基于傳遞收縮剪枝策略的并行頻繁項集挖掘算法的研究
2016-12-28 05:53:29趙明
領導科學論壇 2016年19期
□ 趙明
基于傳遞收縮剪枝策略的并行頻繁項集挖掘算法的研究
□ 趙明
關聯分析作為數據挖掘中探尋事物之間聯系緊密程度的方式之一,被廣泛應用于商業,社交分析等領域,其中如何高效挖掘到頻繁項集一直都是研究重點。FP-growth以頻繁模式樹FP-tree為數據結構,極大降低了I/O吞吐,且利用并行計算,提高了計算效率。但因其需要占用大量內存,使得并行規模受到限制。本文設計了基于傳遞收縮剪枝策略的FP-growth算法,通過限制FP-tree的搜索空間,及時進行剪枝項合并,并將其在分布式平臺Spark并行化。通過實驗對比證明,較Hadoop上提升25%;相比原有的FP-growth算法PFP,在Spark平臺計算提升10%左右。
FP-growth算法;頻繁項集挖掘;傳遞收縮剪枝策略;Spark;
關聯規則作為尋找海量數據中事物聯系緊密程度的方法之一,隨著近幾年電子商務的迅猛發展,在商業領域中,顯示出了強大的生命力。而對頻繁項集的挖掘,作為關聯規則的核心思想,已成為各類學者研究的焦點。但當其面對互聯網的海量數據時,計算量和I/O量都非常大,傳統的串行算法已不能勝任,通過并行化頻繁項集挖掘算法拓展它們的使用場景。
頻繁項集挖掘算法FP-growth,雖降低了對數據庫的I/ O,但其在構建樹形結構時,仍占用了大量的內存資源。雖可以使用并行化可以緩解其過高的內存占用,但因其依賴進程間的通信來協調樹形變化,往往導致并行計算效率較低、內存開銷大且不能夠實現多節點的橫向擴展。對此本文提出了如下創新點:
(1)TCPFP(Transitive Compression Pruning FP-growth algorithm)算法利用了傳遞收縮剪枝策略對FP-growth頻繁項集的搜索空間進行限制,通過傳遞收縮剪枝,及時進行項合并,降低了內存占用,提高算法挖掘速度。
(2)在Spark平臺上并行化了基于傳遞收縮剪枝的FP-growth算法TCPFP。利用其彈性分布式數據集及基于內存計算模式,在對比傳統的FP-growth算法在Hadoop或Spark平臺的挖掘效率上,提升挖掘效率10%。
一、關聯規則挖掘算法
Apriori算法作為關聯規則的經典挖掘算法之一,利用了頻繁項集的先驗知識。將頻繁項集中任意一非空子集劃為頻繁項集。但其運算過程中,需要占用巨大的I/O,拼接產生過多的候選集,效率不高。之后也有利用動態項集計數算法DIC(Dynamic Itemset Counting);或是采用分治法的思想來解決內存不夠用的分塊挖掘算法(Partition)等。
相比Apriori算法,2000年提出FP-growth算法以頻繁模式樹為基礎,只掃描兩次數據庫,大大降低了I/O吞吐。采用深度優先的搜索方式,提高挖掘效率。FP-growth算法有兩個主要步驟:1.頻繁模式樹FP-tree的構造;2.對FP-tree進行頻繁模式挖掘。FP-tree構造時,將數據庫中所有的記錄信息壓縮進去,保留每條交易記錄中數據項之間的聯系。通過掃描數據庫,計算出所有的頻繁1-項集,并按支持度計數排序,刪去小于最小支持度的頻繁項;再來插入到FP-tree中,通過共享相同的數據項前綴,把項頭表(Header table)中的每個頻繁項鏈接到FP-tree中去。然后,對頻繁模式進行挖掘。若FP-tree中的含有單個路徑L,則直接抽取條件模式基;若不包含單個路徑,則對項頭表中每個元素生成條件模式。然后構造其元素的條件模式基和條件模式樹,若條件模式樹不為空,則遞歸找出所有的頻繁項集。
傳統單線程遞歸挖掘頻繁項集,效率底下,隨著Ha?doop分布式并行執行的思想流傳開來。國內外學者,將頻繁項集挖掘與并行化結合起來,展開多方面的研究。Rion?dato等人將FP-growth算法以Hadoop框架為基礎研究提出了PARMA算法,主要是采用減小事務集的大小從而得到時間上的節省。或利用數據本地化的思想減少FP-growth算法在Hadoop中的網絡通信量。還有針對FP-tree和項頭表的數據結構進行改進以及對單路徑問題進行優化,并在Spark上并行實現的。但因其在內存中占用大量空間構建樹形結構,會使其因數據項過多或過深導致FP-tree構造失敗,或遞歸構建了空間復雜度過高的條件模式基。即便其利用了分布式計算平臺,也需要消耗大量內存用于維護樹形的進程通訊,會使得分布式節點難以橫向拓展,并行優勢無法徹底發揮出來。因此本文針對FP-growth算法內存占用高,搜索空間復雜,引入傳遞收縮剪枝策略對搜索空間進行限制,使得其在分布式平臺Spark上有著較高的挖掘效率。
二、基于傳遞收縮剪枝策略的FP-growth算法TCPFP
1.符號定義及理論證明
在挖掘頻繁項集中,我們定義葉子節點上的頻繁項y。在FP-tree上,以y為起點,倒序遍歷直到root的一串節點序列,我們稱為y的傳遞路徑R。即y和root節點的之間連接的一條路徑,包含y本身以及root節點。一般的對于頻繁項y,不止一條傳遞路徑R。通過對傳遞路徑進行收縮,刪去頻繁項y,作為y的傳遞收縮路徑,簡稱收縮路徑Rc。
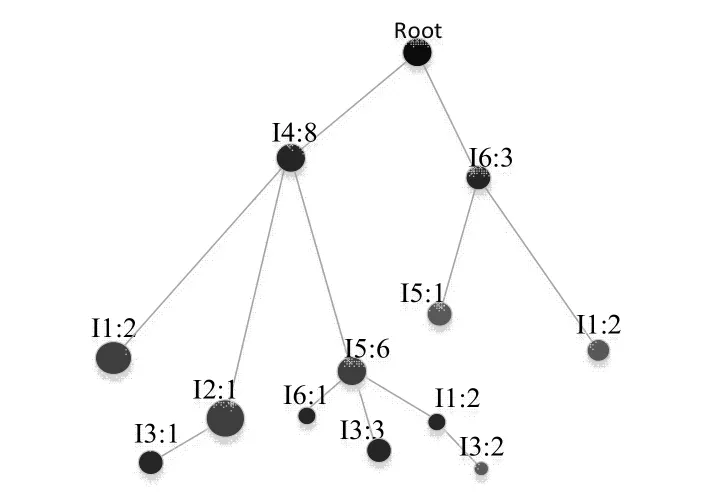
Figure 1 Schematic diagram of FP-tree圖1:FP-tree示意圖
如上圖所示,假設y為I3,則有R為{I3,I2,I4,Root},{I3, I5,I4,Root},{I3,I1,I5,I4,Root}三條路徑。而對于I5來說,其傳遞路徑只有一條{I5,I6,Root}。同理,我們可以得到頻繁項I3的收縮路徑Rc為{I2,I4,Root},{I5,I4,Root},{I1,I5,I4, Root},而I5的收縮路徑為{I6,Root}。
剪枝策略:傳遞收縮剪枝TCP。若頻繁項y存在多條收縮路徑Rc1到Rcn,路徑之間存在非空交集。通過提取交集,合并收縮路徑,將頻繁項y的支持度累加計算,收縮路徑的起點頻繁項,減去因為收縮合并移除的支持度。
證明:若包含頻繁項y的N個頻繁項集中存在包含關系,如A包含B。但A不包含B的任何真超集,則令A∪B形成一個閉頻繁項集。因此在兩個頻繁項集A,B中,y的收縮路徑Rc1和Rc2存在交集路徑Ry。則FP-tree在剪枝之前得到y的條件模式基為{{Rc1:m},{Rc2:n}},產生的頻繁模式為{Ry:m+n}。FP-tree在剪枝之后得到y的條件模式基為{Rc1∩Rc2:m+n},產生的頻繁模式為{Ry:m+n}。FP-tree在剪枝之后與剪枝前得到包含y的頻繁模式一樣。因此,下界路徑Rc2就可以剪枝合并在路徑Rc1上。
所以根據剪枝策略,對I3進行剪枝,則有三條收縮路徑的Rc的交集為{I4,Root},所以經過剪枝和項合并之后有R{I3,I4,Root},生成的條件模式基為{I3,I4,Root:6}。
2.算法流程設計
在建立好頻繁模式樹FP-tree之后,我們可以利用傳遞收縮剪枝策略TCP來對FP-tree進行剪枝和挖掘,其操作步驟如下:
第一步:判斷建立好的FP-tree是否包含無分支的單路徑,若存在單路徑R,把該路徑R中每個元素和模式合并生成頻繁項集,條件模式基即為生成的頻繁模式記為{R:m},m為路徑R中節點的支持度。
第二步:從底部開始遍歷FP-tree的項頭表Header ta?ble,得到每個葉子節點上的頻繁項y的傳遞路徑R,并將所有傳遞路徑按頻繁項統計出來,得到所有頻繁項y在FP-tree上的傳遞路徑R1~Rn。
第三步:將傳遞路徑進行收縮,在對應頻繁項路徑集合中,刪去該頻繁項y,獲得收縮路徑Rc1到Rcn。
第四步:尋找每個頻繁項的收縮路徑中是否存在交集,若存在提取交集,剪枝合并,將支持度疊加的同時減去上一級的支持度。
第五步:檢查FP-tree經過剪枝合并后,判斷頻繁項是否存在多條傳遞路徑,若是回到第一步,如果不是則繼續向下執行第六步。
第六步:對項頭表中的每個頻繁項y,生成頻繁模式記為{Ry:m},該模式中的m等于y的支持度。
根據算法TCPFP,圖1中的FP-tree有I3和I1作為葉子節點上的頻繁項,其收縮路徑存在交集,其中I3提取交集之后其路徑R為{I3,I4,Root},I1為{I1,Root}。在進行項合并時,與I3直連枝干節點,支持度會降低。所以可以看到,原有的I2,I5會因I3合并,支持度分別將至0和1。剪去支持度為0的枝干,構成新的FP-tree如圖2。
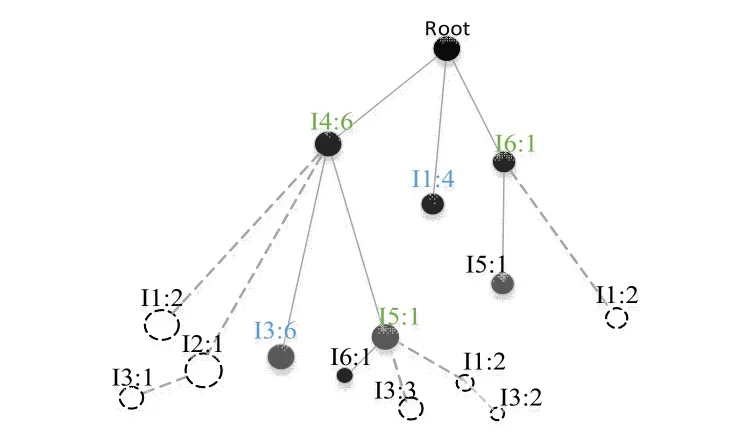
Figure 2 The FP-tree after pruning圖2:經修剪之后的FP-tree
三、Spark并行化
Spark作為分布式并行數據處理框架,利用了MapRe?duce計算思想,將job基于內存模式進行并行計算,省去了Hadoop中大量的磁盤上的I/O。對于FP-growth算法的并行化,主要通過并行投影的方式對數據庫進行劃分,再對每個投影數據庫進行FP-growth處理。按照MapReduce的計算思想,操作分為三步。
第一步:數據切分與并行計數。這里不同的分布式計算平臺會有著不同的方案,Hadoop會利用HDFS設定的block(通常為64MB)來切分存儲在不同的DataNode的節點磁盤上;Spark會利用彈性式數據分布集RDD將數據庫中的數據序列化后引入內存。然后,我們可以通過Mapper方法將每個投影數據庫中的項并行統計,得到形如<key=”items”,value=”sum”>的鍵值對;通過Reducer方法對所有鍵值對按照value值排序,刪除不滿足最小支持度的鍵值對。
第二步:均衡分組。將每個投影數據庫中的頻繁項gid均衡分組,使得分布式處理能力相差不大,并將分組情況寫到一個頻繁項分組表Glist中去。
第三步:FP-growth挖掘。利用多個job在不同的主機上分別處理不同的投影數據庫。Mapper端根據Glist來產生互不依賴的事務記錄。Reducer端對這些來自不同分組的數據庫建立FP-tree進行頻繁項集挖掘。
算法TCPFP在Spark上面并行化的時,會在第三步操作有所不同,即頻繁項集的挖掘。其具體操作:
(1)map。讀取Glist到內存中,刪掉不在其投影上的頻繁項,并根據出現順序,將事務T中的前n項作為一個事務保留到gid的分組中去。生成形如<key=“gid”,value= {t1,t2,…,tn}>的鍵值對。
(2)combiner。將上一步并行分組后的互不依賴的事務記錄,利用Combiner將鍵值對中key值一樣的進行合并。方便后期生成FP-tree。
(3)reduceByKey。根據事務組中的記錄,創建本地FP-tree。利用基于傳遞收縮剪枝策略的FP-growth算法限制搜索空間進行頻繁項的挖掘。輸出形如<key=“num”,value=“itemsets”>的鍵值對。
圖3為整個FP-growth在Spark上并行化的流程示意圖。通過從HDFS中讀取數據庫信息之后,Spark將整個計算過程包括中間結果都運行在內存上。降低了頻繁的I/O。
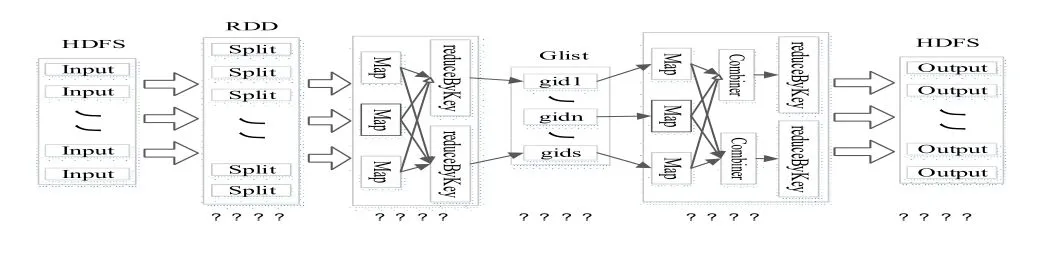
Figure3 The process of FP-growth algorithm parallel exe?cution on Spark圖3:FP-growth算法在Spark上并行執行的流程
相比于Hadoop將每一步的中間結果都會輸出到HDFS中進行存儲,一般HDFS都是由位于機架上的磁盤陣列構成,這個讀取寫入會占用大量的時間,降低處理效率。Spark利用了基于內存的讀寫模式,使得整體計算挖掘效率大幅提高。
四、實驗結果及分析
為了驗證TCPFP算法的有效性,本文設計了在分布式并行計算的環境下對比,原有的PFP(FP-growth)算法與TCPFP算法,以及TCPFP在Spark以及Hadoop平臺上的不同。
實驗利用了4臺主機搭建而成的Hadoop集群,統一安裝ubuntu14.04運行Hadoop2.6和Saprk1.5.2。使用JDK版本為1.8,Scala2.11.7。通過局域網將集群連接起來。采用電子商務網站的訂單數據集總計400W條,通過復制拷貝增加數據集量。其四臺主機的節點分布具體配置如表1.
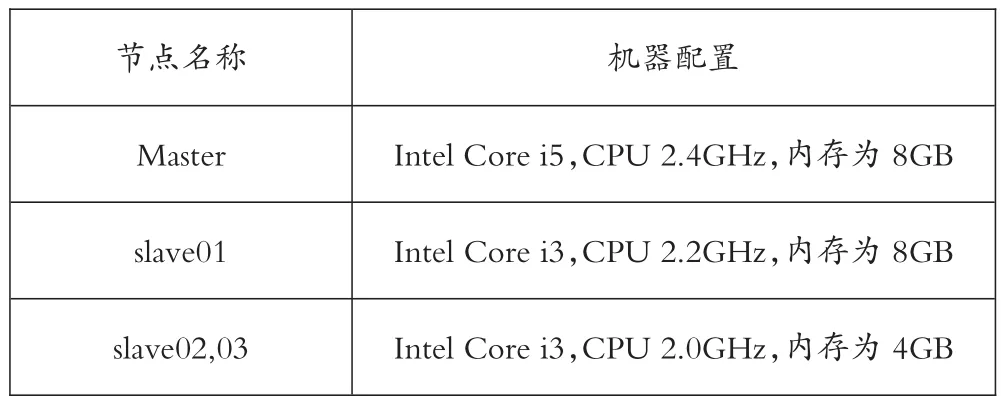
Table 1 Experimental environment configuration表1 實驗環境配置
通過配置不同的數據集大小,我們獲得如圖4中的測試結果。可以對比看出原有的PFP算法在Spark上運行時間,以及TCPFP在Hadoop和Spark上面運行時間的對比。
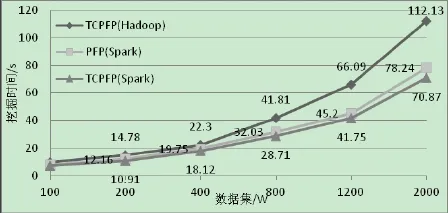
Figure4 The mining time of PFP and TCPFP on distribut?ed platforms圖4:PFP及TCPFP在各分布式平臺上的挖掘時間
可以很明顯地看出Spark在對比Hadoop時有明顯效率提升,約為25%以上的提升。利用了收縮剪枝策略的TCP?FP,比傳統的頻繁項集挖掘算法快10%左右。另外,我們在數據集拷貝4份達2000W條時,設立一組PFP與TCPFP的對比試驗。針對性的分析對比其在各個Spark中各個階段的用時長短。

Figure5 The comparison of operation time between PFP and TCPFP on Spark platform圖5:Spark平臺上PFP與TCPFP各階段運算時間比較
從圖5中可以看出,將TCPFP與PFP算法分步驟比較時,map和combiner階段區別不大,其主要就是reduce?ByKey階段,說明算法TCPFP能通過及時項合并與剪枝,減少了約12%的挖掘時間。
五、總結
針對原有頻繁項集挖掘中的迭代次數多運算量,本文利用了Spark分布式平臺,將原PFP算法進行并行計算。面對并行計算中的樹規模變大導致的內存占用大,效率下降等問題,設計了基于傳遞收縮剪枝策略的TCPFP算法,實驗對比了Hadoop平臺中TCPFP,以及Spark平臺中PFP的運算結果,證明TCPFP算法相比于PFP在Saprk平臺上提升了挖掘效率10%左右。
[1]孟小峰,慈祥.大數據管理:概念、技術與挑戰[J].計算機研究與發展,2013,50(1).
[2]LAMINE M,NHIEN L,TAHAR M.Distributed Fre?quent Itemsets Mining in Heterogeneous Platforms[J]. Journal of Engineering,Computing and Architecture,2007,1(2):1-12.
[3]Agrawal R,Srikant R.Fast algorithms for mining asso?ciation rules.20[J].Proc.int.conf.very Large Databases Vldb,1994,23(3):21-30.
[4]Brin S,Motwani R,Ullman J D,et al.Dynamic itemset counting and implication rules for market basket data [J].Acm Sigmod Record,2001,26(2):255-264.
[5]Savasere A,Omiecinski E,Navathe S B.An Efficient Algorithm for Mining Association Rules in Large Data?bases[J].Vldb Journal,1995:432-444.
[6]Han J,Pei J,Yin Y.Mining frequent patterns without candidate generation[J].Acm Sigmod Record,2000,29 (2):1-12.
[7]馬月坤,劉鵬飛,張振友,等.改進的FP-Growth算法及其分布式并行實現[J].哈爾濱理工大學學報,2016,(2).
[8]Riondato M,Debrabant J A,Fonseca R,et al.PAR?MA:A Parallel Randomized Algorithm for Approxi?mateAssociationRulesMininginMapReduce[C]// Proceedingsofthe21stACMInternationalConfer?enceonInformationandKnowledgeManagement (CIKM 2012).2012:85-94.
[9]章志剛,吉根林.一種基于FP-Growth的頻繁項目集并行挖掘算法[J].計算機工程與應用,2014,(2).
[10]鄧玲玲,婁淵勝,葉楓.FP-growth算法改進與分布式Spark研究[J].微型電腦應用,2016,32(5).
[11]HAN Jiawei,KAMBER Micheline.數據挖掘:概念與技術[M].北京:機械工業出版社,2013.
[12]謝朋峻.基于MapReduce的頻繁項集挖掘算法的并行化研究[D].南京:南京大學,2012.
[13]Duong Q H,Liao B,Fournier-Viger P,et al.An effi?cient algorithm for mining the top-k,high utility itemsets,usingnovelthresholdraisingandpruning strategies[J].Knowledge-Based Systems,2016,104:106-122.
責任編輯:夏曉暢
湖北省咸寧市公安局。
TP392
A
2095-5103(2016)20-0079-04
10.11907/rjdk.1511517
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
中學生數理化·七年級數學人教版(2021年11期)2021-12-06 05:38:48
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
財經(2017年15期)2017-07-03 22:40:49
數學小靈通·3-4年級(2017年6期)2017-06-22 11:28:50
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
