MapReduce框架下的Skyline結果優化算法*
2017-02-18 06:16:06馬學森王曉潔韓江洪王營冠
傳感器與微系統 2017年2期
關鍵詞:實驗
馬學森, 王曉潔, 韓江洪, 王營冠
(1.合肥工業大學 計算機與信息學院,安徽 合肥 230009;2.中國科學院 上海微系統與信息技術研究所 無線傳感網絡與通信重點實驗室,上海 200050)
MapReduce框架下的Skyline結果優化算法*
馬學森1,2, 王曉潔1, 韓江洪1, 王營冠2
(1.合肥工業大學 計算機與信息學院,安徽 合肥 230009;2.中國科學院 上海微系統與信息技術研究所 無線傳感網絡與通信重點實驗室,上海 200050)
隨著大數據時代的到來,數據量和數據復雜度急劇提高,Skyline查詢結果集規模巨大,無法為用戶提供精確的信息。MapReduce作為并行計算框架,已廣泛應用于大數據處理中。本文提出了MapReduce框架下基于支配個數的結果優化算法(MR-DMN),解決了大數據環境下的Skyline結果集優化問題。大量的實驗表明:算法具有良好的時間和空間效率。
大數據; MapReduce; Skyline; 支配個數
0 引 言
Skyline查詢[1]是指從給定數據集中選擇一組不被其他數據支配的數據,所謂支配是指一個數據在所有維度上都不比其他數據差,且至少在一個維度上優于其他數據。典型的Skyline查詢例子是業務選擇問題,由于經營調整,企業需要保留一些銷量高且單件利潤高的業務,Skyline查詢的結果集是銷量和利潤上都不比其他業務差,且至少在一個屬性上優于其他的業務。Skyline查詢廣泛應用于用戶推薦、決策支持以及數據可視化等領域。
在現實生活中,數據在各個維度上的取值是有優有劣的,隨著數據維度的增大,支配的條件越來越難滿足,一個點支配另一個點的可能性越來越小,因此,結果集中將包含很多互不支配的數據點。隨著大數據環境下數據量和數據復雜度的提高,Skyline查詢結果集的規模急劇增大。在隨機數據集中,Skyline結果集數量為Θ(lnd-1n/(d-1)!)[2]。
如何為用戶選取規模較小,更具有代表性的結果集,提高大數據下Skyline結果集的質量,成為急需解決的問題。近年來興起的MapReduce并行計算框架[3]廣泛應用于大數據及云計算[4]處理中,本文將Skyline結果集優化算法與MapReduce框架相結合,提出了大數據下Skyline結果集優化算法。提出了MapReduce框架下的基于支配個數的算法(MapReduce dominant number-based algorithm,MR-DMN)。實驗結果表明:MR-DMN具有良好的時間和空間性能。
1 相關工作
1.1 基本概念
Skyline查詢是指從給定的一個d維空間數據點集合D中選擇一個子集,該子集中的任意一個點都不能被D中其他點所支配。具體來說,給定d維數據空間S={s1,s2,…,sd}(d∈N*)上的數據集合D={P1,P2,…,Pn}(n∈N*),D中的每一個數據點Pi是S空間中的一個d維數據點,Pi.sj表示數據點Pi的第j維度的值。為了簡便,不失一般性,本文中假設數據點越大越優。
定義1支配(dominate):給定數據集D中的兩點Pi,Pj(i,j∈[1,n]),稱Pi支配Pj,當且僅當對于?si∈S(i∈[1,d]),都有Pi·si≥Pj·si,并且?t∈[1,d],使得Pi·st>Pj·st。
定義2Skyline集(Skyline(D)):對于?Pi∈D,稱Pi為D中的Skyline點, 當且僅當在D中不存在支配Pi的數據點。D中所有Skyline數據點構成了D上的Skyline數據集,記作Skyline(D)。
1.2 Skyline結果集優化算法
為了對Skyline查詢結果集進行優化,為用戶返回更具有代表性的結果集。有學者提出返回k個最具有代表性的結果點代表整個結果集,該算法主要分為以下三類:
1)Top-k查詢算法
Top-k查詢算法[5]利用單調打分函數對每個數據的維度值進行聚集,得到單一的打分值,按照打分值對所有數據進行排序,選出前k個數據作為最終結果返回給用戶。例如在圖1的示例中,假設打分函數為F=x+y,則top-3查詢結果為B(6,9),C(7,8),D(9,7)三點。top-k查詢的優勢是用戶可以通過參數k控制返回結果的數量,由于結果對象的選取依賴于打分函數,因此,適當地選取打分函數成為解決問題的關鍵。同時,Top-k查詢的結果是根據打分函數選擇的,數據點之間沒有進行支配比較,因此,其結果不一定是Skyline點。
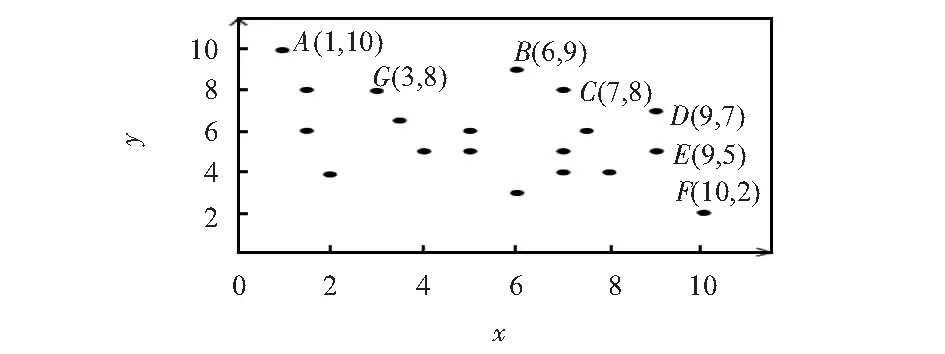
圖1 原始數據集示例
2)Top-k支配
同樣為了有效地返回k個具有代表性的結果點,top-k支配(top-k dominating)查詢[6]的主要思想是,一個點的重要程度可以用該點所支配的其他點個數μ(p)來衡量。top-k支配查詢根據μ(p)值對數據集排序,返回μ(p)值最高的k個點作為查詢結果。例如,圖2示例中top-4支配查詢的結果是B(6,9),C(7,8),D(9,7),E(9,5)。
文獻[6]提出了計算top-k支配查詢的基本方法,即先計算原始數據集的Skyline集,找到top-1支配Skyline點p,之后將p移出數據集D,迭代查找下一個點,直到找到k個點。文獻[7]對傳統的R-tree算法改進,得到聚合R-tree,該算法可以并行計算數據點的打分值,依據打分值優先級遍歷搜索所有樹節點。當數據量很大時,構建索引的代價將非常大。文獻[8]提出了分布式環境下的top-k支配查詢,避免了多余的通信開銷和延遲。
3)k個最具有代表性的Skyline點查詢算法
在top-k支配查詢算法中仍存在一些問題,該算法的結果可能包含非Skyline點,如在上述例子中,top-4支配查詢結果中的E(9,5)不是Skyline點。這也反映出Skyline查詢的特點:在Skyline計算中,盡管一個點支配了很多非Skyline點,最終仍可能被其他Skyline點支配掉,無法成為Skyline點。相反可能有些點支配其他點的個數并不多,它仍是Skyline點,如圖2中的點A(1,10)。
為了解決top-k支配存在的問題,Lin X M等人提出從Skyline結果集中選擇k個最有代表性的Skyline點(top-krepresentative skyline points,top-kRSP)查詢算法[9]。給定一個數據集D和參數k,得到包含k個Skyline點的集合S,使得|D(S)|取得最大值,|D(S)|表示所有被S中的點支配的點的數量。Top-kRSP算法兼具了Skyline查詢和Top-k查詢的優點,不需要依賴具體的打分函數,且有效控制了Skyline查詢結果集數量。
作者提出了針對二維數據Top-kRSP查詢的動態編程算法,該算法的內存開銷為O(m2)(m為Skyline點數量)。作者證明三維及以上數據的top-kRSP算法是NP-hard問題,提出貪婪算法(greedy algorithm,GDY)[9],算法首先計算出所有Skyline結果,接著再次掃描數據集計算出每個Skyline點的支配個數,得到支配個數最多的k個點。為了保存每個Skyline點支配數據點的內存開銷為O(mn)(n為數據集D的大小),當維度達到5維時,45 %的被支配點會被寫入內存中,將產生很大的I/O開銷。
1.3 MapReduce并行計算框架
MapReduce是一個分布式并行計算框架,已廣泛應用于大數據的計算中。它的基本思想是分治法,主要由兩個階段的任務組成:Map Task和Reduce Task。對于具有較少依賴關系的數據,用一定的數據劃分方法對數據進行劃分,每個數據分片交給一個Map Task處理,Reduce Task負責對Map的結果進行匯總整理和輸出。Map Task將讀取的數據分片解析為(key,value)對,調用用戶自定義的map()函數進行處理,并將結果映射成新的(key,value)對存放在本地磁盤上;Reduce Task讀取Map Task的結果,調用reduce()函數處理,最后按照(key,value)對的形式輸出到HDFS文件系統上。Map和Reduce任務在輸出數據時,會按照key值對數據記錄排序輸出。
2 MapReduce下的top-k RSP算法
傳統的top-kRSP算法通常采用索引結構,數據點建立索引將產生巨大的內存和I/O開銷,無法應用于大數據環境。GDY不需要構建索引,但需要多次遍歷整個數據集求出每個Skyline點支配的其他點,需要大量額外的內存空間保存被支配的點,其時間和空間效率還有待提高。本文將GDY算法應用到MapReduce框架下,并對MR-GDY算法(MapReduce-based greedy algorithm, MR-GDY)進行改進,首次提出了大數據環境下的top-kRSP算法中的MR-DMN算法在進行數據支配比較的同時,記錄每個點的支配個數,從而為用戶返回支配個數最多的k個Skyline點。
2.1 MR-DMN算法原理
根據top-kRSP查詢的定義,該算法返回Skyline結果集中k個支配個數最多的Skyline點。因此,MR-DMN算法在進行數據點間的支配比較時,記錄每個數據點的支配個數。具體來說:窗口隊列w用于保存暫時的Skyline點,進入窗口的數據點p將被附加一個標記位num(p),用于標記該點支配的數據點個數。第一個數據點將被放入窗口中,num(p)置為0。接下來,每讀取一個新的數據點q都會與窗口中的所有點進行比較,將會出現以下三種情況(新數據點q的初始num值為0):
1)若窗口中存在點p支配q,則將q刪除,由于支配具有傳遞性,p可以支配q支配的所有點,并且可以支配q,因此,更新num(p),num(p)=num(p)+num(q)+1。
2)若點q支配窗口中的點p,則將p從窗口中刪除,同時將q加入窗口隊列。若q支配p,則q可以支配p所支配的所有點,并可以支配p,因此,num(q)=num(q)+num(p)+1。
3)若q與窗口中的所有點比較后,與所有數據點均互不支配,原來窗口中的點num值不變,將q加入窗口中,num(q)置為0。
MR-DMN算法的難點在于計算每個Skyline點的支配個數,在上述比較中,若點q被支配,則將它直接刪除。然而可能其他點也會支配該點,由于失去了與該點比較的機會,其他點的num值可能會產生偏差。例如圖2中的點G(3,8),它同時被兩個點B(6,9),C(7,8)支配,若G被B支配后被直接刪除,那么G無法與C比較,C的支配個數將會比實際結果小1。因此,在MR-DMN算法中,若一個新點q被支配,不應立即將它刪除,而將它與臨時窗口中的所有點進行比較后再刪除。與此同時產生另一個問題,即若此時C點還沒有進入臨時窗口中,C點也無法與G點進行比較,從而導致C的num值計算不準確。如果將支配能力[10]較強的點優先放在窗口中,那么它們與每個被支配的點都會有比較的機會,這樣計算得出的num(p)會更準確。同時,若將支配能力強的點放在隊列前面,可以避免后面的點支配前面的點,避免了數據的換入換出,從而加快Skyline結果的計算。因此,算法引入參考文獻[10]中數據點支配能力的計算方法
(1)
在MR-DMN算法中,Map階段首先對數據點按照支配能力大小進行排序,再進行數據點間的支配比較,在數據點支配比較的過程中記錄每個數據點的num值,最后按照num值大小降序輸出到Reduce階段。在Reduce階段,匯總所有Map階段的輸出結果,對所有數據點再進行一次支配比較,最終返回支配個數最大的k個Skyline點。
2.2 MR-DMN算法流程
1)Map階段:整個數據集被劃分到2個Map任務中,在每個Map任務中數據點進行排序后,開始數據點間的支配比較。在第一個Map任務中,數據點(7,8)分別支配數據點(5,6),(4,7),(3,8),(4,6),(5,4),(6,3),(3,2),共7個數據點,因此,num(7,8)=7。同理,num(6,9)=7,(1,10)由于未支配任何數據點,num(1,10)=0。在第二個Map任務中,數據點(8,7)支配點(7,7),(6,7),(8,5),(7,4),(6,4),(4,5),num(8,7)=6,(9,6)支配了點(8,5),(9,4),(7,4),(6,4),(4,5),num(9,6)=5,num(10,2)=0。當所有數據點比較結束后,每個Map任務的結果按照num(p)值降序輸出到Reduce階段。
2)Reduce階段:匯總所有Map任務的輸出結果,對所有數據點再進行一次支配比較。數據點(8,8)支配點(7,8),因此,num(8,8)=num(8,8)+num(7,8)+1=6+7+1=14。所有數據點比較結束后,輸出k個num(p)值最大的Skyline點,本例中取k值為3,最終結果為(8,8),(6,9), (9,6)。MR-DMN算法流程如圖2所示。
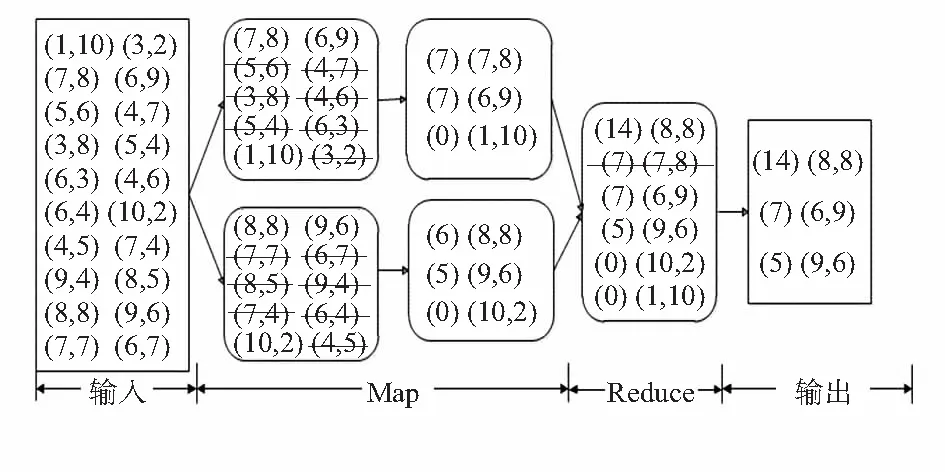
圖2 MR-DMN算法流程
3 MR-DMN算法實驗
3.1 實驗環境
本文實驗用機的配置為:內存4GB,操作系統為Windows7,處理器為Intel(R)Core(TM)i5-3210MCPU@ 2.50GHz。在Ubuntu環境下模擬了Hadoop偽分布式環境,算法全部用Java實現,Eclipse的版本為3.3.2,在JDK1.6環境下編譯,Hadoop的版本為0.20.2。
本文實驗利用文獻[1]中的標準數據生成工具生成了正相關、反相關和獨立分布的實驗數據。每個數據集的數據量為2~10M,數據維度從2~8變化,默認維度是5。將本文中提出的MR-DMN算法與MR-GDY算法進行比較。由于正相關分布下算法查詢性能與獨立分布下相似,因此,本次實驗主要分析獨立分布和反相關分布下的算法性能。
3.2 時間效率分析
1)本次實驗測試了算法運行時間與數據量之間的關系,分別測試了反相關分布及獨立分布下的4維數據,數據量從2M變化到10M的運行時間,實驗結果如圖3(a)和3(b)所示。隨著數據量的增大,算法時間增加,獨立分布數據集的運行時間遠小于反相關分布下的運行時間。這主要是由于反相關分布數據各維度取值相異,在進行支配判斷時需進行大量比較,因此算法運行時間較長。由于MR-GDY算法需要進行多輪全局的比較才能得出結果,而MR-DMN算法只需訪問一次數據集即可求得結果,因此,MR-DMN算法運行時間有明顯縮減。
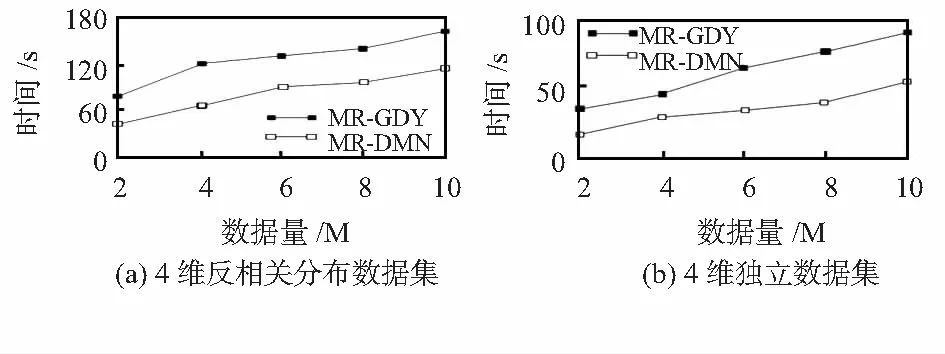
圖3 反相關及獨立數據集運行時間與數據量關系
2)本次實驗測試了算法運行時間與維數之間的關系,測試了在2M數據集下,反相關以及獨立分布下數據維數由2變化到8的運行時間,實驗結果分別如圖4(a)和4(b)所示。從實驗結果看,反相關分布的運行時間對維度比較敏感,當維度增大時,數據點間不相互支配的情況增多,從而導致結果集變大,運行時間增加。而獨立分布下,結果集隨維度增加變化不大,因此,算法運行時間的增加沒有反相關分布下明顯。
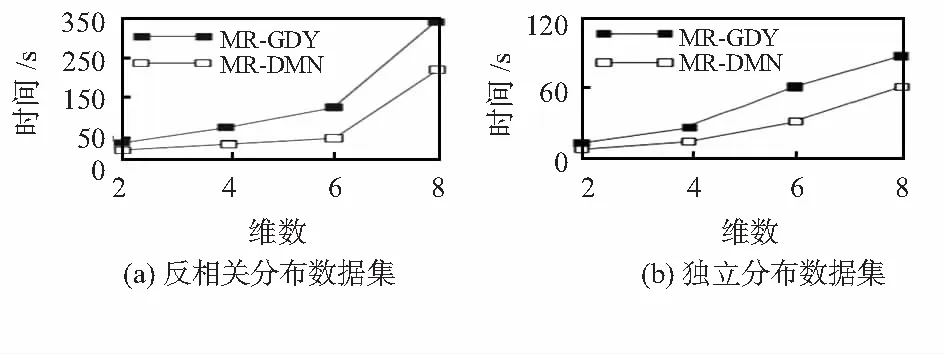
圖4 反相關及獨立數據集運算時間與維數關系
3)本次實驗測試了算法運行時間與k值之間的關系。分別測試了反相關分布以及獨立分布下,k值從10變化到50的運行時間變化,實驗結果分別如圖5(a)和5(b)所示。由于MR-GDY算法中需要不斷合并新的數據點,因此,當k值增大時算法時間變長。
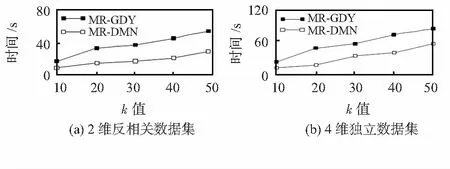
圖5 反相關及獨立數據集運行時間與k值關系
3.3 空間效率分析
由于MR-GDY算法需要保存所有Skyline點支配的點,因此將產生較大的內存開銷。在二維數據集上,MR-GDY所需的內存空間為整個數據集的2倍,而當數據維度為5時,MR-GDY所需要的內存空間為整個數據集的數十倍以上。MR-DMN算法僅需要增加一位用于存儲該數據點的支配個數,除此之外不需要額外的存儲空間,所需內存空間最大為原始數據集的1+1/d倍(d為數據維數),因此,MR-DMN具有良好的空間效率。
4 結 論
本文在分析了傳統Skyline結果優化算法的基礎上,針對大數據環境下的Skyline結果集優化問題,提出了MapReduce框架下基于支配能力的優化算法MR-DMN。MR-DMN在進行支配比較的同時,計算每個Skyline點的支配個數,選取支配個數最大的k個點作為返回結果。實驗結果表明:MR-DMN算法在大數據環境下,相對于傳統的MR-GDY算法,時間效率和空間效率有了明顯的提高。
[1]BorzsonyiS,KossmannD,StockerK.TheSkylineoperator[C]∥Proceedingsofthe17thInternationalConferenceonDataEngineering(ICDE),2001:421-430.
[2]ChanC,JagadishHV,TianKL,etal.Onhighdimensionalskylines[C]∥AdvancesinDatabaseTechnology,2006:478-495.
[3] 張建平,李 斌,劉學軍,等.基于Hadoop的異常傳感數據時間序列檢測[J].傳感技術學報,2014,27(12):1660-1665.
[4] 劉東平,馬利亞,楊 軍.云環境下異構無線傳感器網絡節點調度改進算法[J].傳感器與微系統,2015,34(10):128-132.
[5]TaoY,XiaoP.Efficientskylineandtop-kretrievalinsubspace-s[J].TransactionsonKnowledgeandDataEngineering,2007,19(8):1072-1088.
[6]YiuML,MamoulisN.Multi-dimensionaltop-kdominatingqueries[J].VLDBJournal,2009,18(3):695-718.
[7] 韓希先,楊東華.TKEP:海量數據上一種有效的Top-kDominating查詢處理算法[J].計算機學報,2010,33(8):1405-1417.
[8]AmagataD,SasakiY.Efficientprocessingoftop-kdominatingqueriesindistributedenvironments[C]∥WorldWideWeb,2015:1-33.
[9]LinXM,YuanYD,ZhangQ,etal.Selectingstars-thekmostrepresentativeskylineoperator[C]∥The23rdInternationalConferenceonDataEngineering(ICDE),2007:86-95.
[10] 印 鑒,姚樹宇,薛少鍔,等.一種基于索引的高效k—支配Skyline算法[J].計算機學報,2010,33(7):1237-1245.
作者簡介:
馬學森(1977-),男,博士,副教授,主要從事網絡與信息安全、物聯網研究工作。
Skyline result optimization algorithm based on MapReduce framework*
MA Xue-sen1,2, WANG Xiao-jie1, HAN Jiang-hong1, WANG Ying-guan2
(1.School of Computer & Information,Hefei University of Technology,Hefei 230009,China;2.Key Laboratory of Wireless Sensor Networks & Communication,Shanghai Institute of Microsystem and Information Technology,Chinese Academy of Sciences,Shanghai 200050,China)
With the advent of big data,data volume and complexity increase drastically,Skyline query result set is so large that it can’t provide precise information to the users.As parallel computing framework,MapReduce has been widely applied to big data processing.A result optimal algorithm, MapReduce-based dominant number algorithm(MR-DMN)is proposed,based on dominating number under MapReduce framework,which solves problem of optimization of Skyline result set in big data environments.Lots of experiments show that the algorithm has good time and space efficiency.
big data; MapReduce; Skyline; dominant number
2016—03—24
國家自然科學基金資助項目(61370088);國家科技支撐計劃資助項目(2013BAH51F01);安徽省高校自然科學研究基金資助項目(KJ2012A233);中國科學院無線傳感網絡與通信重點實驗室開放課題資助項目(2013003)
10.13873/J.1000—9787(2017)02—0146—04
TP 274
A
1000—9787(2017)02—0146—04
林 娟(1992-),女,通訊作者,碩士研究生,主要研究方向為信號處理。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
