gè)位序列上的規(guī)范度,把這個(gè)作為1個(gè)最終可能規(guī)范度.另外需要注意的是,BSnext的后|EW|中的第1個(gè)非0位與前面序列中最后一個(gè)非0位之間的差值,也可能是規(guī)范度,所以我們?cè)O(shè)立了lastpos域,我們把這個(gè)作為第2個(gè)最終的可能規(guī)范度.由定義3可知,這2個(gè)可能規(guī)范度和BScur上規(guī)范度3者中的最大值為最終item的reg值.這樣就使我們?cè)谥魂P(guān)注item在新界標(biāo)窗口上bit-sequence中的后|EW|個(gè)位序列的情況下,能夠得到該項(xiàng)在新界標(biāo)窗口上的規(guī)范度.類似地,任意界標(biāo)窗口上規(guī)范項(xiàng)都有這樣的規(guī)律.而和基于新界標(biāo)窗口上該項(xiàng)的整個(gè)bit-sequence來計(jì)算該項(xiàng)的規(guī)范度相比,顯然現(xiàn)有的方法可以更好地減少運(yùn)算量. 3.3.2 Hash索引表HIT(Hash index table) 在基于BVtable計(jì)算前一個(gè)窗口上的最大規(guī)范模式在當(dāng)前窗口上的規(guī)范度,或者是求得當(dāng)前窗口上由規(guī)范項(xiàng)所構(gòu)成的任意模式的規(guī)范度時(shí),我們需要隨時(shí)能得到模式的每個(gè)項(xiàng)在當(dāng)前窗口BVtable中的bit-sequence.如果直接使用BVtable,因?yàn)榍蟮妹總€(gè)項(xiàng)在當(dāng)前窗口中的bit-sequence,實(shí)際上都需要對(duì)BVtable執(zhí)行一次掃描操作,所以效率較低.為解決這個(gè)問題,我們以項(xiàng)名為key,以項(xiàng)在BVtable中索引位置index為value設(shè)計(jì)了Hash索引表HIT.通過這個(gè)數(shù)據(jù)結(jié)構(gòu),我們能以O(shè)(1)的時(shí)間開銷找到當(dāng)前窗口中任何項(xiàng)在BVtable中的位置,進(jìn)而得到該項(xiàng)的bit-sequence.圖2說明了LW1上λ=3時(shí)的HIT與BVtable間的關(guān)系. Fig. 2 The relationship between the HIT and the BV table over the LW1圖2 LW1上的HIT與BV table間的關(guān)系 性質(zhì)7. 每個(gè)窗口上BVtable的HIT都是相同的,無需隨著窗口成員的更新而更新. 證明. 由BVtable的更新過程可知,每個(gè)窗口上的BVtable中項(xiàng)的個(gè)數(shù)與位置并不會(huì)發(fā)生變化,所以與每個(gè)窗口上BVtable相關(guān)的HIT也不會(huì)發(fā)生變化,無需隨著窗口成員的更新而更新. 證畢. 3.3.3 優(yōu)化策略 性質(zhì)8. 在按照邊界界標(biāo)窗口技術(shù)求得當(dāng)前窗口上的最大規(guī)范模式集合時(shí),我們需要計(jì)算前一窗口上的所有最大規(guī)范模式在當(dāng)前窗口上的規(guī)范度.在這個(gè)過程中,假設(shè)前一個(gè)窗口上的最大規(guī)范模式中存在著某些成員項(xiàng),這些項(xiàng)在當(dāng)前窗口BVtable中的sign域值為false,則我們?cè)谔幚碓撟畲笠?guī)范模式時(shí)可以忽略對(duì)于這些項(xiàng)的處理. 證明. 由規(guī)范模式向下閉包性特點(diǎn),性質(zhì)4的結(jié)論3以及性質(zhì)5的結(jié)論2可得性質(zhì)8成立. 證畢. 該優(yōu)化策略可以減少我們?cè)谑褂眠吔缃鐦?biāo)窗口技術(shù)求得界標(biāo)窗口上最大規(guī)范模式過程中對(duì)于很多不必要成員項(xiàng)的處理,能夠提高整個(gè)執(zhí)行過程的時(shí)間效率. 我們以LW3上最大規(guī)范模式的求解過程為例來說明優(yōu)化策略的內(nèi)容,表3是圖1中LW3上當(dāng)λ=3時(shí)的BVtable. Table 3 BV table over the LW3 由前面可知LW2上λ=3的最大規(guī)范模式集合為RS2={ABCE,ABEF}.又由表3可知A,F(xiàn)在LW3上BVtable中的sign域值為false,所以按照優(yōu)化策略,當(dāng)重新計(jì)算ABCE與ABEF在LW3上的規(guī)范度時(shí),可以忽略對(duì)其中A,F(xiàn)的處理.也就是說,只需計(jì)算BCE和BE的規(guī)范度.對(duì)于BCE來說,因?yàn)樗贚W3上的規(guī)范度為4,所以不滿足規(guī)范條件.按照邊界界標(biāo)窗口技術(shù)考慮BCE長度為2的子模式:BC,BE,CE.因?yàn)锽C的規(guī)范度為3,CE的規(guī)范度為2,都滿足規(guī)范條件,所以它們?nèi)允钱?dāng)前窗口上BCE所有子模式的最大規(guī)范模式集合中的成員;對(duì)于BCE的另一個(gè)長度為2的子模式BE,因?yàn)樗贚W3上的規(guī)范度為4,所以不滿足規(guī)范條件.按照邊界界標(biāo)窗口技術(shù)考慮BE的長度為1的項(xiàng)子模式:B,E.顯然B,E此時(shí)都滿足規(guī)范條件.令Stem={BC,CE,B,E},按邊界界標(biāo)窗口技術(shù)可知,當(dāng)消除了Stem中成員之間存在的超集關(guān)系后,Stem={BC,CE}即為當(dāng)前窗口上BCE所有子模式的最大規(guī)范模式集合;對(duì)于RS2中此時(shí)需要處理的另外一個(gè)模式BE,類似地可以得到S1tem={B,E}為當(dāng)前窗口上BE所有子模式的最大規(guī)范模式集合.同樣由邊界界標(biāo)窗口技術(shù)可知,假設(shè)Stem與S1tem中成員構(gòu)成了新集合Sfinal,即Sfinal={BC,CE,B,E},那么當(dāng)消除了該集合中成員間存在的超集關(guān)系后,該集合便是LW3上當(dāng)λ=3的最大規(guī)范模式集合RS3,也即RS3={BC,CE}. 3.4 DSMRM-BLW算法 由邊界界標(biāo)窗口技術(shù)可知,在使用na?ve算法求得第1個(gè)界標(biāo)窗口上最大規(guī)范模式集合后,我們可以基于該集合求得相鄰下一個(gè)窗口上的最大規(guī)范模式集合.依次類推,可以得到之后每個(gè)界標(biāo)窗口上的最大規(guī)范模式集合.另外通過文獻(xiàn)[1,6]可知,NI算法在第1個(gè)窗口上的執(zhí)行效果與文獻(xiàn)[1]中的RPS-tree算法相同,又由文獻(xiàn)[8]可知,PA算法求得滑動(dòng)窗口上規(guī)范模式的時(shí)間開銷小于RPS-tree算法.所以我們可以在第1個(gè)窗口上執(zhí)行NP算法,即使用PA算法求得該窗口上的規(guī)范模式集合,然后消除該集合成員間存在的超集關(guān)系,以此來得到該窗口上的最大規(guī)范模式集合,對(duì)于之后每一個(gè)界標(biāo)窗口上的最大規(guī)范模式集合,使用邊界界標(biāo)窗口技術(shù)來獲得,我們把這種算法稱為DSMRM-BLW算法.另外由前面BVtable結(jié)構(gòu)可知,該數(shù)據(jù)結(jié)構(gòu)中含有PA算法執(zhí)行所需的bit-sequence,所以DSMRM-BLW算法在第1個(gè)窗口上的執(zhí)行無需再構(gòu)造其他數(shù)據(jù)結(jié)構(gòu),直接使用BVtable中的bit-sequence即可. DSMRM-BLW算法在前面數(shù)據(jù)結(jié)構(gòu)的基礎(chǔ)上,完成了基于邊界界標(biāo)窗口技術(shù)挖掘每個(gè)界標(biāo)窗口上數(shù)據(jù)流最大規(guī)范模式的操作.算法具體描述如下: 算法1. DSMRM-BLW. 輸入:數(shù)據(jù)流DS、界標(biāo)窗口LW的起始位置sp、規(guī)范閾值λ、基本窗口大小|EW|; 輸出:每個(gè)界標(biāo)窗口上的最大規(guī)范模式集合. ① 從數(shù)據(jù)流中索引為sp的成員開始,對(duì)每個(gè)界標(biāo)窗LW執(zhí)行如下操作; ② {if (theLWis BLW) ③ {構(gòu)建BLW上的BVtablecurtable與HIT; ④Sregular=PA(curtable);*使用PA算法 得到當(dāng)前窗口上完整的規(guī)范模式集 合* ⑤ 消除Sregular中任意2個(gè)成員間存在的超集關(guān)系; ⑥Smaxregular=Sregular; ⑦ outputSmaxregular;*輸出BLW上的最大規(guī)范模式集合* ⑧ } ⑨ else ⑩ {基于新EW的成員,按照3.3.1節(jié)3)的 方法更新curtable; DSMRM-BLW算法在使用邊界界標(biāo)窗口技術(shù)求得當(dāng)前窗口上最大規(guī)范模式集合時(shí),如果前一窗口上最大規(guī)范模式在當(dāng)前窗口上不滿足規(guī)范條件,則需要求得該模式在當(dāng)前窗口上所有子規(guī)范模式的最大規(guī)范模式.下面的GetMRM-subset算法給出了具體求解過程. 算法2. GetMRM-subset. 輸入:規(guī)范閾值λ、在當(dāng)前窗口上不滿足規(guī)范條件的前一窗口上最大規(guī)范模式eset、當(dāng)前窗口上的BVtablecurtable; 輸出:eset所有子規(guī)范模式的最大規(guī)范模式集合MRSeset. ① for (eset每個(gè)長leneset-1的子集esubset) ② {計(jì)算esubset的規(guī)范度regesubset; ③ if (regesubset<λ)*判斷esubset的規(guī)范度regesubset是否小于λ* ④MRSeset←esubset; ⑤ else ⑥MRSeset←GetMRM-subset (λ,esubset,curtable); ⑦ } ⑧ 消除MRSeset中任意2個(gè)成員間的超集關(guān)系; ⑨ returnMRSeset. 設(shè)eset的長度為leneset,對(duì)于eset中每個(gè)長為leneset-1的子集esubset執(zhí)行如下步驟:如果esubset滿足規(guī)范條件,則將該子集放入MRSeset中(行③~④);如果esubset的規(guī)范度不滿足規(guī)范條件,設(shè)lenesubset是esubset的長度,則使用相同方法對(duì)于esubset的長度為lenesubset-1的子集進(jìn)行處理(行⑥);當(dāng)處理完eset中每個(gè)長為leneset-1的子集后,只需消除MRSeset中成員間的超集關(guān)系,便可得到eset中所有子規(guī)范模式的最大規(guī)范模式集合MRSeset(行⑧~⑨). 本部分實(shí)驗(yàn)主要分3部分:1)實(shí)驗(yàn)驗(yàn)證最大規(guī)范模式相對(duì)于規(guī)范模式的優(yōu)勢(shì),這也是本文的研究意義所在;2)驗(yàn)證本文提出的DSMRM-BLW算法在挖掘界標(biāo)窗口上數(shù)據(jù)流最大規(guī)范模式時(shí)的有效性;3)對(duì)DSMRM-BLW算法性能進(jìn)行了評(píng)價(jià). 4.1 實(shí)驗(yàn)環(huán)境 本文全部實(shí)驗(yàn)都在一臺(tái)配置為Intel?coreTMi5 CPU 650 @3.20 GHz CPU、1.12 GHz主頻、4 GB內(nèi)存、Windows XP 的PC機(jī)上執(zhí)行.算法由VC++6.0實(shí)現(xiàn).實(shí)驗(yàn)使用了頻繁模式挖掘公用數(shù)據(jù)集中的mushroom和retail數(shù)據(jù)集.其中mushroom是1個(gè)稠密數(shù)據(jù)集,共有8 124條記錄,大小為0.54 MB,item的個(gè)數(shù)為120,平均記錄長度為23(即含有23個(gè)item);retail是1個(gè)稀疏數(shù)據(jù)集,共有88 162條記錄,大小為3.97 MB,16 470個(gè)item,平均每條記錄的大小為13;另外在實(shí)驗(yàn)中,我們?cè)O(shè)定界標(biāo)窗口的起始位置都為數(shù)據(jù)樣本中第1個(gè)成員的位置.因?yàn)楫?dāng)前并沒有關(guān)于這個(gè)方向的研究,所以實(shí)驗(yàn)中的對(duì)比算法為前面第3節(jié)提到的NI與NP2類na?ve算法(其中基于IncRT算法的方法被稱為NI算法;而基于PA算法的方法被稱為NP算法). 4.2 最大規(guī)范模式相對(duì)于規(guī)范模式的優(yōu)點(diǎn) 本節(jié)就最大規(guī)范模式相對(duì)于規(guī)范模式的優(yōu)勢(shì)作了實(shí)驗(yàn)驗(yàn)證.具體實(shí)驗(yàn)方法是首先對(duì)數(shù)據(jù)樣本分別執(zhí)行NI與IncRT算法以得到最大規(guī)范模式集合A與規(guī)范模式集合B;接著比較這2個(gè)結(jié)果集合中成員的內(nèi)容與數(shù)目.為便于說明,我們定義了2個(gè)參數(shù):1)Raccommodate,該參數(shù)用于表征集合A對(duì)于集合B的容納程度;2)Rreduction,用于描述集合A相對(duì)于集合B的約減程度.設(shè)|A|與|B|分別表示集合A,B中的成員個(gè)數(shù),又設(shè)變量Naccommodate表示集合A所容納集合B中成員的數(shù)目,該變量的更新變化規(guī)則是,對(duì)于集合B中的每個(gè)成員elementb,如果能在A中找到一個(gè)成員elementa,使得elementb是elementa的子集,則令Naccommodate加1.基于這樣的規(guī)定,我們可以將集合A相對(duì)于集合B的Raccommodate與Rreduction具體定義描述如下: Raccommodate=|Naccommodate||B|, (1) Rreduction= |A||B|. (2) 由上面的定義描述可知,如果實(shí)驗(yàn)結(jié)果中能夠保持Raccommodate=1,且Rreduction<1,則可以說明最大規(guī)范模式集合具有全部規(guī)范模式集合的信息,同時(shí)規(guī)模比規(guī)范模式集合要小.具體針對(duì)不同真實(shí)數(shù)據(jù)樣本的實(shí)驗(yàn)結(jié)果,如圖3所示: Fig. 3 The Raccommodate and Rreduction about maximal regular patterns over the regular ones when different data samples are taken圖3 不同數(shù)據(jù)樣本下最大規(guī)范模式相對(duì)于規(guī)范模式的Raccommodate與Rreduction 由圖3可以看到,在不同數(shù)據(jù)樣本下,最大規(guī)范模式集合相對(duì)于規(guī)范模式集合的Raccommodate始終為1,而Rreduction取值也遠(yuǎn)小于1.由前面分析可知,這樣的實(shí)驗(yàn)結(jié)果足以說明最大規(guī)范模式集合含有規(guī)范模式集合所有的信息,同時(shí)數(shù)量規(guī)模上也小于規(guī)范模式集合,所以,當(dāng)我們只想定性地確定數(shù)據(jù)集中哪些是規(guī)范模式,而不關(guān)注具體每個(gè)規(guī)范模式規(guī)范度時(shí),挖掘最大規(guī)范模式更有效率,這也是本文的研究意義所在. 4.3 DSMRM-BLW算法的有效性 本節(jié)實(shí)驗(yàn)主要用于驗(yàn)證DSMRM-BLW算法在挖掘界標(biāo)窗口上數(shù)據(jù)流最大規(guī)范模式時(shí)的有效性.這里我們使用的方法是將DSMRM-BLW算法的執(zhí)行結(jié)果與最基本的na?ve算法執(zhí)行結(jié)果進(jìn)行比較.為了便于比較,我們定義了DSMRM-BLW算法相對(duì)于其他算法的查全率與查準(zhǔn)率.具體定義如下.設(shè)DSresult與Nresult分別為相同參數(shù)下DSMRM-BLW和na?ve算法的執(zhí)行結(jié)果集合,|DSresult|與|Nresult|分別是這2個(gè)集合中成員數(shù)目.令Vequal是這2個(gè)集合中相等的成員個(gè)數(shù).這里定義DSresult中任一成員A與Nresult中成員B,如果它們對(duì)應(yīng)的窗口起始位置相同,且A與B也相同,則A,B相等;如果二者中有1項(xiàng)不同,則A,B不相等.基于這些我們定義了DSMRM-BLW相對(duì)于na?ve算法的查全率(recall)與查準(zhǔn)率(precision),分別用Rrecall與Rprecision表示.使用它們來評(píng)價(jià)DSMRM-BLW算法的有效性. Rrecall=Vequal|Nresult|, (3) Rprecision=Vequal|DSresult|. (4) 表4給出了mushroom與retail樣本下DSMRM-BLW算法分別相對(duì)于NI與NP算法的查全率與查準(zhǔn)率.表4中我們用Rrecall,NI和Rprecision,NI分別表示DSMRM-BLW算法相對(duì)于NI算法的查全率與查準(zhǔn)率,而用Rrecall,NP和Rprecision,NP分別表示DSMRM-BLW算法相對(duì)于NP算法的查全率與查準(zhǔn)率. Table 4 Parameters and Results in Experiment 2 由表4可見,在不同數(shù)據(jù)樣本及參數(shù)設(shè)置下,DSMRM-BLW算法相對(duì)于na?ve算法的Rrecall與Rprecision的取值都為1,也即DSMRM-BLW算法與na?ve算法的執(zhí)行結(jié)果相同,即DSMRM-BLW算法能正確地得到界標(biāo)窗口下數(shù)據(jù)流的最大規(guī)范模式. 4.4 DSMRM-BLW算法的性能評(píng)價(jià) 本節(jié)對(duì)DSMRM-BLW算法的時(shí)間與空間性能作了評(píng)測.因?yàn)槟壳安]有關(guān)于這方面的研究,所以使用的對(duì)比算法為前面提到的2類na?ve算法.具體來說,我們?cè)?.4.1節(jié)討論了不同|EW|,λ以及樣本大小Lsample與算法執(zhí)行時(shí)間間的關(guān)系;而在4.4.2節(jié)討論了不同|EW|,λ以及樣本大小Lsample與算法空間開銷間的關(guān)系. 4.4.1 DSMRM-BLW算法的時(shí)間開銷分析 首先分析不同λ大小與算法執(zhí)行時(shí)間之間的關(guān)系.實(shí)驗(yàn)效果如圖4所示. 由圖4可見,2類樣本下DSMRM-BLW算法執(zhí)行時(shí)間遠(yuǎn)小于其他2類算法.這說明邊界界標(biāo)窗口技術(shù)是有效的.另外還可以看到,2類樣本下3種算法執(zhí)行時(shí)間都隨λ大小的增加而增加.這是因?yàn)棣嗽酱螅總€(gè)界標(biāo)窗口中滿足規(guī)范度小于λ條件的成員就越多.也即在同一窗口中,λ變大后滿足規(guī)范度小于λ的成員個(gè)數(shù)大于等于λ變大前滿足規(guī)范度小于λ的成員個(gè)數(shù).對(duì)于NI算法,滿足規(guī)范度小于λ的成員個(gè)數(shù)越多,算法需要處理的成員就越多,得到的規(guī)范模式數(shù)目也會(huì)增加.而因?yàn)槲覀冃枰幸?guī)范模式間存在的超集關(guān)系,所以這時(shí)需要執(zhí)行該操作的成員數(shù)目變得更多,算法時(shí)間會(huì)增加.同理對(duì)于NP算法,當(dāng)滿足規(guī)范度小于λ的成員個(gè)數(shù)增加時(shí),算法中也增加了基于bit-sequence執(zhí)行邏輯與操作的成員個(gè)數(shù),得到的規(guī)范模式數(shù)目也會(huì)增加,而對(duì)于所有這些規(guī)范模式,NP算法也會(huì)通過消除它們間存在的超集關(guān)系來得到最大規(guī)范模式集合,所以算法時(shí)間會(huì)增加;DSMRM-BLW算法在第1個(gè)窗口上的情況與NP算法一樣,之后每個(gè)窗口上會(huì)使用邊界界標(biāo)窗口技術(shù)來處理,所以算法時(shí)間開銷主要決定于第1個(gè)窗口.由前面分析可知,該窗口上算法時(shí)間會(huì)隨著滿足規(guī)范度小于λ的成員個(gè)數(shù)增加而增加.另外當(dāng)λ取值的增加并沒有使窗口中滿足規(guī)范度小于λ的項(xiàng)成員個(gè)數(shù)增加時(shí),算法在這些窗口上的執(zhí)行情況在λ取值改變前后變化不大(如圖4(a)中的λ分別在40~60,80~100中取值);當(dāng)λ取值的增加使窗口中滿足規(guī)范度小于λ的項(xiàng)成員個(gè)數(shù)增加時(shí),算法在這些窗口上執(zhí)行時(shí)間會(huì)增加. 其次分析不同|EW|大小與算法執(zhí)行時(shí)間之間的關(guān)系.實(shí)驗(yàn)效果如圖5所示. Fig. 4 The comparison of the execution time about different algorithms when λ changes圖4 算法在λ變化時(shí)的執(zhí)行時(shí)間比較 Fig. 5 The comparison of the execution time about different algorithms when |EW| changes圖5 算法在|EW|變化時(shí)的執(zhí)行時(shí)間比較 由圖5可見,2類樣本下DSMRM-BLW算法執(zhí)行時(shí)間小于其他2類算法,這說明邊界界標(biāo)窗口技術(shù)是有效的.另外可以看到NI與NP算法時(shí)間都隨|EW|的增加而減少,這是因?yàn)閷?duì)于同一個(gè)數(shù)據(jù)流來說,|EW|越大,算法在該數(shù)據(jù)流上執(zhí)行最大規(guī)范模式挖掘的次數(shù)就越少,而且對(duì)于數(shù)據(jù)流上起始位置不變、終止位置以|EW|為單位不斷滑動(dòng)的界標(biāo)窗口來說,當(dāng)|EW|小時(shí),na?ve算法在數(shù)據(jù)流上執(zhí)行挖掘的總次數(shù)以及所處理數(shù)據(jù)流成員的總量,大于|EW|變大后算法所執(zhí)行挖掘的總次數(shù)以及所處理的數(shù)據(jù)流成員的總量,所以它們的時(shí)間都隨窗口大小的增加而減少.DSMRM-BLW算法在第1個(gè)窗口上與NP算法一樣,之后每個(gè)窗口上會(huì)使用邊界界標(biāo)窗口技術(shù)來處理,所以算法時(shí)間開銷主要決定于第1個(gè)窗口.因?yàn)楫?dāng)|EW|變大時(shí),變化后第1個(gè)窗口上的規(guī)范項(xiàng)數(shù)目小于等于變化前該窗口上的規(guī)范模式數(shù)目,所以對(duì)于稠密樣本下第1個(gè)窗口上的DSMRM-BLW算法來說,當(dāng)該窗口上規(guī)范模式數(shù)目不變時(shí),因?yàn)榇翱诖笮〉脑黾訒?huì)使該窗口上參與運(yùn)算的bit-sequene規(guī)模變大,所以執(zhí)行時(shí)間會(huì)增加(圖5(a)中|EW|大小在100~500,700~900);當(dāng)該窗口上的規(guī)范模式數(shù)目減少時(shí),特別是當(dāng)窗口大小的增加使得原第1個(gè)窗口上本來規(guī)范的項(xiàng)變得不規(guī)范時(shí),界于樣本自身的稠密特征,該算法在新窗口上的規(guī)范模式集合與原窗口上的規(guī)范模式集合相比,會(huì)少了很多與被刪除項(xiàng)有關(guān)的規(guī)范模式,這樣后期再執(zhí)行消除規(guī)范模式集合中成員間超集關(guān)系的操作,時(shí)間開銷會(huì)少很多,所以此時(shí)算法時(shí)間開銷會(huì)減少(圖5(a)中|EW|大小在500~700).對(duì)于稀疏樣本下第1個(gè)窗口上的DSMRM-BLW算法,樣本稀疏的特點(diǎn)會(huì)使得該窗口上的規(guī)范模式不多,同時(shí)數(shù)據(jù)結(jié)構(gòu)的規(guī)模會(huì)很大,所以該窗口上的時(shí)間開銷更多的是在于挖掘規(guī)范模式本身所花費(fèi)的時(shí)間,消除所有規(guī)范模式間超集關(guān)系所花費(fèi)的時(shí)間反而不多.當(dāng)|EW|增加時(shí),因?yàn)榈?個(gè)窗口上數(shù)據(jù)結(jié)構(gòu)的規(guī)模會(huì)變大,所以執(zhí)行時(shí)間會(huì)增加.另外我們可以看到3種算法彼此間的時(shí)間差異會(huì)隨|EW|的減少而增加,這是因?yàn)閨EW|越小,算法執(zhí)行挖掘的窗口及次數(shù)就越多,每個(gè)窗口上這3類算法執(zhí)行時(shí)間都會(huì)有差異,隨著窗口數(shù)目的增加,這種差異的累積就會(huì)越來越大,所以它們間執(zhí)行時(shí)間的差別也會(huì)越來越大. 最后分析樣本大小Lsample與算法執(zhí)行時(shí)間之間的關(guān)系.實(shí)驗(yàn)效果如圖6所示: Fig. 6 The comparison of the execution time about different algorithms when Lsample changes圖6 算法在Lsample變化時(shí)的執(zhí)行時(shí)間比較 由圖6可見,2類樣本下DSMRM-BLW算法執(zhí)行時(shí)間小于其他2類算法,這說明邊界界標(biāo)窗口技術(shù)是有效的.另外可以看到這3類算法時(shí)間都隨樣本大小的增加而增加,這是因?yàn)閷?duì)于同一個(gè)數(shù)據(jù)流來說,樣本越大,算法在該樣本上需要處理的數(shù)據(jù)流成員就越多,所以執(zhí)行時(shí)間會(huì)隨著樣本大小的增加而增加;另外由圖6中還可以看到,3類算法彼此間的時(shí)間差異會(huì)隨著樣本大小的增加而增加.這是因?yàn)闃颖驹酱螅惴▓?zhí)行挖掘的窗口及次數(shù)就越多,每個(gè)窗口上這3類算法執(zhí)行時(shí)間都會(huì)有差異,隨著窗口數(shù)目的增加,這種差異的累積就會(huì)越來越大,所以它們間執(zhí)行時(shí)間的差別也會(huì)越來越大. 4.4.2 DSMRM-BLW算法的空間開銷分析 1) 分析不同λ大小與算法空間開銷之間的關(guān)系.實(shí)驗(yàn)效果如圖7所示. Fig. 7 The comparison of the space consumption about different algorithms when λ changes圖7 算法在λ變化時(shí)的空間開銷比較 由圖7可以看到,在空間開銷上DSMRM-BLW Fig. 8 The comparison of the space consumption about different algorithms when |EW| changes圖8 算法在|EW|變化時(shí)的空間開銷比較 另外從圖7可以看到,3種算法空間開銷隨λ大小增加而單調(diào)增加.對(duì)于稠密樣本下的NI與NP算法,樣本的稠密性會(huì)使算法的空間開銷決定于每個(gè)窗口上所有規(guī)范模式的規(guī)模.而當(dāng)λ增加時(shí),每個(gè)窗口中滿足規(guī)范度小于λ的項(xiàng)成員數(shù)目可能會(huì)有2種變化:①數(shù)量保持不變;②數(shù)量增加.NI算法需要保留每個(gè)窗口上完整的規(guī)范模式集合,同時(shí)還需要開辟空間用于在該集合基礎(chǔ)上得到最大規(guī)范模式集合,所以如果λ的增加沒有使窗口中滿足規(guī)范條件的成員數(shù)目發(fā)生變化,則NI算法用于存放規(guī)范模式集合的空間保持不變(如圖7(a)中λ取值在40~60和80~100區(qū)間);如果λ的增加使得窗口中滿足規(guī)范條件的成員數(shù)目增加,則NI算法用于存放規(guī)范模式的空間就會(huì)增加.對(duì)于NP算法,因?yàn)镹P算法需要對(duì)每個(gè)窗口上所有項(xiàng)構(gòu)建bit-sequence序列,另外NP算法也要開辟空間基于每個(gè)窗口上的完整規(guī)范模式集合來得到最大規(guī)范模式集合,所以NP算法與NI算法一樣,空間開銷都會(huì)隨著λ取值的增加而單調(diào)遞增.DSMRM-BLW算法在第1個(gè)窗口上執(zhí)行情況與NP算法一樣,所以該窗口上空間開銷會(huì)隨著λ的增加而單調(diào)遞增.又因?yàn)樵撍惴ㄔ谄渌翱谏鲜褂眠吔缃鐦?biāo)窗口技術(shù),所以空間開銷并不大,也即此時(shí)整個(gè)算法的空間開銷集中在第1個(gè)窗口上,于是空間開銷會(huì)增加.總體來看,DSMRM-BLW算法在每個(gè)窗口上的空間開銷會(huì)隨著λ取值的增加而單調(diào)遞增.對(duì)于稀疏樣本下的算法,樣本的稀疏性會(huì)使得每個(gè)窗口上規(guī)范模式的數(shù)目較少,且數(shù)據(jù)結(jié)構(gòu)規(guī)模較大.這種情況下算法的空間開銷決定于每個(gè)窗口上數(shù)據(jù)結(jié)構(gòu)的規(guī)模.又因?yàn)?類算法在每個(gè)窗口上的數(shù)據(jù)結(jié)構(gòu)與λ無關(guān),所以可以看到它們?cè)诿總€(gè)窗口上的空間開銷基本相同. 2) 分析不同|EW|大小與算法空間開銷間的關(guān)系.實(shí)驗(yàn)效果如圖8所示. 由圖8可以看到,DSMRM-BLW算法具有最好的空間開銷,而且不同算法間空間開銷的關(guān)系與λ變化時(shí)所呈現(xiàn)的狀態(tài)一樣.具體原因與在λ變化時(shí)不同算法空間開銷間關(guān)系分析中己有說明,篇幅原因,這里不再贅述.稠密樣本下2種na?ve算法在每個(gè)窗口上的空間開銷,都隨|EW|增加而減小.這是因?yàn)閷?duì)于界標(biāo)窗口而言,當(dāng)λ確定時(shí),基本窗口較大情況下界標(biāo)窗口中規(guī)范模式數(shù)目會(huì)小于等于基本窗口較小情況下界標(biāo)窗口中的規(guī)范模式數(shù)目,所以用于存放小基本窗口下界標(biāo)窗口中所有規(guī)范模式的空間開銷大于等于大基本窗口下界標(biāo)窗口中用于存放所有規(guī)范模式的空間開銷.對(duì)于DSMRM-BLW算法,因?yàn)閙ushroom樣本稠密性的特點(diǎn),該算法在第1個(gè)窗口上的空間開銷遠(yuǎn)遠(yuǎn)大于其他窗口上的空間開銷,這時(shí)該算法的空間開銷主要決定于這個(gè)窗口,當(dāng)|EW|增加時(shí),需要處理的界標(biāo)窗口數(shù)會(huì)變小,這樣平均每個(gè)窗口上的空間開銷就會(huì)增加;retail樣本下算法的空間開銷都隨|EW|增加而單調(diào)增加.這是因?yàn)闃颖鞠∈璧奶攸c(diǎn)會(huì)使得每個(gè)界標(biāo)窗口上滿足規(guī)范條件的項(xiàng)變得很少,而且同時(shí)又會(huì)使窗口上的數(shù)據(jù)結(jié)構(gòu)規(guī)模增加,所以這種情況下算法空間開銷決定于每個(gè)窗口的數(shù)據(jù)結(jié)構(gòu)規(guī)模.對(duì)于NI算法,因?yàn)榇翱谠酱螅渲谐蓡T越多,每個(gè)窗口上的前綴樹規(guī)模就越大,所以空間開銷會(huì)增加;對(duì)于NP算法與DSMRM-BLW算法,因?yàn)榇翱谠酱螅總€(gè)窗口上BVtable規(guī)模就越大,所以空間開銷單調(diào)增加. 3) 分析樣本大小Lsample與算法空間開銷之間的關(guān)系.實(shí)驗(yàn)效果如圖9所示: Fig. 9 The comparison of the space consumption on different algorithms when Lsample changes圖9 算法在Lsample變化時(shí)的空間開銷比較 由圖9可見,DSMRM-BLW算法具有最好的空間開銷;另外還可以看到稠密樣本下3種算法空間開銷都隨樣本大小增加而單調(diào)遞減.對(duì)于2類na?ve算法,因?yàn)殡S著樣本大小的增加,會(huì)出現(xiàn)更多需要處理的界標(biāo)窗口,而且這些窗口大小會(huì)越來越大,窗口上規(guī)范模式的數(shù)目會(huì)小于等于之前出現(xiàn)的窗口上規(guī)范模式的數(shù)目,所以平均每個(gè)窗口上的空間開銷會(huì)單調(diào)減少;對(duì)于DSMRM-BLW算法,因?yàn)樵摌颖鞠碌目臻g開銷決定于第1個(gè)界標(biāo)窗口,所以隨著窗口數(shù)目的增加,平均每個(gè)窗口的空間開銷會(huì)越來越小.另外還可以看到稀疏樣本下算法的空間開銷都會(huì)隨著樣本大小的增加而單調(diào)增加.這是因?yàn)檫@類樣本下算法的空間開銷主要決定于每個(gè)窗口上的數(shù)據(jù)結(jié)構(gòu)規(guī)模.對(duì)于NI算法,因?yàn)槊總€(gè)新增加窗口上的前綴樹規(guī)模大于等于相鄰前一個(gè)窗口上的前綴樹規(guī)模,所以在樣本大小增加過程中,每個(gè)窗口上平均空間開銷會(huì)增加;對(duì)于NP算法,因?yàn)槊總€(gè)新增加窗口上的BVtable規(guī)模會(huì)大于相鄰前一個(gè)窗口上的BVtable規(guī)模,所以在樣本大小增加過程中,每個(gè)窗口上的平均空間開銷也會(huì)增加;同理DSMRM-BLW算法在樣本大小增加過程中,每個(gè)窗口上平均空間開銷也會(huì)增加. 總之,由本節(jié)實(shí)驗(yàn)可以看到:①在需要定性確定數(shù)據(jù)集上哪些成員是規(guī)范模式時(shí),挖掘最大規(guī)范模式有更好的效率,能在不減少規(guī)范模式所蘊(yùn)含信息的同時(shí),極大減少需要挖掘的模式數(shù)量;②DSMRM-BLW算法在挖掘界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式時(shí),與na?ve算法執(zhí)行結(jié)果相同;③同2類na?ve算法相比,DSMRM-BLW算法具有更好的時(shí)間與空間效率. 本文首次對(duì)于界標(biāo)窗口下數(shù)據(jù)流最大規(guī)范模式挖掘問題進(jìn)行了研究.首先給出了該問題的形式化描述;接著對(duì)處理該問題的na?ve算法中相鄰窗口上最大規(guī)范模式間的關(guān)系進(jìn)行了分析,得到了邊界界標(biāo)窗口技術(shù),并由此提出了DSMRM-BLW算法,與na?ve算法相比,該算法在保持查詢結(jié)果不變的同時(shí),很好地減少了時(shí)間與空間開銷;最后通過對(duì)于公有數(shù)據(jù)樣本的實(shí)驗(yàn)證明了該算法的有效性.因?yàn)橐?guī)范模式與頻繁模式二者都具有向下閉包的特點(diǎn),所以很多與數(shù)據(jù)流最大頻繁模式挖掘相關(guān)的技術(shù)應(yīng)該可以直接或間接地應(yīng)用于數(shù)據(jù)流最大規(guī)范模式的挖掘中,所以未來研究中我們會(huì)著重分析這二者間的關(guān)系,爭取進(jìn)一步提高DSMRM-BLW算法的執(zhí)行效率;另外,界標(biāo)窗口中歷史數(shù)據(jù)的重要性會(huì)隨著時(shí)間的推移而減小.為了能夠體現(xiàn)出這個(gè)特點(diǎn),可以將衰減模型與DSMRM-BLW算法相結(jié)合,這也是未來應(yīng)該著手做的一個(gè)研究方向. [1]Tanbeer S K, Ahmed C F, Jeong B S. Mining regular patterns in data streams[C]Proc of the 15th Int Conf on Data Systems for Advanced Applications. Berlin: Springer, 2010: 399-413 [2]Li Guohui, Chen Hui. Mining the frequent patterns in an arbitrary sliding window over online data stream[J]. Journal of Software, 2008, 19(10): 2585-2596 (in Chinese)(李國徽, 陳輝. 挖掘數(shù)據(jù)流任意滑動(dòng)窗口內(nèi)頻繁模式[J]. 軟件學(xué)報(bào), 2008, 19(10): 2585-2596) [3]Yun U, Lee G, Ryu K H. Mining maximal frequent patterns by considering weight conditions over data streams[J]. Knowledge-Based Systems, 2014, 55: 49-65 [4]Lee G, Yun U, Ryu K H. Sliding window based weighted maximal frequent pattern mining over data streams[J]. Expert Systems with Applications, 2014, 41(2): 694-708 [5]Hang Meng, Wang Zhihai, Yuan Jidong. Efficient method for mining closed frequent patterns from data streams based on time decay model[J]. Chinese Journal of Computers, 2015, 38(7): 1473-1483 (in Chinese)(韓萌, 王志海, 原繼東. 一種基于時(shí)間衰減模型的數(shù)據(jù)流閉合模式挖掘方法[J]. 計(jì)算機(jī)學(xué)報(bào), 2015, 38(7): 1473-1483) [6]Tanbeer S K, Ahmed C F, Jeong B S. Mining regular patterns in incremental transactional databases[C]Proc of the 12th Asia-Pacific Web Conf. Piscataway, NJ: IEEE, 2010: 375-377 [7]Kumar G V, Sreedevi M, Kumar N P. Mining regular patterns in data streams using vertical format[J]. International Journal of Computer Science and Security, 2012, 6(2): 142-149 [8]Verma V K, Saxena K. Mining regular pattern over dynamic data stream using bit stream sequence[J]. International Journal of Innovative Technology and Exploring Engineering, 2013, 3(7): 7-10 [9]Kumar G V, Kumari V V. Sliding window technique to mine regular frequent patterns in data streams using vertical format[C]Proc of the Int Conf on Computational Intelligence and Computing Research. Piscataway, NJ: IEEE, 2012: 1-4 [10]Sreedevi M, Reddy L S S. Mining closed regular patterns in data streams[J]. International Journal of Computer Science & Information Technology, 2013, 5(1): 171-179 [11]Rashid M M, Karim M R, Jeong B S, et al. Efficient mining regularly frequent patterns in transactional databases[C]Proc of the 17th Int Conf on Database Systems for Advanced Applications. Berlin: Springer, 2012: 258-271 [12]Rashid M M, Gondal I, Kamruzzaman J. Regularly frequent patterns mining from sensor data stream[C]Proc of the 20th Int Conf on Neural Information Processing. Berlin: Springer, 2013: 417-424 [13]Agrawal R, Srikant R. Fast algorithms for mining association rules in large database[C]Proc of the 20th Int Conf on Very Large Data Bases. San Francisco, CA: Morgan Kaufmann, 1994: 1-32 Wen Yingyou, born in 1974. PhD and post doctor of Northeastern University. Member of CCF. His main research interests include next generation network, wireless sensor network, network security and network management (wenyy@neusoft.com). Wang Shaopeng, born in 1984. PhD from Northeastern University. Member of CCF. His main research interests include data stream and wireless sensor network. Zhao Hong, born in 1954. Professor and PhD supervisor of Northeastern University. Senior member of CCF. His main research interests include computer network security and information security, distributed multimedia, and network management (zhaoh@neusoft.com). The Maximal Regular Patterns Mining Algorithm Based on Landmark Windowover Data Stream Wen Yingyou1,3, Wang Shaopeng1,2, and Zhao Hong1,3 1(CollegeofComputerScienceandEngineering,NortheasternUniversity,Shenyang110819 )2(CollegeofComputerScience,InnerMongoliaUniversity,Huhhot010021)3(KeyLaboratoryofMedicalImageComputing(NortheasternUniversity),MinistryofEducation,Shenyang110819 ) Mining regular pattern is an emerging area. To the best of our knowledge, no method has been proposed to mine the maximal regular patterns about data stream. In this paper, the problem of mining maximal regular patterns based on the landmark window over data stream is focused at the first time. In order to resolve the issue that the na?ve algorithm which is used to handle the maximal regular patterns mining based on the landmark window over data stream does not have the characteristic of incremental computation, the DSMRM-BLW(data stream maximal regular patterns mining based on boundary landmark window) algorithm is proposed. It takes the first window as the boundary landmark window, and handles it with the na?ve algorithm. For all other windows, it can obtain the maximal regular patterns over them based on the ones over the adjacent last window incrementally, and can overcome the drawback of the na?ve algorithm. It is revealed by the extensive experiments that the DSMRM-BLW algorithm is effective in dealing with the maximal regular patterns mining based on the landmark window over data stream, and outperforms the na?ve algorithm in execution time and space consumption. data stream; landmark window; maximal regular pattern; incremental calculation; boundary landmark window technology 2015-09-06; 2016-02-16 國家自然科學(xué)基金項(xiàng)目(60903159,61173153,61402096,61163011,61262082,61662054);中央高校基本科研業(yè)務(wù)費(fèi)專項(xiàng)資金項(xiàng)目(N110818001,N100218001,N130504007,N120104001);國家“八六三”高技術(shù)研究發(fā)展計(jì)劃基金項(xiàng)目(2015AA016005);沈陽市科技計(jì)劃項(xiàng)目(1091176 -1-00);內(nèi)蒙古自然科學(xué)基金項(xiàng)目(2015MS0612) This work was supported by the National Natural Science Foundation of China (60903159, 61173153, 61402096, 61163011, 61262082, 61662054), the Fundamental Research Funds for the Central Universities (N110818001, N100218001, N130504007, N120104001), the National High Technology Research and Development Program of China (863 Program)(2015AA016005), the Science and Technology Plan of Shenyang of China (1091176-1-00), and the Natural Science Foundation of Inner Mongolia (2015MS0612). TP3113 基于邊界界標(biāo)窗口技術(shù)的數(shù)據(jù)流最大規(guī)范模式挖掘算法



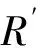
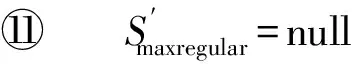
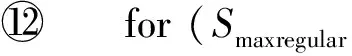










4 實(shí)驗(yàn)及結(jié)果分析
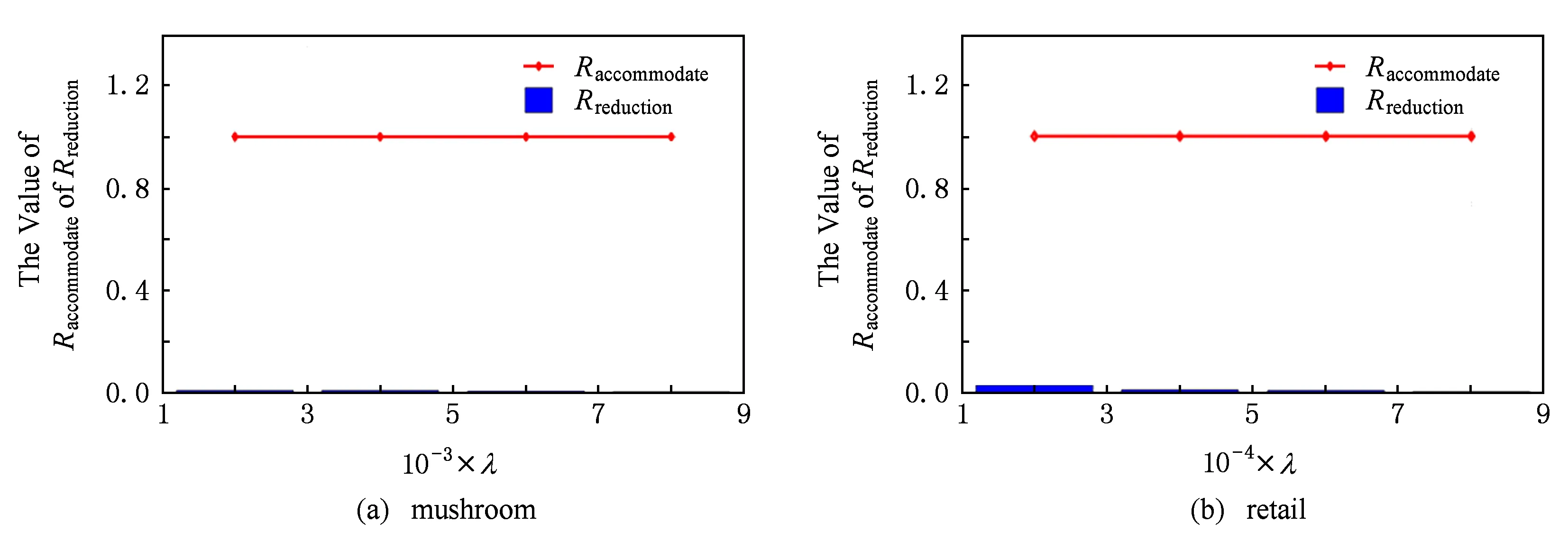
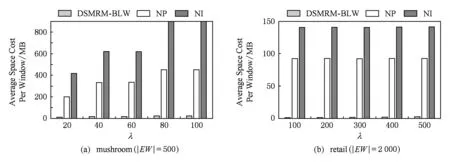

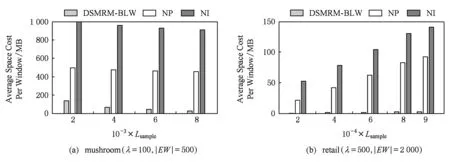
5 總結(jié)與展望


 猜你喜歡
中小學(xué)教師培訓(xùn)(2022年11期)2022-11-01 03:13:54中小學(xué)教師培訓(xùn)(2022年10期)2022-10-15 02:18:04保健醫(yī)苑(2022年6期)2022-07-08 01:24:52北部灣大學(xué)學(xué)報(bào)(2022年1期)2022-06-22 04:58:38北部灣大學(xué)學(xué)報(bào)(2022年2期)2022-06-21 11:44:36中國信息化(2022年4期)2022-05-06 21:24:05北部灣大學(xué)學(xué)報(bào)(2021年1期)2022-01-27 06:40:10現(xiàn)代儀器與醫(yī)療(2021年4期)2021-11-05 08:25:08北部灣大學(xué)學(xué)報(bào)(2021年6期)2021-06-21 06:01:48北部灣大學(xué)學(xué)報(bào)(2021年4期)2021-04-28 08:01:04
猜你喜歡
中小學(xué)教師培訓(xùn)(2022年11期)2022-11-01 03:13:54中小學(xué)教師培訓(xùn)(2022年10期)2022-10-15 02:18:04保健醫(yī)苑(2022年6期)2022-07-08 01:24:52北部灣大學(xué)學(xué)報(bào)(2022年1期)2022-06-22 04:58:38北部灣大學(xué)學(xué)報(bào)(2022年2期)2022-06-21 11:44:36中國信息化(2022年4期)2022-05-06 21:24:05北部灣大學(xué)學(xué)報(bào)(2021年1期)2022-01-27 06:40:10現(xiàn)代儀器與醫(yī)療(2021年4期)2021-11-05 08:25:08北部灣大學(xué)學(xué)報(bào)(2021年6期)2021-06-21 06:01:48北部灣大學(xué)學(xué)報(bào)(2021年4期)2021-04-28 08:01:04
